Introduction
Dans un monde d'utilisateurs globaux, la recherche d'informations multilingues (CLIR) est cruciale. Au lieu de limiter les recherches à une seule langue, le CLIR vous permet de trouver des informations dans n'importe quelle langue, ce qui améliore l'expérience de l'utilisateur et rationalise les opérations. Imaginez un marché mondial où les clients du commerce électronique pourraient rechercher des articles dans leur langue et où les bons résultats apparaîtraient, sans qu'il soit nécessaire de localiser les données à l'avance. Ou encore, où les chercheurs universitaires peuvent rechercher des articles dans leur langue maternelle, avec nuance et complexité, même si la source est dans une autre langue.
Les modèles d'intégration de textes multilingues nous permettent justement de le faire. Les emboîtements sont un moyen de représenter le sens d'un texte sous forme de vecteurs numériques. Ces vecteurs sont conçus de manière à ce que les textes ayant des significations similaires soient situés à proximité les uns des autres dans un espace à haute dimension. Les modèles d'intégration de textes multilingues sont spécifiquement conçus pour représenter dans un espace vectoriel similaire les mots et les phrases ayant la même signification dans différentes langues.
Les modèles tels que le logiciel libre Multilingual E5 sont formés sur des quantités massives de données textuelles, souvent à l'aide de techniques telles que l'apprentissage contrastif. Dans cette approche, le modèle apprend à distinguer les paires de textes dont le sens est similaire (paires positives) de ceux dont le sens est différent (paires négatives). Le modèle est entraîné à ajuster les vecteurs qu'il produit de manière à maximiser la similarité entre les paires positives et à minimiser la similarité entre les paires négatives. Pour les modèles multilingues, ces données d'entraînement comprennent des paires de textes dans différentes langues qui sont des traductions l'une de l'autre, ce qui permet au modèle d'apprendre un espace de représentation commun pour plusieurs langues. Les enchâssements résultants peuvent ensuite être utilisés pour diverses tâches de NLP, y compris la recherche multilingue, où la similarité entre les enchâssements de texte est utilisée pour trouver des documents pertinents quelle que soit la langue de la requête.
Avantages de la recherche vectorielle multilingue
- Nuance: La recherche vectorielle excelle à capturer le sens sémantique, allant au-delà de la correspondance des mots clés. Ceci est crucial pour les tâches qui nécessitent de comprendre le contexte et les subtilités de la langue.
- Compréhension multilingue: Permet de rechercher efficacement des informations dans plusieurs langues, même lorsque la requête et les documents utilisent un vocabulaire différent.
- Pertinence: Fournit des résultats plus pertinents en se concentrant sur la similarité conceptuelle entre les requêtes et les documents.
"Prenons l'exemple d'un chercheur universitaire qui étudie l'impact des médias sociaux sur le discours politique" dans différents pays. Grâce à la recherche vectorielle, ils peuvent saisir des requêtes telles que "l'impatto dei social media sul discorso politico" (italien) ou "ảnh hưởng của mạng xã hội đối với diễn ngôn chính trị" (vietnamien) et trouver des articles pertinents en anglais, espagnol ou toute autre langue indexée. En effet, la recherche vectorielle identifie les articles qui traitent du concept de l'influence des médias sociaux sur la politique, et pas seulement ceux qui contiennent les mots clés exacts. Cela améliore considérablement l'étendue et la profondeur de leurs recherches.
Se lancer
Voici comment configurer CLIR en utilisant Elasticsearch - avec le modèle E5 qui est fourni dans la boîte. Nous utiliserons l'ensemble de données multilingues COCO, qui contient des légendes d'images dans plusieurs langues, pour nous aider à visualiser deux types de recherches :
- Requêtes et termes de recherche dans d'autres langues sur un ensemble de données en anglais, et
- Requêtes en plusieurs langues à partir d'un ensemble de données contenant des documents en plusieurs langues.
Ensuite, nous exploiterons la puissance de la recherche hybride et du reranking pour améliorer encore les résultats de la recherche.
Produits requis
- Python 3.6+
- Elasticsearch 8+
- Client Elasticsearch Python : pip install elasticsearch
Ensemble de données
L'ensemble de données COCO est un ensemble de données de sous-titrage à grande échelle. Chaque image de l'ensemble de données est légendée dans plusieurs langues différentes, avec plusieurs traductions disponibles par langue. À des fins de démonstration, nous indexerons chaque traduction comme un document individuel, avec la première traduction anglaise disponible à titre de référence.
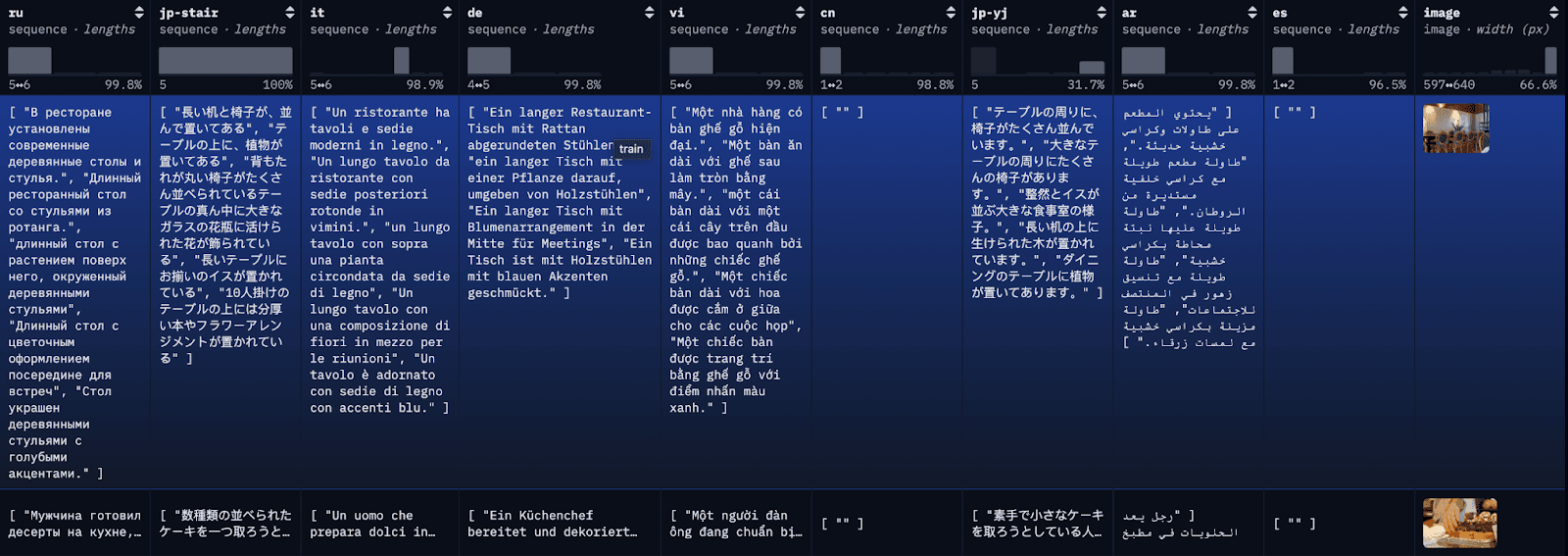
Étape 1 : télécharger l'ensemble de données multilingues COCO
Pour simplifier le blog et faciliter le suivi, nous chargeons ici les 100 premières lignes du restval dans un fichier JSON local à l'aide d'un simple appel à l'API. Vous pouvez également utiliser la bibliothèque de données HuggingFace pour charger le jeu de données complet ou des sous-ensembles du jeu de données.
Si les données sont chargées avec succès dans un fichier JSON, vous devriez voir quelque chose de similaire à ce qui suit :
Data successfully downloaded and saved to multilingual_coco_sample.json
Étape 2 : (Démarrer Elasticsearch) et indexer les données dans Elasticsearch
a) Démarrez votre serveur Elasticsearch local.
b) Lancer le client Elasticsearch.
c) Données d'index
Une fois les données indexées, vous devriez voir quelque chose de similaire à ce qui suit :
Successfully bulk indexed 4840 documents
Indexing complete!
Étape 3 : Déployer le modèle formé E5
Dans Kibana, accédez à la page Stack Management > Trained Models, et cliquez sur Deploy pour le modèle .multilingual-e5-small_linux-x86_64. option. Ce modèle E5 est un petit ordinateur multilingue optimisé pour linux-x86_64, que l'on peut utiliser dès sa sortie de l'emballage. En cliquant sur "Déployer", vous accédez à un écran où vous pouvez ajuster les paramètres de déploiement ou les configurations des vCPUs. Par souci de simplicité, nous utiliserons les options par défaut, en sélectionnant les ressources adaptatives, ce qui permettra de dimensionner automatiquement notre déploiement en fonction de l'utilisation.
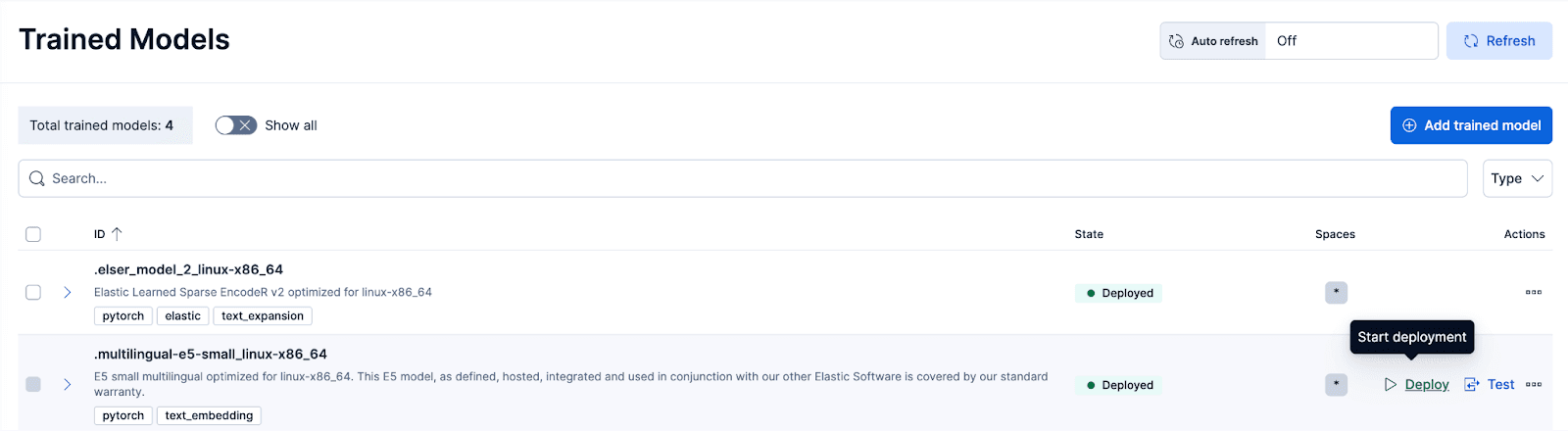
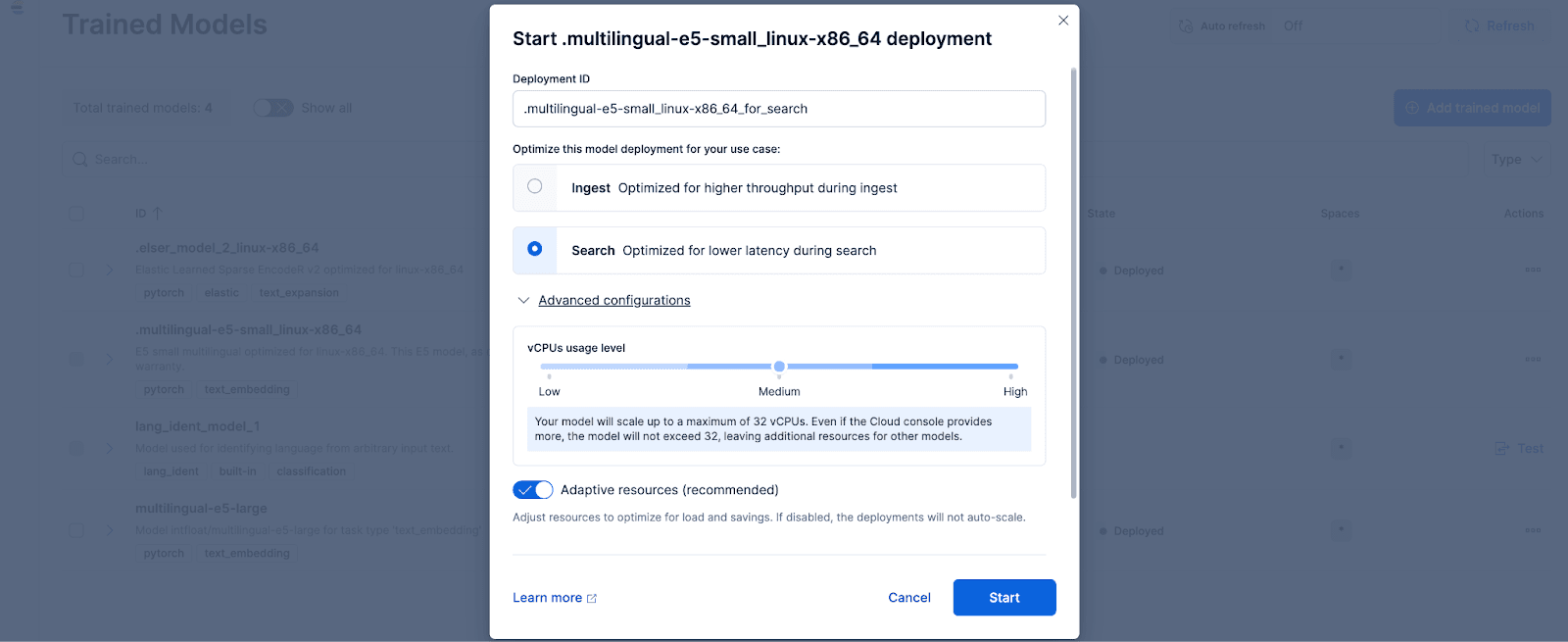
Si vous souhaitez utiliser d'autres modèles d'intégration de texte, vous pouvez le faire en option. Par exemple, pour utiliser le BGE-M3, vous pouvez utiliser le client Python Eland d'Elastic pour importer le modèle de HuggingFace.
Accédez ensuite à la page Modèles formés pour déployer le modèle importé avec les configurations souhaitées.
Étape 4 : Vectorisation ou création d'enchâssements pour les données d'origine avec le modèle déployé
Pour créer les enchâssements, nous devons d'abord créer un pipeline d'ingestion qui nous permettra de prendre le texte et de le faire passer par le modèle d'enchâssement de texte d'inférence. Vous pouvez le faire dans l'interface utilisateur de Kibana ou via l'API d'Elasticsearch.
Pour ce faire via l'interface Kibana, après avoir déployé le modèle entraîné, cliquez sur le bouton Test . Cela vous permettra de tester et de prévisualiser les éléments intégrés générés. Créez une nouvelle vue de données pour l'index coco , définissez Data view sur la vue de données coco nouvellement créée, et définissez Field sur description car c'est le champ pour lequel nous voulons générer des embeddings.
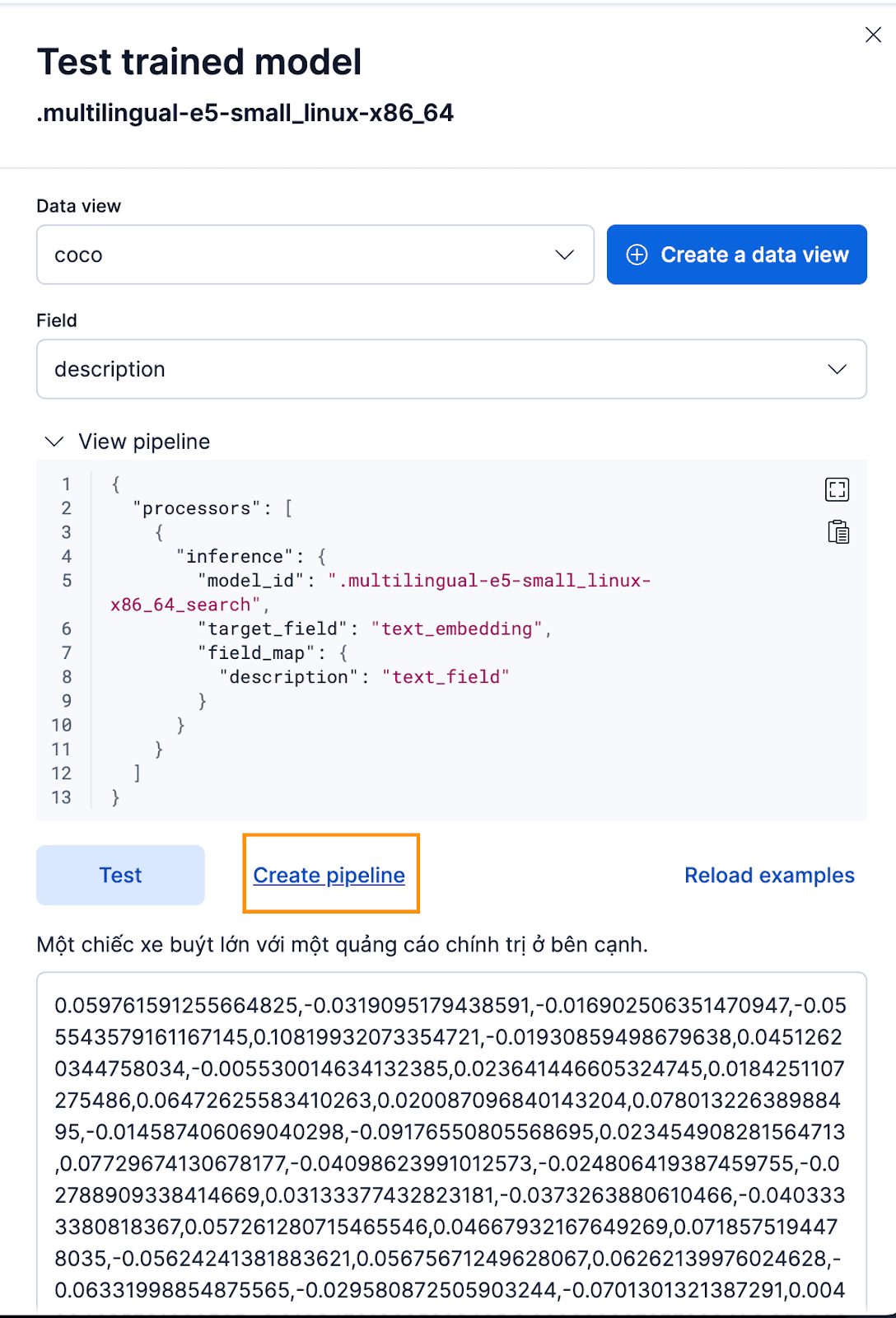
Cela fonctionne très bien ! Nous pouvons maintenant créer le pipeline d'ingestion et réindexer nos documents originaux, les faire passer par le pipeline et créer un nouvel index avec les embeddings. Pour ce faire, cliquez sur Créer un pipeline, ce qui vous guidera tout au long du processus de création du pipeline, avec des processeurs auto-remplis nécessaires pour vous aider à créer les embeddings.
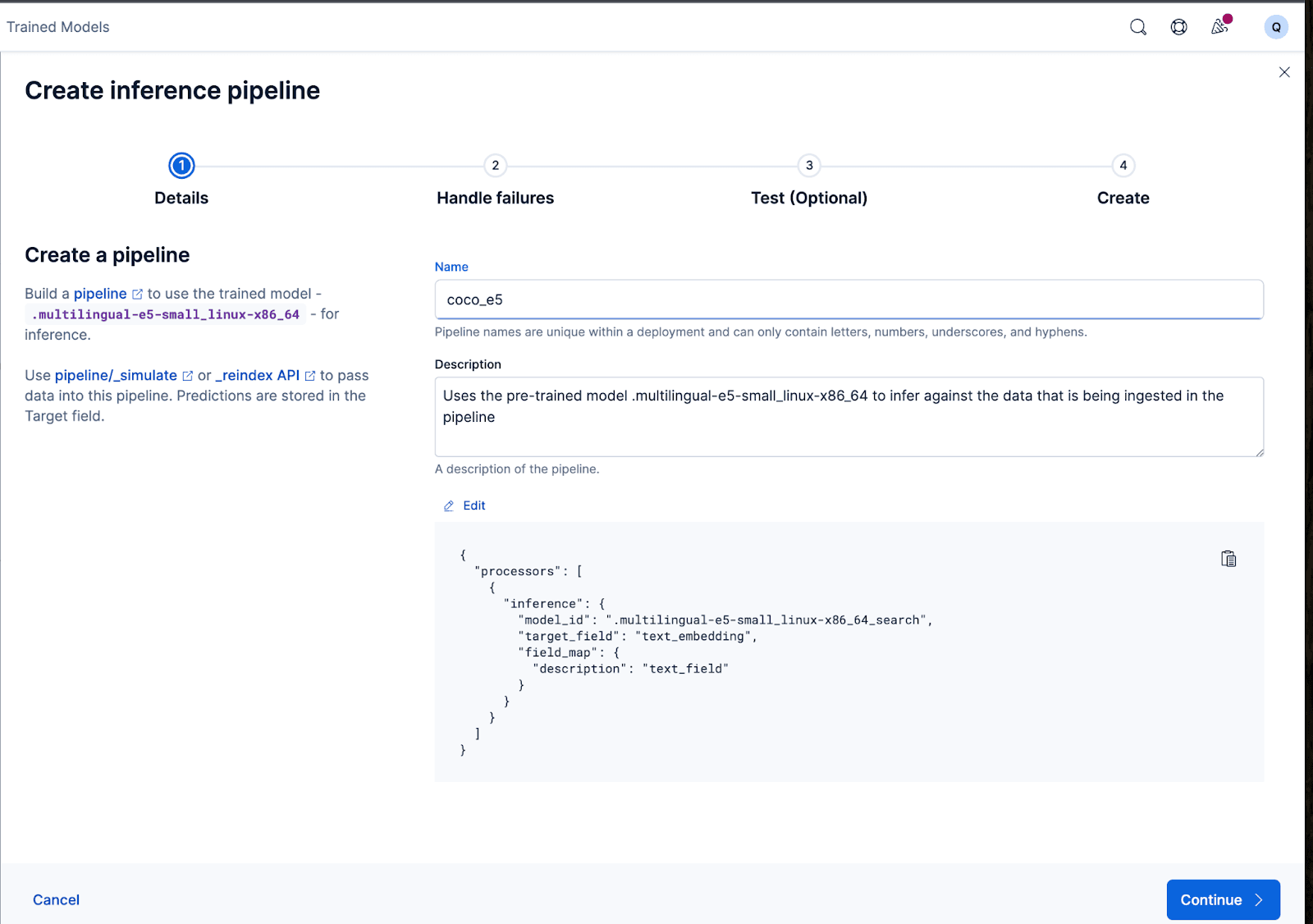
L'assistant peut également remplir automatiquement les processeurs nécessaires pour gérer les défaillances lors de l'ingestion et du traitement des données.
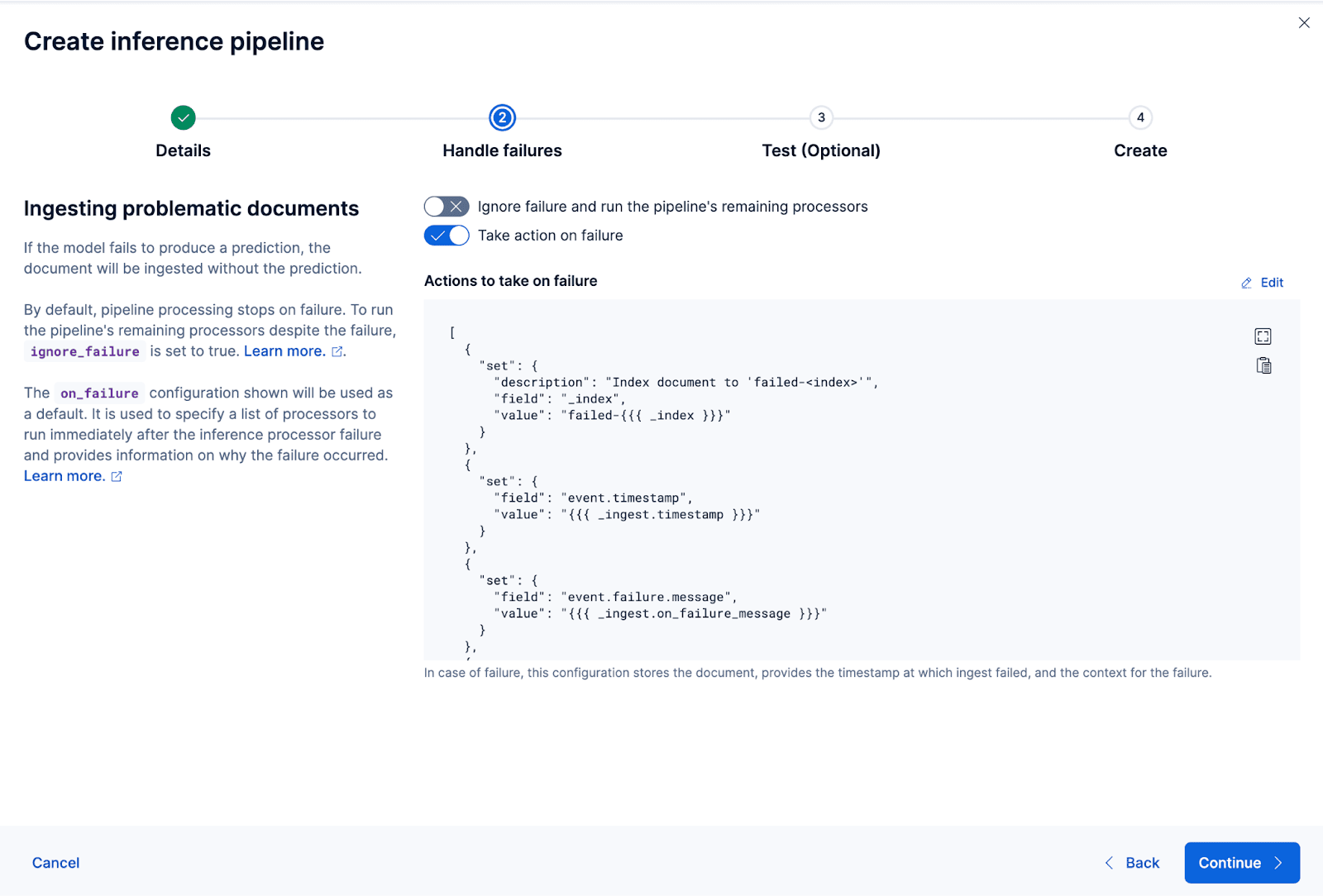
Créons maintenant le pipeline d'ingestion. Je nomme le pipeline coco_e5. Une fois le pipeline créé avec succès, vous pouvez immédiatement l'utiliser pour générer les embeddings en réindexant les données indexées d'origine vers un nouvel index dans l'assistant. Cliquez sur Réindexer pour lancer le processus.
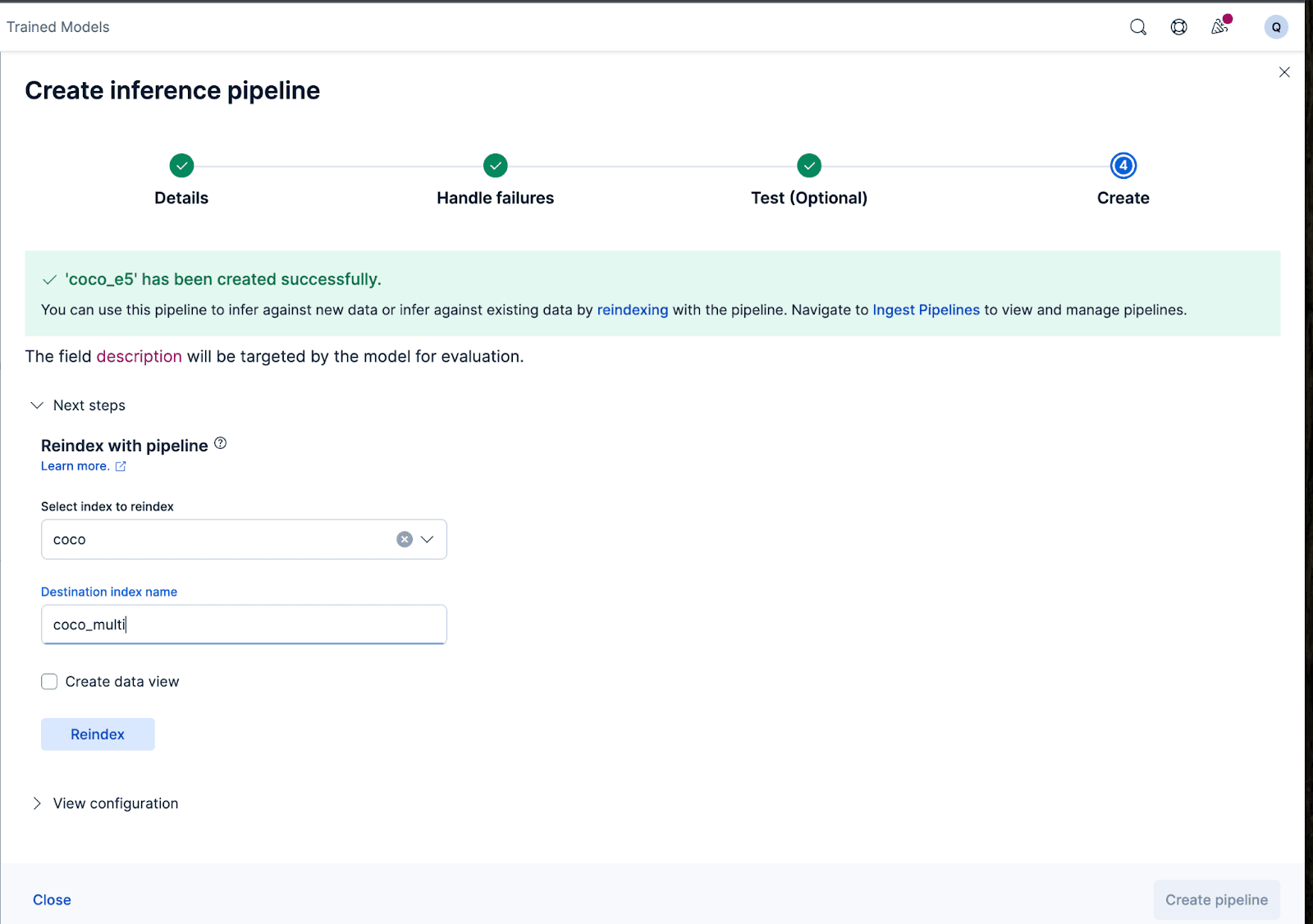
Pour des configurations plus complexes, nous pouvons utiliser l'API Elasticsearch.
Pour certains modèles, en raison de la manière dont ils ont été entraînés, il peut être nécessaire d'ajouter certains textes à l'entrée réelle avant de générer les enchâssements, faute de quoi les performances s'en trouveront dégradées.
Par exemple, avec le e5, le modèle s'attend à ce que le texte d'entrée suive "passage : {content of passage}". Utilisons les pipelines d'ingestion pour y parvenir : Nous allons créer un nouveau pipeline d'ingestion vectorize_descriptions. Dans ce pipeline, nous allons créer un nouveau champ temporaire temp_desc, ajouter "passage : " au texte description, faire passer temp_desc par le modèle pour générer des enchâssements de texte, puis supprimer le champ temp_desc.
En outre, nous pourrions vouloir spécifier le type de quantification que nous voulons utiliser pour le vecteur généré. Par défaut, Elasticsearch utilise int8_hnsw, mais ici je veux Better Binary Quantization (ou bqq_hnsw), qui réduit chaque dimension à une précision d'un seul bit. Cela permet de réduire l'empreinte mémoire de 96% (ou 32x) au prix d'une plus grande précision. J'opte pour ce type de quantification parce que je sais que j'utiliserai plus tard un reranker pour améliorer la perte de précision.
Pour ce faire, nous allons créer un nouvel index nommé coco_multi, et spécifier les mappings. La magie réside ici dans le champ vector_description, où nous spécifions que le type de l'index_optionsest bbq_hnsw.
Nous pouvons maintenant réindexer les documents originaux dans un nouvel index, avec notre pipeline d'ingestion qui va "vectoriser" ou créer des embeddings pour le champ des descriptions.
Et c'est tout ! Nous avons déployé avec succès un modèle multilingue avec Elasticsearch et Kibana et appris étape par étape comment créer les vector embeddings avec vos données avec Elastic, soit via l'interface utilisateur Kibana, soit avec l'API Elasticsearch. Dans la deuxième partie de cette série, nous explorerons les résultats et les nuances de l'utilisation d'un modèle multilingue. En attendant, vous pouvez créer votre propre cluster Cloud pour essayer la recherche sémantique multilingue en utilisant notre modèle E5 prêt à l'emploi sur la langue et l'ensemble de données de votre choix.
Pour aller plus loin

18 mai 2026
Recherche par IA agentique avec garde-fous déterministes dans Elasticsearch pour une exécution sécurisée des requêtes
Les systèmes de recherche par IA agentique échouent souvent lorsque les LLM génèrent des requêtes directement. Découvrez comment des garde-fous déterministes et une architecture de plan de contrôle permettent une exécution de requêtes sûre, fiable et contrôlée avec Elasticsearch.

11 mai 2026
Personnaliser la recherche e-commerce : intégrer l’historique d’achat et les cohortes d’utilisateurs
Découvrez comment créer une expérience de recherche e-commerce personnalisée dans Elasticsearch sans compromettre la gouvernance. Cet article explique comment mettre en avant les produits déjà achetés par un client et comment activer des politiques spécifiques à certaines cohortes selon les profils utilisateurs.

4 mai 2026
Percolateur Elasticsearch pour la gouvernance de la recherche e-commerce : traduire les requêtes ambiguës en stratégies de récupération contrôlée
Découvrez comment utiliser le percolateur Elasticsearch pour mettre en œuvre la gouvernance de la recherche. Dans cet article, nous présentons les modèles nécessaires à la création d'un moteur de politiques gouverné en production et à l'élaboration d'une stratégie de récupération contrôlée.

1 mai 2026
Élaboration d'un plan de contrôle pour gérer la recherche dans le commerce électronique
Comment mettre en place un plan de contrôle géré pour le commerce électronique qui intègre des politiques de recherche conflictuelles en un seul plan d'exécution (sans modification du code).

24 avril 2026
Réindexation des flux de données en raison de conflits de mapping
Découvrez comment résoudre les conflits de mapping Elasticsearch en réindexant les flux de données. Cet article explique le processus de réindexation et comment garantir un mapping correct des nouvelles données.