Plus tôt cette année, Elastic a annoncé la collaboration avec NVIDIA pour apporter l'accélération GPU à Elasticsearch, en intégrant NVIDIA cuVS—comme détaillé lors d'une session à NVIDIA GTC et dans divers blogs. Cet article fait le point sur les efforts de co-ingénierie menés avec l'équipe de recherche vectorielle de NVIDIA.
Récapitulatif
Tout d'abord, faisons le point sur la situation. Elasticsearch s'est imposé comme une base de données vectorielle puissante, offrant un ensemble complet de fonctionnalités et des performances élevées pour la recherche de similitudes à grande échelle. Avec des capacités telles que la quantification scalaire, la quantification binaire améliorée (BBQ), les opérations vectorielles SIMD et des algorithmes plus efficaces en termes d'espace disque comme DiskBBQ, il offre déjà des options efficaces et flexibles pour gérer les charges de travail vectorielles.
En intégrant NVIDIA cuVS en tant que module accessible pour les tâches de recherche vectorielle, nous visons à améliorer considérablement les performances et l'efficacité de l'indexation vectorielle afin de mieux prendre en charge les charges de travail vectorielles à grande échelle.
Le défi
L'un des défis les plus complexes dans la création d'une base de données vectorielle haute performance est la construction de l'index vectoriel, le graphe HNSW. La construction de l'index est rapidement dominée par des millions, voire des milliards d'opérations arithmétiques, car chaque vecteur est comparé à de nombreux autres. De plus, les opérations liées au cycle de vie des index, telles que la compression et les fusions, peuvent augmenter davantage la charge de calcul globale liée à l'indexation. À mesure que les volumes de données et les intégrations vectorielles associées augmentent de manière exponentielle, les GPU de calcul accéléré, conçus pour le parallélisme massif et les calculs mathématiques à haut débit, sont idéalement positionnés pour gérer ces charges de travail.
Installez le plugin Elasticsearch-GPU
NVIDIA cuVS est une bibliothèque open source CUDA-X pour la recherche vectorielle accélérée par GPU et le clustering de données, permettant une création rapide d'index et une récupération d'embeddings pour les charges de travail liées à l'IA et aux recommandations.
Elasticsearch utilise cuVS via cuvs-java, une bibliothèque open-source développée par la communauté et gérée par NVIDIA. La bibliothèque cuvs-java est légère et repose sur l'API cuVS C en utilisant Panama Foreign Function pour exposer les fonctionnalités cuVS d'une manière idiomatique Java, tout en restant moderne et performante.
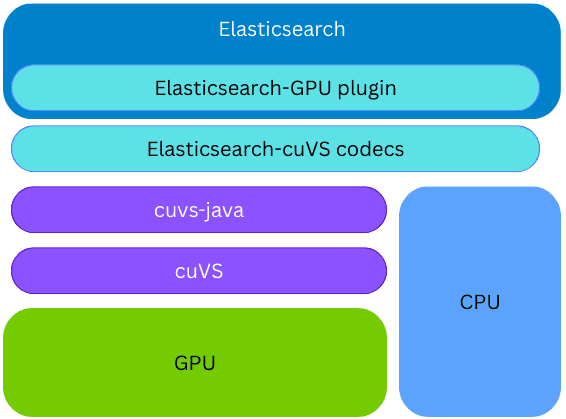
La bibliothèque cuvs-java est intégrée dans un nouveau plug-in Elasticsearch ; par conséquent, l'indexation vectorielle sur le GPU peut être effectuée sur le même node et processus Elasticsearch, sans qu'il soit nécessaire de provisionner du code ou du matériel externe. Lors de la création d'index, si la bibliothèque cuVS est installée et qu'un GPU est présent et configuré, Elasticsearch utilisera le GPU pour accélérer le processus d'indexation vectorielle. Les vecteurs sont transmis au GPU, qui crée un un graphe CAGRA. Ce graphe est ensuite converti au format HNSW, ce qui le rend immédiatement disponible pour la rechercher vectorielle sur le processeur. Le format final du graphe construit est identique à celui qui serait construit sur le CPU ; cela permet à Elasticsearch d'exploiter les GPU pour une indexation vectorielle à haut débit lorsque le matériel sous-jacent le prend en charge, tout en libérant la puissance du CPU pour d'autres tâches (recherche simultanée, traitement des données, etc.).
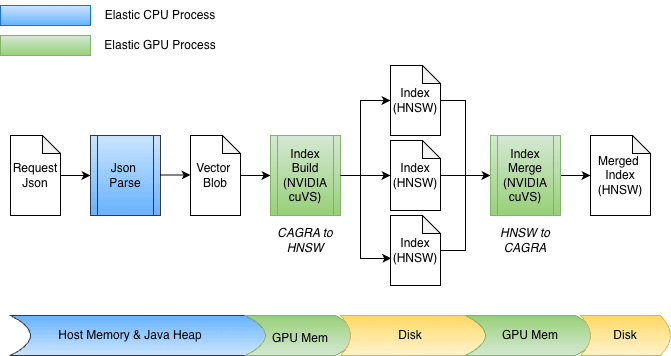
Accélération de la création d'index
Dans le cadre de l'intégration de l'accélération GPU dans Elasticsearch, plusieurs améliorations ont été apportées à cuvs-java, en mettant l'accent sur l'efficacité de l'entrée/sortie de données et l'invocation de fonctions. L'une des principales améliorations est l'utilisation de cuVSMatrix pour modéliser de manière transparente les vecteurs, qu'ils se trouvent sur le tas Java, hors tas ou dans la mémoire du GPU. Cela permet aux données de se déplacer efficacement entre la mémoire et le GPU, en évitant les copies inutiles de milliards de vecteurs potentiels.
Grâce à cette abstraction sous-jacente sans copie, le transfert vers la mémoire GPU et la récupération du graphe peuvent être effectués directement. Pendant l'indexation, les vecteurs sont d'abord mis en mémoire tampon sur le tas Java, puis envoyés au GPU pour construire le graphe CAGRA. Le graphe est ensuite récupéré à partir du GPU, converti au format HNSW et persisté sur le disque.
Au moment de la fusion, les vecteurs sont déjà stockés sur le disque, contournant ainsi entièrement le tas Java. Les fichiers d'index sont mappés en mémoire et les données sont transférées directement dans la mémoire du GPU. La conception s'adapte également facilement à différentes largeurs de bits, telles que float32 ou int8, et s'étend naturellement à d'autres schémas de quantification.
Roulement de tambour... alors, comment ça fonctionne ?
Avant d'examiner les chiffres, un peu de contexte s'impose. La fusion des segments dans Elasticsearch s'exécute généralement automatiquement en arrière-plan pendant l'indexation, ce qui rend difficile l'évaluation comparative de manière isolée. Pour obtenir des résultats reproductibles, nous avons utilisé la fusion forcée pour déclencher explicitement la fusion des segments dans une expérience contrôlée. Comme la fusion forcée effectue les mêmes opérations de fusion sous-jacentes que la fusion en arrière-plan, ses performances servent d'indicateur utile des améliorations attendues, même si les gains exacts peuvent différer selon les charges de travail d'indexation réelles.
Passons maintenant aux chiffres.
Nos premiers résultats de référence sont très prometteurs. Nous avons exécuté une évaluation comparative sur une instance AWS g6.4xlarge avec un stockage NVMe connecté localement. Un seul node d'Elasticsearch a été configuré pour utiliser le nombre optimal par défaut de threads d'indexation (8, soit un pour chaque noyau physique) et pour désactiver la limitation de fusion (qui est moins applicable avec les disques NVMe rapides).
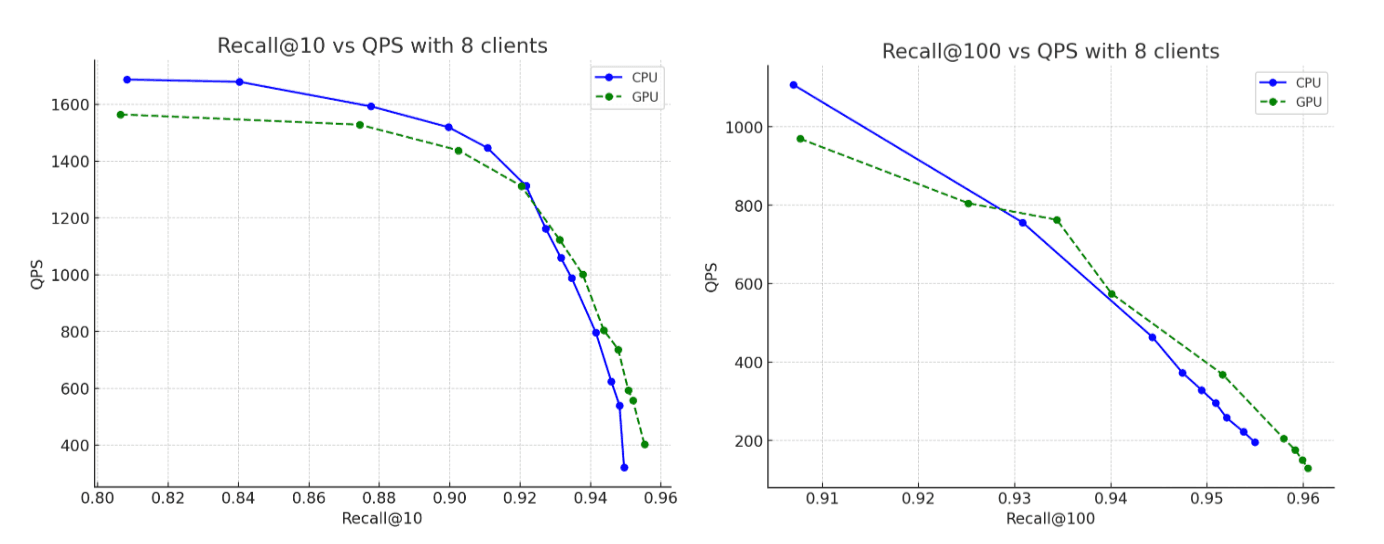
Pour l'ensemble de données, nous avons utilisé 2,6 millions de vecteurs avec 1 536 dimensions provenant de l' OpenAI Rally vector track, encodés sous forme de chaînes base64 et indexés sous forme de float32 hnsw. Dans tous les scénarios, les graphes créés atteignent des niveaux de rappel allant jusqu'à 95 %. Voici nos conclusions :
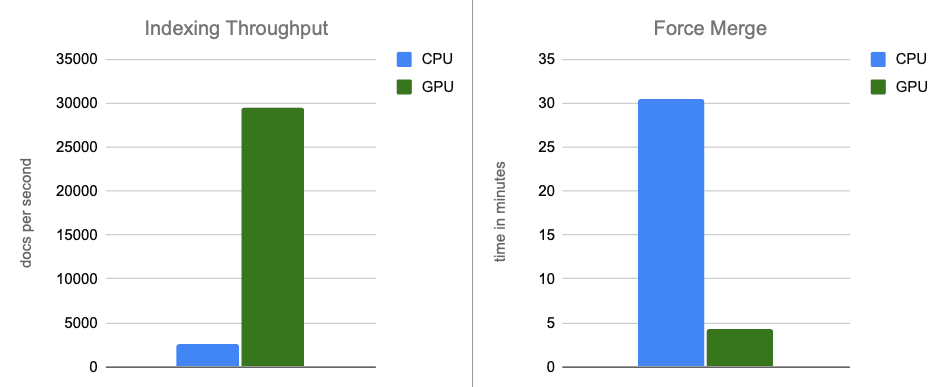
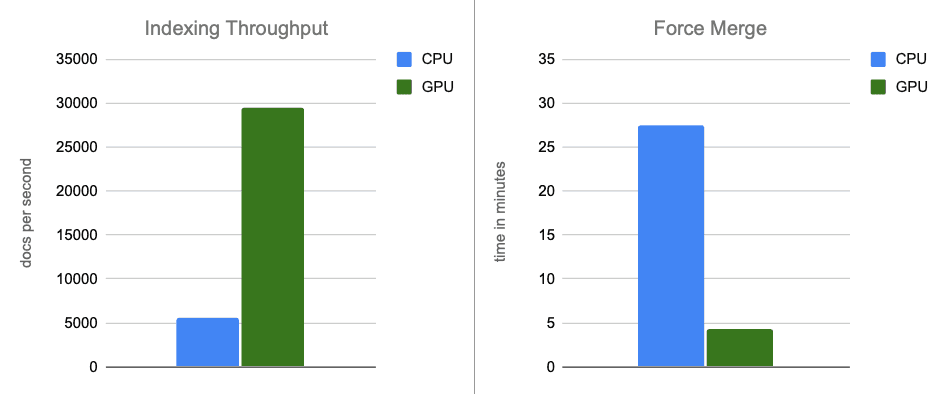
- Débit d'indexation : en transférant la construction des graphiques vers le GPU pendant les vidages de mémoire tampon, nous multiplions le débit par environ 12.
- Fusion forcée : une fois l'indexation terminée, le GPU continue d'accélérer la fusion des segments, multipliant par environ 7 la vitesse de la phase de fusion forcée.
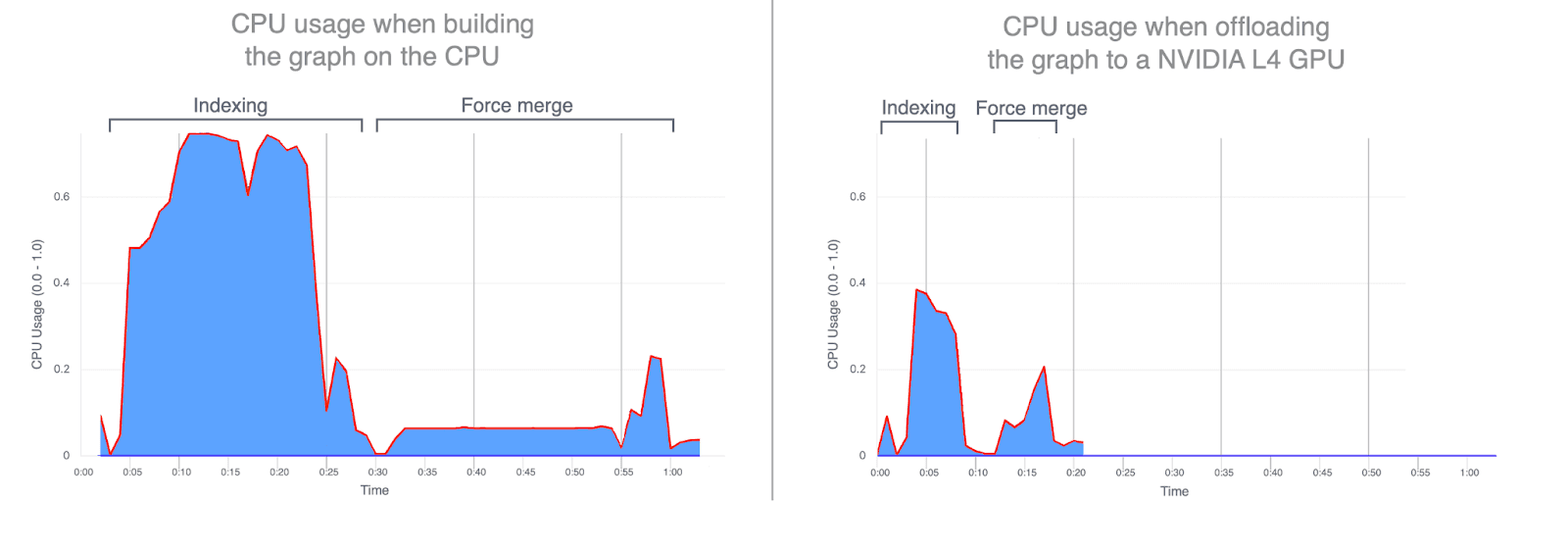
- Utilisation du processeur : le transfert de la construction du graphe vers le GPU réduit considérablement l'utilisation moyenne et maximale du processeur. Les graphiques ci-dessous illustrent l'utilisation du CPU pendant l'indexation et la fusion, et mettent en évidence à quel point elle est plus faible lorsque ces opérations sont exécutées sur le GPU. La réduction de l'utilisation du CPU pendant l'indexation GPU permet de libérer des cycles CPU qui peuvent être réaffectés à l'amélioration des performances de recherche.
- Rappel : la précision reste pratiquement identique entre les exécutions CPU et GPU, le graphique généré par le GPU affichant un rappel légèrement supérieur.
Comparaison selon un autre critère : le prix
La comparaison précédente utilisait intentionnellement un matériel identique, la seule différence étant l'utilisation ou non du GPU lors de l'indexation. Cette configuration est utile pour isoler les effets du calcul brut, mais nous pouvons également examiner la comparaison du point de vue des coûts.
Pour un prix horaire à peu près équivalent à celui de la configuration accélérée par GPU, il est possible de provisionner une configuration uniquement sur processeur avec environ deux fois plus de ressources CPU et mémoire comparables : 32 vCPU (AMD EPYC) et 64 Go de RAM, permettant de doubler le nombre de threads d’indexation à 16.
Afin de garantir l'équité et la cohérence de la comparaison, nous avons réalisé cette expérience uniquement sur processeur sur une instance AWS g6.8xlarge, avec le GPU explicitement désactivé. Cela nous a permis de maintenir toutes les autres caractéristiques matérielles constantes tout en évaluant le compromis coût-performance entre l'accélération GPU et l'indexation uniquement sur processeur.
L'instance de processeur plus puissante montre effectivement une performance améliorée par rapport aux benchmarks de la section ci-dessus, comme on pouvait s'y attendre. Cependant, lorsque nous comparons cette instance de processeur plus puissante aux résultats originaux accélérés par GPU, le GPU offre toujours des gains de performance substantiels : ~5x d'amélioration dans le débit d'indexation, et ~6x dans la fusion forcée, tout en construisant des graphes qui atteignent des niveaux de rappel allant jusqu'à 95%.
Conclusion
Dans les scénarios de bout en bout, l'accélération GPU avec NVIDIA cuVS permet d'améliorer de près de 12 fois le débit d'indexation et de réduire de 7 fois la latence de fusion forcée, tout en diminuant considérablement l'utilisation du processeur. Cela démontre que l'indexation vectorielle et les charges de travail de fusion bénéficient considérablement de l'accélération GPU. Sur une comparaison ajustée en fonction des coûts, l'accélération GPU continue d'offrir des gains de performances substantiels, avec un débit d'indexation environ 5 fois supérieur et des opérations de fusion forcée 6 fois plus rapides.
L'indexation vectorielle accélérée par GPU est actuellement prévue pour la préversion technique dans Elasticsearch 9.3, dont la sortie est prévue début 2026.
Plus d'informations à venir.
Pour aller plus loin

23 avril 2026
Comment nous avons construit Elasticsearch simdvec pour faire de la recherche vectorielle l'une des plus rapides au monde
Comment nous avons conçu Elasticsearch simdvec, la bibliothèque de noyaux SIMD optimisée manuellement qui alimente chaque requête de recherche vectorielle dans Elasticsearch.

4 mai 2026
Comment mesurer et améliorer le rappel de recherche Elasticsearch : de 0,43 à 0,75 avec la recherche hybride
Découvrez comment mesurer et améliorer le rappel de recherche dans Elasticsearch en combinant la recherche lexicale BM25 avec les embeddings vectoriels de Jina AI, en utilisant l’API rank_eval pour valider l’amélioration avec des données chiffrées.

10 avril 2026
Clustering de documents non supervisé avec Elasticsearch + Jina embeddings
Une approche pratique et reproductible pour le clustering non supervisé de documents avec Elasticsearch et les embeddings Jina.

2 avril 2026
Quand les TSDS rencontrent l'ILM : Concevoir des flux de données temporelles qui ne rejettent pas les données en retard
Comment les limites temporelles des TSDS interagissent avec les phases de l'ILM ; et comment concevoir des politiques qui tolèrent les métriques arrivant en retard.

1 avril 2026
LINQ to Elasticsearch ES|QL : écrire en C#, interroger Elasticsearch
Découverte du nouveau fournisseur LINQ to Elasticsearch ES|QL dans le client Elasticsearch .NET, qui vous permet d'écrire du code C# qui est automatiquement converti en requêtes ES|QL.