引言
在用户遍布全球的世界里,跨语言信息检索(CLIR)至关重要。CLIR 可让您以任何语言查找信息,而不是将搜索局限于单一语言,从而增强用户体验并简化操作。想象一下,在全球市场上,电子商务客户可以用自己的语言搜索商品,正确的结果就会出现,而无需提前对数据进行本地化。或者,学术研究人员可以用自己的母语搜索论文,即使资料来源是另一种语言,也会有细微差别和复杂性。
多语言文本嵌入模型让我们能够做到这一点。嵌入是一种用数字向量表示文本含义的方法。设计这些向量的目的是让含义相似的文本在高维空间中彼此靠近。多语言文本嵌入模型专门用于将不同语言中具有相同含义的单词和短语映射到相似的向量空间中。
开源的多语言 E5 等模型是在海量文本数据的基础上进行训练的,通常使用对比学习等技术。在这种方法中,模型学会区分意义相似的文本对(正对)和意义不同的文本对(负对)。对模型进行训练,以调整其产生的向量,从而使正向配对之间的相似性最大化,反向配对之间的相似性最小化。对于多语言模型,这些训练数据包括不同语言的文本对,这些文本对互为翻译,从而使模型能够学习多种语言的共享表示空间。由此产生的嵌入结果可用于各种 NLP 任务,包括跨语言搜索,在跨语言搜索中,文本嵌入之间的相似性可用于查找相关文档,而不受查询语言的限制。
多语言矢量搜索的优势
- 细致入微:矢量搜索擅长捕捉语义,超越关键词匹配。这对于需要理解语境和语言微妙之处的任务至关重要。
- 跨语言理解:即使查询和文档使用不同的词汇,也能跨语言进行有效的信息检索。
- 相关性:通过关注查询和文档之间的概念相似性,提供更相关的结果。
例如,一位学术研究人员正在研究"社交媒体对不同国家政治话语的影响" 。通过矢量搜索,他们可以输入"l'impatto dei social media sul discorso politico" (意大利文) 或"ảnh hưởng của mạng xã hội đối với diễn ngôn chính trị" (越南文) 等查询,并找到相关的英文论文、西班牙语或任何其他索引语言的相关论文。这是因为矢量搜索可以识别讨论社交媒体对政治影响这一概念的论文,而不仅仅是包含确切关键词的论文。这大大提高了他们研究的广度和深度。
开始使用
下面介绍如何使用 Elasticsearch(开箱即用的 E5 模型)设置 CLIR。我们将使用开源的多语言 COCO 数据集(其中包含多种语言的图片说明)来帮助我们可视化两种类型的搜索:
- 一个英语数据集上的其他语言查询和搜索词,以及
- 在包含多语言文档的数据集上进行多语言查询。
然后,我们将利用混合搜索和重新排序的功能,进一步改进搜索结果。
准备工作
- Python 3.6+
- Elasticsearch 8+
- Elasticsearch Python 客户端: pip install elasticsearch
数据集
COCO 数据集是一个大型字幕数据集。数据集中的每张图片都有多种不同语言的标题,每种语言都有几种翻译。为便于演示,我们将把每份译文作为单独的文件进行索引,并附上第一份可用的英文译文以供参考。
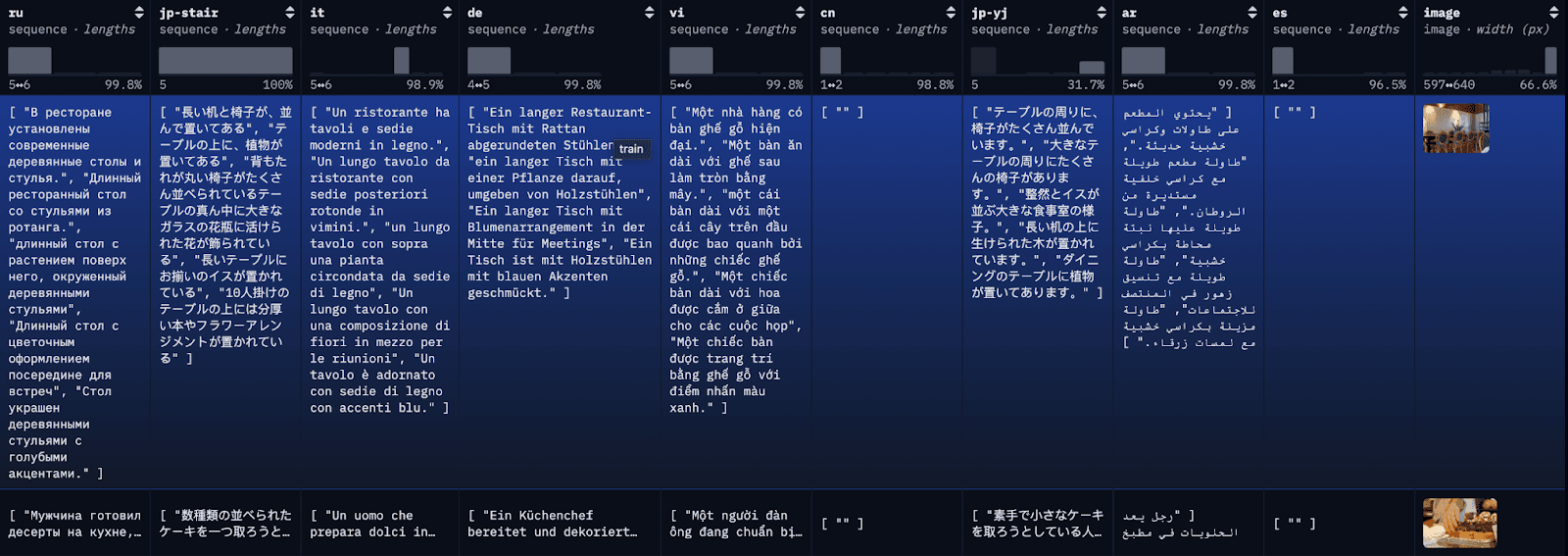
步骤 1:下载多语种 COCO 数据集
为了简化博客并方便阅读,我们在这里通过简单的 API 调用,将 restval 的前 100 行加载到本地 JSON 文件中。或者,您也可以使用 HuggingFace 的库数据集来加载整个数据集或数据集的子集。
如果数据成功加载到 JSON 文件中,你应该会看到类似下面的内容:
Data successfully downloaded and saved to multilingual_coco_sample.json
第 2 步:(启动 Elasticsearch)并在 Elasticsearch 中编制数据索引
a) 启动本地 Elasticsearch 服务器。
b) 启动 Elasticsearch 客户端。
c) 指数数据
数据编入索引后,您应该会看到类似下面的内容:
Successfully bulk indexed 4840 documents
Indexing complete!
步骤 3:部署 E5 训练模型
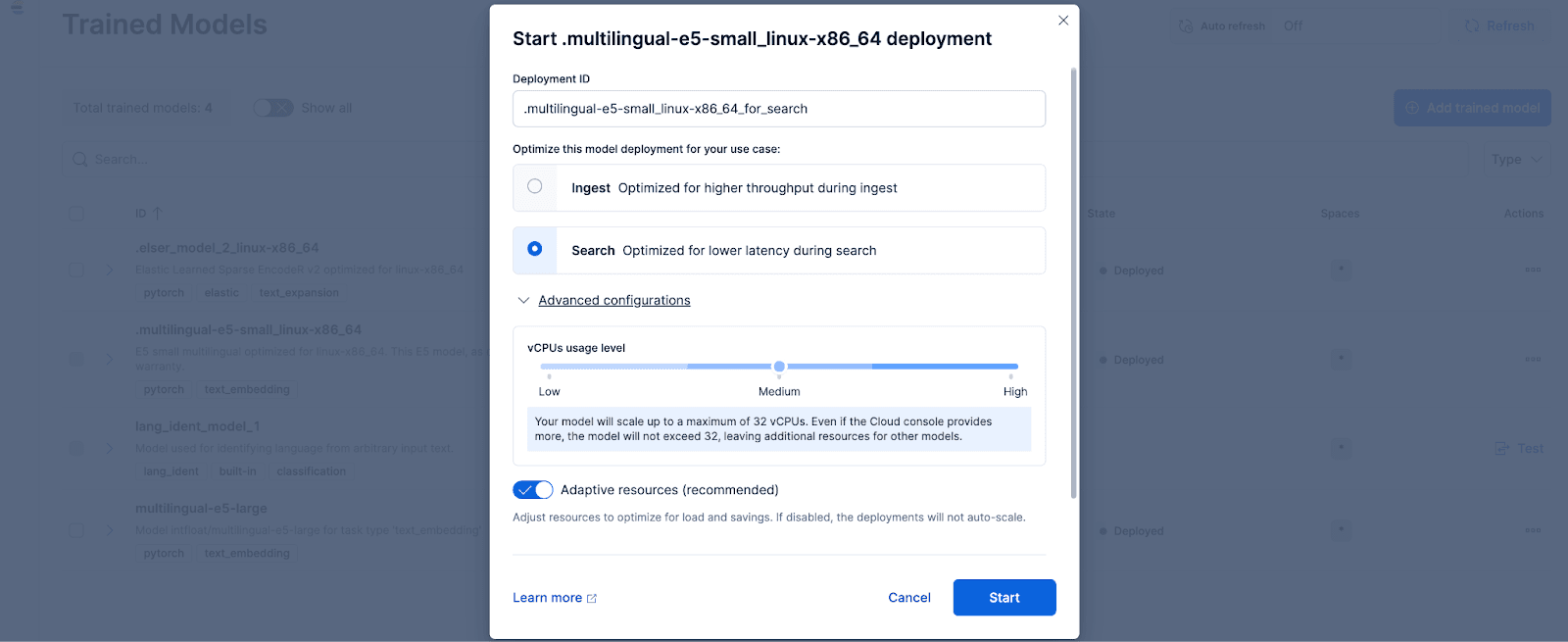
在 Kibana 中,导航到 "堆栈管理> 训练模型"页面,然后单击 "部署.multilingual-e5-small_linux-x86_64选择。这款 E5 机型是为 linux-x86_64 优化的小型多语言机型,开箱即可使用。单击 "部署 "将显示一个屏幕,您可以在此调整部署设置或 vCPU 配置。为简单起见,我们将使用默认选项,并选择自适应资源,它将根据使用情况自动调整部署规模。
如果您想使用其他文本嵌入模型,也可以选择使用。例如,要使用 BGE-M3,可以使用Elastic 的 Eland Python 客户端从 HuggingFace 导入模型。
然后,导航到 "训练有素的模型 "页面,使用所需的配置部署导入的模型。
第 4 步:利用已部署的模型对原始数据进行矢量化或创建嵌入模型
要创建嵌入模型,我们首先需要创建一个摄取管道,使我们能够获取文本并通过推理文本嵌入模型运行。您可以在 Kibana 的用户界面或通过 Elasticsearch 的应用程序接口进行此操作。
要通过 Kibana 界面完成此操作,在部署训练模型后,单击测试 按钮。这将使您能够测试和预览生成的嵌入式内容。为coco 索引创建一个新的数据视图,将数据视图设置为新创建的 coco 数据视图,并将字段设置为description ,因为这是我们要生成嵌入的字段。
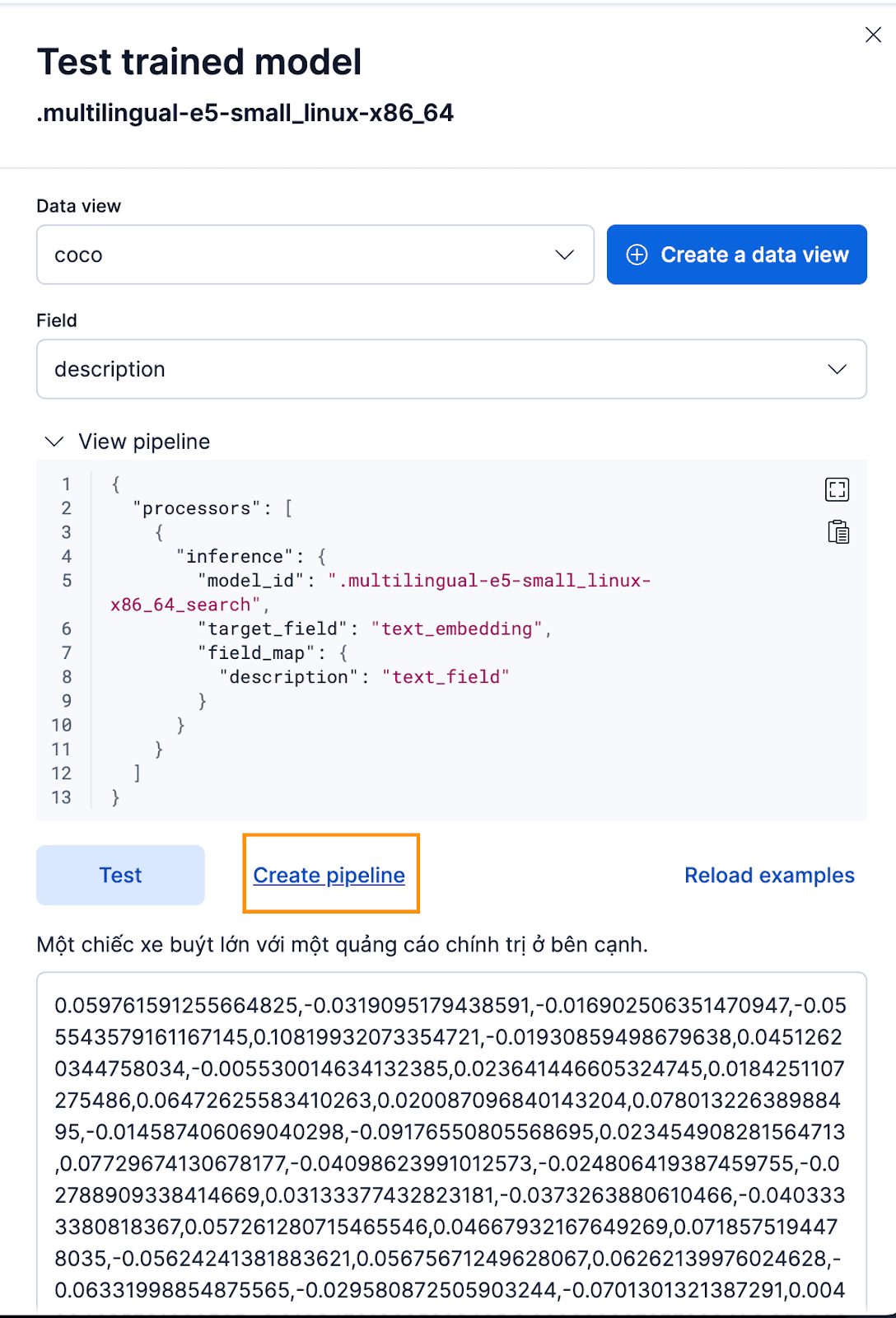
效果很好!现在,我们可以继续创建摄取管道,并重新为原始文档建立索引,将它们通过管道,然后用嵌入创建一个新索引。单击 "创建管道"即可实现这一功能,它将引导您完成管道创建过程,并自动填充所需的处理器,帮助您创建嵌入。
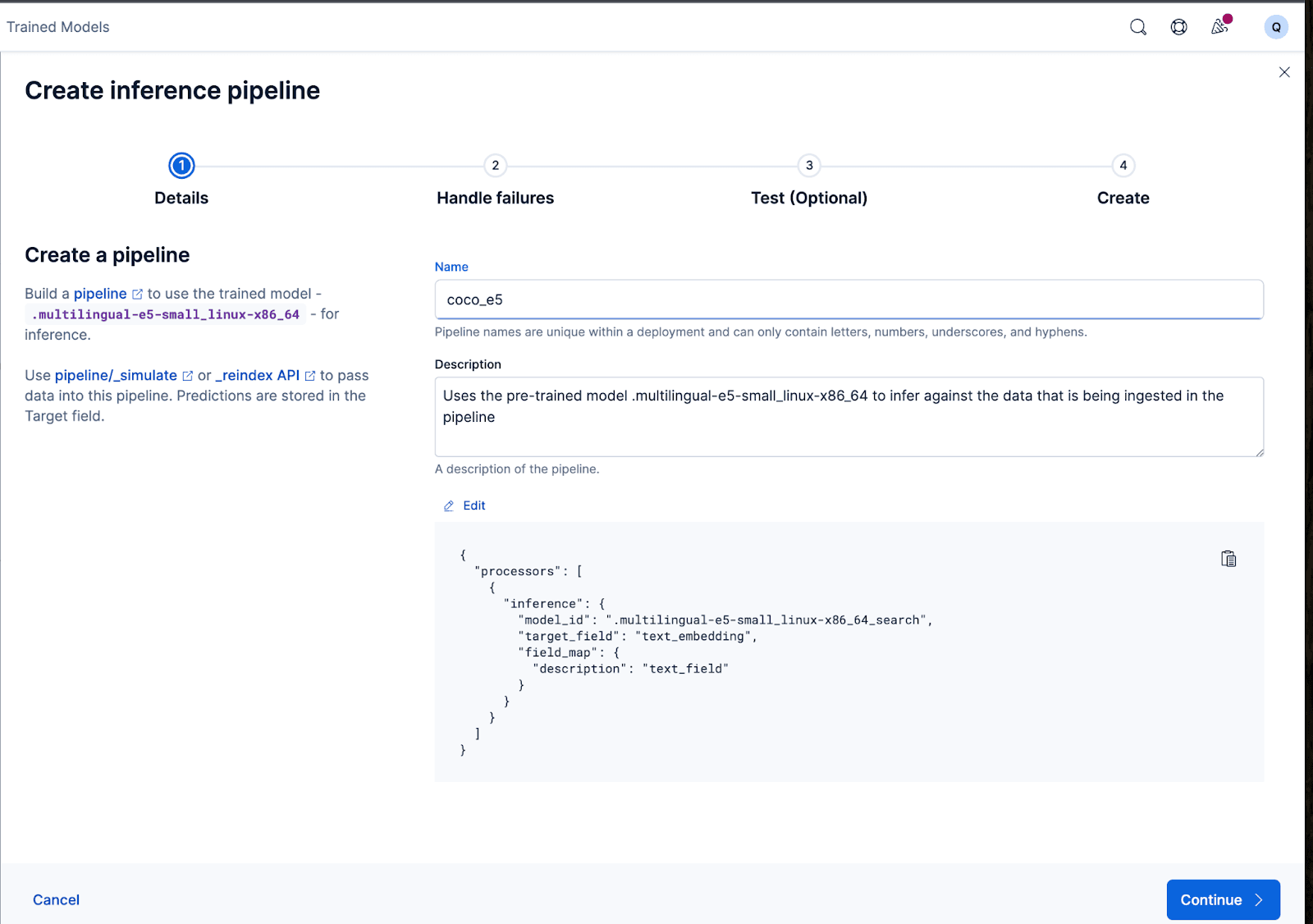
向导还可以自动填充所需的处理器,以便在摄取和处理数据时处理故障。
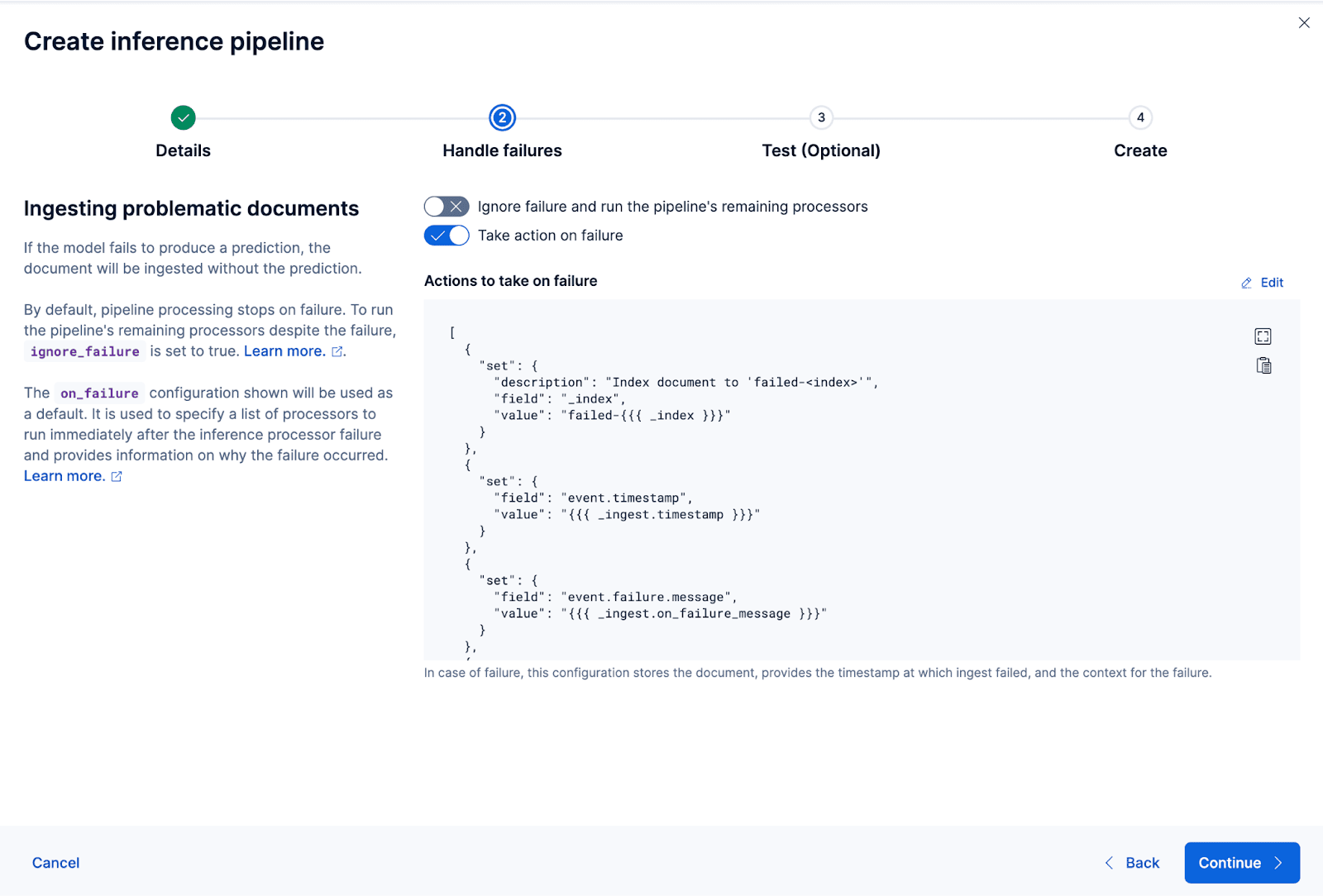
现在让我们创建摄取管道。我将管道命名为coco_e5 。管道创建成功后,可以立即使用管道生成嵌入,方法是将原始索引数据重新索引到向导中的新索引。单击 "重新索引 "启动该过程。
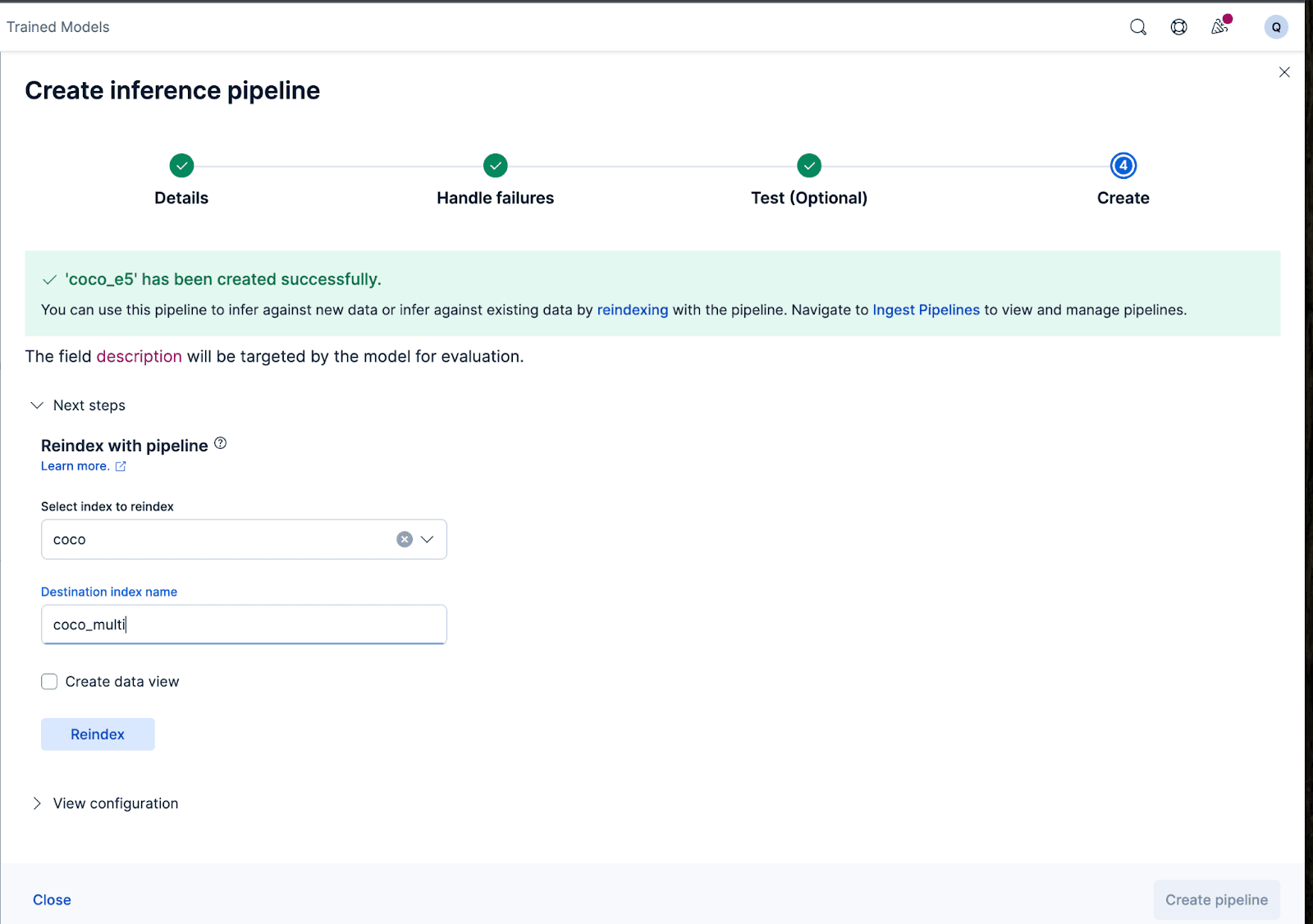
对于更复杂的配置,我们可以使用 Elasticsearch API。
对于某些模型,由于训练模型的方式不同,我们可能需要在生成嵌入之前在实际输入中预置或附加某些文本;否则,我们将看到性能下降。
例如,在使用 e5 时,模型希望输入文本跟随 "passage:{content of passage}".让我们利用摄取管道来实现这一目标:我们将创建一个新的摄取管道vectorize_descriptions。在此流程中,我们将创建一个新的临时temp_desc 字段,在 "passage:" 添加到description 文本中,通过模型运行temp_desc 以生成文本嵌入,然后删除temp_desc 。
此外,我们可能还想为生成的向量指定量化类型。默认情况下,Elasticsearch 使用int8_hnsw ,但在这里,我需要更好的二进制量化(或bqq_hnsw ),它将每个维度降低到一位精度。这样,内存占用减少了 96% (或 32 倍),但精度却提高了。我之所以选择这种量化类型,是因为我知道稍后会使用重新anker 来改善精度损失。
为此,我们将创建一个名为coco_multi 的新索引,并指定映射。这里的奥妙在于 vector_description 字段,我们在其中指定index_options的类型为bbq_hnsw。
现在,我们可以将原始文档重新索引到新的索引中,我们的摄取管道将对描述字段进行 "矢量化 "或创建嵌入。
就是这样!我们已经成功地利用 Elasticsearch 和 Kibana 部署了一个多语言模型,并逐步了解了如何通过 Kibana 用户界面或 Elasticsearch API 利用 Elastic 数据创建向量嵌入。在本系列的第二部分,我们将探讨使用多语言模型的结果和细微差别。同时,您可以 创建一个 自己的 云集群 ,在您选择的语言和数据集上 使用我们开箱即用的 E5 模型 尝试 多语言语义搜索 。
相关内容

2026年5月18日
在 Elasticsearch 中使用确定性防护措施实现智能 AI 搜索,以确保查询安全执行
当 LLM 直接生成查询时,智能体 AI 搜索系统常常会失败。了解确定性防护措施和控制平面架构如何通过 Elasticsearch 实现安全、可靠且受治理的查询执行。

2026年5月11日
个性化电子商务搜索:整合购买历史记录和用户群组
了解如何在 Elasticsearch 中打造个性化电商搜索体验,同时不破坏治理机制。本文介绍了如何提升购物者曾购买过的产品,以及如何根据用户资料启用针对特定用户群组的策略。

2026年5月4日
用于电子商务搜索治理的 Elasticsearch percolator:将模糊查询转化为受控检索策略
了解如何使用 Elasticsearch percolator 实现搜索治理。在本博客中,我们将概述在生产环境中创建受治理的策略引擎以及制定受控检索策略所需的模式。

