Cómo mantener Elasticsearch sincronizado con una base de datos relacional usando Logstash y JDBC
Para aprovechar las poderosas capacidades de búsqueda que ofrece Elasticsearch, muchas empresas implementan Elasticsearch junto con las bases de datos relacionales existentes. En una situación así, probablemente, será necesario mantener Elasticsearch sincronizado con los datos almacenados en la base de datos relacional asociada. Por ello, en este blog mostraremos cómo se puede usar Logstash para copiar registros eficazmente y sincronizar actualizaciones de una base de datos relacional en Elasticsearch. El código y los métodos que presentamos aquí se probaron con MySQL, pero en teoría deberían funcionar con cualquier RDBMS.
Configuración del sistema
Para este blog, probamos lo siguientes:
- MySQL: 8.0.16.
- Elasticsearch: 7.1.1
- Logstash: 7.1.1
- Java: 1.8.0_162-b12
- Plugin de entrada JDBC: v4.3.13
- Conector JDBC: Connector/J 8.0.16
Una visión general de alto nivel de los pasos de sincronización
En este blog usamos Logstash con el plugin de entrada JDBC para mantener Elasticsearch sincronizado con MySQL. En teoría, el plugin de entrada JDBC de Logstash usa un bucle que sondea MySQL periódicamente para obtener los registros que se insertaron o modificaron desde la última iteración de este bucle. Para que esto funcione de manera correcta, deben cumplirse las siguientes condiciones:
- Debido a que los documentos de MySQL se escriben en Elasticsearch, el campo "_id" de Elasticsearch se debe establecer en el campo "id" de MySQL. Esto proporciona un mapeo directo entre el registro de MySQL y el documento de Elasticsearch. Si se actualiza un registro en MySQL, todo el documento asociado se sobrescribirá en Elasticsearch. Ten en cuenta que sobrescribir un documento en Elasticsearch es solo tan eficiente como realizar una operación de actualización, ya que internamente una actualización consistiría en borrar el documento antiguo y después indexar un documento totalmente nuevo.
- Los registros que se insertan o actualizan en MySQL deben contar con un campo que contenga la hora de la actualización o inserción. Este campo se usa para permitir que Logstash solicite solo los documentos que se modificaron o insertaron desde la última iteración del bucle de sondeo. Cada vez que Logstash sondea MySQL, almacena la hora de actualización o inserción del último registro que leyó desde MySQL. En la próxima iteración, Logstash sabe que solo necesita solicitar registros con una hora de actualización o inserción que sea más reciente que la del último registro recibido en la iteración previa del bucle de sondeo.
Si se cumplen las condiciones anteriores, podemos configurar Logstash para que solicite periódicamente todos los registros nuevos o modificados desde MySQL y que después los escriba en Elasticsearch. Mostraremos el código de Logstash para esto más adelante en este blog.
Configuración de MySQL
La base de datos y la tabla de MySQL pueden configurarse de la siguiente manera:
CREATE DATABASE es_db; USE es_db; DROP TABLE IF EXISTS es_table; CREATE TABLE es_table ( id BIGINT(20) UNSIGNED NOT NULL, PRIMARY KEY (id), UNIQUE KEY unique_id (id), client_name VARCHAR(32) NOT NULL, modification_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, insertion_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP );
Los siguientes son algunos parámetros interesantes de la configuración anterior de MySQL:
es_table: Este es el nombre de la tabla de MySQL desde la que los registros se leerán y sincronizarán con Elasticsearch.id: Este es un identificador único para este registro. Observa que “id” se define como CLAVE PRINCIPAL y CLAVE ÚNICA a la vez. Esto garantiza que cada “id” solo aparezca una vez en la tabla actual. Esto se traducirá como “_id” para actualizar el documento o insertarlo en Elasticsearch.client_name: Este es un campo que representa los datos definidos por el usuario que se almacenarán en cada registro. Para que este blog sea lo más simple posible, solo contamos con un único campo con datos definidos por el usuario, pero se pueden agregar más campos con facilidad. Este es el campo que modificaremos para mostrar que no solo se copian en Elasticsearch los registros de MySQL recientemente insertados, sino que también se propagan correctamente en Elasticsearch los registros actualizados.modification_time: Este campo se define para que cualquier inserción o actualización de un registro en MySQL establezca su valor en la hora de la modificación. Esta hora de modificación nos permite quitar cualquier registro que se haya modificado desde la última vez que Logstash solicitó documentos desde MySQL.insertion_time: Este campo tiene como propósito principal la demostración y no es estrictamente necesario para que la sincronización funcione correctamente. Lo usamos para rastrear el momento en que un registro se insertó originalmente en MySQL.
Operaciones de MySQL
De acuerdo con la configuración anterior, los registros pueden escribirse en MySQL de la siguiente manera:
INSERT INTO es_table (id, client_name) VALUES (<id>, <client name>);
Los registros de MySQL se pueden actualizar usando el siguiente comando:
UPDATE es_table SET client_name = <new client name> WHERE id=<id>;
Los upserts de MySQL se pueden realizar de la siguiente manera:
INSERT INTO es_table (id, client_name) VALUES (<id>, <client name when created> ON DUPLICATE KEY UPDATE client_name=<client name when updated>;
Código de sincronización
El siguiente pipeline de Logstash implementa el código de sincronización que se describe en la sección anterior:
input {
jdbc {
jdbc_driver_library => "<path>/mysql-connector-java-8.0.16.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://<MySQL host>:3306/es_db"
jdbc_user => <my username>
jdbc_password => <my password>
jdbc_paging_enabled => true
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC"
}
}
filter {
mutate {
copy => { "id" => "[@metadata][_id]"}
remove_field => ["id", "@version", "unix_ts_in_secs"]
}
}
output {
# stdout { codec => "rubydebug"}
elasticsearch {
index => "rdbms_sync_idx"
document_id => "%{[@metadata][_id]}"
}
}
Existen algunas áreas del pipeline anterior que deben resaltarse:
tracking_column: Este campo especifica el campo “unix_ts_in_secs” (descrito a continuación) que se usa para rastrear el último documento leído por Logstash desde MySQL y se almacena en disco en .logstash_jdbc_last_run. Este valor se usará para determinar el valor inicial de los documentos que Logstash solicitará en la siguiente iteración de su bucle de sondeo. Se puede acceder al valor almacenado en .logstash_jdbc_last_run en la instrucción SELECT como “:sql_last_value”.unix_ts_in_secs: Este es un campo generado por la instrucción SELECT anterior y contiene “modification_time” como una marca de tiempo Unix estándar (segundos desde la época). La “columna de rastreo” de la que acabamos de hablar hace referencia a este campo. Se usa una marca de tiempo Unix para rastrear el progreso en lugar de una marca de tiempo normal, ya que una normal podría causar errores debido a la complejidad de convertir la UMT y la zona horaria local una y otra vez correctamente.sql_last_value: Este es un parámetro integrado que contiene el punto de inicio de la iteración actual del bucle de sondeo de Logstash y al que se hace referencia en la línea de la instrucción SELECT de la configuración de entrada de jdbc anterior. Se establece en el valor más reciente de “unix_ts_in_secs”, que se lee desde .logstash_jdbc_last_run. Se usa como el punto de inicio para que la búsqueda de MySQL que se ejecuta en el bucle de sondeo de Logstash devuelva documentos. Incluir esta variante en la búsqueda garantiza que las inserciones o las actualizaciones que se propagaron en Elasticsearch anteriormente no vuelvan a enviarse a Elasticsearch.schedule: Usa sintaxis cron para especificar la frecuencia con la que Logstash debe sondear MySQL en busca de cambios. La especificación de"*/5 * * * * *"indica a Logstash que contacte a MySQL cada 5 segundos.modification_time < NOW(): Esta porción de la instrucción SELECT es uno de los conceptos más difíciles de explicar y por ello se explicará en detalle en la siguiente sección.filter: En esta sección, simplemente, copiamos el valor de “id” desde el registro de MySQL en un campo de metadatos llamado “_id”, al que haremos referencia más adelante en la salida para garantizar que cada documento se haya escrito en Elasticsearch con el valor “_id” correcto. Usar el campo de metadatos garantiza que este valor temporal no provoque la creación de un campo nuevo. También quitamos los campos “id”, “@version” y “unix_ts_in_secs” del documento, ya que no queremos que se escriban en Elasticsearch.output: En esta sección especificamos que cada documento debe escribirse en Elasticsearch y que se les debe asignar un “_id” extraído del campo de metadatos que creamos en la sección de filtro. También existe una salida de rubydebug convertida en comentario que se puede habilitar para ayudar con la depuración.
Análisis de la exactitud de la instrucción SELECT
En esta sección daremos una descripción de por qué es importante incluir modification_time < NOW() en la instrucción SELECT. Para ayudarnos a explicar este concepto, primero te daremos algunos contraejemplos que demuestran por qué los dos enfoques más intuitivos no funcionarán correctamente. Después seguiremos con una explicación sobre cómo se pueden superar los problemas con los enfoques intuitivos incluyendo modification_time < NOW().
Situación intuitiva uno
En esta sección te mostraremos qué sucede si la cláusula WHERE no incluye modification_time < NOW() y en su lugar solo especifica UNIX_TIMESTAMP(modification_time) > :sql_last_value. En este caso, la instrucción SELECT se vería de la siguiente manera:
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value) ORDER BY modification_time ASC"
A primera vista, el enfoque anterior debería funcionar correctamente, pero existen casos extremos en donde podría omitir algunos documentos. Por ejemplo, consideremos un caso donde MySQL inserta 2 documentos por segundo y donde Logstash ejecuta la instrucción SELECT cada 5 segundos. Esto se demuestra en el diagrama siguiente, donde cada segundo es representado por T0 a T10 y los registros de MySQL, de R1 a R22. Asumimos que la primera iteración del bucle de sondeo de Logstash ocurre en T5 y lee documentos de R1 a R11, como lo representan los cuadros color cian. El valor almacenado en sql_last_value ahora es T5 porque esta es la marca de tiempo del último registro (R11) que se leyó. También asumimos que justo después de que Logstash leyó los documentos desde MySQL, otro documento R12 se insertó en MySQL con una marca de tiempo de T5.
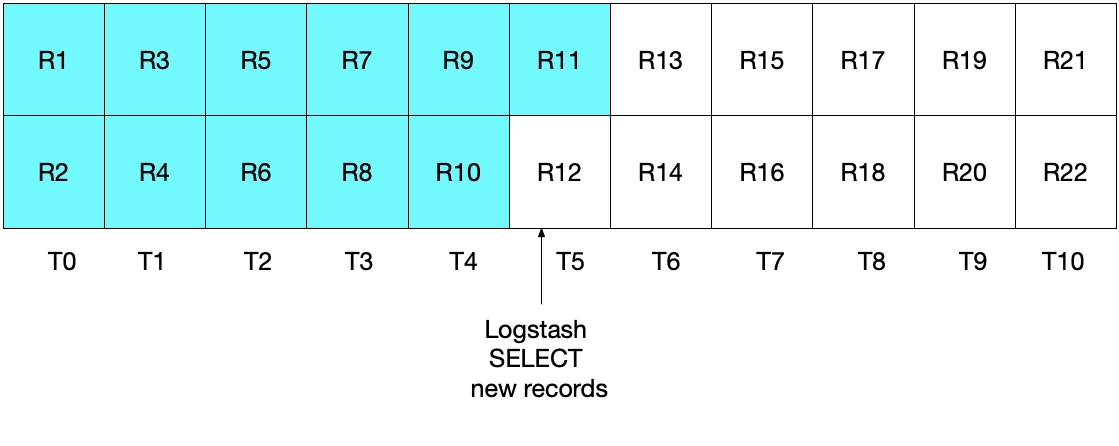
En la siguiente iteración de la instrucción SELECT anterior, solo quitamos los documentos en los que el tiempo es WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value)), lo que significa que se omitirá el registro R12. Esto se muestra en el diagrama que aparece a continuación, donde los cuadros de color cian representan los registros que Logstash lee en la iteración actual y los cuadros grises representan los registros que Logstash leyó anteriormente.
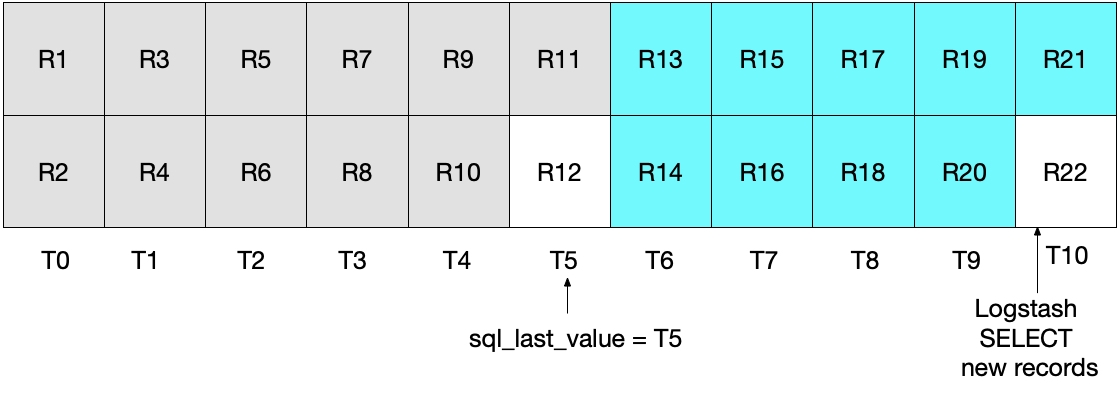
Ten en cuenta que el registro R12 no se escribirá nunca en Elasticsearch con la instrucción SELECT de esta situación.
Situación intuitiva dos
Para resolver el problema anterior, uno puede decidirse a cambiar la cláusula WHERE a
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) >= :sql_last_value) ORDER BY modification_time ASC"
Sin embargo, esta implementación tampoco es ideal. En este caso, el problema radica en que la mayoría de los documentos leídos desde MySQL en el intervalo de tiempo más reciente volverán a enviarse a Elasticsearch. Si bien esto no provoca ningún problema con respecto a la exactitud de los resultados, sí crea trabajo innecesario. Como en la sección anterior, después de la iteración de sondeo inicial de Logstash, el diagrama que aparece a continuación muestra cuáles son los documentos que se leyeron desde MySQL.
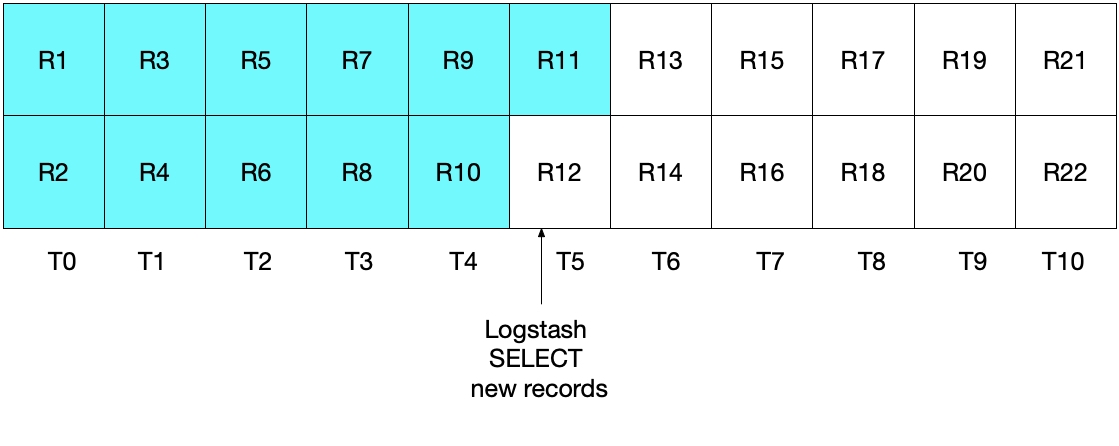
Cuando ejecutamos la iteración de sondeo subsecuente de Logstash, extraemos todos los documentos en los que el tiempo es mayor
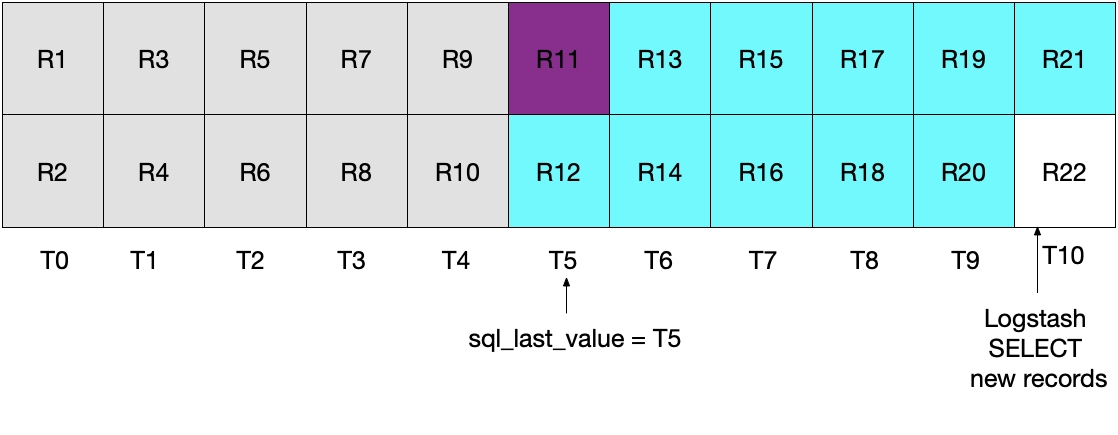
Ninguna de las dos situaciones anteriores es ideal. En la primera situación se pueden perder datos y en la segunda, los datos redundantes se leen desde MySQL y se envían a Elasticsearch.
Cómo corregir los enfoques intuitivos
Dado que ninguna de las dos situaciones anteriores es ideal, se debe emplear un enfoque alternativo. Al especificar (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()), enviamos cada documento a Elasticsearch exactamente una vez.
Esto se demuestra en el siguiente diagrama, donde el sondeo actual de Logstash se ejecuta en T5. Ten en cuenta que como se debe cumplir modification_time < NOW(), solo los documentos hasta (aunque sin incluir) aquellos en el período T5 serán leídos desde MySQL. Dado que recuperamos todos los documentos de T4 y ninguno de T5, sabemos que sql_last_value se establecerá en T4 para la siguiente iteración de sondeo de Logstash.
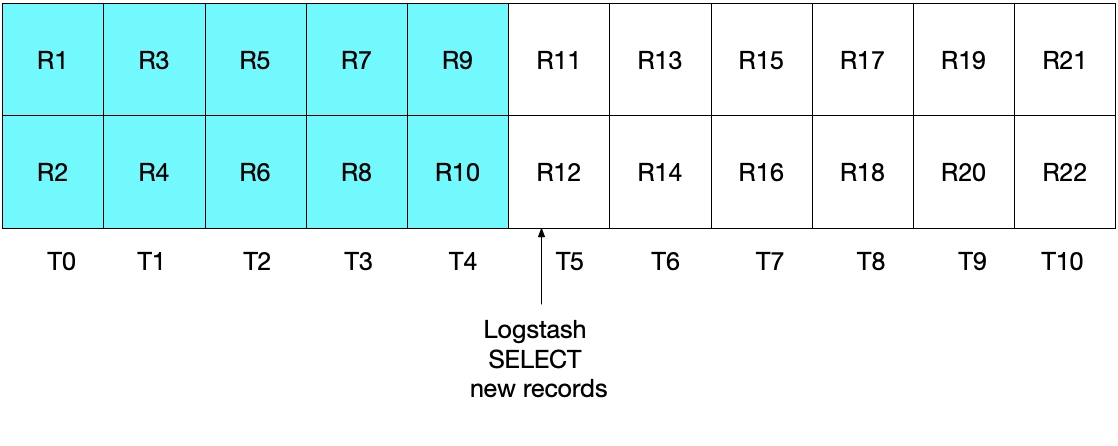
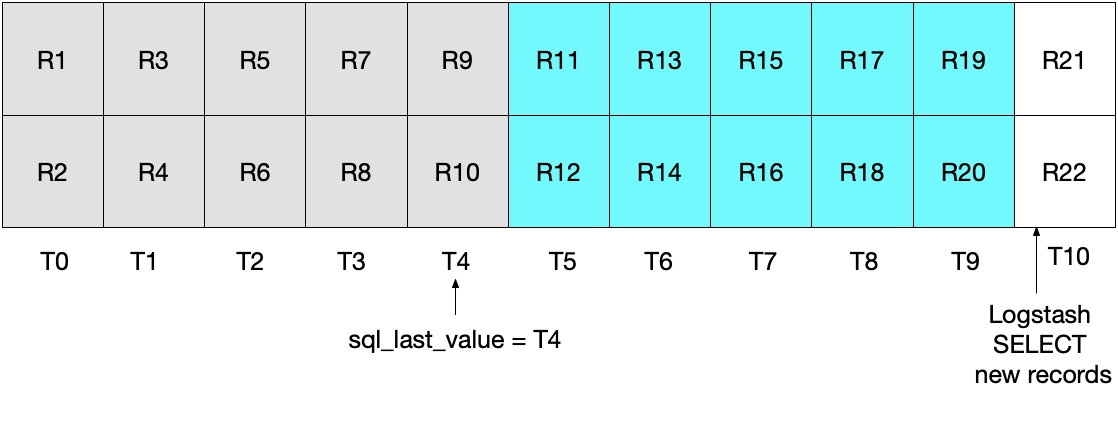
El diagrama que aparece a continuación demuestra lo que ocurrirá en la siguiente iteración del sondeo de Logstash. Como UNIX_TIMESTAMP(modification_time) > :sql_last_value y porque sql_last_value se establece en T4, sabemos que solo se recuperarán los documentos que comienzan a partir de T5. Además, como solo se recuperarán los documentos que cumplan modification_time < NOW(), solo se recuperarán hasta el T9, incluido este. Nuevamente, significa que se recuperaron todos los documentos en T9 y que sql_last_value se establecerá en T9 para la próxima iteración. Por ende, este enfoque elimina el riesgo de recuperar solo un subconjunto de los documentos de MySQL de cualquier intervalo de tiempo dado.
Prueba del sistema
Se pueden usar pruebas simples para demostrar que nuestra implementación se desempeña según lo deseado. Podemos escribir registros en MySQL de la siguiente forma:
INSERT INTO es_table (id, client_name) VALUES (1, 'Jim Carrey'); INSERT INTO es_table (id, client_name) VALUES (2, 'Mike Myers'); INSERT INTO es_table (id, client_name) VALUES (3, 'Bryan Adams');
Una vez que la programación de entrada de JDBC ha activado los registros de lectura de MySQL y los ha escrito en Elasticsearch, podemos ejecutar la siguiente búsqueda de Elasticsearch para ver los documentos de Elasticsearch:
GET rdbms_sync_idx/_search
que devuelve algo similar a la siguiente respuesta:
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"insertion_time" : "2019-06-18T12:58:56.000Z",
"@timestamp" : "2019-06-18T13:04:27.436Z",
"modification_time" : "2019-06-18T12:58:56.000Z",
"client_name" : "Jim Carrey"
}
},
Etc …
Entonces podemos actualizar el documento que corresponde con _id=1 en MySQL de la siguiente forma:
UPDATE es_table SET client_name = 'Jimbo Kerry' WHERE id=1;
que actualiza adecuadamente el documento identificado por _id de 1. Podemos mirar directamente al documento en Elasticsearch ejecutando lo siguiente:
GET rdbms_sync_idx/_doc/1
lo que devuelve un documento que se ve así:
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"insertion_time" : "2019-06-18T12:58:56.000Z",
"@timestamp" : "2019-06-18T13:09:30.300Z",
"modification_time" : "2019-06-18T13:09:28.000Z",
"client_name" : "Jimbo Kerry"
}
}
Observa que la _version ahora se estableció en 2, que modification_time ahora es diferente de insertion_time y que el campo client_name se actualizó correctamente al valor nuevo. El campo @timestamp no es particularmente interesante para este ejemplo y Logstash lo agrega de forma predefinida.
Se puede hacer un upsert en MySQL de la siguiente forma y el lector de este blog puede asegurarse de que la información correcta se vea reflejada en Elasticsearch:
INSERT INTO es_table (id, client_name) VALUES (4, 'Bob is new') ON DUPLICATE KEY UPDATE client_name='Bob exists already';
¿Qué hay sobre los documentos eliminados?
El lector astuto habrá notado que si se elimina un documento de MySQL, esta eliminación no se propagará en Elasticsearch. Se pueden considerar los siguientes enfoques para abordar este problema:
- Los registros de MySQL pueden incluir un campo "is_deleted", que indica que ya no son válidos. Esto se conoce como "eliminación parcial". En cuanto a cualquier otra actualización a un registro de MySQL, el campo "is_deleted" se propagará en Elasticsearch a través de Logstash. Si se implementa este enfoque, las búsquedas de Elasticsearch y MySQL necesitarán escribirse para excluir los registros/documentos donde "is_deleted" es verdadero. Eventualmente, los trabajos en segundo plano pueden quitar dichos documentos de MySQL y Elastic.
- Otra alternativa es asegurarse de que cualquier sistema responsable por la eliminación de registros en MySQL también deba ejecutar posteriormente un comando para eliminar directamente los documentos correspondientes de Elasticsearch.
Conclusión
En este blog mostramos cómo se puede usar Logstash para sincronizar Elasticsearch con una base de datos relacional. El código y los métodos que presentamos aquí se probaron con MySQL, pero en teoría deberían funcionar con cualquier RDBMS.
Si tienes alguna duda sobre Logstash o cualquier otro tema relacionado con Elasticsearch, echa un vistazo a nuestros foros de debate para acceder a debates, conocimientos e información valiosos. No te olvides además de probar nuestro Elasticsearch Service, la única oferta hospedada de Elasticsearch y Kibana desarrollada por los creadores de Elasticsearch.