A busca vetorial não é suficiente para encontrar resultados relevantes. É muito comum usar critérios de filtragem que ajudam a restringir os resultados da pesquisa e a eliminar os resultados irrelevantes.
Compreender como a filtragem funciona na busca vetorial ajudará você a equilibrar as vantagens e desvantagens em termos de desempenho e recall, além de descobrir algumas das otimizações usadas para tornar a busca vetorial eficiente quando a filtragem é utilizada.
Por que filtrar?
A busca vetorial revolucionou a forma como encontramos informações relevantes em grandes conjuntos de dados, permitindo-nos descobrir itens semanticamente semelhantes a uma consulta.
No entanto, simplesmente encontrar itens semelhantes não é suficiente. Frequentemente precisamos refinar os resultados da pesquisa com base em critérios ou atributos específicos.
Imagine que você está procurando um produto em uma loja de comércio eletrônico. Uma busca puramente vetorial pode mostrar itens visualmente semelhantes, mas você também pode querer filtrar por faixa de preço, marca, disponibilidade ou avaliações de clientes. Sem filtros, você se depararia com uma vasta gama de produtos similares, dificultando a busca exatamente pelo que procura.
A filtragem permite um controle preciso sobre os resultados da pesquisa, garantindo que os itens recuperados não apenas estejam alinhados semanticamente, mas também atendam a todos os requisitos necessários. Isso resulta em uma experiência de busca muito mais precisa, eficiente e fácil de usar.
É aqui que o Elasticsearch e o Apache Lucene se destacam — o uso de filtragem eficaz em vários tipos de dados é uma das principais diferenças em relação a outros bancos de dados vetoriais.
Filtrar para pesquisa vetorial exata
Existem duas maneiras principais de realizar buscas vetoriais exatas:
- Utilizando um tipo de índice
flatpara o seu campo dense_vector. Isso faz com que as buscasknnusem busca exata em vez de aproximada. - Utilizando uma consulta script_score que usa funções vetoriais para calcular a pontuação. Isso pode ser usado com qualquer tipo de índice.
Ao executar uma busca vetorial exata, todos os vetores são comparados à consulta. Nesse cenário, a filtragem ajudará no desempenho, pois somente os vetores que passarem pelo filtro precisarão ser comparados.
Isso não afeta a qualidade do resultado, pois todos os vetores são considerados de qualquer forma. Estamos apenas filtrando antecipadamente os resultados que não são interessantes, para que possamos reduzir o número de operações.
Isso é muito importante, pois pode ser mais eficiente executar uma pesquisa exata em vez de uma pesquisa aproximada quando os filtros aplicados resultam em um pequeno número de documentos.
A regra geral é usar a pesquisa exata quando menos de 10 mil documentos passarem pelo filtro. Os índices BBQ são muito mais rápidos para comparações, portanto, faz sentido usar a pesquisa exata quando o número de índices baseados for inferior a 100 mil. Confira esta postagem no blog para obter mais detalhes.
Caso seus filtros sejam sempre muito restritivos, você pode considerar indexar focando na busca exata em vez da busca aproximada usando um tipo de índice flat em vez de um baseado em HNSW. Para obter mais detalhes, consulte as propriedades de index_options.
Filtragem para busca vetorial aproximada
Ao executar uma busca vetorial aproximada, trocamos precisão do resultado por desempenho. Estruturas de dados de busca vetorial, como o HNSW, pesquisam de forma eficiente os vizinhos mais próximos aproximados em milhões de vetores. Eles se concentram em recuperar os vetores mais semelhantes realizando o mínimo de comparações vetoriais possível, que são computacionalmente dispendiosas.
Isso significa que outros atributos de filtragem não fazem parte dos dados vetoriais. Diferentes tipos de dados possuem suas próprias estruturas de indexação, que são eficientes para encontrá-los e filtrá-los, como dicionários de termos, listas de postagens e valores de documentos.
Dado que essas estruturas de dados são separadas do mecanismo de busca vetorial, como aplicamos a filtragem à busca vetorial? Existem duas opções: aplicar filtros após a busca vetorial (pós-filtragem) ou antes da busca vetorial (pré-filtragem).
Cada uma dessas opções tem vantagens e desvantagens. Vamos analisar esses assuntos mais a fundo!
Pós-filtragem
A pós-filtragem aplica filtros após a pesquisa vetorial ter sido realizada. Isso significa que os filtros são aplicados depois que os k resultados vetoriais mais semelhantes forem encontrados.
Obviamente, podemos obter menos de k resultados após aplicar os filtros aos resultados. É claro que poderíamos obter mais resultados com a busca vetorial (valor k maior), mas não teríamos certeza de que obteríamos k ou mais resultados após a aplicação dos filtros.
A vantagem da pós-filtragem é que ela não altera o comportamento em tempo de execução da busca vetorial — a busca vetorial não leva em consideração a filtragem. Mas isso altera o número final de resultados obtidos.
Segue abaixo um exemplo de pós-filtragem usando a consulta knn. Verifique se a cláusula de filtragem está separada da consulta KNN:
O pós-filtro também está disponível para a pesquisa knn usando o comando post-filter:
Lembre-se de que é necessário usar uma seção de pós-filtragem explícita na pesquisa KNN. Se você não usar um filtro posterior, a pesquisa KNN combinará os resultados dos vizinhos mais próximos com outras consultas ou filtros, em vez de aplicar um filtro posterior.
Pré-filtragem
Aplicar filtros antes da busca vetorial primeiro recuperará os documentos que atendem aos filtros e, em seguida, passará essa informação para a busca vetorial.
O Lucene utiliza BitSets para armazenar de forma eficiente os documentos que satisfazem a condição do filtro. A busca vetorial percorre então o grafo HNSW, levando em consideração os documentos que satisfazem a condição. Antes de adicionar um candidato aos resultados, o sistema verifica se ele está contido no BitSet de documentos válidos.
No entanto, o candidato deve ser analisado e comparado à consulta, mesmo que não seja um documento válido. A eficácia do HNSW depende da conexão entre os vetores no grafo — se parássemos de explorar um candidato, isso significaria que também poderíamos estar ignorando seus vizinhos.
Imagine que você está dirigindo até um posto de gasolina. Se você descartar todas as estradas que não têm um posto de gasolina, é improvável que você chegue ao seu destino. Outras estradas podem não ser o que você precisa, mas elas te levam ao seu destino. O mesmo se aplica aos vetores em um grafo HNSW!
Conclui-se, portanto, que aplicar pré-filtragem tem um desempenho inferior a não aplicar filtros. Precisamos processar todos os vetores que visitamos em nossa busca e descartar aqueles que não correspondem ao filtro. Estamos trabalhando mais e dedicando mais tempo para obter nossos melhores resultados.
Segue abaixo um exemplo de pré-filtragem na DSL de consulta do Elasticsearch. Verifique se a cláusula de filtragem agora faz parte da seção knn:
O pré-filtro está disponível tanto para a pesquisa KNN quanto para a consulta KNN:
Otimizações de pré-filtragem
Existem algumas otimizações que podemos aplicar para garantir que a pré-filtragem seja eficiente.
Podemos alternar para a pesquisa exata se o filtro for muito restritivo. Quando há poucos vetores para comparar, é mais rápido realizar uma busca exata nos poucos documentos que satisfazem o filtro.
Essa é uma otimização que é aplicada automaticamente no Lucene e no Elasticsearch.
Outro método de otimização envolve desconsiderar os vetores que não satisfazem o filtro. Em vez disso, esse método verifica os vizinhos dos vetores filtrados que passam pelo filtro. Essa abordagem reduz efetivamente o número de comparações, pois os vetores filtrados não são considerados, e continua a explorar vetores conectados ao caminho atual.
Este algoritmo é o ACORN-1, e o processo é descrito em detalhes nesta postagem do blog.
Filtragem usando segurança em nível de documento
A Segurança em Nível de Documento (DLS, na sigla em inglês) é um recurso do Elasticsearch que especifica os documentos que as funções de usuário podem recuperar.
A DLS é realizada por meio de consultas. Uma função pode ter uma consulta associada a índices, o que efetivamente limita os documentos que um usuário pertencente a essa função pode recuperar dos índices.
A consulta de função é usada como um filtro para recuperar os documentos que correspondem a ela e são armazenados em cache como um BitSet. Esse BitSet é então usado para encapsular o leitor Lucene subjacente, de forma que apenas os documentos retornados pela consulta sejam considerados ativos —ou seja, eles existem no índice e não foram excluídos.
À medida que os documentos ativos são recuperados do leitor para executar a consulta KNN, somente os documentos disponíveis para o usuário serão considerados. Caso exista um pré-filtro, os documentos DLS serão adicionados a ele.
Isso significa que a filtragem DLS funciona como um pré-filtro para a busca vetorial aproximada, com as mesmas implicações de desempenho e otimizações.
A busca DLS com pesquisa exata terá os mesmos benefícios que a aplicação de qualquer filtro — quanto menos documentos forem recuperados da DLS, mais eficiente será a pesquisa exata. Considere também o número de documentos retornados pelo DLS — se as funções do DLS forem muito restritivas, você pode considerar usar a pesquisa exata em vez da pesquisa aproximada.
Benchmarking
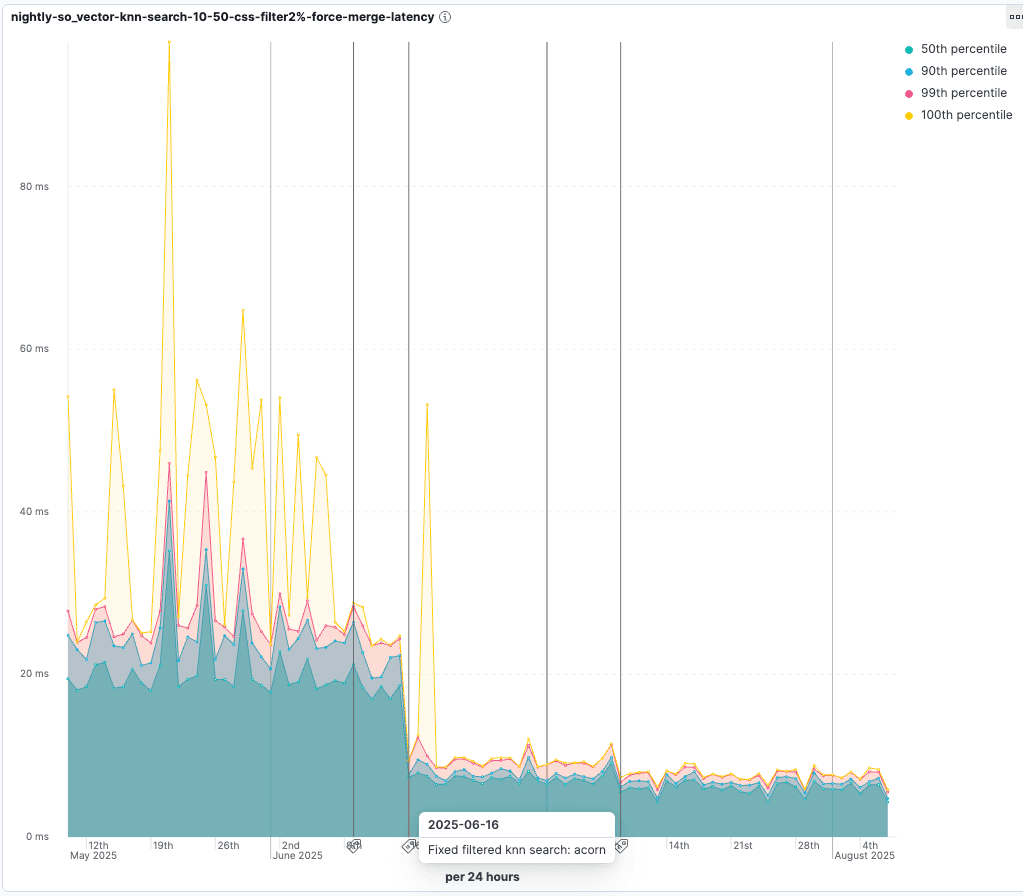
Na Elasticsearch, queremos garantir que a filtragem por vetores seja eficiente. Temos um benchmark específico para filtragem vetorial que realiza buscas vetoriais aproximadas com diferentes filtros para garantir que a busca vetorial continue recuperando resultados relevantes o mais rápido possível.
Confira as melhorias implementadas com a introdução do ACORN-1. Para testes em que apenas 2% dos vetores passam pelo filtro, a latência da consulta é reduzida para 55% da duração original:
Conclusão
A filtragem é parte integrante da pesquisa. Garantir que a filtragem seja eficiente na busca vetorial e compreender as compensações e otimizações envolvidas é o que determina o sucesso ou o fracasso de uma busca eficiente e precisa.
A filtragem afeta o desempenho da busca vetorial:
- A busca exata é mais rápida ao usar filtros. Se a sua filtragem for suficientemente restritiva, considere usar a pesquisa exata em vez da pesquisa aproximada. Esta é uma otimização automática no Elasticsearch.
- A busca aproximada é mais lenta quando se utiliza pré-filtragem. A pré-filtragem permite obter os k melhores resultados que correspondem ao filtro, ao custo de uma pesquisa mais lenta.
- A pós-filtragem não recupera necessariamente os k melhores resultados, pois eles podem ser filtrados pelo filtro quando este é aplicado.
Boa filtragem!
Conteúdo relacionado

23 de abril de 2026
Como criamos o Elasticsearch simdvec para que a busca vetorial seja uma das mais rápidas do mundo
Como criamos o Elasticsearch simdvec, a biblioteca do kernel SIMD ajustada manualmente por trás de cada consulta de busca vetorial no Elasticsearch.

4 de maio de 2026
Como medir e melhorar o recall das buscas no Elasticsearch: de 0,43 a 0,75 com a busca híbrida
Aprenda a medir e melhorar o recall das buscas no Elasticsearch combinando a busca léxica BM25 com embeddings vetoriais do Jina AI, usando a API rank_eval para validar a melhoria com números reais.

10 de abril de 2026
Clustering não supervisionado de documentos com Elasticsearch + embeddings Jina
Uma abordagem prática e reproduzível para clustering não supervisionado de documentos com Elasticsearch e embeddings Jina.

2 de abril de 2026
Quando o TSDS encontra o ILM: projetando fluxos de dados de séries temporais que aceitam dados tardios
Como os limites de tempo do TSDS interagem com as fases do ILM e como projetar políticas que tolerem métricas atrasadas.

1 de abril de 2026
LINQ para Elasticsearch ES|QL: escreva Consultas em C# e Consulte o Elasticsearch
Explorando o novo provedor LINQ para Elasticsearch ES|QL no cliente Elasticsearch .NET, que permite escrever código C# automaticamente traduzido para consultas ES|QL.