Elasticsearch에서 정렬 쿼리를 최적화하여 응답 속도 향상


 Share on Twitter
Share on Twitter트위터에서 공유하기

 Share on LinkedIn
Share on LinkedIn링크드인에서 공유하기

 Share on Facebook
Share on Facebook페이스북에서 공유하기

 Share by Email
Share by Email이메일로 공유하기

 Print this page
Print this page인쇄하기
Elasticsearch에서는 특정 필드를 기준으로 결과를 정렬하도록 요청하는 것이 매우 일반적입니다. Elastic은 정렬 쿼리를 최적화하여 응답 속도를 높이기 위해 상당한 시간과 노력을 투자했습니다. 이 블로그에서는 숫자 필드와 날짜 필드에 대한 정렬 최적화에 대해 설명합니다.
정렬 쿼리 작동 방식
필터와 일치하는 문서를 찾고 특정 필드를 기준으로 결과를 정렬하도록 요청하면 Elasticsearch는 필터와 일치하는 모든 문서에 대해 해당 필드의 문서 값을 검사한 후 상위 값이 있는 상위 K개의 문서를 선택합니다. 매우 광범위한 필터(예: match_all query)와 같은 최악의 경우, 인덱스의 모든 문서에서 문서 값을 검사하고 비교해야 합니다. 인덱스가 큰 경우 상당한 시간이 걸릴 수 있습니다.
특정 필드에 대한 정렬 쿼리를 최적화하는 한 가지 방법은 인덱스 정렬을 사용하고 해당 필드의 전체 인덱스를 정렬하는 것입니다. 인덱스가 필드를 기준으로 정렬된 경우 해당 문서 값도 정렬됩니다. 따라서 필드를 기준으로 정렬된 상위 K개의 문서를 가져오려면 처음 K개의 문서만 가져오면 되며 나머지는 검사할 필요도 없으므로 정렬 쿼리의 속도가 매우 빨라집니다.
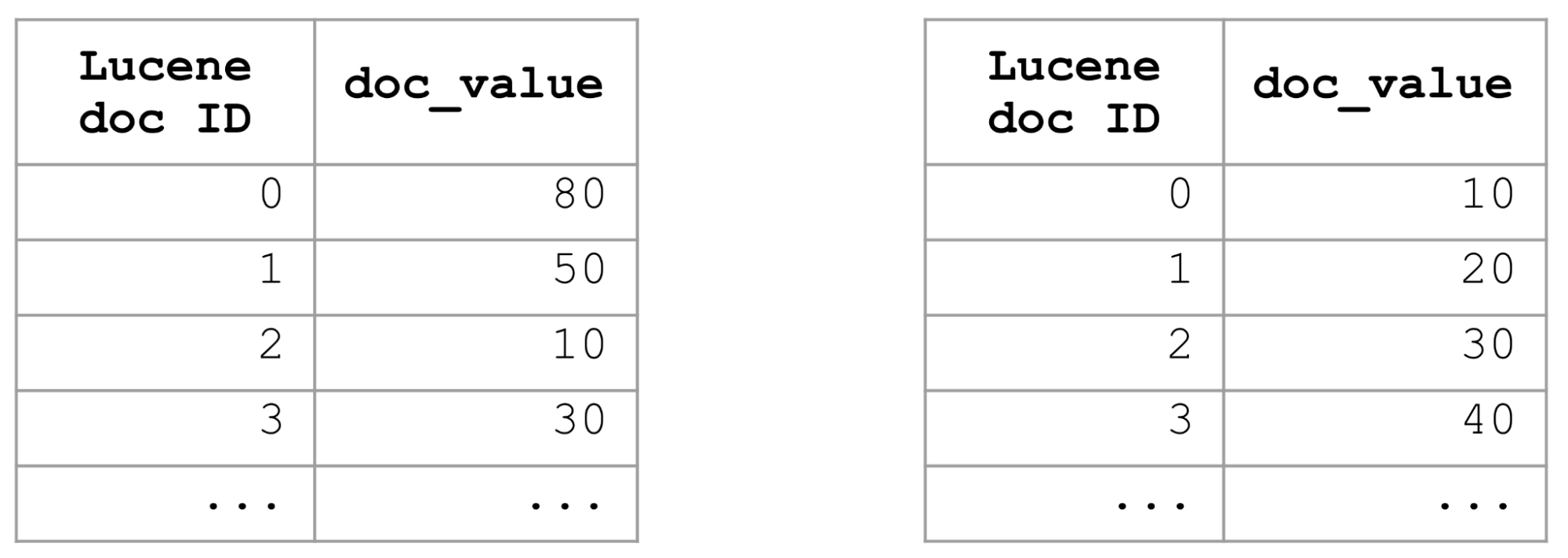
인덱스 정렬은 좋은 솔루션이지만, 이는 한 가지 방법으로만 수행할 수 있습니다. 인덱스 정렬은 내림차순 대 오름차순, 다양한 필드, 인덱스 정렬 정의에 정의된 것과 다른 조합 등 여러 정렬 기준을 사용하는 정렬 쿼리에는 적합하지 않습니다. 따라서 정렬 쿼리의 속도를 높일 수 있는 좀 더 유연한 접근 방식이 필요했습니다.
distance_feature 쿼리로 숫자 정렬 쿼리 최적화
과거에는 문서의 각 블록에 대한 최대 영향(용어 빈도와 문서 길이의 조합)을 저장함으로써 _score로 정렬된 용어 기반 쿼리에서 상당한 속도 향상을 이루었습니다. 쿼리 시간 동안 최대 영향을 확인하면 문서의 블록에서 경합이 발생하는지 여부를 빠르게 판단할 수 있습니다. 블록 경합이 없으면 문서의 해당 블록 전체를 건너뛸 수 있으므로 쿼리 속도가 훨씬 빨라집니다.
숫자 필드 또는 날짜 필드에 유사한 접근 방식을 적용하여 정렬 쿼리 속도를 높일 수 있을 것으로 생각했으며, distance_feature 쿼리로 정렬을 대체하면 가능한 것으로 확인되었습니다. distance_feature 쿼리는 주어진 오리진에 가장 가까운 상위 K개의 문서를 반환하는 흥미로운 쿼리입니다. 필드의 최소값을 오리진으로 사용하면 상위 K개의 문서가 오름차순으로 정렬됩니다. 최대값을 오리진으로 사용하면 상위 K개의 문서가 내림차순으로 정렬됩니다.
distance_feature 쿼리에서 가장 흥미로운 속성은 문서의 비경합 블록을 효율적으로 건너뛸 수 있다는 것입니다. 이 작업은 Elasticsearch에서 숫자 필드와 날짜 필드를 색인하기 위해 사용하는 BKD 트리의 속성을 활용하여 수행됩니다. 텍스트 필드의 포스팅 인덱스를 문서의 블록으로 나누는 방식과 마찬가지로 BKD 인덱스는 최소값과 최대값을 알고 있는 각 셀로 분할됩니다. 따라서 distance_feature 쿼리는 셀의 최소값과 최대값을 검사하는 것만으로도 문서의 비경합 셀을 효율적으로 건너뛸 수 있습니다. 이 정렬 최적화가 작동하려면 숫자 필드 또는 날짜 필드가 모두 색인되고 문서 값이 있어야 합니다.
distance_feature 쿼리로 문서 값 정렬을 대체함으로써 속도를 크게 향상할 수 있었습니다(일부 데이터 세트는 최대 35배 향상). Elasticsearch 7.6에서 날짜 필드와 긴 필드에 이 정렬 최적화를 도입했습니다.
search_after로 정렬 쿼리 최적화
이러한 속도 향상은 반가웠지만, search_after 파라미터를 사용하여 정렬할 수 있는 좋은 솔루션은 여전히 찾지 못했습니다. search_after로 정렬하는 방법은 매우 흔하게 사용되는데, 사용자가 결과의 첫 페이지뿐만 아니라 후속 페이지에도 관심이 있기 때문입니다. Elasticsearch에서 정렬 쿼리를 다시 작성하는 현재의 접근 방식 대신 Lucene의 비교기와 수집기로 이러한 정렬 최적화를 수행하고 비경합 문서를 건너뛰는 것이 더 나은 솔루션이라는 결론을 내렸습니다. Lucene의 비교기와 수집기는 이미 search_after를 지원하고 있으므로 이 문제에 대한 솔루션도 찾을 수 있을 것입니다. distance_feature 쿼리가 비경합 문서 블록을 건너뛰기 위해 사용했던 것과 동일한 Elasticsearch 코드가 Lucene의 숫자 비교기에 추가되었습니다.
Elasticsearch 7.16에서 search_after 파라미터에 이 정렬 최적화를 도입했고, 즉시 일부 야간 성능 벤치마크에서 속도가 최대 10배까지 향상되었습니다.
여러 세그먼트에 걸쳐 정렬 최적화
샤드는 여러 개의 세그먼트로 구성됩니다. Elasticsearch는 검색 시 세그먼트를 순차적으로 검사하므로, 상위 K 값을 가진 문서를 포함하는 것으로 보이는 최적의 후보 세그먼트로 처리를 시작하는 것이 매우 유용합니다. 상위 K 값을 가진 문서를 수집하면 이보다 하위 값만 포함된 다른 세그먼트를 매우 빠르게 건너뛸 수 있습니다.
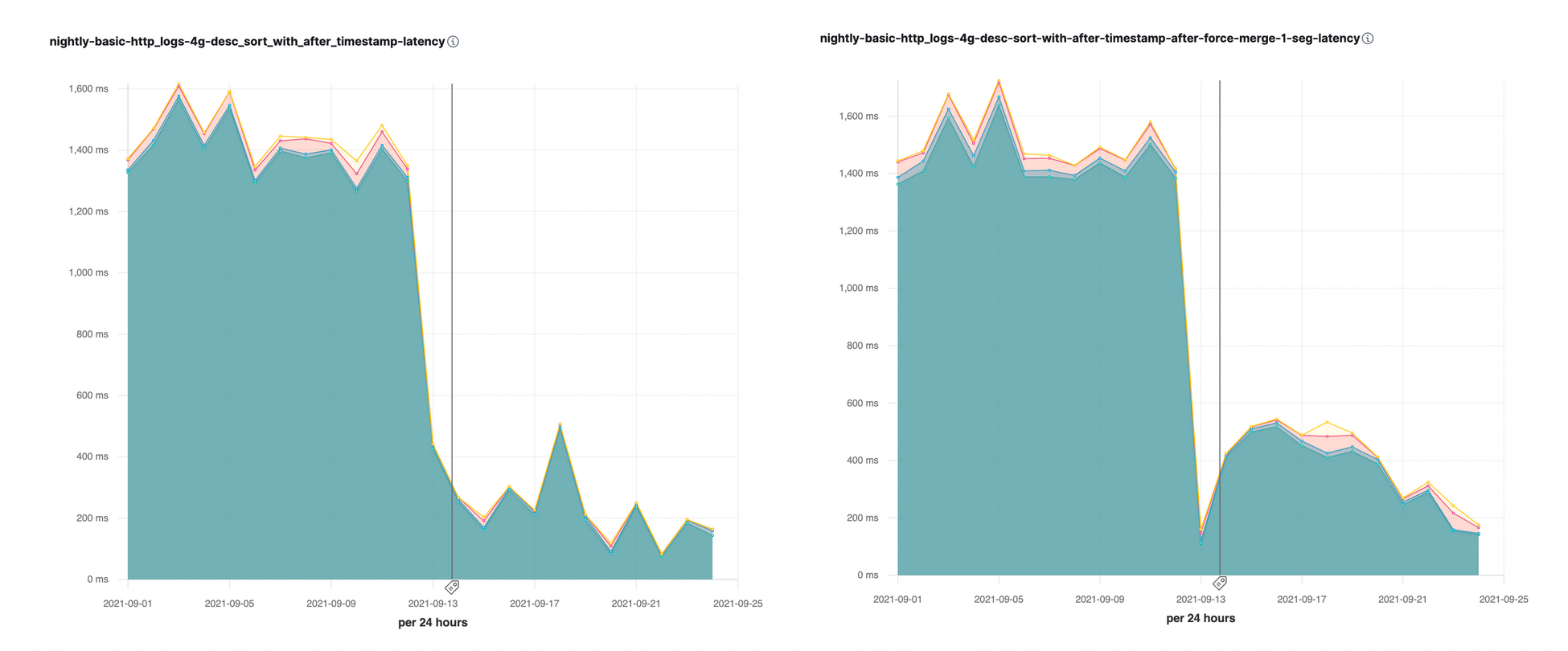
어떤 세그먼트부터 처리를 시작할지는 사용 사례에 따라 크게 달라집니다. 시계열 인덱스의 경우 가장 관심이 있는 것은 최근 이벤트이므로 타임스탬프 필드의 결과를 내림차순으로 정렬하는 것이 가장 일반적인 요청입니다. 시계열 인덱스에 대해 이러한 종류의 정렬을 최적화하기 위해 @timestamp 필드의 세그먼트를 내림차순으로 정렬하기 시작했습니다. 따라서 최신 데이터가 포함된 세그먼트로 처리를 시작하고, 이상적으로는 타임스탬프 문서를 기준으로 가장 최근인 첫 세그먼트를 수집하고 다른 모든 세그먼트는 건너뛸 수 있습니다. 이에 따라 타임스탬프 필드의 내림차순 정렬 쿼리에 대한 속도가 상당히 향상되었습니다.
작은 세그먼트가 더 큰 세그먼트로 병합되면서 가장 최근 문서가 마지막에 있는 새로운 세그먼트가 생기는 상황은 원하지 않습니다. 좀 더 균형 잡힌 병합 세그먼트를 만들기 위해 이전 세그먼트와 새 세그먼트를 인터리빙하는 새로운 병합 정책을 도입했습니다. 즉, 이전 세그먼트와 새 세그먼트의 문서가 새로운 결합 세그먼트에 혼합된 순서로 정렬됩니다. 이를 통해 가장 최근 문서도 효율적으로 찾을 수 있습니다.
여러 샤드에 걸쳐 정렬 최적화
Elasticsearch의 강력한 기능은 분산 검색에 있습니다. 분산 측면을 고려하지 않으면 어떤 최적화든 완전하지 않습니다. 일부 검색에는 수백 개의 샤드가 포함될 수 있으므로(예: 시계열 인덱스에 대한 검색) ‘적절한’ 샤드 세트로 시작하고 경합이 포함되지 않은 샤드는 우회하는 것이 좋습니다. 그리고 Elastic에서는 정확하게 이 접근 방식을 구현했습니다. Elasticsearch 7.6부터는 기본 정렬 필드의 최대/최소 값을 기준으로 샤드를 미리 정렬하여 상위 값을 포함하는 것으로 보이는 최적의 샤드 세트 후보로 분산 검색을 시작할 수 있도록 했습니다. Elasticsearch 7.7부터는 다른 샤드의 결과를 사용하여 쿼리 단계를 단축했습니다. 즉, 첫 번째 샤드 세트에서 상위 값을 수집하면, 가능한 모든 값이 이전 샤드에서 계산된 하위 정렬 값보다 낮으므로 나머지 샤드를 완전히 건너뛸 수 있습니다. 많은 머신 생성 시계열 인덱스에서 문서는 삭제되기 전에 성능 최적화 하드웨어에서 시작하여 비용 최적화 하드웨어로 끝나는 인덱스 수명 주기 정책을 따릅니다. 이러한 샤드 건너뛰기 메커니즘은 더 느리고 경제적인 하드웨어의 샤드를 건너뛰어서 검색 가능한 스냅샷을 특히 효율적으로 사용할 수 있기 때문에 사용자가 광범위한 쿼리를 보내고 성능 최적화 하드웨어에 의해 정의된 쿼리 성능을 누릴 수 있음을 의미합니다.
사용자에게 미치는 영향
Elasticsearch 사용자는 이러한 정렬 최적화를 어떻게 활용할 수 있을까요? 이러한 정렬 최적화는 요청에 대한 정확한 총 적중 결과 수를 추적할 필요가 없고 요청에 집계가 포함되지 않은 경우에만 유효합니다. 정확한 총 적중 결과 수가 필요한 경우 필터와 일치하는 모든 문서를 세야 하므로 건너뛰기를 할 수 없습니다. track_total_hits의 기본 값은 10,000으로 설정되어 있습니다. 즉, 10,000개의 문서를 수집해야 정렬 최적화가 시작됩니다. 이 값을 더 작게 또는 ‘false’로 설정하면 Elasticsearch가 훨씬 일찍 정렬 최적화를 시작하므로 응답 속도가 빨라집니다.
최근에 Kibana에서 track_total_hits가 비활성화된 요청을 보내기 시작했으므로 Kibana의 정렬 쿼리도 속도가 더 빨라질 것입니다.
사용해 보기
기존 Elastic Cloud 고객은 Elastic Cloud 콘솔에서 이 중 많은 기능을 바로 이용하실 수 있습니다. Elastic Cloud를 처음 접하시는 경우, 빠른 시작 안내서(빠른 시작을 위한 짤막한 길이의 교육용 비디오)나 무료 기초 교육 과정을 살펴보세요. Elastic Enterprise Search 14일 무료 체험판을 통해 언제든지 무료로 시작하실 수 있습니다. 또는 자체 관리형 버전의 Elastic Stack을 무료로 다운로드하세요.
공유하기
- Share on Twitter
트위터에서 공유하기
- Share on LinkedIn
링크드인에서 공유하기
- Share on Facebook
페이스북에서 공유하기
- Share by Email
이메일로 공유하기
- Print this page
인쇄하기