Jina de Elastic proporciona modelos fundamentales de búsqueda para aplicaciones y una automatización de procesos empresariales. Estos modelos proporcionan funcionalidad del núcleo para llevar la IA a las aplicaciones de Elasticsearch y a los proyectos innovadores de IA.
Los modelos de Jina se dividen en tres amplias categorías diseñadas para apoyar el procesamiento, la organización y la recuperación de información:
- Modelos de incrustación semántica
- Modelos de reordenamiento
- Pequeños modelos de lenguaje generativo
Modelos de incrustación semántica
La idea detrás de las incrustaciones semánticas es que un modelo de IA puede aprender a representar aspectos del significado de sus entradas en términos de la geometría de espacios de alta dimensión.
Puedes pensar en una incrustación semántica como un punto (técnicamente un vector) en un espacio de alta dimensión. Un modelo de incrustación es una red neuronal que toma algunos datos digitales como entrada (potencialmente cualquier cosa, pero con mayor frecuencia un texto o una imagen) y genera la ubicación de un punto de alta dimensión correspondiente como un conjunto de coordenadas numéricas. Si el modelo funciona bien, la distancia entre dos incrustaciones semánticas es proporcional a la medida en que sus objetos digitales correspondientes significan lo mismo.
Para entender cómo esto es importante para las aplicaciones de búsqueda, imagina una incrustación para la palabra “perro” y una para la palabra “gato” como puntos en el espacio:
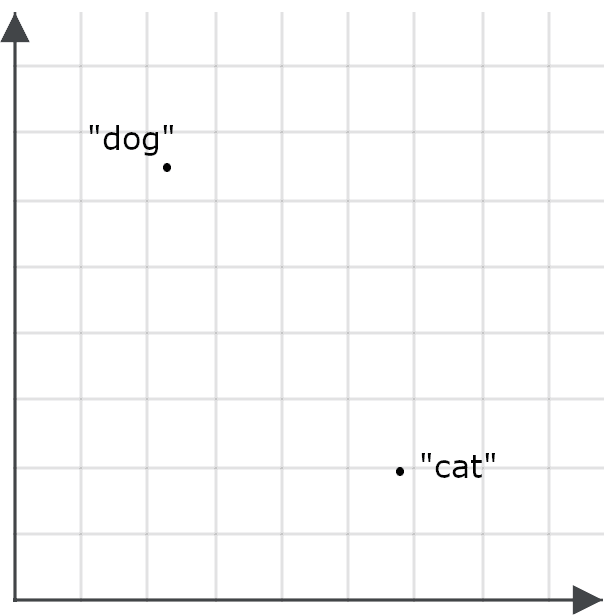
Un buen modelo de incrustación debe generar una para la palabra “felino” que esté mucho más cerca de “gato” que de “perro”, y “canino” debe tener una incrustación mucho más cercana a “perro” que de “gato”, porque esas palabras significan casi lo mismo:

Si un modelo es multilingüe, esperaríamos lo mismo para las traducciones de “gato” y “perro”:

Los modelos de incrustación traducen la similitud o diferencia en el significado entre las cosas en relaciones espaciales entre incrustaciones. Las imágenes anteriores solo tienen dos dimensiones para que puedas verlas en una pantalla, pero los modelos de incrustación producen vectores con docenas o miles de dimensiones. Esto les permite codificar sutilezas de significado para textos completos y asignar un punto en un espacio que tenga cientos o miles de dimensiones para documentos de miles de palabras o más.
Incrustaciones multimodales
Los modelos multimodales amplían el concepto de incrustaciones semánticas a otros elementos, además de los textos, especialmente a las imágenes. Esperaríamos que una incrustación para una imagen esté cerca de una incrustación de una descripción fiel de la imagen:
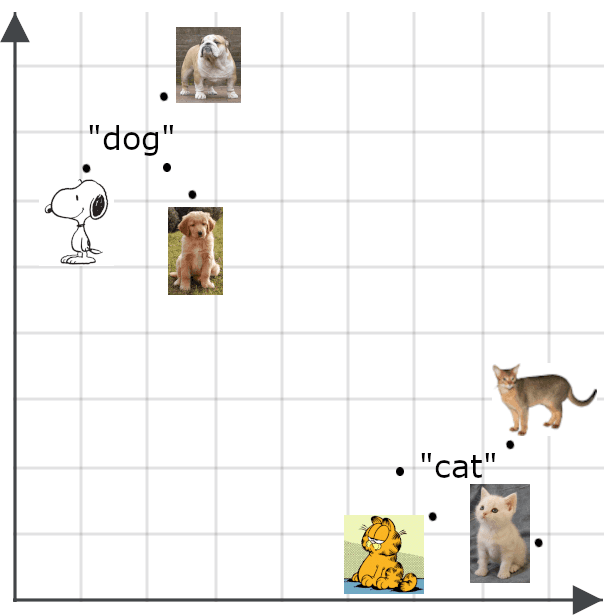
Las incrustaciones semánticas tienen muchos usos. Entre otras cosas, puedes utilizarlos para crear clasificadores eficientes, agrupar datos y llevar a cabo una variedad de tareas, como la deduplicación de datos y la investigación de la diversidad de datos, ambas importantes para aplicaciones de big data que implican trabajar con demasiados datos para gestionarlos manualmente.
El mayor uso directo de las incrustaciones es en la recuperación de información. Elasticsearch puede almacenar objetos de recuperación con incrustaciones como claves. Las consultas se convierten en vectores de incrustación y una búsqueda devuelve los objetos almacenados cuyas claves son las más cercanas a la incrustación de la consulta.
Donde la recuperación tradicional basada en vectores (a veces llamada recuperación de vectores dispersos) utiliza vectores basados en palabras o metadatos en documentos y búsquedas, la recuperación basada en incrustaciones (también conocida como recuperación de vectores densos) utiliza significados evaluados por la IA en lugar de palabras. Esto los hace, en general, mucho más flexibles y precisos que los métodos de búsqueda tradicionales.
Aprendizaje de representación de Matryoshka
El número de dimensiones que tiene una incrustación y la precisión de los números que contiene tienen un impacto significativo en el rendimiento. Los espacios de muy alta dimensión y los números extremadamente de alta precisión pueden representar información muy detallada y compleja, pero exigen modelos de IA más grandes que sean más caros de entrenar y de ejecutar. Los vectores que generan requieren más espacio de almacenamiento y se necesitan más ciclos de computación para calcular las distancias entre ellos. El uso de modelos de incrustación semántica implica hacer compensaciones importantes entre la precisión y el consumo de recursos.
Para maximizar la flexibilidad para los usuarios, los modelos de Jina se entrenan con una técnica llamada Aprendizaje de representación de Matryoshka. Esto hace que los modelos carguen las distinciones semánticas más importantes en las primeras dimensiones del vector de incrustación para que simplemente puedas cortar las dimensiones superiores y aún obtener un buen rendimiento.
En la práctica, esto significa que los usuarios de los modelos de Jina pueden elegir cuántas dimensiones desean que tengan sus incrustaciones. Elegir menos dimensiones reduce la precisión, pero la degradación en el rendimiento es menor. En la mayoría de las tareas, las métricas de rendimiento de los modelos de Jina disminuyen entre un 1 % y un 2 % cada vez que reduces el tamaño de la incrustación en un 50 %, hasta aproximadamente una reducción del 95 % en el tamaño.
Recuperación asimétrica
La similitud semántica usualmente se mide de manera simétrica. El valor que obtienes al comparar “gato” con “perro” es el mismo que el valor que obtendrías al comparar “perro” con “gato”. Pero cuando usas incrustaciones para la recuperación de información, funcionan mejor si rompes la simetría y codificas las búsquedas de manera diferente a como codificas los objetos de recuperación.
Esto se debe a la forma en que entrenamos los modelos de incrustación. Los datos de entrenamiento contienen ejemplos de los mismos elementos, como palabras, en muchos contextos diferentes, y los modelos aprenden semántica al comparar las similitudes y diferencias contextuales entre los elementos.
Entonces, por ejemplo, podríamos encontrar que la palabra “animal” no aparece en muchos de los mismos contextos que “gato” o “perro”, y por lo tanto, la incrustación para “animal” podría no estar particularmente cerca de “gato” o “perro”:
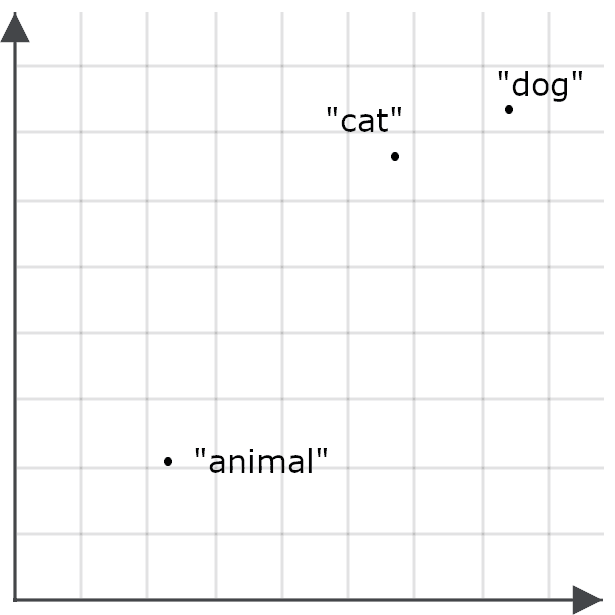
Esto hace que sea menos probable que una búsqueda de "animal" recupere documentos sobre gatos y perros, lo cual es lo opuesto a nuestro objetivo. Así que, en su lugar, codificamos "animal" de forma diferente cuando es una consulta que cuando es un objetivo para la recuperación:
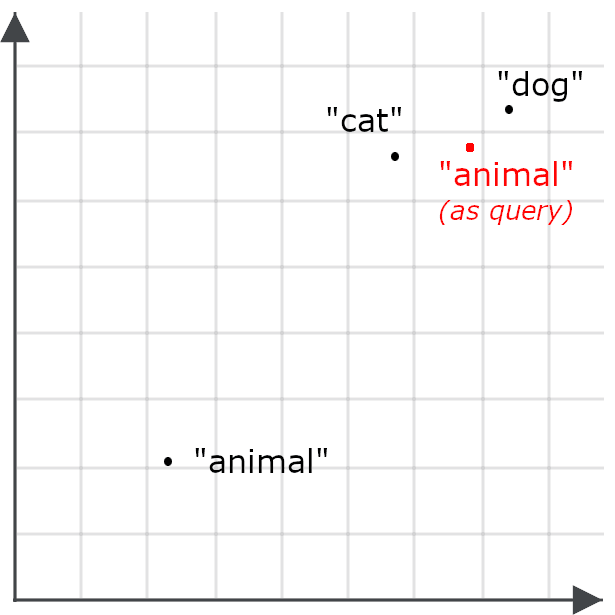
La recuperación asimétrica significa usar un modelo diferente para las búsquedas o entrenar especialmente un modelo de incrustación para codificar cosas de una manera cuando se almacenan para su recuperación y para codificar consultas de otra manera.
Incrustaciones multivectoriales
Las incrustaciones únicas son buenas para la recuperación de información porque se ajustan al marco de trabajo básico de una base de datos indexada: almacenamos objetos para su recuperación con un único vector de incrustación como clave de recuperación. Cuando los usuarios consultan el almacén de documentos, sus búsquedas se traducen en vectores de incrustación y los documentos cuyas claves están más cercanas a la incrustación de búsquedas (en el espacio de incrustación de alta dimensión) se recuperan como posibles coincidencias.
Las incrustaciones multivectoriales funcionan un poco diferente. En lugar de generar un vector de longitud fija para representar una búsqueda y un objeto almacenado completo, producen una secuencia de incrustaciones que representan partes más pequeñas de ellos. Las partes suelen ser tokens o palabras para textos y son mosaicos de imagen para datos visuales. Estas incrustaciones reflejan el significado de la parte en su contexto.
Por ejemplo, considera estas oraciones:
- Ella tenía un corazón de oro.
- Ella cambió de opinión con el corazón.
- Ella tuvo un ataque al corazón.
Superficialmente, se ven muy similares, pero un modelo multivectorial probablemente generaría incrustaciones muy diferentes para cada instancia de "corazón", representando cómo cada una significa algo diferente en el contexto de la oración completa:
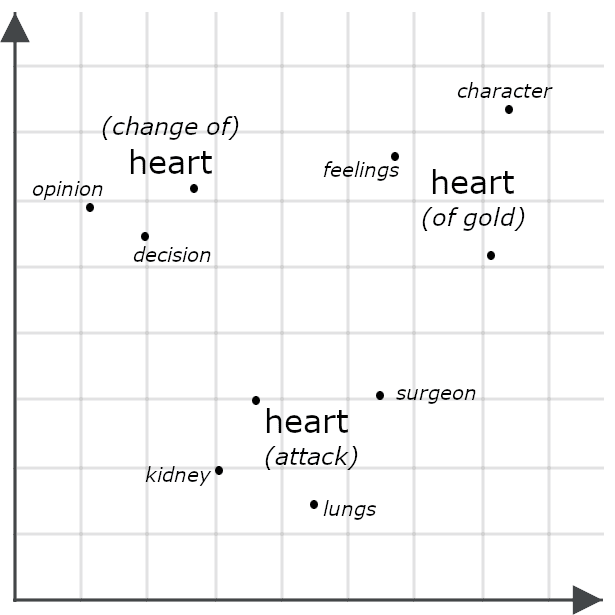
La comparación de dos objetos a través de sus incrustaciones multivectoriales a menudo implica medir su distancia de chaflán: comparar cada parte de una incrustación multivectorial con cada parte de otra y sumar las distancias mínimas entre ellas. Otros sistemas, incluidos los Jina Rerankers que se describen a continuación, los incluyen en un modelo de IA entrenado específicamente para evaluar su similitud. Ambos enfoques suelen tener mayor precisión que la simple comparación de incrustaciones de un solo vector, ya que las incrustaciones multivectoriales contienen información mucho más detallada que las de un solo vector.
Sin embargo, las incrustaciones multivectoriales no son adecuadas para indexar. A menudo se utilizan en tareas de reclasificación, como se describe para el modelo de jina-colbert-v2 en la siguiente sección.
Modelos de incrustación de Jina
Jina embeddings v4
jina-embeddings-v4 es un modelo de incrustación multilingüe y multimodal de 3.8 mil millones (3.8×10⁹) de parámetros que admite imágenes y textos en una variedad de idiomas ampliamente utilizados. Utiliza una arquitectura novedosa para aprovechar el conocimiento visual y el conocimiento del lenguaje para mejorar el rendimiento en ambas tareas, lo que le permite sobresalir en la recuperación de imágenes y especialmente en la recuperación visual de documentos. Esto significa que maneja imágenes como gráficos, diapositivas, mapas, capturas de pantalla, escaneos de páginas y diagramas, tipos comunes de imágenes que a menudo contienen texto importante incrustado y que quedan fuera del alcance de los modelos de visión artificial entrenados con imágenes de escenas del mundo real.
Hemos optimizado este modelo para varias tareas diferentes a través de adaptadores de Low-Rank Adaptation (LoRA) compactos. Esto nos permite entrenar un único modelo para que se especialice en varias tareas, sin comprometer el rendimiento en ninguna de ellas, con un costo adicional mínimo en memoria o procesamiento.
Las características principales incluyen las siguientes:
- Rendimiento de vanguardia en la recuperación visual de documentos, junto con texto multilingüe e imágenes regulares que superan significativamente a modelos mucho más grandes.
- El soporte para un gran tamaño de contexto de entrada: 32.768 tokens equivale aproximadamente a 80 páginas de texto en inglés a doble espacio, y 20 megapíxeles equivalen a una imagen de 4.500 x 4.500 píxeles.
- Tamaños de incrustación seleccionados por el usuario, desde un máximo de 2048 dimensiones hasta 128 dimensiones. Descubrimos empíricamente que el rendimiento se degrada significativamente por debajo de ese umbral.
- Soporte para ambas incrustaciones simples y multivector. En el caso de los textos, la salida multivectorial consiste en una incrustación de 128 dimensiones para cada token de entrada. Para las imágenes, produce una incrustación de 128 dimensiones para cada mosaico de 28x28 píxeles necesario para cubrir la imagen.
- Optimización para la recuperación asimétrica mediante un par de adaptadores LoRA entrenados específicamente para tal fin.
- Un adaptador LoRA optimizado para el cálculo de similitud semántica.
- Soporte especial para lenguajes de programación informática y marcos de trabajo de TI, también a través de un adaptador LoRA.
Desarrollamos jina-embeddings-v4 para servir como una herramienta general y multipropósito para una amplia variedad de tareas de búsqueda común, comprensión del lenguaje natural y análisis de IA. Es un modelo relativamente pequeño teniendo en cuenta sus capacidades, pero su despliegue requiere recursos considerables y es más adecuado para su uso a través de una API en la nube o en un entorno de gran volumen.
Jina embeddings v3
jina-embeddings-v3 es un modelo de incrustación compacto, de alto rendimiento, multilingüe y solo de texto con menos de 600 millones de parámetros. Admite hasta 8192 tokens de entrada de texto y genera incrustaciones de vector único con tamaños elegidos por el usuario, desde un valor predeterminado de 1024 dimensiones hasta 64.
Capacitamos a jina-embeddings-v3 para una variedad de tareas de texto. No solo para la recuperación de información y la similitud semántica, sino también para tareas de clasificación, como análisis de sentimiento y moderación de contenido, así como tareas de agrupar, como agregación de noticias y recomendaciones. Al igual que jina-embeddings-v4, este modelo proporciona adaptadores LoRA especializados para las siguientes categorías de uso:
- Recuperación asimétrica
- Similitud semántica
- Clasificación
- Agrupación
jina-embeddings-v3 es un modelo mucho más pequeño que jina-embeddings-v4 con un tamaño de contexto de entrada significativamente reducido, pero su funcionamiento cuesta menos. No obstante, tiene un rendimiento muy competitivo, aunque solo para textos, y es una mejor opción para muchos casos de uso.
Inmercaciones del código Jina
Los modelos especializados de incrustación de código de Jina, jina-code-embeddings (0.5b y 1.5b), admiten 15 esquemas y marcos de trabajo de programación, así como textos en inglés relacionados con la informática y la tecnología de la información. Son modelos compactos con quinientos millones (0.5x10⁹) y mil quinientos millones (1.5x10⁹) de parámetros, respectivamente. Ambos modelos admiten tamaños de contexto de entrada de hasta 32.768 tokens y permiten a los usuarios seleccionar los tamaños de su incrustación de salida, desde 896 hasta 64 dimensiones para el modelo más pequeño y 1536 hasta 128 para el modelo más grande.
Estos modelos admiten la recuperación asimétrica para cinco especializaciones específicas de tareas, mediante el ajuste de prefijos en lugar de adaptadores LoRA:
- Código a código. Recupera un código similar en todos los lenguajes de programación. Esto se utiliza para la alineación de códigos, deduplicación de códigos y soporte para la traslación y refactorización.
- Lenguaje natural para programar. Recupera códigos para hacer coincidir consultas, comentarios, descripciones y documentación en lenguaje natural.
- Código a lenguaje natural. Haz coincidir el código con la documentación u otros textos en lenguaje natural.
- Finalización de código a código. Sugiere un código relevante para completar o mejorar el código existente.
- Preguntas y respuestas técnicas. Identifica las respuestas en lenguaje natural a las preguntas sobre tecnologías de la información, que son ideales para casos de uso de soporte técnico.
Estos modelos ofrecen un rendimiento superior para tareas relacionadas con documentación informática y materiales de programación con un costo computacional relativamente bajo. Son muy adecuados para integrarse en entornos de desarrollo y asistentes de código.
Jina ColBERT v2
jina-colbert-v2 es un modelo de incrustación de texto multivectorial de 560 millones de parámetros. Es multilingüe, entrenado con materiales en 89 idiomas, y soporta tamaños de incrustación variables y recuperación asimétrica.
Como se ha señalado anteriormente, las incrustaciones multivectoriales no son adecuadas para la indexación, pero resultan muy útiles para aumentar la precisión de los resultados de otras estrategias de búsqueda. Mediante jina-colbert-v2, puedes calcular incrustaciones multivector de antemano y luego usarlas para reclasificar candidatos de recuperación al momento de la búsqueda. Este enfoque es menos preciso que usar uno de los modelos de reclasificación en la siguiente sección, pero es mucho más eficiente porque simplemente implica comparar incrustaciones multivectoriales almacenadas en lugar de invocar todo el modelo de IA para cada búsqueda y coincidencia posible. Es ideal para casos de uso en los que la latencia y la sobrecarga computacional que supone el uso de modelos de reclasificación son demasiado grandes, o cuando el número de candidatos que comparar es demasiado elevado para los modelos de reclasificación.
Este modelo genera una secuencia de incrustaciones, una por token de entrada, y los usuarios pueden seleccionar incrustaciones de token de 128, 96 o 64 dimensiones. Las coincidencias de texto de candidatos están limitadas a 8,192 tokens. Las búsquedas se codifican de manera asimétrica, por lo que los usuarios deben especificar si un texto es una búsqueda o una coincidencia candidata y deben limitar las búsquedas a 32 tokens.
Jina CLIP v2
Jina-Clip-V2 es un modelo de incrustación multimodal de 900 millones de parámetros, y está capacitado para que los textos e imágenes produzcan incrustaciones muy cercanas si el texto describe el contenido de la imagen. Su uso principal es para recuperar imágenes basadas en consultas de textura, pero también es un modelo de solo texto de alto rendimiento, lo que reduce los costos de usuario porque no necesitas modelos separados para la recuperación de texto a texto y de texto a imagen.
Este modelo admite un contexto de entrada de texto de 8,192 tokens, y las imágenes se escalan a 512x512 píxeles antes de generar incrustaciones.
Las arquitecturas de preentrenamiento de lenguaje-imagen contrastivo (CLIP) son fáciles de entrenar y operar y pueden producir modelos muy compactos, pero tienen algunas limitaciones fundamentales. No pueden utilizar los conocimientos adquiridos en un medio para mejorar su rendimiento en otro. No pueden usar un medio para mejorar su rendimiento en otro. Así que, aunque pueda saber que las palabras "perro" y "gato" están más cercanas en significado que a "auto", no necesariamente sabrá que una foto de un perro y una de un gato están más relacionadas que cualquiera de las dos con una foto de un auto.
También sufren de lo que se llama la brecha de modalidad: es probable que una incrustación de un texto sobre perros esté más cerca de una incrustación de un texto sobre gatos que de una incrustación de una imagen de perros. Debido a esta limitación, te recomendamos utilizar CLIP como modelo de recuperación de texto a imagen o como modelo de solo texto, pero sin mezclar los dos en una sola búsqueda.
Modelos de reordenamiento
Los modelos de reclasificación toman una o más coincidencias candidatas, junto con una consulta como entrada al modelo, y las comparan directamente, produciendo coincidencias de mucha mayor precisión.
En principio, podrías usar un reranker directamente para la recuperación de información al comparar cada búsqueda con cada documento almacenado, pero esto sería muy costoso desde el punto de vista computacional y no es práctico para cualquier colección excepto para las más pequeñas. Como resultado, los rerankers tienden a usarse para evaluar listas relativamente cortas de coincidencias de candidatos encontradas por otros medios, como la búsqueda basada en incrustaciones u otros algoritmos de recuperación. Los modelos de reclasificación son ideales para esquemas de búsqueda híbridos y federados, donde realizar una búsqueda puede significar que las consultas se envían a sistemas de búsqueda separadas con conjuntos de datos distintos, cada una devolviendo resultados distintos. Funcionan muy bien al combinar resultados diversos en un único resultado de alta calidad.
La búsqueda basada en incrustaciones puede ser un gran compromiso, ya que implica reindexar todos tus datos almacenados y cambiar las expectativas del usuario sobre los resultados. Agregar un reranker a un esquema de búsqueda existente puede sumar muchos de los beneficios de la IA sin necesidad de rediseñar toda tu solución de búsqueda.
Modelos de reordenación de Jina
Jina Reranker m0
jina-reranker-m0 es un reranker multimodal de 2.4 mil millones (2.4x10⁹) de parámetros que admite consultas textuales y coincidencias candidatas que consisten en textos y/o imágenes. Es el modelo líder en recuperación visual de documentos, lo que lo convierte en una solución ideal para almacenar archivos PDF, escaneos de texto, capturas de pantalla y otras imágenes generadas o modificadas por computadora que contengan texto u otra información semiestructurada, así como datos mixtos que consistan en documentos de texto e imágenes.
Este modelo toma una búsqueda única y una coincidencia candidata y devuelve una puntuación. Cuando la misma consulta se usa con diferentes candidatos, las puntuaciones son comparables y pueden usarse para clasificarlas. Soporta un tamaño total de entrada de hasta 10 240 tokens, incluido el texto de la consulta y el texto o imagen candidata. Cada mosaico de 28x28 píxeles necesario para cubrir una imagen cuenta como un token para calcular el tamaño de entrada.
Jina Reranker v3
jina-reranker-v3 es un reranker de texto de 600 millones de parámetros con rendimiento de vanguardia para modelos de tamaño comparable. A diferencia de jina-reranker-m0, toma una sola búsqueda y una lista de hasta 64 candidatos coincidentes y devuelve el orden de clasificación. Tiene un contexto de entrada de 131 000 tokens, incluida la consulta y todos los candidatos de texto.
Jina Reranker v2
jina-reranker-v2-base-multilingual es un reranker muy compacto y de uso general con características adicionales diseñadas para admitir llamadas a funciones y consultas SQL. Con un peso inferior a 300 millones de parámetros, proporciona una reclasificación de texto multilingüe rápido, eficiente y preciso, con soporte adicional para seleccionar tablas SQL y funciones externas que coincidan con consultas de texto, lo que lo hace adecuado para casos de uso de agentes.
Pequeños modelos de lenguaje generativo
Los modelos de lenguaje generativo son modelos como ChatGPT de OpenAI, Google Gemini y Claude de Anthropic que toman entradas de texto o multimedia y responden con salidas de texto. No existe una línea bien definida que separe los modelos de lenguaje grandes (LLM) de los modelos de lenguaje pequeños (SLM), pero los problemas prácticos de desarrollar, operar y utilizar LLM de primera línea son bien conocidos. Los más conocidos no se distribuyen públicamente, por lo que solo podemos estimar su tamaño, pero se espera que ChatGPT, Gemini y Claude estén en el rango de parámetros de 1 a 3 billones (1–3x10¹²).
Ejecutar estos modelos, incluso si están disponibles públicamente, está muy lejos del alcance del hardware convencional, que requiere los chips más avanzados dispuestos en grandes matrices paralelas. Puedes acceder a LLMs a través de API pagas, pero esto conlleva costos significativos, tiene una gran latencia y es difícil de alinear con las demandas de protección de datos, la soberanía digital y la repatriación en la nube. Además, los costos relacionados con la capacitación y la personalización de modelos de ese tamaño pueden ser considerables.
En consecuencia, se han realizado numerosas investigaciones para desarrollar modelos más pequeños que, aunque carecen de todas las capacidades de los LLM más grandes, pueden realizar determinados tipos de tareas con la misma eficacia y a un menor costo. Las empresas generalmente despliegan software para abordar problemas específicos, y el software de IA no es diferente, por lo que las soluciones basadas en SLM se suelen preferir a las de LLM. Por lo general, pueden ejecutarse en hardware básico, son más rápidos y consumen menos energía para ejecutarse, y son mucho más fáciles de personalizar.
Las ofertas de SLM de Jina están creciendo a medida que nos enfocamos en la mejor manera de llevar la IA a soluciones de búsqueda prácticas.
Jina SLM
ReaderLM v2
ReaderLM-v2 es un modelo de lenguaje generativo que convierte HTML en Markdown o JSON, según los esquemas JSON proporcionados por el usuario y las instrucciones en lenguaje natural.
El preprocesamiento y la normalización de datos son una parte esencial del desarrollo de buenas soluciones de búsqueda para datos digitales, pero los datos del mundo real, especialmente la información derivada de la web, suelen ser caóticos, y las estrategias de conversión simples a menudo resultan ser muy frágiles. En cambio, ReaderLM-v2 ofrece una solución de modelo de IA inteligente que puede entender el caos de un volcado de árbol DOM de una página web e identificar de manera segura elementos útiles.
Con 1500 millones (1,5 x 10⁹) de parámetros, es tres órdenes de magnitud más compacto que los LLM de última generación, pero su rendimiento es similar al de estos en esta tarea específica.
Jina VLM
jina-vlm es un modelo de lenguaje generativo con 2400 millones (2,4 x 10⁹) de parámetros que está entrenado para responder preguntas en lenguaje natural sobre imágenes. Tiene un fuerte soporte para el análisis visual de documentos, es decir, responder preguntas sobre escaneos, capturas de pantalla, diapositivas, diagramas y datos similares de imágenes no naturales.
Por ejemplo:

Crédito de la foto: Usuario dave_7 en Wikimedia Commons.
.jpg){kind=link}
También es muy bueno para leer texto en imágenes:

Crédito de la foto: Usuario Vauxford en Wikimedia Commons.
{kind=link}
Pero donde jina-vlm realmente se destaca es en entender el contenido de las imágenes informativas y creadas por el hombre:

Crédito de la imagen: Wikimedia Commons.
{kind=link}
O:

Crédito de la imagen: Wikimedia Commons.
.png){kind=link}
jina-vlm es adecuado para la generación automática de subtítulos, descripciones de productos, texto alternativo de imágenes y aplicaciones de accesibilidad para personas con discapacidad visual. También crea posibilidades para que los sistemas de generación aumentada por recuperación (RAG) utilicen información visual y para que los agentes de IA procesen imágenes sin ayuda humana.
Contenido relacionado

11 de mayo de 2026
Potenciando Elasticsearch: agregamos soporte nativo de la API de Prometheus
Realiza una búsqueda en Elasticsearch directamente desde clientes compatibles con Prometheus a través de endpoints nativos de PromQL, descubrimiento y metadatos. Envía datos a Elasticsearch con Prometheus Remote Write.

11 de mayo de 2026
Un índice, todos los medios: presentamos jina-embeddings-v5-omni
jina-embeddings-v5-omni te permite incrustar texto, imágenes, video y audio en un único índice de Elasticsearch y realizar búsquedas en todos a la vez.

22 de abril de 2026
Las incrustaciones v3 de Jina ya están disponibles en el Model Garden de Gemini Enterprise Agent Platform
El modelo base de búsqueda de Jina, jina-embeddings-v3, ya se puede implementar de forma autónoma en el Model Garden de Gemini Enterprise Agent Platform, y próximamente habrá más modelos disponibles. Ejecuta jina-embeddings-v3 en una única GPU L4 dentro de tu propia VPC.

23 de marzo de 2026
Uso de la API de inferencia de Elasticsearch junto con modelos de Hugging Face
Aprende a conectar Elasticsearch a modelos de Hugging Face usando endpoints de inferencia y crea un sistema multilingüe de recomendación de blogs con búsqueda semántica y finalización de chat.

27 de marzo de 2026
Cómo crear un servidor MCP de Elasticsearch con TypeScript
Aprende a crear un servidor MCP de Elasticsearch con TypeScript y Claude Desktop.