Elasticsearch 7.9.0 released
We are pleased to announce the release of Elasticsearch 7.9.0, based on Lucene 8.6.0. Version 7.9 is the latest stable release of Elasticsearch and is now available for deployment via Elasticsearch Service on Elastic Cloud or via download for use in your own environment(s).
If you're ready to roll up your sleeves and get started, we have the links you need:
- Start Elasticsearch on Elastic Cloud
- Download Elasticsearch
- Elasticsearch 7.9.0 release notes
- Elasticsearch 7.9.0 breaking changes
With today’s release, our Elastic Enterprise Search, Elastic Observability, and Elastic Security solutions also received significant updates. To learn more about these updates, you might consider giving our main Elastic 7.9 release blog a read.
It all starts with ingest
Elasticsearch is a data store, search engine, and analytics platform — all in one. As the heart of the Elastic Stack, it powers everything from Elastic Workplace Search to infrastructure monitoring and endpoint security. Its ability to efficiently transform data into insights and questions into answers is, perhaps, second to none.
However, none of this is possible without (drum roll): ingest. Ingest is, quite simply, the process of getting your data into Elasticsearch. Over the years, Elastic has steadily improved how ingest is accomplished. With the release of Elasticsearch 7.9, we’re taking another significant step forward.
Simplifying ingest with data streams
Data streams are a new concept for ingesting (and managing) time series data. They’re designed to give you the simplicity of a single named resource with the storage, scalability, and cost-saving benefits of having multiple indices.
Time series data tends to grow over time. And while it might be easier to store and manage this data via a single index, it’s often more efficient and cost-effective to store large volumes of time series data across multiple, time-based indices. Multiple indices enable you to move indices containing older, less frequently queried data to less expensive hardware and delete indices when they’re no longer needed, reducing overhead and storage costs.
Here’s how data streams work. You can now submit indexing and search requests directly to a data stream instead of a specific index (or specific index + alias). The stream automatically routes the requests to a collection of hidden backing indices that store the stream’s data.
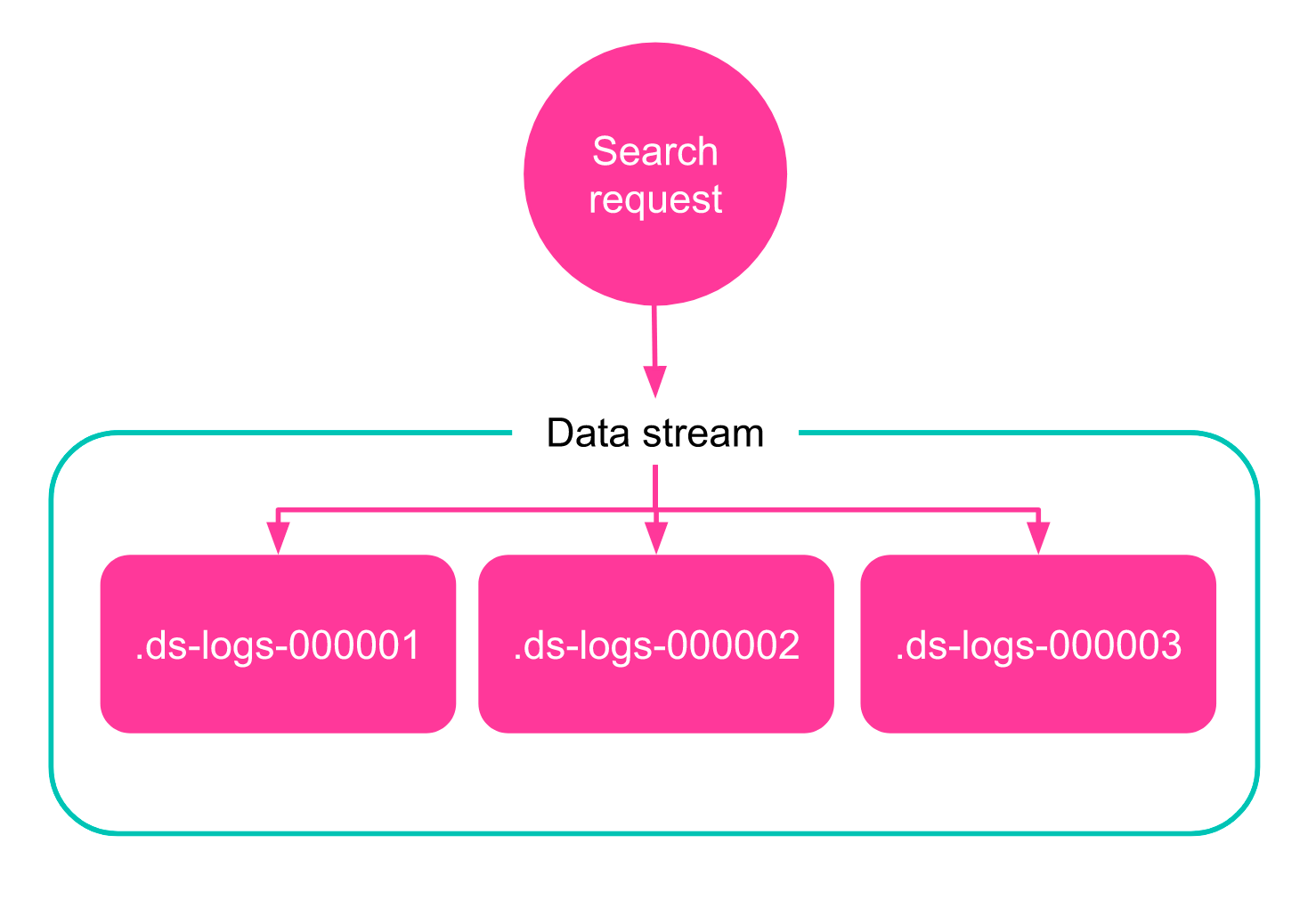
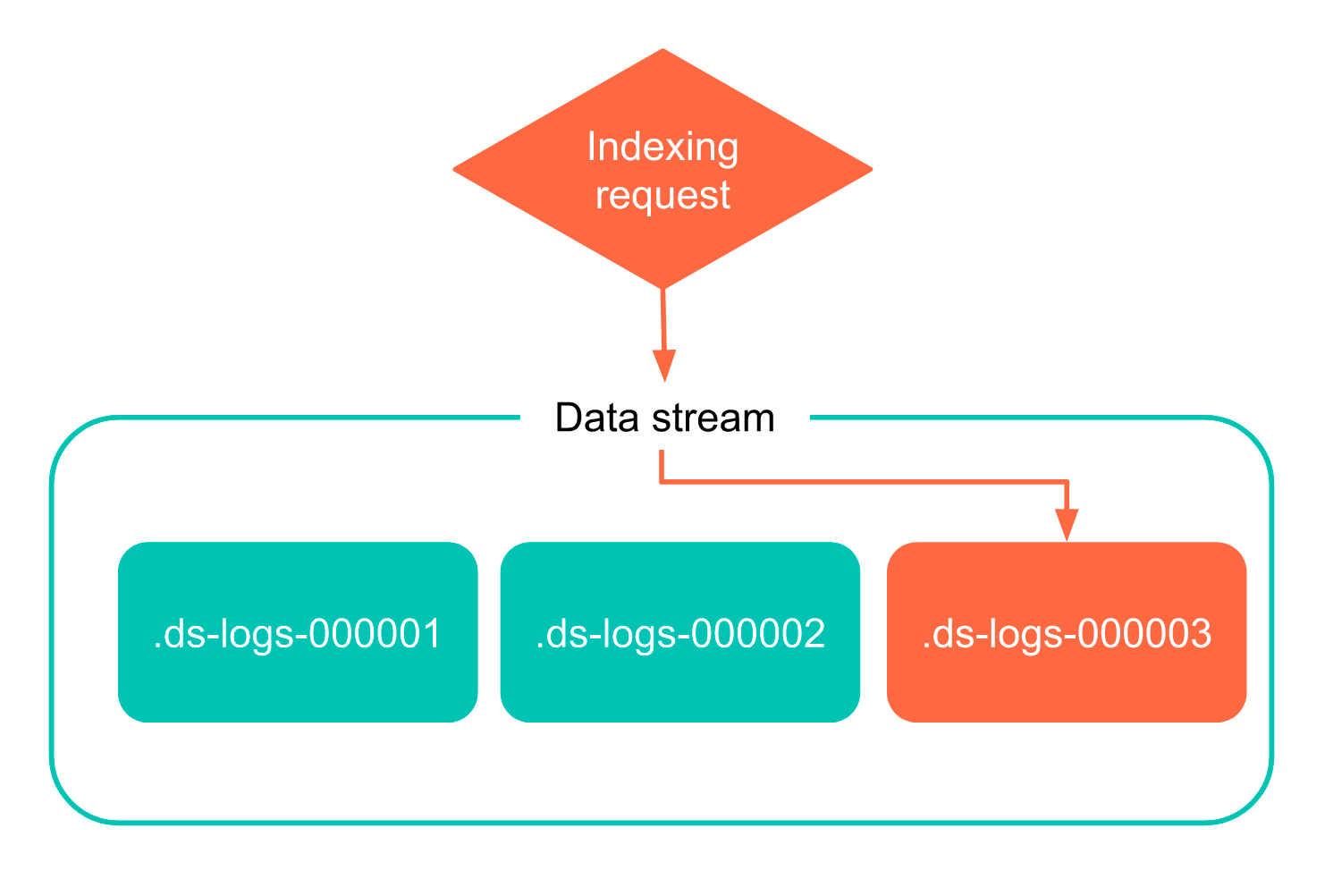
A search request using data streams and an indexing request using data streams.
Data streams abstract away — and simplify — some of the complexity that comes with having to manage numerous time series indices, making features like index lifecycle management (ILM) a breeze to configure and simple to maintain.
Dialing ingest to 11
With the introduction of Elastic Agent and its support for endpoint security, it’s easy to imagine a world where tens of thousands of endpoints come online at the same time — creating a tidal wave of data for Elasticsearch to ingest. We’re continually pushing Elasticsearch to ingest data as quickly as possible, whether it’s from a single client or tens of thousands of clients.
Starting in Elasticsearch 7.9, we’ve increased Elasticsearch ingestion throughout by removing the fixed ingestion queue of 200 documents and replacing it with a new flexible memory-based queue. Through our internal testing, we’ve been able to drastically improve ingestion throughput in Elasticsearch with this new ingestion subsystem, especially when there are large numbers of clients writing data to Elasticsearch.
At each stage of the indexing process (coordinating, primary, and replication), the new ingestion subsystem accounts for the number of bytes associated with an operation and rejects requests if a byte-based limit is exceeded (10% of heap memory by default). This feature is enabled by default in Elasticsearch 7.9, and detailed indexing information is exposed via the node stats API (see the ‘indexing_pressure’ sections).
Ingest and enrich
Way back in October 2019, with the release of Elasticsearch 7.4, we added the shape data type, enabling you to define your own spatial coordinate system. With 7.5 we added the enrich processor. And, more recently, with Elasticsearch 7.8 we introduced an ingest node pipeline builder into Kibana — a handy user interface that makes it easy for you to configure custom ingest pipelines.
How do these three things relate?
Well, with the release of Elasticsearch 7.9 we’ve made the process of data ingest and enrichment even better with the introduction of a (new) tree view and support for enrichment when using the shape data type.
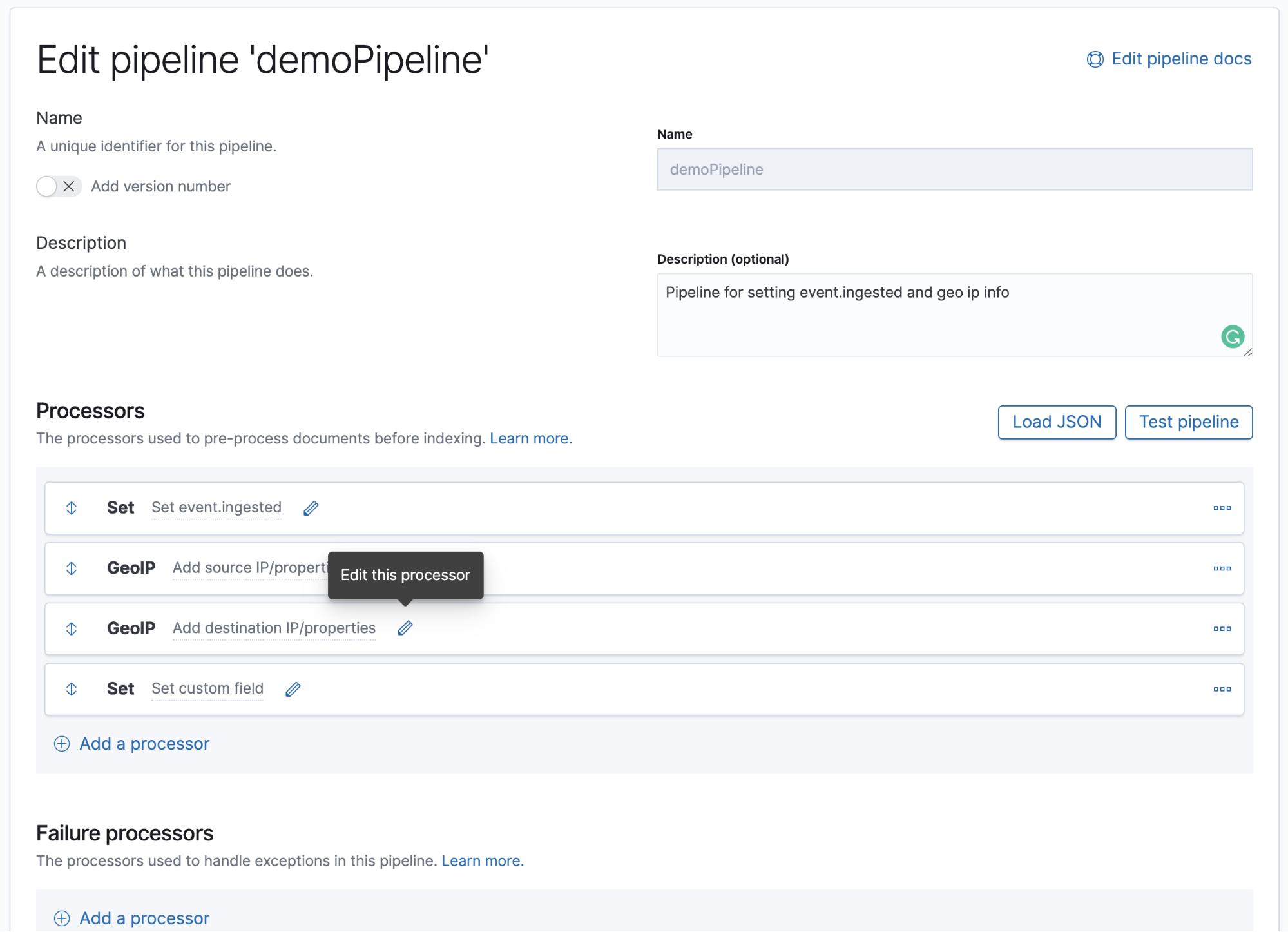
Experimenting with ingest node pipeline builder’s new tree view
Smarter solutions with smarter search
Whether you’re using Elasticsearch to prevent fraud or to transform logging data into operational insights, the following new features and enhancements will help you put your data to work.
Find relevant results faster with wildcard fields
Sometimes you only know half of what you’re searching for (think: *.pdf or *.exe). Especially in observability and security use cases, the wildcard operator delivers more powerful searches. Using the wildcard operator when searching logs, however, can often be problematic.
Why is this? Well, logs are most often stored as strings within Elasticsearch. And until now, strings could be stored in Elasticsearch as either “text” or “keywords.” Borrowing from our recent blog on how to find strings within strings faster with the new wildcard field:
Text fields “tokenize” strings into multiple tokens, each typically representing words. Users looking for quick foxes can therefore match articles talking about a quick brown fox.
Keyword fields tend to be used for shorter, structured content like a country code which would be indexed without analysis as a single token. These can then be used by analysts to, for example, visualize popular holiday destinations using aggregations.
Without an explicit mapping choice by users, Elasticsearch’s default index template assumes that string values presented in JSON documents should be indexed as both a text field and a keyword field. The intention is that Elasticsearch should work if the string represents prose that should be chopped into multiple word tokens for search or if it represents a single structured value (like the city name “New York”) that should be displayed as one item when displayed in a “top travel destinations” bar chart.
Keeping this in mind, the limitations to finding things within log files soon becomes apparent. When storing log files as text, unlike English text such as “quick brown fox,” we have no clue where words begin or end in typical log messages. This makes it very difficult to construct effective queries, even for experienced users. On the other end of the spectrum, when storing log messages as a single keyword, searches for substrings can be particularly slow and the field itself is limited to a default of 256 characters (and only 32K should you attempt to adjust the default value).
Enter the wildcard data type.
This new data type makes searching for partial strings much more efficient. Using a combination of an n-gram index and some new structures that we introduced into Lucene, we can offer faster regexp and wildcard queries over compressed data.
Designed to dramatically reduce the time it takes to find what you’re searching for when using regular expressions or the wildcard operator, we anticipate the wildcard data type will be especially useful for security analysts using our SIEM offering as they hunt for threats.
Introducing Event Query Language (EQL) in Elasticsearch
At Elastic, we've had requests for many years to introduce a correlation query language to support threat hunting and threat detection use cases. When we joined forces with Endgame late last year, we adopted their Event Query Language (EQL) — a powerful, battle-tested language designed for this exact purpose. It has been running efficiently on endpoints blocking threats in Endgame solutions for years.
In 7.9, we're excited to release our first public preview of EQL, an experimental feature, as a first-class query language in Elasticsearch. We're releasing it today as an API in Elasticsearch, and we have plans to incorporate a robust UI for EQL in Elastic Security and Kibana in the future. Here’s an example of what EQL can do for you:
GET /sec_logs/_eql/search
{
"query": """
sequence by process.pid with maxspan=1h
[ process where process.name == "regsvr32.exe" ]
[ file where stringContains(file.name, "scrobj.dll") ]
until [ process where event.type == "termination" ]
"""
}
This EQL query finds any processes that ran regsvr32.exe and later loaded a file named scrobj.dll within the same hour.
We'd love your feedback and welcome your creativity, because while EQL was designed for security, we expect it will open many new ways to use Elasticsearch.
Unleash even more aggregations on your data
For those who might be new to Elasticsearch: Elasticsearch aggregations enable you to easily extract metadata from your search results and, as a core part of the Elastic Stack’s foundational infrastructure, add value to each of our solutions.
With the release of Elasticsearch 7.9, we’ve added four new aggregations to the party. These new aggregations are particularly well-suited for security and observability use cases.
Variable width histogram
Sometimes the easiest way to present data in a histogram diagram is to define the number of buckets, and have their boundaries defined by the data distribution. To that end we worked with James Dorfman (a community member) to merge his contribution to the Elasticsearch code base. At the heart of the variable width histogram lies a clustering algorithm, which merges values into shard local clusters of buckets and then performs hierarchical agglomerative clustering on the coordinating node to reduce the shard local results to a single histogram. Put simply, this new aggregation allows for dynamic clustering of the data with a single pass.
Histogram aggregation on histogram data type
In 7.8 we introduced the sum, value_count, and avg aggregations for the histogram data type. Histograms and aggregations on histograms are super useful for APM. And sometimes users are interested in running a histogram aggregation across a histogram field (i.e., representing the histogram values from multiple documents in a single histogram). To this end, with the release of Elasticsearch 7.9, we have enabled running a histogram aggregation on histogram data type.
Normalize aggregation
Also new with 7.9 — the normalize aggregation. The normalize aggregation provides six methods for normalizing numeric data, enabling you to more easily rescale your data. For example, you may want all the data to be within [0,1] for presentation purposes, while retaining the sorting order and relative distance to the minimum and maximum, and the rescale_0_1 method would provide that using the formula x' = (x - xmin) / (xmax - xmin). Note that the new normalize aggregation is a parent pipeline aggregation (i.e., it was designed to take the output of another aggregation as its input and thren normalize it).
Moving percentiles aggregation
In recent releases we made quite a few enhancements geared towards easier analysis of time series data, which is useful for a lot of our customers that use Elasticsearch for security and observability. In 7.9 we are adding the moving percentiles aggregation, which allows you to calculate cumulative percentiles by sliding a window over a sorted series of percentiles. This aggregation is very similar to the moving function aggregation, but is performed over percentiles.
Additional optimizations and enhancements
Last, but (certainly) not least, in aggregation news: we’ve made several improvements to aggregation performance and memory consumption. We’ve also refined the way we monitor the memory an aggregation consumes during operation. Beyond the obvious speed and resource consumption benefits, this also allowed us to increase the search.max_buckets limit default from 10,000 to 65,535. The result is that this “soft threshold” will very rarely be activated, and while one may be excused for thinking this is just a default, it was a default that was changeable only by Elasticsearch admins and frequently remained set to 10,000 because it was a required protection. This is an important scalability improvement to all aggregations that rely on buckets (which, in practice, means the vast majority of aggregations in the real world).
Machine Learning
As a part of closing the loop on an end-to-end machine learning pipeline within Elasticsearch we introduced a new inference processor that enabled you to make predictions using your regression or classification models in an ingest pipeline. Now, with the release of Elasticsearch 7.9, inference is even more flexible!
Starting today, you can now reference a pre-trained data frame analytics model in pipeline aggregations (to infer on the result field of the parent bucket aggregation) with the inference bucket aggregation. This new aggregation uses a model on aggregation results to provide a prediction and enables you to run classification or regression analysis at search time. Put simply, if you want to perform analysis on a small set of data, you can now generate predictions with the inference bucket aggregation without having to set up a processor in the ingest pipeline.
Meet the Tableau Connector
Finally, let’s talk about Tableau. Before today, data stored in Elasticsearch was not directly available to Tableau users. In order for this data to be incorporated into existing Tableau assets, it had to first be replicated to a relational database (such as MySQL or SQL Server).
We’re pleased to announce that this indirect process has officially gone the way of the dinosaurs. We’re introducing the Tableau Connector for Elasticsearch. The Tableau Connector provides direct, real-time access to Elasticsearch data from Tableau Server and Tableau Desktop. It eliminates the need for expensive and error-prone ETL and enables Tableau users to gain insight and value from data stored in Elasticsearch. For more information on how to get started check out our downloads page.
That's not all, folks...
There are many more new features included in Elasticsearch 7.9: All snapshot ‘create’ and ‘delete’ operations can now be executed concurrently, and ILM is able to wait for a snapshot to complete before, for example, deleting an index. Be sure to check out the release highlights and the release notes for additional information.
Ready to get your hands dirty? Spin up a 14-day free trial of Elastic Cloud or download Elasticsearch today. Try it out. And be sure to let us know what you think on Twitter (@elastic) or in our forum.