Introdução
Em um mundo de usuários globais, a recuperação de informações multilíngue (CLIR) é crucial. Em vez de limitar as buscas a um único idioma, o CLIR permite encontrar informações em qualquer idioma, aprimorando a experiência do usuário e simplificando as operações. Imagine um mercado global onde os clientes de comércio eletrônico possam pesquisar itens em seu idioma e os resultados corretos apareçam, sem a necessidade de localizar os dados antecipadamente. Ou seja, onde pesquisadores acadêmicos podem buscar artigos em seu idioma nativo, com nuances e complexidade, mesmo que a fonte esteja em outro idioma.
Os modelos de incorporação de texto multilíngue nos permitem fazer exatamente isso. Os embeddings são uma forma de representar o significado do texto como vetores numéricos. Esses vetores são projetados de forma que textos com significados semelhantes fiquem localizados próximos uns dos outros em um espaço de alta dimensão. Os modelos de incorporação de texto multilíngue são projetados especificamente para mapear palavras e frases com o mesmo significado em diferentes idiomas para um espaço vetorial semelhante.
Modelos como o Multilingual E5, de código aberto, são treinados com grandes quantidades de dados textuais, frequentemente utilizando técnicas como o aprendizado contrastivo. Nessa abordagem, o modelo aprende a distinguir entre pares de textos com significados semelhantes (pares positivos) e aqueles com significados diferentes (pares negativos). O modelo é treinado para ajustar os vetores que produz de forma a maximizar a similaridade entre pares positivos e minimizar a similaridade entre pares negativos. Para modelos multilíngues, esses dados de treinamento incluem pares de textos em diferentes idiomas que são traduções uns dos outros, permitindo que o modelo aprenda um espaço de representação compartilhado para vários idiomas. Os embeddings resultantes podem então ser usados para diversas tarefas de PNL (Processamento de Linguagem Natural), incluindo buscas multilíngues, onde a similaridade entre os embeddings de texto é usada para encontrar documentos relevantes independentemente do idioma da consulta.
Benefícios da busca vetorial multilíngue
- Nuance: A busca vetorial se destaca na captura do significado semântico, indo além da correspondência por palavras-chave. Isso é crucial para tarefas que exigem a compreensão do contexto e das sutilezas da linguagem.
- Compreensão Interlinguística: Permite a recuperação eficaz de informações em diferentes idiomas, mesmo quando a consulta e os documentos utilizam vocabulário diferente.
- Relevância: Oferece resultados mais relevantes ao focar na similaridade conceitual entre consultas e documentos.
Por exemplo, considere um pesquisador acadêmico que estuda o "impacto das mídias sociais no discurso político" em diferentes países. Com a pesquisa vetorial, eles podem inserir consultas como "l'impatto dei social media sul discorso politico" (italiano) ou "ảnh hưởng của mạng xã hội đối với diễn ngôn chính trị" (vietnamita) e encontrar artigos relevantes em inglês, espanhol ou qualquer outro idioma indexado. Isso ocorre porque a busca vetorial identifica artigos que discutem o conceito da influência das mídias sociais na política, e não apenas aqueles que contêm as palavras-chave exatas. Isso amplia consideravelmente o alcance e a profundidade de suas pesquisas.
Introdução
Veja como configurar o CLIR usando o Elasticsearch - com o modelo E5 que já vem instalado por padrão. Usaremos o conjunto de dados multilíngue de código aberto COCO, que contém legendas de imagens em vários idiomas, para nos ajudar a visualizar 2 tipos de pesquisas:
- Consultas e termos de pesquisa em outros idiomas em um conjunto de dados em inglês, e
- Consultas em vários idiomas sobre um conjunto de dados que contém documentos em vários idiomas.
Em seguida, aproveitaremos o poder da busca híbrida e do reclassificação para melhorar ainda mais os resultados da pesquisa.
Pré-requisitos
- Python 3.6+
- Elasticsearch 8+
- Cliente Python do Elasticsearch: pip install elasticsearch
Conjunto de dados
O conjunto de dados COCO é um conjunto de dados de legendagem em larga escala. Cada imagem no conjunto de dados possui legenda em vários idiomas diferentes, com diversas traduções disponíveis para cada idioma. Para fins de demonstração, indexaremos cada tradução como um documento individual, juntamente com a primeira tradução em inglês disponível para referência.
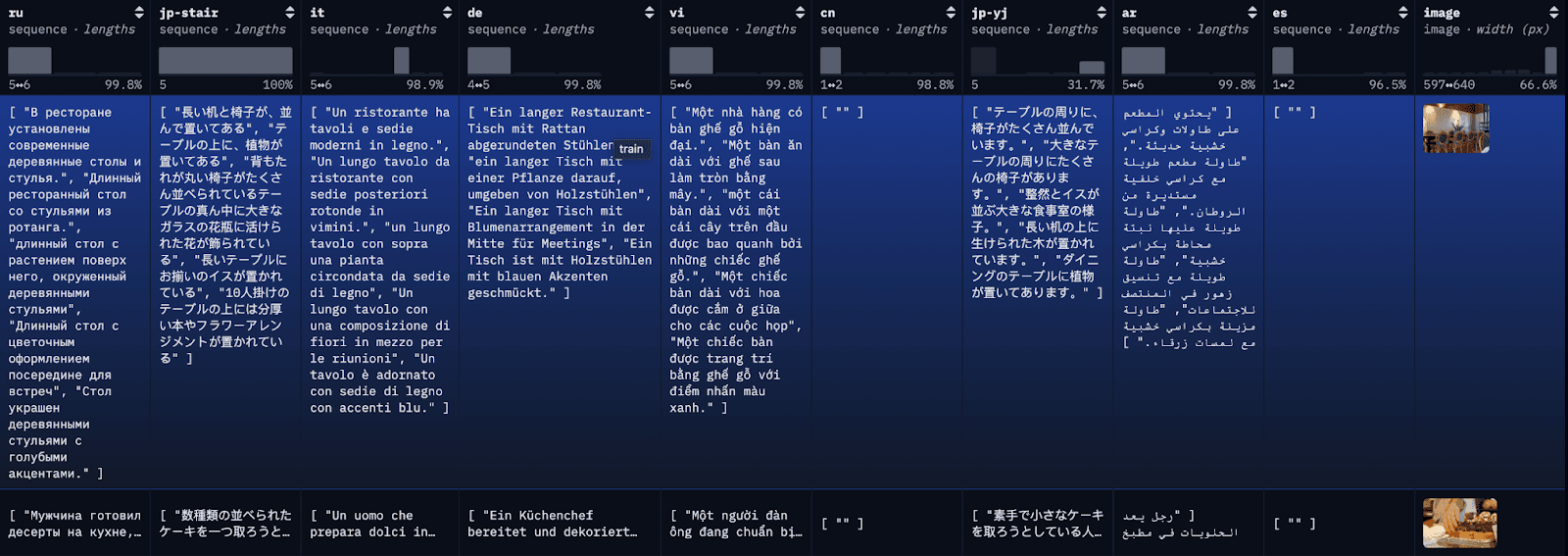
Passo 1: faça o download do conjunto de dados COCO multilíngue.
Para simplificar o blog e facilitar o acompanhamento, estamos carregando as primeiras 100 linhas do restval em um arquivo JSON local com uma simples chamada de API. Alternativamente, você pode usar os conjuntos de dados da biblioteca do HuggingFace para carregar o conjunto de dados completo ou subconjuntos dele.
Se os dados forem carregados com sucesso em um arquivo JSON, você deverá ver algo semelhante a isto:
Data successfully downloaded and saved to multilingual_coco_sample.json
Etapa 2: (Inicie o Elasticsearch) e indexe os dados no Elasticsearch.
a) Inicie o servidor Elasticsearch local.
b) Inicie o cliente Elasticsearch.
c) Dados de índice
Após a indexação dos dados, você deverá ver algo semelhante a isto:
Successfully bulk indexed 4840 documents
Indexing complete!
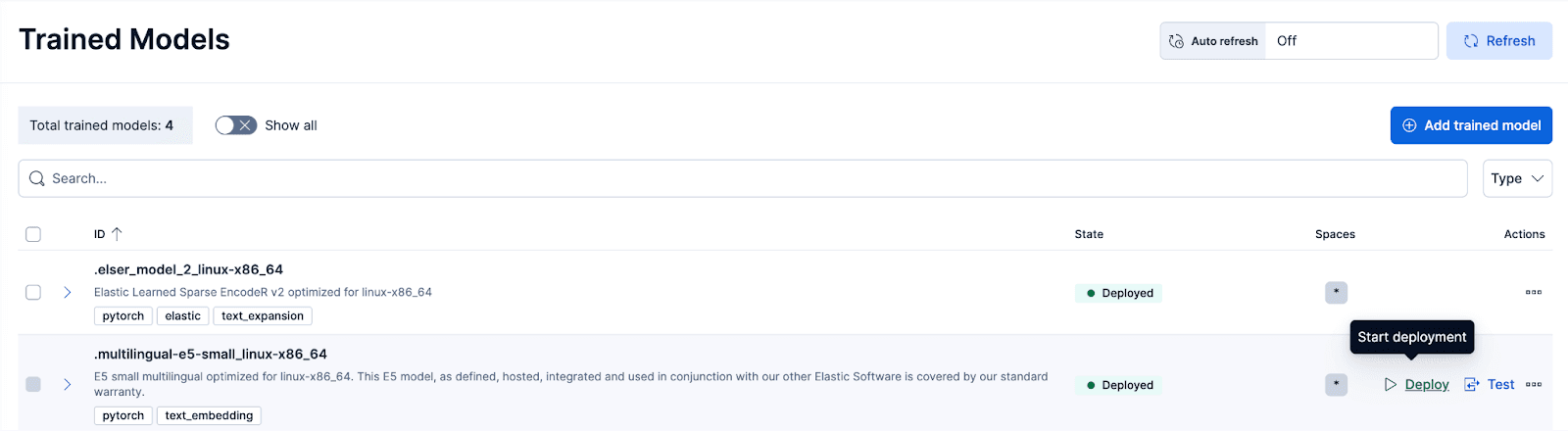
Etapa 3: Implantar o modelo treinado E5
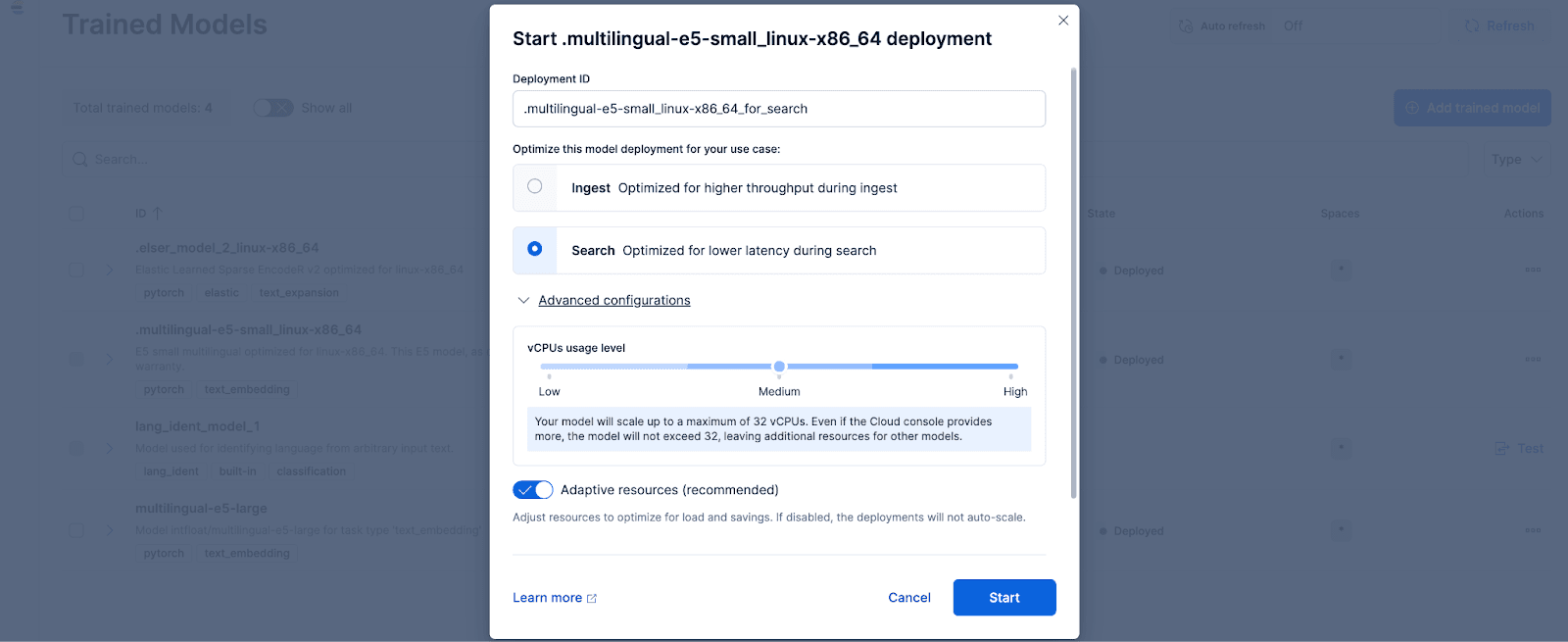
No Kibana, navegue até a página Gerenciamento de Pilha > Modelos Treinados e clique em Implantar para o modelo .multilingual-e5-small_linux-x86_64. opção. Este modelo E5 é um sistema operacional multilíngue compacto, otimizado para Linux x86_64, que podemos usar imediatamente. Ao clicar em "Implantar", será exibida uma tela onde você poderá ajustar as configurações de implantação ou as configurações de vCPUs. Para simplificar, vamos usar as opções padrão, com recursos adaptáveis selecionados, que dimensionarão automaticamente nossa implantação dependendo do uso.
Opcionalmente, se desejar, você pode usar outros modelos de incorporação de texto. Por exemplo, para usar o BGE-M3, você pode usar o cliente Python Eland da Elastic para importar o modelo do HuggingFace.
Em seguida, acesse a página Modelos Treinados para implantar o modelo importado com as configurações desejadas.
Etapa 4: Vetorizar ou criar embeddings para os dados originais com o modelo implantado
Para criar os embeddings, primeiro precisamos criar um pipeline de ingestão que nos permita pegar o texto e executá-lo através do modelo de inferência de embeddings de texto. Você pode fazer isso na interface do usuário do Kibana ou através da API do Elasticsearch.
Para fazer isso através da interface do Kibana, após implantar o modelo treinado, clique no botão Testar . Isso lhe dará a possibilidade de testar e visualizar as imagens incorporadas geradas. Crie uma nova visualização de dados para o coco index, defina a visualização de dados para a visualização de dados coco recém-criada e defina o campo para description porque esse é o campo para o qual queremos gerar embeddings.
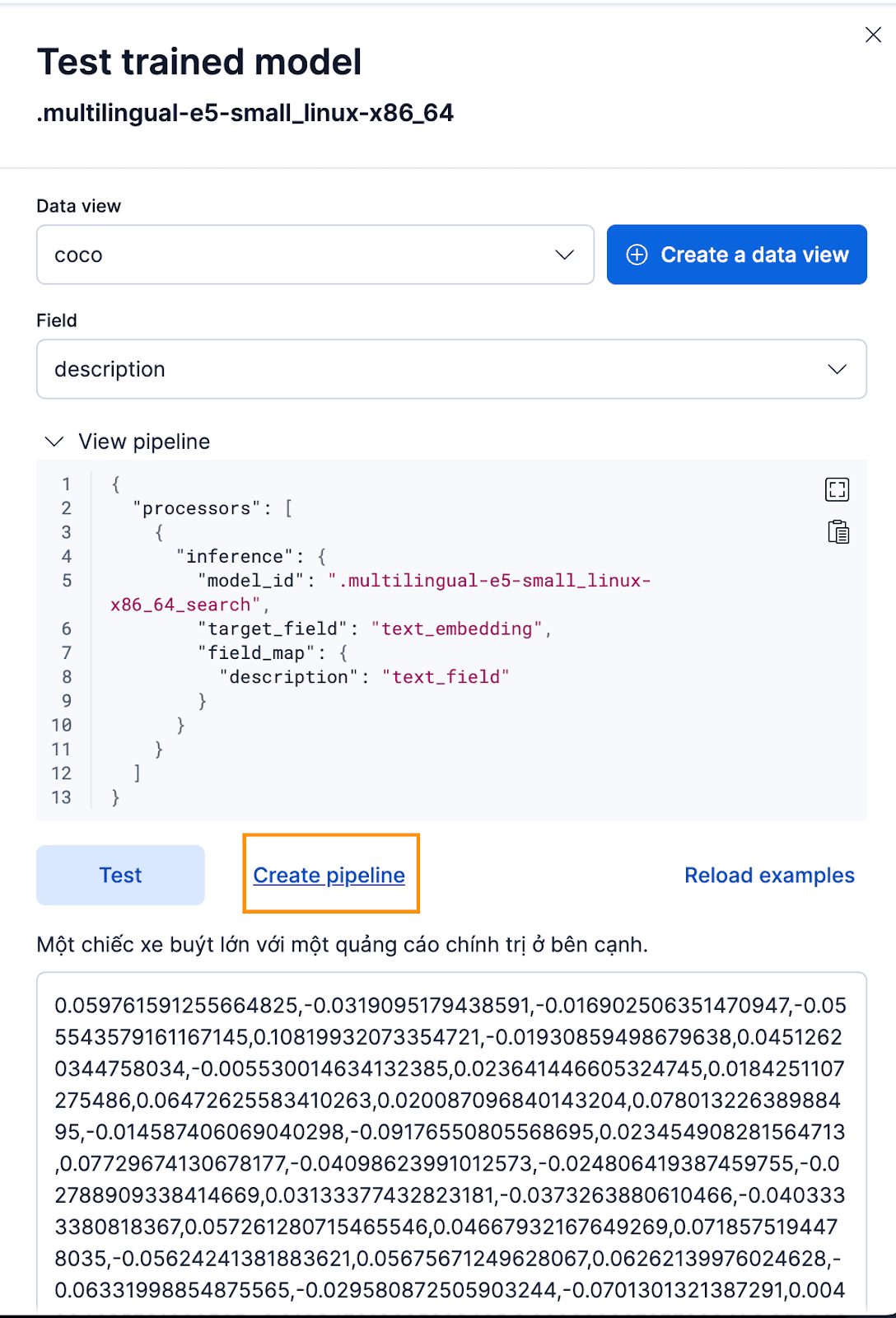
Isso funciona perfeitamente! Agora podemos prosseguir com a criação do pipeline de ingestão e reindexar nossos documentos originais, passá-los pelo pipeline e criar um novo índice com os embeddings. Você pode fazer isso clicando em Criar pipeline, que o guiará pelo processo de criação do pipeline, com processadores preenchidos automaticamente, necessários para ajudá-lo a criar os embeddings.
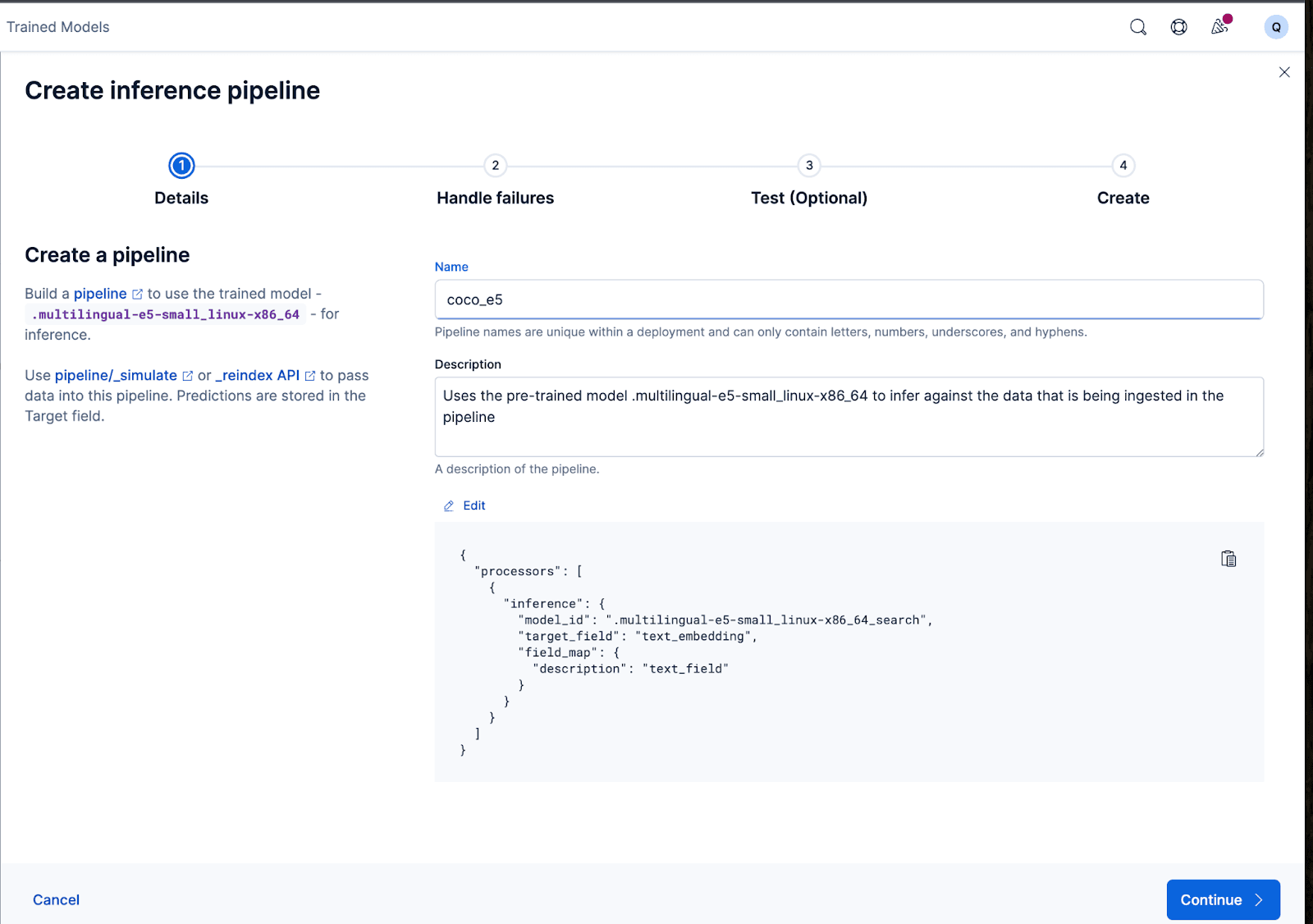
O assistente também pode preencher automaticamente os processadores necessários para lidar com falhas durante a ingestão e o processamento dos dados.
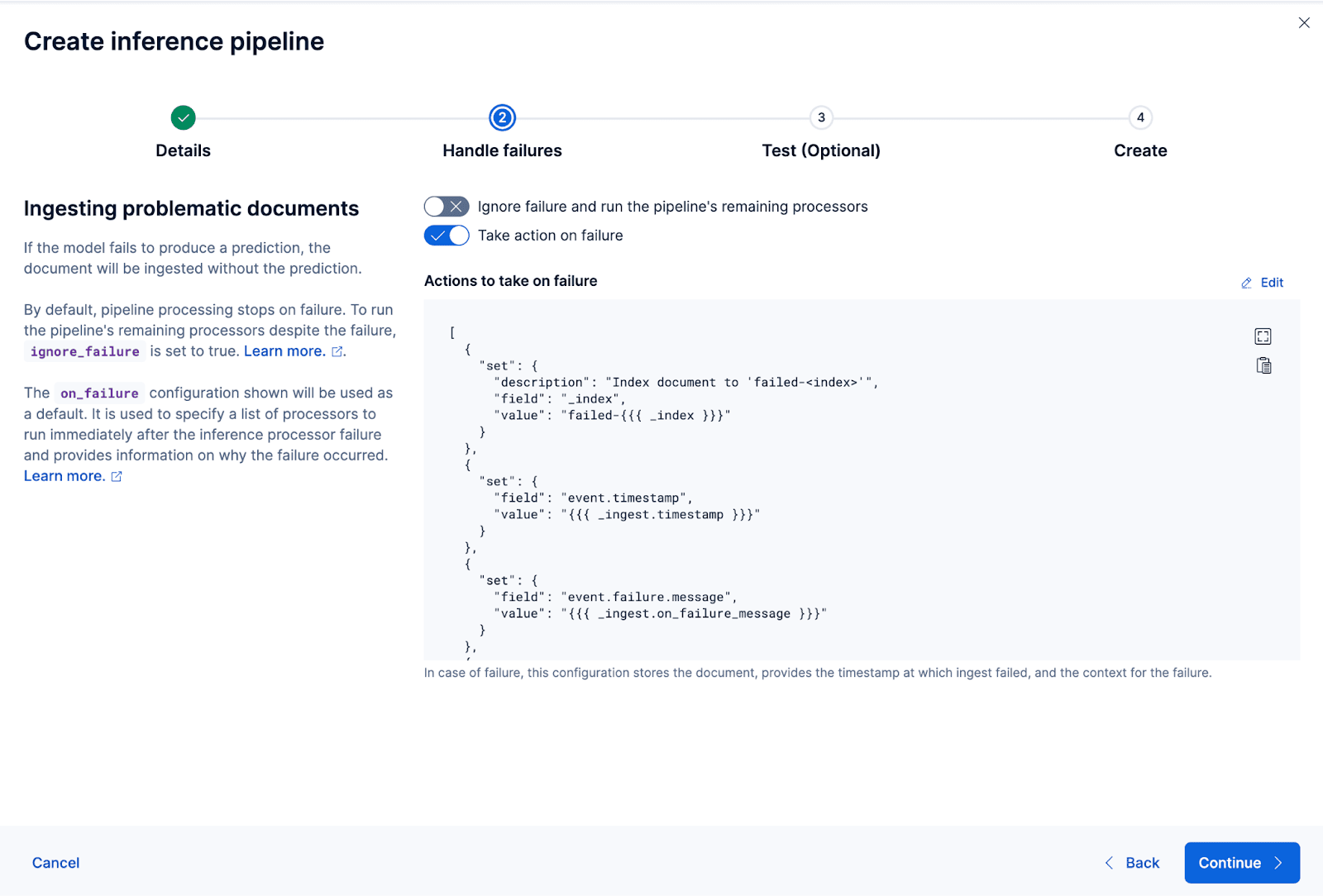
Vamos agora criar o pipeline de ingestão. Estou nomeando o pipeline coco_e5. Após a criação bem-sucedida do pipeline, você pode usá-lo imediatamente para gerar os embeddings, reindexando os dados indexados originais para um novo índice no assistente. Clique em Reindexar para iniciar o processo.
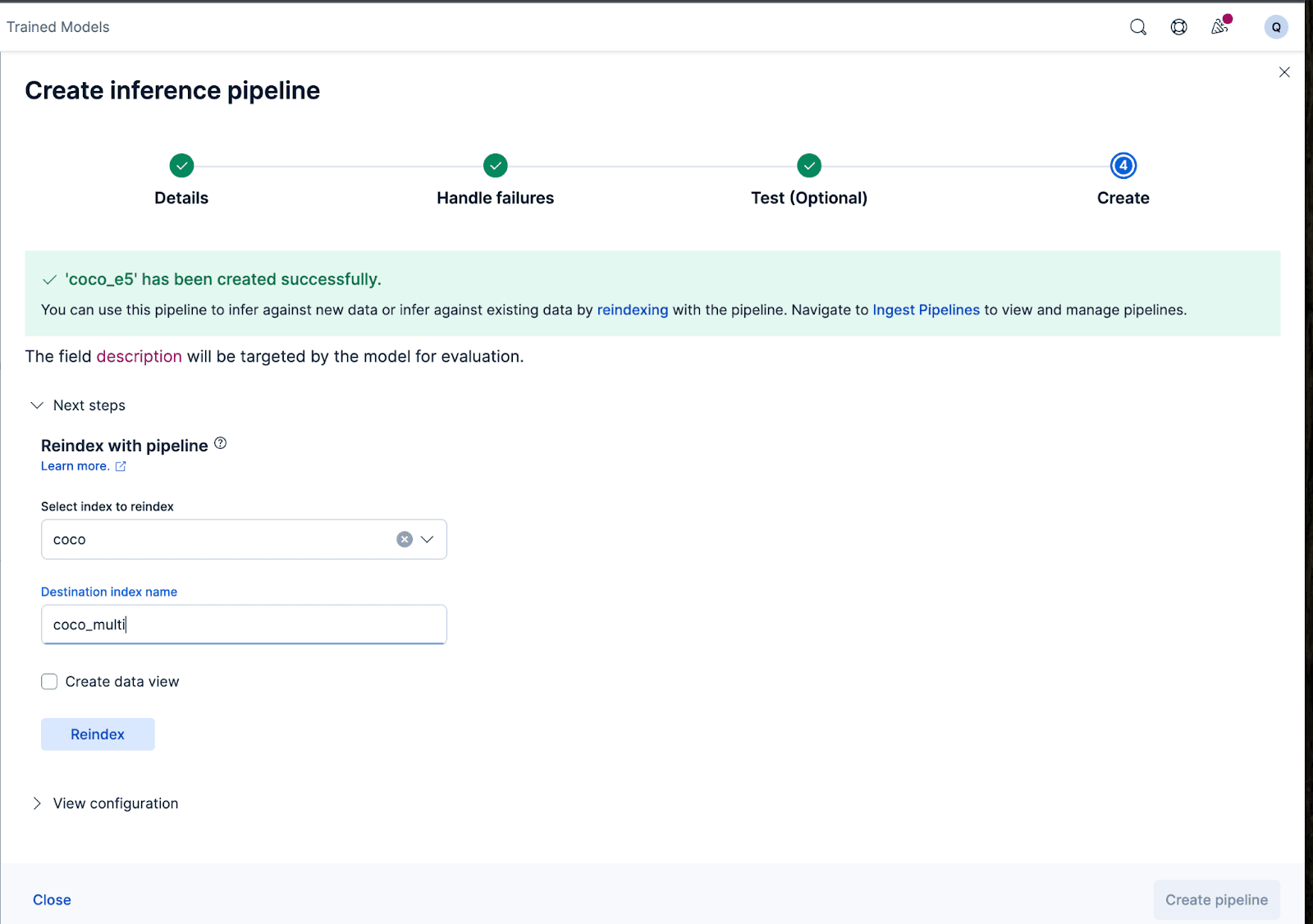
Para configurações mais complexas, podemos usar a API do Elasticsearch.
Para alguns modelos, devido à forma como foram treinados, pode ser necessário adicionar ou acrescentar certos textos à entrada real antes de gerar os embeddings; caso contrário, observaremos uma degradação no desempenho.
Por exemplo, com o e5, o modelo espera que o texto de entrada siga “passagem: {content of passage}”. Vamos utilizar os pipelines de ingestão para realizar isso: Criaremos um novo pipeline de ingestão chamado vectorize_descriptions. Neste pipeline, criaremos um novo campo temporário temp_desc , adicionaremos “passagem: “ ao texto description , executaremos temp_desc através do modelo para gerar embeddings de texto e, em seguida, excluiremos o temp_desc.
Além disso, podemos querer especificar qual tipo de quantização desejamos usar para o vetor gerado. Por padrão, o Elasticsearch usa int8_hnsw, mas aqui eu quero Better Binary Quantization (ou bqq_hnsw), que reduz cada dimensão a uma precisão de um único bit. Isso reduz a necessidade de memória em 96% (ou 32 vezes), ao custo de uma maior perda de precisão. Estou optando por esse tipo de quantização porque sei que usarei um reclassificador posteriormente para melhorar a perda de precisão.
Para isso, criaremos um novo índice chamado coco_multi e especificaremos os mapeamentos. A mágica está no campo vector_description, onde especificamos o tipo de index_optionscomo bbq_hnsw.
Agora, podemos reindexar os documentos originais para um novo índice, com nosso pipeline de ingestão que irá "vetorizar" ou criar embeddings para o campo de descrição.
E é isso! Implementamos com sucesso um modelo multilíngue com Elasticsearch e Kibana e aprendemos passo a passo como criar representações vetoriais (embeddings) com seus dados usando o Elastic, seja pela interface do usuário do Kibana ou pela API do Elasticsearch. Na segunda parte desta série, exploraremos os resultados e as nuances da utilização de um modelo multilíngue. Enquanto isso, você pode criar seu próprio cluster na nuvem para experimentar a busca semântica multilíngue usando nosso modelo E5 pronto para uso no idioma e conjunto de dados de sua escolha.
Conteúdo relacionado

18 de maio de 2026
Busca por IA agêntica com proteções determinísticas no Elasticsearch para execução segura de consultas
Sistemas de busca por IA agêntica falham quando LLMs geram consultas diretamente. Aprenda como as proteções determinísticas e uma arquitetura de plano de controle permitem a execução de consultas seguras, confiáveis e governadas com o Elasticsearch.

11 de maio de 2026
Personalizando a busca de e-commerce: integrando o histórico de compras e de grupos de usuários
Aprenda a criar uma experiência personalizada de busca em e-commerce no Elasticsearch sem comprometer a governança. Este post explica como destacar produtos que um cliente já comprou antes e como ativar políticas específicas de grupo com base nos perfis dos usuários.

4 de maio de 2026
Percolador do Elasticsearch para governança de busca em comércio eletrônico: traduzindo consultas ambíguas em estratégias de recuperação controladas
Aprenda como usar o percolador do Elasticsearch para implementar a governança de busca. Neste blog, delineamos os padrões necessários para criar um motor de políticas governado em produção e criar uma estratégia de recuperação controlada.

1 de maio de 2026
Construindo um plano de controle para gerenciar a busca de comércio eletrônico
Como criar um plano de controle com governança para e-commerce que integra políticas de busca conflitantes em um único plano de execução (sem alterações de código).

24 de abril de 2026
Reindexação de fluxos de dados por causa de conflitos de mapeamento
Aprenda como corrigir conflitos de mapeamento do Elasticsearch reindexando fluxos de dados. Este blog explica o processo de reindexação e como garantir que os novos dados sejam mapeados corretamente.