OpenAI a récemment annoncé la fonctionnalité connecteurs personnalisés pour ChatGPT sur les plans Pro/Business/Entreprise et Edu. En plus des connecteurs prêts à l'emploi pour accéder aux données sur Gmail, GitHub, Dropbox, etc., il est possible de créer des connecteurs personnalisés en utilisant des serveurs MCP.
Les connecteurs personnalisés vous donnent la possibilité de combiner vos connecteurs ChatGPT existants avec des sources de données supplémentaires comme Elasticsearch pour obtenir des réponses complètes.
Dans cet article, nous allons créer un serveur MCP qui connecte ChatGPT à un index Elasticsearch contenant des informations sur les issues GitHub internes et les requêtes pull. Cela permet de répondre aux requêtes en langage naturel en utilisant vos données Elasticsearch.
Nous déploierons le serveur MCP en utilisant FastMCP sur Google Colab avec ngrok pour obtenir une URL publique à laquelle ChatGPT peut se connecter, éliminant ainsi le besoin d'une configuration complexe de l'infrastructure.
Pour un aperçu complet de MCP et de son écosystème, reportez-vous à la section État actuel du MCP.
Prérequis
Avant de commencer, vous aurez besoin des éléments suivants :
- Cluster Elasticsearch (8.X ou supérieur)
- Clé API Elasticsearch avec accès en lecture à votre index
- Compte Google (pour Google Colab)
- Compte ngrok (fonctionne avec le niveau gratuit)
- Compte ChatGPT avec un forfait Pro/Entreprise/Business ou Edu
Comprendre les exigences du connecteur ChatGPT MCP
Les connecteurs ChatGPT MCP nécessitent l'implémentation de deux outils : search et fetch. Pour plus de détails, consultez OpenAI Docs.
Outil de recherche
Renvoie une liste de résultats pertinents depuis votre index Elasticsearch en fonction d'une requête utilisateur.
Ce qu'il reçoit :
- Une chaîne unique contenant la requête en langage naturel de l'utilisateur.
- Exemple : "Recherchez les issues liées à la migration d'Elasticsearch."
Ce qu'il renvoie :
- Un objet avec une clé
resultcontenant un tableau d'objets de résultats. Chaque résultat inclut :id- Identifiant de document uniquetitle- Titre de l'issue ou de la PRurl- Lien vers l'issue/la PR
Dans notre implémentation :
Outil de récupération
Récupère le contenu complet d'un document spécifique.
Ce qu'il reçoit :
- Chaîne unique contenant l'ID du document Elasticsearch extrait du résultat de la recherche
- Exemple : "Donnez-moi les détails de la PR-578."
Ce qu'il renvoie :
- Objet de document complet contenant :
id- Identifiant de document uniquetitle- Titre de l'issue ou de la PRtext- Description complète du problème/PR et détailsurl- Lien vers l'issue/la PRtype- Type de document (issue, pull_request)status- Statut actuel (ouvert, en cours, résolu)priority- Niveau de priorité (faible, moyen, élevé, critique)assignee- Personne en charge de l'issue/la PRcreated_date- Date de créationresolved_date- Date de résolution (le cas échéant)labels- Balises associées au documentrelated_pr- ID de la requête pull associée
Remarque : Cet exemple utilise une structure plate où tous les champs se trouvent au niveau racine. Les exigences d'OpenAI sont flexibles et prennent également en charge les objets de métadonnées imbriqués.
Issues GitHub et ensemble de données de PR
Pour ce tutoriel, nous allons utiliser un ensemble de données interne de GitHub contenant des issues et des requêtes pull. Ceci représente un scénario dans lequel vous souhaitez interroger des données privées et internes via ChatGPT.
L'ensemble de données est accessible ici. Et nous mettrons à jour l'index des données à l'aide de l'API Bulk.
Cet ensemble de données comprend :
- Issues avec description, état, niveau de priorité et personnes en charge
- Requêtes pull avec modifications de code, révisions et informations de déploiement
- Relations entre les issues et les PR (p. ex., la PR-578 corrige l'ISSUE-1889)
- Étiquettes, dates et autres métadonnées
Mappings de l'index
L'index utilise les mappings suivants pour prendre en charge la recherche hybride avec ELSER. Le champ text_semantic est utilisé pour la recherche sémantique, tandis que les autres champs permettent la recherche par mot-clé.
Créer le serveur MCP
Notre serveur MCP implémente deux outils conformes aux spécifications d'OpenAI qui utilisent la recherche hybride pour combiner la sémantique et la correspondance de texte pour de meilleurs résultats.
Outil de recherche
Utilise la recherche hybride avec RRF (fusion des rangs réciproques) qui combine la recherche sémantique avec la correspondance de texte :
Points clés :
- Recherche hybride avec RRF : combine la recherche sémantique (ELSER) et la recherche de texte (BM25) pour de meilleurs résultats.
- Requête à correspondance multiple : Recherches sur plusieurs champs avec boosting (title^3, text^2, assignee^2). Le symbole caret (^) multiplie les scores de pertinence, en privilégiant les correspondances dans les titres plutôt que dans le contenu.
- Fuzzy matching (correspondance approximative) :
fuzziness: AUTOgère les fautes de frappe et d'orthographe en autorisant les correspondances approximatives. - Ajustement des paramètres RRF :
rank_window_size: 50- Spécifie le nombre de résultats principaux de chaque récupérateur (sémantique et texte) pris en compte avant la fusion.rank_constant: 60- Cette valeur détermine l'influence des documents dans chaque ensemble de résultats sur le classement final.
- Ne renvoie que les champs obligatoires :
id,title,urlconformément à la spécification d'OpenAI, et évite d'exposer inutilement des champs supplémentaires.
Outil de récupération
Récupère les détails du document par ID de document, s'il existe :
Points clés :
- Recherche par champ d'ID de document : utilise une requête de terme sur le champ personnalisé
id - Renvoie le document complet : inclut le champ complet
textavec tout le contenu - Structure plate : tous les champs au niveau racine, correspondant à la structure de document d'Elasticsearch.
Déployer sur Google Colab
Nous utiliserons Google Colab pour exécuter notre serveur MCP et ngrok pour l'exposer publiquement afin que ChatGPT puisse s'y connecter.
Étape 1 : Ouvrir le notebook Google Colab
Accédez à notre notebook préconfiguré Elasticsearch MCP pour ChatGPT.
Étape 2 : Configurer vos identifiants
Vous aurez besoin de trois informations :
- URL Elasticsearch : l'URL de votre cluster Elasticsearch.
- Clé API Elasticsearch : clé API avec accès en lecture à votre index.
- Jeton d'authentification ngrok : jeton gratuit fourni par ngrok. Nous utiliserons ngrok pour exposer l'URL du MCP à l'Internet afin que ChatGPT puisse s'y connecter.
Obtenir votre token ngrok
- Créez un compte gratuit sur ngrok
- Accédez à votre tableau de bord ngrok
- Copier votre jeton d'authentification
Ajouter des secrets à Google Colab
Dans le notebook Google Colab :
- Cliquez sur l'icône clé dans la barre latérale gauche pour ouvrir Secrets.
- Ajoutez ces trois secrets :
3. Activer l'accès aux notebooks pour chaque secret

Étape 3 : Exécuter le notebook
- Cliquez sur Runtime (Exécution) puis sur Run all (Tout exécuter) pour exécuter toutes les cellules
- Attendez que le serveur démarre (environ 30 secondes)
- Recherchez l'URL publique de ngrok dans la sortie

4. La sortie affichera quelque chose comme :

Se connecter à ChatGPT
Nous allons maintenant connecter le serveur MCP à votre compte ChatGPT.
- Ouvrez ChatGPT et accédez aux Paramètres.
- Accédez à Connectors (Connecteurs).Si vous utilisez un compte Pro, vous devez activer le mode développeur dans les connecteurs.
Si vous utilisez ChatGPT Enterprise ou Business, vous devez publier le connecteur sur votre espace de travail.
3. Cliquez sur Create (Créer).

Remarque : Dans les espaces de travail Business, Entreprise et Edu, seuls les propriétaires, les administrateurs et les utilisateurs ayant activé l'option correspondante (pour Entreprise/Edu) peuvent ajouter des connecteurs personnalisés. Les utilisateurs ayant un rôle de membre standard ne peuvent pas ajouter de connecteurs personnalisés eux-mêmes.
Une fois qu'un connecteur est ajouté et activé par un propriétaire ou un utilisateur administrateur, il devient accessible à tous les membres de l'espace de travail.
4. Saisissez les informations requises et votre URL ngrok se terminant par /sse/. Notez le "/" après "sse". Cela ne fonctionnera pas sans cet élément :
- Nom : Elasticsearch MCP
- Description : MCP personnalisé pour la recherche et la récupération d'informations GitHub internes.

5. Appuyez sur Créer pour enregistrer le MCP personnalisé.

La connexion est instantanée si votre serveur est en cours d'exécution. Aucune authentification supplémentaire n'est requise, car la clé API Elasticsearch est configurée sur votre serveur.
Tester le serveur MCP
Avant de poser des questions, vous devez sélectionner le connecteur que ChatGPT doit utiliser.

Prompt 1 : Recherchez les issues
Demandez : "Recherchez les issues liées à la migration d'Elasticsearch", puis confirmez l'appel à l'outil d'action.
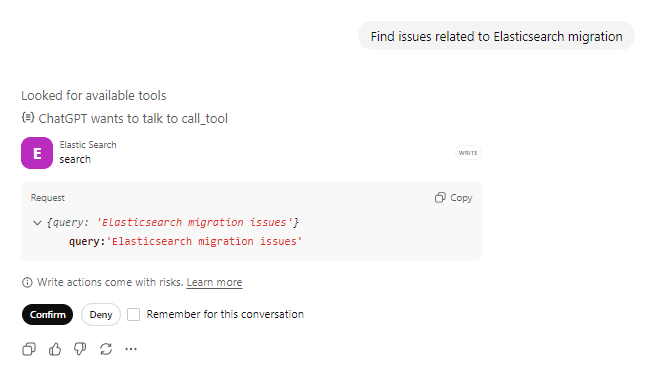
ChatGPT appellera l'outil search avec votre requête. Vous pouvez voir qu'il recherche des outils disponibles et se prépare à appeler l'outil Elasticsearch, et confirme auprès de l'utilisateur avant de prendre toute action sur l'outil.
Demande d'appel d'outil :
Réponse de l'outil :
ChatGPT traite les résultats et les présente dans un format conversationnel naturel.

En coulisses
Prompt : "Recherchez les issues liées à la migration d'Elasticsearch"
1. Appels de ChatGPT search(“Elasticsearch migration”)
2. Elasticsearch effectue une recherche hybride.
- La recherche sémantique comprend des concepts tels que "mise à niveau" et "compatibilité des versions".
- La recherche de texte trouve des correspondances exactes pour "Elasticsearch" et "migration".
- RRF combine et classe les résultats des deux approches
3. Renvoie les 10 événements les plus pertinents avec id, title, url
4. ChatGPT identifie "ISSUE-1712: migrate from Elasticsearch 7.x to 8.x" (Migrer d'Elasticsearch 7.x vers 8.x) comme résultat le plus pertinent.
Prompt 2 : Obtenez tous les détails
Demandez : "Donnez-moi les détails de l'ISSUE-1889"

ChatGPT comprend que vous souhaitez obtenir des informations détaillées sur un problème spécifique, appelle l'outil fetch et confirme auprès de l'utilisateur avant d'entreprendre des actions sur l'outil.
Demande d'appel d'outil :
Réponse de l'outil :
ChatGPT synthétise les informations et les présente clairement.


En coulisses
Prompt : "Donnez-moi les détails de l'ISSUE-1889"
- Appels ChatGPT
fetch(“ISSUE-1889”) - Elasticsearch extrait le document complet
- Retourne un document complet avec tous les champs au niveau racine
- ChatGPT synthétise les informations et répond avec les citations appropriées.
Conclusion
Dans cet article, nous avons créé un serveur MCP personnalisé qui connecte ChatGPT à Elasticsearch à l'aide d'outils MCP de recherche et de récupération dédiés, permettant de lancer des requêtes en langage naturel sur des données privées.
Ce modèle MCP fonctionne pour n'importe quel index Elasticsearch, documentation, produit, log ou toute autre donnée que vous souhaitez interroger en langage naturel.
Pour aller plus loin

4 mai 2026
Comment mesurer et améliorer le rappel de recherche Elasticsearch : de 0,43 à 0,75 avec la recherche hybride
Découvrez comment mesurer et améliorer le rappel de recherche dans Elasticsearch en combinant la recherche lexicale BM25 avec les embeddings vectoriels de Jina AI, en utilisant l’API rank_eval pour valider l’amélioration avec des données chiffrées.

8 avril 2026
Comment créer des applications d'IA agentique avec Mastra et Elasticsearch
Découvrez comment créer des applications d'IA agentiques avec Mastra et Elasticsearch à travers un exemple pratique.

25 mars 2026
L'outil shell n'est pas une solution miracle pour l'ingénierie du contexte
Découvrez quels outils de récupération de contexte existent pour l'ingénierie contextuelle, comment ils fonctionnent et leurs compromis.

23 mars 2026
Utilisation de l'API d'inférence Elasticsearch avec les modèles Hugging Face
Découvrez comment connecter Elasticsearch aux modèles Hugging Face à l'aide de points de terminaison d'inférence, et comment créer un système de recommandation de blogs multilingue avec recherche sémantique et complétion de chat.

27 mars 2026
Création d'un serveur Elasticsearch MCP avec TypeScript
Apprenez à créer un serveur MCP Elasticsearch avec TypeScript et Claude Desktop.