Monitoreo de aplicaciones con Elasticsearch y APM de Elastic
¿Qué es monitoreo del rendimiento de la aplicación (APM)?
Cuando hablamos de APM, puede resultar útil mencionarlo al mismo tiempo que las otras facetas de "observabilidad": logs y métricas de infraestructura. Los logs, APM y las métricas de infraestructura constituyen la trifecta de la observabilidad:
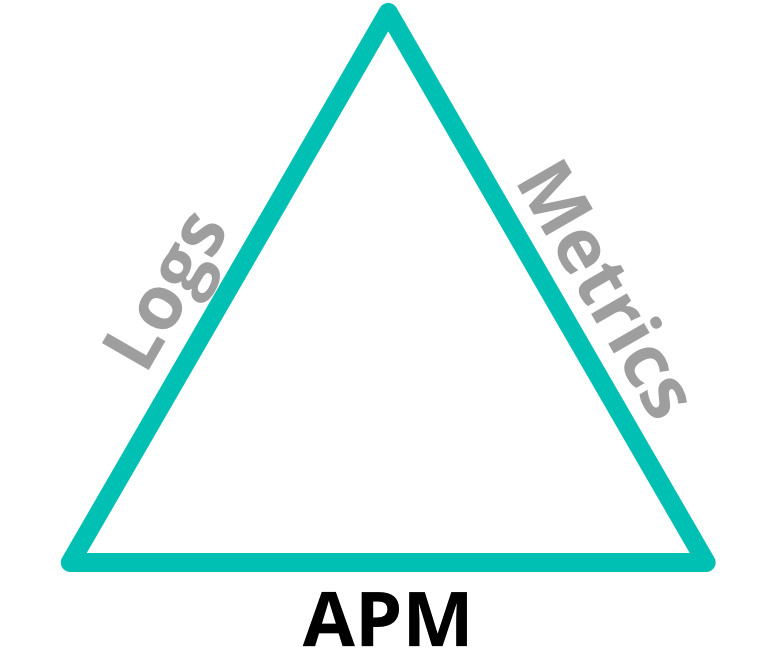
Existe una superposición en estas áreas, la suficiente como para ayudar a correlacionarlas. Los logs pueden indicar que se produjo un error, pero quizás no indiquen cómo se produjo. Las métricas pueden mostrar que el uso de CPU se disparó en un servidor, pero no indicará qué lo causó. Entonces cuando las usamos en conjunto, podemos resolver una gama más amplia de problemas.
Logs
Primero, analicemos algunas definiciones. Existe una diferencia realmente sutil entre logs y métricas. En general, los logs son eventos que se emiten cuando algo ocurre: se recibe y se responde una solicitud, se abre un archivo o se encontró un printf en el código.
Por ejemplo, un formato de log común viene del proyecto de servidor HTTP de Apache (simulado y cortado por el largo):
264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "GET /ESProductDetailView HTTP/1.1" 200 6291 264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "POST /intro.m4v HTTP/1.1" 404 7352 264.242.88.10 - - [22/Jan/2018:16:38:53 -0800] "POST /checkout/addresses/ HTTP/1.1" 500 5253
Los logs aún tienden a estar en el nivel del componente, en lugar de ver la aplicación como un todo. Los logs son interesantes en cuanto a que habitualmente son legibles para las personas. En el ejemplo anterior, vemos una dirección IP, un campo que aparentemente no está configurado, una fecha, la página a la que accedió el usuario (más el método) y algunos números. Por experiencia, sabemos que los números son el código de respuesta (200 es bueno, 404 no es tan bueno, pero es mejor que 500) y la cantidad de datos devueltos.
Los logs son útiles porque usualmente están disponibles en el host, la máquina o el contenedor que ejecuta la aplicación o el servicio correspondientes y, como vimos anteriormente, son legibles para las personas. Las desventajas de los logs residen en su propia naturaleza: si no los codificas, no se imprimirán. Tienes que hacer de forma explícita algo equivalente a puts en Ruby o system.out.println en Java para obtenerlos. Incluso si lo haces, el formato es importante. Los logs de Apache anteriores cuentan con lo que parece ser un formato de fecha extraño. Veamos la fecha "01/02/2019", por ejemplo. En Estados Unidos, eso es el 2 de enero de 2019, pero para muchas otras personas que están leyendo esto, es 1 de febrero. Piensa en esas cuestiones cuando des formato a la expresión de logging.
Métricas
Las métricas, por otro lado, tienden a ser resúmenes periódicos o cuentas: en los últimos 10 segundos, el uso promedio de CPU fue de 12 %, la cantidad de memoria usada por una aplicación fue 27 MB o el disco primario estaba al 71 % de su capacidad (por lo menos este disco).
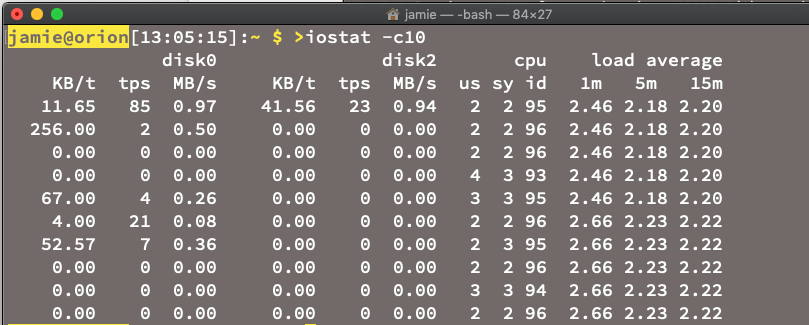
Arriba verás una captura de pantalla de iostat que está ejecutándose en una Mac. Hay muchas métricas allí. Las métricas son útiles cuando quieres mostrar tendencias e historia, y son excelentes para intentar crear reglas simples, predecibles y confiables para detectar incidentes y anomalías. Un problema con las métricas es que tienden a controlar la capa de infraestructura y así obtienen datos sobre el nivel de instancia de componente (cosas como hosts, contenedores y redes) en lugar del nivel de aplicación personalizado. Como las métricas tienden a reunirse después de un período de tiempo, un resumen atípico corre el riesgo de ser considerado "fuera del promedio".
APM
El monitoreo de rendimiento de aplicaciones (APM) cubre las faltantes entre las métricas y los logs. Mientras que los logs y las métricas tienden a ser más transversales (se encargan de la infraestructura y los componentes), APM se concentra en las aplicaciones, lo que permite que la TI y los desarrolladores controlen la capa de aplicación en el stack, incluida la experiencia de usuario final.
Agregar APM a tu monitoreo te permite lo siguiente:
- Comprender cómo tu servicio usa el tiempo y por qué se bloquea
- Ver cómo los servicios interactúan entre ellos y visualizar cuellos de botella
- Descubrir y corregir cuellos de botella y errores de rendimiento de manera proactiva
- Con suerte, antes de que muchos de tus clientes se vean afectados
- Aumentar la productividad del equipo de desarrollo
- Mantener un seguimiento de la experiencia del usuario final en el navegador
Un aspecto clave para tener en cuenta es que APM se comunica con código (veremos más en un momento).
Veamos como APM se compara con lo que obtenemos de los logs. Consideremos esta entrada de log:
264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "GET /ESProductDetailView HTTP/1.1" 200 6291
Cuando vimos esta entrada inicialmente, todo parecía normal. Respondimos correctamente (200) y enviamos 6291 bytes. Lo que no muestra es que tomó 16.6 segundos, como se ve en esta captura de pantalla de APM:
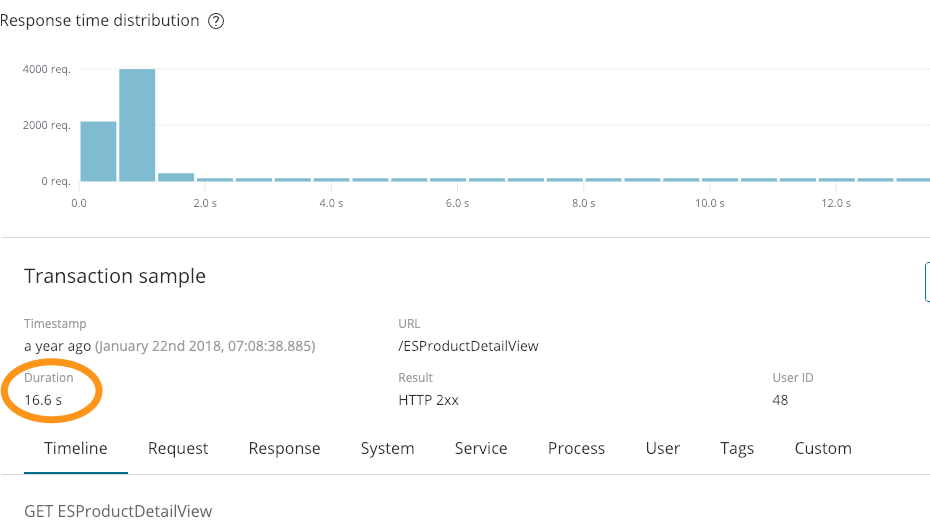
Ese contexto adicional es bastante informativo. También tuvimos un error en los logs anteriores:
264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "POST /checkout/addresses/ HTTP/1.1" 500 5253
AMP también captura errores:
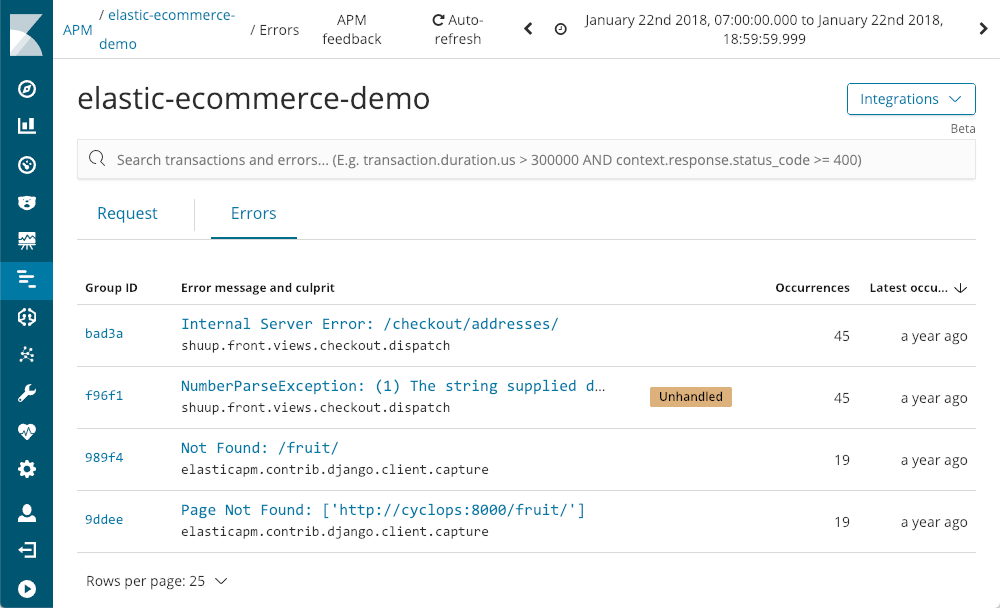
Nos muestra cuándo ocurrieron por última vez, con qué frecuencia ocurrir y si la aplicación se encargó o no de ellos. A medida que consideramos una excepción, usando NumberParseException como ejemplo, recibimos una visualización de la distribución de la cantidad de veces que se produjo ese error en la pantalla:
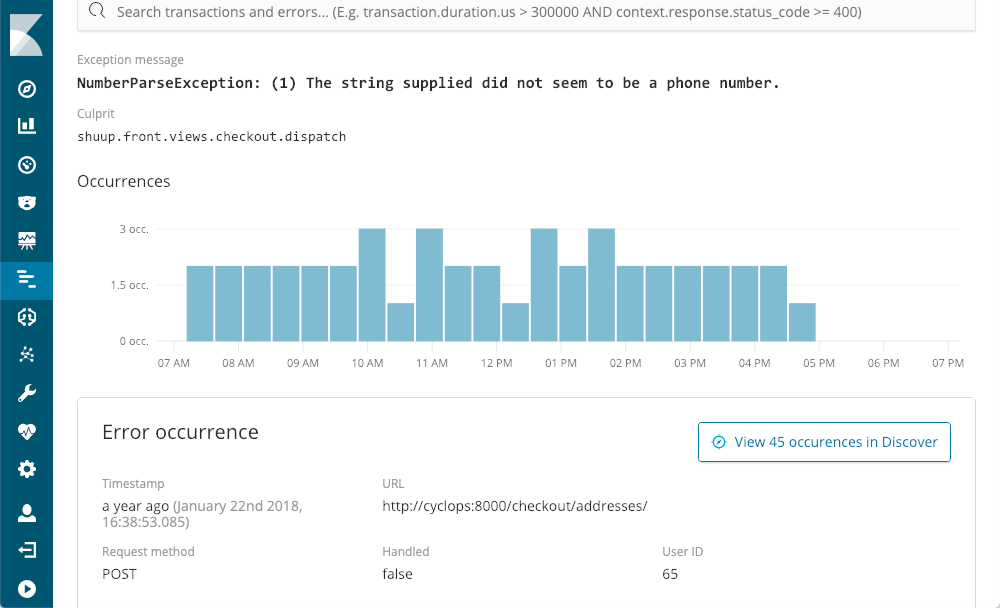
Podemos ver de inmediato que ocurrió un par de veces por período, pero prácticamente todo el día. Podríamos encontrar el rastro del stack correspondiente en uno de los archivos del log, pero las probabilidades muestran que no tendrían el contexto y los metadatos que están disponibles cuando se usa APM:
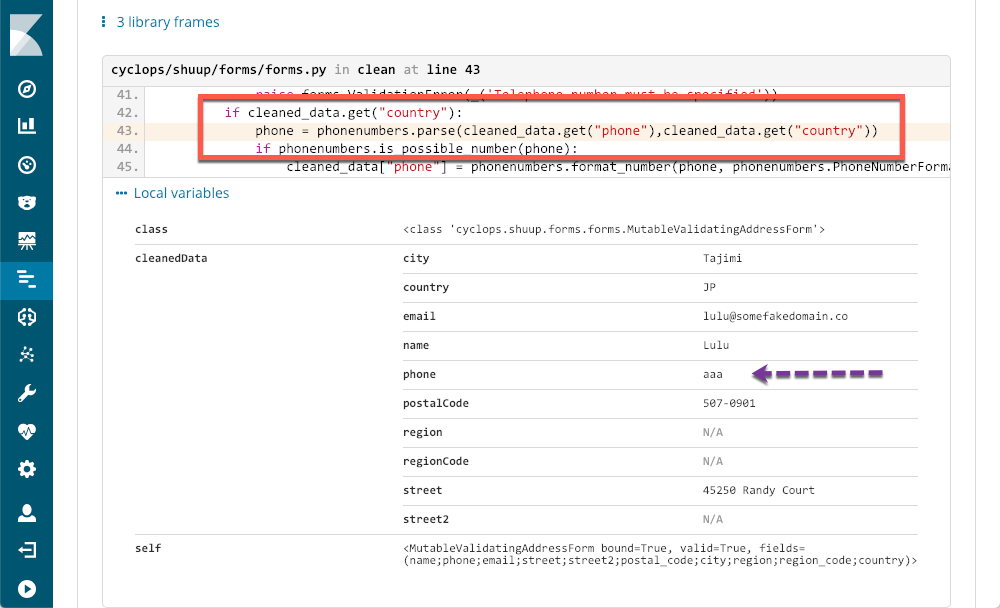
El rectángulo rojo muestra la línea de código que causó la excepción, y los metadatos proporcionados por APM muestran exactamente cuál es el problema. Incluso un programador que no trabaje con Python puede ver exactamente cuál es el problema y contar con suficiente información como para abrir un ticket.
Recorrido por las características de APM (con capturas de pantalla)
Podemos hablar sobre APM de Elastic todo el día (visiten nuestra cuenta de Twitter y se los demostraré), pero creo que es mejor ver lo que puede hacer. Hagamos un recorrido.
Abrir APM
Cuando entramos en la aplicación APM en Kibana, vemos todos los servicios que hemos instrumentado con APM de Elastic:
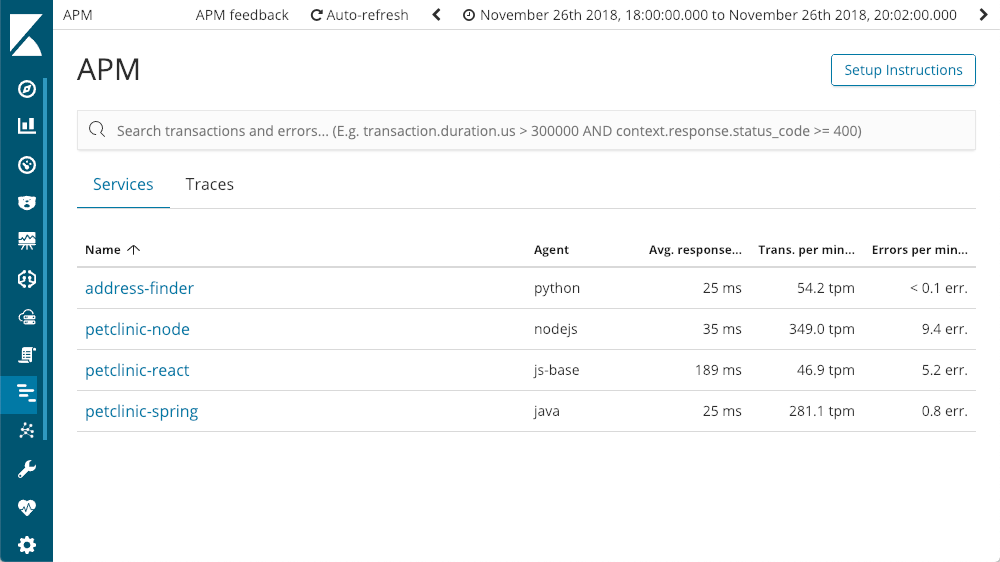
Explorar los servicios
Podemos ir directamente a los servicios individuales. Veamos el servicio "petclinic-spring". Cada uno de los servicios tendrá una visualización similar:
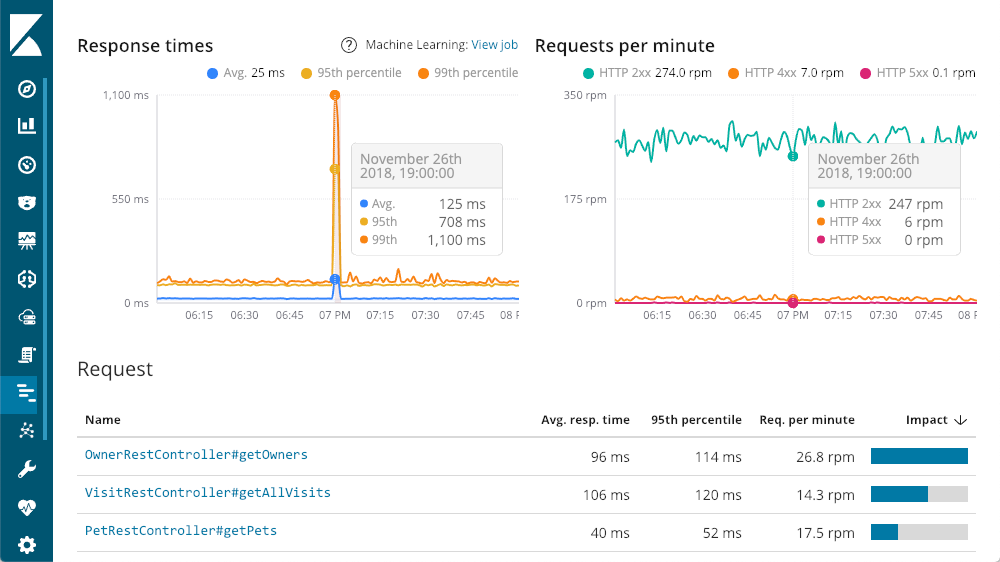
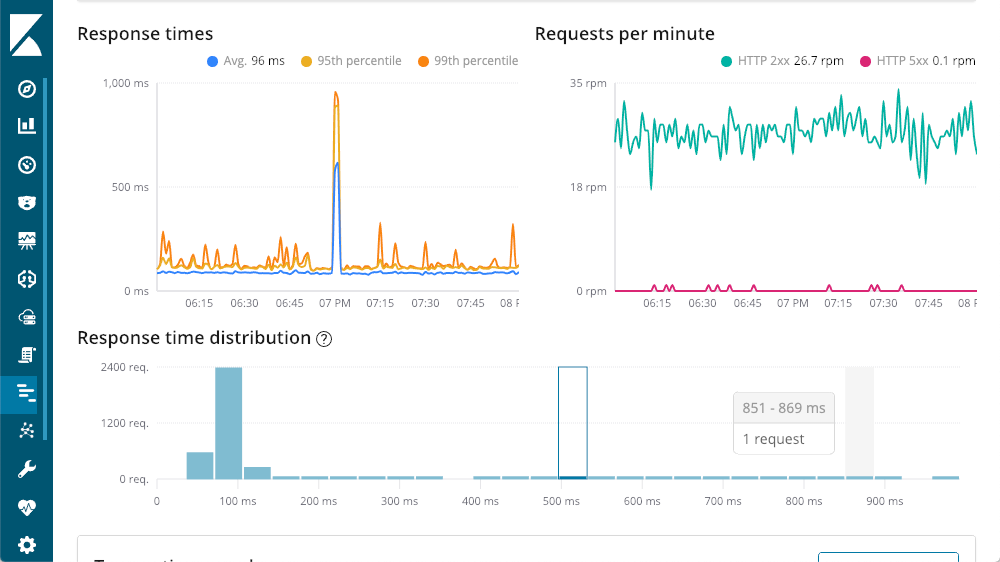
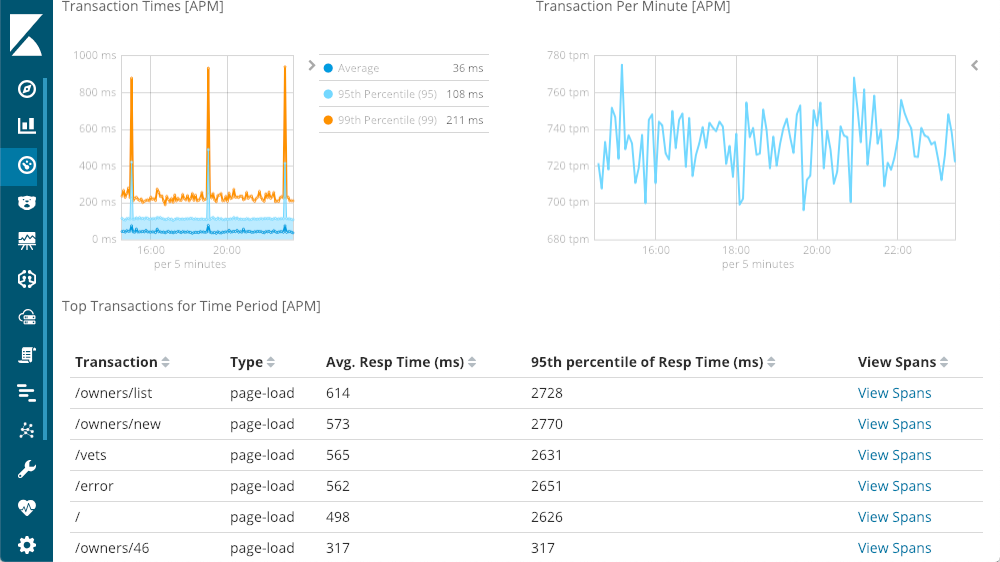
El extremo superior izquierdo muestra los tiempos de respuesta: promedio, percentiles 95 y 99, para ver dónde están los valores atípicos. También podemos mostrar o esconder los diferentes elementos de línea para obtener una visión mejorada sobre cómo los valores atípicos impactan en el cuadro general. El extremo superior derecho muestra los códigos de repuesta. Estos se despliegan en solicitudes por minuto (RPM), en oposición a los tiempos. Como puedes ver en el cuadro, a medida que mueves el mouse sobre cualquier cuadro, verás un recuadro emergente con un resumen de ese punto en el tiempo. La primera visión está disponible antes de que comencemos a explorar. Esa gran mejora en latencia no tiene respuestas 500 (errores de servidor).
Explorar los tiempos de respuesta de la transacción
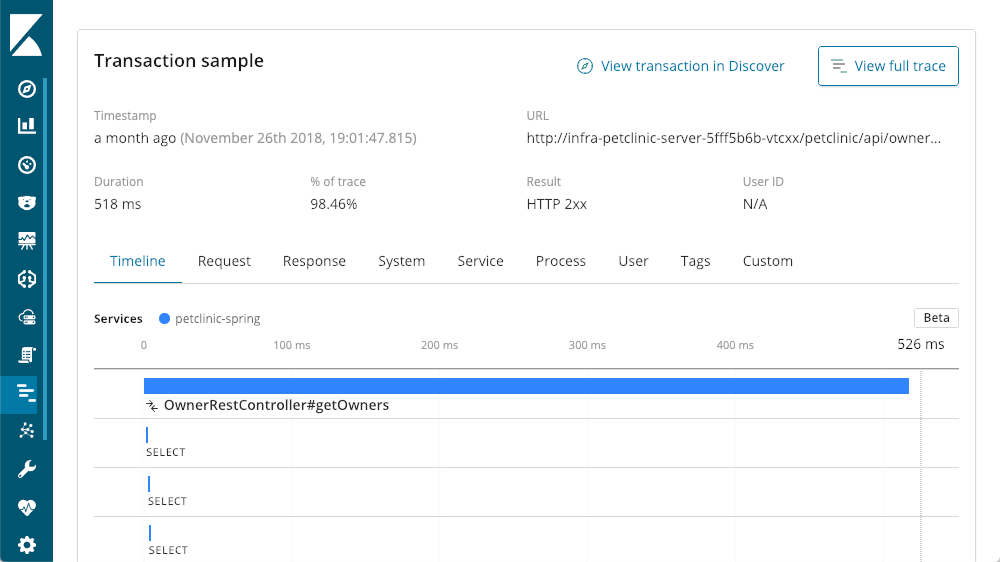
En nuestro recorrido del resumen de transacción, llegamos al final, el despliegue de la solicitud. Cada solicitud es básicamente un extremo diferente en nuestra aplicación (aunque puedas incrementar los elementos predeterminados con las diferentes API de agente). Podemos mover los titulares de las columnas, pero personalmente me gusta la columna "impacto", ya que tiene en cuenta la latencia y la popularidad de una solicitud dada. En este caso, nuestro "getOwners" parece estar causando el problema principal, pero continúa con una latencia promedio bastante respetable de 96 ms. Si continuamos hacia los detalles de esa transacción, vemos la misma pantalla que vimos anteriormente:
Operación cascada
Sin embargo, incluso las solicitudes más lentas continúan siendo de menos de un segundo. Más abajo veremos la vista en cascada de las operaciones en la transacción:
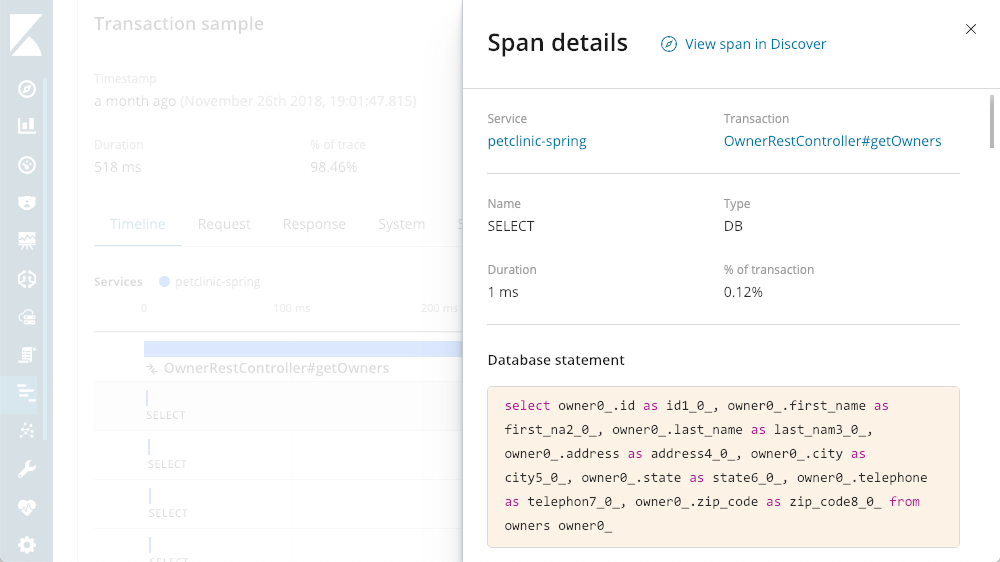
Visor de detalles de búsqueda
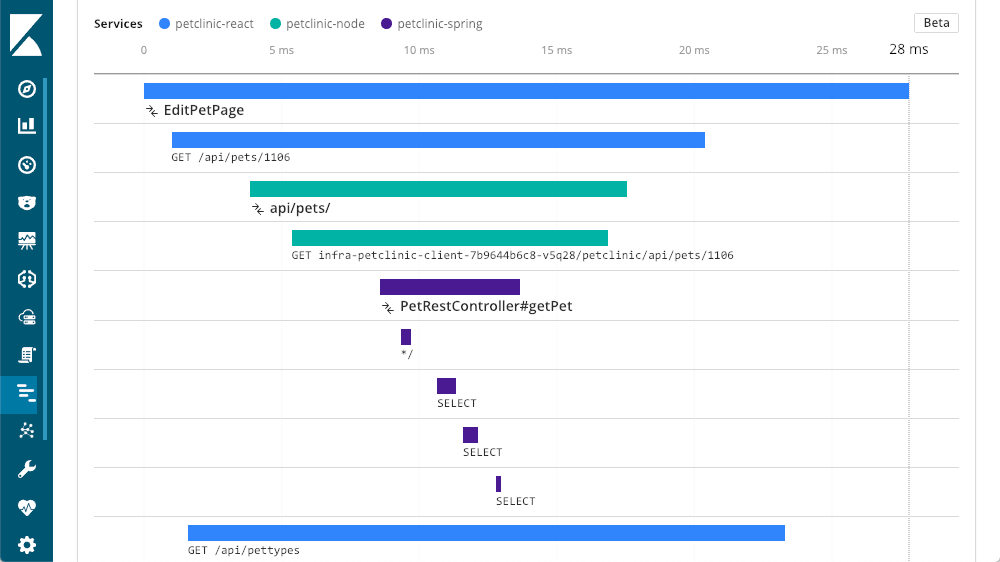
Por supuesto que hay muchos enunciados SELECT en proceso. Con APM, podemos ver las búsquedas reales en ejecución:
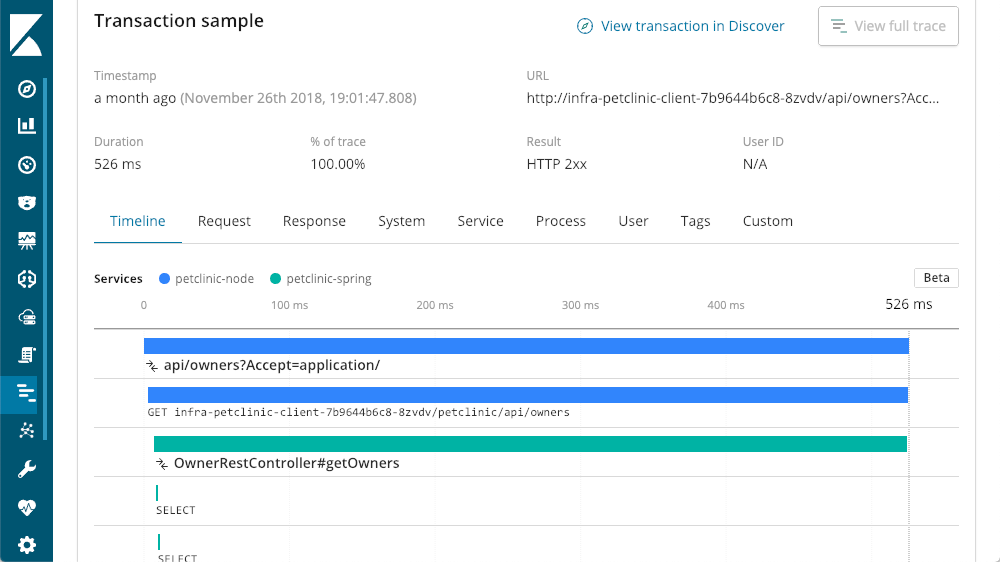
Rastreo distribuido
Nos enfrentamos a una arquitectura de microservicio de múltiple nivel en el stack de esta aplicación. Como todos los niveles se instrumentan con APM de Elastic, podemos acceder a una vista más general con el botón "ver rastreo completo" para ver todo lo involucrado en esta llamada; se mostrará un rastreo distribuido de todos los componentes que participaron de la transacción:
Capas de rastreo
En este caso, la capa en la que comenzamos, la capa Spring, es un servicio que las otras capas llaman. Ahora podemos ver ese "petclinic-node" denominado capa "petclinic-spring". Esas son solo dos capas, pero podemos ver muchas más. En este ejemplo, tenemos una solicitud que comenzó en la capa del navegador (reacción):
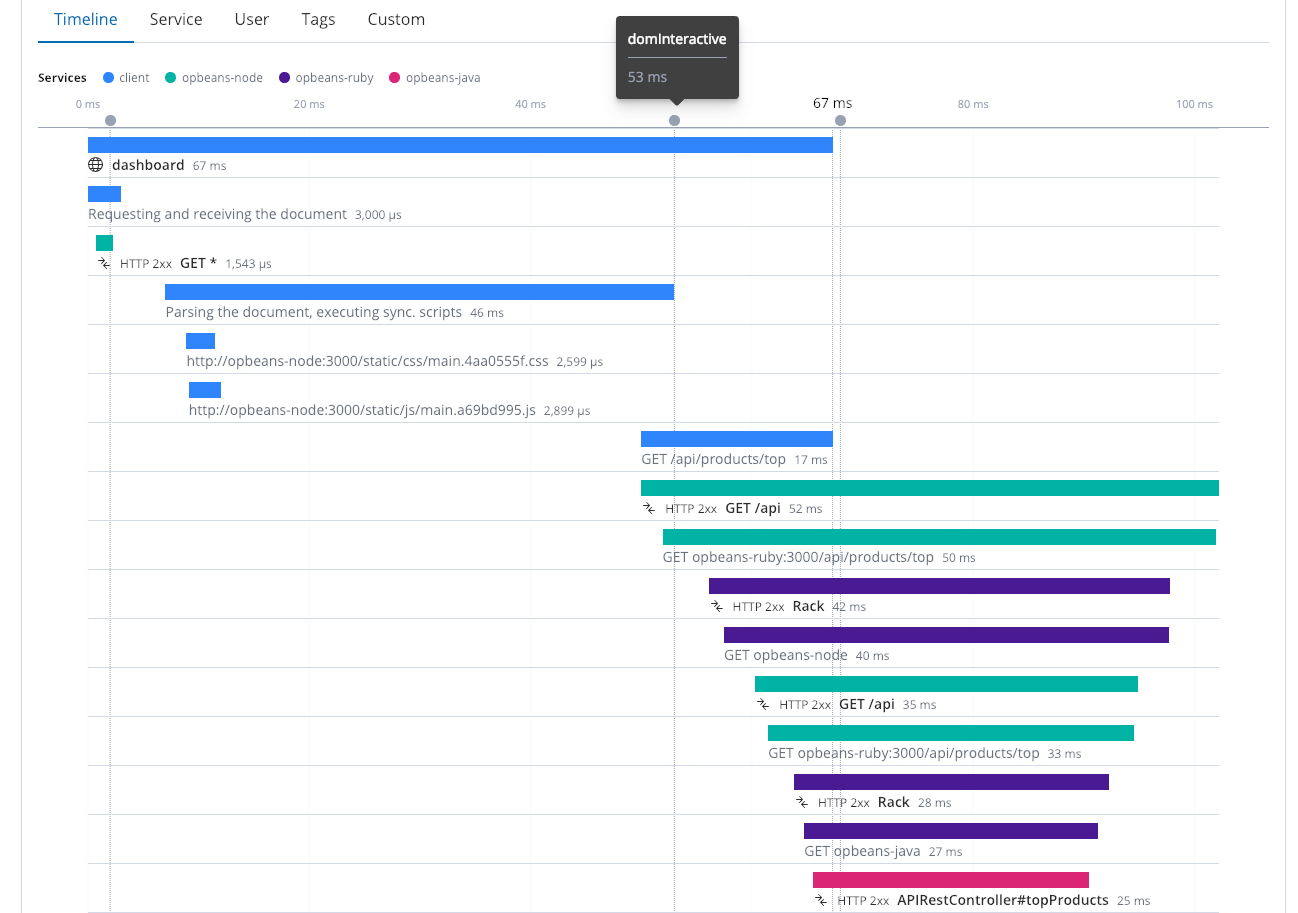
Monitoreo de usuario real
Para aprovechar al máximo el valor del rastreo distribuido, es importante instrumentar tantos componentes y servicios como sea posible, incluso aprovechar el monitoreo de uso real (o RUM). Solo porque cuentas con tiempos de respuesta de servicio rápidos no significa que todo funcionará rápidamente en el navegador. Es importante evaluar las experiencias de los usuarios finales en el buscador. Este rastreo distribuido muestra cuatro servicios diferentes que trabajan juntos. Incluye el buscador web (el cliente) junto con diversos servicios. A los 53 ms, el dom era interactivo, y a los 67 ms vemos que el dom está completo.
No solo una cara bonita
APM de Elastic no es solo una UI de APM preconfigurada dirigida a desarrolladores de aplicaciones, y los datos de respaldo no está allí solo para servir a esa UI. De hecho, una de las mejores características de los datos de APM de Elastic es que son solo un índice más. La información está al alcance, junto con los logs, las métricas, incluso los datos de tu negocio. Esto te permite ver cómo la ralentización del servidor impacta en tus ingresos o aprovechar los datos de APM para ayudar a planificar cuáles deberían ser las próximas mejoras de código (un consejo: echa un vistazo a los requisitos con mayor impacto).
APM se envía con visualizaciones y dashboards predeterminados, lo que nos permite mezclarlos y combinarlos con visualizaciones de logs, métricas o incluso nuestros datos empresariales.
Primeros pasos con APM de Elastic
APM de Elastic puede ejecutarse junto con Logstash y Beats con una topología de despliegue similar:
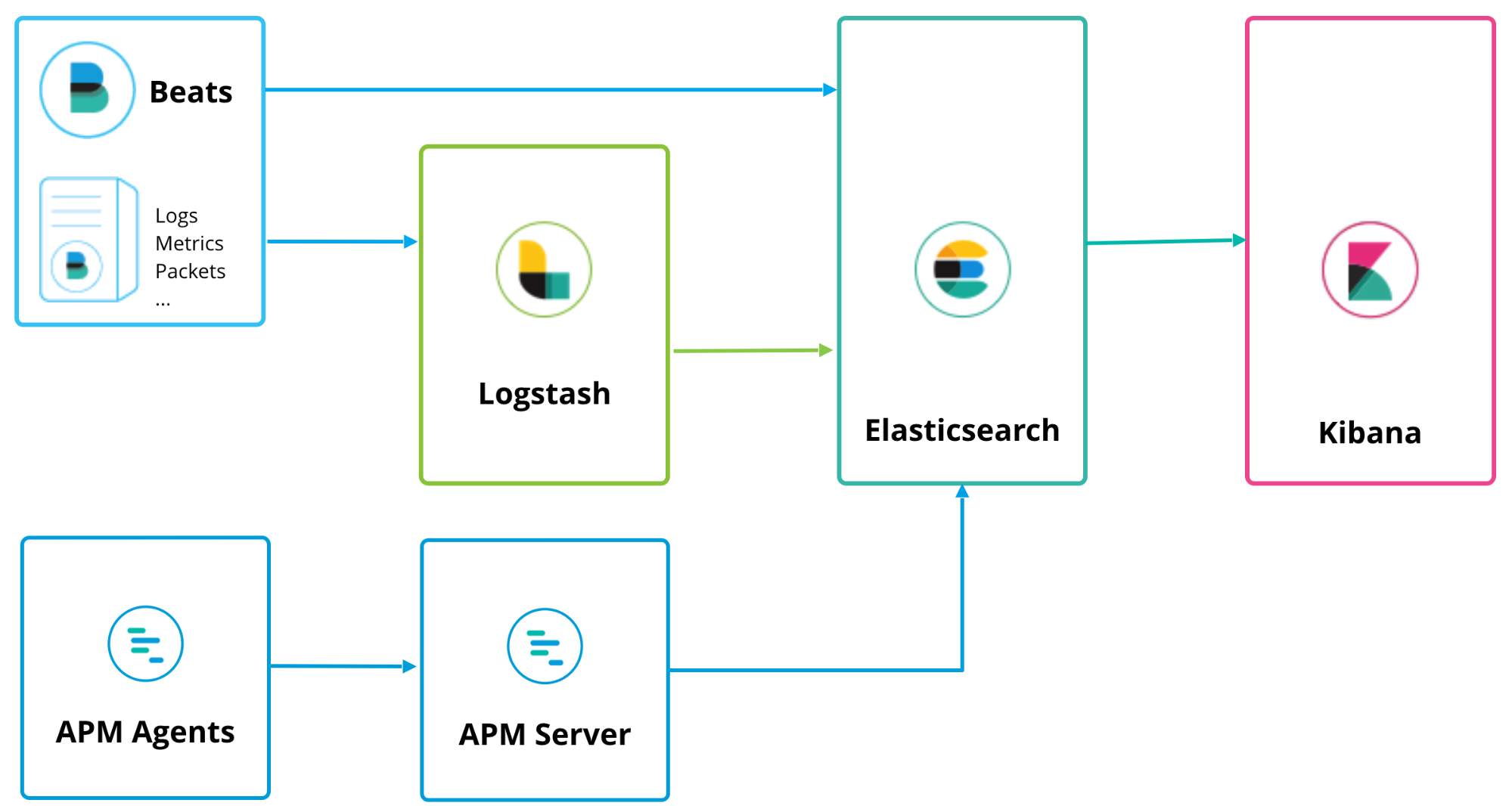
El servidor de APM actúa como un procesador de datos enviando datos dl APM desde los agentes de APM a Elasticsearch. La instalación es bastante simple y puede encontrarse en la página "Instalación y ejecución" de la documentación, o puedes simplemente hacer clic en el logo "K" de Kibana para dirigirte a la página inicial de Kibana, donde podrás ver una opción para "Agregar APM":
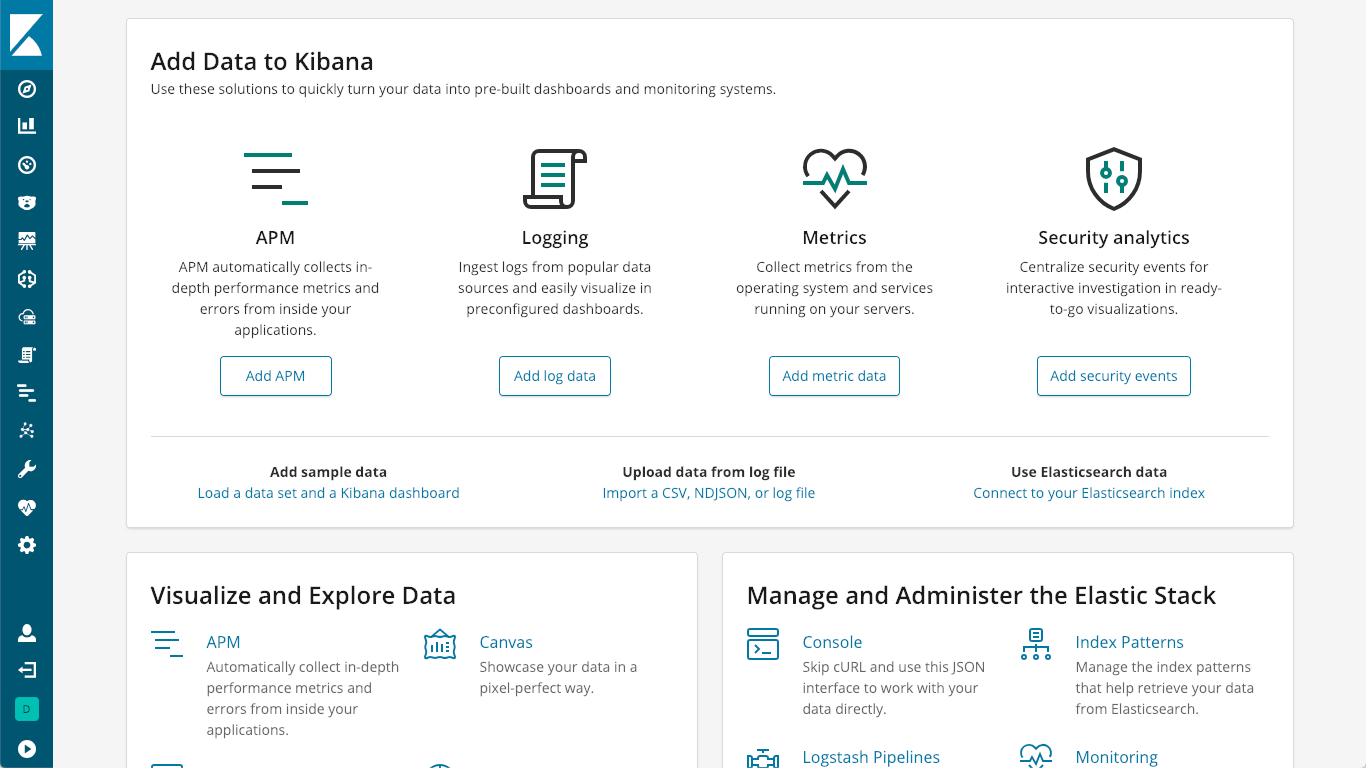
Luego, esta opción de guiará en la instalación y la ejecución de un servidor de APM:
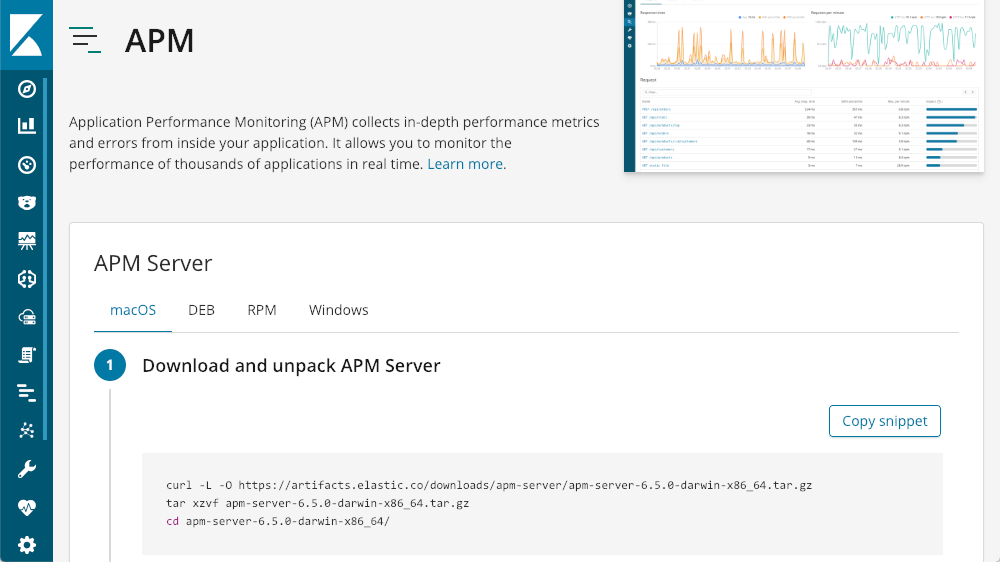
Una vez que esté instalado y en ejecución, Kibana ofrece tutoriales para cada tipo de agente incorporados:
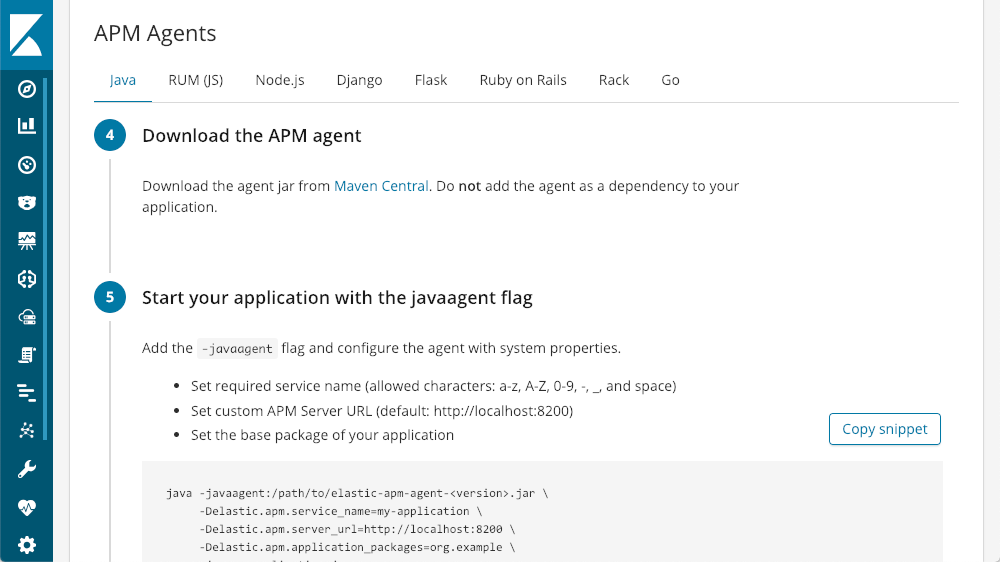
Puedes instalarlo y ejecutarlo con solo algunas líneas de código.
Prueba APM de Elastic
Realmente, no hay mejor manera de aprender algo nuevo que enfrentándolo y poniéndonos manos a la obra, y contamos con diversas formas a tu disposición. Si quieres ver la interfaz en vivo y en directo, puedes hacer clic en nuestro entorno de demostración de APM. Si prefieres ejecutar todo de forma local, puedes seguir los pasos en nuestra página de descarga del servidor de APM.
El camino más corto es a través de Elasticsearch Service o Elastic Cloud, nuestra oferta de SaaS que te permite acceder a un despliegue completo de Elasticsearch ,incluido un servidor de APM (desde 6.6), una instancia de Kibana y un nodo de Machine Learning, instalado y en ejecución en minutos (y dispones de una prueba gratuita de dos semanas). La mejor parte es que mantenemos la infraestructura de despliegue por ti.
Habilitación de APM en Elasticsearch Service
Para crear tu cluster con APM (o agregar APM a un cluster existente) puedes bajar hasta la sección de configuración de APM en tu cluster, hacer clic en "Habilitado" y después "Guardar cambios" (cuando actualices un despliegue existente) o "Crear despliegue" (cuando crees un nuevo despliegue).
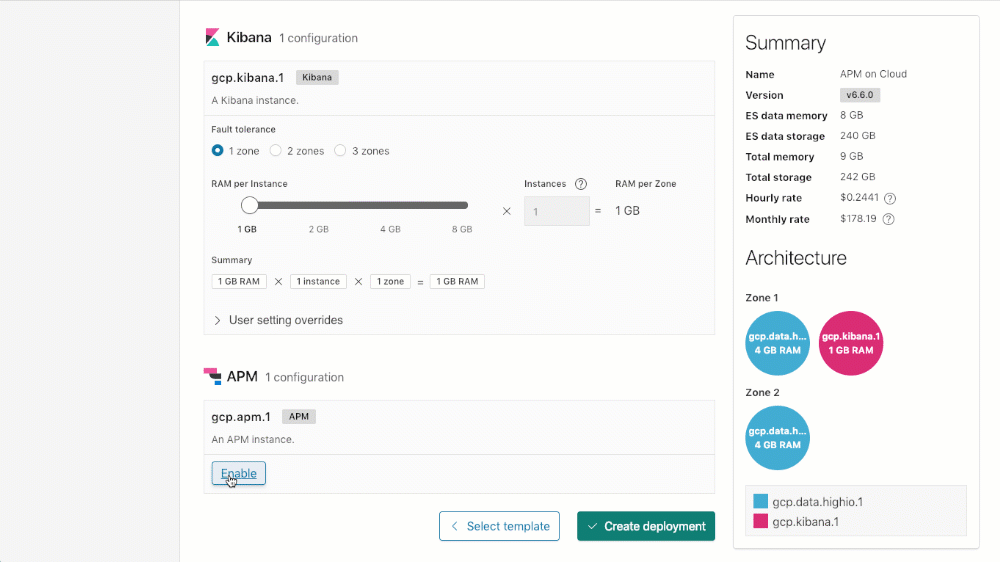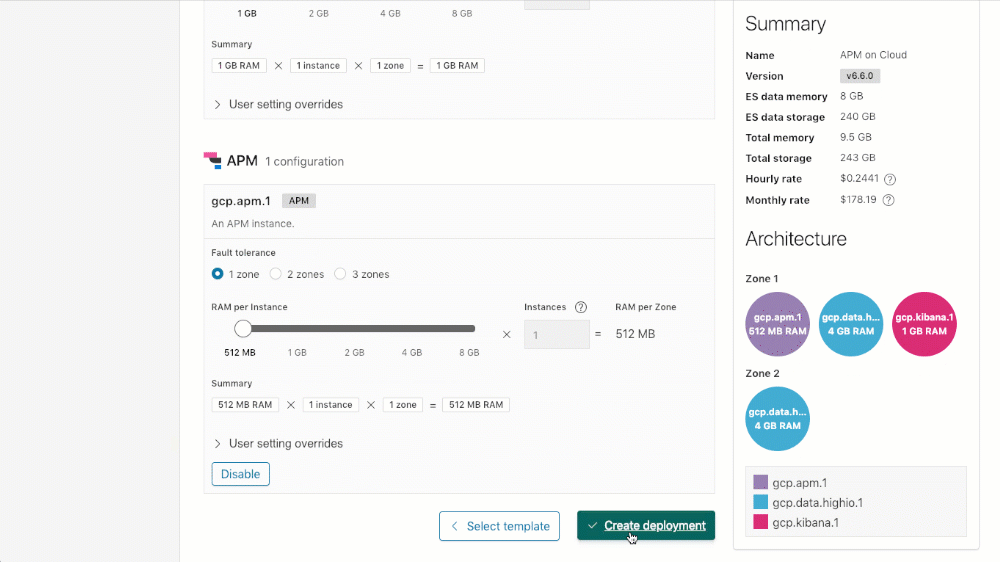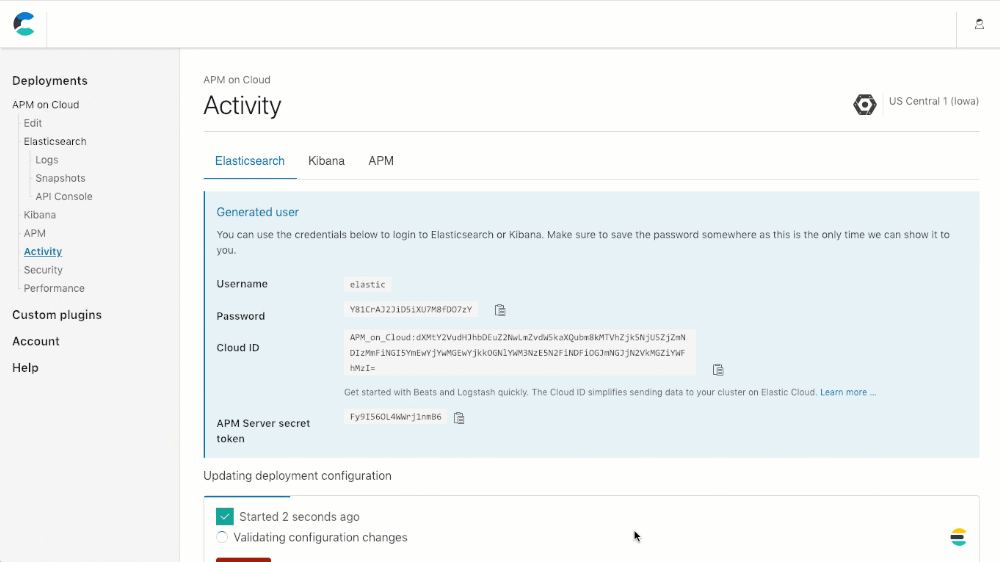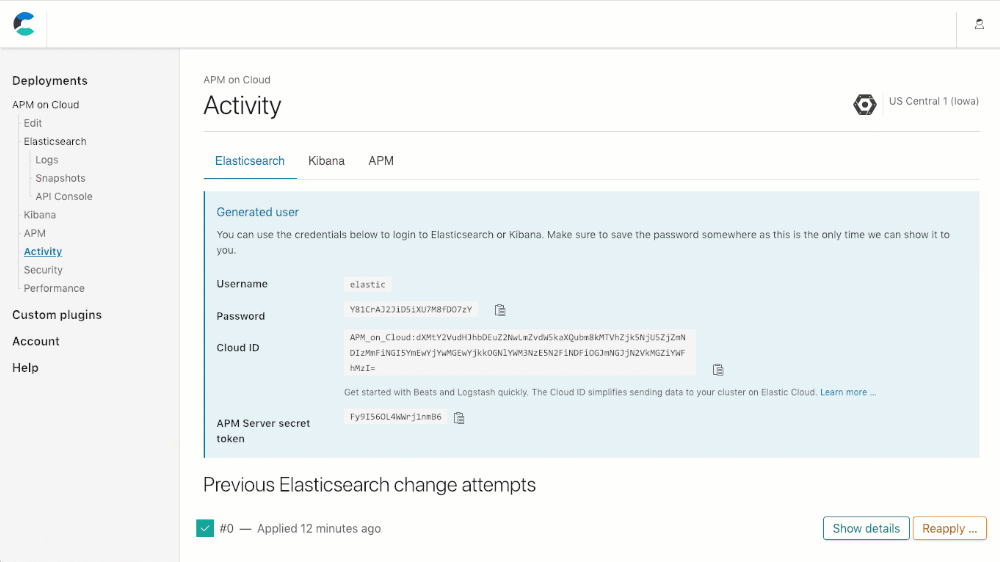
Licenciamiento
El servidor de APM de Elastic y todos los agentes de APM son open source, y la UI de APM seleccionada se incluye en la distribución predeterminada del Elastic Stack bajo la licencia básica gratuita. Las integraciones a las que hacíamos referencia previamente (Alerting y Machine Learning) se adjuntan a la licencia subyacente para la característica básica, Gold para Alerting y Platinum para Machine Learning.
Resumen
APM nos permite ver lo que sucede con nuestras aplicaciones en todos los niveles. Con integraciones con Machine Learning y Alerting combinadas con el poder de búsqueda, APM de Elastic agrega una nueva capa de visibilidad a la infraestructura de nuestra aplicación. Podemos usarlo para visualizar transacciones, rastros, errores y excepciones, todo desde el contexto de una interfaz de usuario de APM seleccionada. Incluso cuando no tenemos problemas, podemos aprovechar los datos de APM de Elastic para ayudar a priorizar correcciones, obtener el mejor desempeño de nuestras aplicaciones y combatir los cuellos de botella.
Si quieres saber más sobre APM de Elastic y observabilidad, echa un vistazo a algunos de nuestros seminarios web anteriores:
- Instrumentar y monitorear aplicaciones de Java usando APM de Elastic
- Usar el Elastic Stack para el monitoreo de rendimiento de aplicaciones
- Usar Elasticsearch, Beats y APM de Elastic para controlar los datos de Openshift
- Unificar APM, los logs y las métricas para una visibilidad operacional más profunda
- Rastrear los logs y las métricas de infraestructura en el Elastic Stack (ELK Stack)
¡Pruébalo hoy! Pregúntanos por el tema de APM en nuestro foro de discusión y envía tickets o solicitudes de características en nuestro repositorio de GitHub para APM.