今年早些时候,Elastic 宣布与 NVIDIA 合作,为 Elasticsearch 引入 GPU 加速功能,并与 NVIDIA cuVS 集成 — 相关详情可参阅 NVIDIA GTC 大会的相关会议以及多篇博文。本文主要介绍我们与 NVIDIA 向量搜索团队在联合工程方面的最新进展。
回顾
先简单回顾一下最新动态。Elasticsearch 现已确立其作为强大向量数据库的地位,在大规模相似性搜索方面提供了丰富的功能和强劲的性能。凭借标量量化、Better Binary Quantization (BBQ)、SIMD 向量运算以及 DiskBBQ 等在磁盘利用方面更高效的算法,Elasticsearch 已经为管理向量工作负载提供了高效而灵活的多种选项。
通过将 NVIDIA cuVS 集成为可调用的向量搜索模块,我们希望大幅提升向量索引的性能和效率,从而更好地支撑大规模向量工作负载。
挑战
构建高性能向量数据库的最大挑战之一,就是构建向量索引,即 HNSW 图。随着每个向量都要与大量其他向量进行比对,索引构建很快就会被数以百万乃至数十亿次的算术运算所主导。此外,压缩、合并等索引生命周期操作还会进一步增加索引的整体计算开销。随着数据量和相关向量嵌入呈指数级增长,专为大规模并行和高吞吐量数值运算而设计的加速计算 GPU 非常适合处理这些工作负载。
进入 Elasticsearch-GPU 插件
NVIDIA cuVS是一个开源的 CUDA-X 库,用于 GPU 加速的向量搜索和数据集群,能够为 AI 和推荐工作负载快速构建索引和嵌入检索。
Elasticsearch 通过 cuvs-java 使用 cuVS,这是一个由社区开发并由 NVIDIA 维护的开源库。cuvs-java 库十分轻量,基于 cuVS C API 构建,并借助 Panama 外部函数接口,以符合 Java 习惯用法的方式暴露 cuVS 功能,同时兼具现代性和高性能。
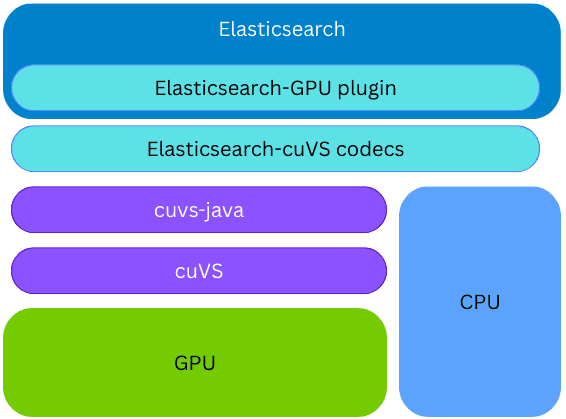
cuvs-java 库被集成到一个新的 Elasticsearch 插件中;因此,GPU 上的向量索引可在同一 Elasticsearch 节点和同一进程内完成,无需部署任何外部组件或额外硬件。在索引构建过程中,如果已安装 cuVS 库且存在已正确配置的 GPU,Elasticsearch 会利用 GPU 加速向量索引过程。向量会被传递给 GPU,由 GPU 构建 CAGRA 图。随后将该图转换为 HNSW 格式,使其能够立即在 CPU 上用于向量搜索。构建完成的图,其最终格式与在 CPU 上构建的图完全一致;这使得在底层硬件支持的情况下,Elasticsearch 可以利用 GPU 实现高吞吐量的向量索引,同时释放 CPU 算力,用于并发搜索、数据处理等其他任务。
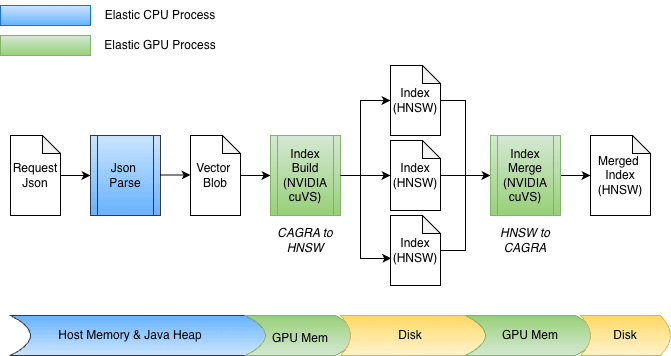
索引构建加速
作为将 GPU 加速集成到 Elasticsearch 的一部分,对 cuvs-java 进行了多项增强,重点是高效的数据输入/输出和函数调用。一项关键增强是使用 cuVSMatrix 对向量进行透明建模,无论它们位于 Java 堆中、堆外还是 GPU 内存中。这使数据可以在内存与 GPU 之间高效传输,避免对可能多达数十亿个向量进行不必要的复制。
由于这种底层的零拷贝抽象,数据传输到 GPU 内存以及从中检索图时都可以直接完成。在索引过程中,向量首先缓存在 Java 堆内存中,然后发送到 GPU,以构建 CAGRA 图。随后,从 GPU 中取回该图,将其转换为 HNSW 格式,并持久化到磁盘。
在合并时,向量已经存储在磁盘上,完全绕过了 Java 堆。索引文件采用内存映射,数据直接传输到 GPU 内存中。该设计还能轻松适应不同的位宽,如 float32 或 int8,并自然扩展到其他量化方案。
话不多说,那它的实际表现如何呢?
在我们探讨数字之前,了解一些背景信息会有所帮助。在索引期间,Elasticsearch 中的分段合并通常在后台自动运行,这会导致在隔离环境中进行基准测试变得十分困难。为了获得可重复的结果,我们使用了强制合并来在受控实验中明确触发分段合并。由于强制合并与后台合并执行相同的底层合并操作,因此其性能可作为预期改进的有用指标,尽管在实际索引工作负载中,具体收获可能会有所不同。
现在让我们来探讨数字。
我们的初步基准测试结果非常令人鼓舞。我们在 AWS g6.4xlarge 实例上运行了基准测试,该实例具有本地连接的 NVMe 存储。我们将单个 Elasticsearch 节点配置为使用默认的最佳索引线程数(8 个,每个物理核心一个),并关闭合并限速功能(在使用快速 NVMe 磁盘时,这一功能的适用性较低)。
对于数据集,我们使用了 OpenAI Rally 向量赛道中的 260 万个、每个具有 1,536 维的向量,将其编码为 base64 字符串,并以 float32 hnsw 结构进行索引。在所有场景中,构建的图都能达到最高约 95% 的召回率。以下是我们的发现:
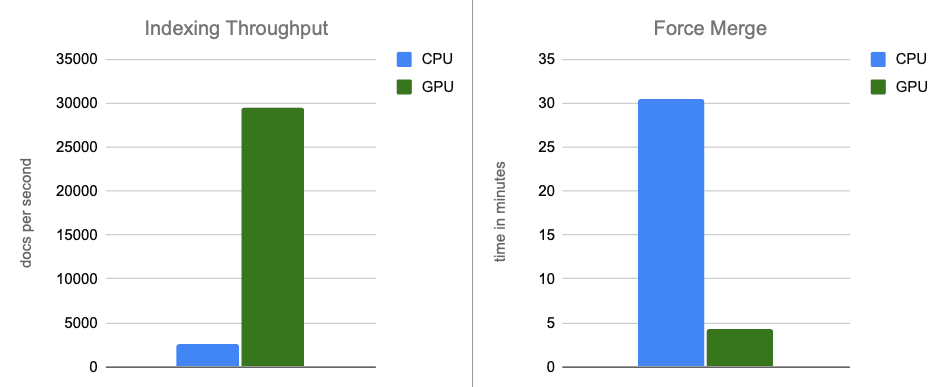
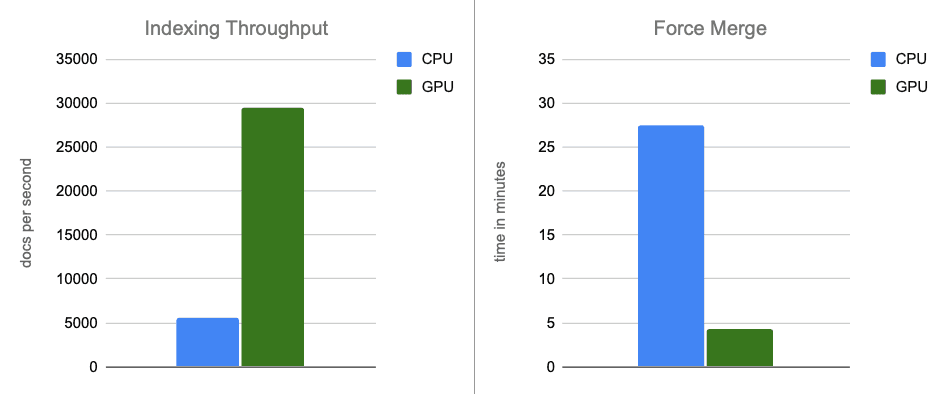
- 索引吞吐量:通过在内存缓冲区刷新期间将图构建移交给 GPU 处理,我们将吞吐量提高了约 12 倍。
- 强制合并:索引完成后,GPU 继续加速分段合并,将强制合并阶段加快约 7 倍。
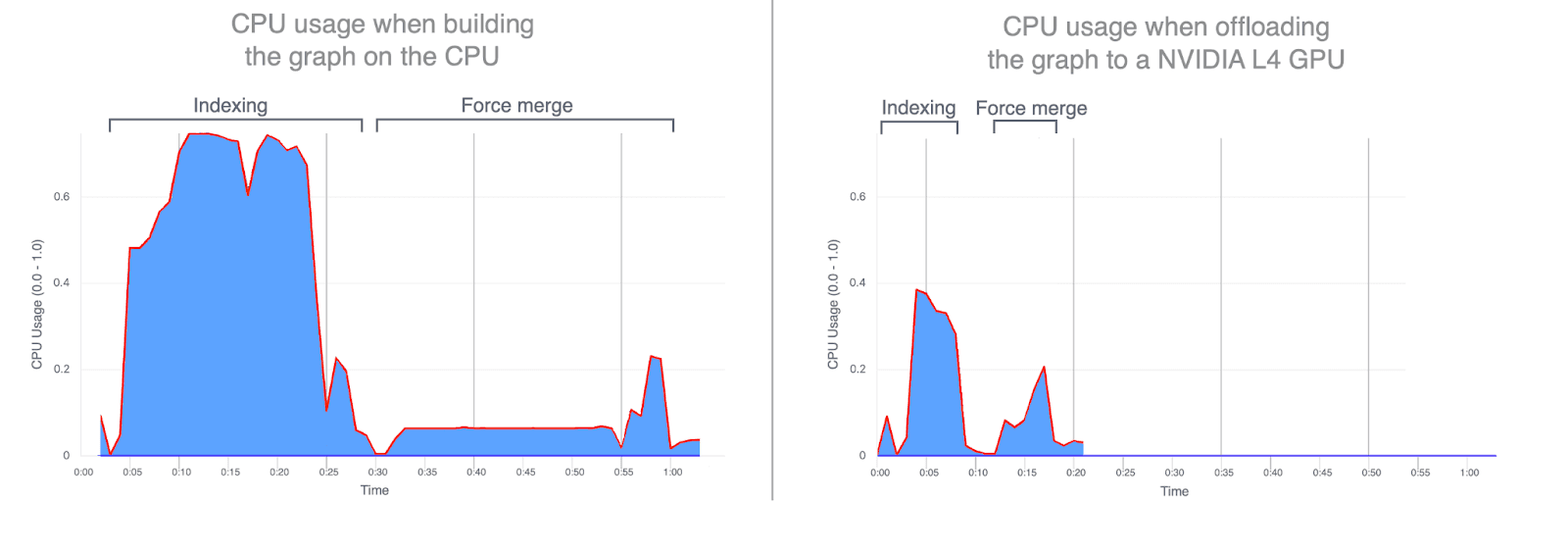
- CPU 使用率:将图构建任务分流到 GPU,可显著降低 CPU 的平均和峰值利用率。以下图表展示了索引和合并期间的 CPU 使用情况,凸显了在 GPU 上运行这些操作时 CPU 使用率的显著降低。GPU 索引期间降低 CPU 使用率,可释放 CPU 周期并重新分配,从而提升搜索性能。
- 召回率:在 CPU 与 GPU 的运行结果中,准确性几乎一致,而 GPU 所构建的图在召回率方面略胜一筹。
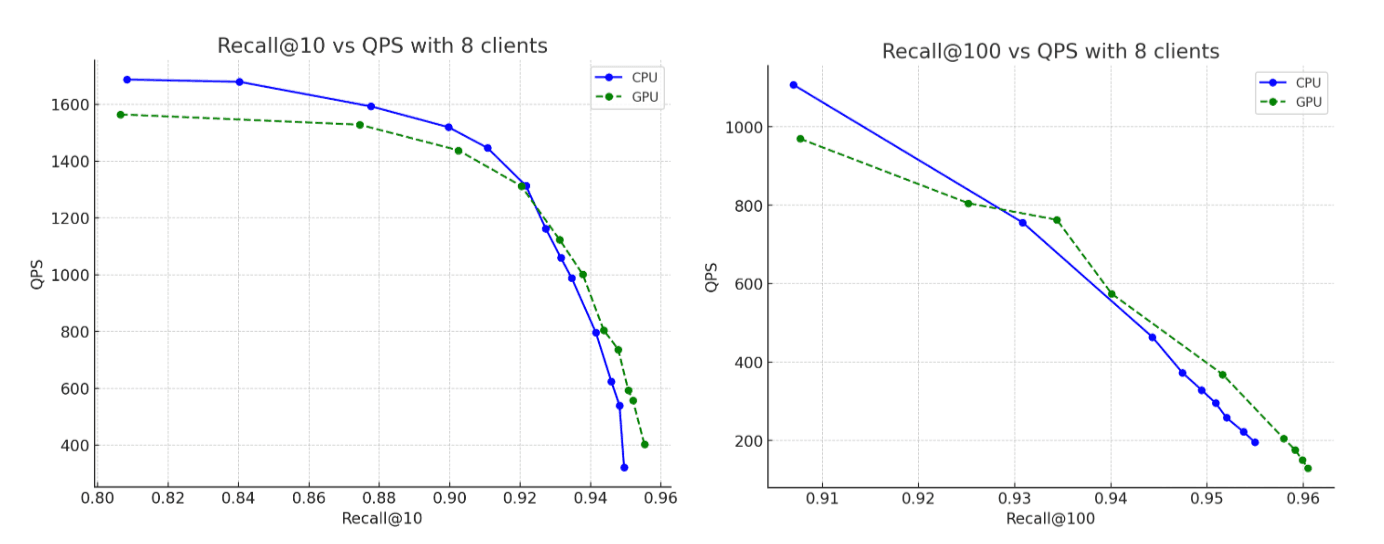
再从价格这个维度来进行比较
前面的对比特意选用了相同的硬件配置,唯一的区别只是索引时是否启用 GPU。这种设置有助于单独考察计算性能的影响,不过也可以从成本角度来进行对比。
在与 GPU 加速配置大致相同的按小时费用下,可以搭建一套仅使用 CPU 的环境,其 CPU 和内存资源大约是前者的两倍:32 个 vCPU(AMD EPYC)和 64 GB RAM,因而可将索引线程数量增加到 16
为了保持比较的公平和一致性,我们在 AWS g6.8xlarge 实例上运行了这个仅 CPU 的实验,并且明确禁用了 GPU。这使我们能够在评估 GPU 加速与仅 CPU 索引的成本-性能权衡时,保持所有其他硬件特性不变。
正如您所预期的那样,更强大的 CPU 实例与上述部分的基准测试相比,性能确实有所提高。然而,将这一性能更强的 CPU 实例与最初的 GPU 加速结果进行对比后可以看到,GPU 依然带来显著性能提升:索引吞吐量提高约 5 倍,强制合并阶段加速约 6 倍,同时构建的图其召回率最高可达 95%。
结论
在端到端场景中,使用 NVIDIA cuVS 进行的 GPU 加速使索引吞吐量提高了近 12 倍,将强制合并延迟降低到原来的 1/7,同时显著降低了 CPU 利用率。这表明向量索引和合并工作负载从 GPU 加速中受益显著。在成本调整后的对比中,GPU 加速依然带来显著的性能提升:索引吞吐量约提升 5 倍,强制合并操作的速度提升约 6 倍。
GPU 加速的向量索引目前计划在 Elasticsearch 9.3 的技术预览版中推出,该版本计划于 2026 年初发布。
敬请关注更多内容。
相关内容

2026年4月23日
我们如何构建 Elasticsearch simdvec,使其成为世界上速度最快的向量搜索之一
我们如何打造 Elasticsearch simdvec——这是 Elasticsearch 中每一次向量搜索查询背后的手动调优 SIMD 内核库。

如何衡量和提升 Elasticsearch 搜索召回率:通过混合搜索将召回率从 0.43 提升至 0.75
了解如何通过将 BM25 词汇搜索与 Jina AI 向量嵌入相结合来测量和提高 Elasticsearch 中的搜索召回率,并使用 rank_eval API 以实际数据验证改进效果。

基于 Elasticsearch + Jina 嵌入的无监督文档集群
一种使用 Elasticsearch 和 Jina 嵌入进行无监督文档集群的实用、可复现方法。


LINQ to Elasticsearch ES|QL:编写 C# 代码,查询 Elasticsearch
探索 Elasticsearch .NET 客户端中全新的 LINQ to Elasticsearch ES|QL 提供程序。借助该程序,您可以编写会自动转换为 ES|QL 查询的 C# 代码。