La recherche vectorielle ne suffit pas pour trouver des résultats pertinents. Il est très courant d'utiliser des critères de filtrage qui permettent de réduire les résultats de la recherche et d'éliminer les résultats non pertinents.
Comprendre le fonctionnement du filtrage dans la recherche vectorielle vous aidera à équilibrer les compromis entre performance et rappel, et à découvrir certaines des optimisations utilisées pour rendre la recherche vectorielle plus performante lorsque le filtrage est utilisé.
Pourquoi le filtrage ?
La recherche vectorielle a révolutionné la manière dont nous trouvons des informations pertinentes dans de grands ensembles de données, en nous permettant de découvrir des éléments sémantiquement similaires à une requête.
Toutefois, il ne suffit pas de trouver des articles similaires. Nous devons souvent réduire les résultats de la recherche en fonction de critères ou d'attributs spécifiques.
Imaginez que vous recherchiez un produit dans un magasin de commerce électronique. Une recherche purement vectorielle peut vous montrer des articles visuellement similaires, mais vous pouvez aussi vouloir filtrer par fourchette de prix, marque, disponibilité ou évaluations des clients. Sans filtrage, vous seriez confronté à un vaste éventail de produits similaires, ce qui rendrait difficile de trouver exactement ce que vous cherchez.
Le filtrage permet un contrôle précis des résultats de la recherche, garantissant que les éléments récupérés ne sont pas seulement alignés sur le plan sémantique, mais qu'ils répondent également à toutes les exigences nécessaires. L'expérience de recherche est ainsi beaucoup plus précise, efficace et conviviale.
C'est là qu'Elasticsearch et Apache Lucene excellent - l'utilisation d'un filtrage efficace sur différents types de données est l'une des principales différences avec les autres bases de données vectorielles.
Filtrage pour la recherche vectorielle exacte
Il existe deux manières principales d'effectuer des recherches de vecteurs exacts :
- Utilisation d'un type d'index
flatpour votre champ dense_vector. Ainsi, les recherches surknnutilisent la recherche exacte au lieu de la recherche approximative. - Utilisation d'une requête script_score qui utilise des fonctions vectorielles pour calculer le score. Ceci peut être utilisé avec n'importe quel type d'index.
Lors de l'exécution d'une recherche vectorielle exacte, tous les vecteurs sont comparés à la requête. Dans ce cas, le filtrage améliore les performances, car seuls les vecteurs qui passent le filtre doivent être comparés.
Cela n'a pas d'incidence sur la qualité du résultat, car tous les vecteurs sont pris en compte de toute façon. Nous filtrons simplement à l'avance les résultats qui ne sont pas intéressants, afin de réduire le nombre d'opérations.
C'est très important, car il peut être plus performant d'exécuter une recherche exacte plutôt qu'une recherche approximative lorsque les filtres appliqués donnent un petit nombre de documents.
La règle de base est d'utiliser la recherche exacte lorsque moins de 10 000 documents passent le filtre. Les index BBQ sont beaucoup plus rapides pour les comparaisons, il est donc logique d'utiliser la recherche exacte lorsque les index basés sont inférieurs à 100k. Consultez cet article de blog pour plus de détails.
Si vos filtres sont toujours très restrictifs, vous pouvez envisager une indexation axée sur la recherche exacte plutôt que sur la recherche approximative en utilisant un type d'index flat plutôt qu'un index basé sur HNSW. Pour plus de détails, voir les propriétés de index_options.
Filtrage pour la recherche vectorielle approximative
Lors de l'exécution d'une recherche vectorielle approximative, nous échangeons la précision des résultats contre la performance. Les structures de données de recherche vectorielle telles que HNSW recherchent efficacement les voisins les plus proches sur des millions de vecteurs. Ils se concentrent sur la récupération des vecteurs les plus similaires en effectuant le moins possible de comparaisons de vecteurs, qui sont coûteuses à calculer.
Cela signifie que les autres attributs de filtrage ne font pas partie des données vectorielles. Les différents types de données ont leurs propres structures d'indexation qui sont efficaces pour les trouver et les filtrer, comme les dictionnaires de termes, les listes d'écritures et les valeurs doc.
Étant donné que ces structures de données sont distinctes du mécanisme de recherche vectorielle, comment appliquer le filtrage à la recherche vectorielle ? Il existe deux options : appliquer les filtres après la recherche vectorielle (post-filtrage) ou avant la recherche vectorielle (préfiltrage).
Chacune de ces options présente des avantages et des inconvénients. Voyons cela de plus près !
Post-filtrage
Le post-filtrage applique des filtres après que la recherche vectorielle a été effectuée. Cela signifie que les filtres sont appliqués après que les k résultats vectoriels les plus similaires ont été trouvés.
Il est évident que nous pouvons potentiellement obtenir moins de k résultats après avoir appliqué les filtres aux résultats. Nous pourrions bien sûr obtenir plus de résultats à partir de la recherche vectorielle (valeur k plus élevée), mais nous ne serons pas sûrs d'obtenir k ou plus après avoir appliqué les filtres.
L'avantage du post-filtrage est qu'il ne modifie pas le comportement de la recherche vectorielle lors de l'exécution - la recherche vectorielle n'est pas consciente du filtrage. En revanche, il modifie le nombre final de résultats obtenus.
Voici un exemple de post-filtrage à l'aide de la requête knn. Vérifier que la clause de filtrage est distincte de la requête knn :
Le post-filtrage est également disponible pour la recherche knn en utilisant le post-filtre:
Gardez à l'esprit que vous devez utiliser une section de post-filtrage explicite avec la recherche knn. Si vous n'utilisez pas de post-filtre, la recherche knn combinera les résultats des plus proches voisins avec d'autres requêtes ou filtres au lieu d'effectuer un post-filtre.
Préfiltrage
L'application de filtres avant la recherche vectorielle permet d'abord d'extraire les documents qui satisfont aux filtres, puis de transmettre ces informations à la recherche vectorielle.
Lucene utilise les BitSets pour stocker efficacement les documents qui satisfont aux conditions du filtre. La recherche vectorielle parcourt ensuite le graphe HNSW en tenant compte des documents qui satisfont à la condition. Avant d'ajouter un candidat aux résultats, il vérifie qu'il est contenu dans le BitSet des documents valides.
Cependant, le candidat doit être exploré et comparé à la requête, même s'il ne s'agit pas d'un document valide. L'efficacité de HNSW repose sur la connexion entre les vecteurs du graphe : si nous cessons d'explorer un candidat, cela signifie que nous risquons d'ignorer également ses voisins.
Imaginez que vous conduisiez pour vous rendre à une station-service. Si vous écartez les routes qui ne comportent pas de station-service, il est peu probable que vous arriviez à destination. Les autres routes ne sont peut-être pas celles dont vous avez besoin, mais elles vous relient à votre destination. Idem pour les vecteurs sur un graphique HNSW !
Il s'ensuit que l'application d'un préfiltrage est moins performante que la non-application de filtres. Nous devons effectuer le travail sur tous les vecteurs que nous visitons dans notre recherche, et nous devons rejeter ceux qui ne correspondent pas au filtre. Nous travaillons davantage et prenons plus de temps pour obtenir nos meilleurs résultats.
Voici un exemple de préfiltrage dans le DSL de requête Elasticsearch. Vérifiez que la clause de filtrage fait désormais partie de la section knn :
Le préfiltrage est disponible à la fois pour la recherche knn et la requête knn:
Optimisation du préfiltrage
Il existe quelques optimisations que nous pouvons appliquer pour garantir la performance du préfiltrage.
Nous pouvons passer à la recherche exacte si le filtre est très restrictif. Lorsqu'il y a peu de vecteurs à comparer, il est plus rapide d'effectuer une recherche exacte sur les quelques documents qui satisfont le filtre.
Il s'agit d'une optimisation appliquée automatiquement dans Lucene et Elasticsearch.
Une autre méthode d'optimisation consiste à ignorer les vecteurs qui ne satisfont pas au filtre. Au lieu de cela, cette méthode vérifie les voisins des vecteurs filtrés qui passent le filtre. Cette approche réduit effectivement le nombre de comparaisons puisque les vecteurs filtrés ne sont pas pris en compte, et continue d'explorer les vecteurs connectés au chemin actuel.
Cet algorithme est ACORN-1, et le processus est décrit en détail dans ce billet de blog.
Filtrage à l'aide de la sécurité au niveau du document
Document Level Security (DLS) est une fonctionnalité d'Elasticsearch qui spécifie les documents que les rôles d'utilisateurs peuvent récupérer.
La DLS est réalisée à l'aide de requêtes. Une requête peut être associée aux index pour un rôle, ce qui limite effectivement les documents qu'un utilisateur appartenant à ce rôle peut extraire des index.
L'interrogation sur le rôle est utilisée comme filtre pour extraire les documents qui y correspondent et qui sont mis en cache sous la forme d'un ensemble de bits. Ce BitSet est ensuite utilisé pour envelopper le lecteur Lucene sous-jacent, de sorte que seuls les documents renvoyés par la requête sont considérés comme vivants, c'est-à-direqu'ils existent dans l'index et n'ont pas été supprimés.
Étant donné que les documents sont extraits du lecteur pour effectuer la requête knn, seuls les documents disponibles pour l'utilisateur seront pris en compte. S'il existe un préfiltre, les documents DLS y seront ajoutés.
Cela signifie que le filtrage DLS fonctionne comme un préfiltre pour la recherche vectorielle approximative, avec les mêmes implications en termes de performances et d'optimisations.
Le DLS avec recherche exacte présente les mêmes avantages que l'application de n'importe quel filtre - moins il y a de documents extraits du DLS, plus la recherche exacte est performante. Tenez également compte du nombre de documents renvoyés par le DLS - si les rôles du DLS sont très restrictifs, vous pouvez envisager d'utiliser la recherche exacte au lieu de la recherche approximative.
Analyse comparative
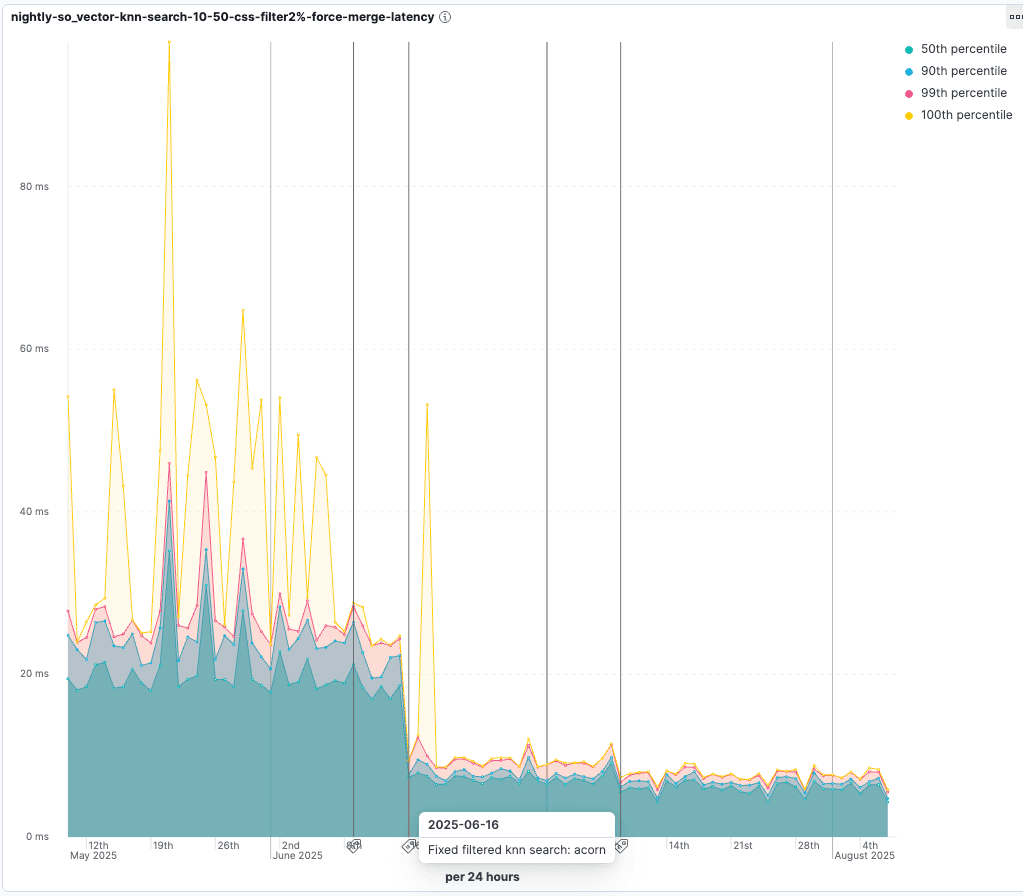
Chez Elasticsearch, nous voulons nous assurer que le filtrage de la recherche vectorielle est efficace. Nous disposons d'un benchmark spécifique pour le filtrage vectoriel qui effectue des recherches vectorielles approximatives avec différents filtrages afin de s'assurer que la recherche vectorielle continue à récupérer des résultats pertinents aussi rapidement que possible.
Vérifiez les améliorations apportées lors de l'introduction d'ACORN-1. Pour les tests où seuls 2% des vecteurs passent le filtre, le temps de latence des requêtes est réduit à 55% de la durée initiale :
Conclusion
Le filtrage fait partie intégrante de la recherche. S'assurer que le filtrage est performant dans la recherche vectorielle, et comprendre les compromis et les optimisations, c'est ce qui fait l'efficacité et la précision d'une recherche.
Le filtrage a un impact sur les performances de la recherche vectorielle :
- La recherche exacte est plus rapide lorsque l'on utilise le filtrage. Vous pouvez envisager d'utiliser la recherche exacte au lieu de la recherche approximative si votre filtrage est suffisamment restrictif. Il s'agit d'une optimisation automatique dans Elasticsearch.
- La recherche approximative est plus lente lorsque l'on utilise le préfiltrage. Le préfiltrage nous permet d'obtenir les k premiers résultats correspondant au filtre, au prix d'une recherche plus lente.
- Le post-filtrage ne permet pas nécessairement de retrouver les k premiers résultats, car ils peuvent être filtrés par le filtre lorsqu'il est appliqué.
Bon filtrage !
Pour aller plus loin

23 avril 2026
Comment nous avons construit Elasticsearch simdvec pour faire de la recherche vectorielle l'une des plus rapides au monde
Comment nous avons conçu Elasticsearch simdvec, la bibliothèque de noyaux SIMD optimisée manuellement qui alimente chaque requête de recherche vectorielle dans Elasticsearch.

4 mai 2026
Comment mesurer et améliorer le rappel de recherche Elasticsearch : de 0,43 à 0,75 avec la recherche hybride
Découvrez comment mesurer et améliorer le rappel de recherche dans Elasticsearch en combinant la recherche lexicale BM25 avec les embeddings vectoriels de Jina AI, en utilisant l’API rank_eval pour valider l’amélioration avec des données chiffrées.

10 avril 2026
Clustering de documents non supervisé avec Elasticsearch + Jina embeddings
Une approche pratique et reproductible pour le clustering non supervisé de documents avec Elasticsearch et les embeddings Jina.

2 avril 2026
Quand les TSDS rencontrent l'ILM : Concevoir des flux de données temporelles qui ne rejettent pas les données en retard
Comment les limites temporelles des TSDS interagissent avec les phases de l'ILM ; et comment concevoir des politiques qui tolèrent les métriques arrivant en retard.

1 avril 2026
LINQ to Elasticsearch ES|QL : écrire en C#, interroger Elasticsearch
Découverte du nouveau fournisseur LINQ to Elasticsearch ES|QL dans le client Elasticsearch .NET, qui vous permet d'écrire du code C# qui est automatiquement converti en requêtes ES|QL.