Avez-vous déjà voulu rechercher votre album photo par signification ? Essayez des requêtes telles que "montrez-moi mes photos où je porte une veste bleue et suis assis sur un banc", "montrez-moi des photos du mont Everest" ou "saké et sushi". Prenez une tasse de café (ou votre boisson préférée) et poursuivez votre lecture. Dans ce blog, nous vous montrons comment créer une application de recherche hybride multimodale. Multimodale signifie que l'application peut comprendre et rechercher différents types d'entrées - texte, images et audio - et pas seulement des mots. Hybride signifie qu'il combine des techniques telles que la correspondance de mots-clés, la recherche vectorielle kNN et la géolocalisation pour fournir des résultats plus précis.

Pour ce faire, nous utilisons le logiciel SigLIP-2 de Google pour générer des encastrements vectoriels pour les images et le texte, et les stocker dans la base de données vectorielles Elasticsearch. Au moment de la requête, nous convertissons l'entrée de la recherche, texte ou image, en encastrements et exécutons des recherches vectorielles kNN rapides pour extraire les résultats. Cette configuration permet une recherche efficace de texte à image et d'image à image. Une interface utilisateur Streamlit donne vie à ce projet en nous fournissant un frontend qui nous permet non seulement d'effectuer une recherche textuelle pour trouver et afficher les photos correspondantes de l'album, mais aussi d'identifier le sommet de la montagne à partir de l'image téléchargée et d'afficher d'autres photos de cette montagne dans l'album photo.
Nous présentons également les mesures que nous avons prises pour améliorer la précision des recherches, ainsi que des conseils et astuces pratiques. Pour une exploration plus approfondie, nous fournissons un dépôt GitHub et un carnet de notes Colab.
Comment cela a commencé
Ce billet a été inspiré par un enfant de 10 ans qui m'a demandé de lui montrer toutes les photos du mont Ama Dablam prises lors de mon trek au camp de base de l'Everest. En parcourant l'album photo, on m'a également demandé d'identifier plusieurs autres pics montagneux, dont certains que je n'arrivais pas à nommer.
Cela m'a donné l'idée d'un projet amusant de vision par ordinateur. Ce que nous voulions réaliser :
- trouver des images d'un sommet de montagne par son nom
- deviner le nom du sommet d'une montagne à partir d'une image et trouver des sommets similaires dans l'album photo
- faire fonctionner les requêtes conceptuelles(personne, rivière, drapeaux de prière, etc.)

Mont Ama Dablam
Assembler l'équipe de rêve : SigLIP-2, Elasticsearch & Streamlit
Il est rapidement apparu que pour que cela fonctionne, nous devions transformer à la fois le texte ("Ama Dablam") et les images (photos de mon album) en vecteurs pouvant être comparés de manière significative, c'est-à-dire dans le même espace vectoriel. Une fois cette étape franchie, la recherche se résume à "trouver les voisins les plus proches".

SigLIP-2, récemment publié par Google, s'inscrit parfaitement dans ce cadre. Il peut générer des enchâssements sans formation spécifique à une tâche (un réglage zéro) et fonctionne bien pour notre cas d'utilisation : des photos non étiquetées et des pics avec des noms et des langues différents. Parce qu'il est formé à la correspondance texte ↔ image, une photo de montagne prise lors d'une randonnée et un court texte d'incitation se retrouvent proches en tant qu'ancrages, même lorsque la langue ou l'orthographe de la requête varient.
SigLIP-2 offre un excellent rapport qualité-vitesse, prend en charge plusieurs résolutions d'entrée et fonctionne à la fois avec le CPU et le GPU. SigLIP-2 est conçu pour être plus résistant aux photos prises en extérieur que les modèles précédents tels que le CLIP original. Lors de nos tests, SigLIP-2 a toujours produit des résultats fiables. Il est également très bien supporté, ce qui en fait un choix évident pour ce projet.
Ensuite, nous avons besoin d'une base de données vectorielle pour stocker les encastrements et effectuer des recherches puissantes. Il devrait permettre non seulement la recherche par cosinus kNN sur des images intégrées, mais aussi l'application de filtres de géographie et de texte en une seule requête. Elasticsearch convient bien ici : il gère très bien les vecteurs (HNSW kNN sur les champs dense_vector), prend en charge la recherche hybride qui combine le texte, les vecteurs et les requêtes géographiques, et propose d'emblée le filtrage et le tri. Il est également évolutif horizontalement, ce qui permet de passer facilement d'une poignée de photos à des milliers. Le client officiel Elasticsearch Python simplifie la plomberie et s'intègre parfaitement au projet. Enfin, nous avons besoin d'un frontal léger où nous pouvons saisir des requêtes de recherche et afficher les résultats. Pour une démonstration rapide, basée sur Python, Streamlit est une solution idéale. Il fournit les primitives dont nous avons besoin - le téléchargement de fichiers, une grille d'images réactive et des menus déroulants pour le tri et la géolocalisation. Il est facile de le cloner et de l'exécuter localement, et il fonctionne également dans un cahier Colab.
Implémentation
Conception et stratégie d'indexation Elasticsearch
Nous utiliserons deux indices pour ce projet : peaks_catalog et photos.
Index du catalogue des pics
Cet index constitue un catalogue compact des principaux sommets visibles pendant le trek du camp de base de l'Everest. Chaque document de cet index correspond à un sommet de montagne, comme le mont Everest. Pour chaque document relatif à un pic montagneux, nous stockons les noms/alias, les coordonnées facultatives de latitude et de longitude, ainsi qu'un vecteur prototype unique construit en mélangeant les messages-guides SigLIP-2 (+ images de référence facultatives).
Mappage de l'index :
| Champ d'application | Type | Exemple | Objectif/Notes | Vecteur/Indexation |
|---|---|---|---|---|
| id | mot-clé | ama-dablam | Slug/id stable | - |
| noms | texte + sous-champ mot-clé | ["Ama Dablam","Amadablam"] | Alias / noms multilingues ; names.raw pour les filtres exacts | - |
| latlon | geo_point | {"lat":27.8617,"lon":86.8614} | Coordonnées GPS du pic sous la forme d'une combinaison latitude/longitude (facultatif) | - |
| elev_m | entier | 6812 | Élévation (facultatif) | - |
| texte_embed | dense_vector | 768 | Prototype mixte (invites et éventuellement 1 à 3 images de référence) pour ce pic | index:true, similarité :"cosine", index_options :{type:"hnsw", m:16, ef_construction:128} |
Cet index est principalement utilisé pour des recherches d'image à image, telles que l'identification de sommets de montagne à partir d'images. Nous utilisons également cet index pour améliorer les résultats de recherche texte-image.
En résumé, le site peaks_catalog transforme la question "Quelle est cette montagne ?" en un problème ciblé de plus proche voisin, séparant efficacement la compréhension conceptuelle des complexités des données d'image.
Stratégie d'indexation pour l'index peaks_catalog : Nous commençons par créer une liste des sommets les plus importants visibles lors de la randonnée EBC. Pour chaque pic, nous stockons sa position géographique, son nom, ses synonymes et son altitude dans un fichier yaml. L'étape suivante consiste à générer l'intégration pour chaque pic et à la stocker dans le champ text_embed. Afin de générer des encastrements robustes, nous utilisons la technique suivante :
- Créer un prototype de texte en utilisant :
- noms des sommets
- l'ensemble des invites (utilisation de plusieurs invites différentes pour tenter de répondre à la même question), par exemple :
- "photo naturelle du sommet de la montagne {name} dans l'Himalaya, Népal".
- "{name} sommet emblématique de la région du Khumbu, paysage alpin"
- "{name} sommet montagneux, neige, ligne de crête rocheuse"
- anti-concept optionnel (indiquant à SigLIP-2 ce qu'il ne faut pas faire) : soustraire un petit vecteur pour "peinture, illustration, affiche, carte, logo" afin de privilégier les photos réelles.
- Créer éventuellement un prototype d'image si des images de référence du pic sont fournies.
Nous fusionnons ensuite les prototypes de texte et d'image pour générer l'intégration finale. Enfin, le document est indexé avec tous les champs obligatoires :
Exemple de document provenant de l'index peaks_catalog:

Index des photos
Cet index primaire contient des informations détaillées sur toutes les photos de l'album. Chaque document représente une seule photo, contenant les informations suivantes :
- Chemin d'accès relatif à la photo dans l'album photo. Cette option permet de visualiser l'image correspondante ou de charger l'image dans l'interface de recherche.
- Informations sur le GPS et l'heure de la photo.
- Vecteur dense pour le codage d'images généré par SigLIP-2.
predicted_peaksqui nous permet de filtrer par nom de pic.
Cartographie de l'index
| Champ d'application | Type | Exemple | Objectif/Notes | Vecteur / Indexation |
|---|---|---|---|---|
| chemin | mot-clé | data/images/IMG_1234.HEIC | Comment l'interface utilisateur ouvre la vignette/l'image complète | - |
| clip_image | dense_vector | 768 | Intégration d'images SigLIP-2 | index:true, similarité :"cosine", index_options :{type:"hnsw", m:16, ef_construction:128} |
| pics_prédits | mot-clé | ["ama-dablam","pumori"] | Les suppositions Top-K au moment de l'indexation (filtre / facette UX bon marché) | - |
| GPS | geo_point | {"lat":27.96,"lon":86.83} | permet d'utiliser des filtres géographiques | - |
| heure de la prise de vue | date | 2023-10-18T09:41:00Z | temps de capture : tri/filtre | - |
Stratégie d'indexation pour l'index des photos : Pour chaque photo de l'album, nous procédons comme suit :
Extraire les informations sur les images shot_time et gps à partir des métadonnées de l'image.
- Intégration d'images SigLIP-2: passage de l'image dans le modèle et normalisation L2 du vecteur. Stocker l'intégration dans le champ
clip_image. - Prédire les pics et les stocker dans le champ
predicted_peaks. Pour ce faire, nous prenons d'abord le vecteur image de la photo généré à l'étape précédente, puis nous effectuons une recherche rapide par kNN sur le champ text_embed de l'indexpeaks_catalog. Nous conservons les 3-4 premiers sommets et ignorons les autres. - Nous calculons le champ
_iden effectuant un hachage du nom de l'image et du chemin d'accès. Cela permet de s'assurer qu'il n'y a pas de doublons après plusieurs exécutions.
Une fois que nous avons déterminé tous les champs de la photo, les documents photo sont indexés par lots à l'aide de l'indexation en bloc :
Exemple de document de l'index des photos :
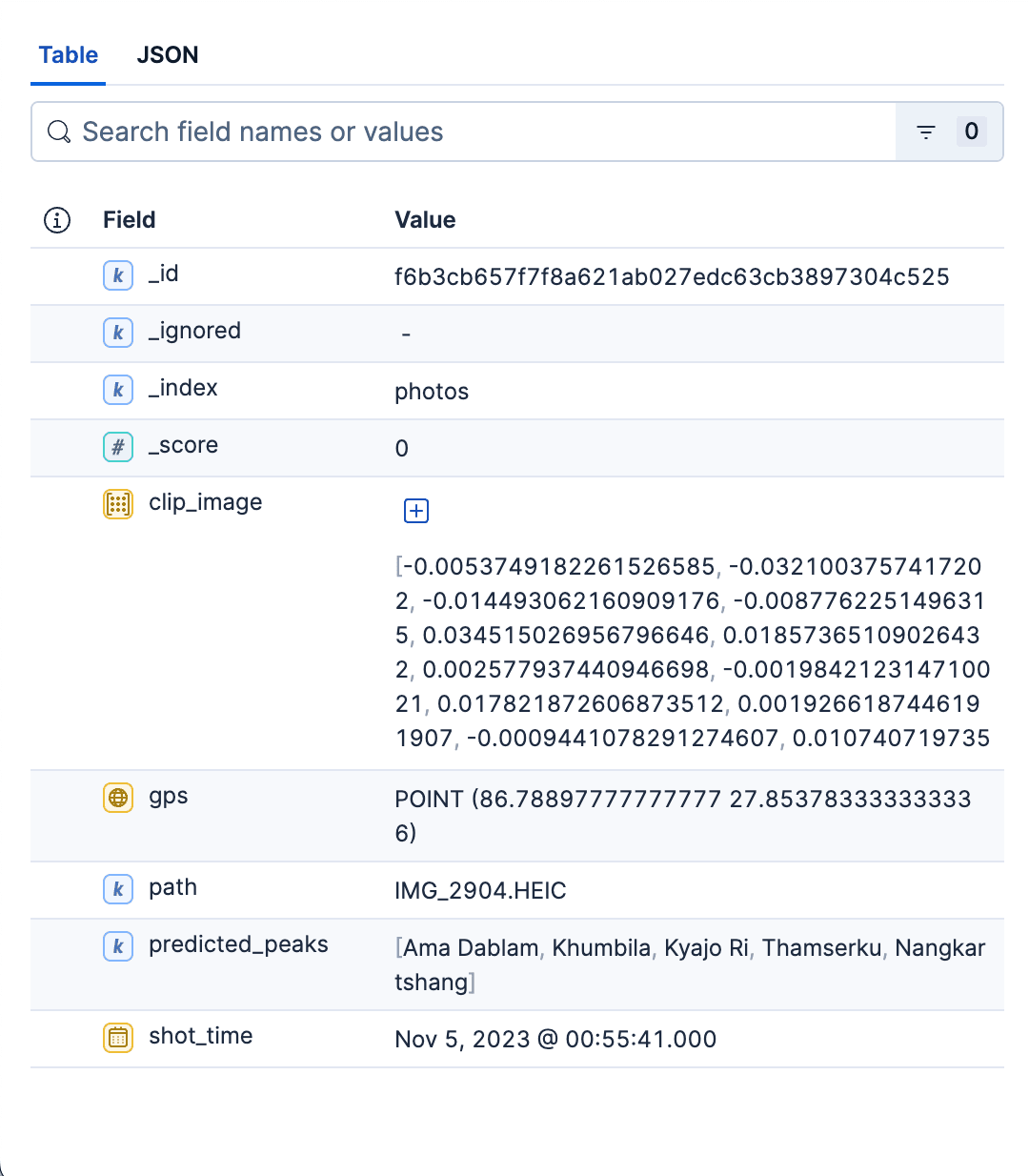
En résumé, l'index des photos est le magasin rapide, filtrable et prêt pour le kNN de toutes les photos de l'album. Sa cartographie est volontairement minimale - juste assez de structure pour permettre une recherche rapide, un affichage propre et une répartition des résultats dans l'espace et dans le temps. Cet index sert aux deux types de recherche. Le script Python permettant de créer les deux indices est disponible ici.
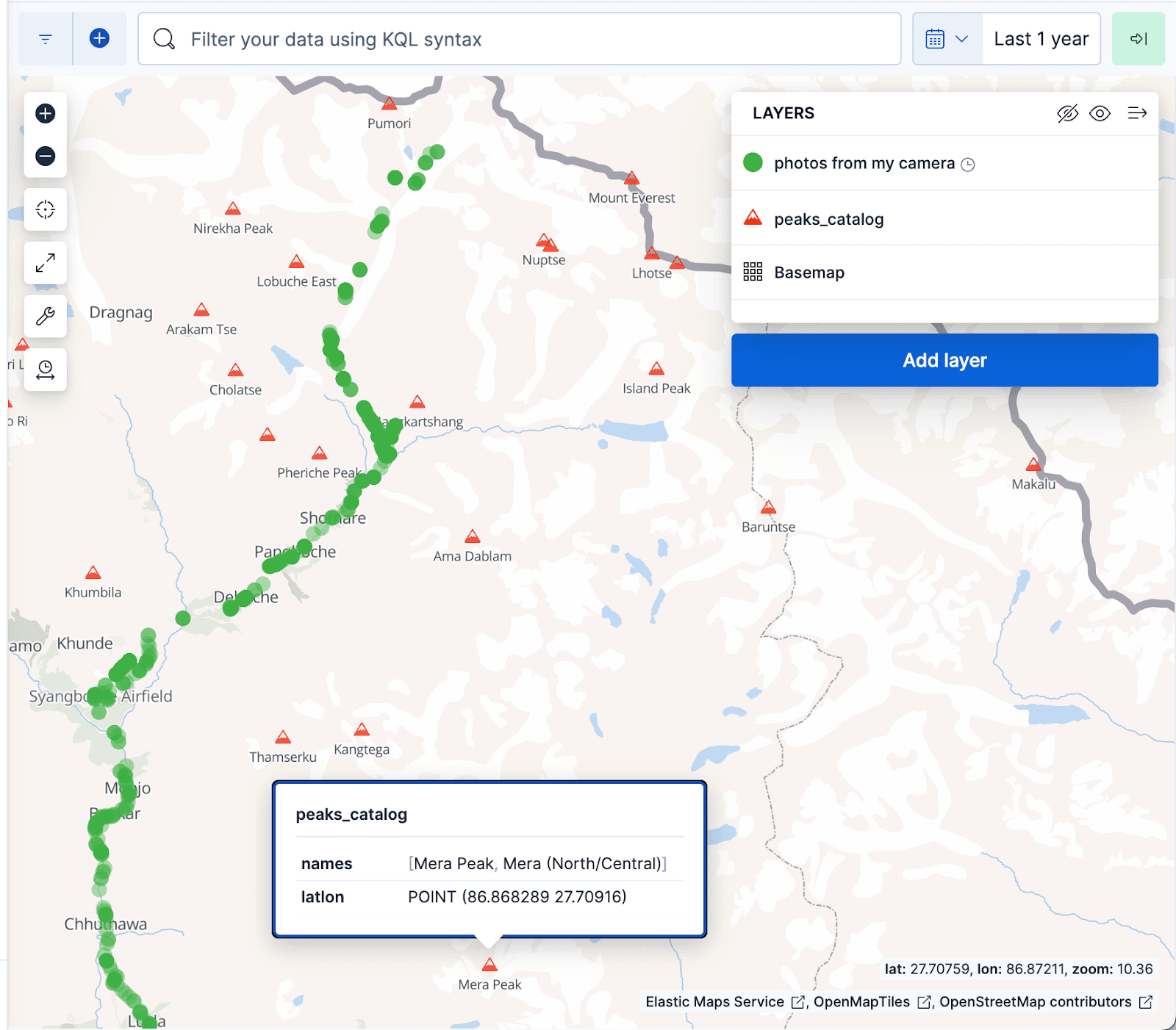
La visualisation des cartes Kibana ci-dessous affiche les documents de l'album photo sous forme de points verts et les pics montagneux de l'index peaks_catalog sous forme de triangles rouges, les points verts correspondant bien au sentier de randonnée du camp de base de l'Everest.
Cas d'utilisation de la recherche
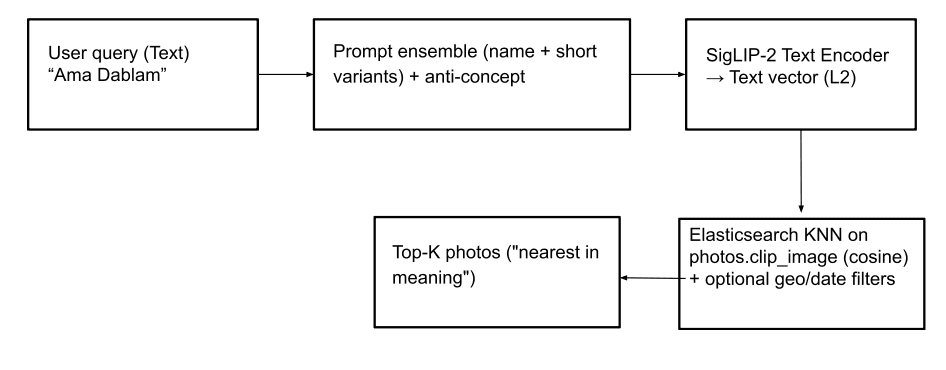
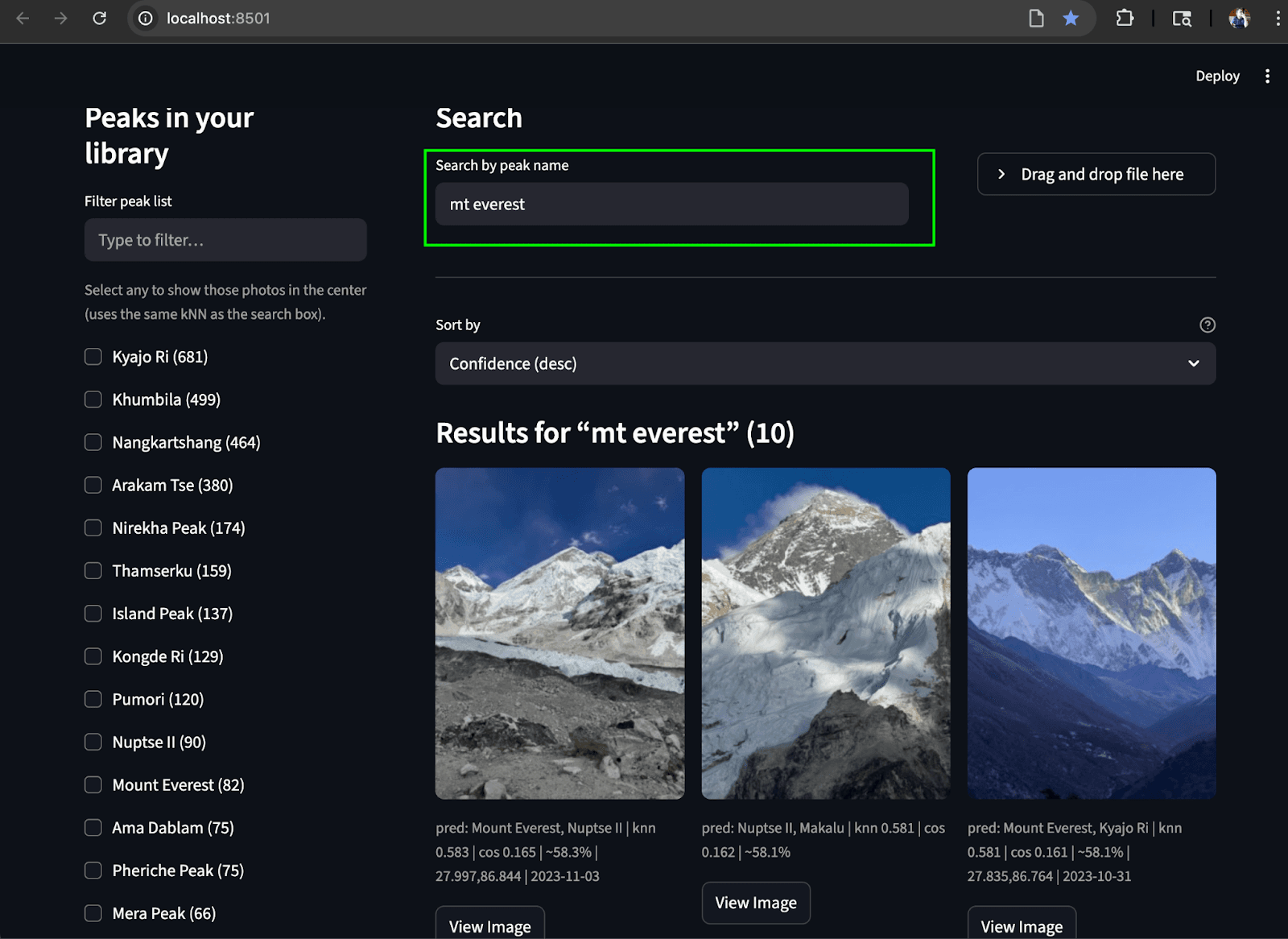
Recherche par nom (texte-image) : Cette fonction permet aux utilisateurs de localiser des photos de sommets de montagne (et même des concepts abstraits comme les "drapeaux de prière") à l'aide de requêtes textuelles. Pour ce faire, l'entrée texte est convertie en un vecteur texte à l'aide de SigLIP-2. Pour la génération de vecteurs de texte robustes, nous utilisons la même stratégie que pour la création d'enchâssements de texte dans l'index peaks_catalog: combinaison de l' entrée texte avec un petit ensemble d'invites, soustraction d'un vecteur anti-concept mineur et application de la normalisation L2 pour produire le vecteur d'interrogation final. Une requête kNN est ensuite exécutée sur le champ photos.clip_image pour récupérer les pics les plus proches, sur la base de la similarité cosinusoïdale pour trouver les images les plus proches. Il est possible de rendre les résultats de la recherche plus pertinents en appliquant des filtres géographiques et de date, et/ou un filtre de terme photos.predicted_peaks dans le cadre de la requête (voir les exemples de requêtes ci-dessous). Cela permet d'exclure les sommets qui ressemblent à d'autres et qui ne sont pas visibles lors de la randonnée.
Requête Elasticsearch avec filtre géographique :
Recherche par image (image à image) : Cette fonction permet d'identifier une montagne sur une photo et de trouver d'autres images de cette même montagne dans l'album photo. Lorsqu'une image est téléchargée, elle est traitée par l'encodeur d'images SigLIP-2 pour générer un vecteur d'image. Une recherche kNN est ensuite effectuée sur le champ peaks_catalog.text_embed pour identifier les noms de pics qui correspondent le mieux. Ensuite, un vecteur de texte est généré à partir des noms de pics correspondants, et une autre recherche kNN est effectuée sur l'index des photos pour localiser les images correspondantes.

Requête Elasticsearch :
Étape 1 : Trouver les noms de pics correspondants
Étape 2 : Effectuer une recherche dans l'index photos pour trouver les images correspondantes (même requête que dans le cas d'utilisation de la recherche texte-image) :
Streamlit UI
Pour réunir le tout, nous avons créé une interface utilisateur Streamlit simple qui nous permet de réaliser les deux cas d'utilisation de la recherche. La barre de gauche affiche une liste déroulante de pics (agrégés à partir de photos.predicted_peaks) avec des cases à cocher et un filtre mini-carte/géo. En haut, il y a un champ de recherche par nom et un bouton d'identification à partir du téléchargement d'une photo. Le volet central présente une grille de vignettes réactive indiquant les scores kNN, les badges de pic prédit et les heures de capture. Chaque image comporte un bouton " Voir l'image" qui permet d'obtenir un aperçu en pleine résolution.
Recherchez en téléchargeant une image : Nous prédisons le pic et trouvons les pics correspondants dans l'album photo.
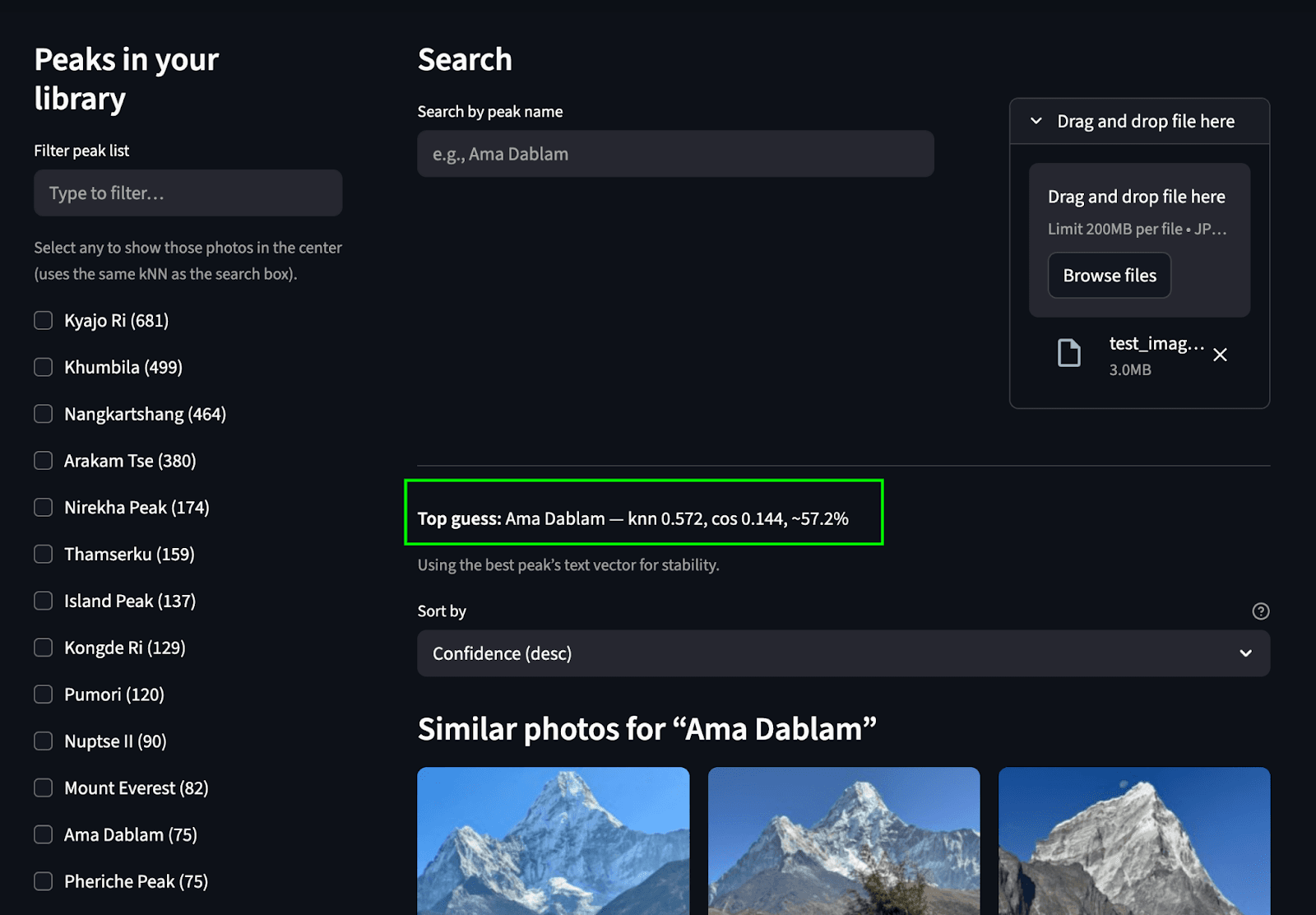
Recherche par texte: Trouver les sommets correspondants dans l'album à partir d'un texte.
Conclusion
Tout a commencé par la possibilité de voir les photos del'Ama Dablam. s'est transformé en un petit système de recherche multimodale fonctionnel. Nous avons pris des photos brutes de trek, les avons transformées en encastrements SigLIP-2 et avons utilisé Elasticsearch pour effectuer un kNN rapide sur les vecteurs, ainsi que des filtres géo/temporels simples pour faire remonter à la surface les bonnes images en fonction de leur signification. En cours de route, nous avons séparé les préoccupations en deux indices : un minuscule peaks_catalog de prototypes mélangés (pour l'identification) et un index évolutif photos de vecteurs d'images et d'EXIF (pour la recherche). Il est pratique, reproductible et facile à étendre.
Si vous souhaitez l'accorder, vous pouvez jouer avec quelques paramètres :
- Paramètres de temps de recherche :
k(nombre de voisins à récupérer) etnum_candidates(étendue de la recherche avant la notation finale). Ces paramètres sont abordés dans le blog ici. - Paramètres de temps d'indexation :
m(connectivité du graphique) etef_construction(précision du temps de construction par rapport à la mémoire). Pour les requêtes, expérimentez avecef_searchégalement - une valeur plus élevée signifie généralement un meilleur rappel avec un certain compromis en termes de latence. Consultez ce blog pour plus de détails sur ces paramètres.
A l'avenir, des modèles natifs/rerankers pour la recherche multimodale et multilingue seront bientôt intégrés à l'écosystème Elastic, ce qui devrait rendre la recherche d'images/de textes et le classement hybride encore plus performants. ir.elastic.co+1
Si vous souhaitez essayer vous-même :
- GitHub repo : https://github.com/navneet83/multimodal-mountain-peak-search
- Colab quickstart : https://github.com/navneet83/multimodal-mountain-peak-search/blob/main/notebooks/multimodal_mountain_peak_search.ipynb
Notre voyage s'achève donc et il est temps de prendre l'avion du retour. J'espère que cela vous a été utile et si vous le cassez (ou l'améliorez), j'aimerais savoir ce que vous avez changé.

Pour aller plus loin

Décrivez, ne dessinez pas : tableaux de bord Kibana IA natifs via MCP et ES|QL
Du prompt au tableau de bord. Apprenez à créer des tableaux de bord Kibana en langage naturel grâce à example-mcp-dashbuilder : une application MCP open source qui écrit des requêtes ES|QL, crée des graphiques interactifs et exporte des tableaux de bord entièrement fonctionnels directement vers Kibana.

23 avril 2026
Comment nous avons construit Elasticsearch simdvec pour faire de la recherche vectorielle l'une des plus rapides au monde
Comment nous avons conçu Elasticsearch simdvec, la bibliothèque de noyaux SIMD optimisée manuellement qui alimente chaque requête de recherche vectorielle dans Elasticsearch.

4 mai 2026
Comment mesurer et améliorer le rappel de recherche Elasticsearch : de 0,43 à 0,75 avec la recherche hybride
Découvrez comment mesurer et améliorer le rappel de recherche dans Elasticsearch en combinant la recherche lexicale BM25 avec les embeddings vectoriels de Jina AI, en utilisant l’API rank_eval pour valider l’amélioration avec des données chiffrées.

10 avril 2026
Clustering de documents non supervisé avec Elasticsearch + Jina embeddings
Une approche pratique et reproductible pour le clustering non supervisé de documents avec Elasticsearch et les embeddings Jina.

2 avril 2026
Quand les TSDS rencontrent l'ILM : Concevoir des flux de données temporelles qui ne rejettent pas les données en retard
Comment les limites temporelles des TSDS interagissent avec les phases de l'ILM ; et comment concevoir des politiques qui tolèrent les métriques arrivant en retard.