Jina AI y Elastic están lanzando jina-embeddings-v5-text, una familia de nuevos modelos compactos de incrustación de texto de alto rendimiento con un rendimiento de última generación para modelos de tamaño comparable en todos los tipos de tareas principales.
La familia incluye dos modelos:
jina-embeddings-v5-text-smalljina-embeddings-v5-text-nano
Estos modelos son el resultado exitoso de una receta de entrenamiento innovadora para modelos de incrustación. Ambos superan a modelos varias veces más grandes, lo que genera ahorros en memoria y recursos informáticos y responde más rápido a las solicitudes.
El modelo jina-embeddings-v5-text-small tiene 677 millones de parámetros, admite una ventana de contexto de entrada de 32 768 tokens y produce incrustaciones de 1024 dimensiones por defecto.
jina-embeddings-v5-text-nano Pesa aproximadamente un tercio del tamaño de su hermano, con 239 millones de parámetros y una ventana de contexto de entrada de 8192 tokens, lo que produce incrustaciones compactas de 768 dimensiones.
| Nombre del modelo | Tamaño total | Tamaño de la ventana de contexto de entrada | Tamaño de incrustación |
|---|---|---|---|
| jina-v5-text-small | 677M parámetros | 32768 tokens | 1024 dimensiones |
| jina-v5-text-nano | 239M parámetros | 8192 tokens | 768 dimensiones |
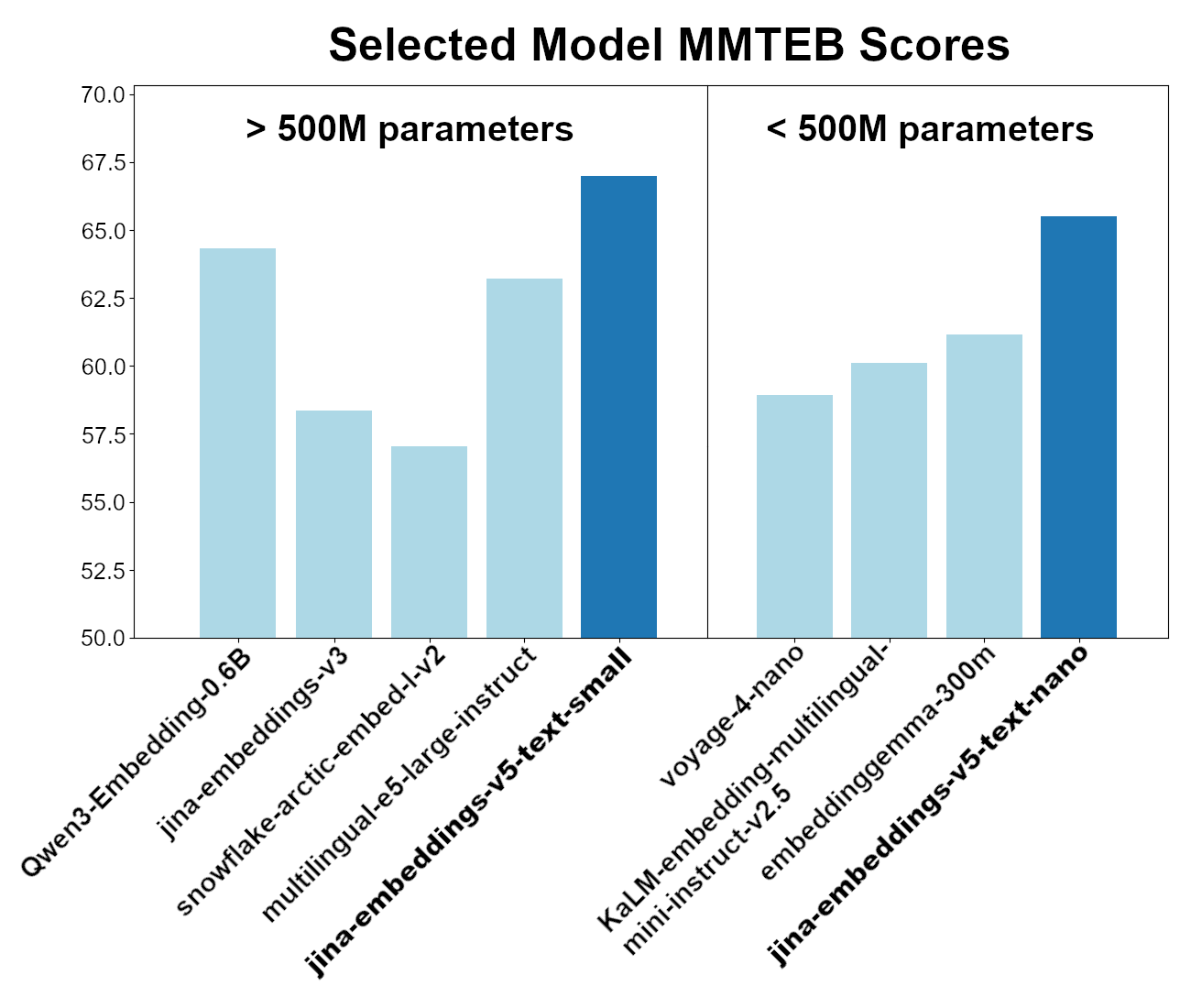
Estos dos modelos son los mejores en su categoría en cuanto al rendimiento general en la evaluación comparativa MMTEB (MTEB multilingüe). Entre los modelos con menos de 500 millones de parámetros, jina-embeddings-v5-text-nano es el de mejor rendimiento, a pesar de tener menos de 250 millones de parámetros, y el modelo jina-embeddings-v5-text-small es el líder entre los modelos de incrustación multilingüe con menos de 750 millones de parámetros.
Estos modelos están disponibles a través del Elastic Inference Service (EIS), mediante una API en línea y están disponibles para alojamiento local. Para obtener instrucciones sobre cómo acceder a los modelos jina-embeddings-v5-text, consulta la sección “Primeros pasos” a continuación.
Los modelos de incrustación y la indexación semántica aumentan considerablemente la precisión de los algoritmos de búsqueda, pero también tienen otros usos para tareas relacionadas con la similitud semántica y la extracción de significado, por ejemplo:
- Búsqueda de textos duplicados.
- Reconocimiento de paráfrasis y traducciones.
- Descubrimiento de temas.
- Motores de recomendación.
- Análisis de sentimiento e intención.
- Filtrado de spam.
- Y muchos otros.
Características
Esta nueva familia de modelos cuenta con varias características diseñadas para mejorar la relevancia y reducir costos.
Optimización de tareas
Optimizamos los modelos jina-embeddings-v5-text para cuatro tipos generales de tareas:
| Tarea | Ejemplos de casos de uso |
|---|---|
| Recuperación | Buscar con consultas en lenguaje natural y recuperar las coincidencias más relevantes en una colección de documentos. |
| Coincidencia de texto | Similitud semántica, deduplicación, paráfrasis y alineación de traducciones, y mucho más. |
| Agrupación | Descubrimiento de temas, organización automática de colecciones de documentos. |
| Clasificación | Categorización de documentos, detección de sentimientos e intenciones, tareas similares. |
La optimización para una tarea suele implicar tener que renunciar a otra, por lo que la mayoría de los modelos de incrustación solo tienen un rendimiento competitivo para un tipo de tarea. Pero los modelos jina-embeddings-v5-text pueden especializarse en las cuatro áreas sin comprometer el entrenamiento de adaptadores de Low-Rank Adaptation (LoRA) específicos para cada tarea.
Los adaptadores de LoRA son un tipo de plugin para un modelo de AI que cambia drásticamente su comportamiento y solo aumenta ligeramente el tamaño total. En lugar de tener un modelo completo para cada tarea, cada uno con cientos de millones de parámetros, la familia de modelos jina-embeddings-v5-text te permite usar solo un modelo con un adaptador de LoRA compacto para cada tarea. Esto ahorra memoria, espacio de almacenamiento y costos de inferencia.
Incrustaciones truncadas
Entrenamos los modelos jina-embeddings-v5-text utilizando Aprendizaje de representación de Matryoshka, que te permite reducir tus incrustaciones a tamaños más pequeños con un costo mínimo para su calidad.
Por defecto, jina-embeddings-v5-text-small genera vectores de incrustación de 1024 dimensiones, cada uno representado por un número de 16 bits, lo que hace que cada incrustación tenga 2 KB de tamaño. En el caso de una gran colección de documentos, esto puede suponer una gran cantidad de datos que almacenar, y la búsqueda en una base de datos vectorial llena de incrustaciones es proporcional tanto al tamaño de la base de datos como al número de dimensiones que tiene cada vector almacenado.
Pero puedes simplemente reducir a la mitad el tamaño de las incrustaciones (desechar 512 de las 1024 dimensiones) y ocupar la mitad del espacio mientras duplicas las velocidades de búsqueda. Esto tiene un impacto en el rendimiento. Eliminar parte de la información reduce la precisión. Sin embargo, como muestra el grafo siguiente, incluso al eliminar la mitad de la incrustación, el rendimiento solo se reduce ligeramente:
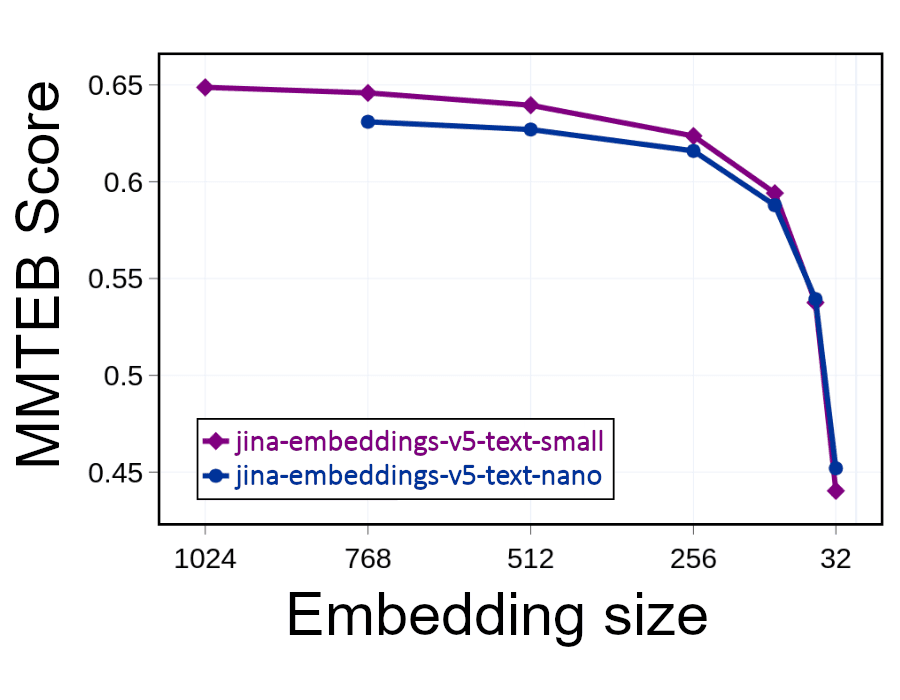
Siempre y cuando tus incrustaciones tengan al menos 256 dimensiones, la pérdida de precisión debería ser bastante pequeña. Sin embargo, por debajo de ese nivel, la relevancia y la precisión se deterioran rápidamente.
Las incrustaciones truncadas como esta permiten a los usuarios gestionar sus propias compensaciones entre precisión y costos de computación. Te dan las herramientas para obtener grandes ganancias de eficiencia y grandes ahorros de costos de tu AI de búsqueda.
Cuantización robusta
La cuantización es otra forma de reducir el tamaño de las incrustaciones. En lugar de desechar parte de cada incrustación, la cuantización reduce la precisión de los números en la incrustación. Los modelos jina-embeddings-v5-text generan incrustaciones con números de 16 bits, pero podemos redondear esos números, reduciendo su precisión y la cantidad de bits necesarios para almacenarlos. En el caso más extremo, podemos reducir cada número a un bit (0 o 1), comprimiendo las incrustaciones predeterminadas de 1024 dimensiones jina-embeddings-v5-textde 2 kilobytes a 128 bytes, una reducción del 94 % solo por cuantización binaria. Al igual que para el truncamiento, esto produce grandes ahorros en memoria y costos de computación. Sin embargo, al igual que el truncamiento, la cuantización reduce la precisión de las incrustaciones.
Entrenamos los modelos de jina-embeddings-v5-text para que funcionen con Better Binary Quantization de Elasticsearch al minimizar esa pérdida de precisión, y las pruebas de evaluación comparativa de incrustaciones binarizadas de estos modelos muestran un rendimiento casi igual al de sus equivalentes no binarizados. Consulta el reporte técnico para obtener estudios detallados sobre el rendimiento de la binarización.
Rendimiento multilingüe
Muchos modelos de incrustación son multilingües porque se entrenaron con materiales que incluyen un gran número de idiomas. Pero eso no significa que todos funcionen igual de bien en todos los idiomas compatibles.
Identificamos 211 idiomas en la evaluación comparativa multilingüe MMTEB y los separamos para poder comparar nuestros modelos con modelos similares idioma por idioma. La imagen de abajo resume nuestros resultados como un mapa de calor. Cada parche es un idioma (identificado por su código ISO-639), y cuanto más verde sea, mejor rendimiento tuvo el modelo en comparación con el promedio de modelos similares:

Aunque la precisión varía entre idiomas, los modelos jina-embeddings-v5-text son de última generación o casi lo son en la mayoría de los idiomas del mundo.
Para obtener detalles sobre el rendimiento multilingüe, consulta el reporte técnico jina-embeddings-v5-text.
Jina en Elastic: IA nativa de última generación para búsqueda
Con los modelos jina-embeddings-v5-text en EIS, puedes ejecutar modelos de incrustación multilingüe de alto rendimiento de forma nativa en Elasticsearch, con inferencia totalmente gestionada y acelerada por GPU y sin infraestructura para aprovisionar o escalar. Los modelos jina-embeddings-v5-text amplían el creciente catálogo de modelos EIS con modelos compactos y multilingües impulsados por los últimos desarrollos en AI. Estos modelos tienen un rendimiento de última generación en recuperación de información y análisis de datos estándar, y ofrecen un soporte multilingüe inigualable que abarca todo el globo.
Con dos modelos de tamaños muy diferentes, los usuarios pueden determinar cuál es el más adecuado para sus aplicaciones y presupuestos. Además, con incrustaciones sólidas que siguen siendo eficientes cuando se truncan a tamaños más pequeños o se cuantifican con menor precisión, los modelos jina-embeddings-v5-text ofrecen oportunidades para ahorros concretos adicionales en costos de almacenamiento y computación, así como en latencia de procesamiento.
Con la familia jina-embeddings-v5-text , Jina Reranker y la rápida búsqueda vectorial y BM25 de Elastic, los usuarios ahora tienen acceso a la búsqueda híbrida de última generación de extremo a extremo de Elastic. Cuando necesitas los resultados más relevantes, ya sea para pipelines de Retrieval-Augmented Generation (RAG), aplicaciones de búsqueda o análisis de datos, Elastic con modelos de AI de búsqueda Jina ofrece una calidad estable y rentable.
Primeros pasos
Los modelos jina-embeddings-v5-text están completamente integrados en EIS y puedes usarlos al configurar el campotype en semantic_text al crear tu índice y especificar el modelo (jina-embeddings-v5-text-small o jina-embeddings-v5-text-nano) en el campo inference_id , como en este ejemplo:
Elasticsearch selecciona automáticamente el adaptador de LoRA adecuado durante la indexación y la recuperación. Las dimensiones de incrustación (consulta la sección “Incrustaciones truncadas” anterior) se pueden establecer al crear un endpoint de inferencia personalizado.
Consulta la documentación de Elasticsearch para obtener más información sobre el uso de modelos jina-embeddings-v5-text .
Más información
Para obtener más información sobre los modelos jina-embeddings-v5-text, lee las notas de lanzamiento en el blog de Jina AI y el reporte técnico, con información técnica más detallada sobre el rendimiento y el nuevo procedimiento de entrenamiento innovador de Jina AI. Para obtener información sobre cómo descargar y ejecutar estos modelos localmente, visita la jina-embeddings-v5-text página de la colección en Hugging Face.
Los modelos de Jina AI están disponibles bajo una licencia CC-BY-NC-4.0, así que puedes descargarlos y probarlos libremente, pero para uso comercial, ponte en contacto con Ventas de Elastic.
Contenido relacionado

11 de mayo de 2026
Un índice, todos los medios: presentamos jina-embeddings-v5-omni
jina-embeddings-v5-omni te permite incrustar texto, imágenes, video y audio en un único índice de Elasticsearch y realizar búsquedas en todos a la vez.

22 de abril de 2026
Las incrustaciones v3 de Jina ya están disponibles en el Model Garden de Gemini Enterprise Agent Platform
El modelo base de búsqueda de Jina, jina-embeddings-v3, ya se puede implementar de forma autónoma en el Model Garden de Gemini Enterprise Agent Platform, y próximamente habrá más modelos disponibles. Ejecuta jina-embeddings-v3 en una única GPU L4 dentro de tu propia VPC.
1 de enero de 2026
Introducción a los modelos de Jina, su funcionalidad y usos en Elasticsearch
Explora las incrustaciones multimodales de Jina, Reranker v3 y los modelos de incrustación semántica, y aprende cómo usarlos de forma nativa en Elasticsearch.

22 de mayo de 2026
Kibana reduce el tiempo de carga del dashboard hasta en un 25 %: esta es la estrategia de sondeo que hay detrás
Descubre cómo Kibana usa el sondeo continuo y la detección de HTTP/2 en el navegador para reducir los tiempos de carga del dashboard hasta en un 25 %, con una transición automática a HTTP/1 en caso de que no sea posible.

Descríbelo, no lo dibujes: dashboard de Kibana con IA integrada a través de MCP y ES|QL
De la indicación al dashboard. Aprende a construir dashboards de Kibana con lenguaje natural a través de example-mcp-dashbuilder: una aplicación MCP open source que escribe consultas ES|QL, crea gráficos interactivos y exporta dashboards completamente funcionales directamente a Kibana.