Indexar los archivos CSV con Elasticsearch Ingest Node
La idea de este artículo es repasar las capacidades de algunas de las características del nodo de ingesta (Ingest Node), que se combinarán para analizar un archivo de valores separados por comas (CSV). Repasaremos qué es un nodo Ingest Node, qué tipo de operaciones se pueden realizar y mostraremos un ejemplo específico comenzando desde cero para analizar y mostrar datos CSV usando Elasticsearch y Kibana.
Para eso, usaremos un catálogo abierto de asuntos comunitarios de Nueva York. Este archivo CSV se actualizó en octubre de 2015 y consta de 32 campos que trazan las listas completas de las entradas y salidas de las estaciones de trenes. El objetivo será usar la función Ingest de Elasticsearch en un clúster en Elastic Cloud para analizar los datos en un json estructurado, indexar los datos y usar Kibana para elaborar un mapa de la ciudad de Nueva York que incluya todas las estaciones de trenes.
Usaremos la función Ingest de Elasticsearch en lugar de Logstash como una manera de eliminar la necesidad de la configuración de software/arquitectura adicional para un problema sencillo que puede resolverse simplemente con Elasticsearch.
Con todo esto listo, podremos visualizar los datos y responder algunas preguntas como por ejemplo, “¿dónde podemos encontrar una estación con elevadores?”, “¿dónde se encuentran la mayoría de las estaciones?”, “¿cuál es el área de mayor densidad?”, entre otras. Nuestros datos vendrán de un archivo de texto y se convertirán en información.
Configuración del clúster
Para empezar, vamos a usar un pequeño clúster de Elastic Cloud con 2 GB de memoria y 48 GB de disco. Descargaremos el archivo CSV con estos datos de Exportación a la función CSV incluidos en el siguiente sitio web: https://data.ny.gov/NYC-Transit-Subway.
Usaremos un script de Linux que está compuesto por un bucle (iteración) simple para iterar a través de las líneas CSV y enviarlo a nuestro clúster en Elastic Cloud. Elastic Cloud nos dará un punto final para nuestra instancia de Elasticsearch. Además de esto, necesitamos habilitar Kibana para usar las herramientas del desarrollador y también para elaborar el Dashboard.
Para poder analizar el archivo, debemos reemplazar todas las comillas dobles con comillas simples y eliminar la primera línea del archivo (encabezado) antes de procesarlo. Esto se puede hacer con su herramienta preferida. Cada entrada se debe ver de la siguiente manera (observe las comillas simples):
BMT,4 Avenue,25th St,40.660397,-73.998091,R,,,,,,,,,,,Stair,YES,,YES,FULL,,FALSE,,FALSE,4th Ave,25th St,SE,40.660323,-73.997952,'(40.660397, -73.998091)','(40.660323, -73.997952)'
Análisis en json
Para poder buscar y crear Visualizaciones, debemos analizar el texto simple en un json estructurado. Para hacerlo, enviaremos los datos a elasticsearch mediante el siguiente script:
while read f1
do
curl -XPOST 'https://XXXXXXX.us-east-1.aws.found.io:9243/subway_info_v1/station' -H "Content-Type: application/json" -u elastic:XXXX -d "{ \"station\": \"$f1\" }"
done < NYC_Transit_Subway_Entrance_And_Exit_Data.csv
Este script leerá el archivo (llamado NYC_Transit_Subway_Entrance_And_Exit_Data.csv), línea por línea y enviará el siguiente json inicial a Elasticsearch:
{
"station": "BMT,4 Avenue,59th St,40.641362,-74.017881,N,R,,,,,,,,,,Stair,YES,,YES,NONE,,FALSE,,TRUE,4th Ave,60th St,SW,40.640682,-74.018857,'(40.641362, -74.017881)','(40.640682, -74.018857)'"
}
El json contiene solo un campo “estación” con una sola línea. Una vez que se envía el json a Elasticsearch, debemos tomar la información y partir el campo estación en múltiples campos, cada un con un solo valor de la línea no estructurada. Es recomendable usar la API simular de Elasticsearch para ejecutar y desarrollar el proceso antes de realmente crearlo. Al principio solo debe comenzar con un documento y un proceso vacío:
POST _ingest/pipeline/_simulate
{
"pipeline": {},
"docs": [
{
"station": "BMT,4 Avenue,59th St,40.641362,-74.017881,N,R,,,,,,,,,,Stair,YES,,YES,NONE,,FALSE,,TRUE,4th Ave,60th St,SW,40.640682,-74.018857,'(40.641362, -74.017881)','(40.640682, -74.018857)'"
}
]
}
Hay muchos procesadores disponibles para procesar las líneas, así que debería considerarlos a todos para elegir cuál va a usar. En este caso, simplemente usaremos el procesador Grok, que nos permite definir con facilidad un patrón simple para nuestras líneas. La idea del siguiente procesador es analizar usando grok y finalmente eliminar el campo que contiene la línea completa:
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description": "Parsing the NYC stations",
"processors": [
{
"grok": {
"field": "station",
"patterns": [
"%{WORD:division},%{DATA:line},%{DATA:station_name},%{NUMBER:location.lat},%{NUMBER:location.lon},%{DATA},%{DATA},%{DATA},%{DATA},%{DATA},%{DATA},%{DATA},%{DATA},%{DATA},%{DATA},%{DATA},%{DATA:entrance_type},%{DATA:entry},%{DATA:exit_only},%{DATA:vending}"
]
}
},
{
"remove": {
"field": "station"
}
}
]
},
"docs": [
{
"_index": "subway_info",
"_type": "station",
"_id": "AVvJZVQEBr2flFKzrrkr",
"_score": 1,
"_source": {
"station": "BMT,4 Avenue,53rd St,40.645069,-74.014034,R,,,,,,,,,,,Stair,NO,Yes,NO,NONE,,FALSE,,TRUE,4th Ave,52nd St,NW,40.645619,-74.013688,'(40.645069, -74.014034)','(40.645619, -74.013688)'"
}
}
]
}
Este proceso producirá el siguiente documento con campos estructurados y listo para ser indexado en Elasticsearch:
{
"division": "BMT",
"station_name": "53rd St",
"entry": "NO",
"exit_only": "Yes",
"line": "4 Avenue",
"vending": "",
"location": {
"lon": "-74.014034",
"lat": "40.645069"
},
"entrance_type": "Stair"
}
Indexar los documentos
Antes de indexar el documento, necesitamos crear una plantilla de índices (index templates) que coincidirán con el nombre del índice que vamos a usar. Para poder hacer un filtrado de documentos y consultas de geolocalización y el panel adecuadamente, se deben configurar ciertos tipos de campos que requieren una definición de asignación específica. Esto se puede hacer explícitamente creando el índice con anticipación pero es mejor usar una plantilla de índices para hacerlo flexible. Se crearán automáticamente nuevos índices siguiendo este nombre con todas estas configuraciones y asignaciones. El nombre del índice que usaremos en este caso comenzará con subway_info seguido por la versión (v1 por ejemplo). Para eso, debemos usar la siguiente plantilla que coincidirá con el nombre de dicho índice:
PUT _template/nyc_template
{
"template": "subway_info*",
"settings": {
"number_of_shards": 1
},
"mappings": {
"station": {
"properties": {
"location": {
"type": "geo_point"
},
"entry": {
"type": "keyword"
},
"exit_only": {
"type": "keyword"
}
}
}
}
}
Después de crear la plantilla, debemos tomar el proceso de ingesta del paso simular y poner el proceso en sí en Elasticsearch, de modo que podamos invocarla en el momento de la indexación. El comando para poner el proceso de ingesta debería verse de la siguiente manera:
PUT _ingest/pipeline/parse_nyc_csv
{
"description": "Parsing the NYC stations",
"processors": [
{
"grok": {
"field": "station",
"patterns": [
"%{WORD:division},%{DATA:line},%{DATA:station_name},%{NUMBER:location.lat},%{NUMBER:location.lon},%{DATA},%{DATA},%{DATA},%{DATA},%{DATA},%{DATA},%{DATA},%{DATA},%{DATA},%{DATA},%{DATA},%{DATA:entrance_type},%{DATA:entry},%{DATA:exit_only},%{DATA:vending}"
]
}
},
{
"remove": {
"field": "station"
}
}
]
}
Ahora, solo debemos leer el archivo y enviar los datos a Elasticsearch usando el proceso que creamos. La definición del proceso está configurada en la URL:
while read f1
do
curl -XPOST 'https://XXXXXXX.us-east-1.aws.found.io:9243/subway_info_v1/station?pipeline=parse_nyc_csv' -H "Content-Type: application/json" -u elastic:XXXX -d "{ \"station\": \"$f1\" }"
done < NYC_Transit_Subway_Entrance_And_Exit_Data.csv
Dejemos que se ejecute por un momento y creará cada todos los documentos, uno a la vez. Observe que estamos usando la API de índices y no la API en masa (bulk API). Para hacerlo más rápido y sólido para casos de producción, recomendamos usar la API en masa (bulk) para indexar estos documentos. Al final del proceso de ingesta, tendrá 1868 estaciones en el índice subway_info_v1.
Creación del panel
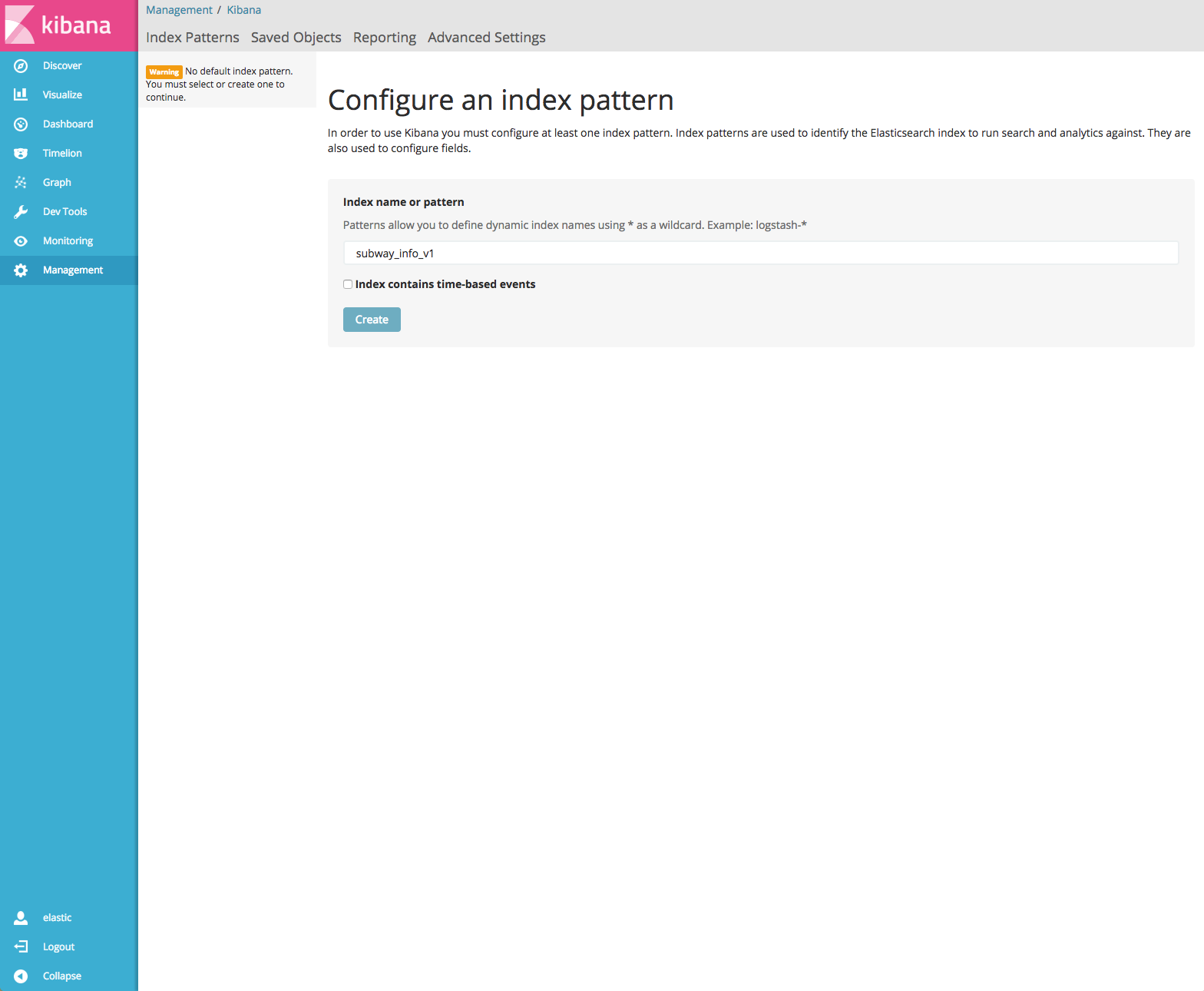
Para construir el Dashboard, primero tenemos que agregar el patrón de índices a Kibana. Para hacerlo, vaya a Administración y agregue el patrón de índices subway_info_v1. Debe desactivar la opción “Index contains time-based events” (el índice contiene eventos basados en el tiempo) ya que no son datos de series temporales (nuestros datos no contienen un campo de fecha y hora).
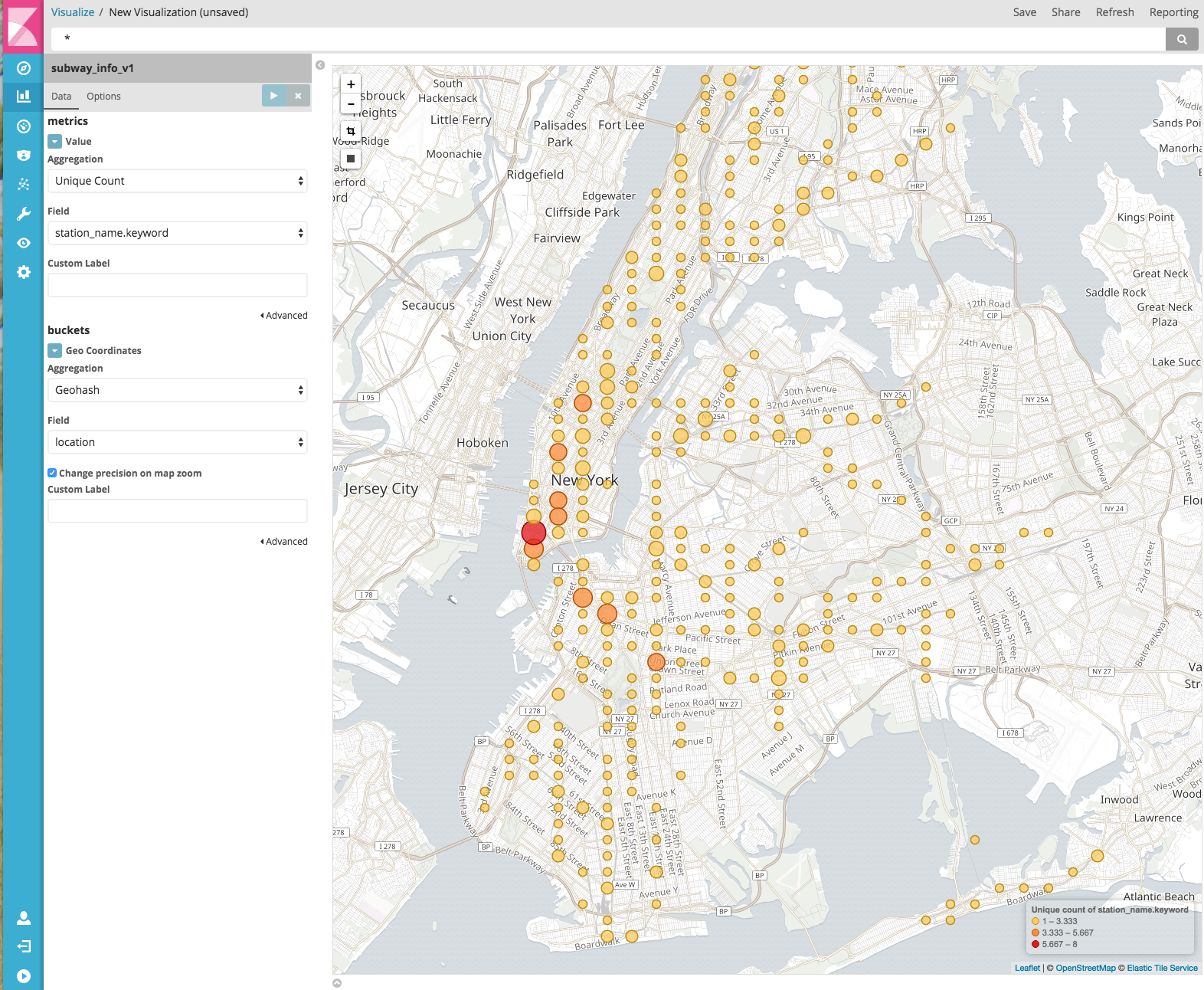
Después de esto podemos ir y crear primero nuestra visualización del mapa de mosaicos que muestra todas las estaciones del metro que tenemos en este conjunto de datos para la ciudad de Nueva York. Para hacerlo, debemos ir a Visualizaciones y seleccionar el tipo de mapa de mosaicos. Al elegir el campo de geolocalización y la cardinalidad del nombre de la estación, obtenemos una vista fácil y rápida de las estaciones existentes.
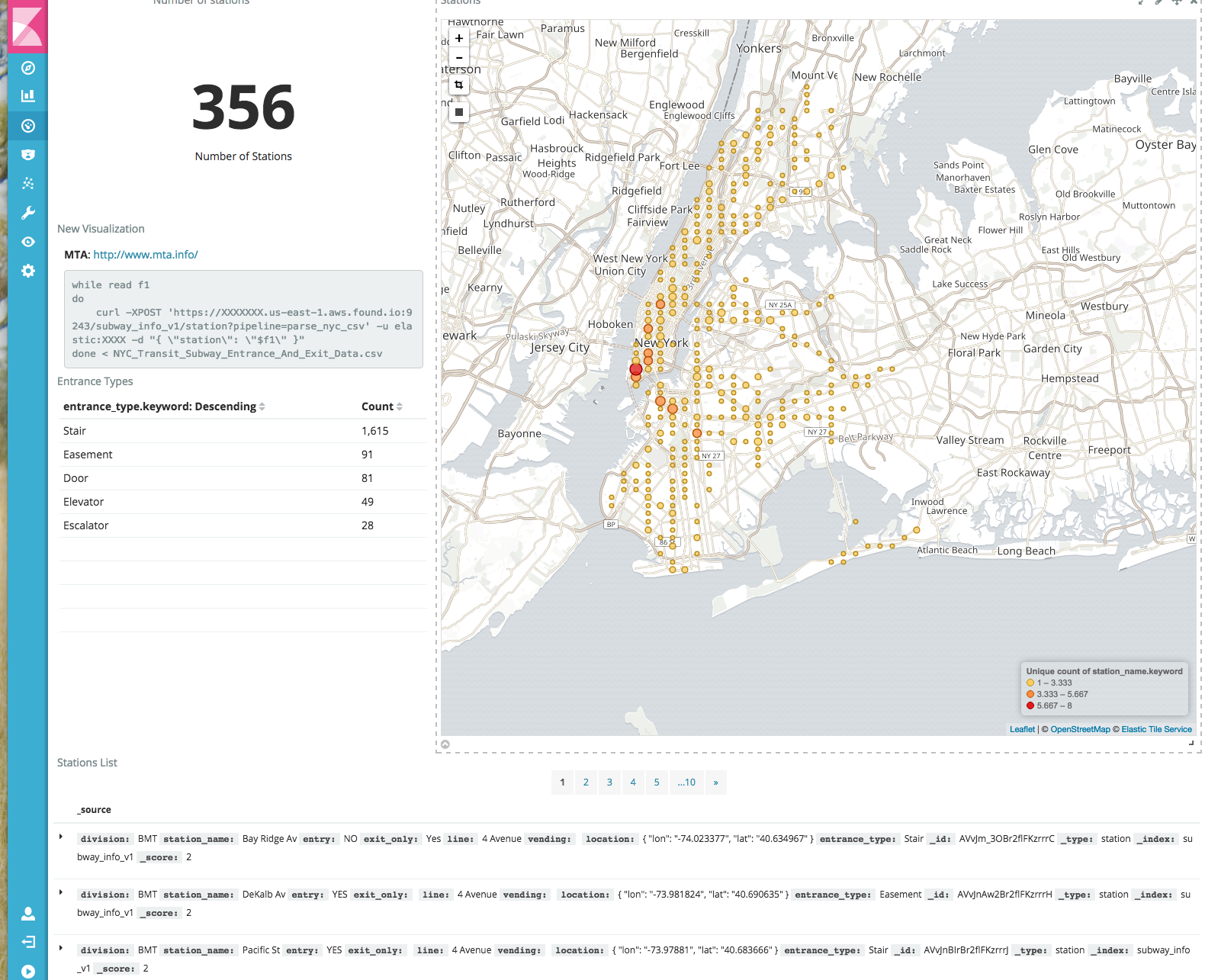
Al agregar algunas visualizaciones adicionales, como una búsqueda guardada y el tipo de entrada, podemos crear fácilmente una herramienta para buscar estaciones de metro específicas en la ciudad de Nueva York.
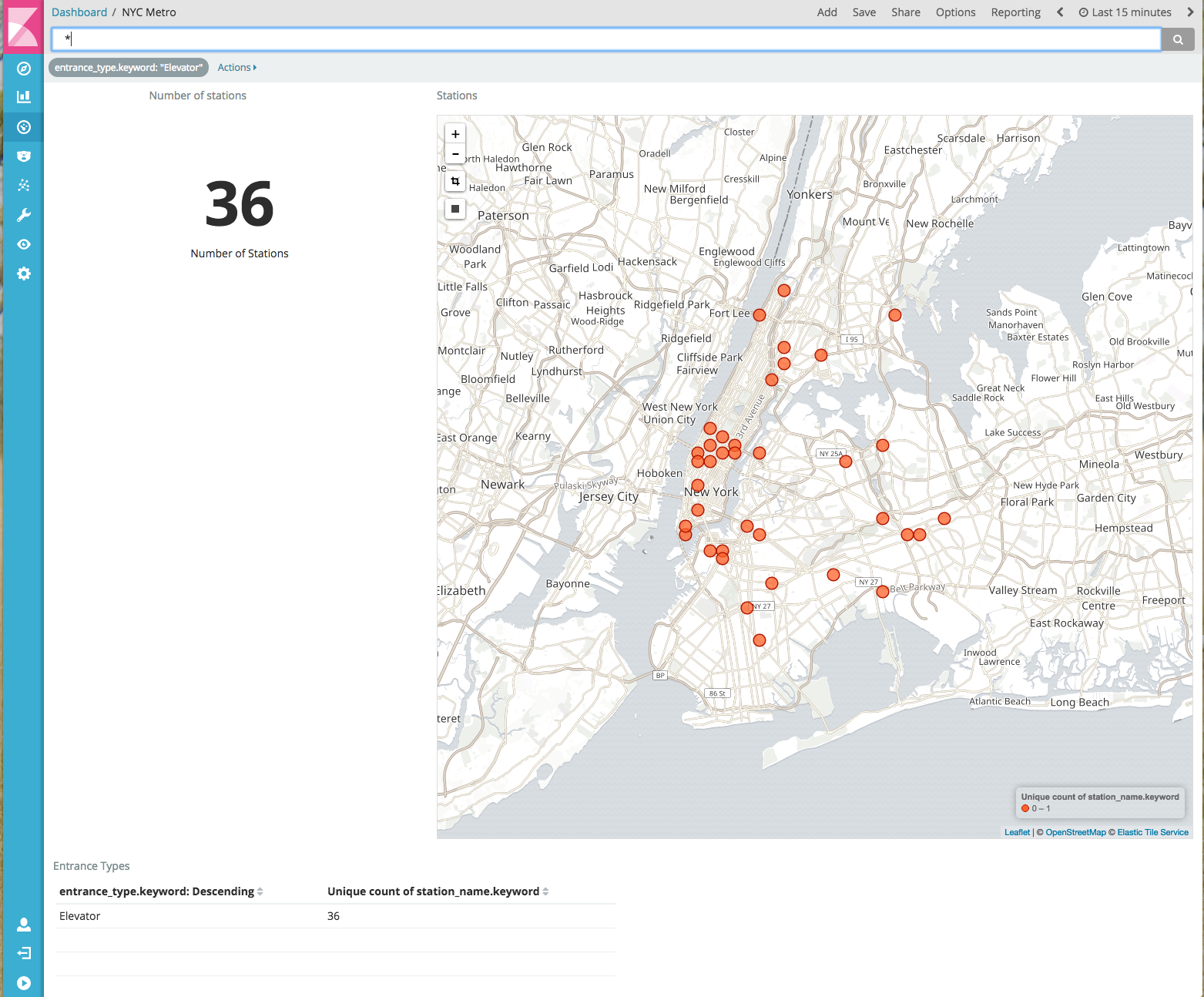
Como podemos ver aquí, el centro de Manhattan es el área con la mayor cantidad de estaciones de metro. Con Kibana puede seleccionar un rectángulo específico y además filtrar en un valor, por ejemplo, “Elevador”. Por ejemplo, de las 356 estaciones, alrededor de 200 se encuentran en Manhattan y 36 estaciones tienen elevadores.
Pruébelo con su conjunto de datos.
Como puede ver, empezar de cero con un archivo CSV es muy sencillo. Puede ejecutar una muestra en una instancia -gratuita- de Elastic Cloud (cloud.elastic.co) e introducir sus datos con muy poco trabajo. Ingest Node es la herramienta que le permitirá convertir datos no estructurados en datos estructurados, y finalmente poder crear visualizaciones eficaces con Kibana. Empezar desde cero y lograr su objetivo en Elasticsearch es tan fácil como crear un clúster. Pruébelo por su cuenta.