Von der Vektorsuche bis hin zu leistungsstarken REST-APIs bietet Elasticsearch Entwicklern das umfangreichste Toolkit für Suchvorgänge. Entdecken Sie unsere Beispiel-Notebooks im Elasticsearch Labs Repository, um etwas Neues auszuprobieren. Sie können auch heute noch Ihre kostenlose Testphase starten oder Elasticsearch lokal ausführen.
TLDR: Elasticsearch ist bis zu 12 Mal schneller – Wir bei Elastic haben zahlreiche Anfragen aus unserer Community erhalten, um die Leistungsunterschiede zwischen Elasticsearch und OpenSearch zu klären, insbesondere im Realm der semantischen Suche/Vektorsuche. Daher haben wir diesen Leistungstest durchgeführt, um einen klaren, datengesteuerten Vergleich bereitzustellen – keine Mehrdeutigkeiten, nur einfache Fakten zur Information unserer Nutzer. Die Ergebnisse zeigen, dass Elasticsearch bei der Vektorsuche bis zu 12 Mal schneller ist als OpenSearch und daher weniger Rechenressourcen benötigt. Dies spiegelt das Bestreben von Elastic wider, Lucene als beste Vektordatenbank für Such- und Abruffälle zu konsolidieren.
Die Vektorsuche revolutioniert die Art und Weise, wie wir Ähnlichkeitssuchen durchführen, insbesondere in Bereichen wie KI und Machine Learning. Mit der zunehmenden Verbreitung von Vektoreinbettungsmodellen wird die Fähigkeit, Millionen von hochdimensionalen Vektoren effizient zu durchsuchen, immer wichtiger.
Bei der Energieversorgung von Vektordatenbanken haben Elastic und OpenSearch bemerkenswert unterschiedliche Ansätze gewählt. Elastic investierte stark in die Optimierung von Apache Lucene mit Elasticsearch, um sie zur erstklassigen Wahl für Vektorsuchanwendungen zu machen. Im Gegensatz dazu erweiterte OpenSearch seinen Fokus, indem es andere Implementierungen der Vektorsuche integriert und über den Rahmen von Lucene hinausgeht. Unser Fokus auf Lucene ist strategisch und ermöglicht es uns, in unserer Version von Elasticsearch hochintegrierten Support bereitzustellen, was zu einem erweiterten Funktionsumfang führt, bei dem jede Komponente die Fähigkeiten der anderen ergänzt und erweitert.
Dieser Blog bietet einen detaillierten Vergleich zwischen Elasticsearch 8.14 und OpenSearch 2.14, wobei verschiedene Konfigurationen und Vektor-Engines berücksichtigt werden. In dieser Leistungsanalyse hat sich Elasticsearch als die überlegene Plattform für Vektorsuchen erwiesen, und kommende Features werden die Unterschiede noch deutlicher machen. Als es gegen OpenSearch antrat, schnitt es in jedem Benchmark-Track hervorragend ab und bot im Durchschnitt eine 2 bis 12 Mal schnellere Leistung. Dies geschah in Szenarien mit unterschiedlichen Vektormengen und Dimensionen, einschließlich so_vector (2 Mio. Vektoren, 768D), openai_vector (2,5 Mio. Vektoren, 1536D) und dense_vector (10 Mio. Vektoren, 96D), die alle in diesem Repository neben den Terraform-Skripten zum Bereitstellen der gesamten erforderlichen Infrastruktur in Google Cloud und Kubernetes-Manifesten für die Ausführung der Tests verfügbar sind.
Die in diesem Blog beschriebenen Ergebnisse ergänzen die Ergebnisse einer zuvor veröffentlichten und von Dritten validierten Studie, die zeigt, dass Elasticsearch bei den gängigsten Suchanalyseoperationen um 40%–140% schneller ist als OpenSearch: bei Textabfrage, Sortierung, Bereich, Datumshistogramm und Begriffsfilterung. Jetzt können wir ein weiteres Unterscheidungsmerkmal hinzufügen: die Vektorsuche.
Bis zu 12 Mal schneller einsatzbereit
Unsere gezielten Benchmarks über die vier Vektordatensätze hinweg umfassten sowohl approximative kNN- als auch exakte kNN-Suchen, wobei unterschiedliche Größen, Dimensionen und Konfigurationen berücksichtigt wurden, was insgesamt 40.189.820 nicht zwischengespeicherte Suchanfragen ergab. Das Ergebnis: Elasticsearch ist bei der Vektorsuche bis zu 12 Mal schneller als OpenSearch und benötigt daher weniger Rechenressourcen.

Abbildung 1: Gruppierte Aufgaben für ANN und exaktes kNN in verschiedenen Kombinationen in Elasticsearch und OpenSearch.
Die Gruppen wie knn-10-100 bezeichnen eine kNN-Suche mit und . Bei der HNSW-Vektorsuche bestimmt die Anzahl der nächsten Nachbarn, die für einen Abfragevektor abgerufen werden sollen. Es wird angegeben, wie viele ähnliche Vektoren als Ergebnis gefunden werden sollen. legt die Anzahl der Kandidatenvektoren fest, die in jedem Segment abgerufen werden sollen. Mehr Kandidaten können die Genauigkeit erhöhen, erfordern jedoch mehr Rechenressourcen.
Wir haben auch mit verschiedenen Quantisierungstechniken getestet und Engine-spezifische Optimierungen genutzt. Die detaillierten Ergebnisse für jeden Track und jede Aufgabe und Vektor-Engine sind unten verfügbar.
Exaktes kNN und approximatives kNN
Beim Umgang mit unterschiedlichen Daten und Anwendungsfällen variiert der richtige Ansatz für die Vektorsuche. In diesem Blog verwenden alle als knn-* angegebenen Aufgaben wie knn-10-100 approximatives kNN und script-score-* beziehen sich auf exaktes kNN, aber was ist der Unterschied zwischen ihnen und warum ist das wichtig?
Im Wesentlichen ist bei der Verarbeitung umfangreicherer Datensätze die Methode des Approximativen K-Nearest-Neighbor (ANN) aufgrund ihrer überlegenen Skalierbarkeit die bevorzugte Methode. Für bescheidenere Datensätze, die möglicherweise einen Filterprozess erfordern, ist die exakte kNN-Methode ideal.
Exaktes kNN verwendet eine Brute-Force-Methode, die den Abstand zwischen einem Vektor und jedem anderen Vektor im Datensatz berechnet. Anschließend werden diese Abstände in eine Rangfolge gebracht, um die nächsten Nachbarn zu finden. Diese Methode gewährleistet zwar eine exakte Übereinstimmung, leidet aber bei großen, hochdimensionalen Datensätzen unter Problemen der Skalierbarkeit. Es gibt jedoch viele Fälle, in denen exaktes kNN benötigt wird:
- Neubewertung: In Szenarien mit lexikalischen oder semantischen Suchen, gefolgt von einer vektorbasierten Neubewertung, ist exaktes kNN unerlässlich. In einer Produktsuchmaschine können erste Suchergebnisse auf der Grundlage von Textabfragen (z. B. Schlüsselwörtern, Kategorien) gefiltert werden. Anschließend werden Vektoren, die mit den gefilterten Elementen verknüpft sind, für eine genauere Ähnlichkeitsbewertung verwendet.
- Personalisierung: Bei einer großen Anzahl von Nutzern, die jeweils durch eine relativ kleine Anzahl (z. B. 1 Million) unterschiedlicher Vektoren repräsentiert werden, wird die Sortierung des Indexes nach nutzerspezifischen Metadaten (z. B. user_id) und die Brute-Force-Bewertung mit Vektoren effizient. Dieser Ansatz ermöglicht personalisierte Empfehlungen oder die Bereitstellung von Inhalten basierend auf präzisen Vektorvergleichen, die auf die individuellen Nutzerpräferenzen zugeschnitten sind.
Exaktes kNN stellt sicher, dass das endgültige Ranking und die Empfehlungen basierend auf der Vektorähnlichkeit präzise und auf die Nutzerpräferenzen zugeschnitten sind.
Approximatives kNN (oder ANN) verwendet hingegen Methoden, um die Datensuche schneller und effizienter als exaktes kNN zu gestalten, insbesondere in großen, hochdimensionalen Datensätzen. Anstelle eines Brute-Force-Ansatzes, der den genauen kürzesten Abstand zwischen einer Abfrage und allen Punkten misst, was zu Berechnungs- und Skalierungsproblemen führt, verwendet ANN bestimmte Techniken, um die Indizes und Dimensionen durchsuchbarer Vektoren im Datensatz effizient neu zu strukturieren. Dies kann zwar zu einer leichten Ungenauigkeit führen, erhöht jedoch die Geschwindigkeit des Suchvorgangs erheblich und macht ihn zu einer effektiven Alternative für den Umgang mit großen Datensätzen.
In diesem Blog verwenden alle als knn-* bezeichneten Aufgaben wie knn-10-100 approximatives kNN und script-score-* beziehen sich auf exaktes kNN.
Testmethodik
Während Elasticsearch und OpenSearch hinsichtlich der API für BM25-Suchvorgänge ähnlich sind, da letzteres ein Fork von ersterem ist, trifft dies auf die Vektorsuche, die nach dem Fork eingeführt wurde, nicht zu. OpenSearch verfolgte einen anderen Ansatz als Elasticsearch in Bezug auf Algorithmen, indem es neben lucene zwei weitere Engines – nmslib und faiss – einführte, die jeweils über spezifische Konfigurationen und Einschränkungen verfügen (z. B. erlaubt nmslib in OpenSearch keine Filter, ein wesentliches Feature für viele Anwendungsfälle).
Alle drei Engines verwenden den Hierarchical Navigable Small World (HNSW)-Algorithmus, der effizient für die approximative Suche nach dem nächsten Nachbarn und besonders leistungsfähig beim Umgang mit hochdimensionalen Daten ist. Es ist wichtig zu beachten, dass faiss auch einen zweiten Algorithmus, ivf, unterstützt, aber da dafür ein Vortraining am Datensatz erforderlich ist, werden wir uns ausschließlich auf HNSW konzentrieren. Die Kernidee von HNSW besteht darin, die Daten in mehreren Schichten verbundener Graphen zu organisieren, wobei jede Schicht eine andere Granularität des Datensatzes darstellt. Das Suchen beginnt auf der obersten Ebene mit der gröbsten Ansicht und schreitet zu immer feineren Schichten fort, bis es die unterste Ebene erreicht.
Beide Suchmaschinen wurden unter identischen Bedingungen in einer kontrollierten Umgebung getestet, um faire Testbedingungen zu gewährleisten. Die angewandte Methode ähnelt diesem zuvor veröffentlichten Leistungsvergleich, mit dedizierten Node-Pools für Elasticsearch, OpenSearch und Rally. Das Terraform-Skript ist (neben allen Quellen) verfügbar, um einen Kubernetes-Cluster mit Folgendem bereitzustellen:
- 1 Node-Pool für Elasticsearch mit 3
e2-standard-32-Maschinen (128 GB RAM und 32 CPUs) - 1 Node-Pool für OpenSearch mit 3
e2-standard-32-Maschinen (128 GB RAM und 32 CPUs) - 1 Node-Pool für Rally mit 2
t2a-standard-16Maschinen (64 GB RAM und 16 CPUs)
Jeder „Track“ (oder Test) wurde 10 Mal für jede Konfiguration ausgeführt, die unterschiedliche Engines, Konfigurationen und Vektortypen umfasste. Die Tracks haben Aufgaben, die sich je nach Track zwischen 1.000 und 10.000 Mal wiederholen. Wenn eine der Aufgaben in einem Track z. B. aufgrund einer Netzwerk-Zeitüberschreitung fehlschlug, wurden alle Aufgaben verworfen, sodass alle Ergebnisse Tracks darstellen, die ohne Probleme gestartet und beendet wurden. Alle Testergebnisse sind statistisch validiert, um sicherzustellen, dass Verbesserungen nicht zufällig sind.
Detaillierte Ergebnisse
Warum das 99. Perzentil und nicht die durchschnittliche Latenz vergleichen? Betrachten Sie ein hypothetisches Beispiel für die durchschnittlichen Hauspreise in einem bestimmten Viertel. Der Durchschnittspreis mag auf eine teure Gegend hindeuten, aber bei näherer Betrachtung stellt sich womöglich heraus, dass die meisten Häuser viel niedriger bewertet sind und nur einige wenige Luxusimmobilien den Durchschnittswert in die Höhe treiben. Dies verdeutlicht, dass der Durchschnittspreis das gesamte Spektrum der Hauswerte in der Gegend nicht unbedingt genau wiedergibt. Man kann das mit der Untersuchung von Reaktionszeiten vergleichen, bei denen der Durchschnittswert möglicherweise kritische Probleme verbirgt.
Aufgaben
- Approximatives kNN mit k:10, n:50
- Approximatives kNN mit k:10, n:100
- Approximatives kNN mit k:100, n:1000
- Approximatives kNN mit k:10, n:50 und Keyword-Filtern
- Approximatives kNN mit k:10, n:100 und Keyword-Filtern
- Approximatives kNN mit k:100, n:1000 und Keyword-Filtern
- Approximatives kNN mit k:10, n:100 in Verbindung mit Indizierung
- Exaktes kNN (Skriptergebnis)
Vektor-Engines
lucenein Elasticsearch und OpenSearch, beide in Version 9.10faissin OpenSearchnmslibin OpenSearch
Vektortypen
hnswin Elasticsearch und OpenSearchint8_hnswin Elasticsearch (HNSW mit automatischer 8-Bit-Quantisierung: Link)sq_fp16 hnswin OpenSearch (HNSW mit automatischer 16-Bit-Quantisierung: Link)
Vorkonfigurierte und gleichzeitige Segmentsuche
Wie Sie wahrscheinlich wissen, ist Lucene eine hochleistungsfähige Text-Suchmaschinen-Bibliothek, die in Java geschrieben wurde und als Rückgrat für viele Suchplattformen wie Elasticsearch, OpenSearch und Solr dient. Im Kern organisiert Lucene Daten in Segmente, die im Wesentlichen in sich geschlossene Indizes sind, mit denen Lucene Suchvorgänge effizienter ausführen kann. Wenn Sie also eine auf Lucene basierende Suchmaschine mit einer Suche beauftragen, wird Ihre Suche in diesen Segmenten entweder sequentiell oder parallel ausgeführt.
OpenSearch hat die gleichzeitige Segmentsuche als optionales Flag eingeführt und verwendet sie standardmäßig nicht. Sie müssen sie mit einer speziellen Indexeinstellung index.search.concurrent_segment_search.enabled, wie hier beschrieben, aktivieren und es gibt einige Einschränkungen.
Elasticsearch hingegen sucht standardmäßig gleichzeitig in Segmenten, daher berücksichtigen die Vergleiche, die wir in diesem Blog anstellen, neben den verschiedenen Vektor-Engines und Vektortypen auch die unterschiedlichen Konfigurationen:
- Elasticsearch ootb: Elasticsearch sofort einsatzbereit, mit gleichzeitiger Segmentsuche;
- OpenSearch ootb: ohne aktivierte gleichzeitige Segmentsuche;
- OpenSearch css: mit aktivierter gleichzeitiger Segmentsuche
Kommen wir nun zu einigen detaillierten Ergebnissen für jeden getesteten Vektordatensatz:
2,5 Millionen Vektoren, 1536 Dimensionen (openai_vector)
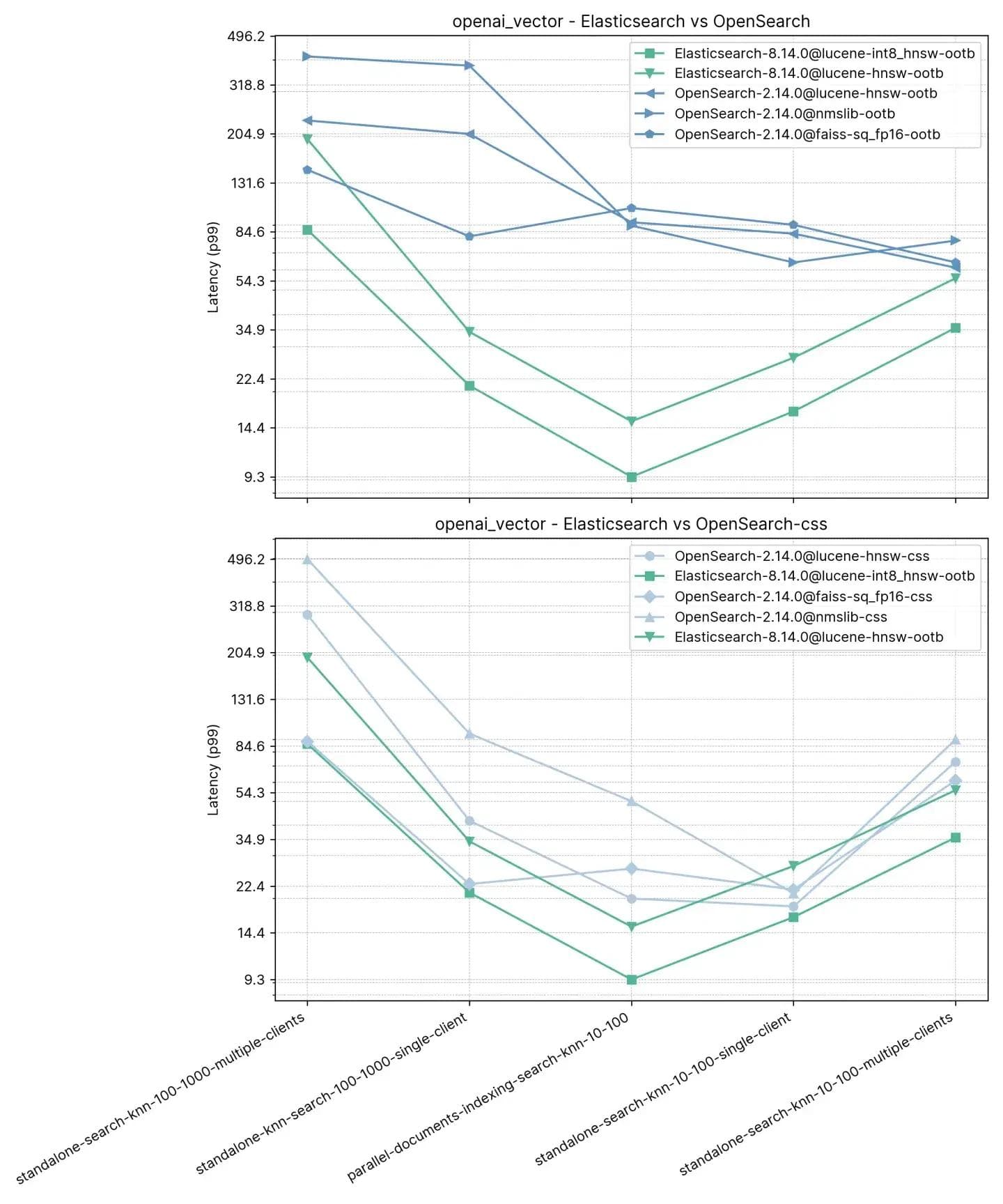
Beginnen wir mit dem einfachsten, aber hinsichtlich der Dimensionen auch größten Track, openai_vector – er verwendet den NQ-Datensatz, der mit Einbettungen angereichert ist, die mit dem Modell „text-embedding-ada-002“ von OpenAI generiert wurden. Dieser Track ist der einfachste, da er nur approximatives kNN testet und nur 5 Aufgaben hat. Er testet sowohl im Standalone-Modus (ohne Indizierung) als auch parallel zur Indizierung und verwendet sowohl einen einzelnen Client als auch 8 gleichzeitige Clients.
Aufgaben
- standalone-search-knn-10-100-multiple-clients: Suche in 2,5 Millionen Vektoren mit 8 Clients gleichzeitig, k:10 und n:100
- standalone-search-knn-100-1000-multiple-clients: Suche in 2,5 Millionen Vektoren mit 8 Clients gleichzeitig, k:100 und n:1000
- standalone-search-knn-10-100-single-client: Suche in 2,5 Millionen Vektoren mit einem einzigen Client, k:10 und n:100
- standalone-search-knn-100-1000-single-client: Suche in 2,5 Millionen Vektoren mit einem einzigen Client, k:100 und n:1000
- parallel-documents-indexing-search-knn-10-100: Suche in 2,5 Millionen Vektoren bei gleichzeitigem Indexieren von weiteren 100.000 Dokumenten, k:10 und n:100
Die durchschnittliche p99-Leistung ist unten aufgeführt:

Hier haben wir beobachtet, dass Elasticsearch zwischen 3 und 8 Mal schneller ist als OpenSearch, wenn es neben dem Indexieren auch eine Vektorsuche (d. h. Lesen und Schreiben) mit :10 und :100 durchführt, und ohne Indizierung für denselben k- und n-Wert 2 bis 3 Mal schneller ist. Bei :100 und :1000 (standalone-search-knn-100-1000-single-client und standalone-search-knn-100-1000-multiple-clients) ist Elasticsearch im Durchschnitt 2 bis 7 Mal schneller als OpenSearch.
Die detaillierten Ergebnisse zeigen die exakten Tickets und Vektor-Engines im Vergleich:
Recall
| knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 0,969485 | 0,995138 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 0,781445 | 0,784817 |
| OpenSearch-2.14.0@lucene-hnsw | 0,96519 | 0,995422 |
| OpenSearch-2.14.0@faiss | 0,984154 | 0,98049 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 0,980012 | 0,97721 |
| OpenSearch-2.14.0@nmslib | 0,982532 | 0,99832 |
10 Millionen Vektoren, 96 Dimensionen (dense_vector)
In dense_vector mit 10 Millionen Vektoren und 96 Dimensionen. Dies basiert auf dem Bilddatensatz DEEP1B von Yandex. Der Datensatz wird aus den ersten 10 Millionen Vektoren der „Beispieldaten“-Datei mit dem Namen learn.350M.fbin erstellt. Die Suchvorgänge verwenden Vektoren aus der Abfrage der Datei „Abfragedaten“public.10K.fbin.
Sowohl Elasticsearch als auch OpenSearch funktionieren bei diesen Daten sehr gut, insbesondere nach einer erzwungenen Zusammenführung, die normalerweise bei schreibgeschützten Indizes durchgeführt wird und der Defragmentierung des Index ähnelt, um eine einzige „Tabelle“ zu haben, in der gesucht werden kann.
Aufgaben
Jede Aufgabe wird mit 100 Anfragen aufgewärmt und dann werden 1000 Anfragen gemessen
- knn-search-10-100: Suche in 10 Millionen Vektoren, k:10 und n:100
- knn-search-100-1000: Suche in 10 Millionen Vektoren, k:100 und n:1000
- knn-search-10-100-force-merge: Suche in 10 Millionen Vektoren nach einer erzwungenen Zusammenführung, k:10 und n:100
- knn-search-100-1000-force-merge: Suche in 10 Millionen Vektoren nach einer erzwungenen Zusammenführung, k:100 und n:1000
- knn-search-100-1000-concurrent-with-indexing: Suche in 10 Millionen Vektoren bei gleichzeitiger Aktualisierung von 5 % des Datensatzes, k:100 und n:1000
- script-score-query: Exakte kNN-Suchen in 2000 spezifischen Vektoren.
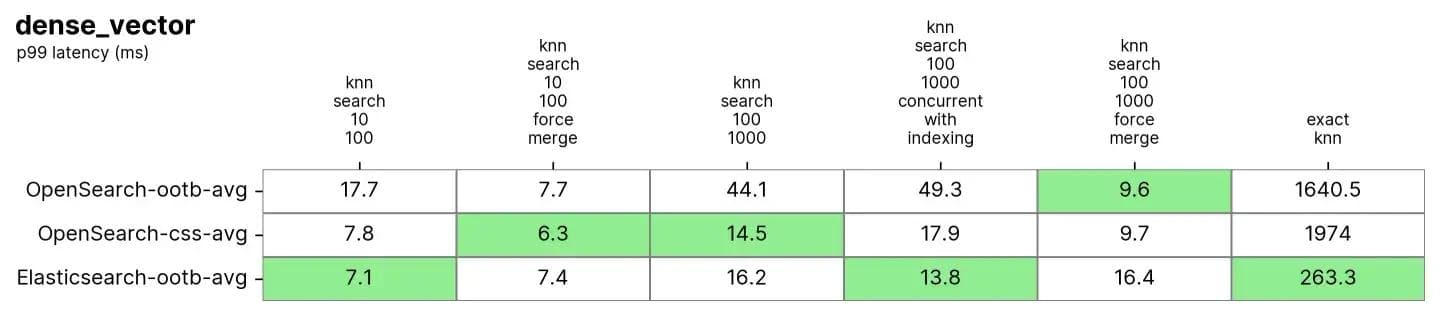
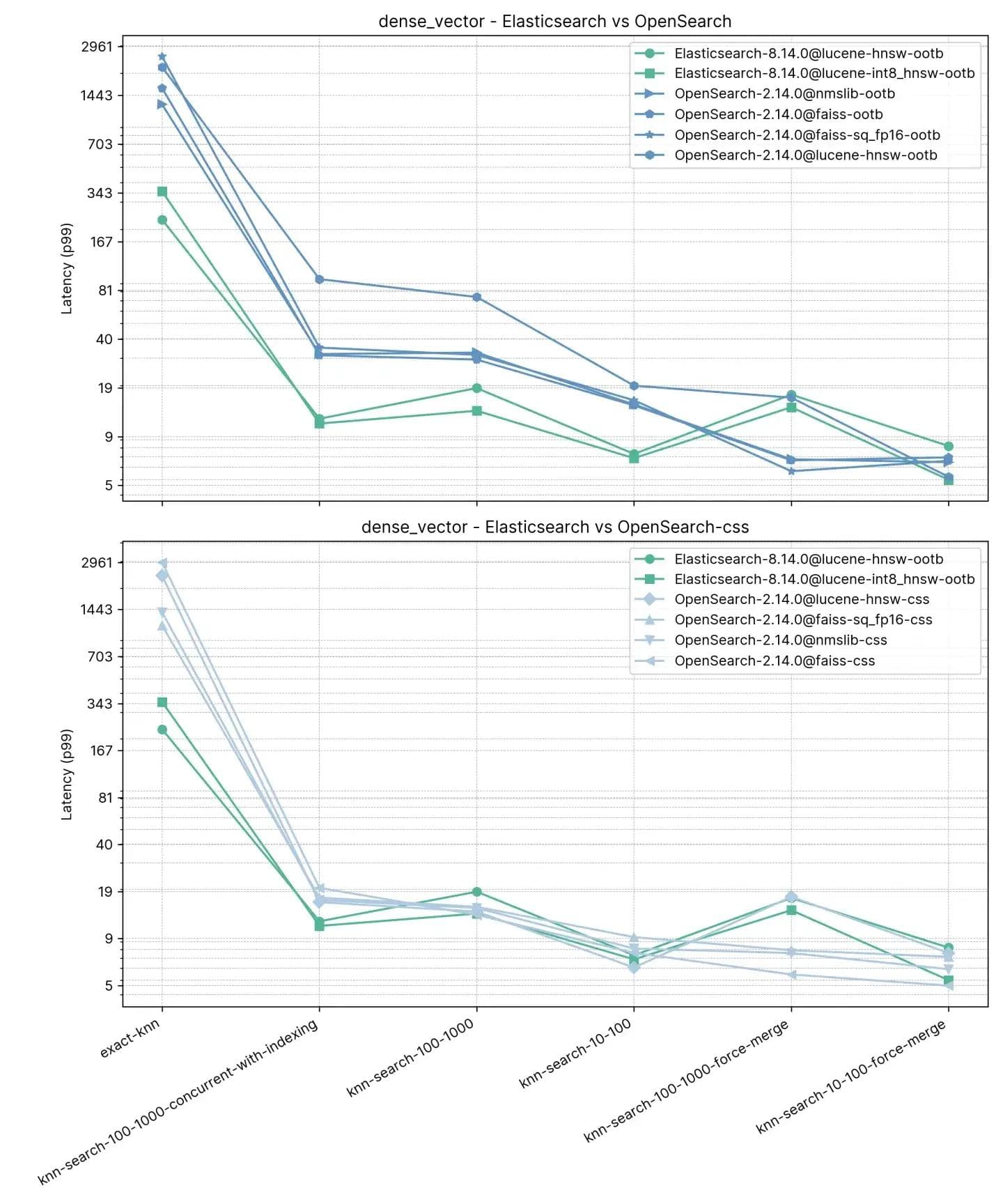
Sowohl Elasticsearch als auch OpenSearch haben sich bei der ANN-Suche gut bewährt. Wenn der Index in knn-search-100-1000-force-merge und knn-search-10-100-force-merge zusammengeführt wird (d. h. nur ein Segment hat), schneidet OpenSearch bei der Verwendung von nmslib und faiss besser ab als die anderen, obwohl sie alle um die 15 ms und dicht beieinander liegen.
Wenn der Index in knn-search-10-100 und knn-search-100-1000 jedoch mehrere Segmente hat (eine typische Situation, in der ein Index Aktualisierungen seiner Dokumente erhält), hält Elasticsearch die Latenz bei etwa ~7 ms und ~16 ms, während alle anderen OpenSearch-Engines langsamer sind.
Auch wenn der Index gleichzeitig gesucht und beschrieben wird (knn-search-100-1000-concurrent-with-indexing), hält Elasticsearch die Latenz unter 15 ms (bei 13,8 ms) und ist damit fast 4 Mal schneller als OpenSearch im Standardmodus (49,3 ms) und auch dann noch schneller, wenn die gleichzeitige Segmentsuche aktiviert ist (17,9 ms). Dies ist aber zu nah, um von Bedeutung zu sein.
Bei exaktem kNN ist der Unterschied viel größer: Elasticsearch ist 6 Mal schneller als OpenSearch (~260 ms gegenüber ~1600 ms).
Recall
| knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 0,969843 | 0,996577 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 0,775458 | 0,840254 |
| OpenSearch-2.14.0@lucene-hnsw | 0,971333 | 0,996747 |
| OpenSearch-2.14.0@faiss | 0,9704 | 0,914755 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 0,968025 | 0,913862 |
| OpenSearch-2.14.0@nmslib | 0,9674 | 0,910303 |
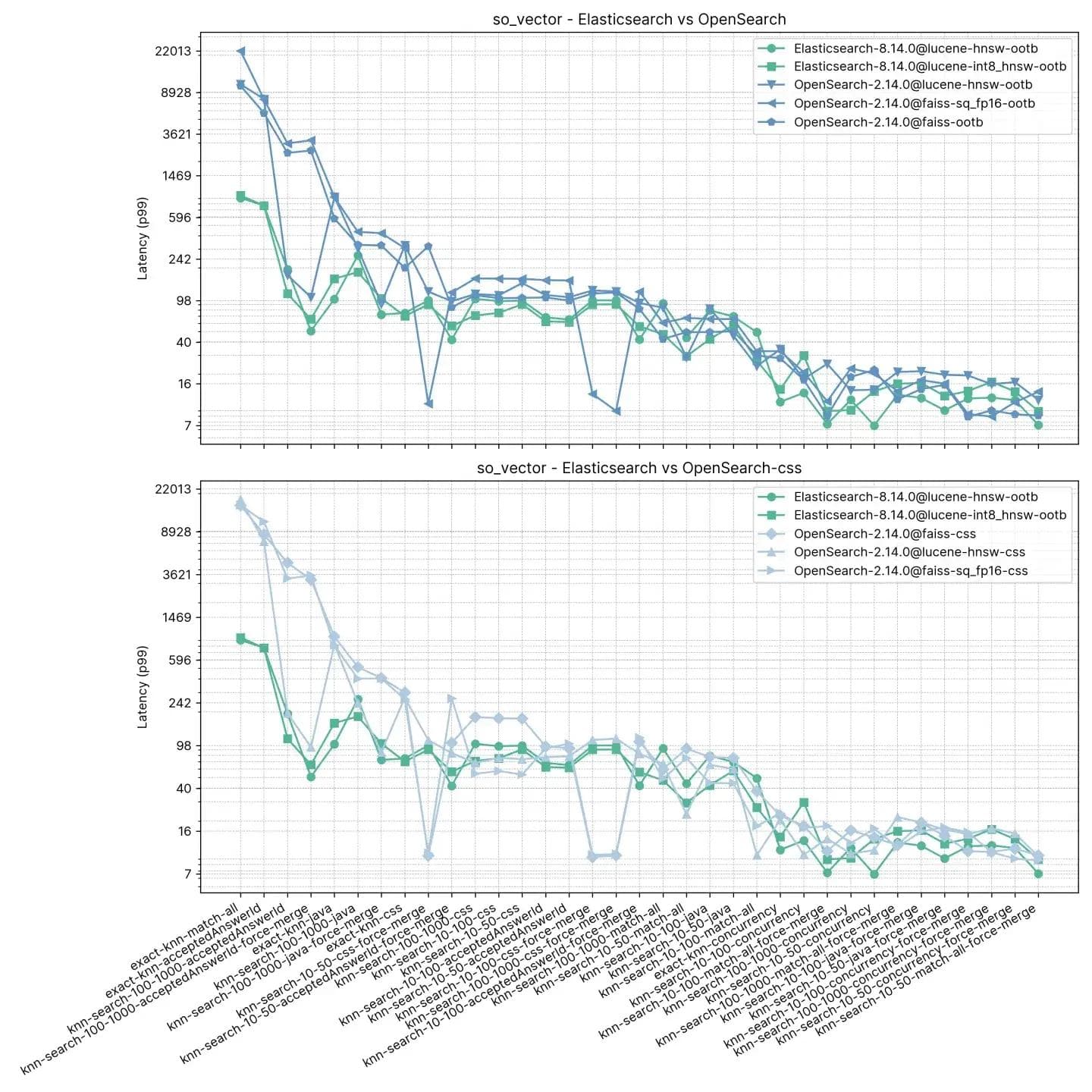
2 Millionen Vektoren, 768 Dimensionen (so_vector)
Dieser Track,so_vector, stammt aus einem Bündel von StackOverflow-Beiträgen, die am 21. April 2022 heruntergeladen wurden. Er enthält nur Fragedokumente – alle Dokumente mit Antworten wurden entfernt. Jeder Fragentitel wurde mithilfe des Satztransformatormodells multi-qa-mpnet-base-cos-v1 in einen Vektor kodiert. Dieser Datensatz enthält die ersten 2 Millionen Fragen.
Im Gegensatz zum vorherigen Track enthält jedes Dokument hier neben Vektoren auch andere Felder, um Test-Features wie approximativer kNN mit Filterung und Hybridsuche zu unterstützen. nmslib für OpenSearch fehlt in diesem Test auffallend, da es keine Filter unterstützt.
Aufgaben
Jede Aufgabe wird mit 100 Anfragen aufgewärmt und dann werden 100 Anfragen gemessen. Beachten Sie, dass die Aufgaben der Einfachheit halber gruppiert wurden, da der Test 16 Suchtypen mal 2 verschiedene k-Werte mal 3 verschiedene n-Werte enthält.
- kNN-10-50: Suche in 2 Millionen Vektoren ohne Filter, k:10 und n:50
- knn-10-50-filtered: Suche in 2 Millionen Vektoren mit Filtern, k:10 und n:50
- knn-10-50-after-force-merge: Suche in 2 Millionen Vektoren mit Filtern und nach einer erzwungenen Zusammenführung, k:10 und n:50
- knn-10-100: Suche in 2 Millionen Vektoren ohne Filter, k:10 und n:100
- knn-10-100-filtered: Suche in 2 Millionen Vektoren mit Filtern, k:10 und n:100
- knn-10-100-after-force-merge: Suche in 2 Millionen Vektoren mit Filtern und nach einer erzwungenen Zusammenführung, k:10 und n:100
- knn-100-1000: Suche in 2 Millionen Vektoren ohne Filter, k:100 und n:1000
- knn-100-1000-filtered: Suche in 2 Millionen Vektoren mit Filtern, k:100 und n:1000
- knn-100-1000-after-force-merge: Suche in 2 Millionen Vektoren mit Filtern und nach einer erzwungenen Zusammenführung, k:100 und n:1000
- exact-knn: Exakte KNN-Suche mit und ohne Filter.

Elasticsearch ist in diesem Test durchweg schneller als OpenSearch, nur in zwei Fällen ist OpenSearch schneller, jedoch nicht viel (knn-10-100 und knn-100-1000). Aufgaben mit knn-10-50, knn-10-100 und knn-100-1000 in Kombination mit Filtern zeigen einen Unterschied von bis zu dem Siebenfachen (112 ms vs. 803 ms).
Die Leistung beider Lösungen scheint sich nach einem „force-merge“ verständlicherweise anzugleichen, wie knn-10-50-after-force-merge, knn-10-100-after-force-merge und knn-100-1000-after-force-merge zeigen. Bei diesen Aufgaben ist faiss schneller.
Die Leistung beim exakten kNN ist erneut sehr unterschiedlich, wobei Elasticsearch diesmal 13 Mal schneller ist als OpenSearch (~385 ms vs. ~5262 ms).
Recall
| knn-recall-10-100 | knn-recall-100-1000 | knn-recall-10-50 | |
|---|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 1 | 1 | 1 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 1 | 0,986667 | 1 |
| OpenSearch-2.14.0@lucene-hnsw | 1 | 1 | 1 |
| OpenSearch-2.14.0@faiss | 1 | 1 | 1 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 1 | 1 | 1 |
| OpenSearch-2.14.0@nmslib | 0,9674 | 0,910303 | 0,976394 |
Elasticsearch und Lucene als klare Sieger
Bei Elastic entwickeln wir Apache Lucene und Elasticsearch ständig weiter, um sicherzustellen, dass wir die führende Vektordatenbank für Such- und Abrufanwendungsfälle bereitstellen können, einschließlich RAG (Retrieval-Augmented Generation). Unsere jüngsten Fortschritte haben die Leistung drastisch gesteigert und, aufbauend auf den Vorteilen von Lucene 9.10, die Vektorsuche noch schneller und platzsparender gemacht. In diesem Blog wurde eine Studie vorgestellt, die zeigt, dass Elasticsearch beim Vergleich aktueller Versionen bis zu 12 Mal schneller ist als OpenSearch.
Es ist erwähnenswert, dass beide Produkte dieselbe Version von Lucene verwenden (Versionshinweise zu Elasticsearch 8.14 und zu OpenSearch 2.14).
Das Innovationstempo bei Elastic wird nicht nur für unsere On-Prem- und Elastic Cloud-Kunden, sondern auch für diejenigen, die unsere zustandslose Plattform nutzen, noch mehr bieten. Features wie die Unterstützung der skalaren Quantisierung auf int4 werden mit strengen Tests angeboten, um sicherzustellen, dass Kunden diese Techniken ohne signifikanten Rückgang der Abrufe nutzen können, ähnlich wie bei unseren Tests für int8.
Die Effizienz der Vektorsuche wird aufgrund der Verbreitung von KI- und Machine Learning-Anwendungen allmählich zu einem unverzichtbaren Feature in modernen Suchmaschinen. Für Unternehmen, die nach einer leistungsstarken Suchmaschine suchen, die in der Lage ist, mit den Anforderungen an großvolumige, hochkomplexe Vektordaten Schritt zu halten, ist Elasticsearch die definitive Antwort.
Egal, ob Sie eine etablierte Plattform erweitern oder neue Projekte initiieren – die Integration von Elasticsearch für Vektorsuchen ist ein strategischer Schritt, der greifbare, langfristige Vorteile bringen wird. Mit seinem nachgewiesenen Leistungsvorteil ist Elasticsearch bereit, die nächste Welle von Innovationen im Bereich des Suchens zu unterstützen.
Zugehörige Inhalte

23. April 2026
Wie wir Elasticsearch simdvec entwickelten, um die Vektorsuche zu einer der schnellsten weltweit zu machen
Wie wir Elasticsearch simdvec entwickelten, die von Hand optimierte SIMD-Kernel-Bibliothek hinter jeder Vektorsuchanfrage in Elasticsearch.

4. Mai 2026
So messen und verbessern Sie den Elasticsearch-Suchabruf: von 0,43 auf 0,75 mit Hybridsuche
Erfahren Sie, wie Sie den Suchabruf in Elasticsearch messen und verbessern können, indem Sie die lexikalische BM25-Suche mit Jina AI-Vektoreinbettungen kombinieren und dabei die rank_eval-API nutzen, um die Verbesserung mit realen Zahlen zu validieren.

2. April 2026
Wenn TSDS auf ILM trifft: Gestaltung von Zeitreihendatenströmen, die verspätete Daten nicht ablehnen
Interaktion zwischen den Zeitgrenzen von TSDS und den ILM-Phasen und Erstellung von Richtlinien, die verspätet eintreffende Metriken tolerieren.

1. April 2026
LINQ to Elasticsearch ES|QL: C# schreiben, Elasticsearch abfragen
Erkundung des neuen LINQ to Elasticsearch ES|QL-Providers im Elasticsearch .NET-Client, mit dem Sie C#-Code schreiben können, der automatisch in ES|QL-Abfragen übersetzt wird.

20. März 2026
Schnell vs. genau: Messung der Recall-Rate bei der quantisierten Vektorsuche
Eine Erklärung, wie der Recall für die Vektorsuche in Elasticsearch mit minimalem Aufwand gemessen werden kann.