Uso do Spring Boot com o Elastic App Search


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
Neste artigo, partiremos do zero para uma aplicação Spring Boot totalmente em execução consultando o Elastic App Search, que rastreou o conteúdo de um site. Iniciaremos o cluster e configuraremos a aplicação passo a passo.
Criar um cluster
Para seguir o exemplo, a maneira mais fácil é clonar o repositório do GitHub de amostra. Ele está pronto para você executar o terraform e começar a trabalhar rapidamente.
git clone https://github.com/spinscale/spring-boot-app-searchPara ter um exemplo funcionando, precisamos criar uma chave de API no Elastic Cloud, conforme descrito na configuração do provedor Terraform.
Feito isso, execute:
terraform init
terraform validate
terraform applye pegue um café antes de abrir os trabalhos. Depois de alguns minutos, você deverá ver sua instância na interface do usuário do Elastic Cloud funcionando assim:
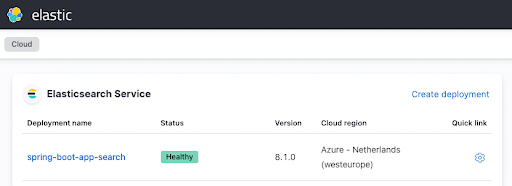
Configuração da aplicação Spring Boot
Antes de continuarmos, vamos nos certificar de que podemos compilar e executar a aplicação Java. Tudo o que você precisa é ter o Java 17 instalado, e você pode prosseguir e executar:
./gradlew clean checkIsso baixará todas as dependências, executará os testes e falhará. É algo esperado, pois não indexamos nenhum dado em nossa instância de busca do app.
Antes de podermos fazer isso, temos de alterar a configuração e indexar alguns dados. Vamos começar editando o arquivo src/main/resources/application.properties (o snippet abaixo mostra apenas os parâmetros que precisam ser alterados!):
appsearch.url=https://dc3ff02216a54511ae43293497c31b20.ent-search.westeurope.azure.elastic-cloud.com
appsearch.engine=web-crawler-search-engine
appsearch.key=search-untdq4d62zdka9zq4mkre4vv
feign.client.config.appsearch.defaultRequestHeaders.Authorization=Bearer search-untdq4d62zdka9zq4mkre4vvSe não quiser inserir nenhuma senha para login, faça login na instância do Kibana por meio da interface do usuário do Elastic Cloud e vá para Enterprise Search > App Search.
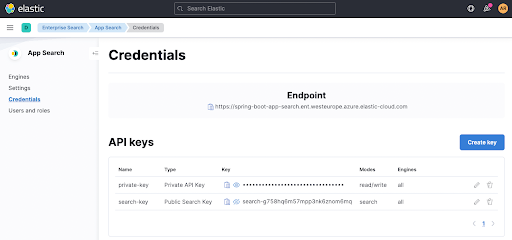
Você pode extrair o appsearch.key e o parâmetro de busca feign... da página Credentials no App Search. O mesmo se aplica ao Endpoint que é mostrado no topo.
Agora, ao executar ./gradlew clean check, o endpoint correto do App Search é
alcançado, mas os testes continuam falhando porque ainda não indexamos nenhum dado. Vamos fazer isso agora!
Configuração do rastreador
Antes de configurar um rastreador, precisamos criar um container para nossos documentos. Isso é chamado de engine agora, então vamos criar um. Dê ao seu mecanismo o nome web-crawler-search-engine para que corresponda ao arquivo application.conf.
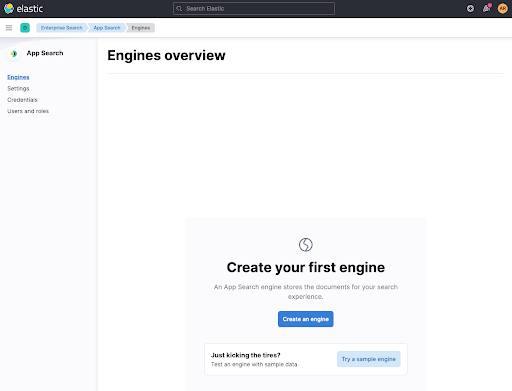
Depois disso, vamos configurar um rastreador clicando em Use The Crawler.
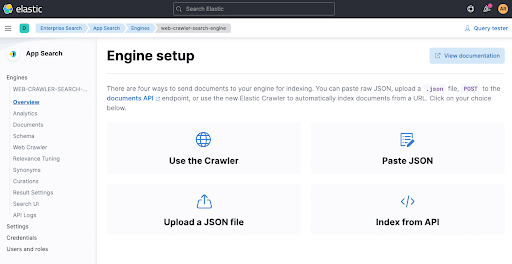
Agora adicione um domínio. Você pode adicionar seu próprio domínio aqui. Eu usei meu blog pessoal spinscale.de.
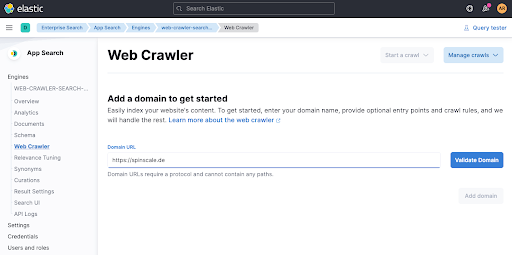
Quando clicamos em Validate Domain, algumas verificações são feitas e, em seguida, o domínio é adicionado ao mecanismo.
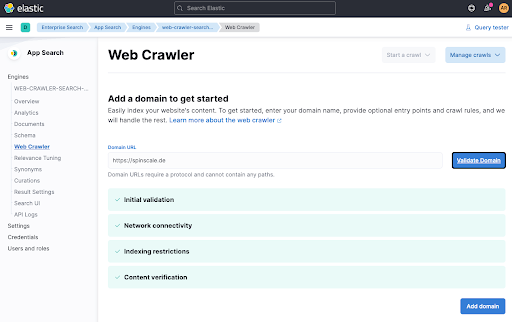
A etapa final é disparar um rastreamento manualmente para que os dados sejam indexados imediatamente. Clique em Start a crawl.
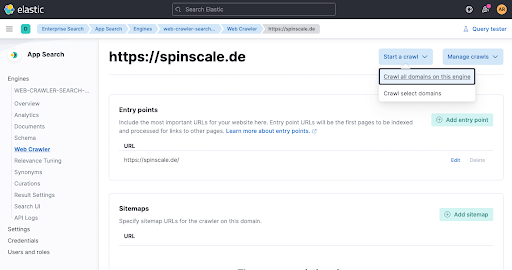
Agora espere um minuto e verifique na visão geral do mecanismo se os documentos foram adicionados.
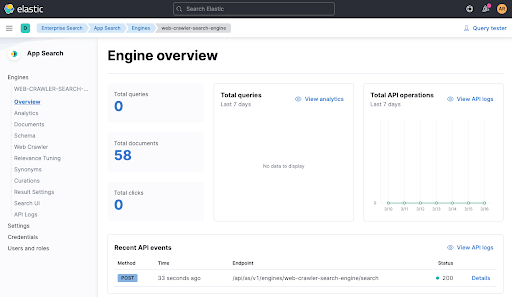
Com os dados indexados no nosso mecanismo, vamos executar novamente o teste e ver se passamos via ./gradlew check. Devemos conseguir passar agora. Você também poderá ver uma chamada de API recente na visão geral do mecanismo proveniente do teste (na parte inferior da tela acima).
Antes de iniciar nosso app, vamos dar uma olhada rápida no código do teste.
@SpringBootTest(classes = SpringBootAppSearchApplication.class, webEnvironment = SpringBootTest.WebEnvironment.NONE)
class AppSearchClientTests {
@Autowired
private AppSearchClient appSearchClient;
@Test
public void testFeignAppSearchClient() {
final QueryResponse queryResponse = appSearchClient.search(Query.of("seccomp"));
assertThat(queryResponse.getResults()).hasSize(4);
assertThat(queryResponse.getResults().stream().map(QueryResponse.Result::getTitle))
.contains("Using seccomp - Making your applications more secure",
"Presentations",
"Elasticsearch - Securing a search engine while maintaining usability",
"Posts"
);
assertThat(queryResponse.getResults().stream().map(QueryResponse.Result::getUrl))
.contains("https://spinscale.de/posts/2020-10-27-seccomp-making-applications-more-secure.html",
"https://spinscale.de/presentations.html",
"https://spinscale.de/posts/2020-04-07-elasticsearch-securing-a-search-engine-while-maintaining-usability.html",
"https://spinscale.de/posts/"
);
}
}Esse teste dispara a aplicação spring sem vincular a uma porta, injeta automaticamente a classe AppSearchClient e executa um teste que procura seccomp.
Inicialização da aplicação
É hora de começar a trabalhar e verificar se nossas aplicações são inicializadas.
./gradlew bootRunVocê deverá ver algumas mensagens de logging, mas o mais importante é que sua aplicação tenha iniciado assim:
2022-03-16 15:43:01.573 INFO 21247 --- [ restartedMain] d.s.s.SpringBootAppSearchApplication : Started SpringBootAppSearchApplication in 1.114 seconds (JVM running for 1.291)Agora você pode abrir o app em um navegador e dar uma olhada, mas eu gostaria primeiro de dar uma olhada no código Java.
Definição de uma interface apenas para nosso cliente de busca
Para poder consultar o endpoint do App Search no Spring Boot, precisamos apenas implementar uma interface devido ao uso do Feign. Não precisamos nos preocupar com a serialização do JSON ou em criar conexões HTTP. Podemos trabalhar apenas com POJOs. Esta é a nossa definição para nosso cliente do App Search.
@FeignClient(name = "appsearch", url="${appsearch.url}")
public interface AppSearchClient {
@GetMapping("/api/as/v1/engines/${appsearch.engine}/search")
QueryResponse search(@RequestBody Query query);
}O cliente usa as definições application.properties para o url e o engine para que nada disso precise ser especificado como parte da chamada de API. Além disso, esse cliente usa os cabeçalhos definidos no arquivo application.properties. Dessa forma, nenhum código de aplicação contém URLs, nomes de mecanismo ou cabeçalhos de autenticação customizados.
As únicas classes que requerem mais implementação são Query para modelar o corpo da solicitação e QueryResponse para modelar a resposta da solicitação. Optei por modelar apenas os campos absolutamente necessários na resposta, embora geralmente contenha muito mais. Sempre que precisar de mais dados, posso adicioná-los à classe QueryResponse.
A classe de consulta consiste apenas no campo query por enquanto.
public class Query {
private final String query;
public Query(String query) {
this.query = query;
}
public String getQuery() {
return query;
}
public static Query of(String query) {
return new Query(query);
}
}Então, finalmente, vamos executar algumas buscas dentro da aplicação.
Consultas e renderização do lado do servidor
A aplicação de amostra implementa três modelos de consulta à instância do App Search e a integra na aplicação Spring Boot. O primeiro envia um termo de busca para o app Spring Boot, que envia a consulta para o App Search e, em seguida, renderiza os resultados via thymeleaf, a dependência de renderização padrão no Spring Boot. Este é o controlador.
@Controller
@RequestMapping(path = "/")
public class MainController {
private final AppSearchClient appSearchClient;
public MainController(AppSearchClient appSearchClient) {
this.appSearchClient = appSearchClient;
}
@GetMapping("/")
public String main(@RequestParam(value = "q", required = false) String q,
Model model) {
if (q != null && q.trim().isBlank() == false) {
model.addAttribute("q", q);
final QueryResponse response = appSearchClient.search(Query.of(q));
model.addAttribute("results", response.getResults());
}
return "main";
}
}Observando o método main(), há uma verificação do parâmetro q. Se ele existir, a consulta será enviada para o App Search, e o model será enriquecido com os resultados. Em seguida, o modelo thymeleaf main.html é renderizado. Ele deverá ficar assim:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org"
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content">
<div>
<form action="/" method="get">
<input autocomplete="off" placeholder="Enter search terms..."
type="text" name="q" th:value="${q}" style="width:20em" >
<input type="submit" value="Search" />
</form>
</div>
<div th:if="${results != null && !results.empty}">
<div th:each="result : ${results}">
<h4><a th:href="${result.url}" th:text="${result.title}"></a></h4>
<blockquote style="font-size: 0.7em" th:text="${result.description}"></blockquote>
<hr>
</div>
</div>
</div>
</body>
</html>O modelo verifica a variável results e, se estiver definida, iterará nessa lista. Para cada resultado, o mesmo modelo é renderizado, que fica assim:
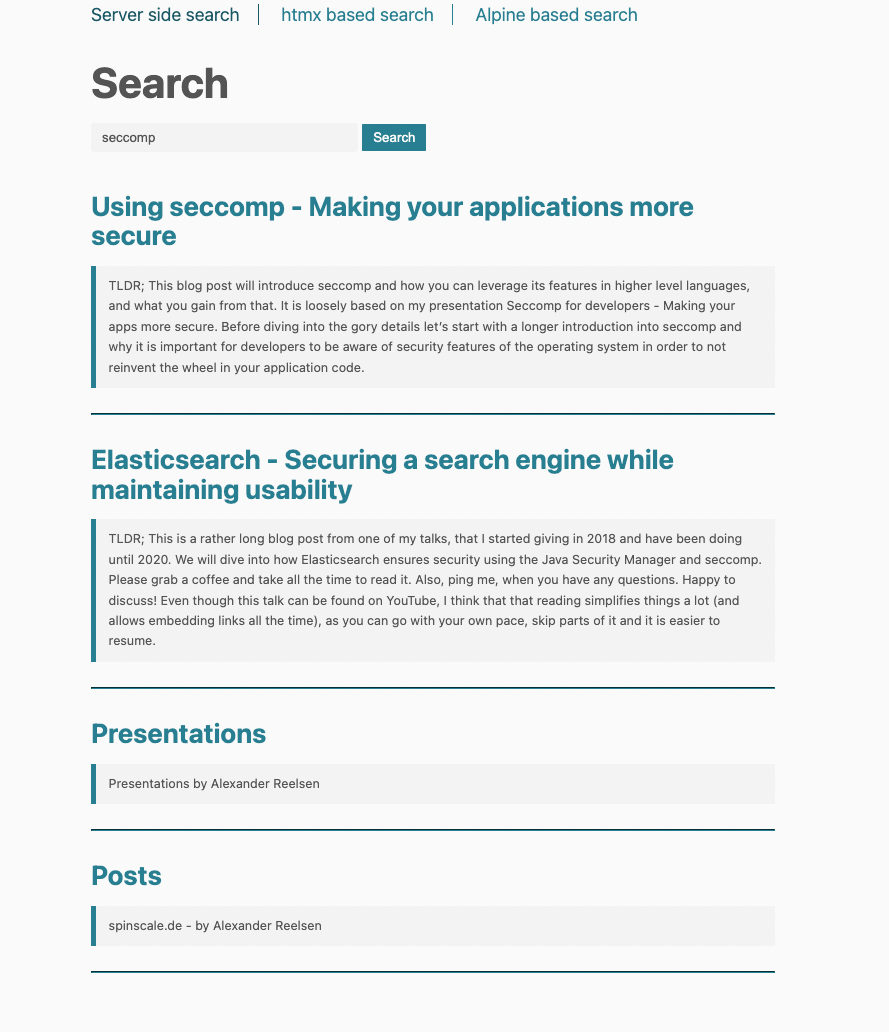
Uso de htmx para atualizações dinâmicas de páginas
Como você pode ver na navegação superior, podemos alterar a forma de busca entre três alternativas. Quando clicamos na segunda, chamada de busca baseada em htmx, o modelo de execução é ligeiramente alterado.
Em vez de recarregar a página inteira, apenas a parte com os resultados é substituída pelo que o servidor retorna. A parte boa disso é que pode ser feito sem escrever nenhum javascript. Isso é possível devido à incrível biblioteca htmx. Citando a descrição do site https://htmx.org/, o htmx fornece acesso a AJAX, transições CSS, WebSockets e eventos enviados pelo servidor diretamente em HTML, usando atributos, para que você possa criar interfaces de usuário modernas com a simplicidade e o poder do hipertexto.
Neste exemplo, apenas um pequeno subconjunto de htmx é usado. Vamos dar uma olhada nas duas definições de endpoint primeiro. Uma para renderizar o HTML e outra para retornar apenas o snippet de HTML necessário para atualizar a parte da página.
O htmx fornece acesso a AJAX, transições CSS, WebSockets e eventos enviados pelo servidor diretamente em HTML, usando atributos, para que você possa criar interfaces de usuário modernas com a simplicidade e o poder do hipertexto.
O primeiro renderiza o modelo htmx-main, enquanto o segundo endpoint renderiza os resultados. O modelo htmx-main fica assim:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org"
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content">
<div>
<form action="/search" method="get">
<input type="search"
autocomplete="off"
id="searchbox"
name="q" placeholder="Begin Typing To Search Articles..."
hx-post="/htmx-search"
hx-trigger="keyup changed delay:500ms, search"
hx-target="#search-results"
hx-indicator=".htmx-indicator"
style="width:20em">
<span class="htmx-indicator" style="padding-left: 1em;color:red">Searching... </span>
</form>
</div>
<div id="search-results">
</div>
</div>
</body>
</html>A mágica acontece nos atributos hx- do elemento HTML <input>. Lendo em voz alta, isso se traduz em:
- Disparar uma solicitação HTTP apenas se não houver atividade de digitação por 500 ms.
- Em seguida, enviar uma solicitação HTTP POST para /htmx-search.
- Enquanto espera, mostre o elemento .htmx-indicator.
- A resposta deve ser renderizada no elemento com o ID #search-results.
Pense na enorme quantidade de javascript que você precisaria para toda a lógica relacionada aos principais ouvintes, exibindo elementos para aguardar uma resposta ou enviar a solicitação AJAX.
A outra grande vantagem é o fato de poder usar sua solução de renderização do lado do servidor favorita para criar o HTML que está sendo retornado. Isso significa que podemos permanecer no ecossistema thymeleaf em vez de ter de implementar alguma linguagem de modelagem do lado do cliente. Isso torna o modelo htmx-search-results muito simples, apenas iterando os resultados:
<div th:each="result : ${results}">
<h4><a th:href="${result.url}" th:text="${result.title}"></a></h4>
<blockquote style="font-size: 0.7em" th:text="${result.description}"></blockquote>
<hr>
</div>Uma diferença em relação ao primeiro exemplo é que o URL dessa busca nunca é alterado, portanto, você não pode marcá-lo como favorito. Embora haja suporte de histórico no htmx, eu o deixei de fora por causa deste exemplo, pois requer uma implementação mais cuidadosa para fazê-lo corretamente.
@GetMapping("/alpine")
public String alpine() {
return "alpine-js";
}O modelo alpine-js.html requer mais algumas explicações, mas vamos dar uma olhada primeiro:
<!DOCTYPE html>
<html
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content" x-data="{ q: '', response: null }">
<div>
<form @submit.prevent="">
<input type="search" autocomplete="off" placeholder="Begin Typing To Search Articles..." style="width:20em"
x-model="q"
@keyup="client.search(q).then(resultList => response = resultList)">
</form>
</div>
<template x-if="response != null && response.info.meta != null && response.info.meta.request_id != null">
<template x-for="result in response.results">
<template x-if="result.data != null && result.data.title != null && result.data.url != null && result.data.meta_description != null ">
<div>
<h4><a class="track-click" :data-request-id="response.info.meta.request_id" :data-document-id="result.data.id.raw" :data-query="q" :href="result.data.url.raw" x-text="result.data.title.raw"></a></h4>
<blockquote style="font-size: 0.7em" x-text="result.data.meta_description.raw"></blockquote>
<hr>
</div>
</template>
</template>
</template>
<script th:inline="javascript">
var client = window.ElasticAppSearch.createClient({
searchKey: [[${@environment.getProperty('appsearch.key')}]],
endpointBase: [[${@environment.getProperty('appsearch.url')}]],
engineName: [[${@environment.getProperty('appsearch.engine')}]]
});
document.addEventListener("click", function(e) {
const el = e.target;
if (!el.classList.contains("track-click")) return;
client.click({
query: el.getAttribute("data-query"),
documentId: el.getAttribute("data-document-id"),
requestId: el.getAttribute("data-request-id")
});
});
</script>
</div>
</body>
</html>A primeira grande diferença é o uso real do JavaScript para inicializar o cliente ElasticAppSearch — usando as propriedades configuradas do arquivo application.properties. Assim que esse cliente é inicializado, podemos usá-lo nos atributos HTML.
O código inicializa duas variáveis a serem usadas:
<div layout:fragment="content" x-data="{ q: '', response: null }">A variável q conterá a consulta do formulário de entrada, e a resposta conterá a resposta de uma busca. A próxima parte interessante é a definição do formulário.
<form @submit.prevent="">
<input type="search" autocomplete="off" placeholder="Search Articles..."
x-model="q"
@keyup="client.search(q).then(resultList => response = resultList)">
</form>O uso de <input x-model="q"...> vincula a variável q à entrada e é atualizado sempre que o usuário digita. Há também um evento para `keyup` para executar uma busca usando client.search() e atribuir o resultado à variável response. Assim que a busca do cliente retornar, a variável de resposta não estará mais vazia. Por fim, o uso de @submit.prevent="" garante que o formulário não seja enviado.
Em seguida, todas as
<div>
<h4><a class="track-click"
:data-request-id="response.info.meta.request_id"
:data-document-id="result.data.id.raw"
:data-query="q"
:href="result.data.url.raw"
x-text="result.data.title.raw">
</a></h4>
<blockquote style="font-size: 0.7em"
x-text="result.data.meta_description.raw"></blockquote>
<hr>
</div>Essa renderização é um pouco diferente das duas implementações de renderização do lado do servidor, pois contém funcionalidade adicional para rastrear links clicados. A parte importante para renderizar os modelos são as propriedades :href e x-text para definir o link e o texto do link. Os outros parâmetros :data são para rastrear links.
Rastreamento de cliques
Então, por que você desejaria rastrear cliques em links? Simples: é uma das possibilidades de descobrir se seus resultados de busca são bons, mensurando se seus usuários clicaram neles. É também por isso que há mais javascript incluído neste snippet de HTML. Vamos dar uma olhada primeiro em como isso fica no Kibana.
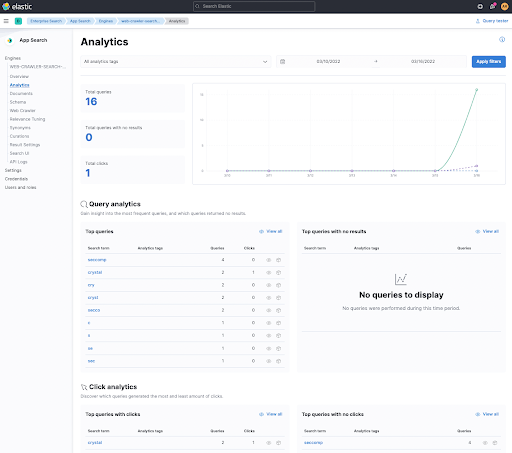
Você pode ver o Click analytics na parte inferior, que rastreou um clique depois que eu busquei por crystal no primeiro link clicado. Ao clicar nesse termo, você pode ver qual documento foi clicado e basicamente seguir a trilha de cliques dos seus usuários.
Então, como isso é implementado no nosso pequeno app? Usando um ouvinte de javascript click para determinados links. Este é o snippet de javascript:
document.addEventListener("click", function(e) {
const el = e.target;
if (!el.classList.contains("track-click")) return;
client.click({
query: el.getAttribute("data-query"),
documentId: el.getAttribute("data-document-id"),
requestId: el.getAttribute("data-request-id")
});
});Se um link clicado tiver a classe track-click, um evento de clique será enviado usando o cliente ElasticAppSearch. Esse evento contém o termo de consulta original, bem como o documentId e o requestId, que faziam parte da resposta de busca e foram renderizados no elemento no modelo acima.
Também poderíamos adicionar essa funcionalidade à renderização do lado do servidor, fornecendo essas informações quando um usuário clicar em um link, portanto, isso não é exclusivo do navegador. Para simplificar, pulei a implementação aqui.
Resumo
Espero que você tenha gostado de ver uma introdução ao Elastic App Search do ponto de vista do desenvolvedor e as diferentes possibilidades de integrá-lo às suas aplicações. Confira o repositório do GitHub e siga o exemplo.
Você pode usar o Terraform com o provedor do Elastic Cloud para começar a trabalhar rapidamente no Elastic Cloud.
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir