矢量搜索不足以找到相关结果。使用过滤标准非常常见,这有助于缩小搜索结果的范围并过滤掉不相关的结果。
了解筛选在矢量搜索中是如何工作的,将有助于你平衡性能和召回率之间的权衡,并发现一些优化方法,使矢量搜索在使用筛选时性能更佳。
为什么要过滤?
矢量搜索彻底改变了我们在大型数据集中查找相关信息的方式,使我们能够发现与查询语义相似的项目。
然而,仅仅找到相似的物品是不够的。我们经常需要根据特定的标准或属性来缩小搜索结果的范围。
想象一下,您正在一家电子商务商店中搜索产品。纯矢量搜索可能会显示视觉上相似的商品,但您可能还想根据价格范围、品牌、可用性或客户评价进行筛选。如果不进行筛选,您就会看到大量类似的产品,很难准确找到您要找的产品。
过滤功能可对搜索结果进行精确控制,确保检索到的项目不仅在语义上一致,而且符合所有必要的要求。这将带来更加准确、高效和用户友好的搜索体验。
这正是 Elasticsearch 和 Apache Lucene 的优势所在--对各种数据类型进行有效过滤是它们与其他矢量数据库的主要区别之一。
精确矢量搜索的筛选
进行精确矢量搜索主要有两种方法:
- 为 dense_vector 字段使用
flat索引类型。这使得knn搜索使用精确搜索而不是近似搜索。 - 使用 script_score 查询 ,该 查询 使用向量函数计算分数。这可用于任何索引类型。
在执行精确向量搜索时,所有向量都会与查询进行比较。在这种情况下,过滤将有助于提高性能,因为只需要比较通过过滤的向量。
这不会影响结果质量,因为所有向量都会被考虑在内。我们只是提前过滤掉不感兴趣的结果,从而减少操作次数。
这一点非常重要,因为当应用筛选器得到的文档数量很少时,执行精确搜索比近似搜索更有效。
经验法则是,当通过过滤器的文件少于 10k 时,应使用精确搜索。BBQ索引的比较速度更快,因此当基于索引的数据少于 100k 时,使用精确搜索是合理的。详情请查看本博文。
如果您的筛选器总是限制性很强,您可以考虑使用flat 索引类型而不是基于 HNSW 的索引类型,将索引重点放在精确搜索而不是近似搜索上。更多详情,请参阅index_options 的属性。
近似矢量搜索的筛选
在执行近似向量搜索时,我们需要用结果的准确性来换取性能。像 HNSW 这样的矢量搜索数据结构可在数百万个矢量上高效搜索近似近邻。它们的重点是通过进行最少的向量比较来检索最相似的向量,而向量比较的计算成本很高。
这意味着其他过滤属性不属于矢量数据的一部分。不同的数据类型有自己的索引结构,如术语字典、发布列表和 doc 值等,可以有效地查找和过滤这些数据。
既然这些数据结构与矢量搜索机制是分开的,那么我们如何将过滤功能应用于矢量搜索呢?有两种选择:在矢量搜索后应用过滤器(后过滤)或在矢量搜索前应用过滤器(预过滤)。
每种方案都各有利弊。让我们深入了解它们!
后过滤
后过滤在矢量搜索完成后应用过滤器。这意味着,在找到前 k 个最相似的向量结果后,才会应用筛选器。
显然,在对结果进行筛选后,我们可能会得到少于 k 个结果。当然,我们可以从矢量搜索中获取更多的结果(k 值更高),但我们无法确定在应用过滤器后是否会得到 k 或更多的结果。
后过滤的优势在于它不会改变矢量搜索的运行时行为--矢量搜索不知道过滤的存在。但是,它确实会改变检索结果的最终数量。
下面是使用knn 查询进行后过滤的示例。检查过滤子句是否与 knn 查询分开:
使用后置过滤器还可对 knn 搜索进行后置过滤:
请记住,您需要在 knn 搜索中使用明确的后置过滤器部分。如果不使用后置过滤器,knn 搜索 会将最近邻 搜索 结果 与其他查询或过滤器 结合起来 ,而不是进行后置过滤器。
预过滤
在矢量搜索前应用筛选器将首先检索出满足筛选条件的文档,然后将这些信息传递给矢量搜索。
Lucene 使用BitSets高效地存储满足筛选条件的文档。然后,矢量搜索会遍历 HNSW 图,并将满足条件的文档考虑在内。在将候选文件添加到结果中之前,它会检查该候选文件是否包含在有效文件的 BitSet 中。
不过,即使候选文件不是有效文件,也必须对其进行探索并与查询进行比较。HNSW 的有效性取决于图中向量之间的联系--如果我们停止探索某个候选向量,就意味着我们可能也会跳过它的邻近向量。
就像开车去加油站一样。如果放弃任何一条没有加油站的道路,您就不可能到达目的地。其他道路可能不是你所需要的,但它们将你连接到目的地。HNSW 图形上的向量也是如此!
因此,应用预过滤比不应用过滤的性能要低。我们需要对搜索中访问的所有向量进行处理,并丢弃不符合筛选条件的向量。我们正在做更多的工作,花更多的时间来获得最高 K 值的结果。
下面是在 Elasticsearch 查询 DSL 中进行预过滤的示例。检查过滤子句是否已成为 knn 部分的一部分:
预过滤优化
我们可以进行一些优化,以确保预过滤的性能。
如果筛选条件非常严格,我们可以切换到精确搜索。当需要比较的向量很少时,对满足筛选条件的少数文档进行精确搜索会更快。
这是Lucene和 Elasticsearch 自动应用的优化。
另一种优化方法是忽略不符合筛选条件的向量。相反,该方法会检查滤波向量的邻近向量是否通过滤波。这种方法不考虑过滤后的向量,而是继续探索与当前路径相连的向量,从而有效减少了比较次数。
这种算法就是 ACORN-1,本篇博文将详细介绍其过程。
使用文档级安全过滤
文档级别安全(DLS)是 Elasticsearch 的一项功能,可指定用户角色可检索的文档。
DLS 通过查询来执行。一个角色可以有一个与索引相关联的查询,这实际上限制了属于该角色的用户可以从索引中检索的文档。
角色查询用作过滤器,用于检索与之匹配的文档,并作为 BitSet 缓存。然后,这个 BitSet 会被用来封装底层的 Lucene 阅读器,因此只有从查询返回的文档才会被认为是实时的,也就是说,它们存在于索引中,并且没有被删除。
由于要从阅读器获取实时文档来执行 knn 查询,因此只考虑用户可用的文档。如果有预检器,DLS 文件将被 添加到 预检器 中 。
这意味着,DLS 过滤可以作为近似矢量搜索的预过滤,具有相同的性能影响和优化效果。
使用精确搜索的 DLS 与应用任何过滤器的好处相同--从 DLS 检索的文档越少,精确搜索的性能就越高。还要考虑 DLS 返回的文档数量--如果 DLS 的作用非常有限,可以考虑使用精确搜索而不是近似搜索。
基准
在 Elasticsearch,我们希望确保矢量搜索过滤的效率。我们有一个专门的向量过滤基准,通过不同的过滤执行近似向量搜索,以确保向量搜索尽可能快地检索到相关结果。
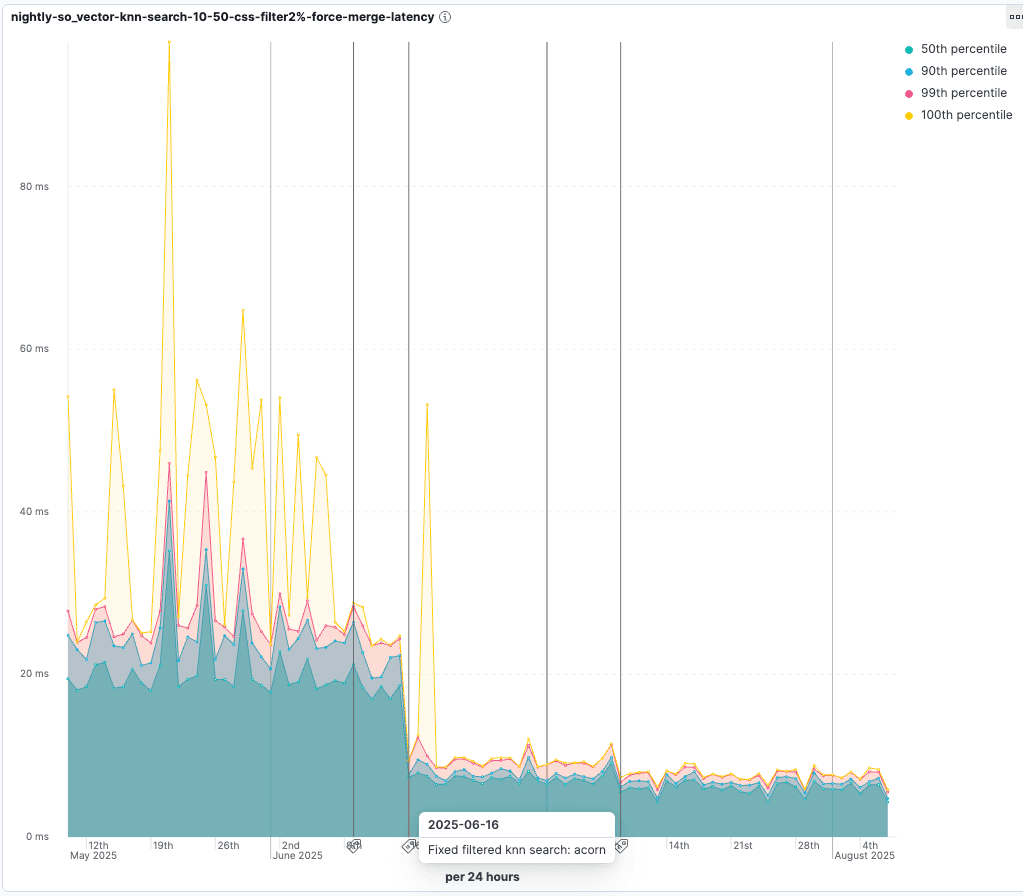
查看 ACORN-1 推出时的改进情况。在只有 2% 个向量通过过滤器的测试中,查询延迟时间缩短到原来的 55% :
结论
过滤是搜索不可或缺的一部分。确保过滤在矢量搜索中的性能,并了解权衡和优化,是高效和准确搜索的关键所在。
过滤会影响向量搜索的性能:
- 使用过滤功能时,精确搜索速度更快。如果过滤条件足够严格,应考虑使用精确搜索而不是近似搜索。这是 Elasticsearch 的自动优化功能。
- 使用预过滤时,近似搜索速度较慢。通过预过滤,我们可以得到与过滤器匹配的前 k 个结果,但搜索速度会减慢。
- 后过滤并不一定能检索到前 k 个结果,因为在应用过滤器时,这些结果可能已被过滤器过滤。
快乐过滤
相关内容

2026年4月23日
我们如何构建 Elasticsearch simdvec,使其成为世界上速度最快的向量搜索之一
我们如何打造 Elasticsearch simdvec——这是 Elasticsearch 中每一次向量搜索查询背后的手动调优 SIMD 内核库。

如何衡量和提升 Elasticsearch 搜索召回率:通过混合搜索将召回率从 0.43 提升至 0.75
了解如何通过将 BM25 词汇搜索与 Jina AI 向量嵌入相结合来测量和提高 Elasticsearch 中的搜索召回率,并使用 rank_eval API 以实际数据验证改进效果。

基于 Elasticsearch + Jina 嵌入的无监督文档集群
一种使用 Elasticsearch 和 Jina 嵌入进行无监督文档集群的实用、可复现方法。


LINQ to Elasticsearch ES|QL:编写 C# 代码,查询 Elasticsearch
探索 Elasticsearch .NET 客户端中全新的 LINQ to Elasticsearch ES|QL 提供程序。借助该程序,您可以编写会自动转换为 ES|QL 查询的 C# 代码。