Elasticsearch 与 OpenSearch:向量搜索性能比较
Elasticsearch 开箱即用,在向量搜索方面比 OpenSearch 快 2 倍至 12 倍
TLDR:Elasticsearch 的速度提高了 12 倍 - Elastic 收到了来自社区的大量请求,要求澄清 Elasticsearch 和 OpenSearch 之间的性能差异,特别是在语义搜索/向量搜索领域,因此我们进行了这项性能测试,以提供清晰、数据驱动的对比——没有模棱两可之处,只有直接的事实来为我们的用户提供信息。结果表明,Elasticsearch 在向量搜索方面比 OpenSearch 快 12 倍,因此所需的计算资源更少。这反映了 Elastic 致力于将 Lucene 打造为搜索和检索用例的最佳向量数据库。
向量搜索正在彻底改变我们进行相似性搜索的方式,特别是在 AI 和机器学习等领域。随着向量嵌入模型的日益普及,在数百万个高维向量中进行高效搜索的能力变得至关重要。
在为向量数据库提供支持时,Elastic 和 OpenSearch 采取了显著不同的方法。Elastic 投入巨资优化 Apache Lucene 和 Elasticsearch,使其成为向量搜索应用程序的顶级选择。相比之下,OpenSearch 扩大了其关注范围,整合了其他向量搜索实现,并探索了超出 Lucene 范围的领域。我们对 Lucene 的关注具有战略意义,这使我们能够在 Elasticsearch 版本中提供高度集成的支持,从而形成一个功能更强大的组合,其中每个组件都能相互补充并增强彼此的功能。
本博客详细比较了 Elasticsearch 8.14 和 OpenSearch 2.14 的不同配置和向量引擎。在这项性能分析中,Elasticsearch 被证明是向量搜索操作的卓越平台,而即将推出的功能将更加显著地扩大差异。与 OpenSearch 相比,它在每个基准轨道上都表现出色——平均性能提高了 2 倍到 12 倍。这涉及使用不同的向量数量和维度的场景,包括 so_vector(2M 向量,768D)、openai_vector(2.5M 向量,1536D)和 dense_vector(10M 向量,96D),所有这些都可在此存储库中找到,并附有在 Google Cloud 上配置所有所需基础架构的 Terraform 脚本和用于运行测试的 Kubernetes 清单。
本博客中详述的结果补充了之前发布并经过第三方验证的研究的结果。该研究表明,在最常见的搜索分析操作中,Elasticsearch 比 OpenSearch 快 40%–140%;此类操作包括文本查询、排序、范围、日期直方图和术语过滤。现在我们可以添加另一个差异化因素:向量搜索。
开箱即用,性能提升高达 12 倍
我们在四个向量数据集上的基准测试涉及近似 KNN 和精确 KNN 搜索,考虑了不同的大小、维度和配置,总共进行了 40.189.820 次未缓存的搜索请求。结果:Elasticsearch 在向量搜索中比 OpenSearch 快 12 倍,因此需要更少的计算资源。
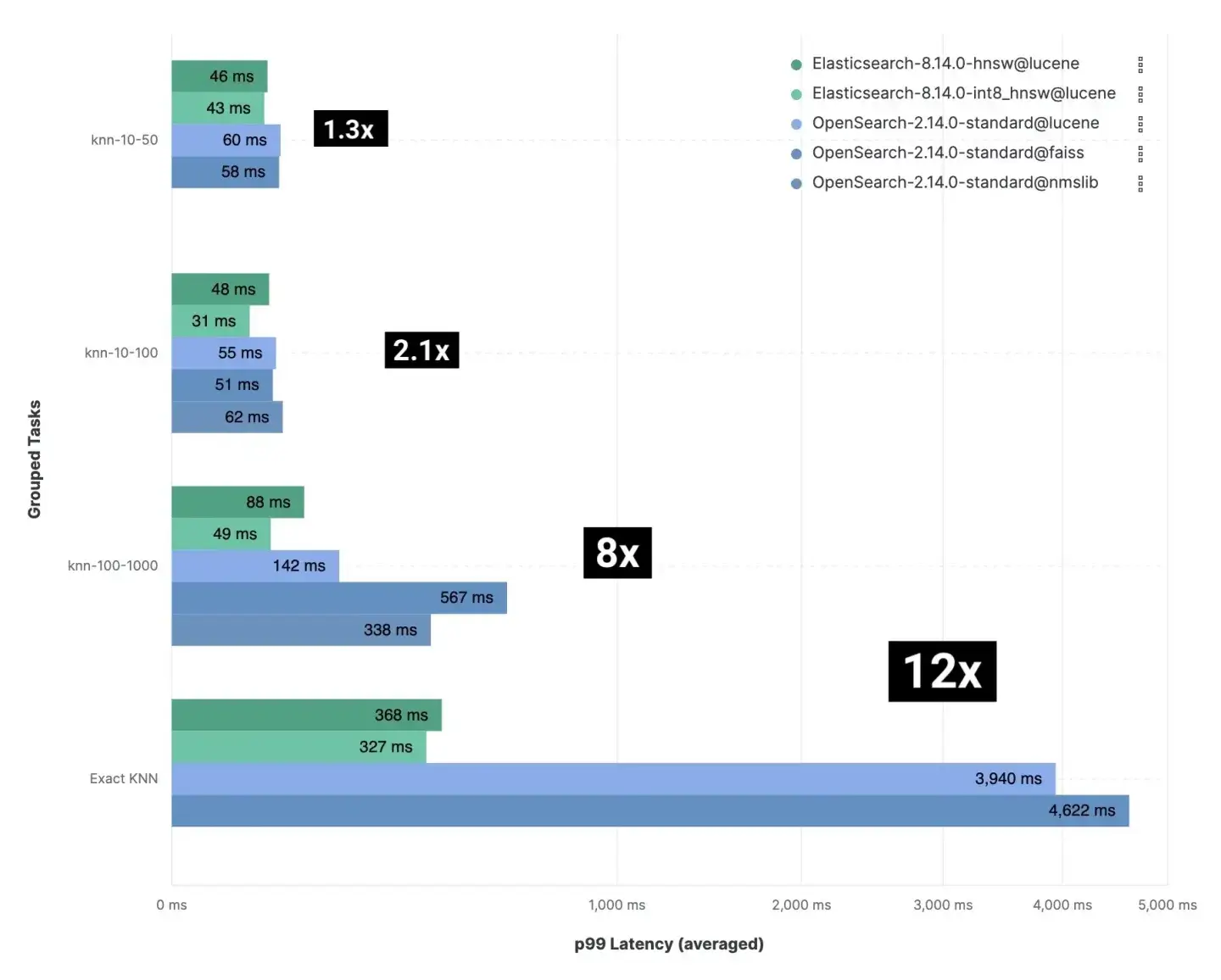
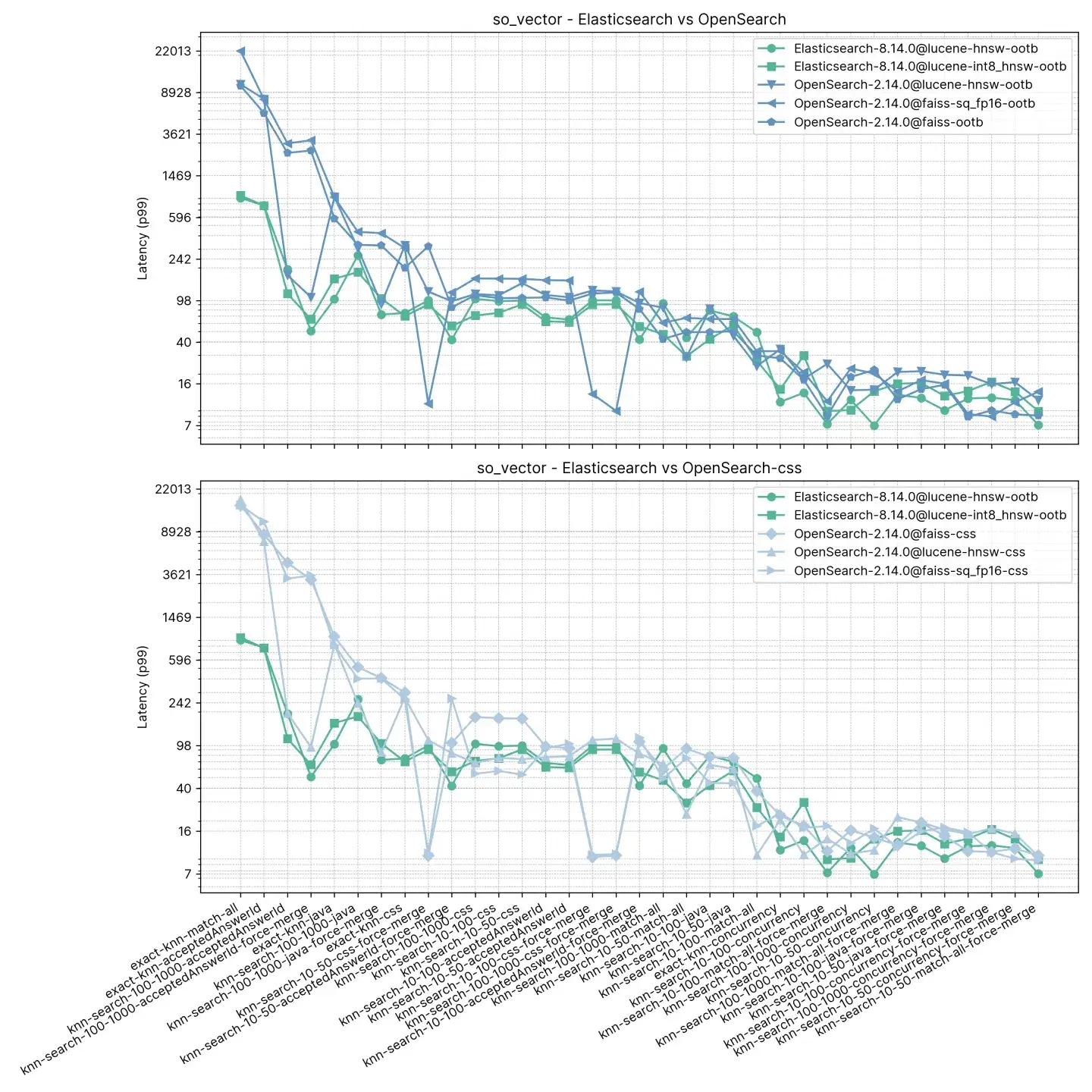
图 1:Elasticsearch 和 OpenSearch 中不同组合的 ANN 和精确 KNN 的分组任务。
像 knn-10-100 这样的组表示 KNN 搜索, 和 。在 HNSW 向量搜索中, 决定了查询向量要检索的最近邻居数量。它指定了要找到多少个相似向量。 设置每个段要检索的候选向量数量。更多的候选者可以提高准确性,但需要更多的计算资源。
我们还测试了不同的量化技术,并利用特定引擎进行了优化。各个轨道、任务和向量引擎的详细结果如下。
精确 KNN 和近似 KNN
在处理不同的数据集和用例时,向量搜索的正确方法会有所不同。在本博客中,所有标记为 knn-* 的任务,如 knn-10-100,使用 近似 KNN,而 script-score-* 指的是 精确 KNN,但它们之间有什么区别,为什么它们很重要?
本质上,如果您处理的是更大规模的数据集,首选方法是近似 K 最近邻 (ANN),因为它具有更出色的可扩展性。对于可能需要过滤过程的规模较小的数据集,精确 KNN 方法是理想选择。
精确 KNN 使用暴力方法,计算数据集中一个向量与其他每个向量之间的距离。然后对这些距离进行排序,找出 个最近的邻居。虽然这种方法能确保精确匹配,但对于大型高维数据集来说,它在可扩展性方面面临挑战。然而,在很多情况下,需要使用精确 KNN:
重新评分:在涉及词汇或语义搜索后进行基于向量的重新评分时,精确 KNN 至关重要。例如,在产品搜索引擎中,可以根据文本查询(例如,关键字、类别)筛选初始搜索结果,然后使用与筛选出的项目相关的向量进行更准确的相似性评估。
个性化:处理大量用户时,如果每个用户都由相对较少数量(例如 100 万)的不同向量表示,则按用户特定的元数据(例如 user_id)对索引进行排序,并使用向量进行暴力评分会变得高效。这种方法能够根据精准的向量比较,根据用户的个人偏好为用户量身定制个性化推荐或内容交付。
因此,精确 KNN 确保了基于向量相似度的最终排名和推荐精准且符合用户偏好。
另一方面,近似 KNN(或 ANN)采用的方法使得数据搜索比精确 KNN 更快、更高效,尤其是在大型高维数据集中。ANN 并不采用蛮力方法(即测量查询与所有点之间的精确最近距离,从而带来计算和扩展挑战),而是使用某些技术来有效地重构数据集中可搜索向量的索引和维度。虽然这可能会导致轻微的不准确,但它显著提高了搜索过程的速度,使其成为处理大型数据集的有效替代方案。
在本博客中,所有表述为 knn-* 的任务,例如 knn-10-100,均使用近似 KNN,而 script-score-* 指的是精确 KNN。
测试方法
虽然 Elasticsearch 和 OpenSearch 在 BM25 搜索操作的 API 方面相似,但由于后者是前者的分支,向量搜索并非如此,因为它是在分支之后才引入的。在算法方面,OpenSearch 采取了与 Elasticsearch 不同的方法,除了 lucene 之外,还引入了另外两个引擎——nmslib 和 faiss,每个引擎都有其特定的配置和限制(例如,OpenSearch 中的 nmslib 不支持使用筛选器,而筛选器是许多用例的一项基本功能)。
这三个引擎都使用分层可导航小世界 (HNSW) 算法,该算法对于近似最近邻搜索非常高效,尤其在处理高维数据时表现出色。需要注意的是,faiss 还支持第二种算法 ivf,但由于它需要对数据集进行预训练,因此我们将仅关注 HNSW。HNSW 的核心理念是将数据组织成多层连接图表,每一层代表数据集的不同粒度。搜索从最顶层的粗略视图开始,逐步深入到越来越精细的层级,直至到达最底层。
这两个搜索引擎在受控环境中的相同条件下进行了测试,以确保测试的公平性。所采用的方法与之前发布的性能比较类似,为 Elasticsearch、OpenSearch 和 Rally 配备了专用节点池。terraform 脚本(与所有源一起)可用于配置具有以下功能的 Kubernetes 集群:
1 个适用于 Elasticsearch 的节点池,包含 3 台
e2-standard-32计算机(128GB RAM 和 32 个 CPU)1 个 Node 池用于 OpenSearch,配备 3 台
e2-standard-32机器(128GB RAM 和 32 个 CPU)1 个适用于 Rally 的节点池,包含 2 台
t2a-standard-16计算机(64GB RAM 和 16 个 CPU)
每个“轨道”(或测试)的每种配置都运行了 10 次,其中包括不同的引擎、不同的配置和不同的向量类型。轨道上的任务会根据轨道的不同重复 1,000 到 10,000 次。如果某个轨道中的某个任务由于网络超时而失败,则所有任务都将被丢弃,因此所有结果都代表了顺利开始并完成的轨道。所有测试结果都经过统计验证,确保改进并非偶然。
详细结果
为什么要使用第 99 个百分位而不是平均延迟来进行比较?考虑一个假设的例子:某个社区的平均房价。平均价格可能表明一个昂贵的地区,但仔细观察后,可能会发现大多数房屋的价值要低得多,只有少数豪华属性抬高了平均价格。这说明了平均价格如何无法准确代表该地区房屋价值的完整范围。这就好比检查响应时间,平均值可能会掩盖关键问题。
任务
近似 KNN,k:10 n:50
使用 k:10 n:100 的近似 KNN
近似 KNN,k:100 n:1000
使用 k:10 n:50 和关键字筛选器的近似 KNN
使用 k:10 n:100 和关键字筛选器的近似 KNN
使用 k:100 n:1000 和关键字筛选器的近似 KNN
使用 k:10 n:100 结合索引的近似 KNN
精确 KNN(脚本分数)
向量引擎
lucene在 Elasticsearch 和 OpenSearch 中,版本均为 9.10faiss在 OpenSearch 中nmslib在 OpenSearch 中
向量类型
hnsw在 Elasticsearch 和 OpenSearch 中int8_hnsw在 Elasticsearch 中(采用自动 8 位量化的 HNSW:链接)sq_fp16 hnsw在 OpenSearch 中(采用自动 16 位量化的 HNSW:链接)
开箱即用和并行分段搜索
您可能知道,Lucene 是一个用 Java 编写的高性能文本搜索引擎库,它是 Elasticsearch、OpenSearch 和 Solr 等许多搜索平台的核心。Lucene 的核心是将数据组织成多个段,这些段本质上是独立的索引,使 Lucene 能够更高效地执行搜索。因此,当您向任何基于 Lucene 的搜索引擎发出搜索请求时,您的搜索最终将在这些段中按顺序或并行执行。
OpenSearch 将并发分段搜索作为可选标记引入,默认情况下不使用该标记,您必须使用特殊的索引设置 index.search.concurrent_segment_search.enabled 启用该标记,此处有详细说明,但有一些限制。
另一方面,Elasticsearch 能以开箱即用的方式并发搜索各网段,因此我们在本博客中进行的比较除了考虑不同的向量引擎和向量类型外,还将考虑不同的配置:
Elasticsearch ootb:开箱即用的 Elasticsearch,支持并行分段搜索;
OpenSearch ootb:未启用并行分段搜索;
OpenSearch css:启用并发段搜索
现在,让我们深入了解每个已测试的向量数据集的详细结果:
250 万个向量,1536 个维度(openai_vector)
从最简单的轨道开始,但在维度方面也是最大的,openai_vector——它使用了 NQ 数据集,并通过使用 OpenAI 的 text-embedding-ada-002 模型生成的嵌入来丰富该数据集。它是最简单的,因为它仅测试近似 KNN,并且只有 5 个任务。它既能独立测试(不进行索引),也能与索引一起测试,并且能使用单个客户端和 8 个同时运行的客户端进行测试。
任务
standalone-search-knn-10-100-multiple-clients:同时使用 8 个客户端搜索 250 万个向量 (k:10, n:100)
standalone-search-knn-100-1000-multiple-clients:使用 8 个客户端同时搜索 250 万个向量(k: 100,n: 1000)
standalone-search-knn-10-100-single-client:使用单个客户端在 250 万个向量上搜索(k: 10,n: 100)
standalone-search-knn-100-1000-single-client:使用单个客户端在 250 万个向量上搜索(k: 100,n: 1000)
parallel-documents-indexing-search-knn-10-100:在 250 万个向量上搜索,同时索引另外 100,000 个文档 (k:10, n:100)
平均 p99 性能概述如下:
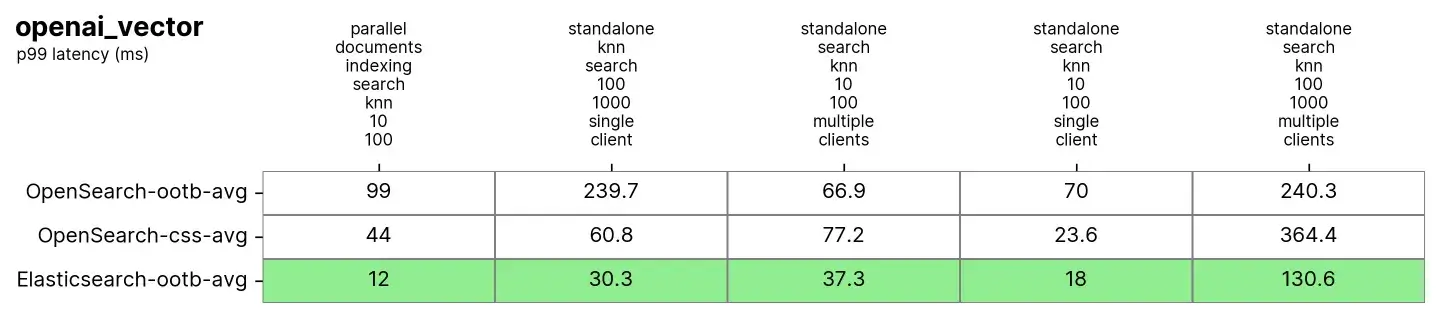
在此我们观察到,在执行索引(即读写)的同时进行向量搜索时,Elasticsearch 比 OpenSearch 快 3 到 8 倍,而在不进行索引的情况下(:10, :100),速度提高了 2 倍到 3 倍,其中 k 和 n 相同。对于 :100 和 :1000(standalone-search-knn-100-1000-single-client 和 standalone-search-knn-100-1000-multiple-clients),Elasticsearch 的平均速度比 OpenSearch 快 2 到 7 倍。
详细结果显示了比较的确切案例和向量引擎:
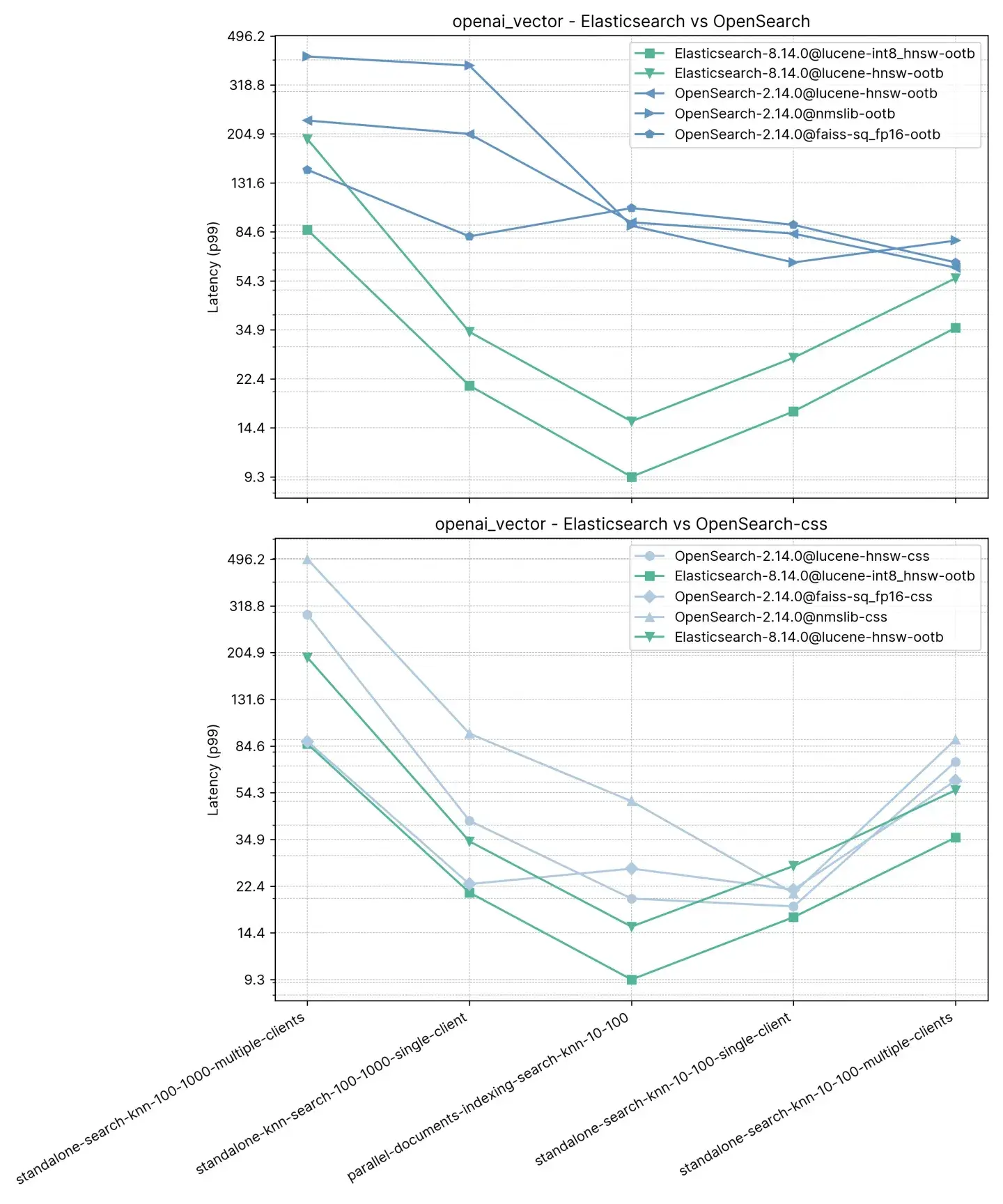
召回
knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
Elasticsearch-8.14.0@lucene-hnsw | 0.969485 | 0.995138 |
Elasticsearch-8.14.0@lucene-int8_hnsw | 0.781445 | 0.784817 |
OpenSearch-2.14.0@lucene-hnsw | 0.96519 | 0.995422 |
OpenSearch-2.14.0@faiss | 0.984154 | 0.98049 |
OpenSearch-2.14.0@faiss-sq_fp16 | 0.980012 | 0.97721 |
OpenSearch-2.14.0@nmslib | 0.982532 | 0.99832 |
一千万个向量,96 个维度 (dense_vector)
在具有 1000 万个向量和 96 维的 dense_vector 中。它基于 Yandex DEEP1B 图像数据集。该数据集是从名为 learn.350M.fbin 的“样本数据”文件的前 1000 万个向量创建的。搜索操作使用来自“查询数据”文件查询的向量。public.10K.fbin。
Elasticsearch 和 OpenSearch 在此数据集上的表现都非常出色,尤其是在强制合并之后,这通常是在只读索引上进行的,类似于对索引进行碎片整理,使其成为一个单一的“表”以供搜索。
任务
每个任务预热 100 个请求,然后测量 1000 个请求
knn-search-10-100:在 1000 万个向量上搜索(k: 10,n: 100)
knn-search-100-1000:在 1000 万个向量上搜索(k:100,n:1000)
knn-search-10-100-force-merge:在强制合并后搜索 1,000 万个向量 (k:10, n:100)
knn-search-100-1000-force-merge:在强制合并后搜索 1000 万个向量 (k: 100, n: 1000)
knn-search-100-1000-concurrent-with-indexing:在 1,000 万个向量上进行搜索,同时更新数据集的 5% (k:100, n:1000)
script-score-query:对 2000 个特定向量进行精确的 KNN 搜索。
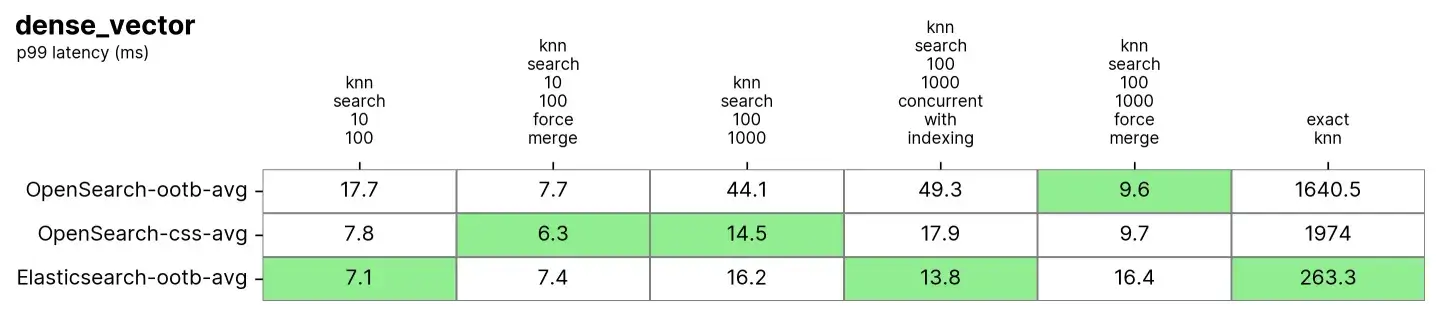
Elasticsearch 和 OpenSearch 在近似 KNN 上表现良好。当索引在 knn-搜索-100-1000-force-merge 和 knn-搜索-10-100-force-merge 中合并(即只有一个段)时,OpenSearch 在使用 nmslib 和 faiss 时表现优于其他,即使它们都在 15 毫秒左右并且都非常接近。
但是,当索引在 knn-search-10-100 和 knn-search-100-1000 中具有多个分段(这是索引接收其文档更新的典型情况)时,Elasticsearch 将延迟保持在约 7 毫秒和 16 毫秒左右,而所有其他 OpenSearch 引擎则较慢。
此外,当同时搜索和写入索引时 (knn-search-100-1000-concurrent-with-indexing),Elasticsearch 将延迟保持在 15 毫秒以下(13.8 毫秒),比开箱即用的 OpenSearch 快近 4 倍(49.3 毫秒),并且在启用并发段搜索时仍然更快(17.9 毫秒),但由于过于接近,所以意义不大。
至于精确 KNN,差距则大得多:Elasticsearch 比 OpenSearch快 6 倍(约 260 毫秒对约 1600 毫秒)。
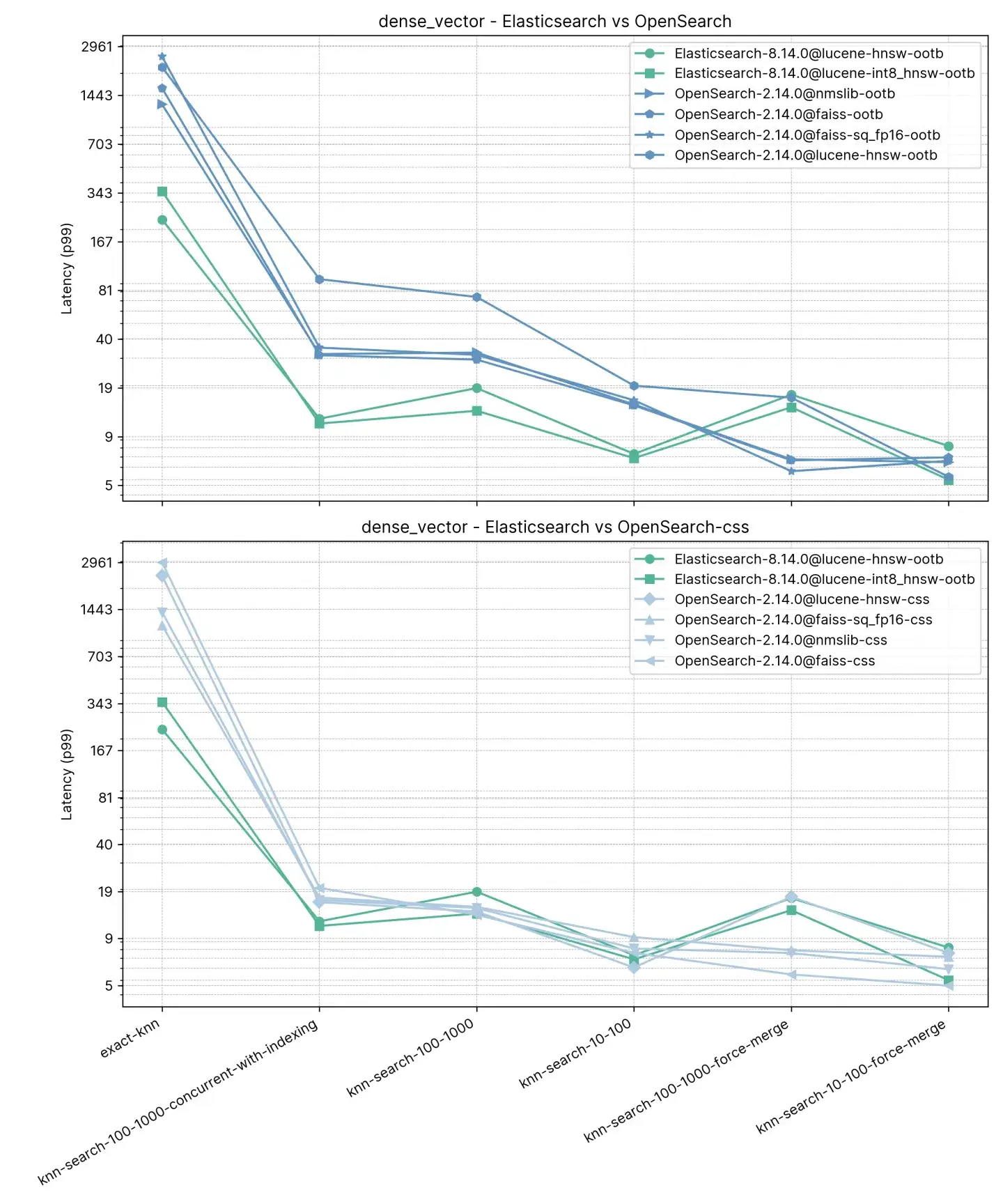
召回
knn-recall-10-100 | knn-recall-100-1000 | |
|---|---|---|
Elasticsearch-8.14.0@lucene-hnsw | 0.969843 | 0.996577 |
Elasticsearch-8.14.0@lucene-int8_hnsw | 0.775458 | 0.840254 |
OpenSearch-2.14.0@lucene-hnsw | 0.971333 | 0.996747 |
OpenSearch-2.14.0@faiss | 0.9704 | 0.914755 |
OpenSearch-2.14.0@faiss-sq_fp16 | 0.968025 | 0.913862 |
OpenSearch-2.14.0@nmslib | 0.9674 | 0.910303 |
200 万个向量,768 个维度 (so_vector)
此轨道 so_vector 源自于 2022 年 4 月 21 日下载的 StackOverflow 帖子转储。它仅包含问题文档——所有代表答案的文档都已删除。每个问题的标题都已使用句子转换器模型 multi-qa-mpnet-base-cos-v1 编码成一个向量。此数据集包含前 200 万个问题。
与前一个轨道不同,这里的每个文档都包含除向量之外的其他字段,以支持诸如带筛选和混合搜索功能的近似 KNN 等测试功能。此测试中明显缺少适用于 OpenSearch 的 nmslib,因为它不支持筛选器。
任务
每个任务会预热 100 个请求,然后测量 100 个请求。请注意,为了简单起见,我们对任务进行了分组,因为测试包含 16 种搜索类型 * 2 个不同的 k 值 * 3 个不同的 n 值。
knn-10-50:在没有筛选器的情况下搜索 200 万个向量 (k:10, n:50)
knn-10-50-filtered:使用筛选器在 200 万个向量上进行搜索 (k:10, n:50)
knn-10-50-after-force-merge:在强制合并并使用过滤器后,对 200 万个向量进行搜索(k: 10,n: 50)
knn-10-100:在没有过滤器的情况下搜索 200 万个向量(k: 10,n: 100)
KNN-10-100-filtered:在 200 万个向量上使用过滤器进行搜索(k: 10,n: 100)
knn-10-100-after-force-merge:在强制合并后,使用筛选器在 200 万个向量上进行搜索 (k:10, n:100)
knn-100-1000:在没有过滤器的情况下搜索 200 万个向量(k:100,n:1000)
knn-100-1000-filtered:使用筛选器在 200 万个向量上进行搜索 (k:100, n:1000)
knn-100-1000-after-force-merge:在强制合并后使用过滤器在 200 万个向量上搜索(k:100,n:1000)
exact-knn:带筛选器和不带筛选器的精确 KNN 搜索。
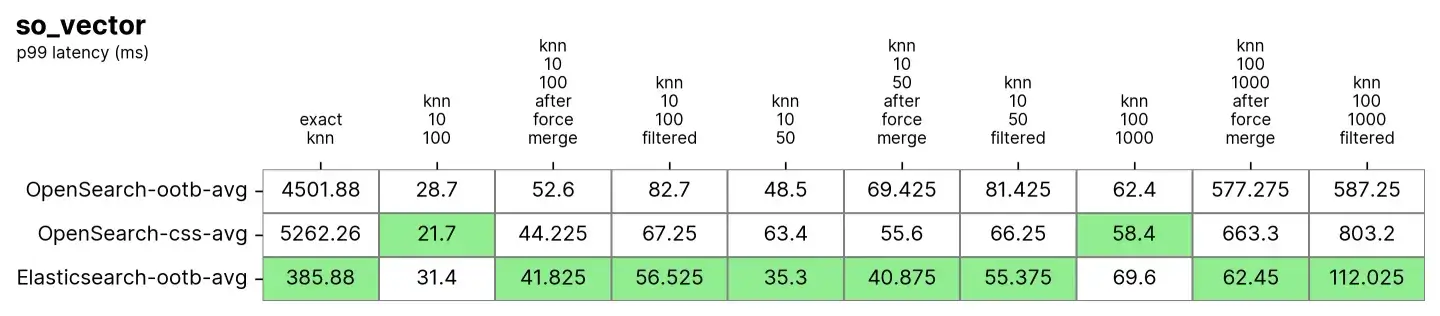
在这项测试中,Elasticsearch 始终比 OpenSearch 的开箱即用速度快,OpenSearch 仅在两种情况下更快,但差距不大(knn-10-100 和 knn-100-1000)。将knn-10-50、knn-10-100 和 knn-100-1000 与筛选器结合使用的任务显示出高达 7 倍的差异(112 毫秒对 803 毫秒)。
执行“强制合并”操作后,两种解决方案的性能似乎趋于平稳,这是可以理解的,从 knn-10-50-after-force-merge、knn-10-100-after-force-merge 和 knn-100-1000-after-force-merge 中可以明显看出这一点。在这些任务中,faiss 的速度更快。
在精确 KNN 的性能上差异再次明显,这次 Elasticsearch 比 OpenSearch 快 13 倍(约 385 毫秒对比 5262 毫秒)。
召回
knn-recall-10-100 | knn-recall-100-1000 | knn-recall-10-50 | |
|---|---|---|---|
Elasticsearch-8.14.0@lucene-hnsw | 1 | 1 | 1 |
Elasticsearch-8.14.0@lucene-int8_hnsw | 1 | 0.986667 | 1 |
OpenSearch-2.14.0@lucene-hnsw | 1 | 1 | 1 |
OpenSearch-2.14.0@faiss | 1 | 1 | 1 |
OpenSearch-2.14.0@faiss-sq_fp16 | 1 | 1 | 1 |
OpenSearch-2.14.0@nmslib | 0.9674 | 0.910303 | 0.976394 |
Elasticsearch 和 Lucene 明显胜出
在 Elastic,我们坚持不懈地对 Apache Lucene 和 Elasticsearch 进行创新,以确保我们能够为搜索和检索用例(包括 RAG (Retrieval-Augmented Generation))提供一流的向量数据库。我们最近取得的进展极大地提升了性能,使向量搜索比以前更快、更节省空间,这是在 Lucene 9.10 所取得的成果基础上实现的。这篇博客介绍了一项研究,该研究表明,在比较最新版本时,Elasticsearch 的速度比 OpenSearch 快多达 12 倍。
值得注意的是,这两款产品都使用相同版本的 Lucene(Elasticsearch 8.14 发行说明 和 OpenSearch 2.14 发行说明)。
Elastic 的创新步伐不仅将为我们的本地部署和 Elastic Cloud 客户提供更多服务,还将为使用我们的无状态平台的客户提供更多服务。在提供对标量量化到 int4 等功能的支持时,我们将进行严格的测试,以确保客户能够在不显著减少召回率的情况下使用这些技术,这与我们对 int8 的测试类似。
由于 AI 和机器学习应用程序的普及,向量搜索效率正成为现代搜索引擎中不可或缺的功能。对于寻求能够满足大容量、高复杂性向量数据需求的强大搜索引擎的组织来说,Elasticsearch 是最佳选择。
无论是扩展已建立的平台还是启动新项目,集成 Elasticsearch 以满足向量搜索需求都是一项战略性举措,将带来切实的长期效益。Elasticsearch 凭借其公认的性能优势,已准备好支撑搜索领域的下一波创新浪潮。