Você já quis pesquisar seu álbum de fotos por significado? Experimente buscas como "mostre-me fotos minhas onde estou usando uma jaqueta azul e sentado em um banco", "mostre-me fotos do Monte Everest" ou "saquê e sushi". Pegue uma xícara de café (ou sua bebida favorita) e continue lendo. Neste blog, mostraremos como criar um aplicativo de busca híbrido multimodal. Multimodal significa que o aplicativo consegue entender e pesquisar em diferentes tipos de entrada — texto, imagens e áudio — e não apenas palavras. Híbrido significa que combina técnicas como correspondência de palavras-chave, busca vetorial kNN e geofencing para fornecer resultados mais precisos.

Para isso, utilizamos o SigLIP-2 do Google para gerar representações vetoriais tanto para imagens quanto para texto, e as armazenamos no banco de dados vetorial Elasticsearch. No momento da consulta, convertemos a entrada da pesquisa, seja texto ou imagem, em representações vetoriais (embeddings) e executamos buscas vetoriais kNN rápidas para recuperar os resultados. Essa configuração permite uma busca eficiente de texto para imagem e de imagem para imagem. A interface Streamlit UI dá vida a este projeto, fornecendo-nos um frontend que não só permite realizar buscas textuais para encontrar e visualizar as fotos correspondentes no álbum, como também nos permite identificar o pico da montanha na imagem carregada e visualizar outras fotos dessa montanha no álbum.
Abordamos também as medidas que tomamos para melhorar a precisão da pesquisa, juntamente com dicas e truques práticos. Para uma exploração mais aprofundada, disponibilizamos um repositório no GitHub e um notebook no Colab.
Como tudo começou
Este post do blog foi inspirado por uma criança de 10 anos que me pediu para mostrar todas as fotos do Monte Ama Dablam que tirei na minha trilha até o Acampamento Base do Everest. Enquanto examinávamos o álbum de fotos, também me pediram para identificar vários outros picos de montanhas, alguns dos quais eu não sabia o nome.
Isso me deu a ideia de que este pode ser um projeto divertido de visão computacional. O que queríamos alcançar:
- Encontre fotos de um pico de montanha pelo nome.
- Adivinhe o nome do pico da montanha a partir de uma imagem e encontre picos semelhantes no álbum de fotos.
- Fazer com que as consultas de conceito funcionem (pessoa, rio, bandeiras de oração, etc.)

Monte Ama Dablam
Montando a equipe dos sonhos: SigLIP-2, Elasticsearch e Streamlit
Rapidamente ficou claro que, para isso funcionar, precisaríamos transformar tanto o texto (“Ama Dablam”) quanto as imagens (fotos do meu álbum) em vetores que pudessem ser comparados de forma significativa, ou seja, no mesmo espaço vetorial. Uma vez feito isso, a busca se torna simplesmente "encontrar os vizinhos mais próximos".

O SigLIP-2, lançado recentemente pelo Google, se encaixa bem aqui. Ele consegue gerar embeddings sem treinamento específico para a tarefa (uma configuração zero-shot ) e funciona bem para o nosso caso de uso: fotos não rotuladas e picos com nomes e idiomas diferentes. Como foi treinado para correspondência de texto ↔ imagem, uma foto da montanha tirada durante a trilha e um breve texto de exemplo resultam em representações vetoriais muito semelhantes, mesmo quando o idioma ou a ortografia da consulta variam.
O SigLIP-2 oferece um excelente equilíbrio entre qualidade e velocidade, suporta múltiplas resoluções de entrada e funciona tanto na CPU quanto na GPU. O SigLIP-2 foi projetado para ser mais resistente a fotos tiradas ao ar livre em comparação com modelos anteriores, como o CLIP original. Durante nossos testes, o SigLIP-2 gerou resultados confiáveis de forma consistente. Além disso, conta com amplo suporte, o que a torna a escolha óbvia para este projeto.
Em seguida, precisamos de um banco de dados vetorial para armazenar os embeddings e realizar buscas avançadas. Deveria suportar não apenas a busca kNN de cosseno em embeddings de imagem, mas também aplicar filtros de geolocalização e texto em uma única consulta. O Elasticsearch se encaixa bem aqui: ele lida muito bem com vetores (HNSW kNN em campos dense_vector), suporta busca híbrida que combina consultas de texto, vetores e geolocalização, e oferece filtragem e classificação prontas para uso. Ele também se adapta à escala horizontal, facilitando a expansão de um punhado de fotos para milhares. O cliente oficial do Elasticsearch para Python mantém a infraestrutura simples e se integra perfeitamente ao projeto. Por fim, precisamos de uma interface leve onde possamos inserir consultas de pesquisa e visualizar os resultados. Para uma demonstração rápida baseada em Python, o Streamlit é uma ótima opção. Ele fornece os recursos básicos de que precisamos: upload de arquivos, uma grade de imagens responsiva e menus suspensos para classificação e geolocalização. É fácil clonar e executar localmente, e também funciona em um notebook do Colab.
Implementação
Design e estratégia de indexação do Elasticsearch
Usaremos dois índices para este projeto: peaks_catalog e photos.
Índice do catálogo de picos
Este índice serve como um catálogo compacto dos picos de montanhas mais proeminentes que podem ser vistos durante a trilha até o Acampamento Base do Everest. Cada documento neste índice corresponde a um único pico de montanha, como o Monte Everest. Para cada documento de pico de montanha, armazenamos nomes/apelidos, coordenadas opcionais de latitude e longitude e um único vetor protótipo construído pela combinação de prompts de texto SigLIP-2 (e imagens de referência opcionais).
Mapeamento do índice:
| Campo | Tipo | Exemplo | Objetivo/Observações | Vetor/Indexação |
|---|---|---|---|---|
| eu ia | palavra-chave | ama-dablam | Slug/ID estável | — |
| nomes | texto + subcampo de palavra-chave | ["Ama Dablam","Amadablam"] | Aliases / nomes multilíngues; names.raw para filtros exatos | — |
| latlon | ponto_geográfico | {"lat":27.8617,"lon":86.8614} | Coordenadas GPS do pico como uma combinação de latitude/longitude (opcional) | — |
| elev_m | inteiro | 6812 | Elevação (opcional) | — |
| texto incorporado | dense_vector | 768 | Protótipo misto (com instruções e, opcionalmente, 1 a 3 imagens de referência) para este pico. | índice:true, similaridade:"cosseno", opções_de_índice:{type:"hnsw", m:16, ef_construction:128} |
Este índice é usado principalmente para buscas de imagem para imagem, como identificar picos de montanhas a partir de imagens. Também utilizamos esse índice para aprimorar os resultados de busca de texto para imagem.
Em resumo, o peaks_catalog transforma a pergunta "Que montanha é esta?" em um problema de vizinho mais próximo focado, separando efetivamente a compreensão conceitual das complexidades dos dados da imagem.
Estratégia de indexação para o índice peaks_catalog: Começamos criando uma lista dos picos mais proeminentes visíveis durante a trilha do Campo Base do Everest. Para cada pico, armazenamos sua localização geográfica, nome, sinônimos e altitude em um arquivo YAML. O próximo passo é gerar o embedding para cada pico e armazená-lo no campo text_embed . Para gerar embeddings robustos, utilizamos a seguinte técnica:
- Crie um protótipo de texto usando:
- nomes dos picos
- Conjunto de prompts (usando vários prompts diferentes para tentar responder à mesma pergunta), por exemplo:
- “uma foto natural do pico da montanha {name} no Himalaia, Nepal”
- “{name} pico emblemático na região de Khumbu, paisagem alpina”
- “{name} cume da montanha, neve, crista rochosa”
- Anti-conceito opcional (indicando ao SigLIP-2 o que não deve ser correspondido): subtrair um pequeno vetor para "pintura, ilustração, pôster, mapa, logotipo" para que haja uma preferência por fotos reais.
- Opcionalmente, crie um protótipo de imagem se forem fornecidas imagens de referência do pico.
Em seguida, combinamos o texto e o protótipo da imagem para gerar a incorporação final. Finalmente, o documento é indexado com todos os campos necessários:
Documento de exemplo do índice peaks_catalog :

Índice de fotos
Este índice principal armazena informações detalhadas sobre todas as fotos do álbum. Cada documento representa uma única fotografia, contendo as seguintes informações:
- Caminho relativo até a foto no álbum de fotos. Isso pode ser usado para visualizar a imagem correspondente ou carregar a imagem na interface de pesquisa.
- Informações de GPS e horário da imagem.
- Vetor denso para codificação de imagem gerado por SigLIP-2.
predicted_peaksIsso nos permite filtrar pelo nome do pico.
Mapeamento de índice
| Campo | Tipo | Exemplo | Objetivo/Observações | Vetor / Indexação |
|---|---|---|---|---|
| caminho | palavra-chave | dados/imagens/IMG_1234.HEIC | Como a interface do usuário abre a miniatura/imagem completa | — |
| imagem_recortada | dense_vector | 768 | Incorporação de imagem SigLIP-2 | índice:true, similaridade:"cosseno", opções_de_índice:{type:"hnsw", m:16, ef_construction:128} |
| picos_previstos | palavra-chave | ["ama-dablam","pumori"] | Top-K palpites no momento da indexação (filtro/faceta de UX barato) | — |
| GPS | ponto_geográfico | {"lat":27.96,"lon":86.83} | Ativa filtros geográficos | — |
| tempo_de_tiro | date | 2023-10-18T09:41:00Z | Tempo de captura: classificar/filtrar | — |
Estratégia de indexação para o índice de fotos: Para cada foto no álbum, fazemos o seguinte:
Extrair informações das imagens shot_time e gps dos metadados da imagem.
- Incorporação de imagem SigLIP-2: passe a imagem pelo modelo e normalize o vetor usando a notação L2. Armazene o embedding no campo
clip_image. - Preveja os picos e armazene-os no campo
predicted_peaks. Para fazer isso, primeiro pegamos o vetor de imagem da foto gerado na etapa anterior e, em seguida, executamos uma busca kNN rápida no campo text_embed no índicepeaks_catalog. Mantemos os 3 ou 4 picos mais altos e ignoramos o resto. - Calculamos o campo
_idfazendo um hash no nome e caminho da imagem. Isso garante que não teremos duplicatas após várias execuções.
Após determinarmos todos os campos da foto, os documentos fotográficos são indexados em lotes usando indexação em massa :
Exemplo de documento do índice de fotos:
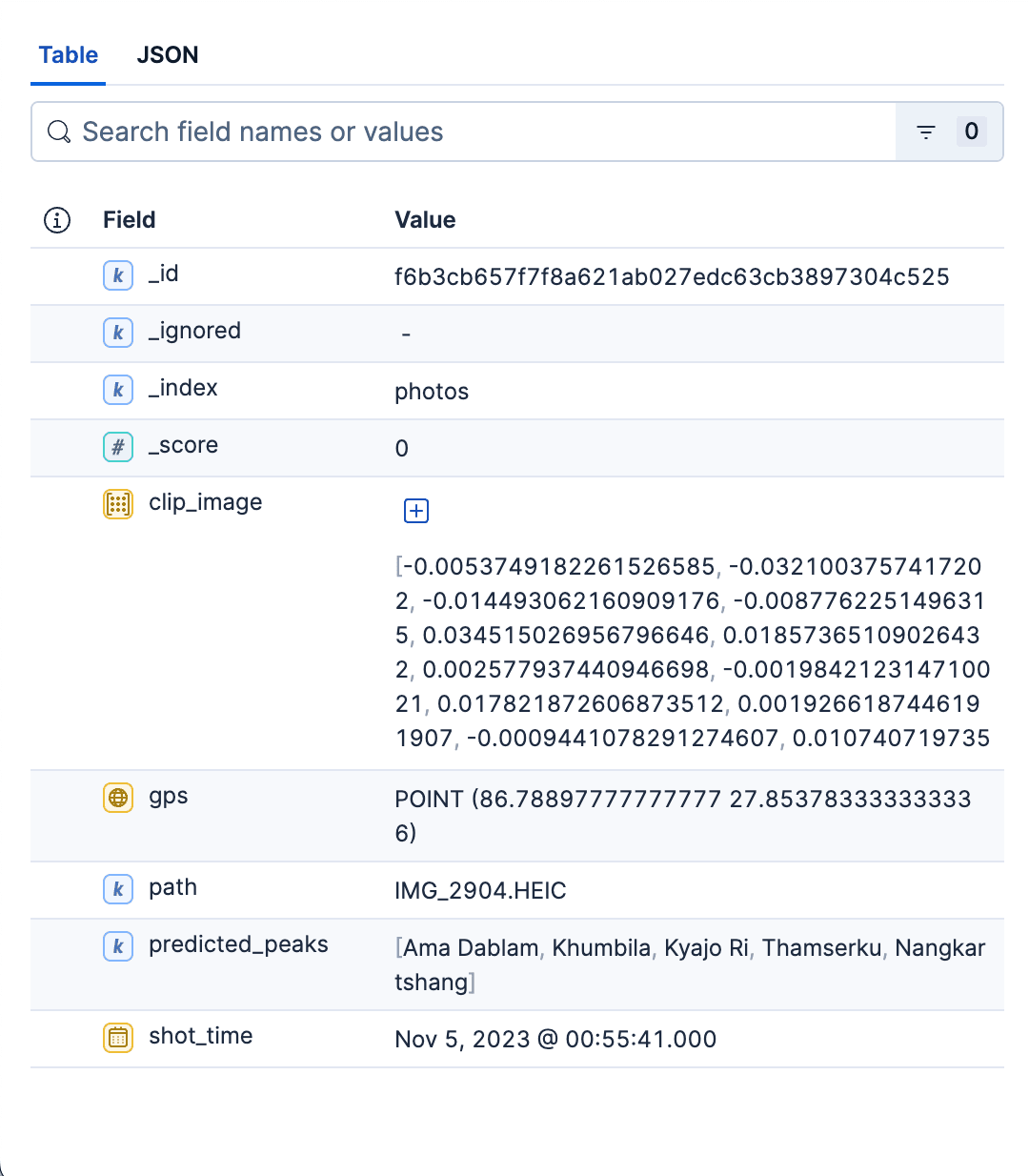
Em resumo, o índice de fotos é um armazenamento rápido, filtrável e compatível com kNN de todas as fotos do álbum. Seu mapeamento é propositalmente minimalista — apenas a estrutura necessária para recuperar rapidamente, exibir de forma clara e segmentar os resultados por espaço e tempo. Este índice serve para ambos os casos de uso de pesquisa. O script em Python para criar ambos os índices pode ser encontrado aqui.
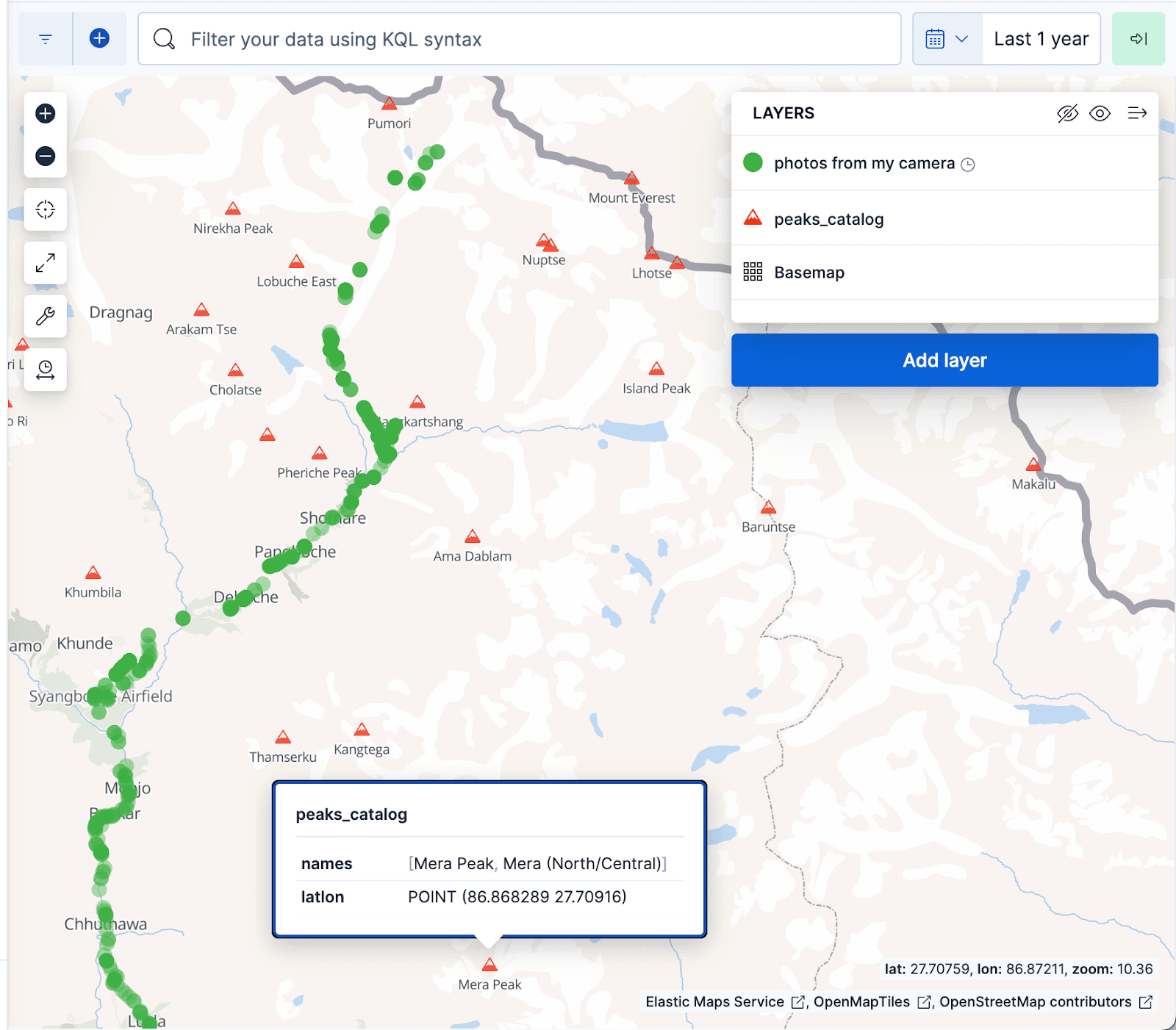
A visualização do mapa Kibana abaixo exibe documentos do álbum de fotos como pontos verdes e picos de montanhas do índice peaks_catalog como triângulos vermelhos, com os pontos verdes alinhando-se bem com a trilha da caminhada até o Acampamento Base do Everest.
Pesquisar casos de uso
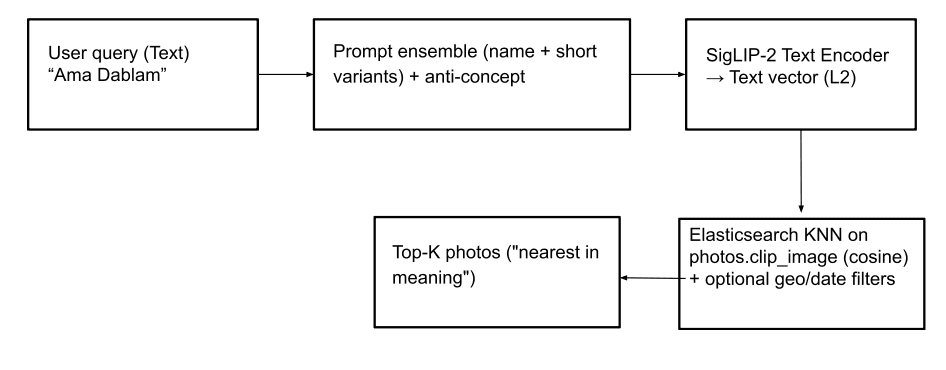
Busca por nome (texto para imagem): Este recurso permite que os usuários localizem fotos de picos de montanhas (e até mesmo conceitos abstratos como "bandeiras de oração") usando consultas de texto. Para isso, o texto de entrada é convertido em um vetor de texto usando o SigLIP-2. Para geração robusta de vetores de texto, empregamos a mesma estratégia usada para criar embeddings de texto no índice peaks_catalog : combinando a entrada de texto com um pequeno conjunto de prompts, subtraindo um vetor de anti-conceito menor e aplicando a normalização L2 para produzir o vetor de consulta final. Uma consulta kNN é então executada no campo photos.clip_image para recuperar os picos correspondentes principais, com base na similaridade de cosseno para encontrar as imagens mais próximas. Opcionalmente, os resultados da pesquisa podem ser tornados mais relevantes aplicando filtros geográficos e de data e/ou um filtro de termo photos.predicted_peaks como parte da consulta (veja exemplos de consulta abaixo). Isso ajuda a excluir picos semelhantes que, na verdade, não estão visíveis durante a trilha.
Consulta Elasticsearch com filtro geográfico:
Busca por imagem (imagem para imagem): Este recurso permite identificar uma montanha em uma imagem e encontrar outras imagens dessa mesma montanha no álbum de fotos. Quando uma imagem é carregada, ela é processada pelo codificador de imagens SigLIP-2 para gerar um vetor de imagem. Uma busca kNN é então realizada no campo peaks_catalog.text_embed para identificar os nomes de picos que melhor correspondem. Em seguida, um vetor de texto é gerado a partir desses nomes de picos correspondentes, e outra busca kNN é realizada no índice de fotos para localizar as imagens correspondentes.

Consulta do Elasticsearch:
Passo 1: Encontre os nomes de pico correspondentes.
Etapa 2: Realize uma busca no índice photos para encontrar as imagens correspondentes (mesma consulta mostrada no caso de uso de busca de texto para imagem):
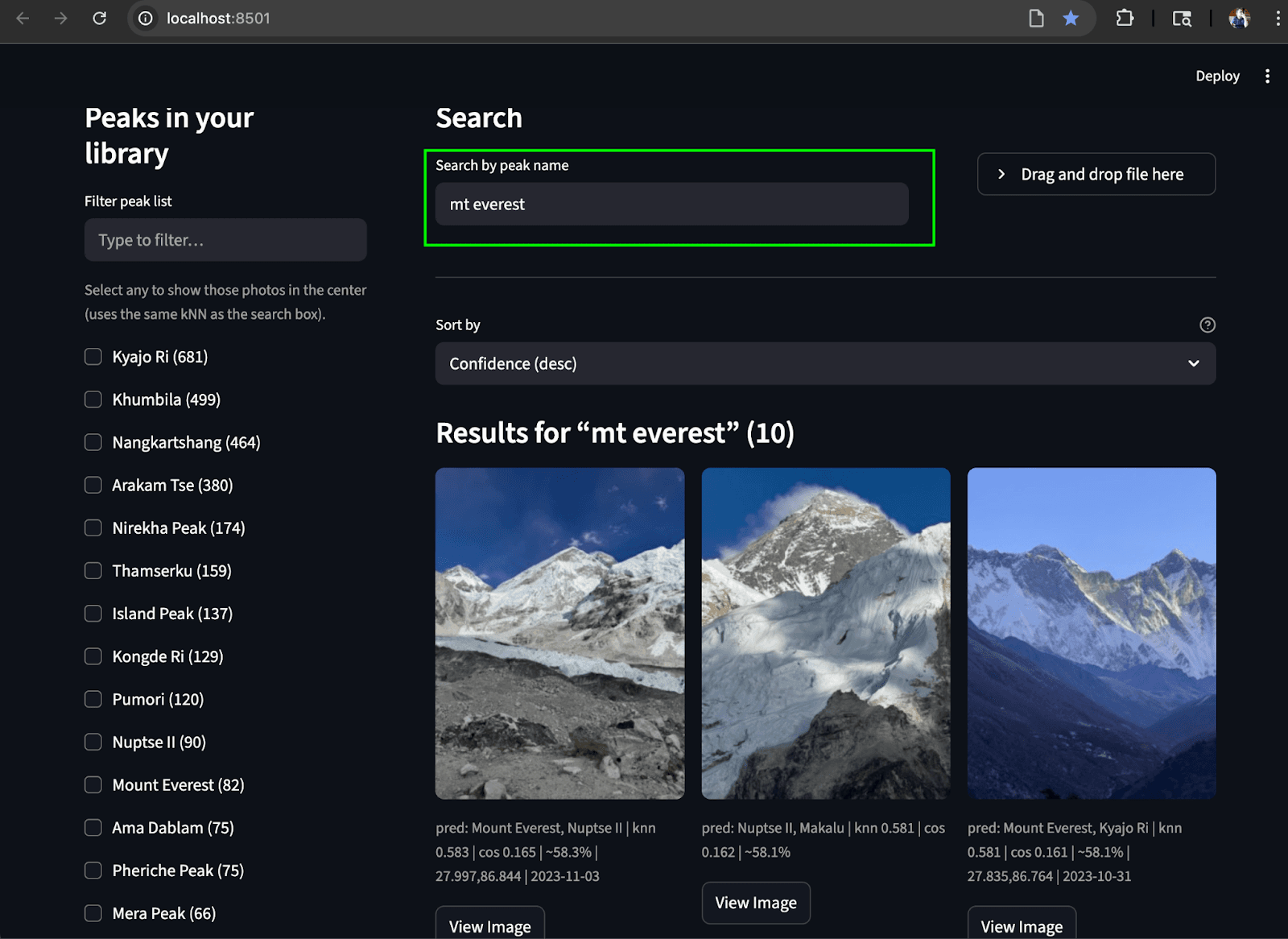
Interface de usuário Streamlit
Para integrar tudo, criamos uma interface de usuário Streamlit simples que nos permite executar ambos os casos de uso de pesquisa. A barra lateral esquerda exibe uma lista rolável de picos (agregados de photos.predicted_peaks) com caixas de seleção e um minimapa/filtro geográfico. Na parte superior, há uma caixa de pesquisa por nome e um botão para identificar o usuário a partir de uma foto enviada. O painel central apresenta uma grade de miniaturas interativa que exibe as pontuações kNN, os indicadores de pico previsto e os horários de captura. Cada imagem inclui um botão "Ver imagem" para pré-visualizações em resolução total.
Pesquisa por upload de imagem: Prevemos o pico e encontramos picos correspondentes no álbum de fotos.
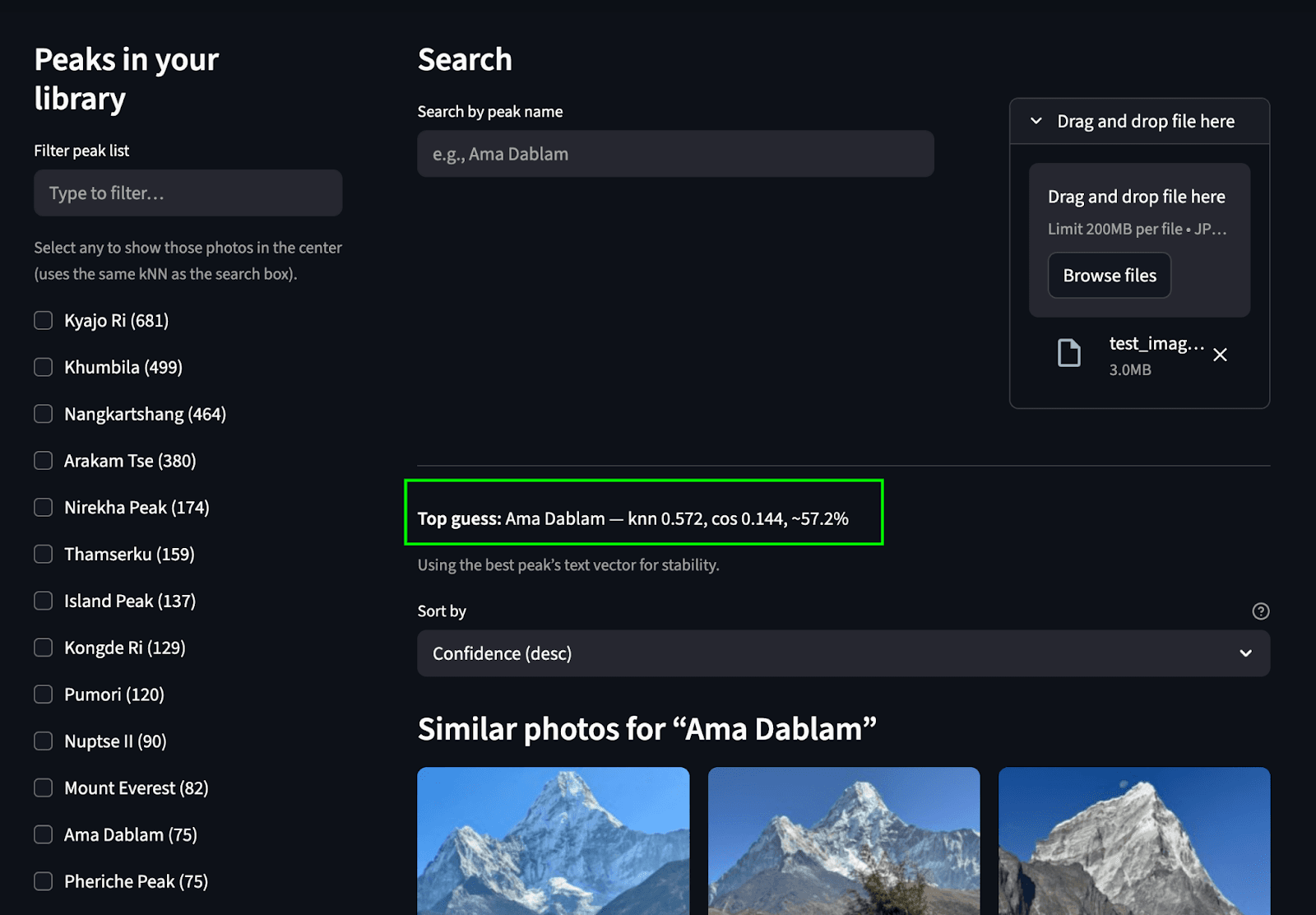
Pesquisa por texto: Encontre os picos correspondentes no álbum a partir do texto.
Conclusão
Tudo começou com uma pergunta: "Podemos ver as fotosdo Ama Dablam ?" transformou-se em um pequeno sistema de busca multimodal funcional. Capturamos fotos brutas da trilha, transformamos em embeddings SigLIP-2 e usamos o Elasticsearch para realizar uma rápida análise kNN sobre vetores, além de filtros geográficos/temporais simples para exibir as imagens relevantes. Ao longo do processo, separamos as preocupações com dois índices: um pequeno peaks_catalog de protótipos combinados (para identificação) e um índice escalável photos de vetores de imagem e EXIF (para recuperação). É prático, reproduzível e fácil de expandir.
Se você quiser ajustá-lo, existem algumas configurações que você pode modificar:
- Configurações de tempo de consulta:
k(quantos vizinhos você deseja retornar) enum_candidates(quão ampla a pesquisa antes da pontuação final). Essas configurações são discutidas no blog aqui. - Configurações de tempo de indexação:
m(conectividade do grafo) eef_construction(precisão do tempo de construção vs. memória). Para consultas, experimente também comef_search— um valor maior geralmente significa melhor recuperação com alguma compensação de latência. Consulte este blog para obter mais detalhes sobre essas configurações.
Olhando para o futuro, modelos/reclassificadores nativos para busca multimodal e multilíngue chegarão em breve ao ecossistema Elastic, o que deverá tornar a recuperação de imagens/texto e a classificação híbrida ainda mais robustas e prontas para uso. ir.elastic.co+1
Se você quiser experimentar você mesmo:
- Repositório do GitHub: https://github.com/navneet83/multimodal-mountain-peak-search
- Guia rápido do Colab: https://github.com/navneet83/multimodal-mountain-peak-search/blob/main/notebooks/multimodal_mountain_peak_search.ipynb
Com isso, nossa jornada chegou ao fim e é hora de voltar para casa. Espero que isso tenha sido útil e, se você quebrar alguma coisa (ou melhorar alguma coisa), adoraria saber o que você mudou.

Conteúdo relacionado

Descreva, não desenhe: dashboards nativos de IA do Kibana via MCP e ES|QL
Do prompt ao dashboard. Aprenda a construir dashboards do Kibana com linguagem natural, usando example-mcp-dashbuilder: uma aplicação MCP open source que escreve consultas ES|QL, cria gráficos interativos e exporta dashboards totalmente funcionais diretamente para Kibana.

23 de abril de 2026
Como criamos o Elasticsearch simdvec para que a busca vetorial seja uma das mais rápidas do mundo
Como criamos o Elasticsearch simdvec, a biblioteca do kernel SIMD ajustada manualmente por trás de cada consulta de busca vetorial no Elasticsearch.

4 de maio de 2026
Como medir e melhorar o recall das buscas no Elasticsearch: de 0,43 a 0,75 com a busca híbrida
Aprenda a medir e melhorar o recall das buscas no Elasticsearch combinando a busca léxica BM25 com embeddings vetoriais do Jina AI, usando a API rank_eval para validar a melhoria com números reais.

10 de abril de 2026
Clustering não supervisionado de documentos com Elasticsearch + embeddings Jina
Uma abordagem prática e reproduzível para clustering não supervisionado de documentos com Elasticsearch e embeddings Jina.

2 de abril de 2026
Quando o TSDS encontra o ILM: projetando fluxos de dados de séries temporais que aceitam dados tardios
Como os limites de tempo do TSDS interagem com as fases do ILM e como projetar políticas que tolerem métricas atrasadas.