有了Elastic Open Web Crawler及其 CLI 驱动的架构,现在就可以非常直接地实现版本化爬虫配置和具有本地测试功能的 CI/CD 管道。
传统上,管理爬虫是一个手动且容易出错的过程。这涉及到直接在用户界面上编辑配置,以及克隆抓取配置、回滚、版本控制等问题。将爬虫配置视为代码可以解决这个问题,因为它提供了我们在软件开发中期待的相同优势:可重复性、可追溯性和自动化。
这种工作流程可以更轻松地将开放式网络爬虫带入您的 CI/CD 流水线,以进行回滚、备份和迁移--这些任务在使用早期的弹性爬虫(如弹性网络爬虫或应用程序搜索爬虫)时要棘手得多。
在本文中,我们将学习如何:
- 使用 GitHub 管理我们的抓取配置
- 在部署前进行本地设置以测试管道
- 创建一个生产设置,以便在每次向主分支推送更改时使用新设置运行网络爬虫
你可以在这里找到项目仓库。 在撰写本文时,我使用的是 Elasticsearch 9.1.3 和 Open Web Crawler 0.4.2。
准备工作
- Docker 桌面
- Elasticsearch 实例
- 可通过 SSH 访问的虚拟机(如 AWS EC2)并安装 Docker
步长
- 文件夹结构
- 履带配置
- Docker-compose 文件(本地环境)
- Github 操作
- 本地测试
- 部署到 prod
- 进行更改和重新部署
文件夹结构
本项目的文件结构如下:
履带配置
在crawler-config.yml, 下,我们将填写以下内容:
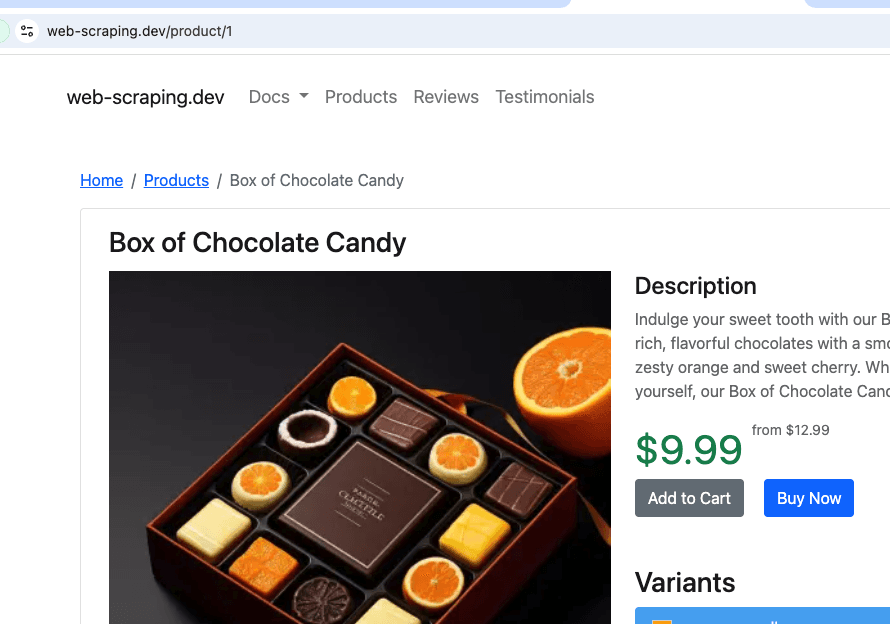
这将从https://web-scraping.dev/products 抓取,这是一个产品模拟网站。我们只会抓取前三个产品页面。max_crawl_depth 设置将通过不打开其中的链接,防止爬虫发现比定义为seed_urls 的页面更多的页面。
Elasticsearchhost 和api_key 将根据我们运行脚本的环境动态填充。
Docker-compose 文件(本地环境)
对于本地docker-compose.yml, ,我们将部署爬虫和单个 Elasticsearch 集群 + Kibana,这样在部署到生产环境之前,我们就可以轻松查看爬虫结果。
请注意爬虫是如何等待 Elasticsearch 准备好运行的。
Github 操作
现在,我们需要创建一个 GitHub Action,它将复制新设置,并在每次推送到 main 时在虚拟机中运行爬虫。这样就能确保我们始终部署有最新的配置,而无需手动进入虚拟机更新文件和运行爬虫。我们将使用 AWS EC2 作为虚拟机提供商。
第一步是将主机 (VM_HOST) 、机器用户 (VM_USER) 、SSH RSA 密钥 (VM_KEY) 、Elasticsearch 主机 (ES_HOST) 和 Elasticsearch API 密钥 (ES_API_KEY) 添加到 GitHub Action secrets 中:
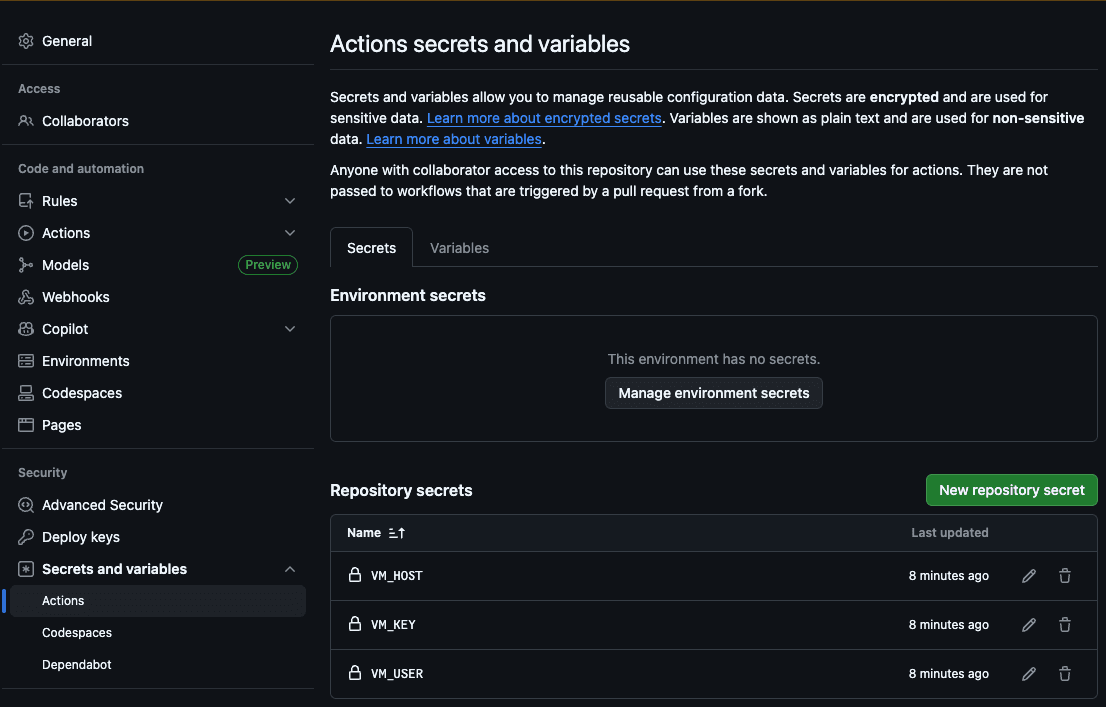
这样,操作就能访问我们的服务器,将新文件复制过来并运行抓取。
现在,让我们创建.github/workflows/deploy.yml 文件:
每次我们向爬虫配置文件推送更改时,该操作都会执行以下步骤:
- 在 yml 配置中填入 Elasticsearch 主机和 API 密钥
- 将配置文件夹复制到我们的虚拟机
- 通过 SSH 连接到我们的虚拟机
- 使用我们刚从 repo 复制的配置运行抓取程序
本地测试
为了在本地测试爬虫,我们创建了一个 bash 脚本,将 Elasticsearch 主机与 Docker 中的本地主机进行填充,然后开始爬行。您可以运行./local.sh 来执行它。
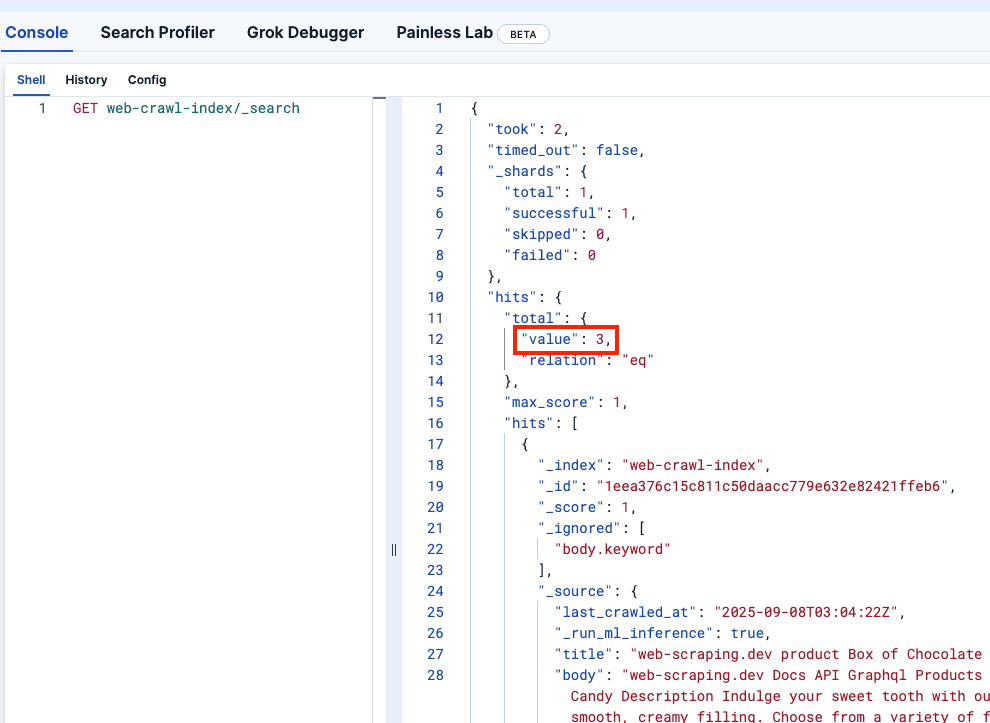
让我们看看 Kibana DevTools,以确认 web-crawler-index 的填充是否正确:
部署到 prod
现在,我们准备推送到主分支,这将在虚拟机中部署爬虫,并开始向无服务器 Elasticsearch 实例发送日志。
这将触发 GitHub 操作,在虚拟机中执行部署脚本并开始抓取。
您可以访问 GitHub 仓库并访问 "操作 "选项卡,确认操作已执行:

进行更改和重新部署
您可能已经注意到,每个产品的price 都是文档正文字段的一部分。如果能将价格存储在一个单独的字段中,我们就可以根据它运行筛选器,这将是最理想的。
让我们在crawler.yml 文件中添加这一更改,使用提取规则从product-price CSS 类中提取价格:
我们还可以看到,价格包含一个美元符号 ($),如果要运行范围查询,我们必须去掉这个符号。为此,我们可以使用摄取管道。请注意,我们在上面的新爬虫配置文件中引用了它:
我们可以在生产 Elasticsearch 集群中运行该命令。对于开发进程,由于它是短暂的,我们可以通过添加以下服务,使管道创建成为docker-compose.yml 文件的一部分。请注意,我们还为爬虫服务添加了一个depends_on ,这样它就能在管道创建成功后启动。
现在让我们运行`./local.sh` 查看本地的变化:

太好了!现在让我们推动变革:
要确认一切正常,可以检查生产的 Kibana,它应该会反映这些更改,并将价格显示为一个不带美元符号的新字段。
结论
Elastic Open Web Crawler 允许您将爬虫作为代码进行管理,这意味着您可以自动执行从开发到部署的整个流程,并以编程方式添加短暂的本地环境和针对爬虫数据的测试。
我们邀请您克隆官方资源库,并开始使用此工作流程为自己的数据编制索引。您还可以阅读本文,了解如何在爬虫生成的索引上运行语义搜索。
相关内容

2026年5月18日
在 Elasticsearch 中使用确定性防护措施实现智能 AI 搜索,以确保查询安全执行
当 LLM 直接生成查询时,智能体 AI 搜索系统常常会失败。了解确定性防护措施和控制平面架构如何通过 Elasticsearch 实现安全、可靠且受治理的查询执行。

2026年5月11日
个性化电子商务搜索:整合购买历史记录和用户群组
了解如何在 Elasticsearch 中打造个性化电商搜索体验,同时不破坏治理机制。本文介绍了如何提升购物者曾购买过的产品,以及如何根据用户资料启用针对特定用户群组的策略。

2026年5月4日
用于电子商务搜索治理的 Elasticsearch percolator:将模糊查询转化为受控检索策略
了解如何使用 Elasticsearch percolator 实现搜索治理。在本博客中,我们将概述在生产环境中创建受治理的策略引擎以及制定受控检索策略所需的模式。

