Try out vector search for yourself using this self-paced hands-on learning for Search AI. You can start a free cloud trial or try Elastic on your local machine now.
In this blog post we'll take a deep dive into our efforts on making the onboarding experience to kNN search just a bit easier!
Vector search overview
Vector search has been available for quite some time on Elasticsearch through the use of a new dedicated knn search type, while we also introduced kNN as a query in the 8.12.0 release (more on this amazing blog post we recently published!).
While the execution flow and the applications of each approach have some differences, the syntax to do basic kNN retrieval is pretty much similar. So, a typical knn search request looks like this:
The first couple of params are pretty much intuitive: we specify where the data is stored (field) and what we want to compare it against (query_vector).
The k and num_candidates params on the other hand are a bit more obscure and require some understanding in order to fine-tune them. They are specific to the algorithm & data structure that we use, i.e. HNSW, and exist mainly to control the amount of graph exploration we want to do.
Elasticsearch docs are a great resource for all things around search, so taking a look at the knn section we have:
k: Number of nearest neighbors to return as top hits. This value must be less thannum_candidates.
num_candidates-> The number of nearest neighbor candidates to consider per shard. Needs to be greater thank, orsizeifkis omitted, and cannot exceed 10,000. Elasticsearch collectsnum_candidatesresults from each shard, then merges them to find the topkresults. Increasingnum_candidatestends to improve the accuracy of the finalkresults.
However, when you're first met with something like this, it really isn't that obvious what these values should be, and properly configuring them could turn out to be a challenge. The larger these values are, the more vectors we'll get to explore, but this will come with a performance cost. Once again we're met with the ever present tradeoff of accuracy vs performance.
To make kNN search just a bit easier and more intuitive to use, we decided to make these parameters optional, so that you'd only need to provide where and what you want to search, and you could tune them if you only really need to. While seemingly a rather small change, it makes things much more clear! So, the above query could now simply be rewritten as:
Simplifying kNN search by making
So we want to make k and num_candidates optional. That's great! How should we set the default values though?

There are two options at this point. Pick something that looks like a good option, ship it, and hope for the best, or do the hard work and make extensive evaluations to let data drive our decisions. Here at Elastic, we love such challenges, and want to make sure that any decision taken is justified and for good reason!
Just above, we stated that k for kNN search is the number of results we get back from each shard, so one obvious default here would be to just use size. So, each shard would return size results, and we would merge & sort them to find the global top size results. This also works really nice with the kNN query where we don't have a k param at all, but instead we operate based on the request's size (remember that knn query behaves just like any other query such as term, prefix, etc). So, size seems like a sensible default that would cover most of the use cases (or at least be good enough during the onboarding experience!).
num_candidates on the other hand is something that is much more different. This parameter is specific to the HNSW algorithm and controls the size of the nearest neighbor queue we'll consider (for the curious: this is equivalent to the ef parameter in the original paper )
There are multiple approaches we could take here:
- we could account for the size of each graph and come up with a function that would calculate the appropriate
num_candidatesforNindexed vectors - we could take a look at the underlying data distribution and try to guesstimate the needed exploration (maybe by also considering HNSW's entry points)
- we could assume that
num_candidatesis not directly related to the indexed data, but rather to the search request, and ensure that we'll do the needed exploration to provide good enough results.
As a start and to keep things simple, we looked into setting a num_candidates value relative to k (or size). So, the more results you actually want to retrieve, the higher the exploration we'll perform on each graph to make sure that we escape from local minima. The candidates that we'll focus mostly on are the following:
num_candidates = knum_candidates = 1.5 * knum_candidates = 2 * knum_candidates = 3 * knum_candidates = 4 * knum_candidates = Math.max(100, k)
It's worth noting here that more alternatives were initially examined but higher values provided little benefit, so for the rest of the blog we'll focus mostly on just the above.
Having a set of num_candidates candidates (no pun intended!) we now focus on the k parameter. We opted to account for both standard searches as well as very large k values (to see the actual impact of the exploration we do). So, the values we decided to focus more upon were:
k = 10(to account for the requests where nosizeis specified)k = 20k = 50k = 100k = 500k = 1000
Benchmarking & experimentation for simplifying kNN search
Data
As there is no one-size-fits-all solution, we wanted to test with different datasets that had varying attributes. So, different number of total vectors, dimensions, as well as generated from different models, so different data distributions.
At the same time we have rally available, which is an awesome tool for benchmarking Elasticsearch (https://github.com/elastic/rally), and supports running a bunch of queries & extracting metrics for a number of vector datasets. Here at Elastic, we make extensive use of rally and rely on it for all our nightly benchmarks, which you can check here!
Running a benchmark on rally is as simple as running the following:
To this end, we slightly modified the tracks (i.e. rally's test scenarios) to include additional metric configurations, added some new ones, and ended up with the following set of tracks:
dense-vector(2M docs, 96dims): https://github.com/elastic/rally-tracks/tree/master/dense_vectorso-vector(2M docs, 768 dims): https://github.com/elastic/rally-tracks/tree/master/so_vectorcohere-vector(3M docs, 768 dims): https://github.com/elastic/rally-tracks/tree/master/cohere_vectoropenai-vector(2.5M docs, 1536dims): https://github.com/elastic/rally-tracks/tree/master/openai_vectorGlove 200d(1.2M, 200dims) new track created based on https://github.com/erikbern/ann-benchmarks repo
It's also worth noting that for the first couple of datasets, we would also like to account for both having one vs multiple segments so we included 2 variants of each,
- one where we execute
force_mergeand have a single segment, and - one where we rely to the underlying
MergeSchedulerto do its magic and end up with how many segments it sees fit.
Metrics
For each of the above tracks, we calculated the standard recall and precision metrics, latency, as well as the actual exploration that we did on the graph by reporting the nodes that we visited. The first couple of metrics are evaluated against the true nearest neighbors, as in our scenario, this is the gold standard dataset(remember we're evaluating how good the approximate search is, and not the quality of the vectors themselves). The nodes_visited attribute has been recently added to knn's profile output (https://github.com/elastic/elasticsearch/pull/102032) so, with some minor changes to the track definitions in order to extract all needed metrics, we should be good to go!
Benchmarks
Now that we know what we want to test, which datasets to use, and how to evaluate the results, it's time to actually run the benchmarks!
To have a standardized environment, for each test we used a clean n2-standard-8 (8 vCPU, 4 core, 32 GB memory) cloud node. The Elasticsearch configuration, along with necessary mappings and all else needed, is configured and deployed through rally, so it's consistent for all similar tests.
Each of the dataset above was executed multiple times, gathering all metrics available for all candidate sets defined, making sure that no results were one-offs.
Results
The recall - latency graphs for each of the specified datasets & param combinations can be found below (higher and to the left is better, latency is measured in ms):
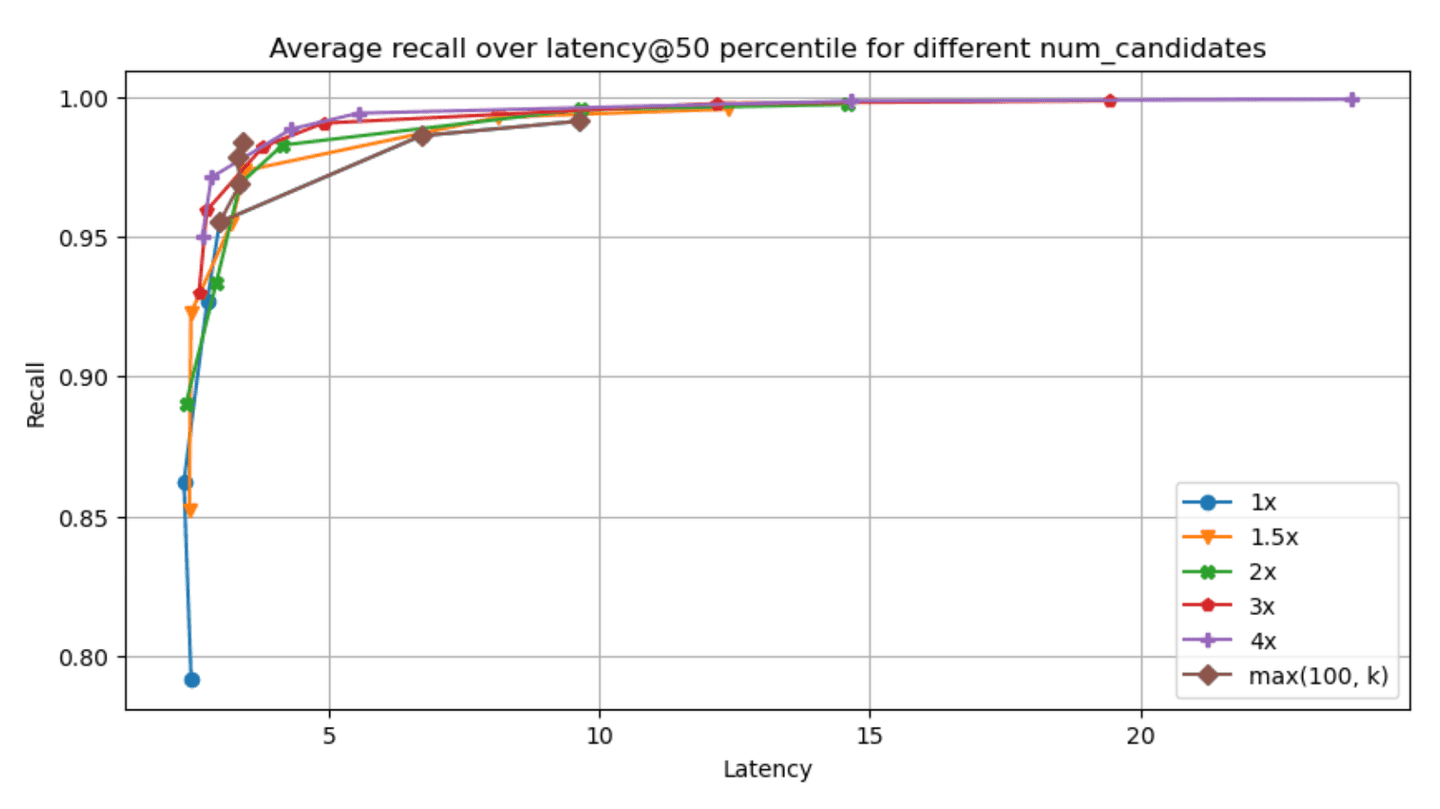
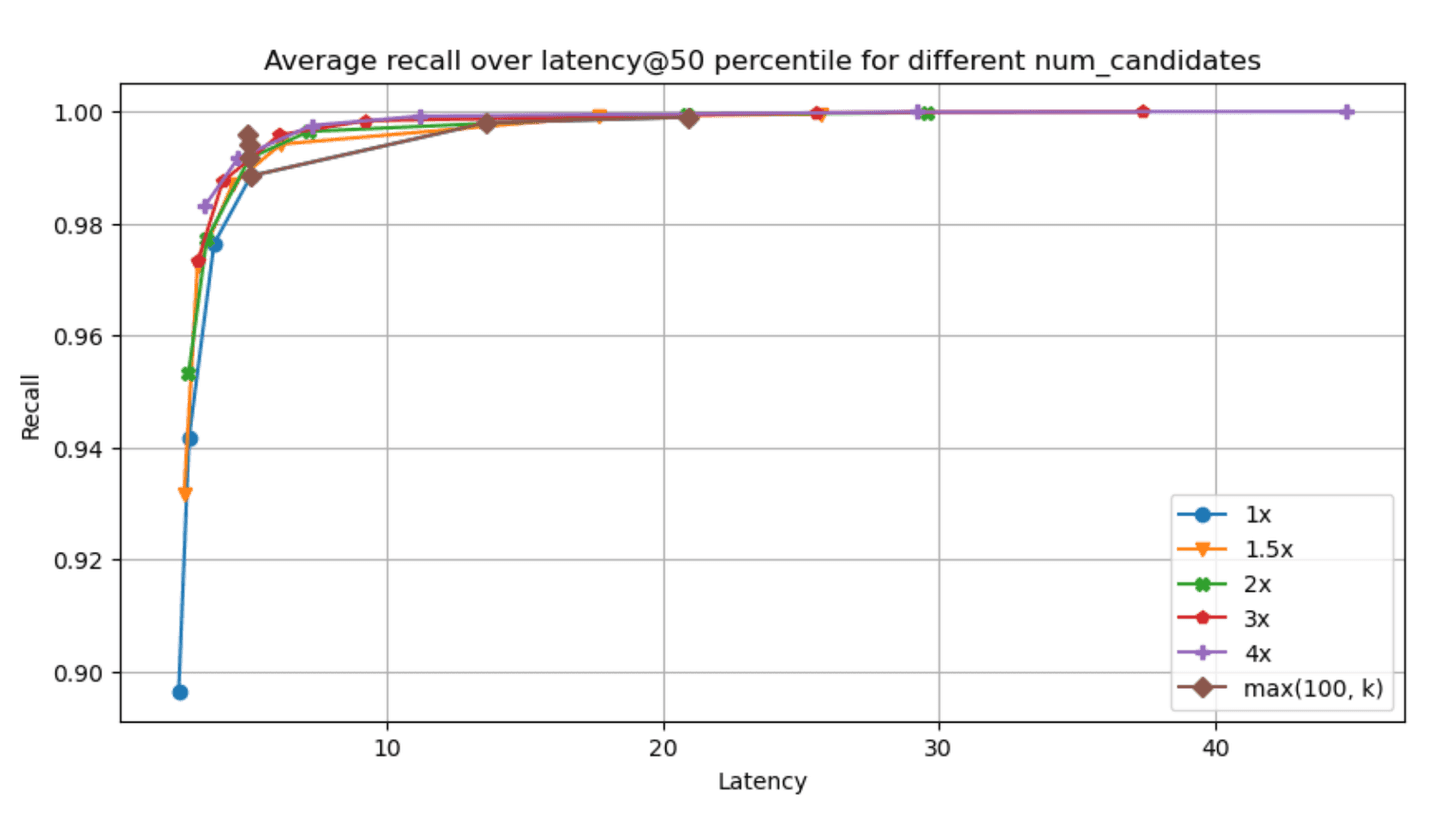
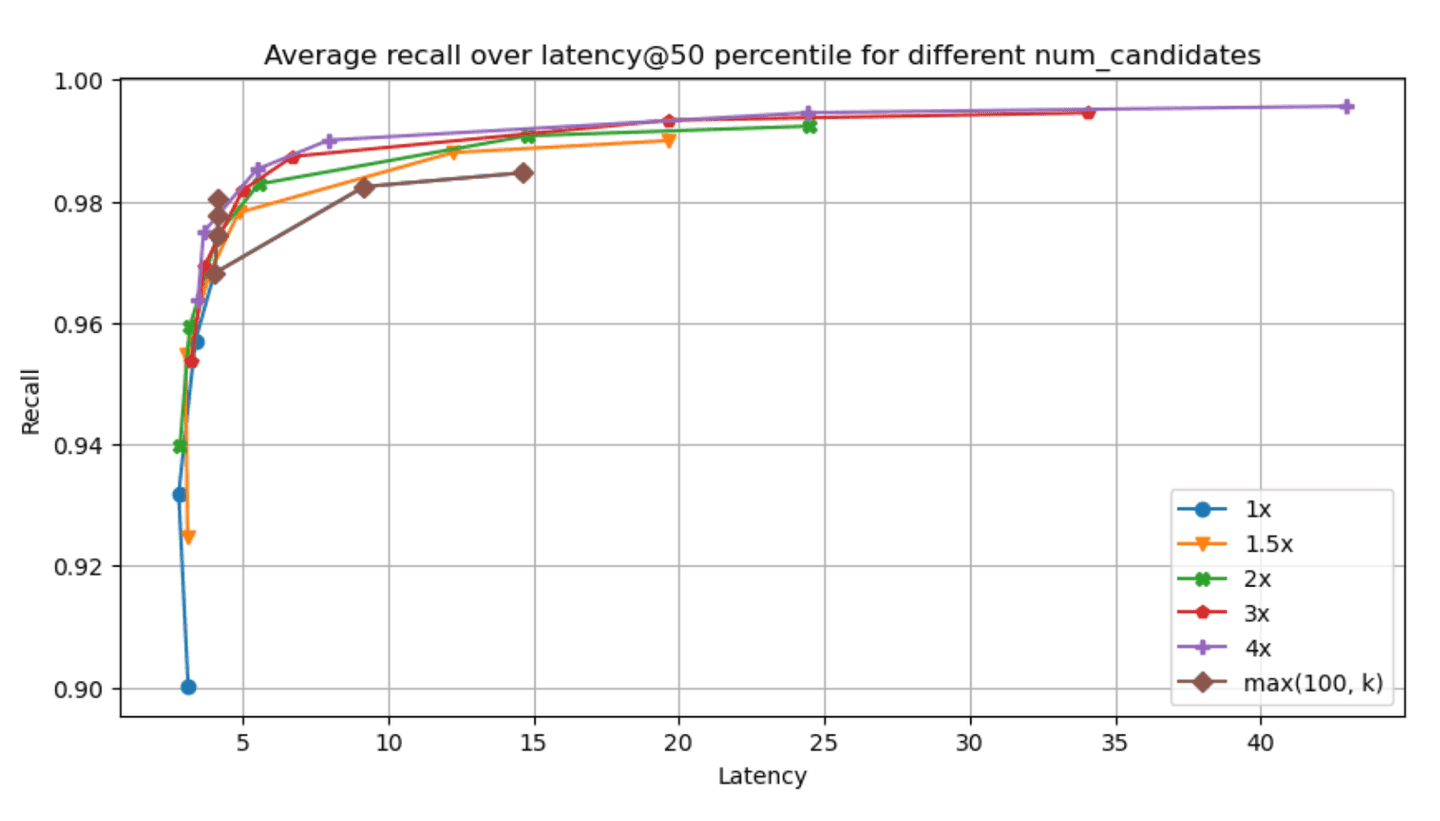
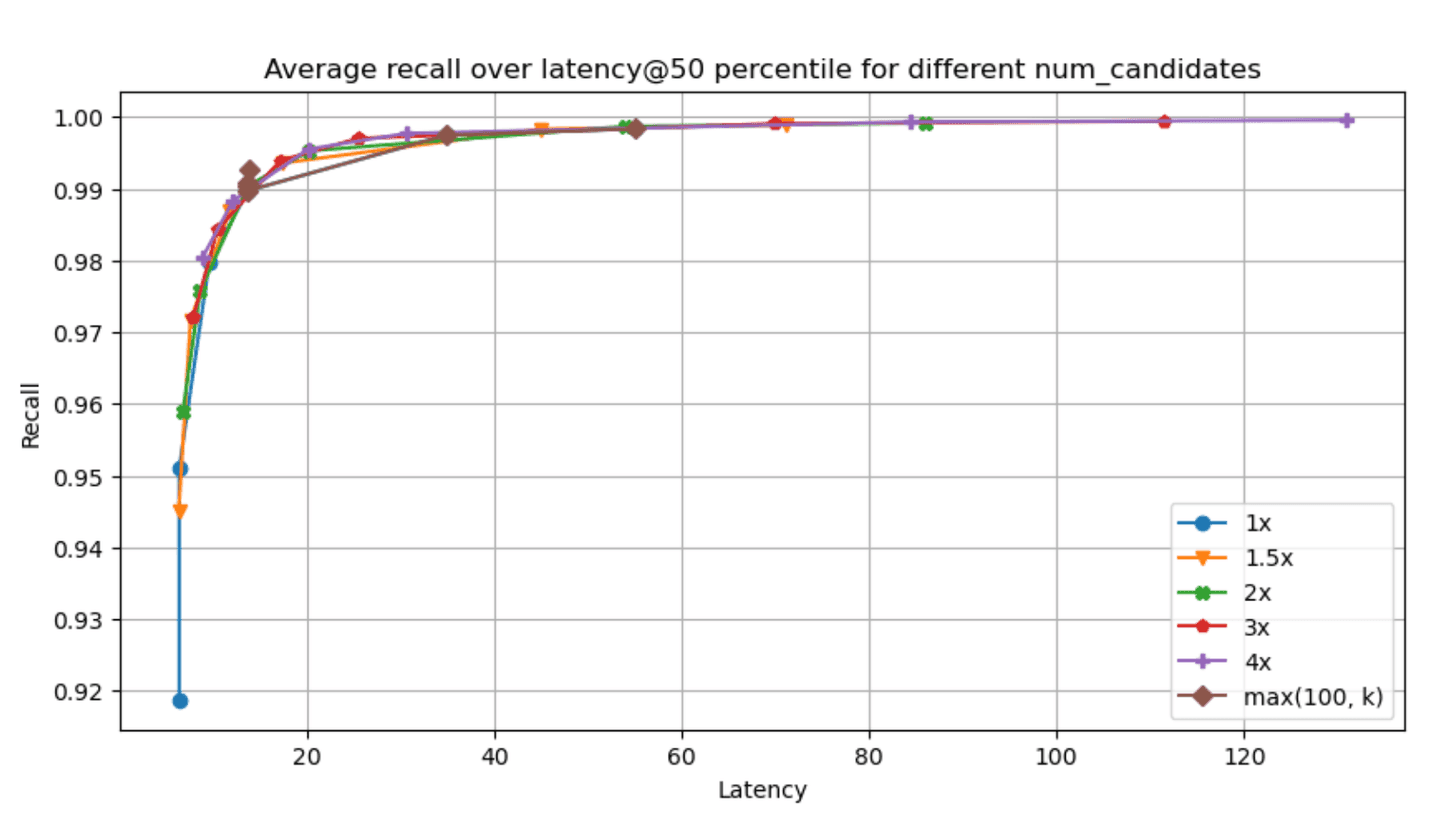
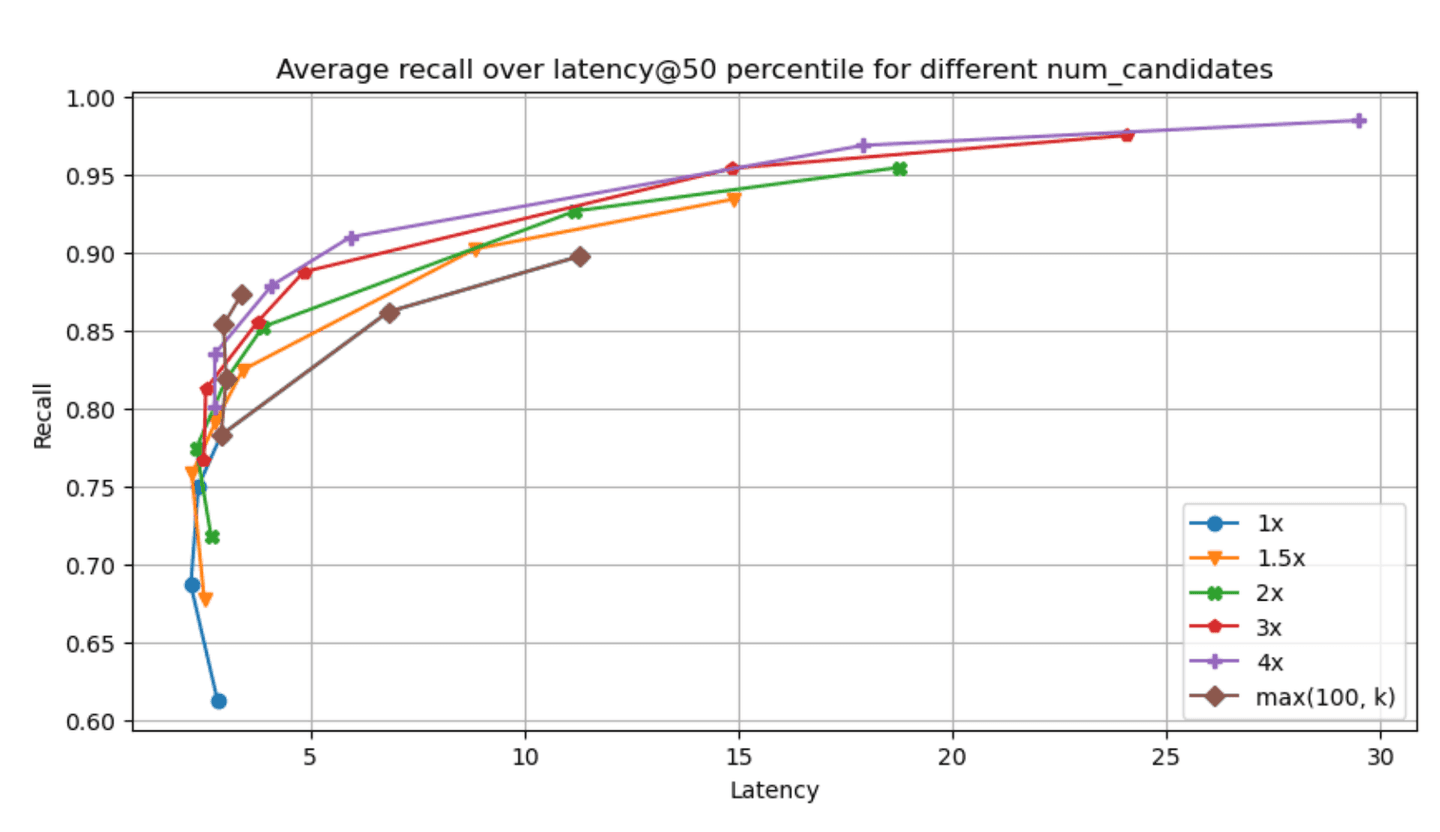
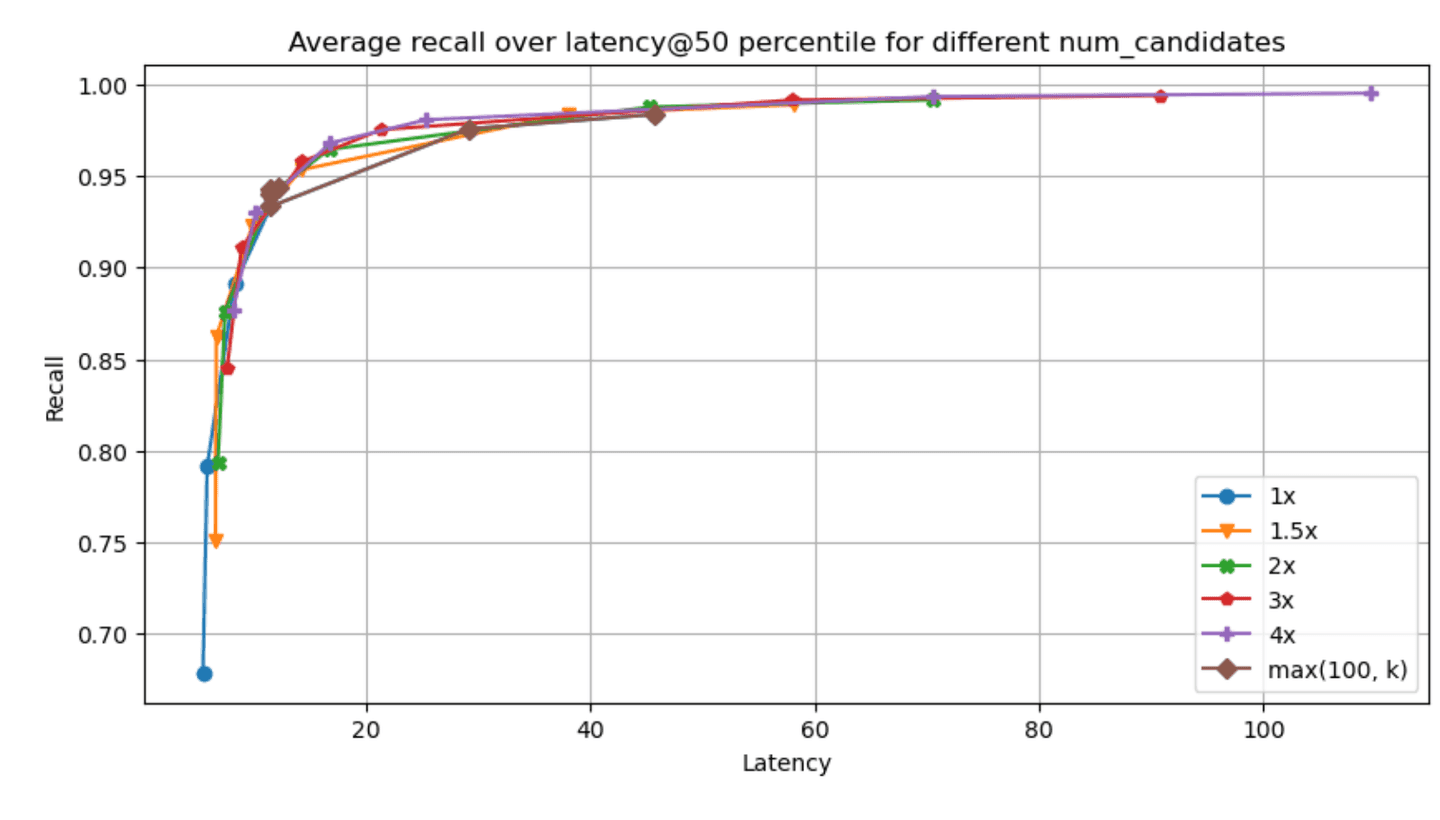
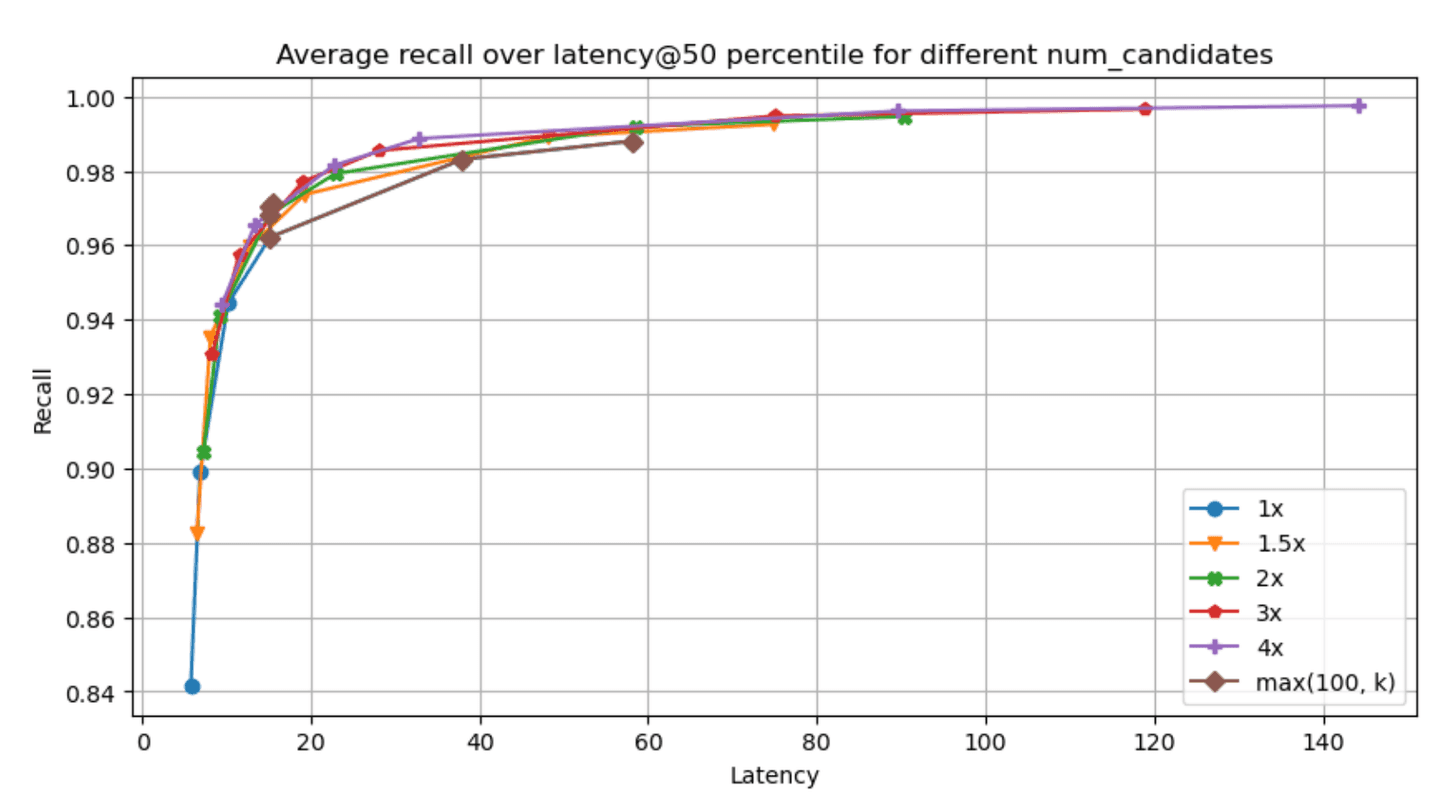
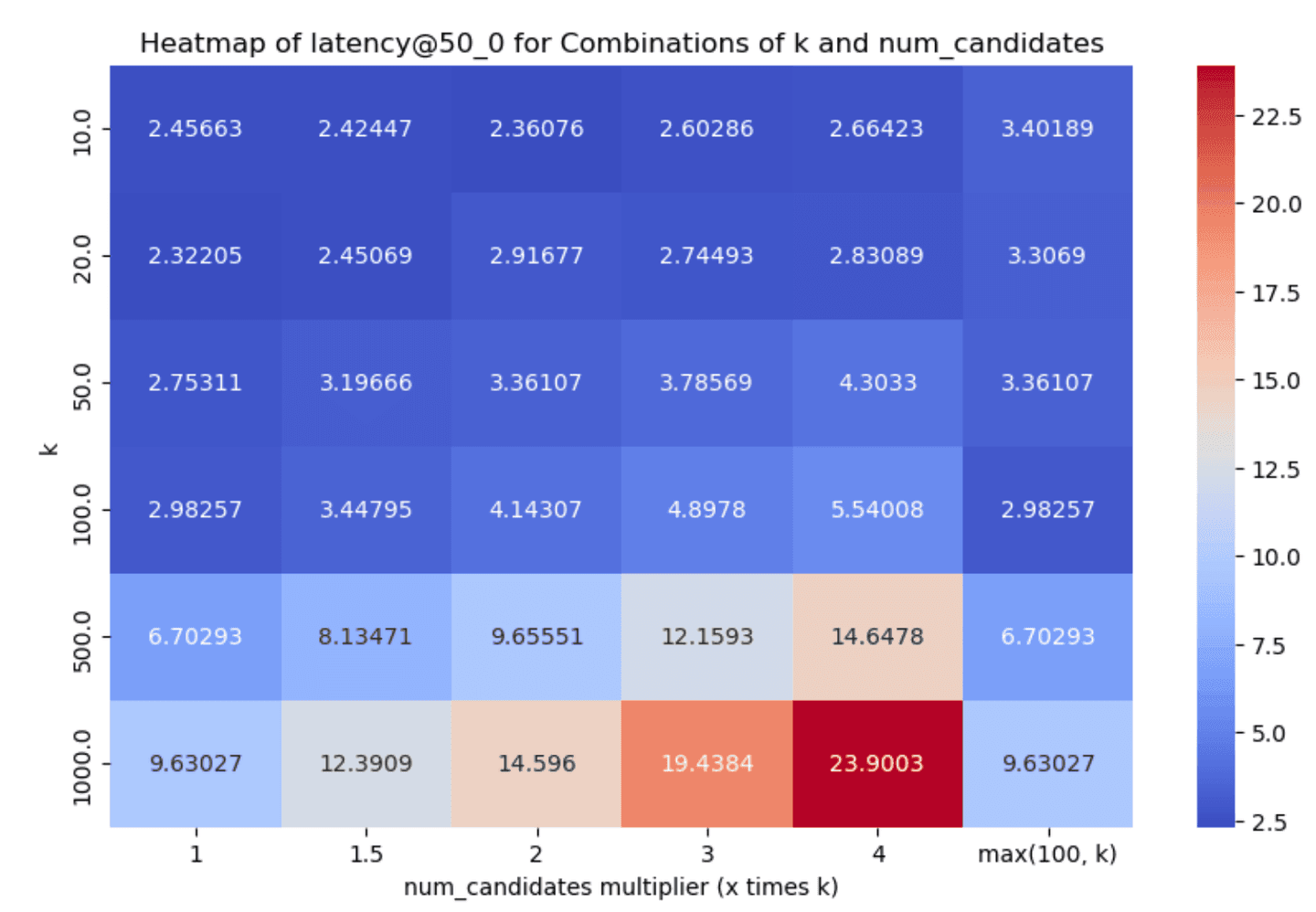
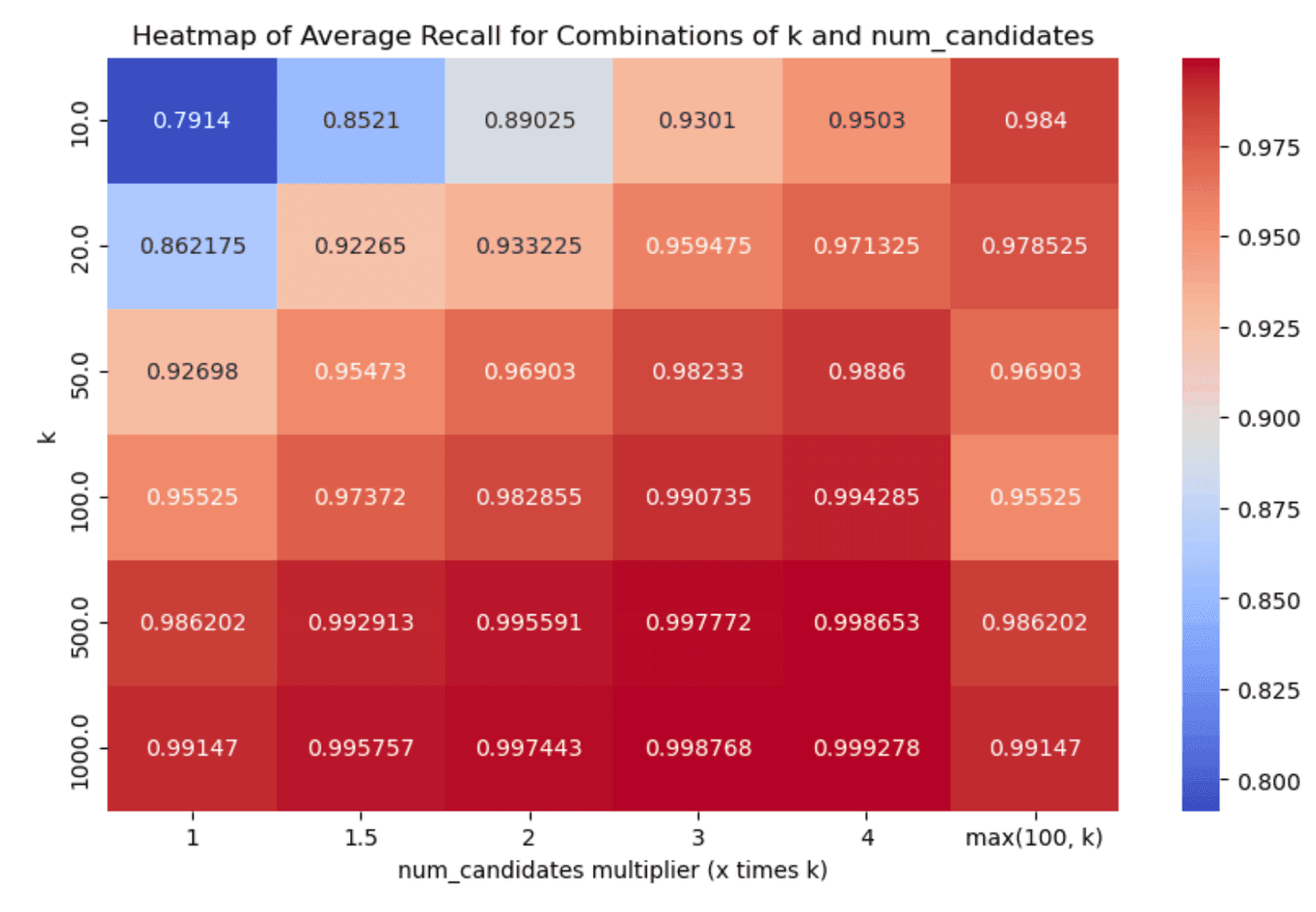
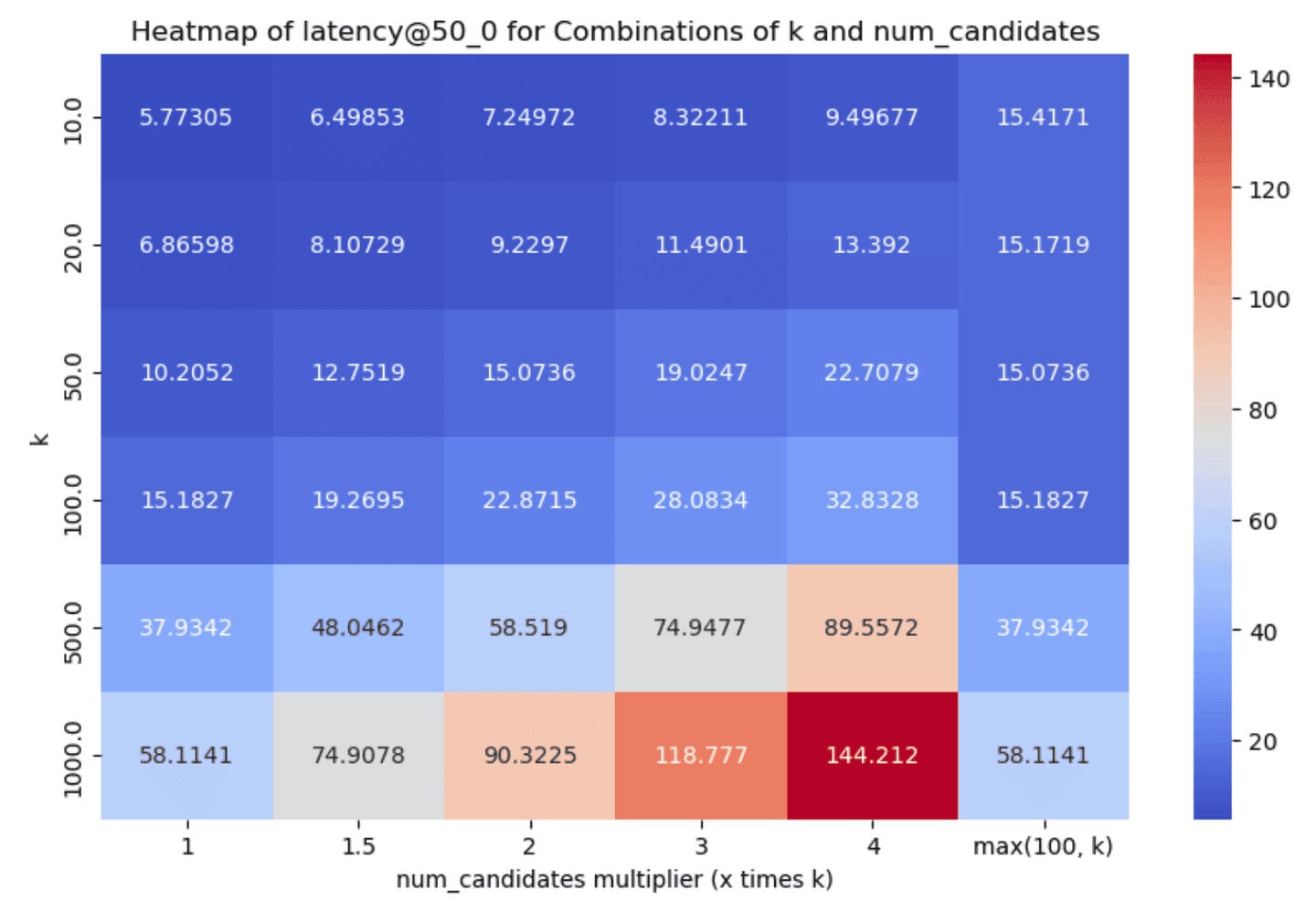
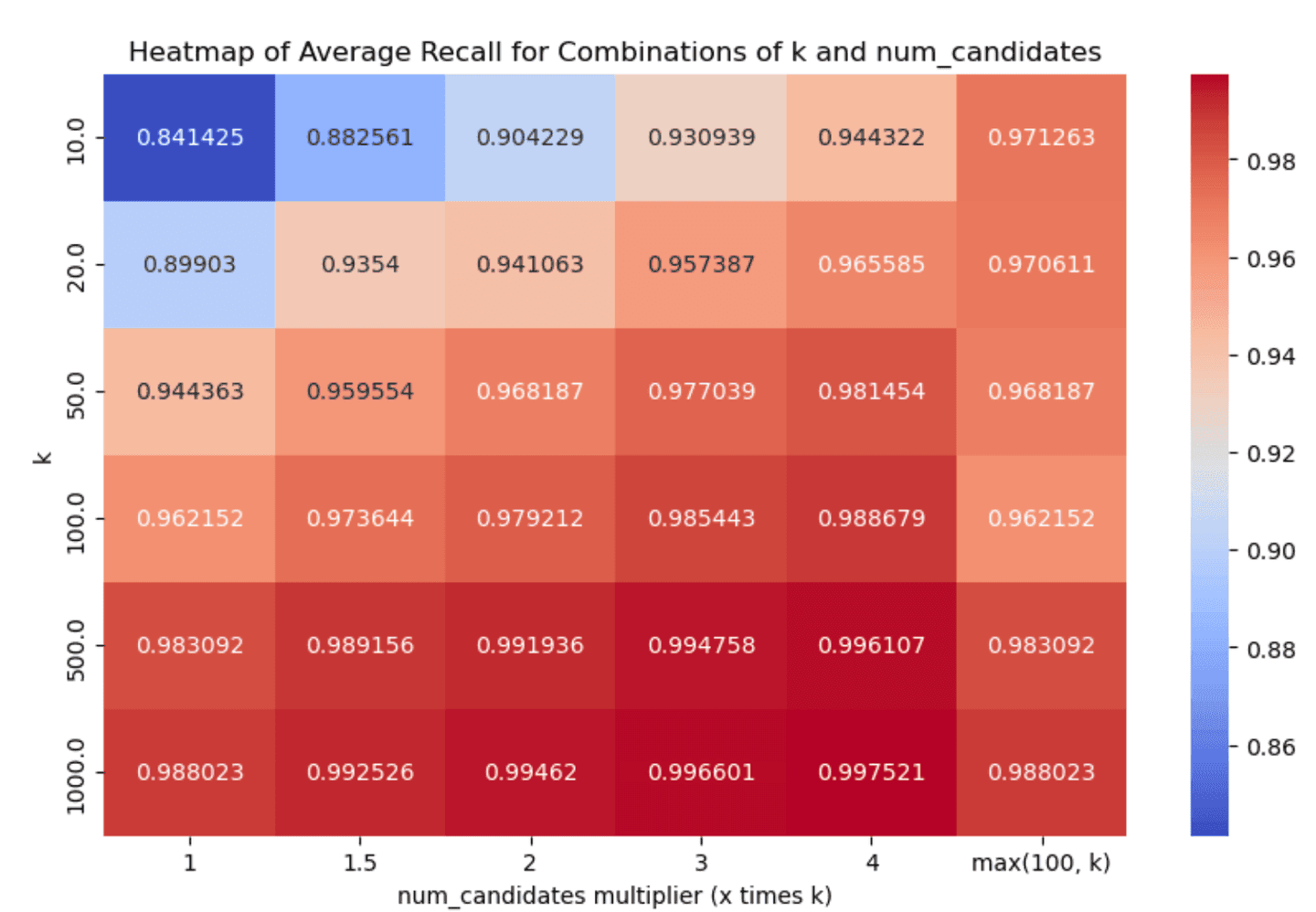
Narrowing down to the dense_vector and openai_vector tracks for the absolute values of latency@50th percentile and recall we have:
Similarly, the 99th percentile of the HNSW graph nodes visited for each scenario can be found below (smaller is better):
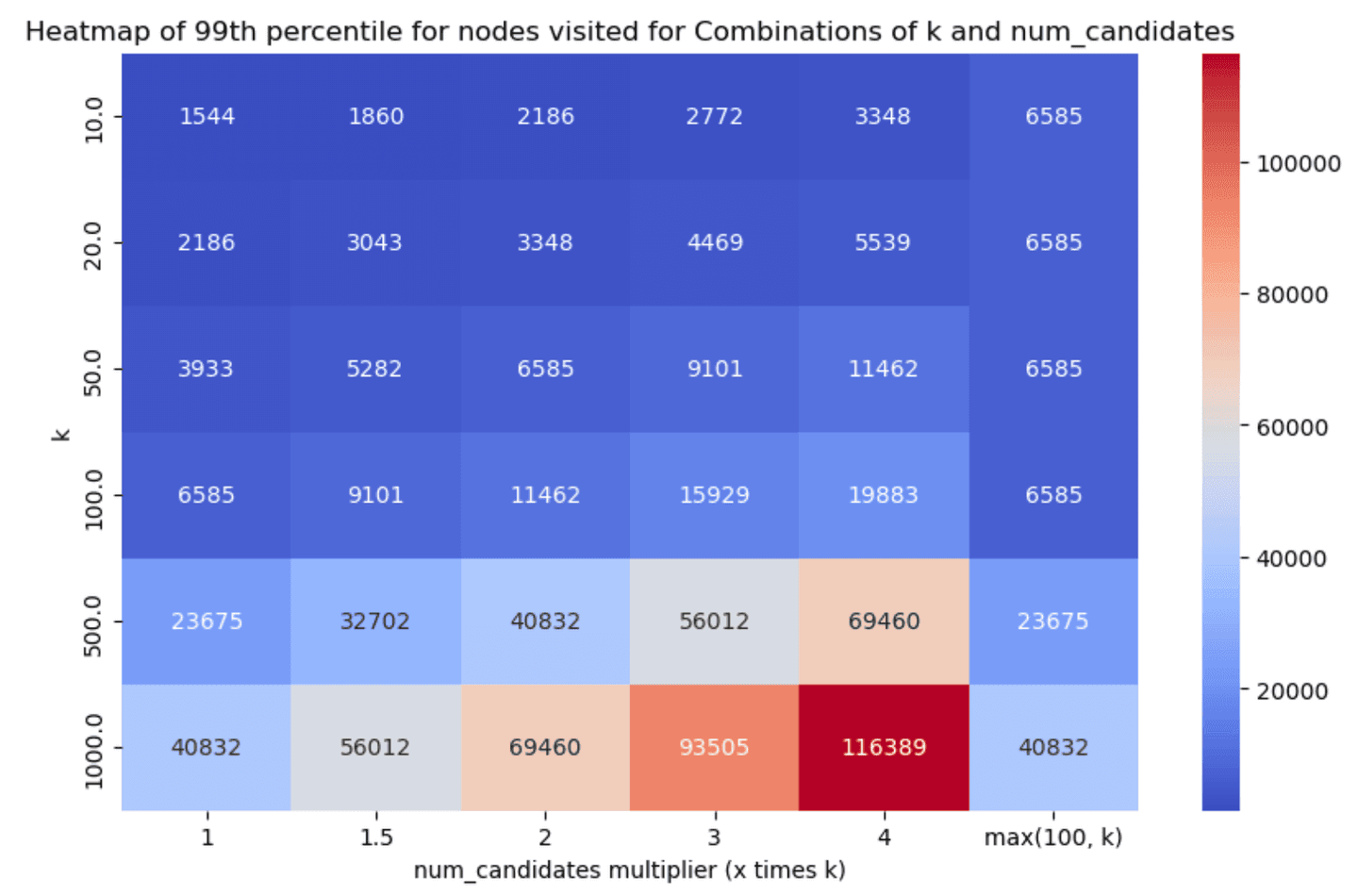

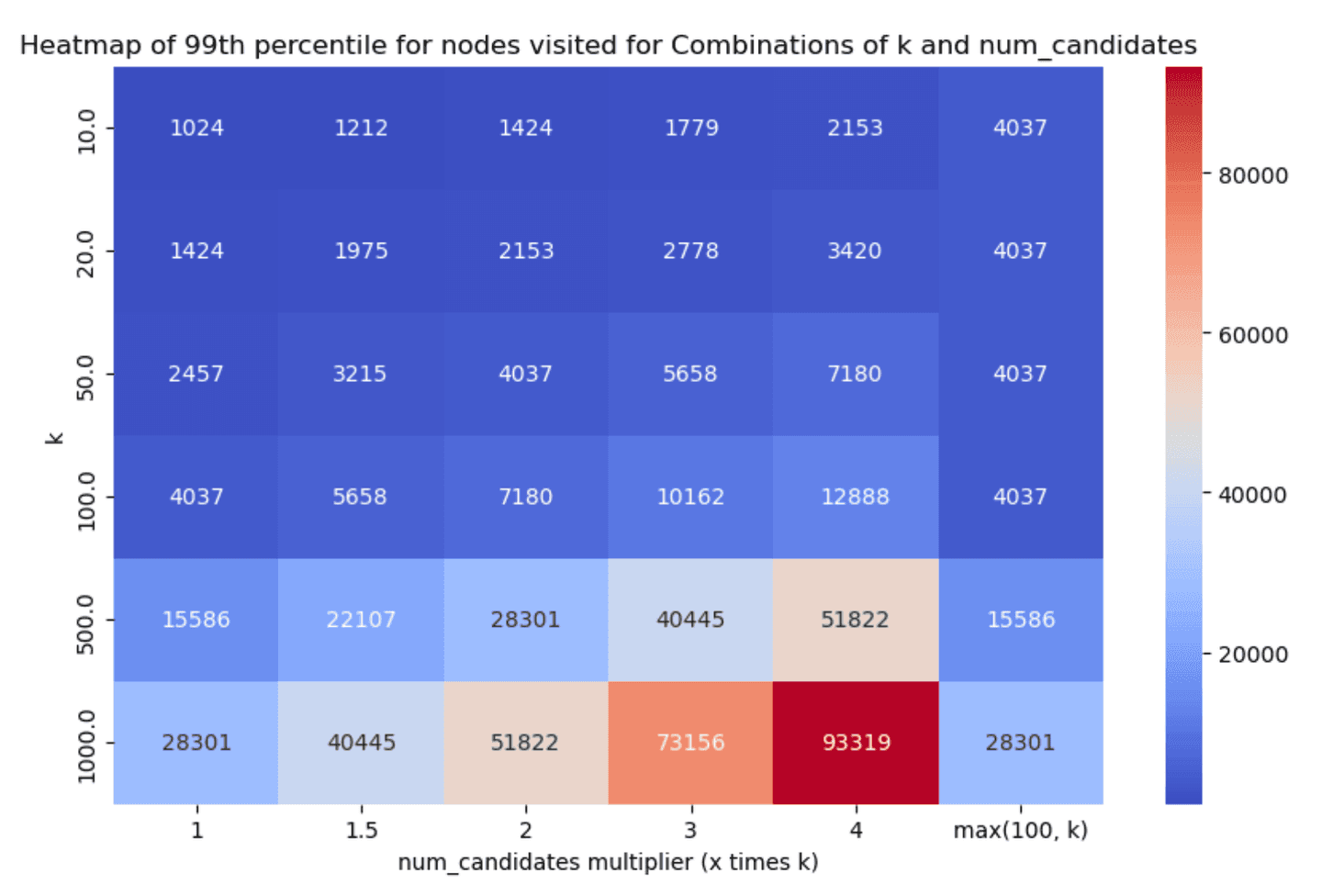
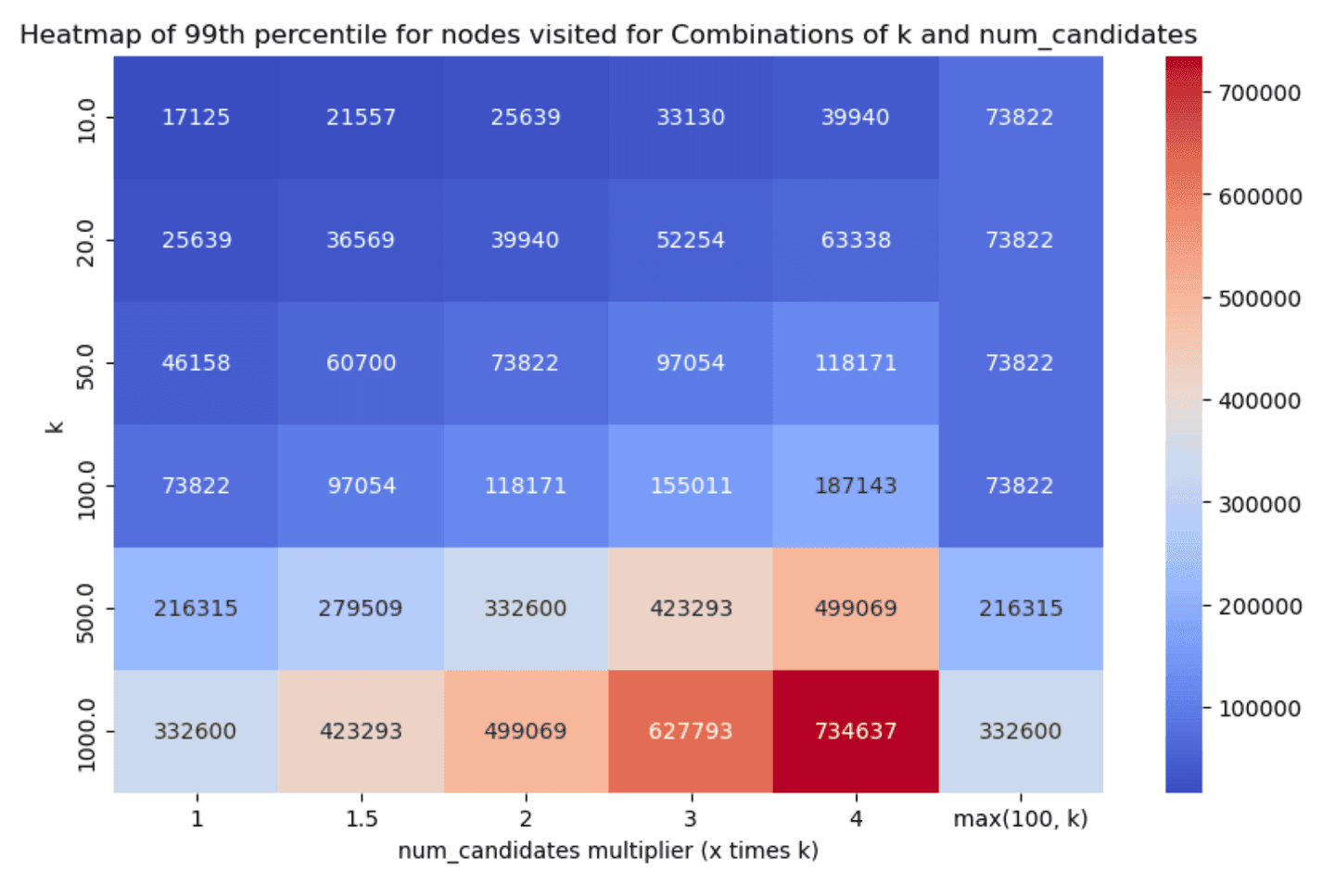
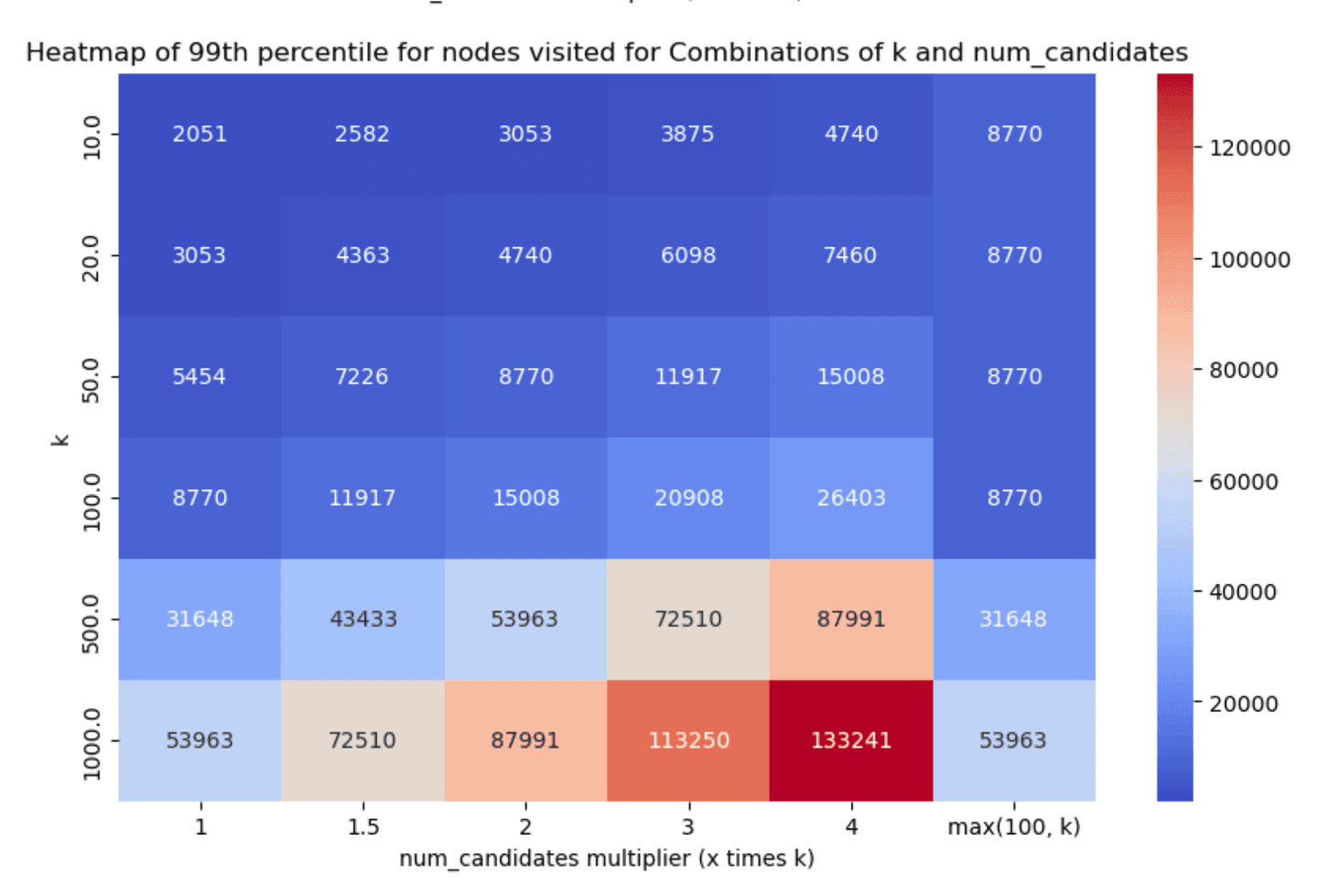
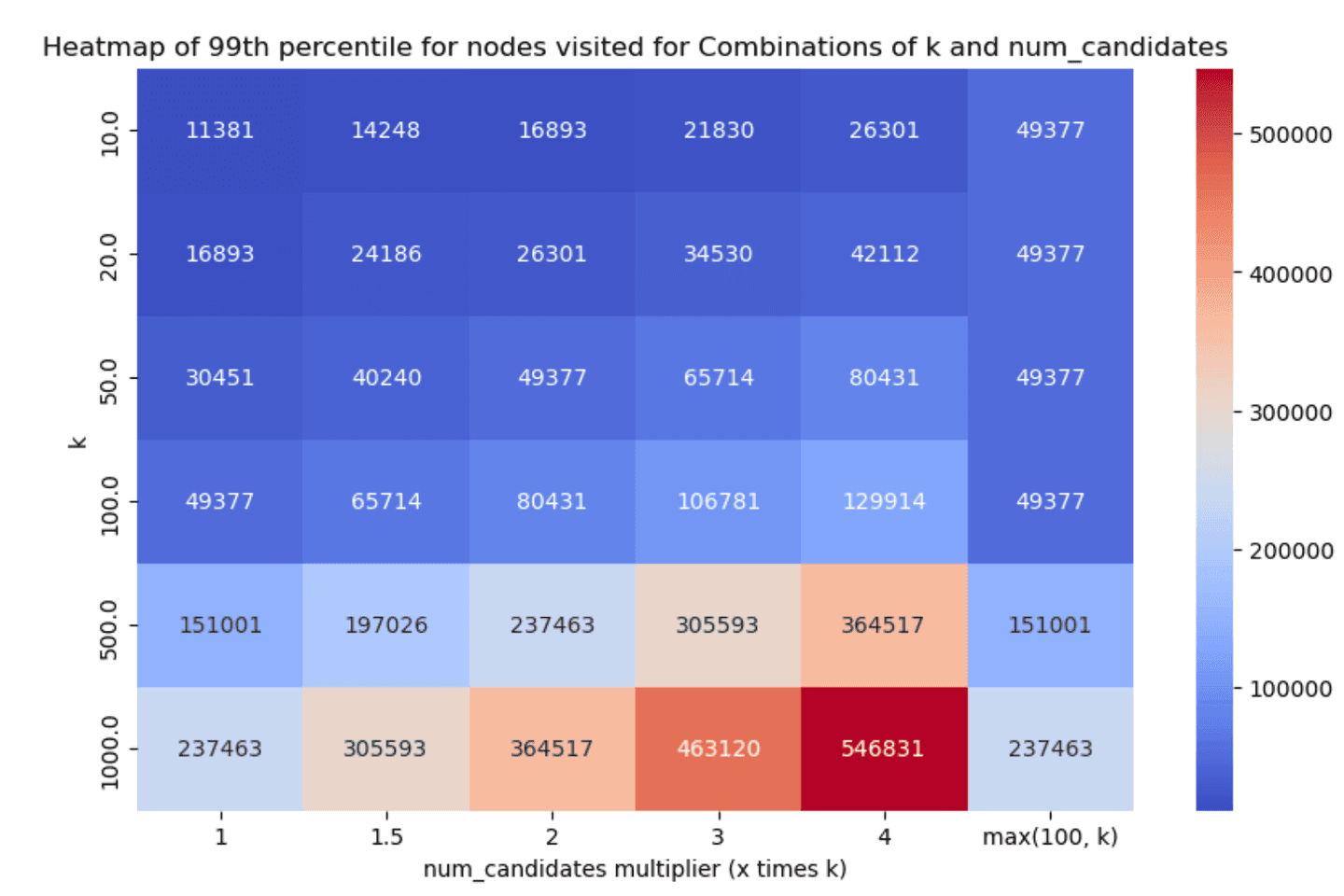
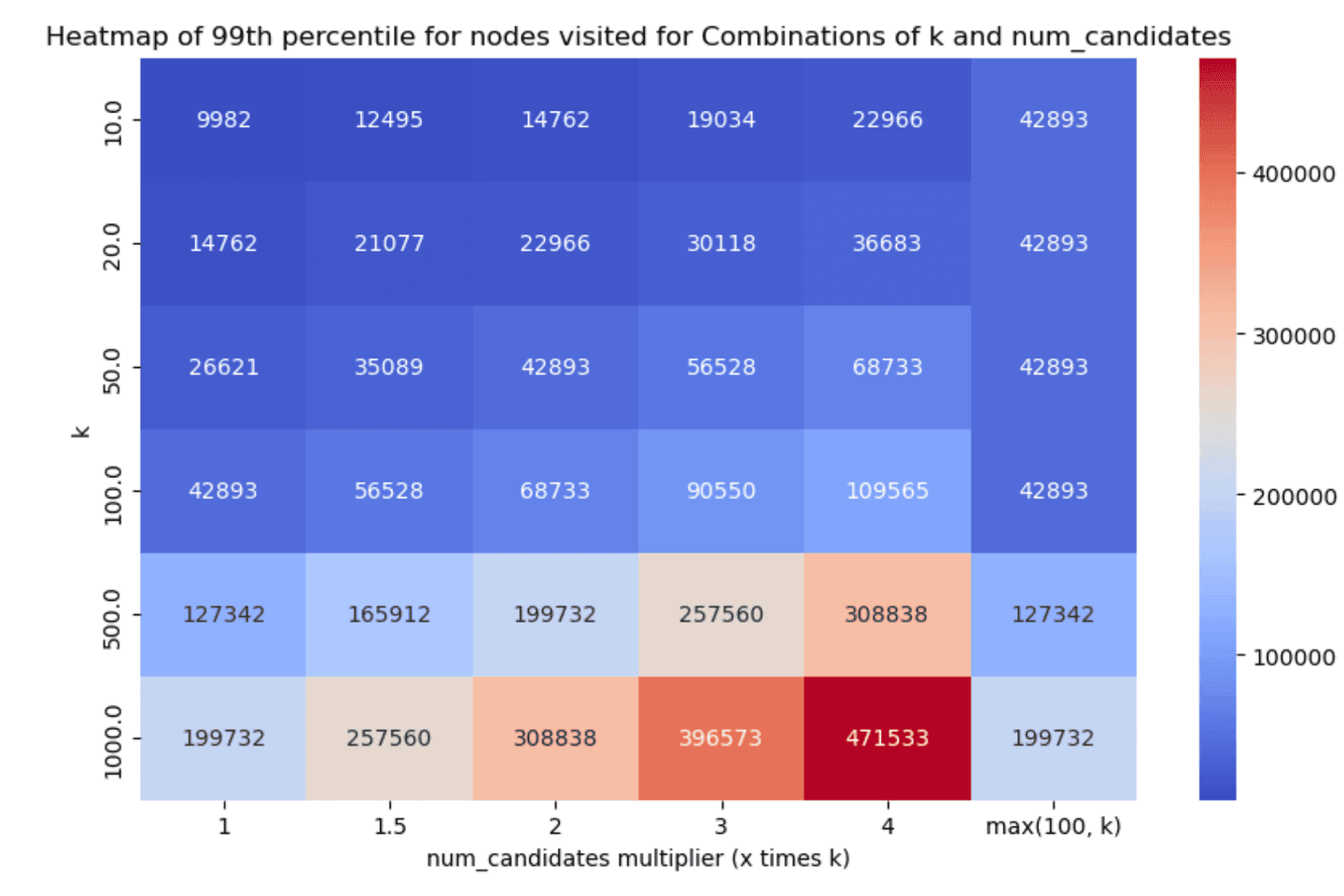
Less is more*
*well not in all cases, but hey :)
Taking a look at the results, two things stand out:
- Having one vs many segments clearly affects recall & latency metrics in an inversely proportional manner. Having less segments decreases latency (as we have fewer graphs to traverse, i.e. searches to run) which is great, but it also affects recall in the opposite manner, as it is quite possible that some good candidates will be left out (due to a fewer
num_candidateslists). - Even with little exploration we can achieve good enough recall in almost all cases, which is great!
We're constantly aiming at improving multi-segment search (a great example can be found in this post) so we expect that this tradeoff will be less of an issue going forward (the numbers reported here do not include these improvements).
Taking all things into account, the two main options we discussed were the following:
num_candidates = 1.5 * k- this achieves good enough recall in almost all cases, with very good latency scores.num_candidates = Math.max(100, k)- this achieves slightly better recall especially for lowerkvalues, with the tradeoff though of increased graph exploration and latency.
After careful consideration and (lengthy!) discussions, we opted to go with the former as the default, i.e. set num_candidates = 1.5 * k. We had to do far less exploration and recall was greater than 90% in almost all the cases we tested (with some significantly higher reported numbers as well), which should yield a good enough onboarding experience.
Conclusion
How we handle kNN search at Elastic is always evolving and we're constantly introducing new features and improvements, so these parameters and this evaluation overall could very well be outdated pretty soon! We're always on the lookout and whenever that happens we'll make sure to follow up and adjust our configurations appropriately!
One important thing to remember is that these values only act as sensible defaults for simplifying the onboarding experience and for very generic use cases. One can easily experiment on their own datasets and adjust accordingly based on their needs (e.g. recall might be much more important than latency in some scenarios).
Happy tuning 😃
Frequently Asked Questions
What's the default value for num_candidates in kNN search?
The default value for num_candidates is 1.5 * k. This achieves good enough recall in almost all cases, with very good latency scores.
Related Content

July 16, 2026
A picture is worth 1.5x the words: What we learned benchmarking product search embeddings
We benchmarked two embedding models on 5,000 real products and found that combining image and text beats either alone by up to 50%. Here's the data and the model that won.

July 13, 2026
The disk that never woke up: what actually decided our Qdrant vector search benchmark rematch
On the same hardware, Elasticsearch and Qdrant land in the same range at 56 QPS. The io_uring disk scorer and memory claims turned out to be the two things that mattered least.

July 21, 2026
4 NVIDIA AI tasks, 1 Elasticsearch API: Embeddings, chat, completion, and rerank
Set up NVIDIA hosted models in Elasticsearch with one API key and a model ID. No custom integration code needed.

July 10, 2026
How BBQ shrinks Jina v5 embeddings by 29x without losing recall in Elasticsearch
A hands-on test comparing BBQ and float32 vector indices in Elasticsearch, measuring memory, disk and recall@10 across five languages.

July 7, 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.