Base de datos vectorial frente a base de datos de grafos: Entendiendo las diferencias


 Share on Twitter
Share on TwitterComparte en Twitter

 Share on LinkedIn
Share on LinkedInComparte en LinkedIn

 Share on Facebook
Share on FacebookComparte en Facebook

 Share by Email
Share by EmailComparte por correo electrónico

 Print this page
Print this pageImprime
La gestión de big data no solo se trata de almacenar la mayor cantidad de datos posible. Sino de poder identificar información significativa, descubrir patrones ocultos y tomar decisiones informadas. Esta búsqueda de analíticas avanzadas ha sido la fuerza impulsora detrás de las innovaciones en las soluciones de modelado y almacenamiento de datos, mucho más allá de las bases de datos relacionales tradicionales.
Dos de estas innovaciones son las bases de datos de vectores y las bases de datos de grafos. Ambas son avances importantes en la gestión de datos, que proporcionan estructuras de datos únicas con sus propias fortalezas distintivas. Pero necesitas entender cómo funcionan y en qué se diferencian antes de que puedas elegir de manera efectiva cuál es la mejor opción para tu proyecto u objetivos.
Esta publicación de blog será tu guía: describirá cómo funcionan, cómo son similares y cómo también son muy diferentes. Exploraremos las estructuras de datos contrastantes, así como sus casos de uso ideales y te ayudaremos a elegir entre los dos. Para que esto sea más fácil, lo hemos dividido en secciones:
Definición y conceptos de base de datos vectoriales
¿Qué son las bases de datos de grafos?
Comparación de bases de datos vectoriales y de grafos
Casos de uso de bases de datos vectoriales y grafos
Elegir entre bases de datos vectoriales y de grafos
Cuando termines este artículo, tendrás toda la información necesaria para tomar una decisión informada, así podrás aprovechar al máximo tus datos.
Definición y conceptos de base de datos vectoriales
En lugar de filas y columnas, una base de datos vectorial organiza los datos como puntos en un vasto espacio multidimensional. Cada punto representa un dato, y la ubicación refleja sus características en relación con otros datos. Piensa en esto como un universo en el que cada planeta es un dato, y están organizados para estar más cerca de planetas similares y más lejos de aquellos con menos similitudes.
Esto se logra almacenando los datos como vectores de alta dimensionalidad, que son representaciones numéricas de las características de datos. Estos vectores capturan la esencia de los datos que representan; así es como pueden codificarse y organizarse en el espacio multidimensional. Cuanto más cerca se encuentren dos puntos en el espacio multidimensional, más similares son los datos subyacentes.
Por eso las bases de datos vectoriales son tan eficaces en las búsquedas por similitud. Dado que los vectores se estructuran conforme a la similitud, puedes identificar rápidamente los puntos de datos más cercanos a tu vector de búsqueda. Esto los hace ideales para una serie de aplicaciones importantes:
Recuperación de imágenes y documentos: Encontrar imágenes similares basándote en el contenido, no solo en las palabras clave.
Recomendaciones personalizadas: Recomendar productos o contenido similares a aquellos con los que el usuario interactuó anteriormente.
Detección de anomalías: Identificar puntos de datos inusuales que se desvían de la norma, lo que podría indicar fraude o errores del sistema.
Machine Learning: Procesar y analizar de forma eficiente datos de alta dimensión para tareas como análisis de texto, clasificación de imágenes y procesamiento de lenguaje natural.
¿Quieres una guía más detallada? Lee «¿Qué es una base de datos vectorial?» para ver una explicación completa.
¿Qué son las bases de datos de grafos?
Si bien pueden parecer similares a primera vista, las bases de datos de grafos organizan los datos de una forma completamente diferente. En lugar de usar tablas rígidas (como una base de datos relacional) u organizar los datos por similitud (como las bases de datos vectoriales), almacenan datos en una estructura de grafos. Las entidades se representan con nodos en el grafo, y las relaciones se representan con bordes. Piensa en ellas como un mapa mental, en el que cada nodo es un círculo que representa a personas, lugares o cosas, y las líneas entre ellos (bordes) muestran cómo están conectados.
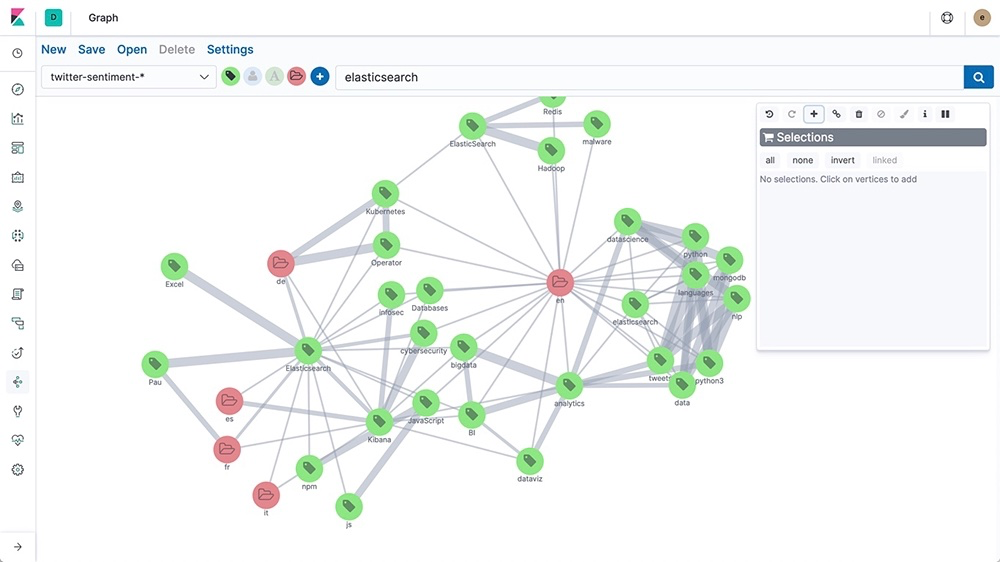
Una de las ventajas de este tipo de estructura es que es una representación más natural de relaciones complejas. Esto facilita la interpretación de las conexiones en comparación con otros tipos de bases de datos. La estructura sin esquema de las bases de datos de grafos también significa que puedes agregar con facilidad nodos y bordes nuevos a medida que aumentan tus datos, lo cual hace que sea flexible y escalable. Esto hace que las bases de datos de grafos sean ideales para muchas aplicaciones:
Análisis en tiempo real: Analizar datos en tiempo real, predecir resultados futuros y optimizar sistemas dinámicos con bases de datos de grafos.
Gestión de datos maestros: Crear una visión unificada de las entidades, resolver las ambigüedades y realizar un seguimiento de la evolución de las entidades dentro de un único grafo interconectado.
Descubrimiento de redes: Descubrir conexiones ocultas, identificar anomalías y predecir fallos en cascada analizando las relaciones dentro de las redes.
Creación de grafos de conocimiento: Crear bases de conocimiento inteligentes, responder preguntas complejas e impulsar aplicaciones inteligentes mediante entidades y conceptos interconectados.
Comparación de bases de datos vectoriales y de grafos
Ahora deberías entender qué es cada tipo de base de datos y cómo estructura los datos. Pero también es esencial comprender las diferencias matizadas entre las bases de datos de vectores y de grafos. La forma más sencilla de hacerlo es con una comparación en paralelo:
| Base de datos vectorial | Base de datos de grafos | |
| Representación de datos | Los datos se estructuran como puntos en un vasto espacio multidimensional. Los puntos más cercanos representan contenido similar. Es ideal para capturar similitudes inherentes en los datos en sí, independientemente de las conexiones o relaciones. | Los datos se estructuran como una red de nodos (entidades) interconectados unidos por bordes (relaciones). Se enfoca en representar las conexiones y jerarquías entre puntos de datos, lo que ofrece información valiosa sobre cómo las entidades se relacionan entre sí. |
| Búsqueda y recuperación | Destácate en la búsqueda por similitud, encontrando con eficiencia puntos de datos similares a un vector de búsqueda. Ideal para tareas como la recuperación de imágenes o documentos, donde es crucial entender la similitud del contenido. | Muy útil para navegar relaciones y conexiones. Permite un recorrido eficiente a través de las estructuras de red, ideal para el análisis de redes sociales, sistemas de recomendación y la exploración de grafos de conocimiento. |
| Rendimiento y escalabilidad | Por lo general escala bien con grandes sets de datos gracias a los algoritmos de búsqueda por similitud optimizados. Sin embargo, los cambios de esquema pueden requerir la reincrustación de datos, lo cual afecta el rendimiento. | Sumamente flexible gracias a su naturaleza sin esquema, lo que permite agregar y modificar datos de manera sencilla. Sin embargo, las búsquedas complejas o las redes grandes pueden afectar el rendimiento, lo cual requiere una optimización cuidadosa. |
Casos de uso
Para comprender mejor las diferencias entre las bases de datos vectoriales y las de grafos, comparemos cómo puede usarse cada una dentro del mismo sector. Esto no solo muestra los contrastes, sino también cómo podrían usarse potencialmente juntas para lograr resultados excelentes:
Detección de fraudes
Bases de datos vectoriales: Identifica transacciones fraudulentas analizando los patrones de las transacciones y la información de los usuarios. Detecta anomalías en los hábitos de gasto, los lugares de compra o las huellas digitales de los dispositivos basándote en perfiles de similitud aprendidos.
- Bases de datos de grafos: Descubre redes sospechosas de personas o transacciones conectadas. Identifica la actividad fraudulenta analizando las relaciones entre entidades involucradas en posibles intentos de fraude.
Investigación científica
Bases de datos vectoriales: Analiza estructuras de datos complejas como secuencias de proteínas, expresiones génicas o compuestos químicos. Compara diversos conjuntos de datos e identifica similitudes basadas en características multidimensionales, lo que lleva a nuevos descubrimientos científicos.
- Bases de datos de grafos: Modela rutas biológicas o interacciones moleculares. Explora relaciones intrincadas entre entidades y visualiza sistemas complejos, lo que lleva a una comprensión más profunda de los procesos biológicos.
Comercio electrónico
Bases de datos vectoriales: Analizan atributos de productos como imágenes, descripciones de texto y especificaciones técnicas. Recomiendan productos similares en función de la similitud de contenido, lo que genera sugerencias más relevantes y atractivas.
- Bases de datos de grafos: Capturan las interacciones entre usuarios y productos, como compras, historial de navegación y listas de deseos. Recomiendan productos según las similitudes de los usuarios con otros de gustos similares, creando una experiencia de compra más personalizada.
Medios de comunicación y entretenimiento
Bases de datos vectoriales: Analiza características de contenido como géneros musicales, temas de artículos o temas de películas. Recomienda canciones, películas o artículos similares basados en la similitud de contenido inherente, que se basen en las preferencias individuales.
- Bases de datos de grafos: Explora las relaciones con el contenido del usuario, como el historial de visualización, las listas de lectura o las acciones compartidas en las redes sociales. Recomienda contenido basado en conexiones entre usuarios con intereses similares, fomentando el compromiso y el descubrimiento.
Elegir entre bases de datos vectoriales y de grafos
Incluso con la información que hemos repasado en este artículo, seleccionar la base de datos correcta puede seguir siendo una tarea abrumadora. Para simplificar este proceso, aquí tienes un marco de trabajo que puedes seguir para ayudarte a tomar la mejor decisión y alcanzar tu objetivo.
Paso 1. Entiende tus datos
La primera parte de este proceso es observar la complejidad de los datos. ¿Son principalmente estructurados o no estructurados? ¿Involucra relaciones intrincadas o entidades independientes?
Debes tener en cuenta el volumen de tus datos y qué tan rápido esperas que crezca. Luego, necesitas decidir qué características o atributos específicos definen tus puntos de datos; y si estos son numéricos o categóricos.
Paso 2. Identifica tus principales casos de uso
En términos simples, ¿qué información esperas obtener a partir del análisis de los datos? ¿Estás intentando encontrar puntos de datos similares basados en el contenido o de explorar conexiones intrincadas entre las entidades? ¿Qué tipo de búsquedas realizarás con frecuencia?
Paso 3. Necesidades de rendimiento y escalabilidad
El tercer paso es pensar en qué tan importantes son la velocidad y la escalabilidad para tu objetivo. ¿Qué tan esenciales son las respuestas en tiempo real en tu aplicación? ¿Qué tan grandes son tus sets de datos y qué tan complejas son las búsquedas que anticipas? También debes tener en cuenta las restricciones de presupuesto y las limitaciones de recursos.
Paso 4. Evalúa las ventajas específicas de cada tecnología
Cada uno de estos tipos de bases de datos tiene sus propias fortalezas y debilidades. Las bases de datos de vectores son ideales para la búsqueda de similitudes, son eficientes con datos de alta dimensionalidad y se ocupan además de grandes sets de datos. Las bases de datos de grafos se destacan en la navegación por relaciones, son poderosas para análisis de redes complejas y tienen un esquema sumamente flexible.
Liberar todo el potencial de tus datos
Navegar por el panorama de big data requiere de herramientas poderosas, y las bases de datos de vectores y grafos se posicionan como jugadores innovadores en este espacio de información. Pero seleccionar el modelo correcto para tus necesidades puede ser abrumador.
Evalúa detenidamente los factores mencionados antes y comprende las distintas fortalezas de cada tecnología. Terminarás con una lista de factores que te brindará información para tomar la decisión, y esto te ayudará a elegir el modelo de base de datos adecuado para liberar todo el potencial de tus datos.
¿Qué deberías hacer a continuación?
Cuando estés listo, estas son cuatro maneras en las que podemos ayudarte a lograr mejores experiencias de búsqueda para tu empresa:
Comienza una prueba gratuita y ve cómo Elastic puede ayudar a tu empresa.
Haz un recorrido por nuestras soluciones para ver cómo funciona Elasticsearch Platform y cómo nuestras soluciones se ajustarán a tus necesidades.
Conoce cómo las bases de datos vectoriales impulsan la búsqueda de IA.
Comparte este artículo con alguien que sepas que disfrutaría leerlo por correo electrónico, o en LinkedIn, X o Facebook.
Explora más recursos de bases de datos y analíticas de datos:
El momento del lanzamiento de cualquiera de las características o funcionalidades descritas en esta publicación queda a exclusivo criterio de Elastic. Es posible que algunas características o funcionalidades que no estén disponibles en este momento no se lancen a tiempo o no se lancen en absoluto.
En esta publicación del blog, es posible que hayamos usado o nos hayamos referido a herramientas de AI generativa de terceros, que son propiedad de sus respectivos propietarios y están gestionadas por ellos. Elastic no tiene ningún control sobre las herramientas de terceros y no tenemos ninguna responsabilidad por su contenido, operación o uso, ni por ninguna pérdida o daño que pueda surgir de tu uso de dichas herramientas. Ten cuidado al usar herramientas de AI con información personal, sensible o confidencial. Cualquier dato que envíes puede usarse para el entrenamiento de la AI u otros fines. No se garantiza que la información que proporciones se mantenga segura o confidencial. Debes familiarizarte con las prácticas de privacidad y los términos de uso de cualquier herramienta de IA generativa antes de usarla.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine y las marcas asociadas son marcas comerciales, logotipos o marcas comerciales registradas de Elasticsearch N.V. en Estados Unidos y otros países. Todos los demás nombres de empresas y productos son marcas comerciales, logotipos o marcas comerciales registradas de sus respectivos dueños.
Comparte
- Share on Twitter
Comparte en Twitter
- Share on LinkedIn
Comparte en LinkedIn
- Share on Facebook
Comparte en Facebook
- Share by Email
Comparte por correo electrónico
- Print this page
Imprime