July 16, 2026
A picture is worth 1.5x the words: What we learned benchmarking product search embeddings
We benchmarked two embedding models on 5,000 real products and found that combining image and text beats either alone by up to 50%. Here's the data and the model that won.


July 13, 2026
The disk that never woke up: what actually decided our Qdrant vector search benchmark rematch
On the same hardware, Elasticsearch and Qdrant land in the same range at 56 QPS. The io_uring disk scorer and memory claims turned out to be the two things that mattered least.

July 10, 2026
How BBQ shrinks Jina v5 embeddings by 29x without losing recall in Elasticsearch
A hands-on test comparing BBQ and float32 vector indices in Elasticsearch, measuring memory, disk and recall@10 across five languages.

July 7, 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.

July 2, 2026
A simdvec deep-dive: How Elasticsearch uses neural-net and video-codec CPU instructions for vector search
Four ways Elasticsearch's vector search engine reuses neural-network, video-codec and cryptography CPU instructions for up to 6x speedups; with the math, the failed attempts and the benchmarks.

June 24, 2026
Elasticsearch DiskBBQ delivers 7x faster vector search than Qdrant on network-attached storage
Elasticsearch DiskBBQ achieves up to 7x higher vector search throughput than Qdrant at comparable recall on network-attached storage. Explore the benchmark methodology and full results.

June 18, 2026
Jingra: A Reproducible Framework for Vector Search Benchmarking
Jingra is an open source benchmarking framework that runs the same vector search workload across Elasticsearch, OpenSearch and Qdrant so you can compare engines under identical, reproducible conditions.
June 16, 2026
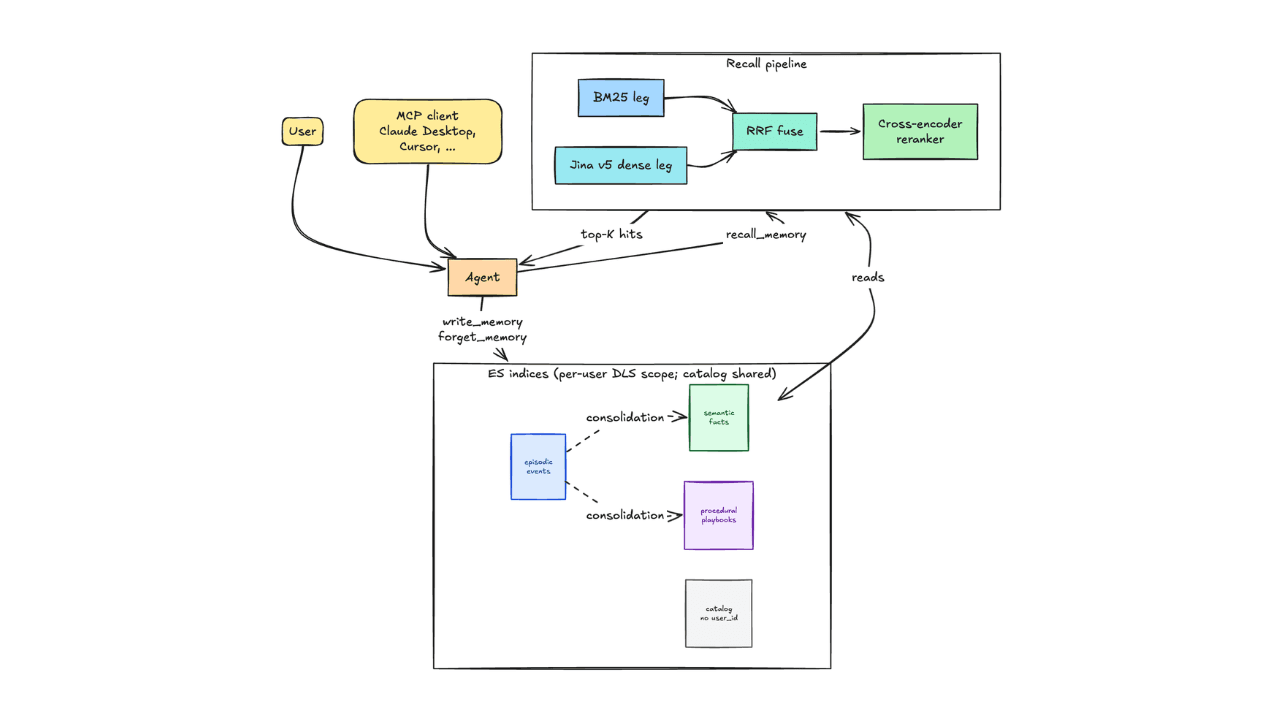
How we built a persistent agent memory layer on Elasticsearch with 0.89 recall and zero tenant leaks
Discover the architecture behind a persistent, multi-tenant agent memory layer on Elasticsearch: three indices, hybrid retrieval with RRF and a reranker, supersession, decay, and per-user DLS isolation. R@10 0.89 across 168 questions. Full open-source implementation included.
June 10, 2026
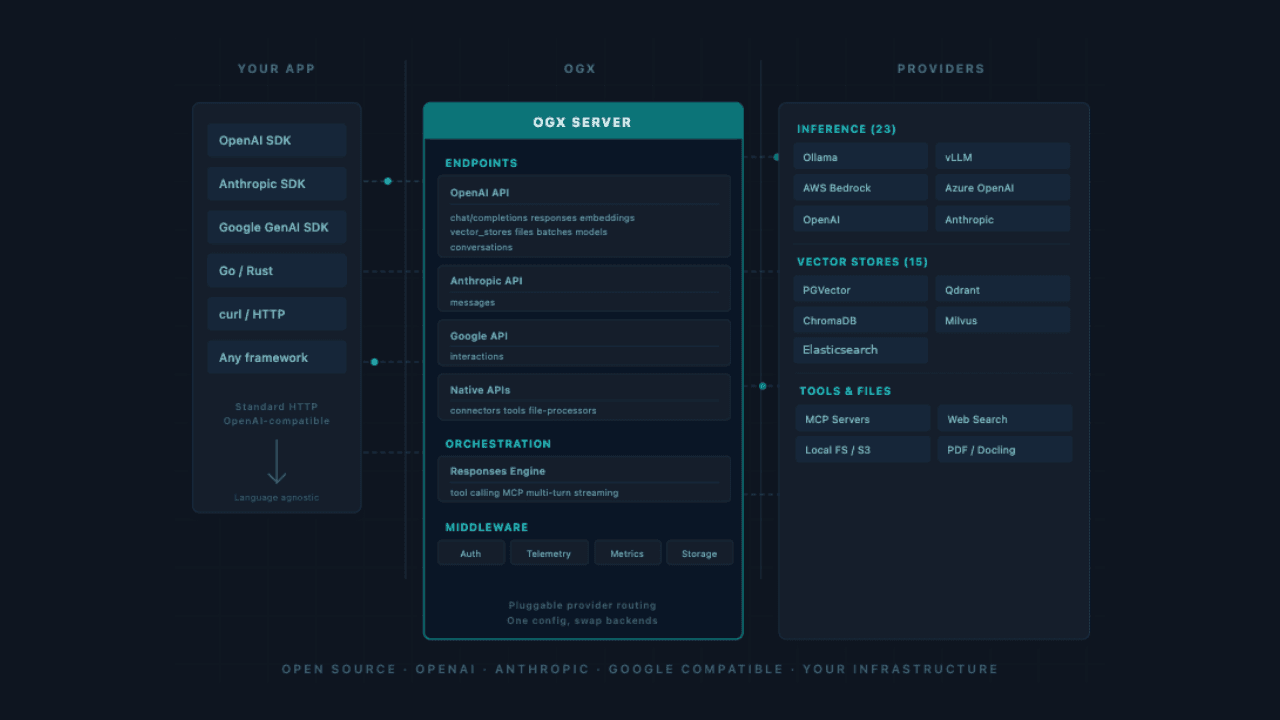
Your AI agent reads the fine print: building a RAG pipeline over EU regulations with Elasticsearch and OGX
Learn how to configure Elasticsearch as an OGX vector store, ingest EU regulation PDFs and build a Python RAG agent that runs hybrid BM25 and vector search with source-level citations.