Uso de um modelo de PLN em japonês no Elasticsearch para habilitar buscas semânticas


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
Encontrar rapidamente os documentos necessários em meio ao grande volume de documentos internos e informações de produtos gerados todos os dias é uma tarefa extremamente importante tanto no trabalho quanto no cotidiano. No entanto, se precisarmos fazer buscas em um grande volume de documentos, o processo poderá ser demorado até mesmo para os computadores, que precisarão reler todos os documentos em tempo real para encontrar o arquivo certo. Foi isso que levou ao surgimento do Elasticsearch® e de outros softwares de mecanismo de busca. Quando um mecanismo de busca é usado, os dados do índice são criados primeiro para que os principais termos de busca incluídos nos documentos possam ser usados para localizar rapidamente esses documentos.
No entanto, mesmo que o usuário tenha uma ideia geral do tipo de informação que está procurando, ele pode não conseguir se lembrar de uma palavra-chave adequada ou pode buscar outra expressão que tenha o mesmo significado. O Elasticsearch possibilita que sinônimos e termos semelhantes sejam definidos para lidar com tais situações, mas em alguns casos pode ser difícil simplesmente usar uma tabela de correspondência para converter uma consulta de busca em uma consulta mais adequada.
Para atender a essa necessidade, o Elasticsearch 8.0 lançou o recurso de busca vetorial, que faz a busca pelo conteúdo semântico de uma frase. Além disso, também temos uma série de posts do blog sobre como usar o Elasticsearch para realizar buscas vetoriais e outras tarefas de PLN. No entanto, até a versão 8.8, não era possível analisar corretamente textos em outros idiomas além do inglês.
Com a versão 8.9, a Elastic adicionou uma funcionalidade para analisar adequadamente o japonês no processamento da análise de texto. Essa funcionalidade permite que o Elasticsearch execute buscas semânticas, como busca vetorial em texto no idioma japonês, bem como tarefas de processamento de linguagem natural, como análise de sentimentos em japonês. Neste artigo, forneceremos instruções passo a passo específicas sobre como usar esses recursos.
Pré-requisitos
Antes de implementar a busca semântica, confirme os pré-requisitos para usar esse recurso. Nos clusters do Elasticsearch, funções individuais recebem funções de nó. Enquanto isso, os nós de machine learning do Elasticsearch orientam o modelo de machine learning. Para usar esse recurso, deve haver um nó de machine learning ativo no cluster do Elasticsearch; portanto, confirme antecipadamente se esse é o caso. Você também deve ter uma licença Platinum ou superior para usar nós de machine learning. No entanto, uma licença de avaliação poderá ser usada se você quiser apenas testar os recursos para ver se funcionam. Para verificar a funcionalidade da operação em um ambiente de desenvolvimento ou instância semelhante, ative a avaliação na tela do Kibana® ou por meio da API.
Processo de execução de uma busca semântica
As etapas a seguir são necessárias para executar uma busca semântica no Elasticsearch.
(Preparação) Instale o Eland e bibliotecas relacionadas na estação de trabalho.
Importe o modelo de machine learning para possibilitar a realização de tarefas de processamento de linguagem natural.
Indexe os resultados da análise de texto no modelo de machine learning importado.
Realize uma busca de kNN usando o modelo de machine learning.
A busca semântica não é a única coisa que é possível fazer com o processamento de linguagem natural. Na segunda metade deste post do blog, apresentaremos exemplos de como usar o modelo de machine learning, que permite a execução de tarefas de classificação de texto, para realizar análises de sentimentos do texto (categorias positiva e negativa).
Vamos prosseguir com as explicações detalhadas sobre como realizar as tarefas a seguir.
Instalação do Eland
Agora o Elasticsearch é capaz de se comportar como uma plataforma de processamento de linguagem natural. No entanto, a realidade é que nenhum processamento aprofundado de linguagem natural é realmente implementado no Elasticsearch. Qualquer processamento de linguagem natural necessário deve ser importado para o Elasticsearch pelo usuário como um modelo de machine learning. Esse processo de importação é realizado usando o Eland. Como os usuários podem importar livremente um modelo externo dessa forma, eles podem adicionar a funcionalidade de machine learning sempre que precisarem.
O Eland é uma biblioteca Python fornecida pela Elastic que permite aos usuários vincular dados do Elasticsearch a bibliotecas abrangentes de machine learning do Python, como PyTorch e scikit-learn. A ferramenta de linha de comando eland_import_hub_model incluída no Eland pode ser usada para importar para o Elasticsearch modelos de PLN que foram publicados no Hugging Face. Todas as tarefas de linha de comando abordadas abaixo neste artigo pressupõem o uso de um notebook do Python, como o Google Colaboratory. (Naturalmente, outros tipos de terminais podem ser usados, como um Mac ou uma máquina com Linux. Nesses casos, ignore o ! no início dos comandos abaixo.)
Primeiro, instale as bibliotecas dependentes.
!pip install torch==1.13
!pip install transformers
!pip install sentence_transformers
!pip install fugashi
!pip install ipadic
!pip install unidic_litePrecisaremos das bibliotecas Fugashi, ipadic e unidic_lite para usar um modelo japonês.
Depois que essas bibliotecas forem instaladas, o Eland também poderá ser instalado. O Eland 8.9.0 ou posterior será necessário para usar um modelo japonês, portanto, anote o número da versão.
!pip install elandQuando a instalação for concluída, use o comando abaixo para confirmar que o Eland pode ser usado.
!eland_import_hub_model -h
Importando o modelo de PLN
O principal método para habilitar a busca vetorial é o mesmo usado em inglês neste artigo. Abordaremos brevemente o mesmo procedimento aqui para relembrar.
Conforme explicamos acima, o modelo de machine learning apropriado deve ser importado para o Elasticsearch para o processamento de PLN. Você pode implementar um modelo de machine learning por conta própria usando PyTorch, mas isso também requer um conhecimento suficiente de machine learning e processamento de linguagem natural, bem como o poder de computação que o machine learning exige. No entanto, existe agora um repositório online, o Hugging Face, que é muito utilizado por pesquisadores e desenvolvedores nas áreas de machine learning e processamento de linguagem natural, e muitos modelos são publicados nesse repositório. Neste exemplo, usaremos um modelo publicado no Hugging Face para implementar a funcionalidade de busca semântica.
Para começar, vamos escolher um modelo no Hugging Face que incorporará (vetorizará) frases em japonês em vetores numéricos. Neste artigo, usaremos o modelo do link abaixo.
Vamos abordar alguns pontos a serem observados ao selecionar um modelo japonês na versão 8.9.
Primeiro, apenas o algoritmo do modelo BERT é compatível. Verifique as tags no Hugging Face e outras informações para confirmar se o modelo de PLN desejado é um modelo treinado em BERT.
Além disso, para BERT e outras tarefas de PLN, o texto inserido é “pré-tokenizado”, ou seja, é dividido em unidades no nível da palavra. Neste caso, um mecanismo de análise morfológica do idioma japonês é usado para pré-tokenizar nosso texto em japonês. O Elasticsearch 8.9 é compatível com análise morfológica usando o MeCab. Na página de modelos do Hugging Face, abra a guia “Files and versions” (Arquivos e versões) e visualize o conteúdo do arquivo tokenizer_config.json. Confirme se o valor de word_tokenizer_type é mecab.
{
"do_lower_case": false,
"word_tokenizer_type": "mecab",
"subword_tokenizer_type": "wordpiece",
"mecab_kwargs": {
"mecab_dic": "unidic_lite"
}
}
Infelizmente, se o modelo que você quiser usar tiver um valor diferente de mecab para word_tokenizer_type, esse modelo não será compatível no momento com o Elasticsearch. Recebemos de bom grado feedback sobre qualquer tipo específico de tokenizador de palavras (word_tokenizer_type) para o qual seja necessário suporte.
Depois que você decidiu qual modelo será importado, as etapas necessárias para a importação são as mesmas de um modelo em inglês. Primeiro, use eland_import_hub_model para importar o modelo para o Elasticsearch. Consulte esta página para saber como usar o eland_import_hub_model.
!eland_import_hub_model \
--url "https://your.elasticserach" \
--es-api-key "your_api_key" \
--hub-model-id cl-tohoku/bert-base-japanese-v2 \
--task-type text_embedding \
--start
Depois que o modelo for importado, ele será exibido em Machine Learning > Model Management > Trained Models (Machine Learning > Gerenciamento de modelos > Modelos treinados) no Kibana. Abra a guia “Config” do modelo para ver se “bert_ja” está sendo usado para tokenização e se o modelo está configurado corretamente para lidar com o japonês.
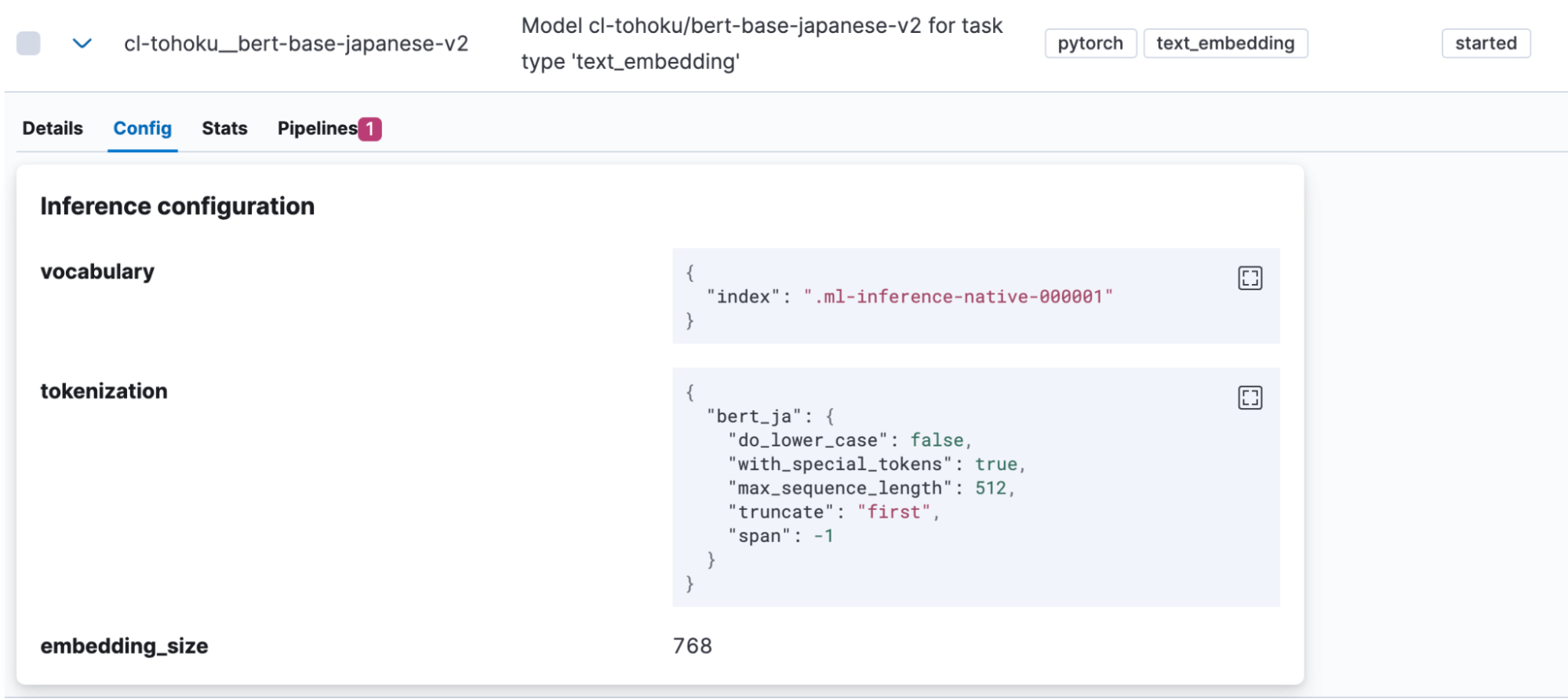
Após a conclusão do upload do modelo, vamos testá-lo. Clique em um botão na coluna Actions (Ações) para abrir o menu.
Selecione “Test model” (Testar modelo), digite qualquer frase em japonês em “Input text” (Texto de entrada) e clique no botão “Test” (Testar).
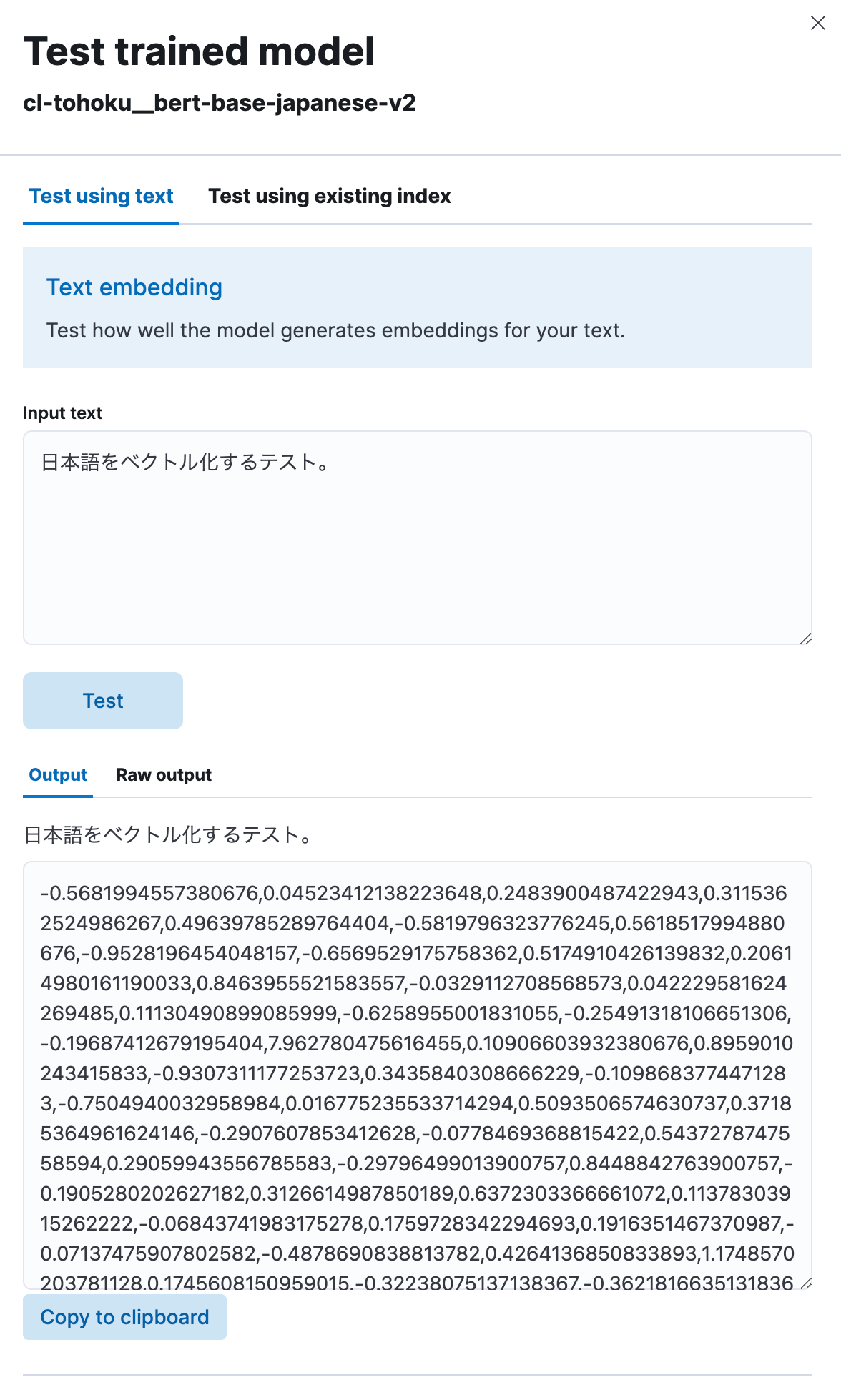
Você verá que o modelo vetorizou o texto em japonês inserido e o converteu em uma string numérica, conforme mostrado aqui. Parece estar funcionando corretamente.
Implementação de busca semântica usando embeddings vetoriais
Agora que o modelo foi carregado, podemos implementar a funcionalidade de busca semântica (busca vetorial) no Elasticsearch.
Primeiro, para realizar uma busca vetorial, é necessário indexar os valores vetoriais nos quais o texto original em japonês foi incorporado. Para fazer isso, criaremos um pipeline que inclui um processador de inferência para vetorizar o texto em japonês antes de ele ser inserido no índice, usando o modelo carregado anteriormente.
PUT _ingest/pipeline/japanese-text-embeddings
{
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "cl-tohoku__bert-base-japanese-v2",
"target_field": "text_embedding",
"field_map": {
"title": "text_field"
}
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
Quando o processador de inferência é usado, o modelo especificado em model_id é aplicado ao texto salvo no campo de destino (neste caso,title), e a saída dele é armazenada em target_field. Além disso, cada modelo espera um campo diferente (neste caso, text_field) para o valor de entrada do processo. Por esse motivo, field_map é usado para especificar a correspondência entre o campo de entrada real do destino do processo e o nome do campo esperado pelo modelo de ML.
Depois que o pipeline estiver configurado, ele poderá ser usado para criar índices. Como serão necessários campos nesses índices para armazenar vetores, definiremos o mapeamento apropriado. No exemplo abaixo, o campo text_embedding.predicted_value está configurado para conter dados dense_vector de 768 dimensões. Observe que o número de dimensões varia de acordo com o modelo. Verifique a página do modelo no Hugging Face (valor hidden_size no config.json do modelo) ou em outro lugar e defina um número apropriado.
PUT japanese-text-with-embeddings
{
"mappings": {
"properties": {
"text_embedding.predicted_value": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "cosine"
}
}
}
}
Se já houver um índice que inclua os dados do texto em japonês direcionados para busca, a API reindex poderá ser usada. Neste exemplo, os dados do texto original estão no índice japanese-text. Um documento contendo a vetorização desse texto é registrado no índice japanese-text-embeddings.
POST _reindex?wait_for_completion=false
{
"source": {
"index": "japanese-text"
},
"dest": {
"index": "japanese-text-with-embeddings",
"pipeline": "japanese-text-embeddings"
}
}
Como alternativa, um documento pode ser registrado diretamente para fins de teste, especificando um pipeline criado conforme mostrado abaixo e armazenando-o no índice.
POST japanese-text-with-embeddings/_doc?pipeline=japanese-text-embeddings
{
"title": "日本語のドキュメントをベクトル化してインデックスに登録する。"
}
Depois que o documento vetorizado for registrado, finalmente será possível executar uma busca. Uma busca de kNN (k-ésimo vizinho mais próximo) é um método disponível que faz uso de vetores. Agora executaremos uma busca vetorial de kNN usando a opção query_vector_builder na API _search padrão. Quando query_vector_builder é usado, o modelo especificado em model_id pode ser usado para converter o texto em model_text em uma consulta contendo um vetor no qual esse texto está incorporado.
GET japanese-text-with-embeddings/_search
{
"knn": {
"field": "text_embedding.predicted_value",
"k": 10,
"num_candidates": 100,
"query_vector_builder": {
"text_embedding": {
"model_id": "cl-tohoku__bert-base-japanese-v2",
"model_text": "日本語でElasticsearchを検索したい"
}
}
}
}
Quando essa consulta de busca é executada, o seguinte tipo de resposta é recebido:
"hits": [
{
"_index": "japanese-text-with-embeddings",
"_id": "vOD6MIoBdRdLZd7EKaBy",
"_score": 0.82438844,
"_source": {
"title": "日本語のドキュメントをベクトル化してインデックスに登録する。",
"text_embedding": {
"predicted_value": [
-0.13586345314979553,
-0.6291824579238892,
0.32779985666275024,
0.36690405011177063,
(略、768次元のベクトルが表示される)
],
"model_id": "cl-tohoku__bert-base-japanese-v2"
}
}
}
]
Busca bem-sucedida! A busca também contém campos nos quais o japonês foi incorporado. Na maioria dos casos de uso reais, não é necessário que esse texto seja incluído na resposta. Nesses casos, use o parâmetro _source ou algum outro método para excluir essas informações da resposta (ou execute outra ação semelhante).
Para ajustar as classificações de busca, foi lançado o recurso Reciprocal Rank Fusion (RRF), que combina habilmente os resultados de buscas vetoriais e buscas de palavras-chave padrão. Não deixe de dar uma olhada nele também.
Isso conclui nosso post sobre como habilitar a busca semântica usando a busca vetorial. Embora a configuração dessa funcionalidade possa exigir mais trabalho do que uma busca padrão e você possa encontrar algum vocabulário de machine learning exclusivo, você será capaz de executar buscas quase da mesma maneira que o normal quando a fase de configuração for concluída. Portanto, convidamos você a experimentar!
Classificação de texto (análise de sentimentos)
Como vimos que podemos usar a busca vetorial usando kNN em japonês, vamos ver como usar outras tarefas de PLN da mesma maneira.
A classificação de texto é uma tarefa na qual a entrada de texto é colocada em algum tipo de categoria. Para este exemplo, usaremos um modelo de análise de sentimentos encontrado no Hugging Face que julga se a entrada de texto em japonês é acompanhada de um sentimento positivo ou negativo (koheiduck/bert-japanese-finetuned-sentiment). Olhando para seu tokenizer_config.json, pode-se ver que esse modelo também usa mecab como word_tokenizer_type; portanto, pode ser usado com o bert_ja do Elasticsearch.
Como fizemos antes, use o Eland para importar o modelo para o Elasticsearch.
!eland_import_hub_model \
--url "https://your.elasticserach" \
--es-api-key "your_api_key" \
--hub-model-id koheiduck/bert-japanese-finetuned-sentiment \
--task-type text_classification \
--start
Depois que o modelo for importado, ele será exibido em Machine Learning > Model Management > Trained Models (Machine Learning > Gerenciamento de modelos > Modelos treinados) no Kibana.
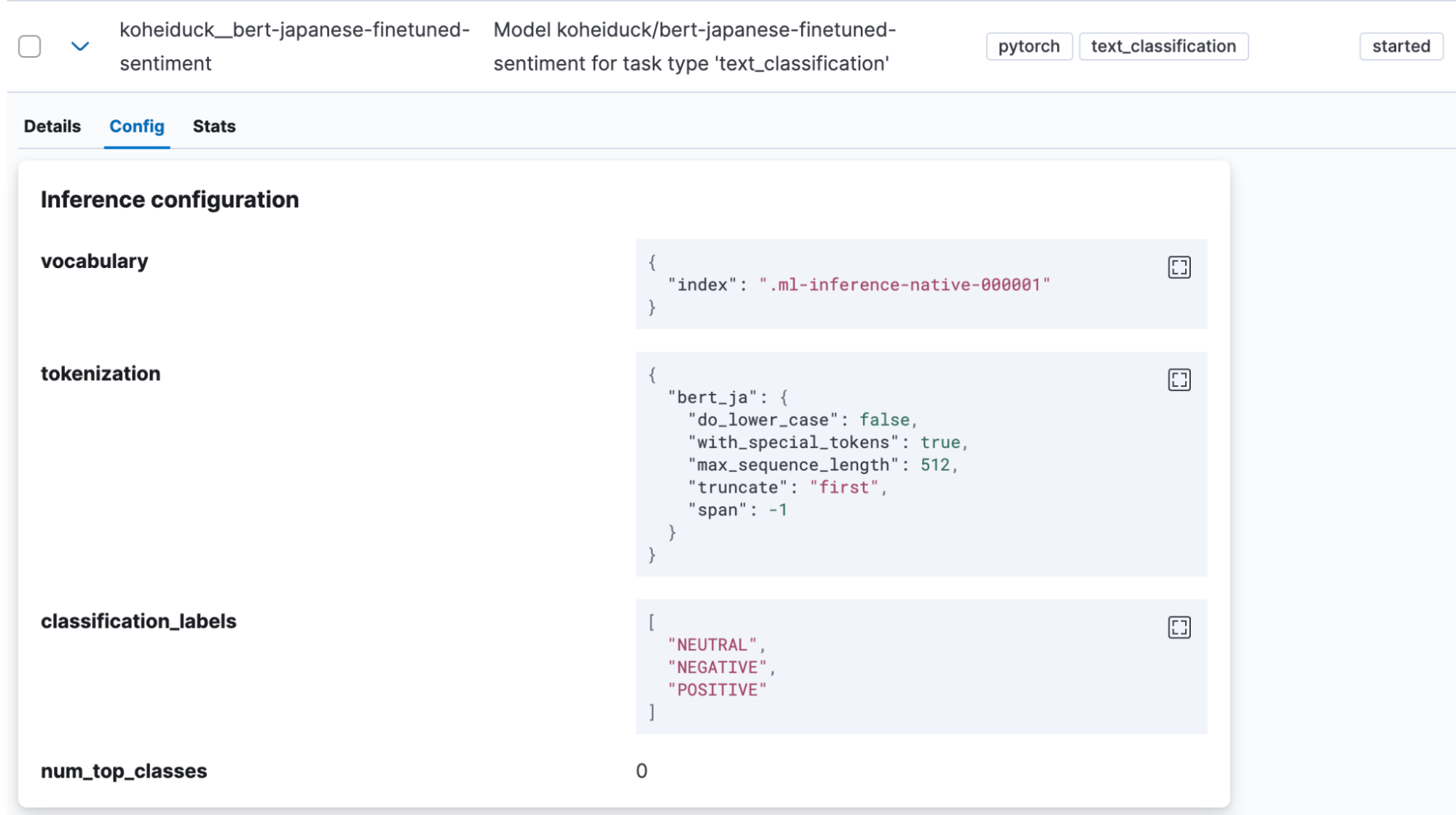
Neste caso também, clique em “Test model” (Testar modelo) no menu Actions (Ações).
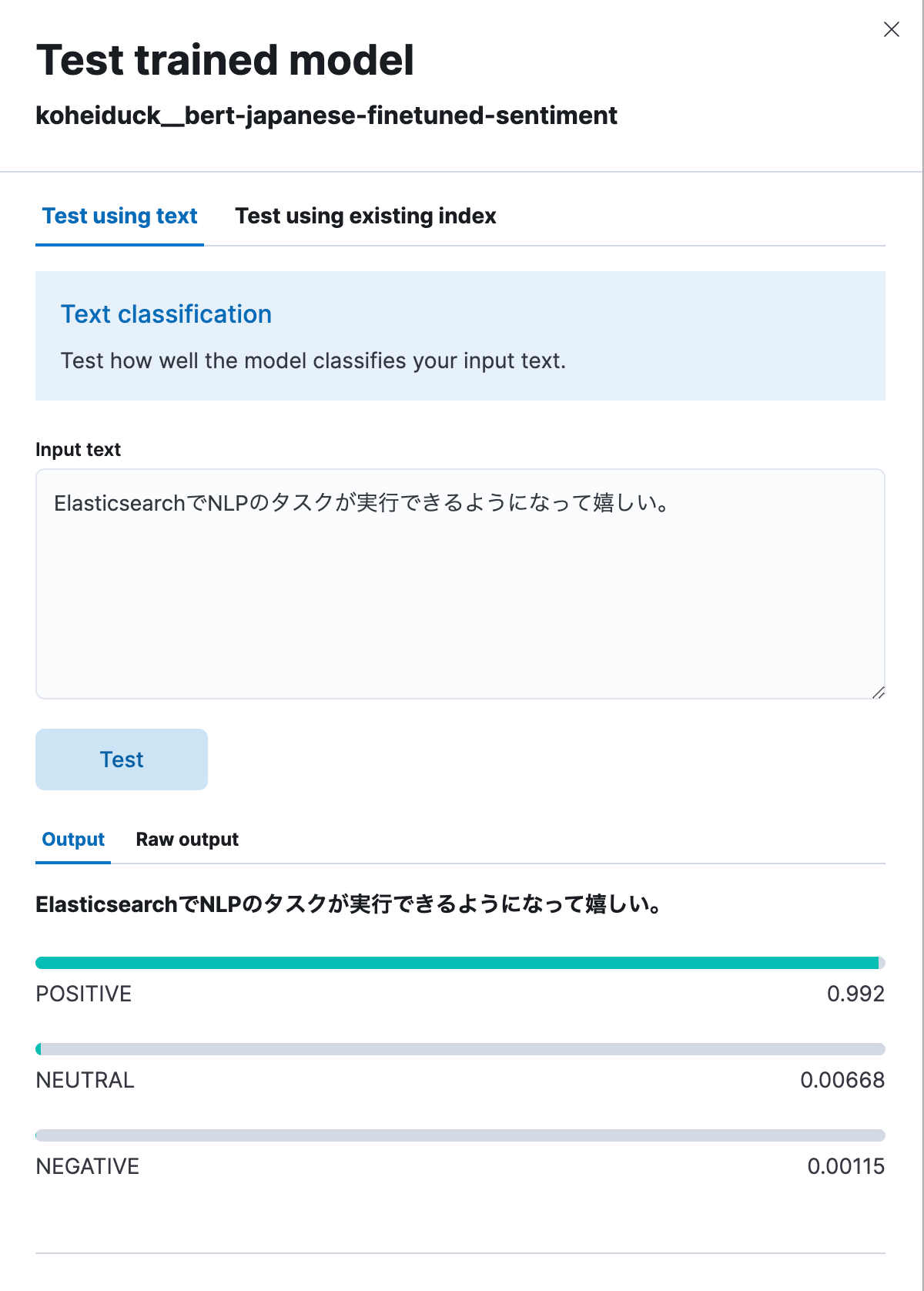
Como antes, será exibida uma caixa de diálogo para o teste. Digite aqui o texto, que será classificado como POSITIVE (positivo), NEUTRAL (neutro) ou NEGATIVE (negativo). Como teste, vamos inserir: “Estou feliz por agora poder executar tarefas de PLN com o Elasticsearch.” Conforme mostrado abaixo, isso gerou um resultado de 99,2% positivo.
Abaixo vemos o mesmo processo executado via API.
POST _ml/trained_models/koheiduck__bert-japanese-finetuned-sentiment/_infer
{
"docs": [{"text_field": "ElasticsearchでNLPのタスクが実行できるようになって嬉しい。"}],
"inference_config": {
"text_classification": {
"num_top_classes": 3
}
}
}
A resposta é a seguinte:
{
"inference_results": [
{
"predicted_value": "POSITIVE",
"top_classes": [
{
"class_name": "POSITIVE",
"class_probability": 0.9921651090124636,
"class_score": 0.9921651090124636
},
{
"class_name": "NEUTRAL",
"class_probability": 0.006682728902566756,
"class_score": 0.006682728902566756
},
{
"class_name": "NEGATIVE",
"class_probability": 0.0011521620849697567,
"class_score": 0.0011521620849697567
}
],
"prediction_probability": 0.9921651090124636
}
]
}Como esse processo também pode ser executado com o processador de inferência, é possível anexar os resultados da análise antes que o texto em japonês seja indexado. Por exemplo, aplicar esse processo ao texto de comentários de produtos específicos pode ajudar a converter as avaliações desses produtos feitas por usuários em valores numéricos.
Feedback
A partir do Elasticsearch 8.9, o suporte para o modelo de PLN em japonês ainda está no estágio de prévia técnica. Entre em contato com a Elastic® se encontrar algum bug ou precisar de suporte para algoritmos não BERT, tokenizadores não MeCab etc.
O GitHub Issues é a melhor maneira de enviar feedback à Elastic. Em “Issues” (Ocorrências) no repositório elastic/elasticsearch, adicione a tag :ml e deixe sua solicitação. A equipe apropriada fará o trabalho de investigação.
Como arquiteto consultor da Elastic (portanto, não faço parte da equipe de desenvolvimento), consegui adicionar suporte ao idioma japonês enviando uma solicitação pull de uma modificação via GitHub como colaborador externo. Se você é um desenvolvedor e tem um recurso que gostaria de solicitar para ser adicionado a um caso de uso específico, experimente fazer como eu fiz.
Conclusão
Atualmente, a Elastic está investindo muitos recursos na implementação de funcionalidade de PLN usando machine learning em seus recursos de busca, e há cada vez mais funções desse tipo que podem ser executadas no Elasticsearch. No entanto, a maioria dos recursos é lançada primeiro com suporte em inglês e suporte limitado para outros idiomas.
No entanto, estamos muito felizes por termos decidido oferecer suporte para o japonês. Esperamos que esses novos recursos do Elasticsearch ajudem a tornar suas buscas mais significativas.
O lançamento e o tempo de amadurecimento de todos os recursos ou funcionalidades descritos neste post permanecem a exclusivo critério da Elastic. Os recursos ou funcionalidades não disponíveis atualmente poderão não ser entregues dentro do prazo previsto ou nem chegar a ser entregues.
Neste post do blog, podemos ter usado ou nos referido a ferramentas de IA generativa de terceiros, que pertencem a seus respectivos proprietários e são operadas por eles. A Elastic não tem nenhum controle sobre as ferramentas de terceiros e não temos nenhuma responsabilidade por seu conteúdo, operação ou uso nem por qualquer perda ou dano que possa surgir do uso de tais ferramentas. Tenha cuidado ao usar ferramentas de IA com informações pessoais, sensíveis ou confidenciais. Os dados que você enviar poderão ser usados para treinamento de IA ou outros fins. Não há garantia de que as informações fornecidas serão mantidas em segurança ou em confidencialidade. Você deve se familiarizar com as práticas de privacidade e os termos de uso de qualquer ferramenta de IA generativa antes de usá-la.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine e marcas associadas são marcas comerciais, logotipos ou marcas registradas da Elasticsearch N.V. nos Estados Unidos e em outros países. Todos os outros nomes de empresas e produtos são marcas comerciais, logotipos ou marcas registradas de seus respectivos proprietários.
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir