Try out vector search for yourself using this self-paced hands-on learning for Search AI. You can start a free cloud trial or try Elastic on your local machine now.
This blog talks about token pruning, an exciting enhancement to ELSER performance released with Elasticsearch 8.13.0!
The strategy behind token pruning
We've already talked in great detail about lexical and semantic search in Elasticsearch and text similarity search with vector fields. These articles offer great, in-depth explanations of how vector search works.
We've also talked in the past about reducing retrieval costs by optimizing retrieval with ELSER v2. While Elasticsearch is limited to 512 tokens per inference field ELSER can still produce a large number of unique tokens for multi-term queries. This results in a very large disjunction query, and will return many more documents than an individual keyword search would - in fact, queries with a large number of resulting queries may match most or all of the documents in an index!
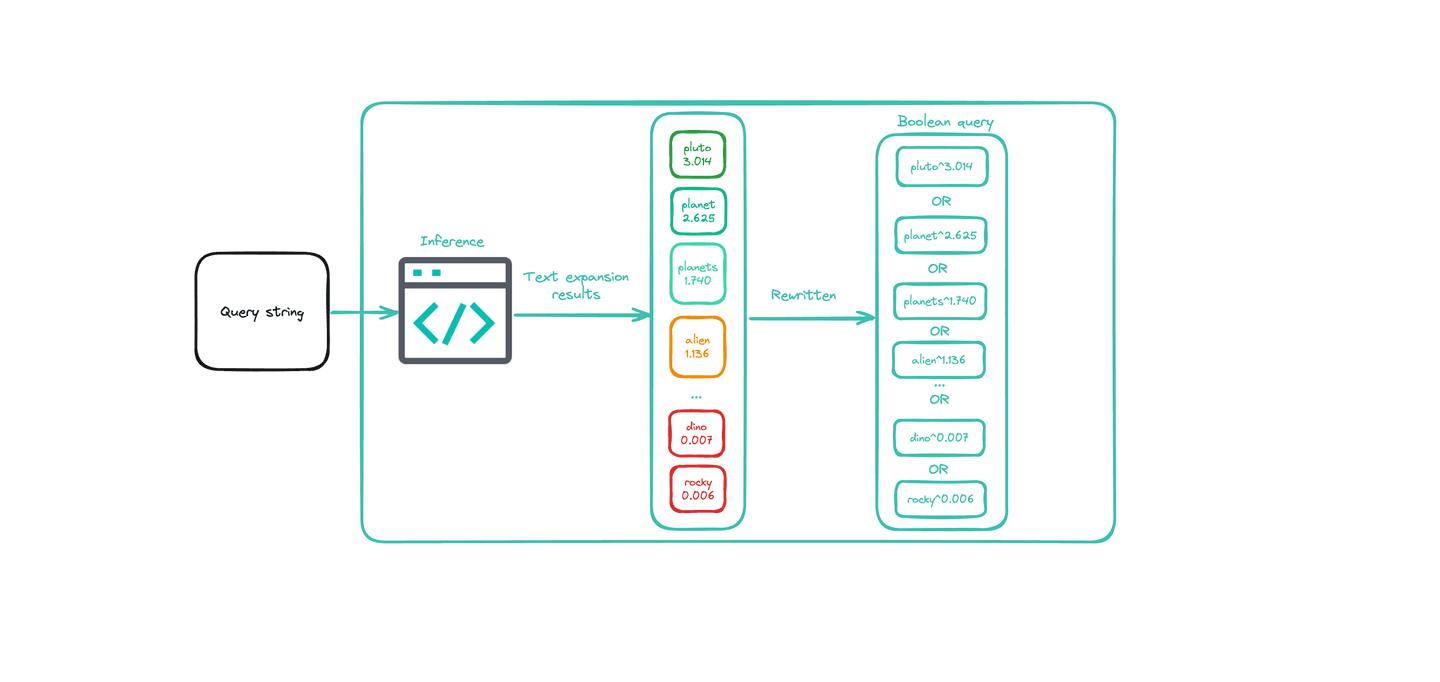
Now, let's take a more detailed look into an example using ELSER v2. Using the infer API we can view the predicted values for the phrase "Is Pluto a planet?"
This returns the following inference results:
These are the inference results that would be sent as input into a text expansion search. When we run a text expansion query, these terms eventually get joined together in one large weighted boolean query, such as:
Speed it up by removing tokens
Given the large number of tokens produced by ELSER text expansion, the quickest way to realize a performance improvement is to reduce the number of tokens that make it into that final boolean query. This reduces the total work that Elasticsearch invests when performing the search. We can do this by identifying non-significant tokens produced by the text expansion and removing them from the final query.

Non-significant tokens can be defined as tokens that meet both of the following criteria:
- The weight/score is so low that the token is likely not very relevant to the original term
- The token appears much more frequently than most tokens, indicating that it is a very common word and may not benefit the overall search results much.
We started with some default rules to identify non-significant tokens, based on internal experimentation using ELSER v2:
- Frequency: More than 5x more frequent than the average token frequency for all tokens in that field
- Score: Less than 40% of the best scoring token
- Missing: If we see documents with a frequency of 0, that means that it never shows up at all and can be safely pruned
If you're using text expansion with a model other than ELSER, you may need to adjust these values in order to return optimal results.
Both the token frequency threshold and weight threshold must show the token is non-significant in order for the token to be pruned. This lets us ensure we keep frequent tokens that are very high scoring or very infrequent tokens that may not have as high of a score.
Performance improvements with token pruning
We benchmarked these changes using the MS Marco Passage Ranking benchmark. Through this benchmarking, we observed that enabling token pruning with the default values described above resulted in a 3-4x improvement in 99th pctile latency and above!
Relevance impact of token pruning
Once we measured a real performance improvement, we wanted to validate that relevance was still reasonable. We used a small dataset against the MS Marco passage ranking dataset. We did observe an impact on relevance when pruning the tokens; however, when we added the pruned tokens back in a rescore block the relevance was close to the original non-pruned results with only a marginal increase in latency. The rescore, adding in the tokens that were previously pruned, queries the pruned tokens only against the documents that were returned from the previous query. Then it updates the score including the dimensions that were previously left behind.
Using a sample of 44 queries with judgments against the MS Marco Passage Ranking dataset:
| Top K | Rescore Window Size | Avg rescored recall vs control | Control NDCG@K | Pruned NDCG@K | Rescored NDCG@K |
|---|---|---|---|---|---|
| 10 | 10 | 0.956 | 0.653 | 0.657 | 0.657 |
| 10 | 100 | 1 | 0.653 | 0.657 | 0.653 |
| 10 | 1000 | 1 | 0.653 | 0.657 | 0.653 |
| 100 | 100 | 0.953 | 0.51 | 0.372 | 0.514 |
| 100 | 1000 | 1 | 0.51 | 0.372 | 0.51 |
Now, this is only one dataset - but it's encouraging to see this even at smaller scale!
How to use: Pruning configuration
Pruning configuration will launch in our next release as an experimental feature. It's an optional, opt-in feature so if you perform text expansion queries without specifying pruning, there will be no change to how text expansion queries are formulated - and no change in performance.
We have some examples of how to use the new pruning configuration in our text expansion query documentation.
Here's an example text expansion query with both the pruning configuration and rescore:
Note that the rescore query sets only_score_pruned_tokens to false, so it only adds those tokens that were originally pruned back into the rescore algorithm.
This feature was released as a technical preview feature in 8.13.0. You can try it out in Cloud today! Be sure to head over to our discuss forums and let us know what you think.
Related Content

July 16, 2026
A picture is worth 1.5x the words: What we learned benchmarking product search embeddings
We benchmarked two embedding models on 5,000 real products and found that combining image and text beats either alone by up to 50%. Here's the data and the model that won.

July 13, 2026
The disk that never woke up: what actually decided our Qdrant vector search benchmark rematch
On the same hardware, Elasticsearch and Qdrant land in the same range at 56 QPS. The io_uring disk scorer and memory claims turned out to be the two things that mattered least.

July 21, 2026
4 NVIDIA AI tasks, 1 Elasticsearch API: Embeddings, chat, completion, and rerank
Set up NVIDIA hosted models in Elasticsearch with one API key and a model ID. No custom integration code needed.

July 10, 2026
How BBQ shrinks Jina v5 embeddings by 29x without losing recall in Elasticsearch
A hands-on test comparing BBQ and float32 vector indices in Elasticsearch, measuring memory, disk and recall@10 across five languages.

July 7, 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.