La Ingeniería del Contexto está ganando cada vez más importancia para construir agentes y arquitecturas de IA fiables. A medida que los modelos mejoran, su eficacia y fiabilidad dependen menos de sus datos capacitados y más de lo bien que estén fundamentados en el contexto adecuado. Los agentes que pueden recuperar y aplicar la información más relevante en el momento adecuado tienen muchas más probabilidades de producir resultados precisos y fiables.
En este blog, emplearemos Mastra para construir un agente de conocimiento que recuerda lo que dicen los usuarios y puede recuperar información relevante más adelante, empleando Elasticsearch como backend de memoria y recuperación. Puedes extender fácilmente este mismo concepto a casos de uso reales, piensa en agentes de soporte que puedan recordar conversaciones y resoluciones pasadas, permitiéndoles adaptar las respuestas a usuarios específicos o a soluciones superficiales más rápido basar en contextos previos.
Sigue aquí para ver cómo construirlo paso a paso. Si te pierdes o simplemente quieres ejecutar un ejemplo terminado, echa un vistazo al repositorio aquí.
¿Qué es Mastra?
Mastra es un framework TypeScript de código abierto para construir agentes de IA con partes intercambiables para razonamiento, memoria y herramientas. Su función de recuperación semántica permite a los agentes recordar y recuperar interacciones pasadas almacenando mensajes como incrustaciones en una base de datos vectorial. Esto permite a los agentes mantener el contexto y la continuidad de la conversación a largo plazo. Elasticsearch es un excelente almacén vectorial para habilitar esta función, ya que soporta una búsqueda vectorial densa eficiente. Cuando se activa la recuperación semántica, el agente extrae mensajes pasados relevantes en la ventana de contexto del modelo, permitiendo que el modelo emplee ese contexto recuperado como base para su razonamiento y respuestas.
Lo que necesitas para empezar
- Nodo v18+
- Elasticsearch (versión 8.15 o posterior)
- Clave API de Elasticsearch
- Clave API de OpenAI
Nota: Necesitarás esto porque la demo usa el proveedor OpenAI, pero Mastra soporta otros SDKs de IA y proveedores de modelos comunitarios, así que puedes cambiarlo fácilmente según tu configuración.
Construyendo un proyecto de Mastra
Emplearemos la CLI integrada de Mamra para proporcionar el andamiaje de nuestro proyecto. Ejecuta el comando:
Recibirás un conjunto de indicaciones, que empiezan por:
1. Pon un nombre a tu proyecto.

2. Podemos mantener este valor predeterminado; No dudes en dejar esto en blanco.

3. Para este proyecto, emplearemos un modelo proporcionado por OpenAI.

4. Selecciona la opción "Saltar por ahora" porque almacenaremos todas nuestras variables de entorno en un archivo '.env' que configuraremos en un paso posterior.

5. También podemos saltar esta opción.

Saltar la instalación del servidor MCP de Mamra
Una vez que termines de inicializar, podemos pasar al siguiente paso.
Instalación de dependencias
A continuación, necesitamos instalar algunas dependencias:
ai- Paquete básico de SDK de IA que proporciona herramientas para gestionar modelos de IA, prompts y flujos de trabajo en JavaScript/TypeScript. Mastra está construido sobre el SDK de IA por Vercel, así que necesitamos esta dependencia para permitir la interacción del modelo con tu agente.@ai-sdk/openai- Plugin que conecta el SDK de IA con modelos OpenAI (como GPT-4, GPT-4o, etc.), habilitando llamadas API usando tu clave API OpenAI.@elastic/elasticsearch- Cliente oficial de Elasticsearch para Node.js, se emplea para conectarse a tu Elastic Cloud o a un clúster local para operaciones de indexación, búsqueda y vectores.dotenv- Carga variables de entorno desde un .env archivar en process.env, permitiendo inyectar de forma segura credenciales como claves API y endpoints Elasticsearch.
Configuración de variables de entorno
Crea un archivo .env en el directorio raíz de tu proyecto si aún no ves uno. Alternativamente, puedes copiar y renombrar el ejemplo .env que proporcioné en el repositorio. En este archivo, podemos agregar las siguientes variables:
Eso concluye la configuración básica. Desde aquí, ya puedes empezar a construir y orquestar agentes. Vamos un paso más allá y agregaremos Elasticsearch como la capa de almacenamiento y búsqueda vectorial.
Agregar Elasticsearch como almacenamiento vectorial
Crea una nueva carpeta llamada stores y dentro, agrega este archivo. Antes de que Mastra y Elastic lanzaran una integración oficial de almacenamiento vectorial de Elasticsearch, Abhi Aiyer(CTO de Mestra) compartió esta clase prototipo temprana llamada ElasticVector. Simplemente, conecta la abstracción de memoria de Mamra con las densas capacidades vectoriales de Elasticsearch, para que los desarrolladores puedan incluir Elasticsearch como base de datos vectorial para sus agentes.
Echemos un vistazo más profundo a las partes importantes de la integración:
Ingestión del cliente Elasticsearch
Esta sección define la clase ElasticVector y configura la conexión cliente de Elasticsearch con soporte tanto para despliegues estándar como serverless.
ElasticVectorConfig extends ClientOptions: Esto crea una nueva interfaz de configuración que hereda todas las opciones del cliente de Elasticsearch (comonode,auth,requestTimeout) y agrega nuestras propiedades personalizadas. Esto significa que los usuarios pueden pasar cualquier configuración válida de Elasticsearch junto con nuestras opciones específicas para serverless.extends MastraVector: Esto permiteElasticVectorheredar de la clase base deMastraVectorde Mastra, que es una interfaz común a la que se ajustan todas las integraciones de almacenamiento vectorial. Esto garantiza que Elasticsearch se comporte como cualquier otro backend de vectores Mastra desde la perspectiva del agente.private client: Client: Esta es una propiedad privada que contiene una instancia del cliente JavaScript Elasticsearch. Esto permite que la clase hable directamente con tu grupo.isServerlessydeploymentChecked: Estas propiedades trabajan juntas para detectar y almacenar en caché si estamos conectados a un despliegue serverless o estándar de Elasticsearch. Esta detección ocurre automáticamente en el primer uso, o puede configurar explícitamente.constructor(config: ClientOptions): Este constructor toma un objeto de configuración (que contiene tus credenciales de Elasticsearch y configuraciones opcionales de serverless) y lo emplea para inicializar el cliente en la líneathis.client = new Client(config).super(): Esto llama constructor base de Mastra, por lo que hereda el registro, los asistentes de validación y otros ganchos internos.
En este punto, Mastra sabe que hay un nuevo almacén vectorial llamado ElasticVector
Detección del tipo de despliegue
Antes de crear índices, el adaptador detecta automáticamente si estás usando Elasticsearch estándar o Elasticsearch Serverless. Esto es importante porque los despliegues serverless no permiten la configuración manual de shards.
Qué pasa:
- Primero comprueba si pusiste explícitamente
isServerlessen la configuración (se salta la auto-detección). - Llama a la API
info()de Elasticsearch para obtener información del clúster - Comprueba el
build_flavor field(los despliegues serverless devuelvenserverless) - Vuelve a revisar el lema si no hay variedad de build disponible
- Almacena en caché el resultado para evitar llamadas repetidas a la API
- Por defecto se aplica al despliegue estándar si falla la detección
Ejemplo de uso:
Creación del almacén de "memoria" en Elasticsearch
La función siguiente establece un índice Elasticsearch para almacenar incrustaciones. Comprueba si el índice ya existe. Si no, crea uno con el mapeo que aparece abajo y contiene un campo dense_vector para almacenar incrustaciones y métricas de similitud personalizadas.
Algunas cosas a tener en cuenta:
- El parámetro
dimensiones la longitud de cada vector de incrustación, que depende del modelo de incrustación que estés usando. En nuestro caso, generaremos incrustaciones usando el modelotext-embedding-3-smallde OpenAI, que genera vectores de tamaño1536. Usaremos esto como nuestro valor por defecto. - La variable
similarityempleada en el mapeo a continuación se define a partir de la función auxiliar const similarity = this.mapMetricToSimilarity(metric), que toma el valor del parámetrometricy lo convierte en una palabra clave compatible con Elasticsearch para la métrica de distancia elegida.- Por ejemplo: Mastra emplea términos generales para similitud vectorial como
cosine,euclidean, ydotproduct. Si pasáramos la métricaeuclideandirectamente al mapeo de Elasticsearch, generaría un error porque Elasticsearch espera que la palabra clavel2_normrepresente la distancia euclidiana.
- Por ejemplo: Mastra emplea términos generales para similitud vectorial como
- Compatibilidad sin servidor: El código omite automáticamente los ajustes de shard y réplica para despliegues sin servidor, ya que estos son gestionados automáticamente por Elasticsearch Serverless.
Almacenar una nueva recordación o nota tras una interacción
Esta función toma nuevas incrustaciones generadas tras cada interacción, junto con los metadatos, y luego las inserta o actualiza en el índice usando la API bulk de Elastic. La API bulk agrupa múltiples operaciones de escritura en una sola solicitud; Esta mejora en nuestro rendimiento de indexación garantiza que las actualizaciones se mantengan eficientes a medida que la memoria de nuestro agente sigue creciendo.
Consulta de vectores similares para la recuperación semántica
Esta función es el núcleo de la característica de recuperación semántica. El agente emplea búsqueda vectorial para encontrar incrustaciones almacenadas similares dentro de nuestro índice.
Bajo el capó:
- Ejecuta una consulta kNN (k-vecinos más cercanos) usando la API
knnen Elasticsearch. - Recupera los vectores top-K similares al vector de consulta de entrada.
- Opcionalmente, aplica filtros de metadatos para reducir resultados (por ejemplo, buscar solo dentro de una categoría o rango de tiempo específico)
- Devuelve resultados estructurados que incluyen el ID del documento, el puntaje de similitud y los metadatos almacenados.
Creación del agente del conocimiento
Ahora que vimos la conexión entre Mastra y Elasticsearch a través de la integración ElasticVector , creemos el propio Knowledge Agent.
Dentro de la carpeta agents, crea un archivo llamado knowledge-agent.ts. Podemos empezar conectando nuestras variables de entorno e inicializando el cliente Elasticsearch.
Aquí, nosotros:
- Usa
dotenvpara cargar nuestras variables desde nuestro archivo.env. - Comprueba si las credenciales de Elasticsearch se están inyectando correctamente y podemos establecer una conexión exitosa con el cliente.
- Pasa el endpoint de Elasticsearch y la clave API al constructor
ElasticVectorpara crear una instancia de nuestro almacén vectorial que definimos antes. - Opcionalmente, especifica
isServerless: truesi usas Elasticsearch Serverless. Esto omite el paso de detección automática y mejora el tiempo de arranque. Si se omite, el adaptador detectará automáticamente el tipo de despliegue en el primer uso.
A continuación, podemos definir el agente usando la clase Agent de Mastra.
Los campos que podemos definir son:
nameyinstructions: Darle una identidad y función primaria.model: Estamos usando lagpt-4ode OpenAI a través del paquete@ai-sdk/openai.memory:vector: Apunta a nuestra tienda Elasticsearch, así que los embeddings se almacenan y recuperan desde allí.embedder: Qué modelo usar para generar incrustacionessemanticRecallLas opciones deciden cómo funciona la retirada:topK: Cuántos mensajes semánticamente similares recuperar.messageRange: Cuánto de la conversación incluir en cada partido.scope: Define el límite de la memoria.
Casi termino. Solo tenemos que agregar este agente recién creado a nuestra configuración de Mestra. En el archivo llamado index.ts, importa el agente de conocimiento e insértalo en el campo agents .
Los otros campos incluyen:
storage: Este es el almacén interno de datos de Mamra para historial de ejecuciones, métricas de observabilidad, puntajes y cachés. Para más información sobre el almacenamiento de mastras, visita aquí.logger: Mastra emplea Pino, que es un registrador JSON estructurado y ligero. Captura eventos como inicios y atajada de agentes, llamadas y resultados de herramientas, errores y tiempos de respuesta de los LLM.observability: Controla el rastreo de IA y la visibilidad de ejecución de los agentes. Sigue lo siguiente:- Inicio/final de cada paso de razonamiento.
- Qué modelo o herramienta se empleó.
- Entradas y salidas.
- Puntajes y evaluaciones
Probando al agente con Mastra Studio
¡Felicidades! Si llegaste hasta aquí, estás listo para ejecutar este agente y probar sus capacidades semánticas de recuperación. Por suerte, Mastra ofrece una interfaz de chat integrada para que no tengamos que crear la nuestra.
Para iniciar el servidor de desarrollo de Mestra, abre un terminal y ejecuta el siguiente comando:
Tras el empaquetado y el arranque inicial del servidor, debería proporcionarte una dirección del Playground.

Pega esta dirección en tu navegador y te recibirás con Mastra Studio.
Selecciona la opción de knowledgeAgent y charla sin parar.
Para una prueba rápida y ver si todo está correctamente cableado, dale información como: "El equipo anunció que el rendimiento de ventas en octubre subió un 12%, impulsado principalmente por renovaciones empresariales. El siguiente paso es ampliar su alcance a clientes de gama media." Después, inicia un nuevo chat y haz una pregunta como: "¿En qué segmento de clientes dijimos que debemos centrarnos a continuación?" El agente de conocimiento debería ser capaz de recordar la información que le diste en el primer chat. Deberías ver una respuesta como:

Ver una respuesta así significa que el agente almacenó con éxito nuestro mensaje anterior como incrustaciones en Elasticsearch y lo recuperó después usando búsqueda vectorial.
Inspección del almacenamiento de memoria a largo plazo del agente
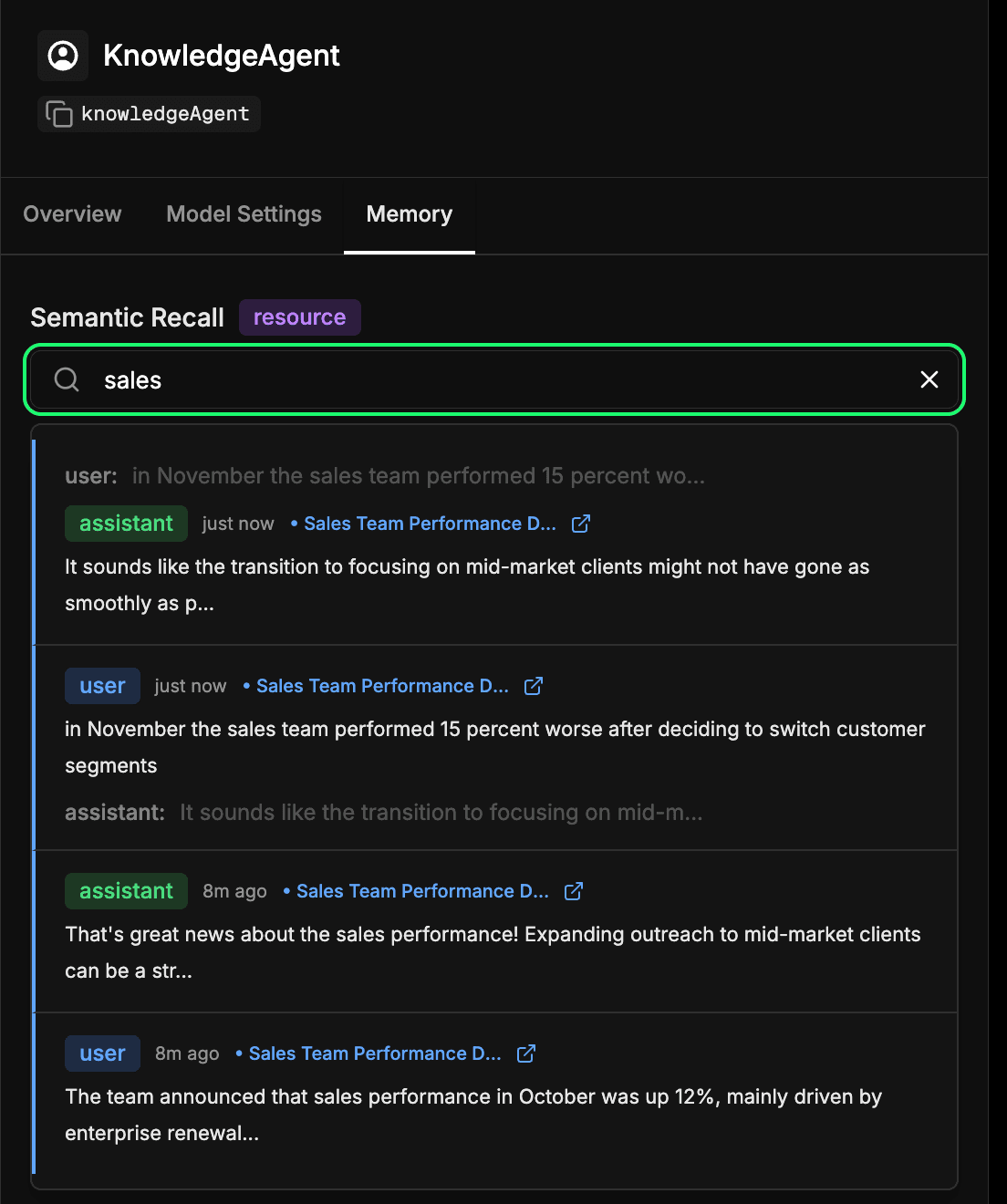
Ve a la pestaña memory en la configuración de tu agente en Mastra Studio. Esto te permite ver lo que tu agente aprendió con el tiempo. Cada mensaje, respuesta e interacción que se incrusta y almacena en Elasticsearch pasa a formar parte de esta memoria a largo plazo. Puedes buscar semánticamente en interacciones pasadas para encontrar rápidamente información o contexto recordado que el agente aprendió antes. Este es esencialmente el mismo mecanismo que emplea el agente durante la recuperación semántica, pero aquí puedes inspeccionarlo directamente. En nuestro ejemplo a continuación, buscamos el término "ventas" y recibimos cada interacción que incluyera algo relacionado con las ventas.
Conclusión
Al conectar Mastra y Elasticsearch, podemos dar memoria a nuestros agentes, que es una capa clave en la ingeniería de contexto. Con la memoria semántica, los agentes pueden construir contexto con el tiempo, basando sus respuestas en lo que aprendieron. Eso significa interacciones más precisas, fiables y naturales.
Esta integración temprana es solo el punto de partida. El mismo patrón aquí puede permitir que los agentes de soporte recuerden tiquetes anteriores, bots internos que recuperen la documentación relevante o asistentes de IA que puedan recuperar detalles de los clientes en medio de una conversación. También estamos trabajando en una integración oficial de Mestra, haciendo que esta pareja sea aún más fluida en un futuro próximo.
Estamos deseando ver qué construyes a continuación. Pruébalo, explora Mastra y sus funciones de memoria, y siéntete libre de compartir lo que descubras con la comunidad.
Contenido relacionado

11 de mayo de 2026
Potenciando Elasticsearch: agregamos soporte nativo de la API de Prometheus
Realiza una búsqueda en Elasticsearch directamente desde clientes compatibles con Prometheus a través de endpoints nativos de PromQL, descubrimiento y metadatos. Envía datos a Elasticsearch con Prometheus Remote Write.

20 de abril de 2026
Introducción de claves API unificadas para Elastic Cloud Serverless y Elasticsearch
Aprende cómo Elastic unificó la autenticación del plano de control y del plano de datos en Serverless con una arquitectura de IAM distribuida globalmente. Usa una sola clave de API para las API de Cloud y de Elasticsearch.

8 de abril de 2026
Cómo construir aplicaciones de IA con agentes con Mastra y Elasticsearch
Aprende a construir aplicaciones de IA agéntica usando Mastra y Elasticsearch a través de un ejemplo práctico.
3 de abril de 2026
Monitoreo de las vistas del dashboard de Kibana con flujos de trabajo de Elastic
Conoce cómo usar flujos de trabajo de Elastic para recopilar métricas de vista del dashboard de Kibana cada 30 minutos e indexarlas en Elasticsearch, para que puedas crear análisis y vistas personalizadas sobre tus propios datos.

25 de marzo de 2026
La herramienta de shell no es una solución mágica para la ingeniería de contexto
Aprenda qué herramientas de recuperación de contexto existen para la ingeniería de contexto, cómo funcionan y sus compensaciones.