Recentemente, a OpenAI anunciou o recurso de conectores personalizados para o ChatGPT nos planos Pro/Business/Empresarial e Edu. Além dos conectores prontos para uso para acessar dados no Gmail, GitHub, Dropbox etc. É possível criar conectores personalizados usando servidores MCP.
Os conectores personalizados permitem que você combine seus conectores ChatGPT existentes com fontes adicionais de dados, como o Elasticsearch, para obter respostas abrangentes.
Neste artigo, criaremos um servidor MCP que conecta o ChatGPT a um índice Elasticsearch contendo informações sobre problemas internos e solicitações de pull do GitHub. Isso permite que consultas em linguagem natural sejam respondidas usando os dados do seu Elasticsearch.
Implantaremos o servidor MCP usando o FastMCP no Google Colab com ngrok para obter um URL público ao qual o ChatGPT possa se conectar, eliminando a necessidade de uma configuração de infraestrutura complexa.
Para uma visão geral do MCP e seu ecossistema, consulte O Estado Atual do MCP.
Pré-requisitos
Antes de começar, você precisará de:
- Cluster do Elasticsearch (8.X ou superior)
- Chave de API do Elasticsearch com acesso de leitura ao seu índice
- Conta do Google (para o Google Colab)
- Conta Ngrok (versão gratuita funciona)
- Conta do ChatGPT com plano Pro/Empresarial/Business ou Edu
Entendendo os requisitos do conector MCP do ChatGPT
Os conectores MCP do ChatGPT exigem a implementação de duas ferramentas: search e fetch. Para mais detalhes, consulte OpenAI Docs.
Ferramenta de busca
Retorna uma lista de resultados relevantes do seu índice Elasticsearch com base em uma consulta do usuário.
O que ele recebe:
- Uma única string com a consulta de linguagem natural do usuário.
- Exemplo: "Encontre problemas relacionados à migração do Elasticsearch."
O que ele retorna:
- Um objeto com uma chave
resultcontendo um array de objetos de resultado. Cada resultado inclui:id- Identificador único do documentotitle- Título da issue ou do PRurl- Link para o problema/PR
Na nossa implementação:
Ferramenta de recuperação
Recupera o conteúdo completo de um documento específico.
O que ele recebe:
- Uma única string com o ID do documento Elasticsearch do resultado de busca
- Exemplo: "Me dê os detalhes do PR-578."
O que ele retorna:
- Um objeto de documento completo com:
id- Identificador único do documentotitle- Título da issue ou do PRtext- Complete a descrição e os detalhes do problema/PRurl- Link para o problema/PRtype- Tipo de documento (issue, pull_request)status- Status atual (aberto, em_andamento, resolvido)priority- Nível de prioridade (baixo, médio, alto, crítico)assignee- Pessoa designada para o problema/PRcreated_date- Quando foi criadoresolved_date- Quando foi resolvido (se aplicável)labels- Tags associadas ao documentorelated_pr- ID de pull request relacionado
Observação: este exemplo usa uma estrutura plana onde todos os campos estão no nível raiz. Os requisitos do OpenAI são flexíveis e também permitem objetos de metadados aninhados.
Questões do GitHub e conjunto de dados PRs
Para este tutorial, vamos usar um conjunto de dados interno do GitHub contendo problemas e solicitações de pull. Isso representa um cenário em que você deseja consultar dados privados e internos por meio do ChatGPT.
O conjunto de dados pode ser encontrado aqui. E atualizaremos o índice dos dados usando a bulk API.
Esse conjunto de dados inclui:
- Problemas com descrições, status, prioridade e responsáveis
- Solicitações de pull com alterações de código, revisões e informações de implantação
- Relações entre problemas e PRs (por exemplo, PR-578 corrige o ISSUE-1889)
- Rótulos, datas e outros metadados
Mapeamentos de índice
O índice usa os seguintes mapeamentos para permitir a pesquisa híbrida com o ELSER. A text_semantic é usada para busca semântica, enquanto outros campos permitem a busca por palavras-chave.
Construa o servidor MCP
Nosso servidor MCP implementa duas ferramentas seguindo as especificações da OpenAI, usando busca híbrida para combinar correspondência semântica e de texto para obter melhores resultados.
Ferramenta de busca
Utiliza busca híbrida com RRF (Reciprocal Rank Fusion), combinando buscar semântica com correspondência de texto:
Pontos principais:
- Busca híbrida com RRF: combina busca semântica (ELSER) e busca por texto (BM25) para melhores resultados.
- Consulta multi-correspondência: busca em múltiplos campos com aumento de relevância (title^3, text^2, assignee^2). O símbolo de caret (^) multiplica as pontuações de relevância, priorizando as correspondências nos títulos em detrimento do conteúdo.
- Correspondência inexata:
fuzziness: AUTOlida com erros de digitação e ortografia, permitindo correspondências aproximadas. - Ajuste dos parâmetros do RRF:
rank_window_size: 50- Especifica quantos resultados principais de cada recuperador (semântico e textual) são considerados antes da mesclagem.rank_constant: 60- Esse valor determina quanta influência os documentos em conjuntos de resultados individuais têm sobre o resultado final classificado.
- Retorna somente os campos obrigatórios:
id,title,urlde acordo com a especificação da OpenAI e evita a exposição desnecessária de campos adicionais.
Ferramenta de recuperação
Recupera detalhes do documento pelo ID do documento, quando existe:
Pontos principais:
- Buscar por campo de ID do documento: Utiliza consulta de termo no campo personalizado
id - Retorna o documento completo: inclui o campo
textcompleto com todo o conteúdo - Estrutura plana: Todos os campos no nível da raiz, correspondendo à estrutura de documentos do Elasticsearch.
Implantar no Google Colab
Usaremos o Google Colab para executar nosso servidor MCP e o ngrok para expô-lo publicamente, permitindo que o ChatGPT se conecte a ele.
Etapa 1: Abra o notebook do Google Colab
Acesse nosso notebook pré-configurado Elasticsearch MCP para ChatGPT.
Etapa 2: Configure suas credenciais
Você precisará de três informações:
- URL do Elasticsearch: seu URL do cluster do Elasticsearch.
- Chave da API do Elasticsearch: Chave da API com permissão de leitura do seu índice.
- Token de autenticação Ngrok: token grátis do ngrok. Vamos usar o ngrok para expor a URL do MCP à internet para que o ChatGPT possa se conectar a ela.
Obter seu token ngrok
- Cadastre-se para uma conta gratuita em ngrok
- Acesse seu painel do ngrok
- Copie seu token de autenticação.
Adicionando segredos ao Google Colab
No notebook do Google Colab:
- Clique no ícone de chave na barra lateral esquerda para abrir Secrets.
- Adicione estes três segredos:
3. Habilitar o acesso ao notebook para cada segredo

Passo 3: Execute o notebook
- Clique em Runtime e depois em Executar tudo para executar todas as células
- Aguarde o servidor iniciar (cerca de 30 segundos)
- Procure a saída mostrando seu URL público do ngrok

4. A saída exibirá algo como:

Conectar-se ao ChatGPT
Agora vamos conectar o servidor MCP à sua conta do ChatGPT.
- Abra o ChatGPT e vá para Configurações.
- Navegue até Conectores. Se você estiver usando uma conta Pro, precisará ativar o modo de desenvolvedor nos conectores.
Se você está usando o ChatGPT em empresas ou negócios, precisa disponibilizar o conector para seu local de trabalho.
3. Clique em Criar.

Observação: nos espaços de trabalho Business, Empresarial e Edu, somente os proprietários, administradores e usuários com a respectiva configuração ativada (para Empresarial/Edu) podem adicionar conectores personalizados. Usuários com a função de membro padrão não têm permissão para adicionar conectores personalizados.
Após um conector ser adicionado e habilitado por um proprietário ou usuário administrador, ele fica disponível para todos os membros do espaço de trabalho.
4. Insira as informações necessárias e sua URL ngrok que termina em /sse/. Repare no "/" após "sse". Não vai funcionar sem ele:
- Nome: Elasticsearch MCP
- Descrição: MCP personalizado para pesquisar e recuperar informações internas do GitHub.

5. Pressione Criar para salvar o MCP personalizado.

A conexão será instantânea se seu servidor estiver em execução. Não é necessária autenticação adicional, pois a chave da API do Elasticsearch está configurada no seu servidor.
Teste o servidor MCP
Antes de fazer perguntas, você precisa selecionar qual conector o ChatGPT deve usar.

Prompt 1: Buscar por problemas
Pergunte: "Encontre problemas relacionados à migração do Elasticsearch" e confirme a chamada da ferramenta de ações.
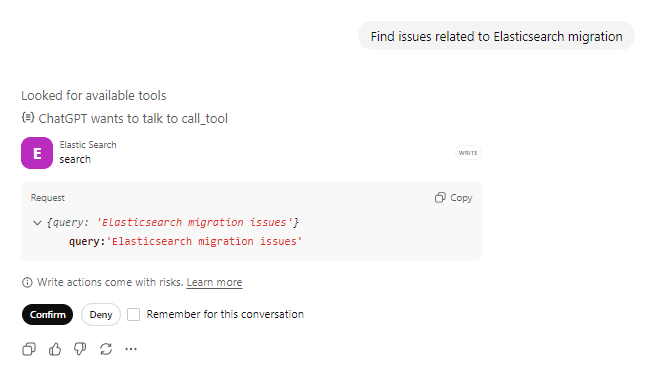
O ChatGPT chamará a ferramenta search com sua consulta. Você pode ver que ele está procurando as ferramentas disponíveis, se preparando para chamar a ferramenta Elasticsearch e confirma com o usuário antes de tomar qualquer medida em relação à ferramenta.
Solicitação de chamada de ferramenta:
Resposta da ferramenta:
O ChatGPT processa os resultados e os apresenta em um formato natural e conversacional.

Nos bastidores
Prompt: "Encontrar problemas relacionados à migração do Elasticsearch"
1. Chamadas do ChatGPT search(“Elasticsearch migration”)
2. O Elasticsearch realiza uma busca híbrida
- A busca semântica compreende conceitos como "atualização" e "compatibilidade de versões".
- A busca de texto encontra correspondências exatas para "Elasticsearch" e "migração".
- O RRF combina e classifica os resultados de ambas as abordagens
3. Retorna os 10 melhores eventos de correspondência com id, title, url
4. O ChatGPT identifica "ISSUE-1712: migrar do Elasticsearch 7.x para o 8.x" como o resultado mais relevante
Prompt 2: Obter todos os detalhes
Perguntar: "Informe detalhes sobre o ISSUE-1889"

O ChatGPT reconhece que você quer informações detalhadas sobre um problema específico e aciona a ferramenta fetch, confirmando com o usuário antes de tomar qualquer medida em relação à ferramenta.
Solicitação de chamada de ferramenta:
Resposta da ferramenta:
O ChatGPT sintetiza as informações e as apresenta claramente.


Nos bastidores
Prompt: “Informe mais detalhes sobre ISSUE-1889”
- Chamadas do ChatGPT
fetch(“ISSUE-1889”) - O Elasticsearch recupera o documento completo
- Retorna um documento completo com todos os campos no nível raiz
- O ChatGPT sintetiza as informações e responde com citações adequadas.
Conclusão
Neste artigo, criamos um servidor MCP personalizado que conecta o ChatGPT ao Elasticsearch usando ferramentas MCP dedicadas de busca e recuperação, permitindo consultas em linguagem natural sobre dados privados.
Este padrão MCP funciona para qualquer índice Elasticsearch, documentação, produtos, log ou quaisquer outros dados que você queira consultar por meio de linguagem natural.
Conteúdo relacionado

4 de maio de 2026
Como medir e melhorar o recall das buscas no Elasticsearch: de 0,43 a 0,75 com a busca híbrida
Aprenda a medir e melhorar o recall das buscas no Elasticsearch combinando a busca léxica BM25 com embeddings vetoriais do Jina AI, usando a API rank_eval para validar a melhoria com números reais.

8 de abril de 2026
Como criar aplicações de IA agentiva com Mastra e Elasticsearch
Aprenda como construir aplicações de IA agentiva usando Mastra e Elasticsearch com um exemplo prático.

25 de março de 2026
A ferramenta shell não é uma solução milagrosa para engenharia de contexto
Saiba quais ferramentas de recuperação de contexto existem para a engenharia de contexto, como elas funcionam e as vantagens e desvantagens.

23 de março de 2026
Usando a API de Inferência Elasticsearch junto com modelos de Hugging Face
Aprenda a conectar o Elasticsearch a modelos do Hugging Face usando endpoints de inferência e a construir um sistema multilíngue de recomendação de blogs com busca semântica e conclusões de chat.

27 de março de 2026
Criando um servidor MCP do Elasticsearch com TypeScript
Saiba como criar servidor MCP do Elasticsearch com TypeScript e Claude Desktop.