自 8.16 版起,用户可以配置将长文档导入语义文本字段时使用的分块策略。从 9.1 / 8.19 版开始,我们引入了一种新的可配置递归分块策略,使用正则表达式列表对文档进行分块。分块的目的是将长文档分割成囊括相关内容的部分。我们现有的策略会按单词/句子的粒度分割文本,但以结构化格式编写的文档(例如:"......")则不会这样做。Markdown)通常会在由一些分隔字符串定义的部分内包含相关内容(例如:"......")。标题)。对于这些类型的文档,我们正在引入递归分块策略,以利用结构化文档的格式来创建更好的分块!
什么是递归分块?
递归分块法会遍历所提供的分块模式列表,逐步将文档分成更小的分块,直到达到所需的最大分块大小。
如何配置递归分块?
以下是用户为递归分块提供的可配置值:
- (必填)
max_chunk_size:字块中的最大字数。 - 任选其一:
separators:用于将文档分割成块的 regex 字符串模式列表。separator_group:一个字符串,它将映射到 Elastic 定义的默认分隔符列表,用于特定类型的文档。目前,markdown和plaintext。
递归分块是如何工作的?
递归分块的过程如下:给定输入文档、max_chunk_size (以字数为单位)和分隔符字符串列表:
- 如果输入文档已经在最大分块大小范围内,则返回一个涵盖整个输入文档的分块。
- 根据分隔符的出现次数,将文本分割成潜在的文本块。对于每个潜在的数据块
- 如果潜在数据块在最大数据块大小范围内,则将其添加到要返回给用户的数据块列表中。
- 否则,从第 2 步开始重复,只使用潜在文本块中的文本,并使用列表中的下一个分隔符进行分割。如果没有其他分隔符可以尝试,就退回到基于句子的分块。
配置递归分块的示例
除了分块大小,递归分块的主要配置是选择应使用哪些分隔符来分割文档。如果您不确定从哪里开始,Elasticsearch 提供了一些默认的分离器组,可用于常见的使用情况。
利用分离器组
要使用分隔组,只需在配置分块设置时提供要使用的组名即可。例如
这样就可以利用分隔符列表["(?<!\\n)\\n\\n(?!\\n)", "(?<!\\n)\\n(?!\\n)")] 来实现递归分块策略。对于一般的纯文本应用程序,这种方法效果很好,可以在 2 个换行符后再分隔出 1 个换行符。
我们还提供一个分隔符组markdown ,它将利用分隔符列表:
这个分隔符列表可以很好地适用于一般的标记符使用情况,在 6 个标题层次和分节符上分别进行分隔。
创建资源(推理端点/语义文本字段)时,与当时分隔符组相对应的分隔符列表将存储在您的配置中。如果以后更新了分隔符组,也不会改变已创建资源的行为。
使用自定义分隔符列表
如果预定义的分隔符组不适合您的使用情况,您可以定义一个符合您需求的自定义分隔符列表。请注意,可以在分隔符列表中提供正则表达式。以下是使用自定义分隔符配置分块设置的示例:
上述分块策略将在 2 个换行符、1 个换行符和一个字符串“<my-custom-separator>” 上进行分割。
递归分块的实际应用示例
让我们来看一个递归分块的实例。在本示例中,我们将使用以下分块设置和自定义分隔符列表,使用顶部两层标题分割标记符文档:
让我们来看看一个简单的未分块 Markdown 文档:

现在,让我们使用上面定义的分块设置对文档进行分块:
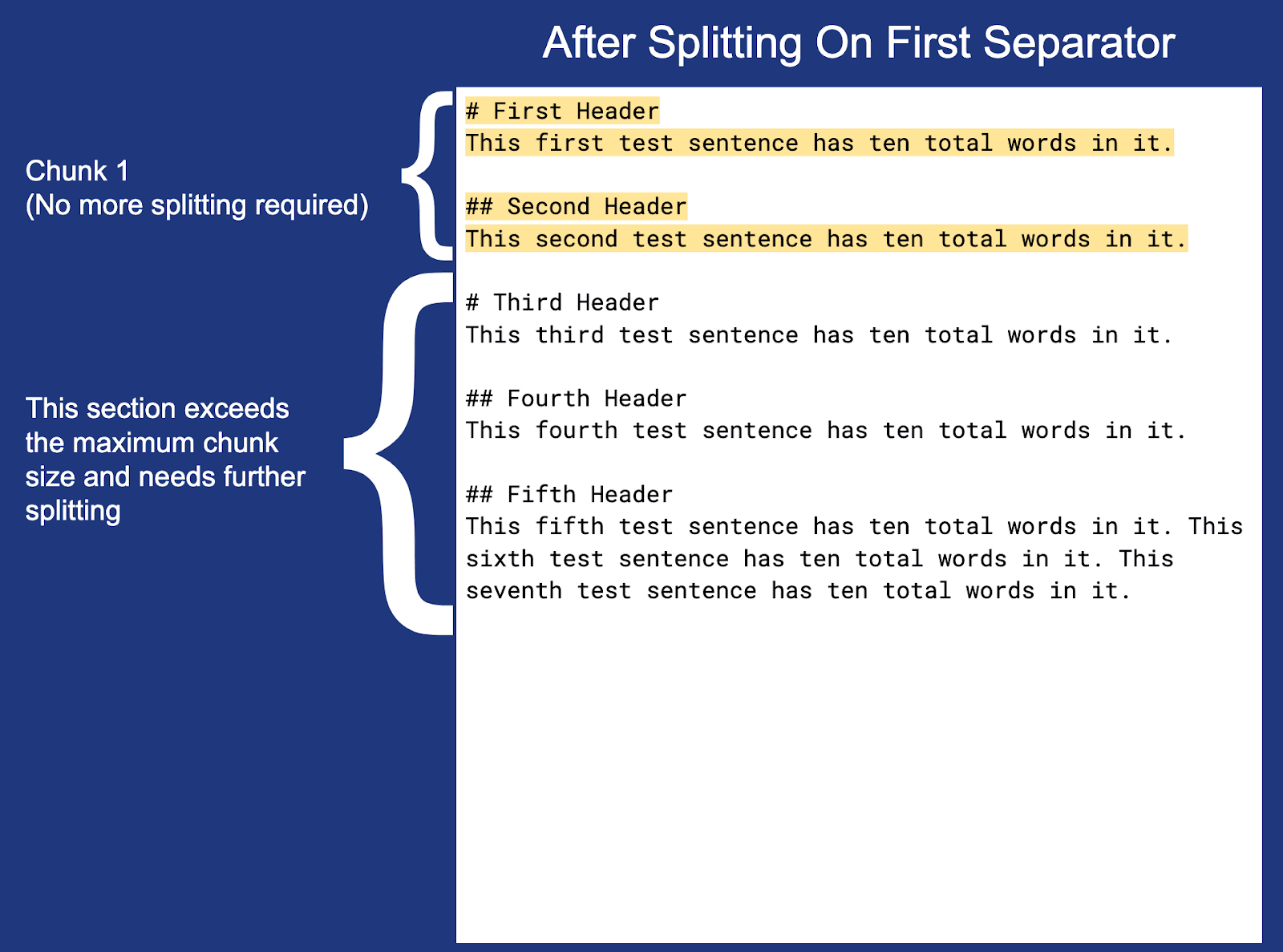

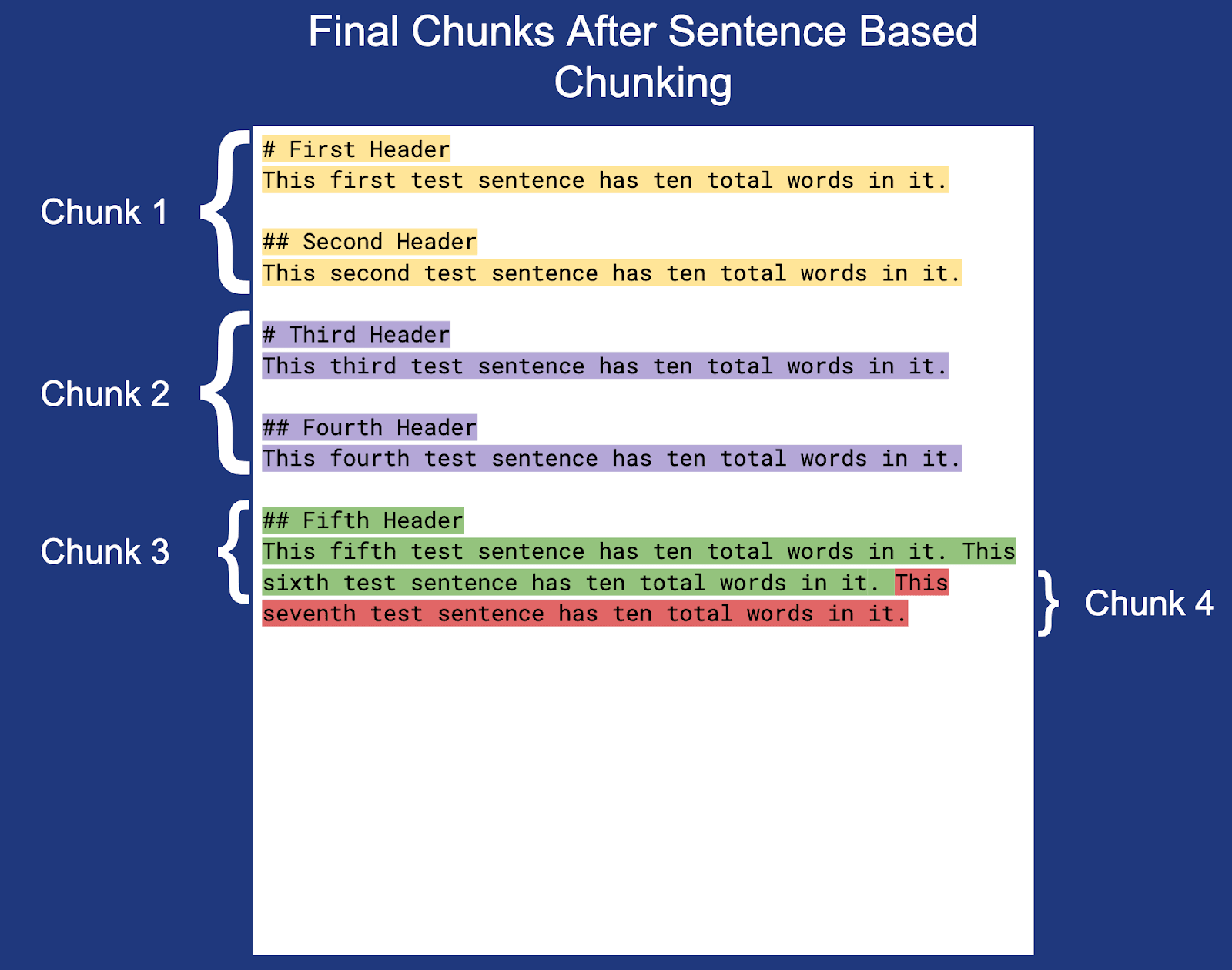
注意:每个分块(分块 3 除外)末尾的换行符不会突出显示,而是包含在实际分块边界内。
今天就开始使用递归分块技术!
有关使用该功能的更多信息,请查看有关配置分块设置的文档。
相关内容

用描述代替手动绘制:通过 MCP 和 ES|QL 构建 AI 原生 Kibana 仪表板。
从提示词到仪表板了解如何使用 example-mcp-dashbuilder 通过自然语言构建 Kibana 仪表板:这是一款开源 MCP 应用,能够编写 ES|QL 查询、创建交互式图表,并将功能完整的仪表板直接导出到 Kibana。

2026年4月23日
我们如何构建 Elasticsearch simdvec,使其成为世界上速度最快的向量搜索之一
我们如何打造 Elasticsearch simdvec——这是 Elasticsearch 中每一次向量搜索查询背后的手动调优 SIMD 内核库。