Elastic App Search와 함께 Spring Boot 사용하기


 Share on Twitter
Share on Twitter트위터에서 공유하기

 Share on LinkedIn
Share on LinkedIn링크드인에서 공유하기

 Share on Facebook
Share on Facebook페이스북에서 공유하기

 Share by Email
Share by Email이메일로 공유하기

 Print this page
Print this page인쇄하기
이 글에서는 웹사이트의 내용을 크롤링한 Elastic App Search를 쿼리하는 Spring Boot 애플리케이션을 아주 처음부터 시작하여 완전히 실행시켜 보겠습니다. 클러스터를 시작하고 애플리케이션을 단계별로 구성해 볼 것입니다.
클러스터 스핀업
이 예를 따르기 위해 가장 쉬운 방법은 샘플 GitHub 리포지토리를 복제하는 것입니다. terraform을 실행하고 즉시 시작하여 실행할 수 있습니다.
git clone https://github.com/spinscale/spring-boot-app-search예제를 설치하고 실행하려면, terraform 공급자 설정에 설명된 대로 Elastic Cloud에 API 키를 만들어야 합니다.
일단 그 작업이 끝나면, 다음을 실행하세요.
terraform init
terraform validate
terraform apply그리고 본격적인 작업이 시작되기 전에 커피를 한 잔 가져오세요. 몇 분 후 Elastic Cloud UI의 인스턴스가 이렇게 실행되는 것을 볼 수 있습니다.
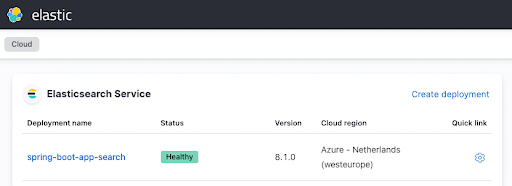
Spring Boot 애플리케이션 구성
계속하기 전에, Java 애플리케이션을 빌드하고 실행할 수 있는지 확인해 봅시다. Java 17을 설치하기만 하면 됩니다. 그러면 다음을 실행하실 수 있습니다.
./gradlew clean check이렇게 하면, 모든 종속성을 다운로드하고 테스트를 실행한 후 실패하게 됩니다. 앱 검색 인스턴스에 데이터를 색인하지 않았기 때문에 예상된 결과입니다.
그러기 전에 먼저 구성을 변경하고 일부 데이터를 색인해야 합니다. 먼저 src/main/resources/application.properties 파일을 편집하여 구성 변경을 시작해 봅시다. (아래 코드 조각에는 변경이 필요한 매개 변수만 나와 있습니다!)
appsearch.url=https://dc3ff02216a54511ae43293497c31b20.ent-search.westeurope.azure.elastic-cloud.com
appsearch.engine=web-crawler-search-engine
appsearch.key=search-untdq4d62zdka9zq4mkre4vv
feign.client.config.appsearch.defaultRequestHeaders.Authorization=Bearer search-untdq4d62zdka9zq4mkre4vvKibana 로그인 비밀번호를 입력하지 않으려는 경우, Elastic Cloud UI를 통해 Kibana 인스턴스에 로그인한 후 Enterprise Search > App Search로 이동합니다.
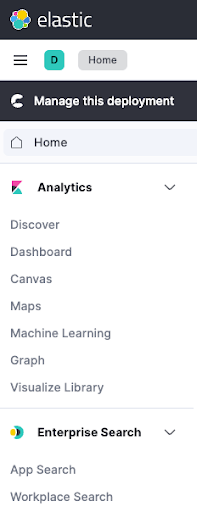
App Search 내의 Credentials 페이지에서 appsearch.key와 feign... 매개 변수를 추출할 수 있습니다. 맨 위에 표시된 Endpoint에 대해서도 마찬가지입니다.
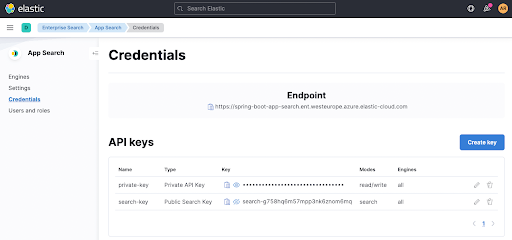
이제 ./gradlew clean check을 실행할 때 올바른 App Search 엔드포인트에 도달합니다.
그러나 여전히 데이터를 색인하지 않았기 때문에 테스트가 계속 실패합니다. 그럼 이제 색인을 해봅시다!
크롤러 구성
크롤러를 설정하기 전에, 우리의 문서를 위한 컨테이너를 만들어야 합니다. 이것은 지금 engine이라고 불리는데, 엔진을 만들어 보겠습니다. application.conf 파일과 일치하도록 엔진 이름을 web-crawler-search-engine으로 지정합니다.
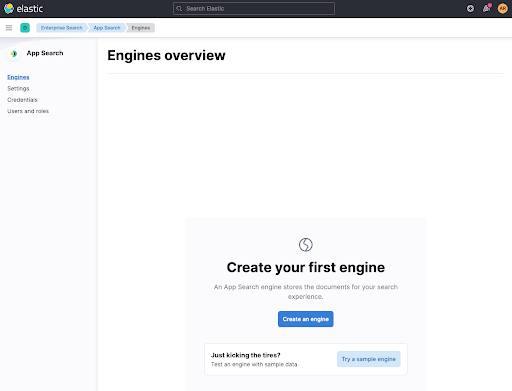
그런 다음 Use The Crawler를 클릭하여 크롤러를 구성합니다.
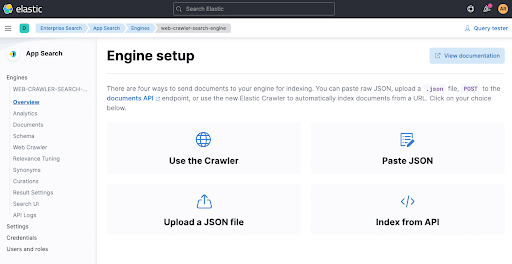
이제 도메인을 추가합니다. 여기에서 여러분의 자체 도메인을 추가할 수 있습니다. 저는 제 개인 블로그 spinscale.de를 사용했습니다. 이 블로그가 누구의 권한도 침해하지 않는다는 것을 알고 있기 때문입니다.
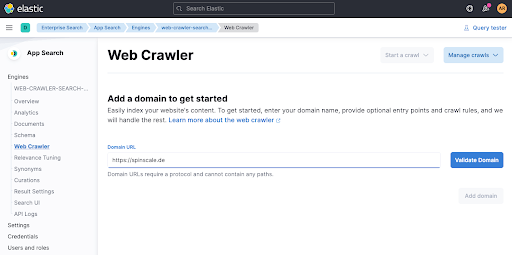
Validate Domain을 클릭하면 몇 가지 확인이 완료되고, 도메인이 엔진에 추가됩니다.
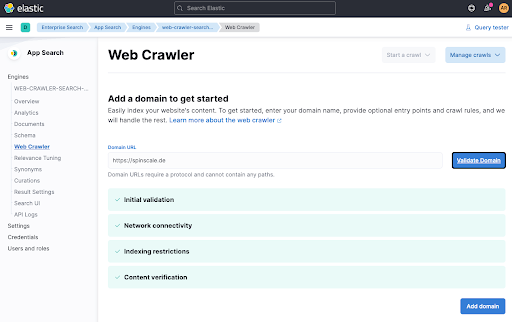
마지막 단계는 수동으로 크롤링을 트리거하여 데이터를 지금 바로 색인하는 것입니다. Start a crawl을 클릭합니다.
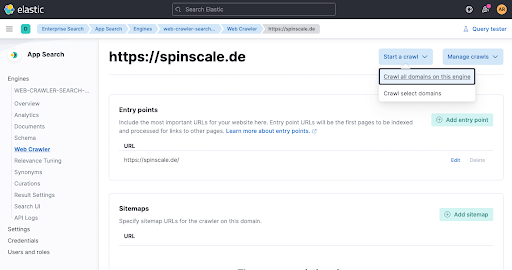
이제 잠시 기다려 문서가 추가되었는지 엔진 개요를 확인합니다.
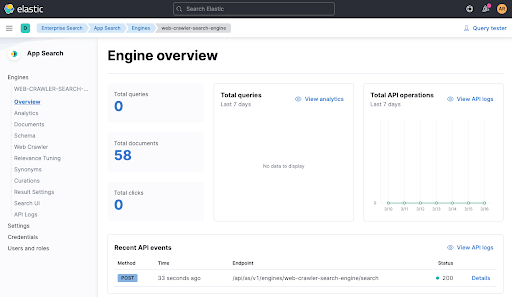
이제 엔진에 색인된 데이터를 사용하여 테스트를 다시 실행하고 ./gradlew check 검사를 통해 테스트가 통과되는지 확인해 보겠습니다. 이제 통과해야 합니다. 엔진 개요에서 테스트에서 나오는 최신 API 호출도 확인할 수 있습니다(위의 하단 참조).
앱을 시작하기 전에, 테스트 코드를 간단히 살펴보겠습니다
@SpringBootTest(classes = SpringBootAppSearchApplication.class, webEnvironment = SpringBootTest.WebEnvironment.NONE)
class AppSearchClientTests {
@Autowired
private AppSearchClient appSearchClient;
@Test
public void testFeignAppSearchClient() {
final QueryResponse queryResponse = appSearchClient.search(Query.of("seccomp"));
assertThat(queryResponse.getResults()).hasSize(4);
assertThat(queryResponse.getResults().stream().map(QueryResponse.Result::getTitle))
.contains("Using seccomp - Making your applications more secure",
"Presentations",
"Elasticsearch - Securing a search engine while maintaining usability",
"Posts"
);
assertThat(queryResponse.getResults().stream().map(QueryResponse.Result::getUrl))
.contains("https://spinscale.de/posts/2020-10-27-seccomp-making-applications-more-secure.html",
"https://spinscale.de/presentations.html",
"https://spinscale.de/posts/2020-04-07-elasticsearch-securing-a-search-engine-while-maintaining-usability.html",
"https://spinscale.de/posts/"
);
}
}이 테스트는 포트에 바인딩하지 않고 스프링 애플리케이션을 실행하고 AppSearchClient 클래스를 자동으로 주입하며 seccomp를 검색하는 테스트를 실행합니다.
애플리케이션 시작하기
이제 애플리케이션을 실행하고 애플리케이션이 시작되는지를 확인할 시간입니다.
./gradlew bootRun몇 가지 로깅 메시지가 표시됩니다. 가장 중요한 것은 다음과 같이 애플리케이션이 시작되었다는 것입니다.
2022-03-16 15:43:01.573 INFO 21247 --- [ restartedMain] d.s.s.SpringBootAppSearchApplication : Started SpringBootAppSearchApplication in 1.114 seconds (JVM running for 1.291)이제 브라우저에서 앱을 열고 볼 수 있지만, 저는 먼저 Java 코드를 보고 싶습니다.
검색 클라이언트에 대해서만 인터페이스 정의
Spring Boot 내에서 App Search 엔드포인트를 쿼리할 수 있으려면, Feign을 사용하기 위한 인터페이스만 구현하면 됩니다. 우리는 JSON 직렬화나 HTTP 연결 생성을 신경 쓸 필요가 없으며, POJO로만 작업할 수 있습니다. 다음은 앱 검색 클라이언트에 대한 정의입니다.
@FeignClient(name = "appsearch", url="${appsearch.url}")
public interface AppSearchClient {
@GetMapping("/api/as/v1/engines/${appsearch.engine}/search")
QueryResponse search(@RequestBody Query query);
}클라이언트는 url 및 engine에 대해 application.properties 정의를 사용하므로 API 호출의 일부로 지정할 필요가 없습니다. 또한 이 클라이언트는 application.properties 파일에 정의된 헤더를 사용합니다. 이렇게 하면, 애플리케이션 코드에 URL, 엔진 이름 또는 사용자 정의 인증 헤더가 포함되지 않습니다.
더 많은 구현이 필요한 클래스는 요청 본문을 모델링하기 위한 Query와 요청 응답을 모델링하는 QueryResponse뿐입니다. 일반적으로 JSON이 훨씬 더 많이 포함되어 있음에도 불구하고, 응답에서 절대적으로 필요한 필드만 모델링하기로 선택했습니다. 데이터가 더 필요할 때마다 QueryResponse 클래스에 추가할 수 있습니다.
쿼리 클래스는 현재 query 필드로만 구성되어 있습니다.
public class Query {
private final String query;
public Query(String query) {
this.query = query;
}
public String getQuery() {
return query;
}
public static Query of(String query) {
return new Query(query);
}
}마지막으로, 애플리케이션 내에서 몇 가지 검색을 실행해 보겠습니다.
서버 사이드 쿼리 및 렌더링
샘플 애플리케이션은 App Search 인스턴스를 쿼리하고 Spring Boot 애플리케이션 내에 통합하는 세 가지 모델을 구현합니다. 첫 번째는 Spring Boot 앱으로 검색 단어를 보내고, App Search로 쿼리를 보낸 다음 Spring Boot의 표준 렌더링 종속성인 타임리프를 통해 결과를 렌더링합니다. 이것이 컨트롤러입니다.
@Controller
@RequestMapping(path = "/")
public class MainController {
private final AppSearchClient appSearchClient;
public MainController(AppSearchClient appSearchClient) {
this.appSearchClient = appSearchClient;
}
@GetMapping("/")
public String main(@RequestParam(value = "q", required = false) String q,
Model model) {
if (q != null && q.trim().isBlank() == false) {
model.addAttribute("q", q);
final QueryResponse response = appSearchClient.search(Query.of(q));
model.addAttribute("results", response.getResults());
}
return "main";
}
}main() 메서드를 보면 q 매개 변수에 대한 확인이 있습니다. 쿼리가 있으면 쿼리가 App Search로 전송되고 model이 결과로 풍부해집니다. 그런 다음 main.html 타임리프 템플릿이 렌더링됩니다. 다음과 같이 표시됩니다.
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org"
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content">
<div>
<form action="/" method="get">
<input autocomplete="off" placeholder="Enter search terms..."
type="text" name="q" th:value="${q}" style="width:20em" >
<input type="submit" value="Search" />
</form>
</div>
<div th:if="${results != null && !results.empty}">
<div th:each="result : ${results}">
<h4><a th:href="${result.url}" th:text="${result.title}"></a></h4>
<blockquote style="font-size: 0.7em" th:text="${result.description}"></blockquote>
<hr>
</div>
</div>
</div>
</body>
</html>템플릿은 results 변수를 확인하고, 설정된 경우 해당 목록을 반복합니다. 모든 결과에 대해 다음과 같은 동일한 템플릿이 렌더링됩니다.
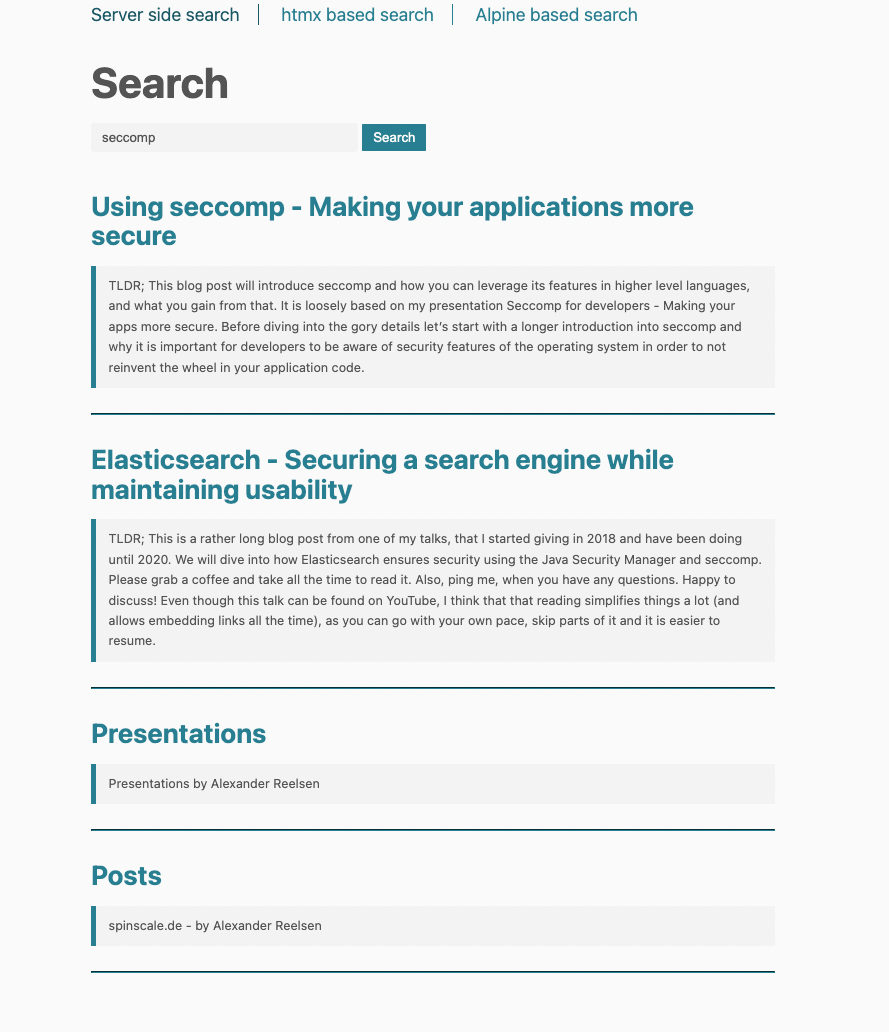
동적 페이지 업데이트에 htmx 사용
위쪽 탐색에서 볼 수 있듯이, 세 가지 방법 중에서 검색 방법을 변경할 수 있습니다. 두 번째 htmx 기반 검색을 클릭하면, 실행 모델이 약간 변경됩니다.
전체 페이지를 다시 로드하는 대신, 결과가 있는 부분만 서버가 반환하는 부분으로 대체됩니다. 이것의 좋은 점은 Javascript를 작성하지 않고도 할 수 있다는 것입니다. 이것은 멋진 htmx 라이브러리 덕분에 가능합니다. 설명 > htmx를 인용하면 속성을 사용하여 HTML로 직접 AJAX, CSS Transitions, WebSockets, Server Sent Events에 액세스할 수 있으므로, 하이퍼텍스트의 단순성과 강력한 기능으로 현대적인 사용자 인터페이스를 구축할 수 있습니다
이 예에서는 htmx의 아주 작은 부분 집합만 사용됩니다. 먼저, 두 개의 엔드포인트 정의를 살펴보겠습니다. 하나는 HTML을 렌더링하기 위한 것이고 다른 하나는 페이지의 부분을 업데이트하는 데 필요한 HTML 코드 조각만 반환하기 위한 것입니다.
htmx는 속성을 사용하여 HTML로 직접 AJAX, CSS Transitions, WebSockets, Server Sent Events에 액세스할 수 있으므로, 하이퍼텍스트의 단순성과 강력한 기능으로 현대적인 사용자 인터페이스를 구축할 수 있습니다
첫 번째는 htmx-main 템플릿을 렌더링하고 두 번째 엔드포인트는 결과를 렌더링합니다. htmx-main 템플릿은 다음과 같습니다.
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org"
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content">
<div>
<form action="/search" method="get">
<input type="search"
autocomplete="off"
id="searchbox"
name="q" placeholder="Begin Typing To Search Articles..."
hx-post="/htmx-search"
hx-trigger="keyup changed delay:500ms, search"
hx-target="#search-results"
hx-indicator=".htmx-indicator"
style="width:20em">
<span class="htmx-indicator" style="padding-left: 1em;color:red">Searching... </span>
</form>
</div>
<div id="search-results">
</div>
</div>
</body>
</html>마법은 <input> HTML 요소의 hx- 속성에서 발생합니다. 이것을 큰 소리로 읽으면, 다음과 같은 뜻이 됩니다.
- 500ms 동안 입력 작업이 없는 경우에만 HTTP 요청을 트리거합니다.
- 그런 다음 /htmx-search에 HTTP POST 요청을 보냅니다.
- 기다리는 동안, .htmx-indicator 요소를 표시합니다.
- 응답은 ID #search-results로 요소에 렌더링되어야 합니다.
키 리스너, 응답 대기 요소 표시 또는 AJAX 요청 전송과 관련된 모든 논리에 필요한 Javascript의 양을 생각해 보세요.
또 다른 큰 장점은 즐겨찾는 서버 사이드 렌더링 솔루션을 사용하여 반환되는 HTML을 만들 수 있다는 것입니다. 즉, 클라이언트 사이드 템플릿 언어를 구현하는 대신 타임리프 생태계에 계속 머물 수 있습니다. 따라서 htmx-search-results 템플릿은 결과를 반복하기만 하며 매우 간단합니다.
<div th:each="result : ${results}">
<h4><a th:href="${result.url}" th:text="${result.title}"></a></h4>
<blockquote style="font-size: 0.7em" th:text="${result.description}"></blockquote>
<hr>
</div>첫 번째 예와 다른 점은 이 검색의 URL이 변경되지 않으므로 즐겨찾기에 추가할 수 없다는 것입니다. htmx에 이력 지원이 있지만, 제대로 하려면 좀 더 신중한 구현이 필요하기 때문에 이 예를 위해 생략했습니다.
App Search에 대해 브라우저를 통해 검색
이제 마지막 예로 넘어가겠습니다. 이는 Spring Boot 서버 사이드를 전혀 포함하지 않기 때문에 크게 다릅니다. 모든 것이 브라우저에서 수행됩니다. 이 작업은 Alpine.js를 사용하여 수행됩니다. 서버 사이드 엔드포인트는 다음과 같이 가능한 한 단순해 보입니다.
@GetMapping("/alpine")
public String alpine() {
return "alpine-js";
}alpine-js.html 템플릿에 대한 자세한 설명이 필요하지만, 먼저 살펴보겠습니다.
<!DOCTYPE html>
<html
xmlns:layout="http://www.ultraq.net.nz/thymeleaf/layout"
layout:decorate="~{layouts/base}">
<body>
<div layout:fragment="content" x-data="{ q: '', response: null }">
<div>
<form @submit.prevent="">
<input type="search" autocomplete="off" placeholder="Begin Typing To Search Articles..." style="width:20em"
x-model="q"
@keyup="client.search(q).then(resultList => response = resultList)">
</form>
</div>
<template x-if="response != null && response.info.meta != null && response.info.meta.request_id != null">
<template x-for="result in response.results">
<template x-if="result.data != null && result.data.title != null && result.data.url != null && result.data.meta_description != null ">
<div>
<h4><a class="track-click" :data-request-id="response.info.meta.request_id" :data-document-id="result.data.id.raw" :data-query="q" :href="result.data.url.raw" x-text="result.data.title.raw"></a></h4>
<blockquote style="font-size: 0.7em" x-text="result.data.meta_description.raw"></blockquote>
<hr>
</div>
</template>
</template>
</template>
<script th:inline="javascript">
var client = window.ElasticAppSearch.createClient({
searchKey: [[${@environment.getProperty('appsearch.key')}]],
endpointBase: [[${@environment.getProperty('appsearch.url')}]],
engineName: [[${@environment.getProperty('appsearch.engine')}]]
});
document.addEventListener("click", function(e) {
const el = e.target;
if (!el.classList.contains("track-click")) return;
client.click({
query: el.getAttribute("data-query"),
documentId: el.getAttribute("data-document-id"),
requestId: el.getAttribute("data-request-id")
});
});
</script>
</div>
</body>
</html>첫 번째 주요 차이점은 application.properties 파일의 구성된 속성을 사용하여 ElasticAppSearch 클라이언트를 초기화하기 위한 JavaScript의 실제 사용입니다. 클라이언트가 초기화되면 HTML 특성에 이를 사용할 수 있습니다.
코드가 사용할 두 변수를 초기화합니다.
<div layout:fragment="content" x-data="{ q: '', response: null }">q 변수에는 입력 양식의 쿼리가 포함되고 응답에는 검색의 응답이 포함됩니다. 다음으로 흥미로운 부분은 양식 정의입니다.
<form @submit.prevent="">
<input type="search" autocomplete="off" placeholder="Search Articles..."
x-model="q"
@keyup="client.search(q).then(resultList => response = resultList)">
</form><input x-model="q"...>를 사용하면 q 변수가 입력에 바인딩되고 사용자가 입력할 때마다 업데이트됩니다. client.search()를 이용해 검색을 실행하고 결과를 response 변수에 할당하는 `keyup` 이벤트도 있습니다. 따라서 클라이언트 검색이 반환되면 응답 변수가 더 이상 비어 있지 않게 됩니다. 마지막으로, @submit.prevent=""을 사용해 양식이 제출되지 않도록 보장합니다.
다음으로 응답이 설정되고
<div>
<h4><a class="track-click"
:data-request-id="response.info.meta.request_id"
:data-document-id="result.data.id.raw"
:data-query="q"
:href="result.data.url.raw"
x-text="result.data.title.raw">
</a></h4>
<blockquote style="font-size: 0.7em"
x-text="result.data.meta_description.raw"></blockquote>
<hr>
</div>이 렌더링은 클릭된 링크를 추적하는 기능이 추가되었기 때문에 두 서버 사이드 렌더링 구현과는 약간 다릅니다. 템플릿을 렌더링하는 데 중요한 부분은 링크와 링크의 텍스트를 설정하는 :href 및 x-text 속성입니다. 다른 :data 매개 변수는 링크를 추적하기 위한 것입니다.
클릭 추적
그렇다면, 링크 클릭을 추적하려는 이유는 무엇일까요? 간단히 말하면, 사용자가 검색 결과를 클릭했는지 여부를 측정하여 검색 결과가 양호한지 여부를 확인할 수 있는 방법 중 하나입니다. 이것은 또한 이 HTML 코드 조각에 Javascript가 더 포함된 이유이기도 합니다. 먼저 Kibana에서 이것이 어떻게 보이는지 살펴보겠습니다.
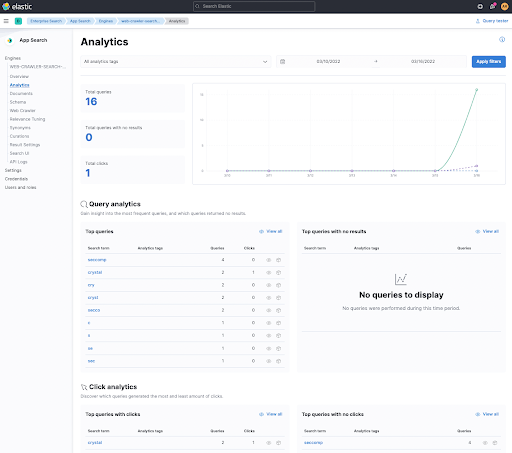
클릭한 첫 번째 링크에서 crystal을 검색한 후, 클릭을 추적한 Click analytics를 하단에서 볼 수 있습니다. 해당 단어를 클릭하면 어떤 문서가 클릭되었는지 확인할 수 있으며 기본적으로 사용자의 클릭 추적을 따라갈 수 있습니다.
그렇다면, 이것은 우리의 작은 앱에서 어떻게 구현될까요? 특정 링크에 대해 click Javascript 리스너를 사용해서입니다. 다음은 Javascript 코드 조각입니다.
document.addEventListener("click", function(e) {
const el = e.target;
if (!el.classList.contains("track-click")) return;
client.click({
query: el.getAttribute("data-query"),
documentId: el.getAttribute("data-document-id"),
requestId: el.getAttribute("data-request-id")
});
});클릭한 링크에 트랙 track-click 클래스가 있는 경우, ElasticAppSearch 클라이언트를 사용하여 클릭 이벤트를 보냅니다. 이 이벤트에는 원래 쿼리 단어와 검색 응답의 일부였으며 위 템플릿의 요소로 렌더링된 documentId 및 requestId가 포함됩니다.
또한 사용자가 링크를 클릭할 때 해당 정보를 제공하여 이 기능을 서버 사이드 렌더링에 추가할 수 있으므로, 브라우저에만 독점적으로 해당되지 않습니다. 간단하게 진행하기 위해, 여기서는 이 구현을 생략했습니다.
요약
개발자의 관점에서 Elastic App Search를 소개하고 이를 여러분의 애플리케이션에 통합할 수 있는 다양한 가능성을 경험해 보셨기를 바랍니다. 반드시 GitHub 리포지토리를 확인하시고 예제를 따라해 보세요.
Elastic Cloud Provider와 함께 Terraform을 사용하면 Elastic Cloud에서 즉시 시작하고 실행하실 수 있습니다.
공유하기
- Share on Twitter
트위터에서 공유하기
- Share on LinkedIn
링크드인에서 공유하기
- Share on Facebook
페이스북에서 공유하기
- Share by Email
이메일로 공유하기
- Print this page
인쇄하기