No início deste ano, a Elastic anunciou a colaboração com a NVIDIA para trazer aceleração de GPU ao Elasticsearch, integrando-se com a NVIDIA cuVS—conforme detalhado em uma sessão na NVIDIA GTC e em vários blogs. Esta postagem é uma atualização sobre o esforço de coengenharia com a equipe de busca vetorial da NVIDIA.
Resumo
Primeiro, vamos atualizá-lo. O Elasticsearch se estabeleceu como um poderoso banco de dados vetorial, oferecendo um rico conjunto de recursos e um forte desempenho para buscas por similaridade em larga escala. Com recursos como quantização escalar, Better Binary Quantization (BBQ), operações vetoriais SIMD e algoritmos mais eficientes em termos de disco, como DiskBBQ, ele já oferece opções eficientes e flexíveis para o gerenciamento de cargas de trabalho vetoriais.
Ao integrar o NVIDIA cuVS como um módulo chamável para tarefas de busca vetorial, buscamos entregar ganhos significativos no desempenho e eficiência da indexação vetorial para melhor suportar cargas de trabalho vetoriais em grande escala.
O desafio
Um dos maiores desafios na construção de um banco de dados vetorial de alto desempenho é a construção do índice vetorial - o gráfico HNSW. Rapidamente, a construção de índices se torna dominada por milhões ou até bilhões de operações aritméticas, à medida que cada vetor é comparado com muitos outros. Além disso, operações do ciclo de vida do índice, como compactação e fusões, podem aumentar ainda mais a sobrecarga total de processamento da indexação. À medida que os volumes de dados e os embeddings vetoriais associados crescem exponencialmente, GPUs de computação acelerada, construídas para paralelismo massivo e matemática de alto rendimento, estão idealmente posicionadas para lidar com essas cargas de trabalho.
Apresentando o plugin Elasticsearch-GPU
NVIDIA cuVS é uma biblioteca open source CUDA-X para busca vetorial acelerada por GPU e clustering de dados que permite a construção rápida de índices e recuperação de embeddings para cargas de trabalho de IA e recomendação.
O Elasticsearch utiliza o cuVS através do cuvs-java, uma biblioteca de open source desenvolvida pela comunidade e mantida pela NVIDIA. A biblioteca cuvs-java é leve e se baseia na API C do cuVS, utilizando a função estrangeira Panama para expor os recursos do cuVS de uma maneira idiomática em Java, mantendo-se moderna e eficiente.
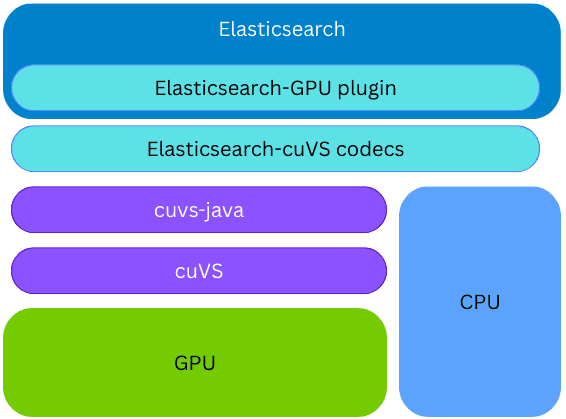
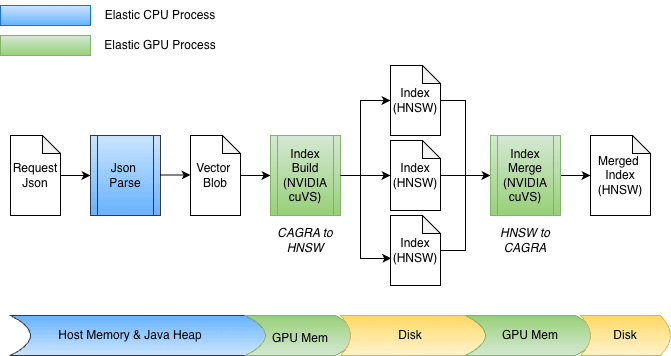
A biblioteca cuvs-java está integrada a um novo plugin do Elasticsearch; portanto, a indexação na GPU pode ocorrer no mesmo node e processo do Elasticsearch, sem a necessidade de provisionar qualquer código ou hardware externo. Durante a criação do índice, se a biblioteca cuVS estiver instalada e uma GPU estiver presente e configurada, o Elasticsearch usará a GPU para acelerar o processo de indexação vetorial. Os vetores são fornecidos à GPU, que constrói um gráfico CAGRA. Esse gráfico é então convertido para o formato HNSW, tornando-o imediatamente disponível para busca vetorial na CPU. O formato final do gráfico construído é o mesmo que seria construído na CPU; isso permite que o Elasticsearch utilize GPUs para indexação de alto desempenho quando o hardware subjacente a suporta, liberando poder de processamento da CPU para outras tarefas (buscar, processamento de dados, etc.).
Aceleração de construção de índice
Como parte da integração da aceleração de GPU no Elasticsearch, várias melhorias foram feitas no cuvs-java, focando na entrada/saída eficiente de dados e na invocação de funções. Uma melhoria importante é o uso de cuVSMatrix para modelar vetores de forma transparente, independentemente de estarem na heap do Java, fora da heap ou na memória da GPU. Isso permite que os dados se movam eficientemente entre a memória e a GPU, evitando cópias desnecessárias de potencialmente bilhões de vetores.
Graças a essa abstração subjacente de cópia zero, tanto a transferência para a memória da GPU quanto a recuperação do gráfico podem ocorrer diretamente. Durante a indexação, os vetores são primeiro armazenados em buffer na memória do heap Java e depois enviados para a GPU para construir o gráfico CAGRA. O gráfico é posteriormente recuperado da GPU, convertido para o formato HNSW e persistido no disco.
No momento da fusão, os vetores já estão armazenar no disco, ignorando completamente o heap Java. Os arquivos de índice são mapeados em memória, e os dados são transferidos diretamente para a memória da GPU. O projeto também acomoda facilmente diferentes larguras de bits, como float32 ou int8, e se estende naturalmente a outros esquemas de quantização.
Drumroll... então, como funciona?
Antes de entrarmos nos números, um pouco de contexto é útil. A fusão de segmentos no Elasticsearch normalmente é executada de forma automática em segundo plano durante a indexação, o que dificulta a realização de testes de desempenho isoladamente. Para obter resultados reprodutíveis, usamos a fusão forçada para desencadear explicitamente a fusão de segmentos em um experimento controlado. Como a fusão forçada realiza as mesmas operações subjacentes de fusão que a fusão em segundo plano, seu desempenho serve como um indicador útil das melhorias esperadas, mesmo que os ganhos exatos possam diferir nas cargas de trabalho de indexação do mundo real.
Agora, vamos ver os números.
Nossos resultados iniciais de benchmark são muito promissores. Executamos o benchmark em uma instância AWS g6.4xlarge com armazenamento NVMe conectado localmente. Um único node do Elasticsearch foi configurado para usar o número padrão e ideal de threads de indexação (8 - uma para cada núcleo físico) e para desativar a limitação de mesclagem (o que é menos aplicável com discos NVMe rápidos).
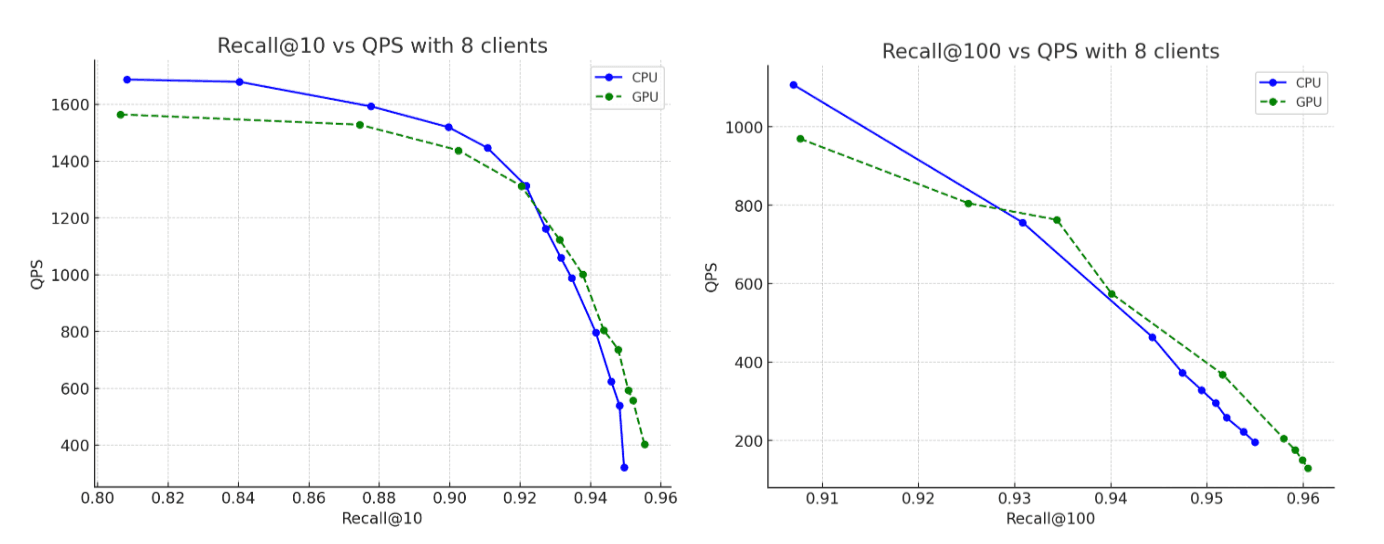
Para o conjunto de dados, usamos 2,6 milhões de vetores com 1.536 dimensões da trilha vetorial do OpenAI Rally, codificados como strings base64 e indexados como float32 hnsw. Em todos os cenários, os gráficos construídos atingem níveis de recall de até 95%. Veja o que descobrimos:
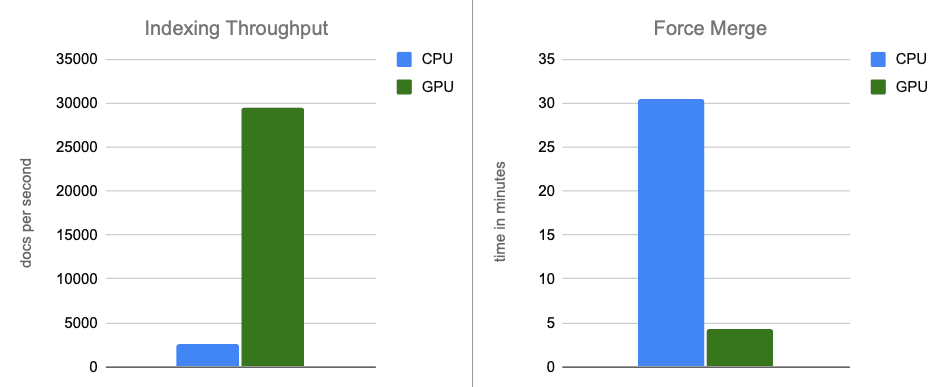
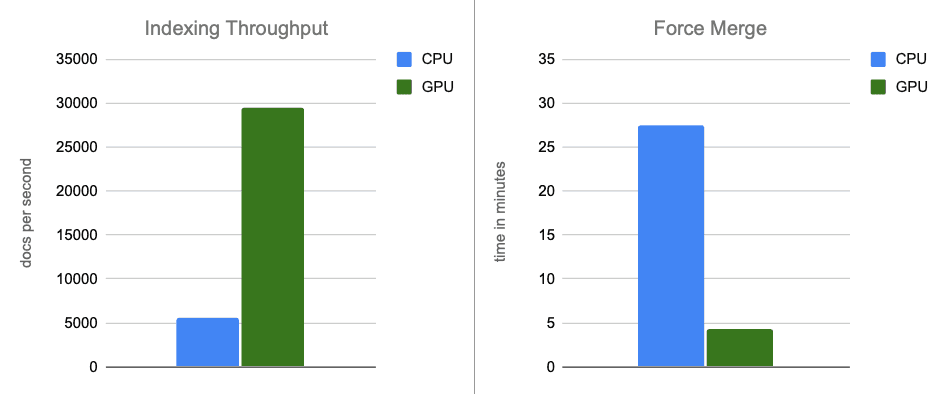
- Taxa de transferência de indexação: ao transferir a construção de gráficos para a GPU durante as descargas de buffer na memória, aumentamos a taxa de transferência em cerca de 12 vezes.
- Fusão forçada: após a conclusão da indexação, a GPU continua acelerando a fusão de segmentos, acelerando a fase de mesclagem forçada em aproximadamente 7x.
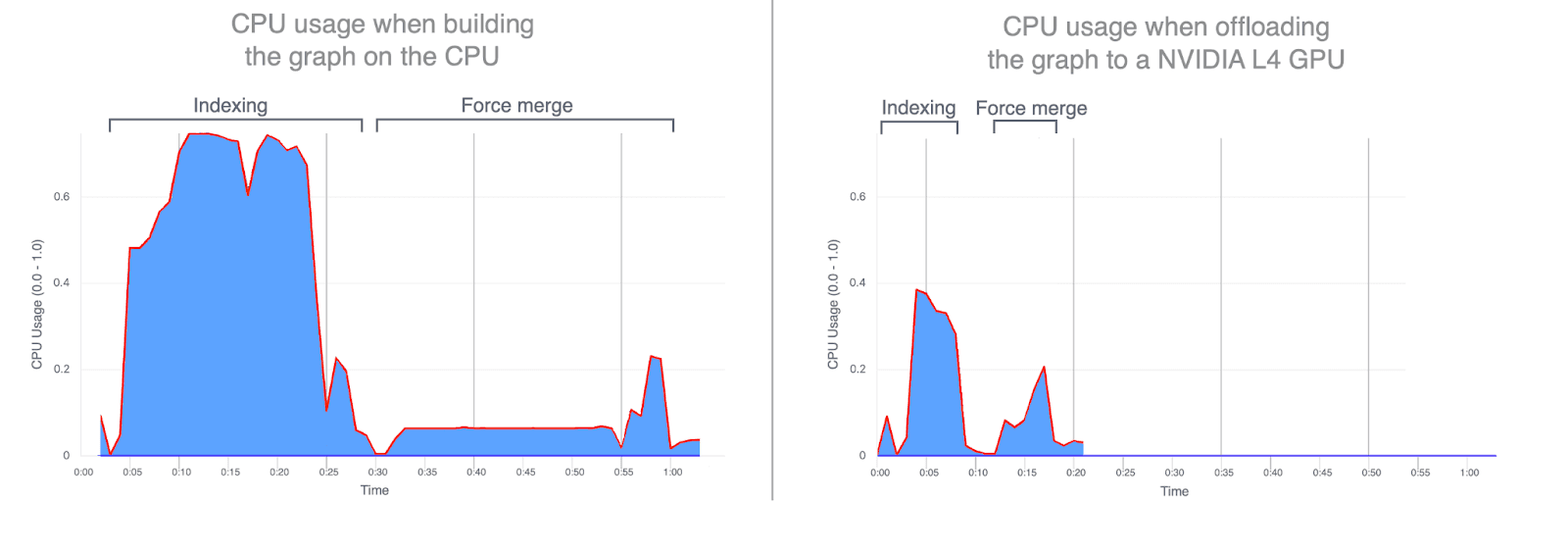
- Uso da CPU: o descarregamento da construção de gráficos para a GPU reduz significativamente a utilização média e de pico da CPU. Os gráficos abaixo ilustram o uso da CPU durante a indexação e a fusão, destacando o quanto é menor quando essas operações são executadas na GPU. Menor utilização da CPU durante a indexação da GPU libera ciclos de CPU que podem ser redirecionados para melhorar o desempenho da busca.
- Lembrete: a precisão permanece efetivamente a mesma entre as execuções de CPU e GPU, com o gráfico construído por GPU alcançando um recall marginalmente mais alto.
Comparando em outra dimensão: Preço
A comparação anterior usava intencionalmente hardware idêntico, com a única diferença sendo se a GPU era usada durante a indexação. Essa configuração é útil para isolar efeitos brutos de computação, mas também podemos olhar para a comparação dos custos.
Por aproximadamente o mesmo preço por hora da configuração acelerada por GPU, é possível provisionar uma configuração apenas CPU com aproximadamente o dobro dos recursos comparáveis de CPU e memória: 32 vCPUs (AMD EPYC) e 64 GB de RAM, permitindo dobrar o número de threads de indexação para 16.
Para manter a comparação justa e consistente, executamos esse experimento apenas com CPU em uma instância AWS g6.8xlarge, com a GPU explicitamente desativada. Isso nos permitiu manter todas as outras características de hardware constantes ao avaliar a relação custo-desempenho da aceleração da GPU em comparação com a indexação somente da CPU.
A instância mais potente da CPU mostra desempenho melhor em comparação com os benchmarks da seção acima, como era de se esperar. No entanto, ao compararmos essa instância de CPU mais potente com os resultados originais acelerados por GPU, a GPU ainda oferece ganhos de desempenho substanciais: melhoria de aproximadamente 5 vezes na taxa de transferência de indexação e aproximadamente 6 vezes na fusão forçada, tudo isso enquanto constrói gráficos que atingem níveis de recall de até 95%.
Conclusão
Em cenários de ponta a ponta, a aceleração de GPU com NVIDIA cuVS proporciona quase 12x de melhoria na taxa de indexação e uma redução de 7x na latência de fusão forçada, com uma utilização significativamente menor da CPU. Isso mostra que a indexação vetorial e as cargas de trabalho de fusão se beneficiam significativamente da aceleração da GPU. Em uma comparação ajustada ao custo, a aceleração da GPU continua a gerar ganhos substanciais de desempenho, com taxa de transferência de indexação aproximadamente 5 vezes maior e operações de fusão forçada 6 vezes mais rápidas.
A indexação de vetores acelerada por GPU está atualmente planejada para Prévia Técnica no Elasticsearch 9.3, que está programada para ser lançada no início de 2026.
Fique ligado para mais.
Conteúdo relacionado

23 de abril de 2026
Como criamos o Elasticsearch simdvec para que a busca vetorial seja uma das mais rápidas do mundo
Como criamos o Elasticsearch simdvec, a biblioteca do kernel SIMD ajustada manualmente por trás de cada consulta de busca vetorial no Elasticsearch.

4 de maio de 2026
Como medir e melhorar o recall das buscas no Elasticsearch: de 0,43 a 0,75 com a busca híbrida
Aprenda a medir e melhorar o recall das buscas no Elasticsearch combinando a busca léxica BM25 com embeddings vetoriais do Jina AI, usando a API rank_eval para validar a melhoria com números reais.

10 de abril de 2026
Clustering não supervisionado de documentos com Elasticsearch + embeddings Jina
Uma abordagem prática e reproduzível para clustering não supervisionado de documentos com Elasticsearch e embeddings Jina.

2 de abril de 2026
Quando o TSDS encontra o ILM: projetando fluxos de dados de séries temporais que aceitam dados tardios
Como os limites de tempo do TSDS interagem com as fases do ILM e como projetar políticas que tolerem métricas atrasadas.

1 de abril de 2026
LINQ para Elasticsearch ES|QL: escreva Consultas em C# e Consulte o Elasticsearch
Explorando o novo provedor LINQ para Elasticsearch ES|QL no cliente Elasticsearch .NET, que permite escrever código C# automaticamente traduzido para consultas ES|QL.