Jina AI와 Elastic은 jina-embeddings-v5-text라는 새로운 고성능 간결한 텍스트 임베딩 모델 계열을 출시합니다. 이 모델은 모든 주요 작업 유형에서 비슷한 크기의 모델에 최첨단 성능을 자랑합니다.
이 제품군에는 두 가지 모델이 포함되어 있습니다:
jina-embeddings-v5-text-smalljina-embeddings-v5-text-nano
이러한 모델은 임베딩 모델을 위한 혁신적인 새로운 훈련 방식의 성공적인 결과입니다. 두 모델 모두 크기가 몇 배나 큰 모델보다 성능이 뛰어나 메모리와 컴퓨팅 리소스를 절약하고 요청에 더 빠르게 응답합니다.
jina-embeddings-v5-text-small 모델은 6억 7,700만개의 매개변수를 가지고 있으며, 32,768개의 토큰 입력 컨텍스트 창을 지원하고 기본적으로 1,024차원 임베딩을 생성합니다.
jina-embeddings-v5-text-nano 무게는 형제 제품의 크기의 대략 3분의 1로, 2억 3,900만 개의 매개변수와 8,192개의 토큰의 입력 컨텍스트 창을 가지며, 768차원의 간결한 임베딩을 제공합니다.
| 모델 이름 | 전체 크기 | 입력 컨텍스트 창 크기 | 임베딩 크기 |
|---|---|---|---|
| jina-v5-text-small | 677M 매개변수 | 32,768개 토큰 | 1,024차원 |
| jina-v5-text-nano | 239M 매개변수 | 8192개의 토큰 | 768차원 |
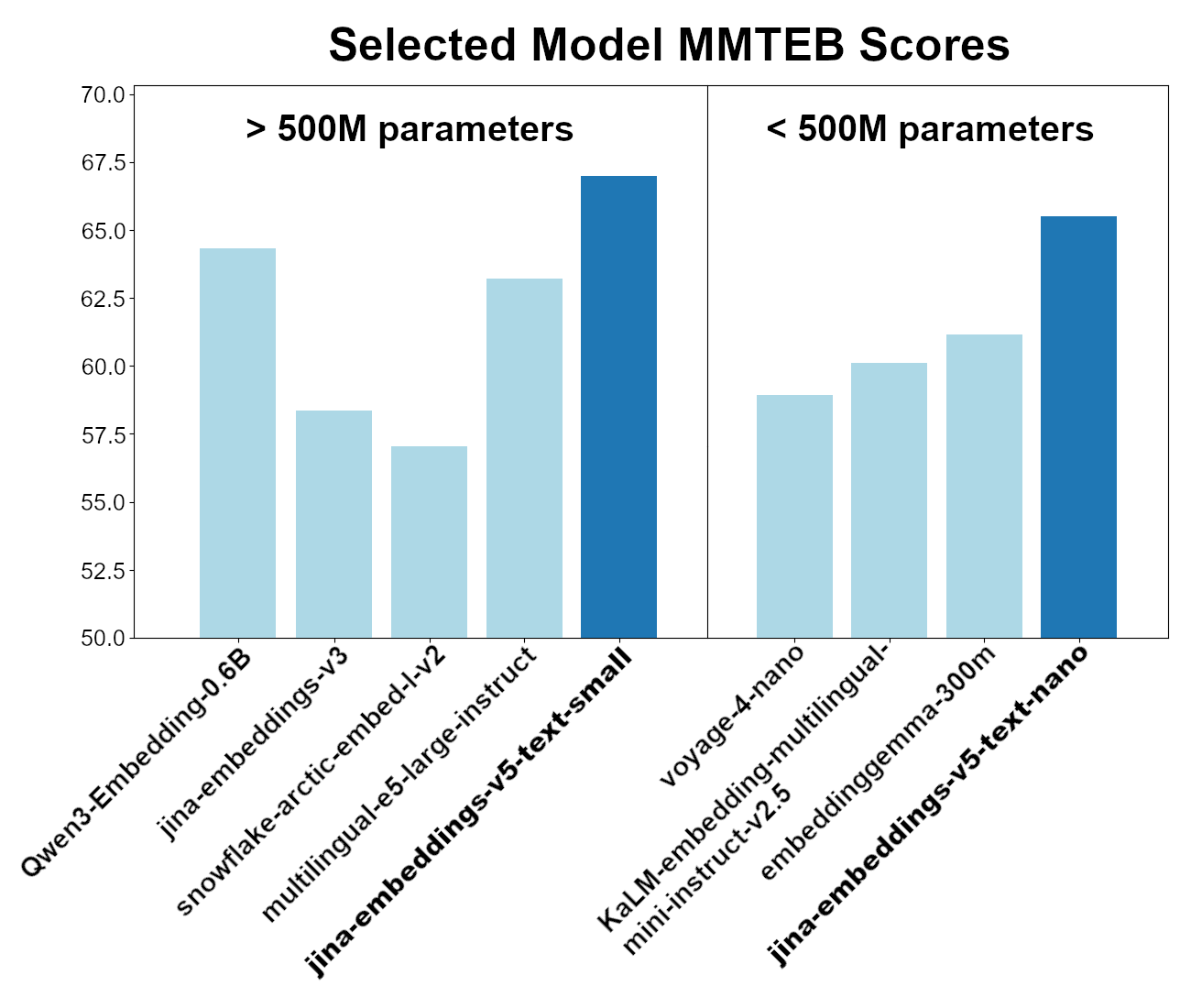
이 두 모델은 전체 MMTEB(다국어 MTEB) 벤치마크 성능에서 동급 최고 수준입니다. 5억 개 미만의 매개변수를 가진 모델 중, jina-embeddings-v5-text-nano는 2억 5,000만 개 미만의 매개변수를 가지고 있음에도 불구하고 최고 성능을 보이며, jina-embeddings-v5-text-small 모델은 7억 5,000만 개 미만의 매개변수를 가진 다국어 임베딩 모델 중 선두에 있습니다.
이러한 모델은 Elastic Inference Service(EIS), 온라인 API를 통해 사용할 수 있으며 로컬 호스팅도 가능합니다. jina-embeddings-v5-text 모델에 액세스하는 방법에 대한 지침은 아래의 '시작하기' 섹션을 참조하세요.
임베딩 모델과 의미 색인화는 검색 알고리즘의 정확도를 획기적으로 향상시킬 뿐만 아니라 의미 유사성 및 의미 추출과 관련된 다양한 작업에도 활용될 수 있습니다. 예를 들면 다음과 같습니다.
- 중복된 텍스트 찾기.
- 의역 및 번역 인식하기.
- 주제 발견.
- 추천 엔진.
- 감정 및 의도 분석.
- 스팸 필터링.
- 그 밖에도 여러 가지가 있습니다.
기능
이 새로운 모델 제품군은 관련성을 높이고 비용을 절감하도록 설계된 여러 기능을 갖추고 있습니다.
작업 최적화
jina-embeddings-v5-text 모델을 네 가지 작업 유형에 맞게 최적화했습니다.
| 작업 | 예시 사용 사례 |
|---|---|
| 검색 | 자연어 쿼리를 사용하여 문서 모음에서 가장 관련성이 높은 결과 검색하기. |
| 텍스트 일치 | 의미적 유사성, 중복 제거, 의미 변환 및 번역 정렬 등 |
| 클러스터링 | 주제 검색, 문서 컬렉션의 자동 정리. |
| 분류 | 문서 분류, 감정 및 의도 감지, 유사 작업. |
한 작업에 최적화하는 것은 일반적으로 다른 작업에서 타협을 의미하므로 대부분의 임베딩 모델은 한 종류의 작업에 대해서만 경쟁력 있는 성능을 가집니다. 하지만 jina-embeddings-v5-text 모델은 작업별 로우랭크 적응(LoRA) 어댑터를 훈련하여 타협 없이 네 가지 영역 모두에 전문성을 갖출 수 있습니다.
LoRA 어댑터는 AI 모델의 동작을 극적으로 변화시키면서도 전체 크기는 약간만 늘리는 일종의 플러그인입니다. 각 작업마다 수억 개의 매개변수가 있는 전체 모델을 사용하는 대신 jina-embeddings-v5-text 모델 제품군을 사용하면 각 작업마다 컴팩트한 LoRA 어댑터가 포함된 하나의 모델만 사용할 수 있습니다. 이렇게 하면 메모리, 저장 공간, 추론 비용을 절약할 수 있습니다.
임베딩 잘라내기
최소한의 비용으로 임베딩의 품질을 유지하면서 더 작은 크기로 줄일 수 있는 Matryoshka 표현 학습을 사용하여 jina-embeddings-v5-text 모델을 훈련시켰습니다.
기본적으로 jina-embeddings-v5-text-small은 1024차원 임베딩 벡터를 생성하며, 각 벡터는 16비트 숫자로 표현되어 각 임베딩 크기가 2KB입니다. 대규모 문서 컬렉션의 경우 저장해야 할 데이터가 많을 수 있으며, 임베딩으로 가득 찬 벡터 데이터베이스에서 검색하는 것은 데이터베이스의 크기와 저장된 각 벡터의 차원 수 모두에 비례합니다.
하지만 임베딩의 크기를 절반으로 줄이면(1024차원 중 512차원을 버리면) 공간을 절반으로 줄이면서 검색 속도를 두 배로 높일 수 있습니다. 이는 성능에 영향을 미칩니다. 정보를 버리면 정밀도가 떨어집니다. 그러나 아래의 그래프가 보여주듯이, 임베딩의 절반을 제거하더라도 성능은 약간만 저하됩니다.
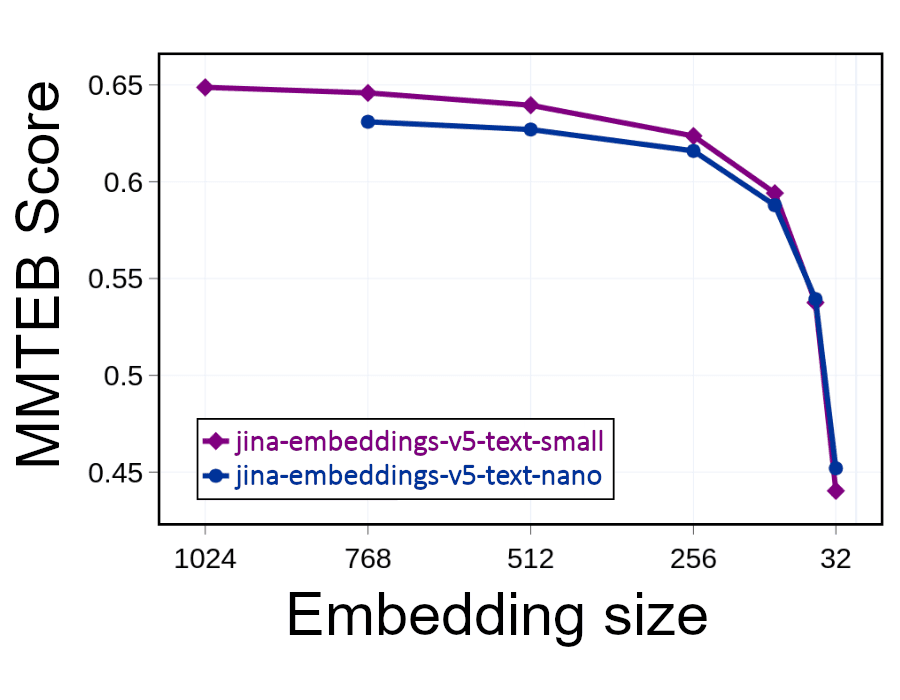
임베딩이 최소 256차원을 가지는 한, 정밀도 손실은 상당히 작게 유지되어야 합니다. 그러나 이 수준 이하에서는 관련성과 정확도가 빠르게 저하됩니다.
이처럼 임베딩을 잘라내는 방식을 통해 사용자는 정확도와 컴퓨팅 비용 간의 균형을 스스로 관리할 수 있습니다. 이 솔루션은 검색 AI를 통해 효율성을 크게 향상시키고 비용을 대폭 절감할 수 있는 도구를 제공합니다.
강력한 양자화
양자화는 임베딩의 크기를 줄이는 또 다른 방법입니다. 양자화는 각 임베딩의 일부를 버리는 대신 임베딩에 포함된 숫자의 정밀도를 낮춥니다. jina-embeddings-v5-text 모델은 16비트 숫자로 임베딩을 생성하지만, 이 숫자를 반올림하여 정밀도와 저장에 필요한 비트 수를 줄일 수 있습니다. 가장 극단적인 경우, 각 숫자를 1비트(0 또는 1)로 줄여 jina-embeddings-v5-text의 기본 1024차원 임베딩을 2킬로바이트에서 128바이트로 압축할 수 있으며, 이는 이진 양자화만으로 94% 줄어든 것입니다. 잘라내기와 마찬가지로 메모리 및 컴퓨팅 비용을 크게 절감할 수 있습니다. 하지만 잘라내기와 마찬가지로 양자화는 임베딩의 정확도를 떨어뜨립니다.
정확도 손실을 최소화하여 Elasticsearch의 더 나은 이진 양자화(BBQ) 기능을 사용하도록 jina-embeddings-v5-text 모델을 훈련시켰으며, 이러한 모델의 이진화된 임베딩에 대한 벤치마크 테스트 결과 이진화되지 않은 임베딩과 거의 동일한 성능을 보여주었습니다. 이진화 성능에 대한 자세한 제거 연구는 기술 보고서를 참조하세요.
다국어 성능
많은 임베딩 모델은 다양한 언어가 포함된 자료에 대한 훈련을 거쳤기 때문에 다국어를 지원합니다. 하지만 그렇다고 해서 모든 지원 언어에서 모두 똑같이 잘 작동하는 것은 아닙니다.
MMTEB 다국어 벤치마크에서 211개 언어를 식별하고 이를 분리하여 언어별로 유사한 모델과 비교할 수 있도록 했습니다. 아래 이미지는 히트맵 형태로 결과를 요약한 것입니다. 각 패치는 언어(ISO-639 코드로 식별)이며, 초록색이 짙을수록 유사한 모델의 평균에 비해 더 나은 성능을 발휘하는 모델입니다.

언어마다 정확도는 다르지만 jina-embeddings-v5-text 모델은 전 세계 대부분의 언어에서 최첨단 또는 그에 가까운 정확도를 제공합니다.
다국어 성능에 대한 자세한 내용은 jina-embeddings-v5-text 기술 보고서를 참조하세요.
Elastic의 Jina: 검색을 위한 최첨단 네이티브 AI
EIS의 jina-embeddings-v5-text 모델을 사용하면 프로비저닝이나 확장을 위한 인프라 없이 완전 관리형 GPU 가속 추론을 통해 고성능 다국어 임베딩 모델을 Elasticsearch에서 기본적으로 실행할 수 있습니다. jina-embeddings-v5-text 모델은 최신 AI 개발로 구동되는 컴팩트한 다국어 모델로 성장하는 EIS 모델 카탈로그를 확장합니다. 이러한 모델은 정보 검색 및 표준 데이터 분석 벤치마크에서 최첨단 성능을 제공하며, 비교할 수 없는 전 세계적인 다국어 지원을 제공합니다.
크기가 크게 다른 두 가지 모델이 있으므로 사용자는 용도와 예산에 가장 적합한 모델을 선택할 수 있습니다. 또한, 더 작은 크기로 잘라내거나 더 낮은 정밀도로 정량화해도 성능이 유지되는 강력한 임베딩을 통해 jina-embeddings-v5-text 모델은 저장 공간 및 컴퓨팅 비용, 처리 지연 시간을 더욱 구체적으로 절감할 수 있는 기회를 제공합니다.
jina-embeddings-v5-text 제품군, Jina Reranker, Elastic의 빠른 벡터 및 BM25 검색을 통해 사용자는 이제 Elastic의 엔드투엔드 최신 하이브리드 검색에 액세스할 수 있습니다. Retrieval-Augmented Generation(RAG) 파이프라인, 검색 애플리케이션, 데이터 분석 등 가장 연관성이 높은 결과가 필요한 경우, Jina 검색 AI 모델이 포함된 Elastic은 견고하고 비용 효율적인 품질을 제공합니다.
시작하기
jina-embeddings-v5-text 모델은 EIS에 완전히 통합되어 있으며, 색인 생성 시 type 필드를 semantic_text로 설정하고 inference_id 필드에 모델(jina-embeddings-v5-text-small 또는 jina-embeddings-v5-text-nano)을 지정하면 이 예시에서와 같이 사용할 수 있습니다.
Elasticsearch는 색인 및 검색 과정에서 적절한 LoRA 어댑터를 자동으로 선택합니다. 임베딩 차원(위의 "임베딩 잘라내기" 섹션 참조)은 사용자 지정 추론 엔드포인트를 생성할 때 설정할 수 있습니다.
jina-embeddings-v5-text 모델 사용에 관한 자세한 내용은 Elasticsearch 문서를 참조하세요.
추가 정보
jina-embeddings-v5-text 모델에 대한 자세한 내용은 Jina AI 블로그의 릴리즈 노트와 기술 보고서를 참조하세요. 성능 및 Jina AI의 혁신적인 새로운 훈련 절차에 대한 자세한 기술 정보를 확인할 수 있습니다. 이러한 모델을 로컬에서 다운로드하고 실행하는 방법에 대한 자세한 내용은 Hugging Face의 jina-embeddings-v5-text 컬렉션 페이지를 참조하세요.
Jina AI 모델은 CC-BY-NC-4.0 라이선스 하에 제공되므로 무료로 다운로드하여 사용할 수 있으나, 상업적 사용은 Elastic 영업팀에 문의해 주시기 바랍니다.
관련 콘텐츠

2026년 5월 11일
모든 미디어, 단 하나의 인덱스: jina-embeddings-v5-omni
jina-embeddings-v5-omni를 사용하면 텍스트, 이미지, 동영상 및 오디오를 단일 Elasticsearch 인덱스에 임베드하고 모든 항목을 한 번에 쿼리할 수 있습니다.

2026년 4월 22일
Gemini Enterprise Agent Platform Model Garden에서 Jina Embeddings v3를 사용할 수 있습니다
Jina 검색 기반 모델인 jina-embeddings-v3는 이제 Gemini Enterprise Agent Platform Model Garden에서 자체 배포할 수 있으며, 더 많은 기능이 추가될 예정입니다. 자체 VPC 내부의 단일 L4 GPU에서 jina-embeddings-v3를 실행하세요.
Jina 모델, 그 기능 및 Elasticsearch에서의 사용에 대한 소개
Jina 멀티모달 임베딩, Reranker v3 및 시맨틱 임베딩 모델을 탐색하고, 이를 Elasticsearch에서 기본적으로 사용하는 방법을 알아보세요.

2026년 5월 22일
Kibana 대시보드 로딩 속도 최대 25% 단축, 그 뒤에 숨겨진 폴링 최적화 전략
Kibana가 어떻게 지속적 폴링과 브라우저 단 HTTP/2 감지 기술을 활용해 대시보드 로딩 시간을 최대 25%까지 줄였는지, 그리고 HTTP/1 환경으로의 자동 폴백 기능은 어떻게 작동하는지 알아봅니다.

그리지 말고 설명하세요: MCP와 ES|QL을 통한 AI 네이티브 Kibana 대시보드
프롬프트부터 대시보드까지, ES|QL 쿼리를 작성하고, 대화형 차트를 생성하며, 모든 기능을 갖춘 대시보드를 Kibana로 직접 내보내는 오픈 소스 MCP 애플리케이션인 example-mcp-dashbuilder를 사용해 자연어로 Kibana 대시보드를 구축하는 방법에 대해 알아보세요.