De la recherche vectorielle aux API REST puissantes, Elasticsearch met à disposition des développeurs la boîte à outils de recherche la plus complète. Explorez nos notebooks d’exemple dans le dépôt Elasticsearch Labs pour tester de nouvelles approches. Vous pouvez également démarrer un essai gratuit ou exécuter Elasticsearch en local dès aujourd’hui.
Elasticsearch est jusqu’à 12 fois plus rapide - Chez Elastic, suite aux nombreuses requêtes de notre communauté concernant les écarts de performance entre Elasticsearch et OpenSearch, notamment dans la recherche sémantique et vectorielle, nous avons mené cette série de tests. Le but est d’offrir une comparaison claire et axée sur les données, sans ambiguïté, avec des faits simples pour informer nos utilisateurs. Les résultats montrent qu'Elasticsearch est jusqu'à 12 fois plus rapide qu'OpenSearch pour la recherche vectorielle et nécessite donc moins de ressources informatiques. Cela reflète la volonté d’Elastic de se concentrer sur la consolidation de Lucene comme la meilleure base de données vectorielles pour les cas d’utilisation de recherche et de récupération.
La recherche vectorielle est en train de révolutionner la manière dont nous effectuons les recherches par similarité, en particulier dans des domaines comme l’IA et le Machine Learning. Face à l’adoption de plus en plus répandue des modèles d’intégration de vecteurs, la capacité de rechercher efficacement à travers des millions de vecteurs de haute dimension devient cruciale.
Elastic et OpenSearch ont choisi des approches très distinctes pour l’exécution des bases de données vectorielles. Pour que ses produits soient le meilleur choix pour les applications de recherche vectorielle, Elastic a investi massivement dans l’optimisation d’Apache Lucene avec Elasticsearch. En revanche, OpenSearch a élargi son champ d’action en intégrant d’autres implémentations de recherche vectorielle et en explorant au-delà de la portée de Lucene. En nous concentrant de manière stratégique sur Lucene, nous pouvons proposer un soutien très intégré dans notre version d’Elasticsearch. Il en résulte un ensemble de fonctionnalités amélioré, où chaque composant complète et amplifie les capacités de l’autre.
Ce blog offre une comparaison détaillée entre Elasticsearch 8.14 et OpenSearch 2.14, en se basant sur différentes configurations et différents moteurs vectoriels. Dans cette analyse des performances, Elasticsearch s'est avéré être la plateforme supérieure pour les opérations de recherche vectorielle, et les fonctionnalités à venir creuseront encore davantage l'écart. Comparé à OpenSearch, il a excellé dans tous les domaines de référence — offrant des performances 2 à 12 fois plus rapides en moyenne. Cela s’est produit dans des scénarios utilisant des quantités et des dimensions de vecteurs variables, notamment so_vector (2 millions de vecteurs, 768D), openai_vector (2,5 millions de vecteurs, 1536D) et dense_vector (10 millions de vecteurs, 96D), tous disponibles dans ce référentiel aux côtés des scripts Terraform pour provisionner toute l’infrastructure requise sur Google Cloud et les manifestes Kubernetes pour exécuter les tests.
Les résultats de ce blog s’ajoutent à ceux d'une étude validée par une tierce partie et publiée précédemment. L’étude avait révélé qu’Elasticsearch est plus rapide de 40%–140% qu’OpenSearch en ce qui concerne les opérations d’analyse de recherche les plus courantes : requêtes textuelles, tri, plages, histogramme de dates et filtrage par termes. Maintenant, nous pouvons ajouter un autre facteur de différenciation : la recherche vectorielle. Maintenant, nous pouvons ajouter un autre facteur de différenciation : la recherche vectorielle.
Jusqu’à 12 fois plus rapide d’emblée
Nos tests d'évaluation ciblés sur les quatre ensembles de données vectorielles impliquaient à la fois des recherches KNN approximatives et KNN exactes, en tenant compte de différentes tailles, dimensions et configurations, totalisant 40.189.820 demandes de rechercher non mises en cache. Les résultats : Elasticsearch est jusqu'à 12 fois plus rapide qu'OpenSearch pour la recherche vectorielle et nécessite donc moins de ressources de calcul.

Figure 1 : Tâches groupées pour ANN et KNN exact dans différentes combinaisons dans Elasticsearch et OpenSearch.
Les groupes tels que knn-10-100 signifient une rechercher KNN avec et . Dans la recherche vectorielle HNSW, détermine le nombre de voisins les plus proches à récupérer pour un vecteur de requête. Il définit le nombre de vecteurs similaires qui seront renvoyés en résultat. définit le nombre de vecteurs candidats à récupérer à chaque segment. Un plus grand nombre de candidats peut renforcer la précision, au prix de ressources de calcul plus importantes.
Après avoir testé différentes techniques de quantification et tiré parti des optimisations spécifiques à chaque moteur, nous avons obtenu des résultats détaillés pour chaque piste, tâche et moteur vectoriel, que vous trouverez ci-dessous.
KNN exact et KNN approximatif
Pour des ensembles de données et des cas d’utilisation variés, l’approche appropriée pour la recherche vectorielle variera. Dans ce blog, toutes les tâches indiquées comme knn-* comme knn-10-100 utilisent Approximate KNN et script-score-* font référence à Exact KNN, mais quelle est la différence entre elles et pourquoi sont-elles importantes ?
Grâce à sa plus grande évolutivité, la méthode de l’algorithme des plus proches voisins approximatifs (ANN) est la solution préférée lorsque vous traitez des ensembles de données plus substantiels. La méthode des plus proches voisins exacts (KNN) est idéale pour les jeux de données plus modestes qui nécessitent parfois un processus de filtrage.
La méthode du KNN exact emploie une approche par la force brute, qui consiste à calculer la distance entre un vecteur et chaque autre vecteur du jeu de données. Elle classe ensuite ces distances pour trouver les voisins les plus proches. Même si cette méthode assure une correspondance exacte, elle fait face à des problèmes d’évolutivité pour les jeux de données volumineux et à haute dimension. Toutefois, il y a de nombreuses situations dans lesquelles le recours au KNN exact est requis :
- Réévaluation: dans les cas qui impliquent des recherches lexicales ou sémantiques suivies d’une réévaluation basée sur les vecteurs, le KNN exact est indispensable. Dans un moteur de recherche de produits, par exemple, on peut d’abord filtrer les résultats de recherche initiaux à l’aide de requêtes textuelles (mots-clés, catégories), puis utiliser les vecteurs associés aux éléments filtrés pour une évaluation de similarité plus précise.
- Personnalisation: dans le cas d'un grand nombre d'utilisateurs, dont chacun est représenté par un nombre relativement peu élevé (environ 1 million) de vecteurs distincts, le classement de l'index en fonction des métadonnées de l'utilisateur (p. ex., user_id) et le score par force brute avec des vecteurs deviennent efficaces. Cette approche permet de fournir des recommandations personnalisées ou un contenu personnalisé, en fonction de comparaisons de vecteurs précises qui sont spécifiquement conçues pour les préférences de chaque utilisateur.
Le KNN exact permet d’assurer un classement final et des recommandations précis et adaptés aux préférences de l’utilisateur, car ils sont fondés sur la similarité vectorielle.
D’un autre côté, le KNN approximatif (ANN) utilise des méthodes qui rendent la recherche de données plus rapide et plus efficace que le KNN exact, en particulier dans les jeux de données volumineux et à haute dimension. Contrairement à une approche par force brute qui mesure la distance exacte entre une requête et tous les points (ce qui pose des défis de calcul et de mise à l’échelle), l’ANN recourt à des techniques spécifiques afin de restructurer efficacement les index et les dimensions des vecteurs interrogeables dans l’ensemble de données. Même si cela peut entraîner une légère inexactitude, cela accélère considérablement le processus de recherche, ce qui en fait une solution de rechange efficace pour les ensembles de données volumineux.
Dans ce blog, toutes les tâches indiquées comme knn-* comme knn-10-100 utilisent KNN approximatif et script-score-* font référence à KNN exact.
Méthodologie de test
Même si l'API des opérations de recherche BM25 est similaire pour Elasticsearch et OpenSearch (puisque ce dernier est une copie du premier), cela ne s’applique pas à la recherche vectorielle, laquelle a été introduite après la copie. OpenSearch a adopté une approche différente d’Elasticsearch en ce qui concerne les algorithmes, en introduisant deux autres moteurs - nmslib et faiss luceneplus , chacun avec ses configurations et limitations spécifiques (par exemple, nmslib dans OpenSearch n’autorise pas les filtres, une fonctionnalité essentielle pour de nombreux cas d’utilisation).
Les trois moteurs emploient l’algorithme HNSW, lequel est très performant pour la recherche approximative des plus proches voisins et particulièrement puissant en présence de données de grande dimension. Il est important de noter que faiss prend également en charge un deuxième algorithme, ivf, mais comme il nécessite une formation préalable sur l'ensemble de données, nous allons nous concentrer uniquement sur HNSW. Le concept principal de HNSW est d’organiser les données en couches de graphes connectés, où chaque couche reflète une granularité différente de l’ensemble de données. La recherche s’amorce à la couche supérieure, qui propose la vue la plus grossière. Elle progresse ensuite vers des couches de plus en plus fines jusqu’au niveau de base.
Les deux moteurs de recherche ont fait l’objet de tests dans un cadre contrôlé, sous des conditions strictement identiques, afin de garantir un terrain d'essai équitable. La méthode utilisée est comparable à la comparaison de performance publiée précédemment, avec des groupes de nœuds dédiés pour Elasticsearch, OpenSearch et Rally. Le script terraform est disponible (ainsi que toutes les sources) pour provisionner un cluster Kubernetes avec :
- 1 pool de nœuds pour Elasticsearch avec 3 machines
e2-standard-32(128 Go de RAM et 32 processeurs) - 1 pool de nœuds pour OpenSearch avec 3 machines
e2-standard-32(128 Go de RAM et 32 processeurs) - 1 pool de nœuds pour Rally avec 2 machines
t2a-standard-16(64 Go de RAM et 16 processeurs)
Chaque test (ou piste) a été exécuté à 10 reprises pour chaque configuration, qui incluait différents moteurs, différentes configurations et différents types de vecteurs. Chaque piste se compose de tâches qui sont répétées de 1000 à 10 000 fois, en fonction de la piste. En cas d'échec d’une tâche dans une piste (en raison, par exemple, d’une temporisation de réseau), toutes les tâches sont abandonnées. C’est pourquoi tous les résultats sont issus de pistes qui ont démarré et se sont terminées sans problème. L’ensemble des résultats de test sont validés sur le plan statistique, ce qui assure que les améliorations ne sont pas le résultat d’une coïncidence.
Résultats détaillés
Pourquoi comparer en utilisant le 99e percentile et non la latence moyenne ? Prenons un exemple hypothétique du prix moyen des logements dans un quartier donné. Le prix moyen peut laisser penser que la zone est onéreuse, mais en y regardant de plus près, il peut se révéler que la plupart des logements sont évalués à un prix beaucoup plus bas, et que seules quelques propriétés de luxe font augmenter la moyenne. Le prix moyen peut ne pas refléter avec précision la gamme complète des valeurs des maisons dans la région, comme l’illustre cet exemple. C’est comparable à l’étude des temps de réponse, où le chiffre moyen peut dissimuler des enjeux critiques.
Tâches
- KNN approximatif avec k :10 n :50
- KNN approximatif avec k : 10 n : 100
- KNN approximatif avec k : 100 n : 1 000
- KNN approximatif avec k :10, n :50 et filtres de mots-clés
- KNN approximatif avec k : 10, n : 100 et filtres de mots-clés
- KNN approximatif avec k :100, n :1000 et filtres de mots-clés
- KNN approximatif avec k:10 n:100 en conjonction avec l'indexation
- KNN exact (score du script)
Moteurs vectoriels
lucenedans Elasticsearch et OpenSearch, tous deux en version 9.10faissdans OpenSearchnmslibdans OpenSearch
Types de vecteurs
hnswdans Elasticsearch et OpenSearchint8_hnswdans Elasticsearch (HNSW avec quantification automatique 8 bits–: lien)sq_fp16 hnswdans OpenSearch (HNSW avec quantification automatique 16 bits : lien)
Recherche prête à l'emploi et recherche de segments simultanés
Lucene est une bibliothèque de moteur de recherche de texte hautement performante, rédigée en Java. Elle constitue la pierre angulaire de nombreuses plateformes de recherche, telles qu’Elasticsearch, OpenSearch et Solr. Le cœur du système de Lucene repose sur l’organisation des données en segments. Ces segments sont des index autonomes qui permettent d’exécuter les recherches plus efficacement. Donc, si vous effectuez une recherche sur un moteur basé sur Lucene, cette recherche sera exécutée dans ces segments, de manière séquentielle ou en parallèle.
OpenSearch a introduit la recherche de segments simultanés en tant qu’indicateur facultatif et ne l’utilise pas par défaut, vous devez l’activer à l’aide d’un paramètre d’index spécial index.search.concurrent_segment_search.enabled comme détaillé ici, avec certaines limitations.
En revanche, Elasticsearch effectue des recherches sur les segments en parallèle par défaut. C’est pourquoi les comparaisons que nous effectuons dans cet article de blog tiendront compte, outre des différents moteurs et types de vecteurs, des différentes configurations également :
- Elasticsearch ootb : Elasticsearch prêt à l'emploi, avec recherche de segments simultanés ;
- OpenSearch ootb : sans activation de la recherche par segments simultanés ;
- OpenSearch css : avec la recherche par segments simultanés activée
À présent, examinons en détail les résultats pour chaque ensemble de données vectorielles qui a été testé :
2,5 millions de vecteurs, 1536 dimensions (openai_vector)
En commençant par la piste la plus simple, mais aussi la plus grande en termes de dimensions, openai_vector - qui utilise l'ensemble de données NQ enrichi avec des intégrations générées à l'aide du modèle text-embedding-ada-002 d'OpenAI. Il s'agit du plus simple, du fait qu’il ne teste que le KNN approximatif et qu'il ne comporte que 5 tâches. Les tests sont effectués en mode autonome (sans indexation) de même qu’en conjonction avec l’indexation, et avec un seul client ou 8 clients simultanés.
Tâches
- standalone-search-knn-10-100-multiple-clients : recherche sur 2,5 millions de vecteurs avec 8 clients simultanément, k : 10 et n :100
- standalone-search-knn-100-1000-multiple-clients : recherche sur 2,5 millions de vecteurs avec 8 clients simultanément, k : 100 et n : 1000
- standalone-search-knn-10-100-single-client: recherche sur 2,5 millions de vecteurs avec un seul client, k : 10 et n : 100
- standalone-search-knn-100-1000-single-client: recherche sur 2,5 millions de vecteurs avec un seul client, k : 100 et n : 1000
- parallel-documents-indexing-search-knn-10-100: indexation sur 2,5 millions de vecteurs tout en recherchant 100 000 documents supplémentaires, k : 10 et n : 100
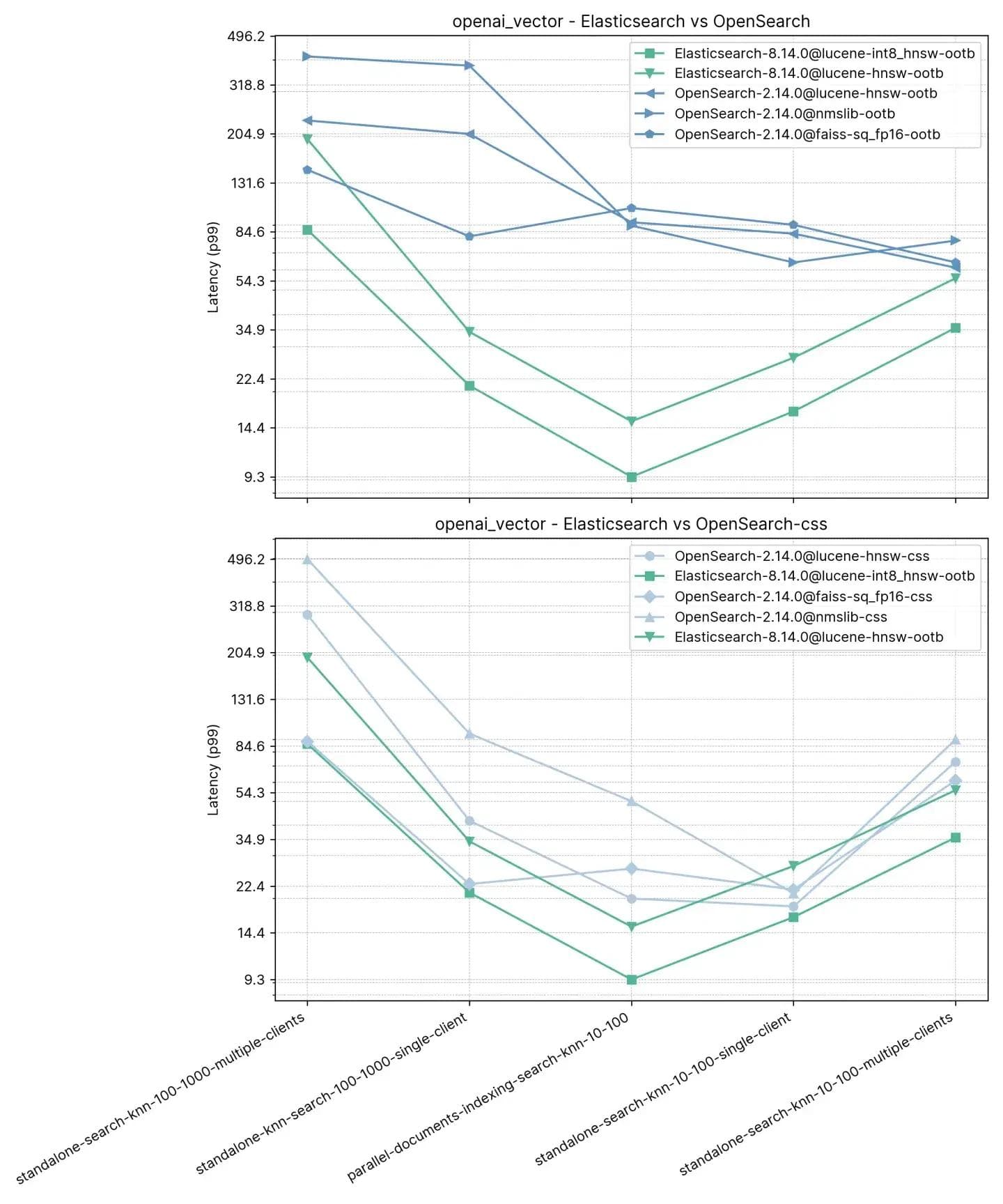
Les performances moyennes de p99 sont décrites ci-dessous :

Nous avons constaté ici qu’Elasticsearch est 3 à 8 fois plus rapide qu’OpenSearch lors d’une recherche vectorielle effectuée en parallèle de l'indexation (c’est-à-dire. lecture+écriture) avec :10 et :100 et 2 à 3 fois plus rapide sans indexation pour les mêmes k et n. Pour :100 et :1000 (standalone-rechercher-knn-100-1000-single-client et standalone-rechercher-knn-100-1000-multiple-clients Elasticsearch est 2 à 7 fois plus rapide qu'OpenSearch, en moyenne.
Les résultats détaillés montrent les cas exacts et les moteurs vectoriels comparés :
Rappel
| knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 0,969485 | 0,995138 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 0,781445 | 0,784817 |
| OpenSearch-2.14.0@lucene-hnsw | 0,96519 | 0,995422 |
| OpenSearch-2.14.0@faiss | 0,984154 | 0,98049 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 0,980012 | 0,97721 |
| OpenSearch-2.14.0@nmslib | 0,982532 | 0,99832 |
10 millions de vecteurs, 96 dimensions (dense_vector)
dense_vector avec 10 millions de vecteurs et 96 dimensions. Il est basé sur le jeu de données d'images Yandex DEEP1B. Le jeu de données est créé à partir des 10 premiers millions de vecteurs du fichier « données d’échantillon » appelé learn.350M.fbin. Les opérations de recherche font appel à des vecteurs qui proviennent du fichier de « requêtes de données » query.public.10K.fbin.
Après une fusion forcée, qui est habituellement effectuée sur des index en lecture seule, Elasticsearch et OpenSearch sont très performants sur cet ensemble de données. Cette opération est similaire à une défragmentation, ce qui permet d’avoir une seule « table » pour la recherche.
Tâches
Chaque tâche fait l'objet d’un préchauffage de 100 requêtes, et la mesure est ensuite effectuée sur les 1000 requêtes suivantes
- knn-search-10-100: recherche sur 10 millions de vecteurs, k : 10 et n : 100
- knn-search-100-1000: recherche sur 10 millions de vecteurs, k : 100 et n : 1000
- knn-search-10-100-force-merge: recherche sur 10 millions de vecteurs après une fusion forcée, k : 10 et n : 100
- knn-search-100-1000-force-merge: recherche sur 10 millions de vecteurs après une fusion forcée, k : 100 et n :1000
- knn-search-100-1000-concurrent-with-indexing: indexation sur 10 millions de vecteurs tout en mettant à jour 5 % de l'ensemble de données, k : 100 et n : 1000
- script-score-query: recherche KNN exacte de 2000 vecteurs spécifiques.
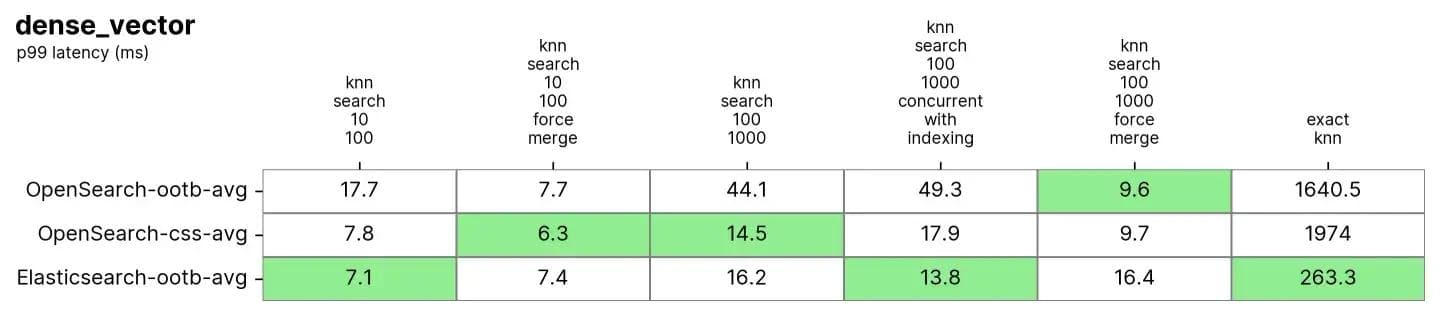
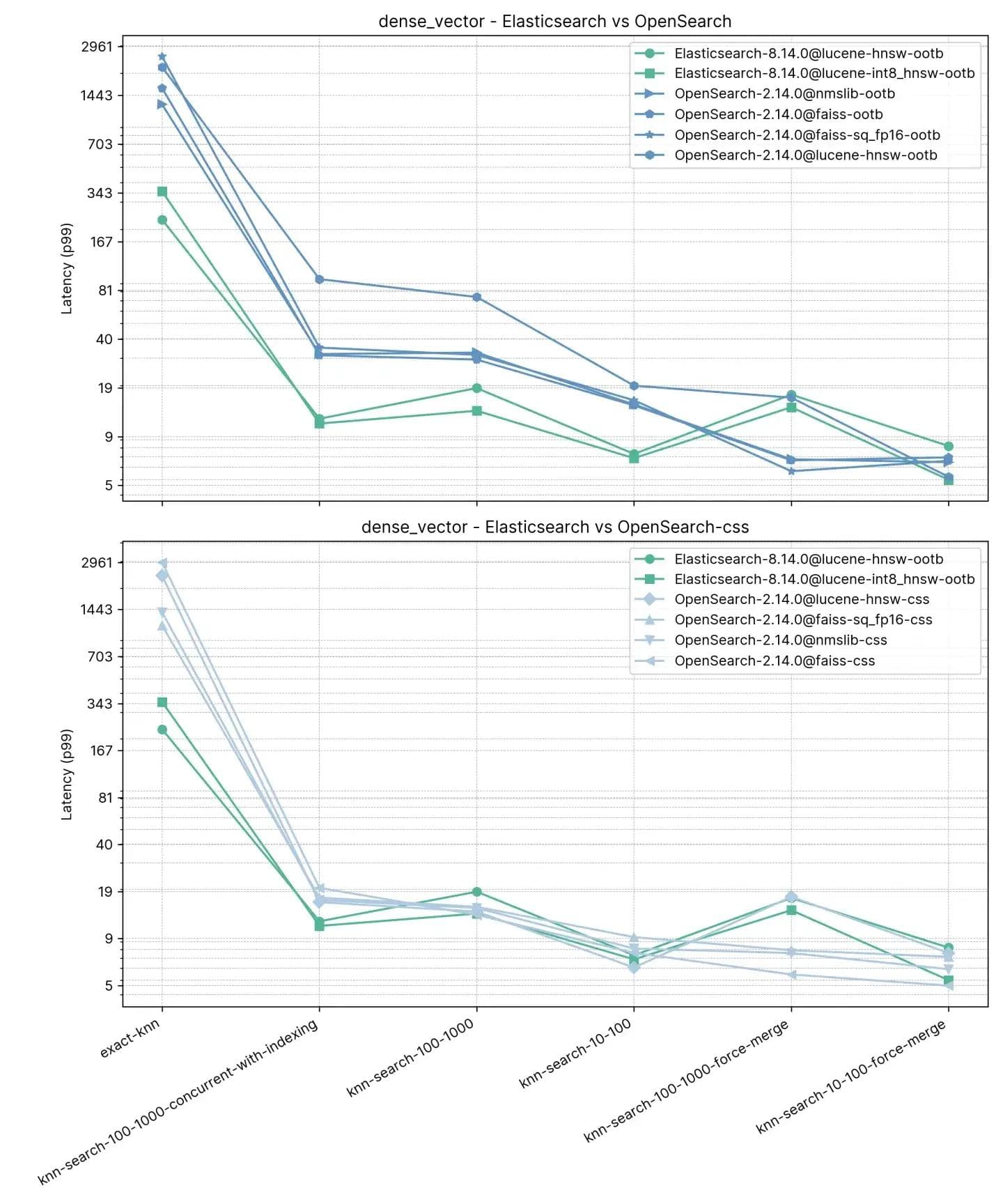
Elasticsearch et OpenSearch ont tous deux obtenu de bons résultats pour le KNN approximatif. Lorsque l’index est fusionné (c’est-à-dire qu’il n’a qu’un seul segment) dans knn-rechercher-100-1000-force-merge et knn-rechercher-10-100-force-merge, OpenSearch fonctionne mieux que les autres lors de l’utilisation de nmslib et faiss, même s’ils sont tous autour de 15 ms et tous très proches.
Lorsque l'index a plusieurs segments (ce qui est typique lorsqu'un index reçoit des mises à jour), Elasticsearch maintient la latence autour de ~7ms et ~16ms dans les tests knn-search-10-100 et knn-search-100-1000, tandis que tous les autres moteurs OpenSearch sont plus lents.
Lorsque l'index est interrogé et mis à jour simultanément (knn-search-100-1000-concurrent-with-indexing), Elasticsearch maintient une latence inférieure à 15 ms (13,8 ms). Il est presque 4 fois plus rapide qu’OpenSearch par défaut (49,3 ms) et reste plus rapide lorsque la recherche concurrente de segments est activée (17,9 ms), bien que la différence ne soit pas significative.
En ce qui concerne le KNN exact, l’écart est bien plus important : Elasticsearch est 6 fois plus rapide qu’OpenSearch (~260 ms contre ~1600 ms).
Rappel
| knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 0,969843 | 0,996577 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 0,775458 | 0,840254 |
| OpenSearch-2.14.0@lucene-hnsw | 0,971333 | 0,996747 |
| OpenSearch-2.14.0@faiss | 0,9704 | 0,914755 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 0,968025 | 0,913862 |
| OpenSearch-2.14.0@nmslib | 0,9674 | 0,910303 |
2 millions de vecteurs, 768 dimensions (so_vector)
Cette piste, so_vector, est dérivée d’une extraction des publications de StackOverflow téléchargée le 21 avril 2022. Seuls les documents de questions y figurent, les documents de réponses ayant tous été supprimés. Chaque titre de question a été encodé dans un vecteur en utilisant le modèle de transformateur de phrase multi-qa-mpnet-base-cos-v1. Cet ensemble de données contient les 2 premiers millions de questions.
Contrairement à la piste précédente, chaque document ici contient d'autres champs en plus des vecteurs pour prendre en charge le test de fonctionnalités comme le KNN approximatif avec filtrage et la recherche hybride. nmslib pour OpenSearch est notamment absent dans ce test car il ne prend pas en charge les filtres.
Tâches
Chaque tâche fait l'objet d’un préchauffage de 100 requêtes, et la mesure est ensuite effectuée sur les 100 requêtes suivantes. Veuillez noter que les tâches ont été groupées dans un souci de simplicité, le test contenant 16 types de recherche, 2 valeurs k et 3 valeurs n différentes.
- KNN-10-50: recherche sur 2 millions de vecteurs sans filtres, k :10 et n :50
- knn-10-50-filtered: recherche sur 2 millions de vecteurs avec des filtres, k :10 et n :50
- knn-10-50-after-force-merge: recherche sur 2 millions de vecteurs avec filtres et après une fusion forcée, k :10 et n :50
- KNN-10-100: recherche sur 2 millions de vecteurs sans filtres, k :10 et n :100
- knn-10-100-filtered: recherche sur 2 millions de vecteurs avec des filtres, k :10 et n :100
- knn-10-100-after-force-merge: recherche sur 2 millions de vecteurs avec filtres et après une fusion forcée, k :10 et n :100
- KNN-100-1000: Recherche sur 2 millions de vecteurs sans filtres, k :100 et n :1000
- knn-100-1000-filtered: recherche sur 2 millions de vecteurs avec des filtres, k :100 et n :1000
- knn-100-1000-after-force-merge: recherche sur 2 millions de vecteurs avec filtres et après une fusion forcée, k :100 et n :1000
- exact-knn: recherche KNN exacte avec et sans filtres.

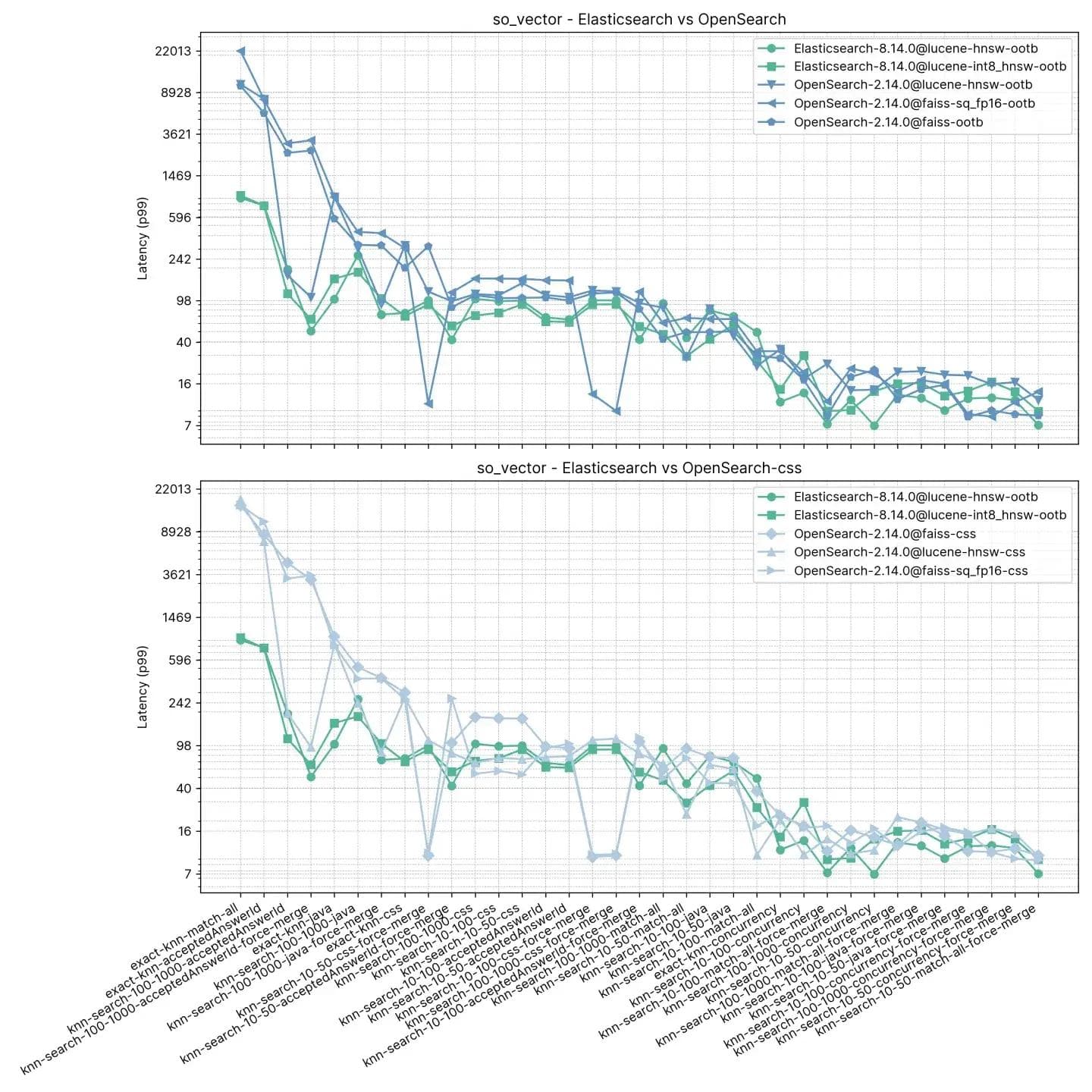
Au cours de ce test, Elasticsearch est toujours plus rapide qu’OpenSearch par défaut, sauf dans deux cas où la différence n’est pas très grande (knn-10-100 et knn-100-1000). Les tâches impliquant knn-10-50, knn-10-100 et knn-100-1000 en combinaison avec des filtres montrent une différence allant jusqu'à 7x (112 ms contre 803 ms).
Les performances des deux solutions semblent s'équilibrer après une « fusion forcée », ce qui est compréhensible, comme en témoignent knn-10-50-after-force-merge, knn-10-100-after-force-merge et knn-100-1000-after-force-merge. Pour ces tâches, faiss est plus rapide.
La performance pour le KNN exact est à nouveau très différente : Elasticsearch est cette fois 13 fois plus rapide qu’OpenSearch (~385 ms contre ~5262 ms).
Rappel
| knn-recall-10-100 | knn-recall-100-1000 | knn-recall-10-50 | |
|---|---|---|---|
| Elasticsearch-8.14.0@lucene-hnsw | 1 | 1 | 1 |
| Elasticsearch-8.14.0@lucene-int8_hnsw | 1 | 0,986667 | 1 |
| OpenSearch-2.14.0@lucene-hnsw | 1 | 1 | 1 |
| OpenSearch-2.14.0@faiss | 1 | 1 | 1 |
| OpenSearch-2.14.0@faiss-sq_fp16 | 1 | 1 | 1 |
| OpenSearch-2.14.0@nmslib | 0,9674 | 0,910303 | 0,976394 |
Elasticsearch et Lucene, les vainqueurs incontestables
Chez Elastic, nous innovons sans cesse avec Apache Lucene et Elasticsearch pour pouvoir proposer la meilleure base de données vectorielles pour les cas d'utilisation de recherche et de récupération, y compris la RAG (Génération augmentée de récupération). Nos avancées récentes ont considérablement amélioré les performances, rendant la recherche vectorielle plus rapide et plus économe en espace qu'auparavant, en s'appuyant sur les améliorations de Lucene 9.10. Ce blog présente une étude qui montre que lorsque l’on compare les versions les plus récentes, Elasticsearch est jusqu’à 12 fois plus rapide qu’OpenSearch.
Il convient de noter que les deux produits utilisent la même version de Lucene (Notes de publication d'Elasticsearch 8.14 et Notes de publication d'OpenSearch 2.14).
Le rythme d'innovation d'Elastic nous permettra d'aller encore plus loin, non seulement pour nos clients sur site et Elastic Cloud, mais aussi pour ceux qui utilisent notre plateforme sans état. Des fonctionnalités comme la prise en charge de la quantification scalaire vers int4 seront proposées avec des tests rigoureux, afin que les clients puissent utiliser ces techniques sans une perte significative d'exactitude, de la même manière que nos tests pour l’int8.
La capacité d’une recherche vectorielle à être efficace est un critère non négociable pour les moteurs de recherche modernes, du fait de la prolifération des applications d’IA et de Machine Learning. Elasticsearch est la solution qui s’impose pour les organisations qui ont besoin d’un moteur de recherche puissant capable de gérer la demande en données vectorielles de grand volume et de haute complexité.
L’intégration d’Elasticsearch pour les besoins de recherche vectorielle, que ce soit pour étendre une plateforme établie ou lancer de nouveaux projets, représente une approche stratégique qui générera des bénéfices tangibles et à long terme. Fort de son avantage de performance avéré, Elasticsearch est bien placé pour sous-tendre la prochaine vague d’innovations dans la recherche.
Pour aller plus loin

23 avril 2026
Comment nous avons construit Elasticsearch simdvec pour faire de la recherche vectorielle l'une des plus rapides au monde
Comment nous avons conçu Elasticsearch simdvec, la bibliothèque de noyaux SIMD optimisée manuellement qui alimente chaque requête de recherche vectorielle dans Elasticsearch.

4 mai 2026
Comment mesurer et améliorer le rappel de recherche Elasticsearch : de 0,43 à 0,75 avec la recherche hybride
Découvrez comment mesurer et améliorer le rappel de recherche dans Elasticsearch en combinant la recherche lexicale BM25 avec les embeddings vectoriels de Jina AI, en utilisant l’API rank_eval pour valider l’amélioration avec des données chiffrées.

10 avril 2026
Clustering de documents non supervisé avec Elasticsearch + Jina embeddings
Une approche pratique et reproductible pour le clustering non supervisé de documents avec Elasticsearch et les embeddings Jina.

2 avril 2026
Quand les TSDS rencontrent l'ILM : Concevoir des flux de données temporelles qui ne rejettent pas les données en retard
Comment les limites temporelles des TSDS interagissent avec les phases de l'ILM ; et comment concevoir des politiques qui tolèrent les métriques arrivant en retard.

1 avril 2026
LINQ to Elasticsearch ES|QL : écrire en C#, interroger Elasticsearch
Découverte du nouveau fournisseur LINQ to Elasticsearch ES|QL dans le client Elasticsearch .NET, qui vous permet d'écrire du code C# qui est automatiquement converti en requêtes ES|QL.