Com o Elastic Open Web Crawler e sua arquitetura orientada por linha de comando, ter configurações de crawler versionadas e um pipeline de CI/CD com testes locais agora é bastante simples de se obter.
Tradicionalmente, o gerenciamento de rastreadores era um processo manual e propenso a erros. Isso envolvia editar configurações diretamente na interface do usuário e ter dificuldades com a clonagem de configurações de rastreamento, reversão, controle de versão e muito mais. Tratar as configurações do rastreador como código resolve isso, proporcionando os mesmos benefícios que esperamos no desenvolvimento de software: repetibilidade, rastreabilidade e automação.
Esse fluxo de trabalho facilita a integração do Open Web Crawler ao seu pipeline de CI/CD para reversões, backups e migrações — tarefas que eram muito mais complicadas com versões anteriores do Elastic Crawler, como o Elastic Web Crawler ou o App Search Crawler.
Neste artigo, vamos aprender como:
- Gerencie nossas configurações de rastreamento usando o GitHub.
- Ter um ambiente local para testar pipelines antes da implantação.
- Criar um ambiente de produção para executar o rastreador web com novas configurações sempre que enviarmos alterações para nossa branch principal.
Você pode encontrar o repositório do projeto aqui. No momento em que escrevo, estou usando o Elasticsearch 9.1.3 e o Open Web Crawler 0.4.2.
Pré-requisitos
- Docker Desktop
- instância do Elasticsearch
- Máquina virtual com acesso SSH (por exemplo, AWS EC2) e Docker instalado.
Etapas
- Estrutura de pastas
- Configuração do rastreador
- Arquivo Docker-compose (ambiente local)
- Ações do GitHub
- Testando localmente
- Implantação em produção
- Realizar alterações e redistribuir
Estrutura de pastas
Para este projeto, teremos a seguinte estrutura de arquivos:
Configuração do rastreador
Em crawler-config.yml, colocaremos o seguinte:
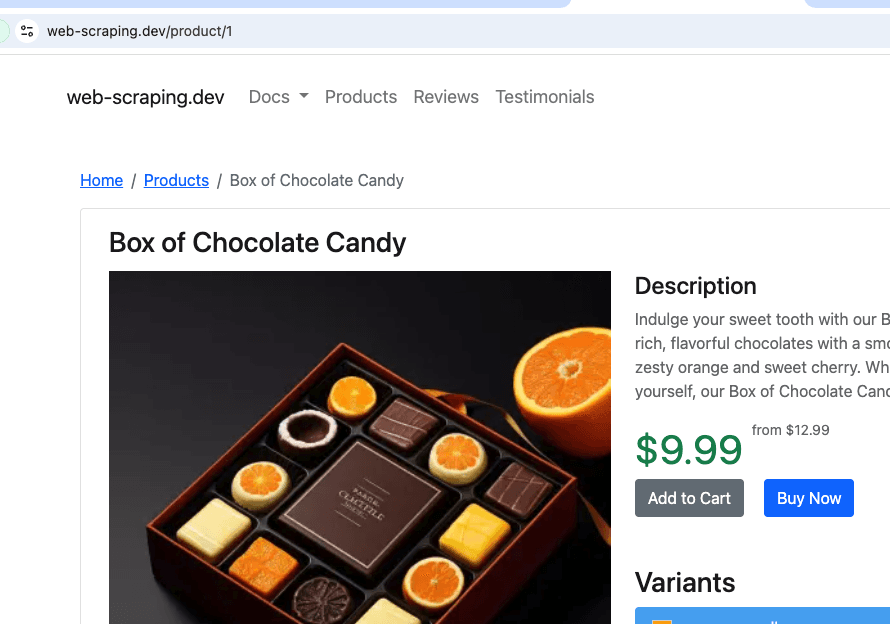
Este script irá extrair dados de https://web-scraping.dev/products, um site fictício para produtos. Iremos rastrear apenas as três primeiras páginas de produtos. A configuração max_crawl_depth impedirá que o rastreador descubra mais páginas do que as definidas como seed_urls , não abrindo os links dentro delas.
Elasticsearch host e api_key serão preenchidos dinamicamente dependendo do ambiente em que estamos executando o script.
Arquivo Docker-compose (ambiente local)
Para o ambiente local docker-compose.yml, implantaremos o rastreador e um único cluster Elasticsearch + Kibana, para que possamos visualizar facilmente os resultados do rastreamento antes da implantação em produção.
Observe como o rastreador aguarda até que o Elasticsearch esteja pronto para ser executado.
Ações do GitHub
Agora precisamos criar uma ação do GitHub que copie as novas configurações e execute o rastreador em nossa máquina virtual a cada push para o repositório principal. Isso garante que sempre tenhamos a configuração mais recente implantada, sem precisar entrar manualmente na máquina virtual para atualizar arquivos e executar o rastreador. Vamos usar o AWS EC2 como provedor de máquinas virtuais.
O primeiro passo é adicionar o host (VM_HOST), o usuário da máquina (VM_USER), a chave SSH RSA (VM_KEY), o host do Elasticsearch (ES_HOST) e a chave da API do Elasticsearch (ES_API_KEY) aos segredos da ação do GitHub:
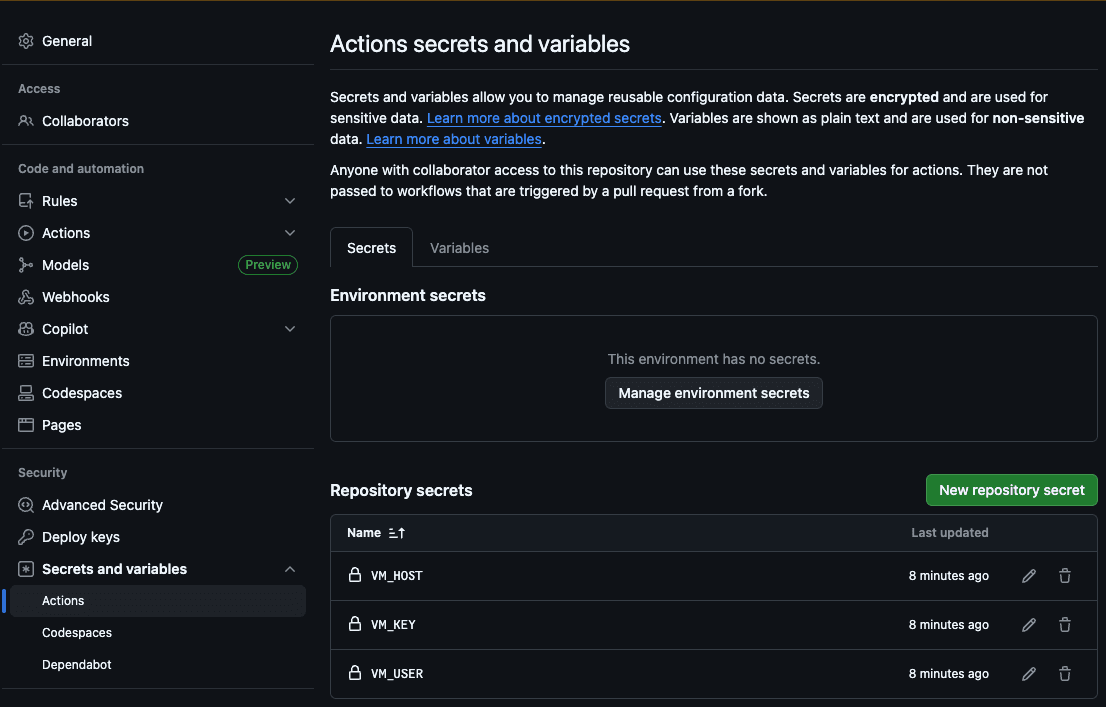
Dessa forma, a ação poderá acessar nosso servidor para copiar os novos arquivos e executar a indexação.
Agora, vamos criar nosso arquivo .github/workflows/deploy.yml :
Essa ação executará os seguintes passos sempre que enviarmos alterações para o arquivo de configuração do rastreador:
- Preencha o arquivo de configuração YAML com o host e a chave da API do Elasticsearch.
- Copie a pasta de configuração para a nossa máquina virtual.
- Conecte-se à nossa VM via SSH.
- Execute o rastreamento com a configuração que acabamos de copiar do repositório.
Testando localmente
Para testar nosso rastreador localmente, criamos um script bash que popula o host do Elasticsearch com a versão local do Docker e inicia uma busca. Você pode executar ./local.sh para executá-lo.
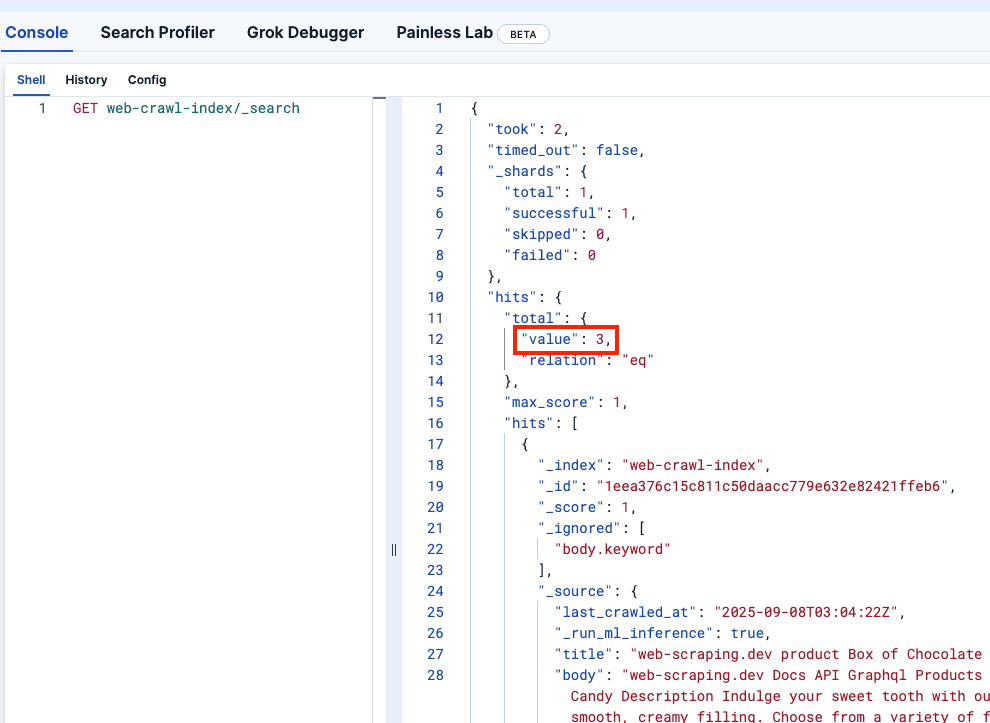
Vamos verificar as Ferramentas de Desenvolvedor do Kibana para confirmar se o campo web-crawler-index foi preenchido corretamente:
Implantação em produção
Agora estamos prontos para enviar a alteração para a branch principal, o que implantará o crawler em sua máquina virtual e começará a enviar logs para sua instância do Elasticsearch Serverless.
Isso acionará a ação do GitHub, que executará o script de implantação na máquina virtual e iniciará a indexação.
Você pode confirmar se a ação foi executada acessando o repositório do GitHub e visitando a aba “Ações”:

Realizar alterações e redistribuir
Algo que você pode ter notado é que o price de cada produto faz parte do corpo do documento. O ideal seria armazenar o preço em um campo separado para que pudéssemos aplicar filtros a ele.
Vamos adicionar essa alteração ao arquivo crawler.yml para usar regras de extração para extrair o preço da classe CSS product-price :
Também vemos que o preço inclui um sinal de dólar ($), que devemos remover se quisermos executar consultas de intervalo. Podemos usar um pipeline de ingestão para isso. Observe que estamos fazendo referência a ele em nosso novo arquivo de configuração do rastreador acima:
Podemos executar esse comando em nosso cluster Elasticsearch de produção. Para o desenvolvimento, como é efêmero, podemos fazer com que a criação do pipeline faça parte do arquivo docker-compose.yml adicionando o seguinte serviço. Observe que também adicionamos um depends_on ao serviço de rastreamento para que ele seja iniciado após a criação bem-sucedida do pipeline.
Agora vamos executar `./local.sh` para ver a alteração localmente:

Ótimo! Agora vamos impulsionar a mudança:
Para confirmar se tudo funciona corretamente, você pode verificar seu Kibana de produção, que deverá refletir as alterações e mostrar o preço como um novo campo sem o símbolo de dólar.
Conclusão
O Elastic Open Web Crawler permite que você gerencie seu crawler como código, o que significa que você pode automatizar todo o pipeline — do desenvolvimento à implantação — e adicionar ambientes locais efêmeros e testes com os dados rastreados programaticamente, para citar alguns exemplos.
Você está convidado a clonar o repositório oficial e começar a indexar seus próprios dados usando este fluxo de trabalho. Você também pode ler este artigo para aprender como executar uma pesquisa semântica em índices produzidos pelo rastreador.
Conteúdo relacionado

18 de maio de 2026
Busca por IA agêntica com proteções determinísticas no Elasticsearch para execução segura de consultas
Sistemas de busca por IA agêntica falham quando LLMs geram consultas diretamente. Aprenda como as proteções determinísticas e uma arquitetura de plano de controle permitem a execução de consultas seguras, confiáveis e governadas com o Elasticsearch.

11 de maio de 2026
Personalizando a busca de e-commerce: integrando o histórico de compras e de grupos de usuários
Aprenda a criar uma experiência personalizada de busca em e-commerce no Elasticsearch sem comprometer a governança. Este post explica como destacar produtos que um cliente já comprou antes e como ativar políticas específicas de grupo com base nos perfis dos usuários.

4 de maio de 2026
Percolador do Elasticsearch para governança de busca em comércio eletrônico: traduzindo consultas ambíguas em estratégias de recuperação controladas
Aprenda como usar o percolador do Elasticsearch para implementar a governança de busca. Neste blog, delineamos os padrões necessários para criar um motor de políticas governado em produção e criar uma estratégia de recuperação controlada.

1 de maio de 2026
Construindo um plano de controle para gerenciar a busca de comércio eletrônico
Como criar um plano de controle com governança para e-commerce que integra políticas de busca conflitantes em um único plano de execução (sem alterações de código).

24 de abril de 2026
Reindexação de fluxos de dados por causa de conflitos de mapeamento
Aprenda como corrigir conflitos de mapeamento do Elasticsearch reindexando fluxos de dados. Este blog explica o processo de reindexação e como garantir que os novos dados sejam mapeados corretamente.