Avec Elastic Open Web Crawler et son architecture pilotée par CLI, il est désormais assez simple d'avoir des configurations de crawler versionnées et un pipeline CI/CD avec des tests locaux.
Traditionnellement, la gestion des robots d'indexation était un processus manuel et sujet aux erreurs. Il s'agissait de modifier les configurations directement dans l'interface utilisateur et de se débattre avec le clonage des configurations de crawl, le retour en arrière, la gestion des versions, etc. Traiter les configurations des robots comme du code résout ce problème en offrant les mêmes avantages que ceux que nous attendons du développement de logiciels : répétabilité, traçabilité et automatisation.
Ce flux de travail facilite l'intégration de l'Open Web Crawler dans votre pipeline CI/CD pour les retours en arrière, les sauvegardes et les migrations, tâches qui étaient beaucoup plus délicates avec les Elastic Crawlers précédents, tels que l'Elastic Web Crawler ou l'App Search Crawler.
Dans cet article, nous allons apprendre à.. :
- Gérer nos configurations de crawl en utilisant GitHub
- Disposer d'une installation locale pour tester les pipelines avant de les déployer
- Créer une configuration de production pour exécuter le robot d'exploration avec de nouveaux paramètres à chaque fois que nous apportons des modifications à notre branche principale.
Vous pouvez trouver le dépôt du projet ici. Pour l'instant, j'utilise Elasticsearch 9.1.3 et Open Web Crawler 0.4.2.
Produits requis
- Bureau Docker
- Instance Elasticsearch
- Machine virtuelle avec accès SSH (par exemple, AWS EC2) et Docker installé.
Étapes
- Structure des dossiers
- Configuration du robot
- Fichier Docker-compose (environnement local)
- Actions Github
- Tests au niveau local
- Déploiement vers prod
- Modifications et redéploiement
Structure des dossiers
Pour ce projet, nous aurons la structure de fichier suivante :
Configuration du robot
Sous crawler-config.yml,, nous mettrons les éléments suivants :
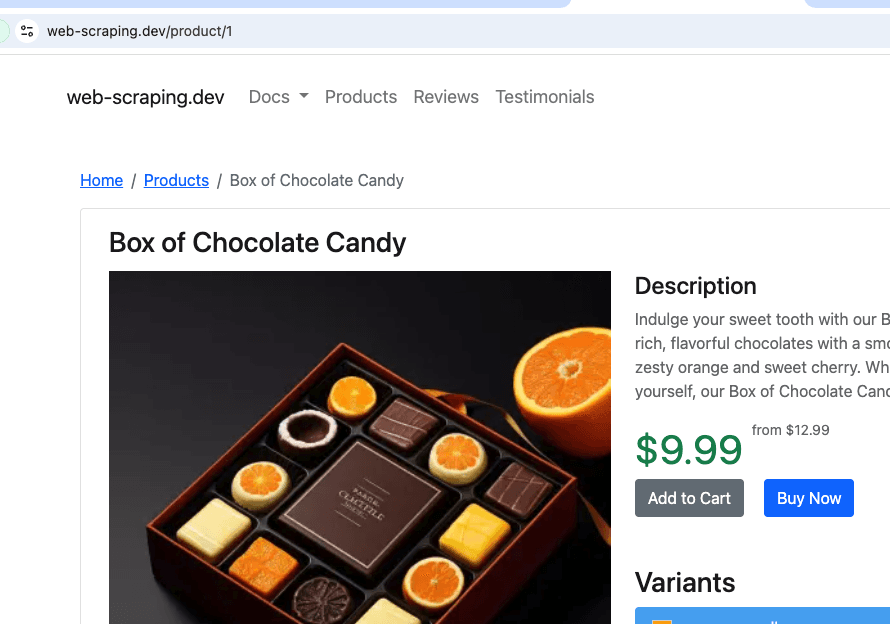
Il s'agit d'une recherche à partir de https://web-scraping.dev/products, un site fictif pour les produits. Nous ne parcourrons que les trois premières pages du produit. Le paramètre max_crawl_depth empêchera le robot d'exploration de découvrir d'autres pages que celles définies comme seed_urls en n'ouvrant pas les liens qu'elles contiennent.
Elasticsearch host et api_key seront alimentés dynamiquement en fonction de l'environnement dans lequel nous exécutons le script.
Fichier Docker-compose (environnement local)
Pour le site local docker-compose.yml,, nous allons déployer le crawler et un seul cluster Elasticsearch + Kibana, de sorte que nous puissions facilement visualiser nos résultats de crawling avant de les déployer en production.
Notez que le crawler attend qu'Elasticsearch soit prêt à fonctionner.
Actions Github
Nous devons maintenant créer une action GitHub qui copiera les nouveaux paramètres et exécutera le crawler dans notre machine virtuelle à chaque poussée vers main. Ainsi, nous disposons toujours de la dernière configuration déployée, sans avoir à entrer manuellement dans la machine virtuelle pour mettre à jour les fichiers et exécuter le crawler. Nous allons utiliser AWS EC2 comme fournisseur de machines virtuelles.
La première étape consiste à ajouter l'hôte (VM_HOST), l'utilisateur de la machine (VM_USER), la clé RSA SSH (VM_KEY), l'hôte Elasticsearch (ES_HOST) et la clé API Elasticsearch (ES_API_KEY) aux secrets d'action GitHub :
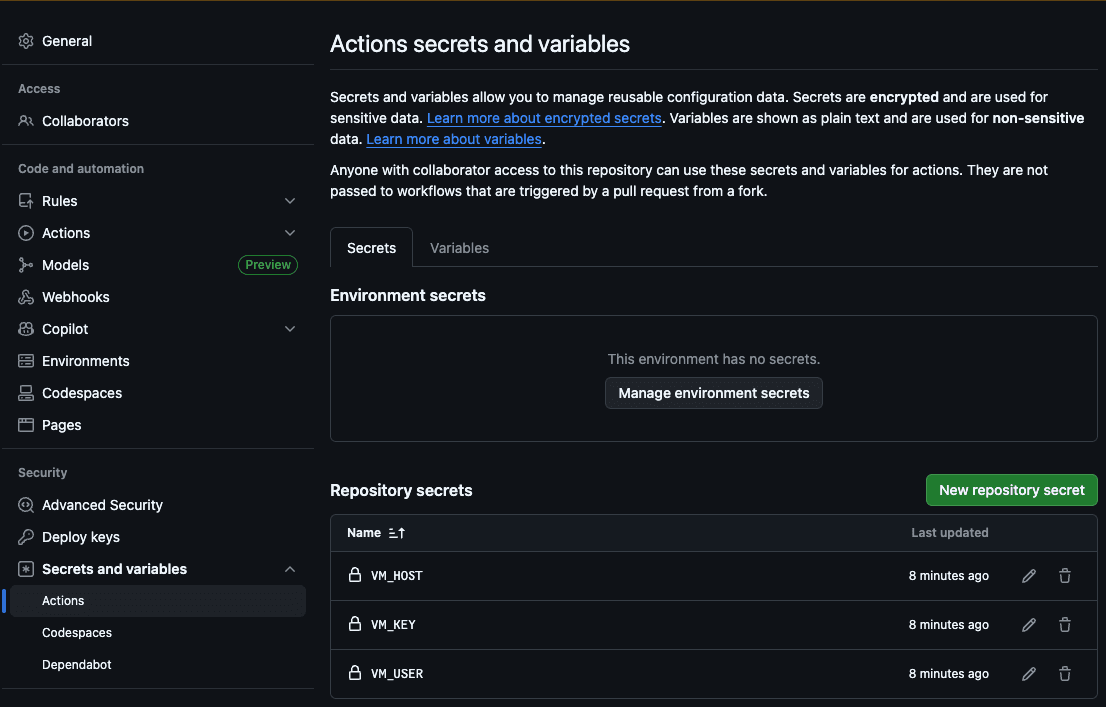
De cette manière, l'action pourra accéder à notre serveur pour copier les nouveaux fichiers et exécuter le crawl.
Maintenant, créons notre fichier .github/workflows/deploy.yml:
Cette action exécutera les étapes suivantes à chaque fois que des modifications seront apportées au fichier de configuration du crawler :
- Renseigner l'hôte Elasticsearch et la clé API dans la configuration yml
- Copier le dossier config sur notre VM
- Se connecter via SSH à notre VM
- Exécuter le crawl avec la configuration que nous venons de copier depuis le repo
Tests au niveau local
Pour tester notre crawler localement, nous avons créé un script bash qui remplit l'hôte Elasticsearch avec l'hôte local de Docker et démarre un crawl. Vous pouvez lancer ./local.sh pour l'exécuter.
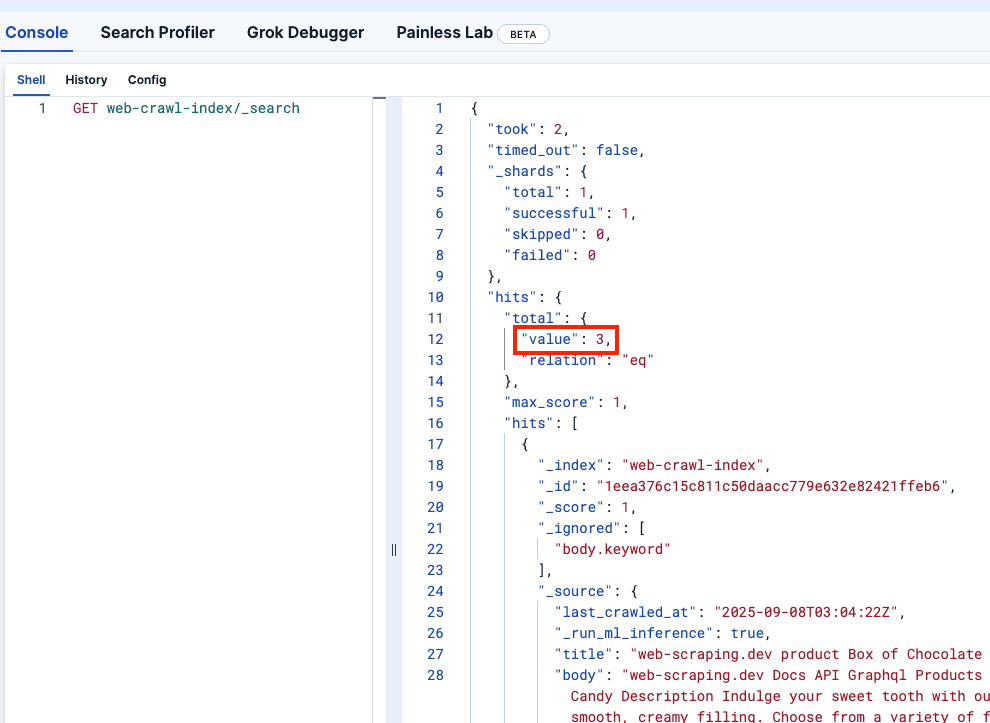
Regardons Kibana DevTools pour confirmer que le site web-crawler-index a été correctement renseigné :
Déploiement vers prod
Nous sommes maintenant prêts à pousser vers la branche principale, ce qui déploiera le crawler dans votre machine virtuelle et commencera à envoyer des logs à votre instance Serverless Elasticsearch.
Cela déclenchera l'action GitHub, qui exécutera le script de déploiement dans la machine virtuelle et commencera l'exploration.
Vous pouvez confirmer que l'action a été exécutée en allant sur le dépôt GitHub et en visitant l'onglet "Actions" :

Modifications et redéploiement
Vous avez peut-être remarqué que le site price de chaque produit fait partie du champ "body" du document. L'idéal serait de stocker le prix dans un champ distinct afin de pouvoir utiliser des filtres.
Ajoutons cette modification au fichier crawler.yml afin d'utiliser des règles d'extraction pour extraire le prix de la classe CSS product-price:
Nous constatons également que le prix comprend un signe de dollar ($), que nous devons supprimer si nous voulons exécuter des requêtes de plage. Nous pouvons utiliser un pipeline d'acquisition pour cela. Notez que nous y faisons référence dans notre nouveau fichier de configuration du crawler ci-dessus :
Nous pouvons exécuter cette commande dans notre cluster Elasticsearch de production. Pour celui de développement, comme il est éphémère, nous pouvons intégrer la création du pipeline dans le fichier docker-compose.yml en ajoutant le service suivant. Notez que nous avons également ajouté un depends_on au service crawler afin qu'il démarre après la création réussie du pipeline.
Exécutons maintenant `./local.sh` pour voir les changements localement :

C'est très bien ! Poussons maintenant la modification :
Pour confirmer que tout fonctionne, vous pouvez vérifier votre Kibana de production, qui devrait refléter les changements et afficher le prix comme un nouveau champ sans le signe du dollar.
Conclusion
Elastic Open Web Crawler vous permet de gérer votre crawler en tant que code, ce qui signifie que vous pouvez automatiser l'ensemble du pipeline - du développement au déploiement - et ajouter des environnements locaux éphémères et des tests sur les données explorées de manière programmatique, pour ne citer que quelques exemples.
Vous êtes invités à cloner le dépôt officiel et à commencer à indexer vos propres données à l'aide de ce flux de travail. Vous pouvez également lire cet article pour apprendre comment effectuer une recherche sémantique sur les index produits par le crawler.
Pour aller plus loin

18 mai 2026
Recherche par IA agentique avec garde-fous déterministes dans Elasticsearch pour une exécution sécurisée des requêtes
Les systèmes de recherche par IA agentique échouent souvent lorsque les LLM génèrent des requêtes directement. Découvrez comment des garde-fous déterministes et une architecture de plan de contrôle permettent une exécution de requêtes sûre, fiable et contrôlée avec Elasticsearch.

11 mai 2026
Personnaliser la recherche e-commerce : intégrer l’historique d’achat et les cohortes d’utilisateurs
Découvrez comment créer une expérience de recherche e-commerce personnalisée dans Elasticsearch sans compromettre la gouvernance. Cet article explique comment mettre en avant les produits déjà achetés par un client et comment activer des politiques spécifiques à certaines cohortes selon les profils utilisateurs.

4 mai 2026
Percolateur Elasticsearch pour la gouvernance de la recherche e-commerce : traduire les requêtes ambiguës en stratégies de récupération contrôlée
Découvrez comment utiliser le percolateur Elasticsearch pour mettre en œuvre la gouvernance de la recherche. Dans cet article, nous présentons les modèles nécessaires à la création d'un moteur de politiques gouverné en production et à l'élaboration d'une stratégie de récupération contrôlée.

1 mai 2026
Élaboration d'un plan de contrôle pour gérer la recherche dans le commerce électronique
Comment mettre en place un plan de contrôle géré pour le commerce électronique qui intègre des politiques de recherche conflictuelles en un seul plan d'exécution (sans modification du code).

24 avril 2026
Réindexation des flux de données en raison de conflits de mapping
Découvrez comment résoudre les conflits de mapping Elasticsearch en réindexant les flux de données. Cet article explique le processus de réindexation et comment garantir un mapping correct des nouvelles données.