Así fue como construimos una plataforma de gestión de dependencias autohospedada mediante Kubernetes, Argo Workflows, Argo Events y Renovate CLI para automatizar actualizaciones, abordar rápidamente vulnerabilidades y exposiciones comunes (CVE), y propagar eficientemente nuevas versiones de paquetes en miles de repositorios.
Gestión de dependencias en Elastic
En Elastic, tenemos que gestionar cientos o incluso miles de repositorios, tanto privados como públicos. Cuando se descubre una CVE crítica, necesitamos respuestas y acciones inmediatas: ¿qué repositorios son vulnerables? ¿Con qué rapidez podemos solucionarlos? Además de la seguridad, surgen cuestiones relacionadas con la productividad: ¿cómo podemos propagar rápidamente el lanzamiento de una nueva versión de un paquete a todos los repositorios que dependen de él, sin dedicar demasiado tiempo a tareas manuales?
El disparador inicial para buscar formas de hacer la gestión de dependencias fue la necesidad de establecer una base segura con actualizaciones automatizadas para reducir los CVEs. Después de considerar cuidadosamente las soluciones para la gestión de dependencias, empezamos a trabajar en una infraestructura autohospedada. Usábamos nuestro propio clúster de Kubernetes para ejecutar Mend Renovate Community Self-Hosted. La idea era poder ofrecer una plataforma de gestión de dependencias a la que nuestros usuarios pudieran acceder de forma autónoma.
El experimento inicial tuvo éxito, así que cada vez más equipos comenzaron a implementar nuestra plataforma y usarla en el ciclo de vida de sus repositorios diarios para actualizaciones y parches CVE. Esto sucedió tan rápido que pronto alcanzamos el límite de nuestra instalación autohospedada.

Fig. 1: Una visión general de alto nivel de la gestión de dependencias en Elastic
El reto: ¿Cómo podemos escalar una plataforma de gestión de dependencias en una gran organización con una cantidad significativa de repositorios?
Nuestra plataforma de gestión de dependencias procesaba un repositorio a la vez, entonces el modelo de procesamiento secuencial no podía seguir el ritmo debido a la gran cantidad de repositorios que tenemos. Ya habíamos identificado que el problema residía en el concepto de que una sola instancia de nuestra herramienta de gestión de dependencias podría procesar nuestra gran y siempre creciente lista de repositorios. Los repositorios esperaban en una cola, a veces durante muchas horas. Más del 50 % de nuestros repositorios ni siquiera se procesaban diariamente. Eso significa que más del 50 % de nuestros repositorios esperaron más de 24 horas entre los escaneos.
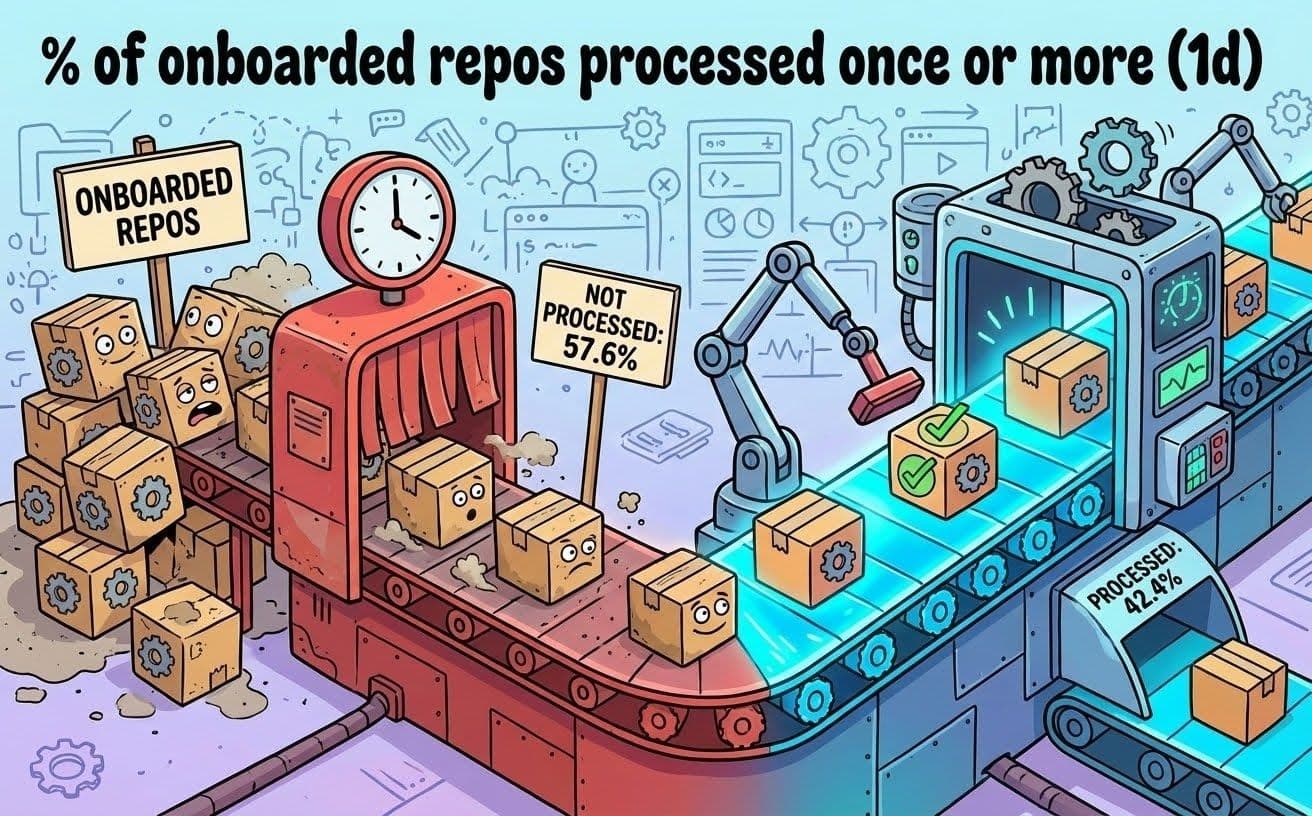
Fig. 2: Cantidad de repositorios procesados al menos una vez al día (hechos con Nano Banana)
Los grandes repositorios creaban cuellos de botella mayores, debido a sus grandes bases de código y a sus múltiples PRs abiertas. Los eventos de webhook de GitHub interrumpieron la secuencia. Automerge se volvió poco confiable debido a que el tiempo de escaneo era impredecible. Habíamos hecho una promesa a nuestros usuarios sobre la frecuencia de los escaneos y no pudimos cumplirla.
La decisión de integrarnos internamente: satisfacer las necesidades únicas de escalabilidad y seguridad de Elastic
Aunque considerábamos opciones comerciales, como la edición Renovate autohospedada empresarial de Mend, internamente en Elastic teníamos algunas iniciativas clave en marcha.
Nuestra decisión de crear una plataforma interna se basó en el reconocimiento de que solo una solución altamente personalizada podría satisfacer los requisitos específicos e innegociables de Elastic:
- Inversión en nuestra plataforma interna para desarrolladores: en ese momento, ya habíamos comenzado a invertir considerablemente en nuestra plataforma interna para desarrolladores. Estábamos discutiendo y diseñando formas en las que cada uno de nuestros servicios pudiera encajar. Esto significaba que queríamos probar nuestras propias reglas y prácticas para nuestra plataforma de gestión de dependencias. Además de eso, entraban en juego nuevas pautas y queríamos diseñar la plataforma antes de los eventos.
- Integración nativa y personalización del flujo de trabajo: requeríamos una integración directa con nuestras herramientas y procesos internos. Por ejemplo, queríamos centralizar la configuración como código con nuestro Catálogo de servicios (Backstage). Tenemos necesidades específicas sobre el uso de Backstage con las que queríamos que nuestra plataforma fuera compatible. Así que, aunque fuera posible usar las API de Renovate autohospedadas junto con nuestra automatización de Backstage, esto no cubriría completamente nuestros procesos internos.
- Seguridad en profundidad específica de Elastic: nuestro cumplimiento de seguridad estricto requería mecanismos personalizados adaptados a nuestro ecosistema. Estábamos trabajando para fortalecer nuestro uso de “identidades no humanas”. Las medidas de seguridad implementadas implicaban que los métodos no estándar de autenticación en GitHub no funcionarían con una herramienta comercial que no fuera compatible con esta implementación interna. Nuestro flujo de trabajo incluía la implementación de un patrón de cifrado secreto de flujo de trabajo principal-secundario y el uso de tokens de GitHub transitorios y de un solo uso. La creación interna era la única forma práctica de integrar estas capas de seguridad únicas y minimizar la superficie de ataque en nuestro complejo entorno multinube.
La solución: Orquestación de flujo de trabajo para la gestión de dependencias
Nuestra solución partió del hecho de que queríamos basarnos en la herramienta de gestión de dependencias que ya usábamos, no reemplazarla y buscar otras soluciones. Había mostrado signos de su potencial, y su flexibilidad es importante para las distintas necesidades de toda nuestra organización. Consideramos diferentes soluciones, y lo que nos ayudó a decidir fueron las necesidades grandes y a veces especiales que tenemos que cubrir. Decidimos crear una plataforma de gestión de dependencias fiable y escalable, donde cada repositorio se procesa por sí mismo, lo que eliminaría los cuellos de botella y nos prepararía para crecer.
Diseñamos la plataforma mediante tres principios fundamentales:
1. Procesamiento en paralelo
Cada repositorio tiene su propio entorno de procesamiento de gestión de dependencias. No más colas. Nuestra concurrencia solo está limitada por la cantidad de recursos que gastamos. También aplicamos una programación distribuida inteligente para evitar que GitHub limite la velocidad.
2. Autoservicio
Usamos nuestro Catálogo de servicios (Backstage) para incorporar y gestionar automáticamente cualquier repositorio nuevo. Usamos nuestra propia definición de recursos para darle al usuario final la opción de seleccionar con qué frecuencia se procesará un repositorio, cuántos recursos quiere asignar a sus programaciones y si quiere desactivar o volver a activar el procesamiento por cualquier motivo. Planeamos agregar más opciones así a medida que las necesidades de nuestros usuarios evolucionen y se adapten mejor a la nueva instalación.
3. Alcance secreto reducido y aislamiento del espacio de nombres
Para aumentar la seguridad, suministramos a nuestros pods de gestión de dependencias tokens efímeros de GitHub que se generan al inicio de cada flujo de trabajo. Además, aislamos nuestras cargas de trabajo en espacios de nombres específicos para que solo se les proporcionen los secretos necesarios. Controlamos a qué secretos puede acceder cada uno de los flujos de trabajo de gestión de dependencias mediante Kubernetes RBAC. También utilizamos el cifrado para propagar el token de GitHub desde los flujos de trabajo principales a los secundarios.
Reconstruimos nuestra plataforma mediante Kubernetes y, al aprovechar el poder de Kubernetes, Argo Workflows impulsa la lógica de nuestros procesos, y Renovate CLI está configurado para escanear y procesar un repositorio a la vez.
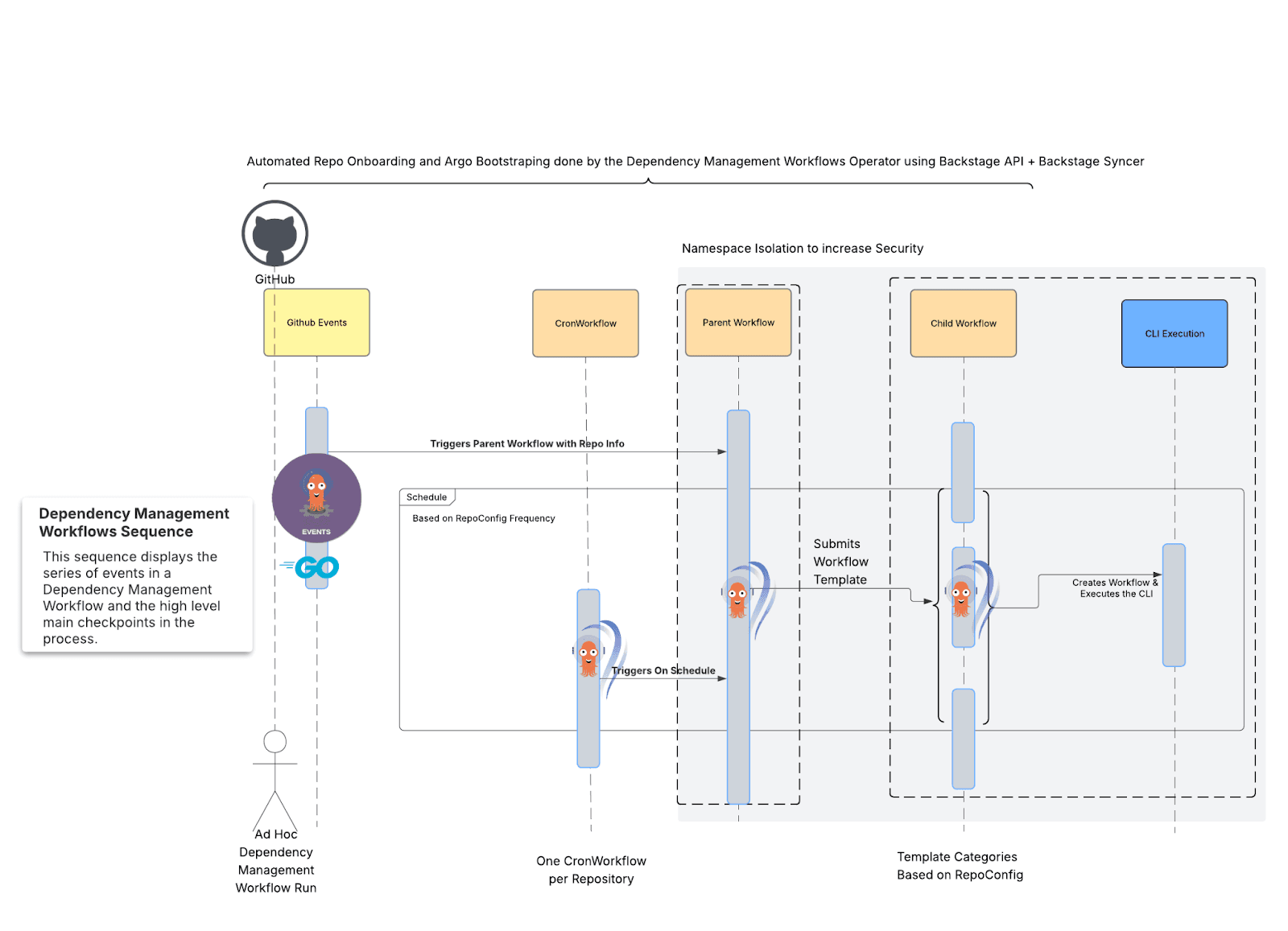
Fig. 3: Una visión general de alto nivel del nuevo proceso de flujos de trabajo de gestión de dependencias
La belleza: estamos utilizando proyectos de código abierto probados en batalla de una manera original, lo que ofrece nuevos ejemplos de trabajo para todos esos proyectos y, al mismo tiempo, aumenta la velocidad de desarrollo y consolida la reducción de CVE para nuestros equipos.
Arquitectura de gestión de dependencias: Cuatro microservicios
La plataforma cuenta con cuatro componentes personalizados:
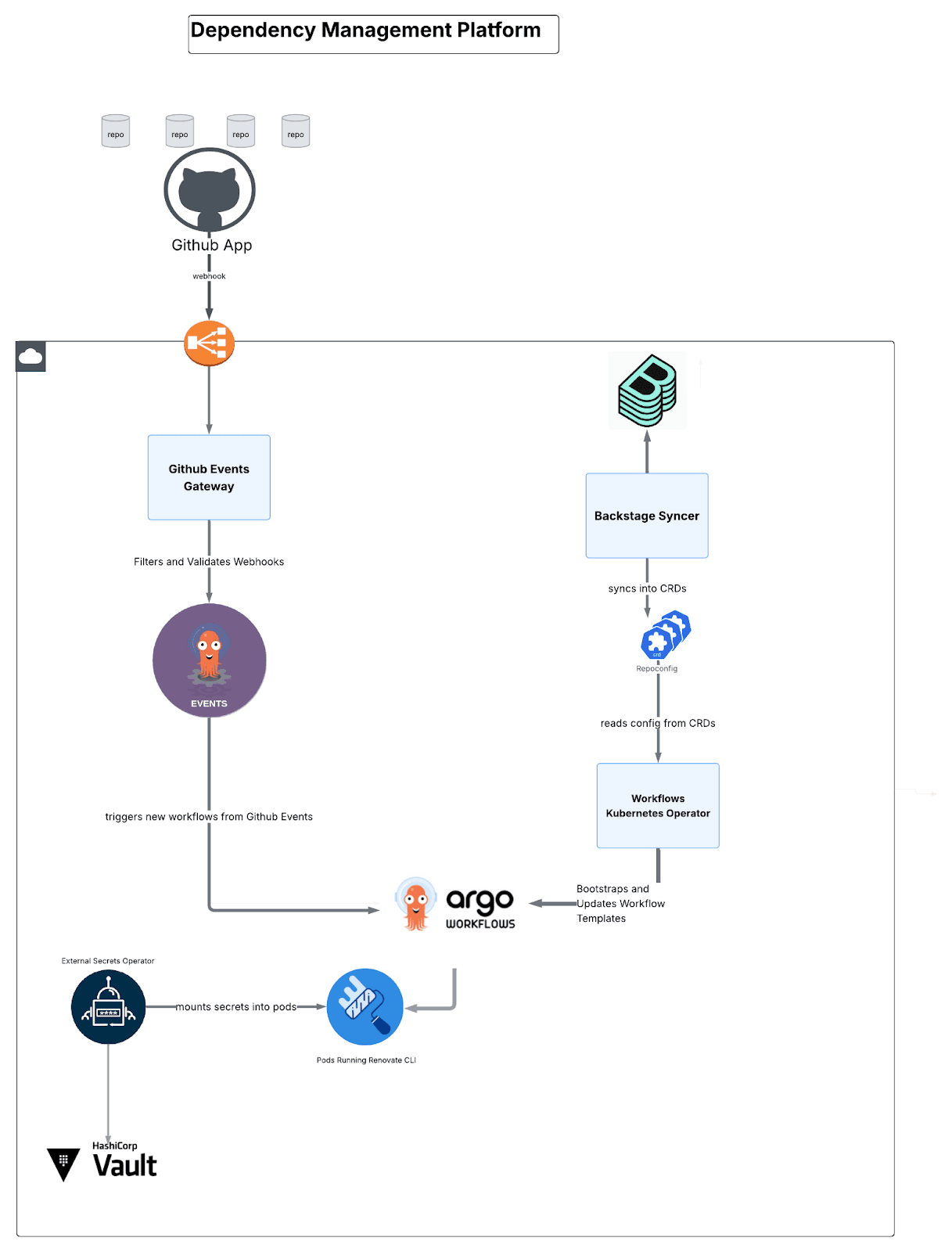
Fig. 4: Una visión general de alto nivel de cómo se conectan los componentes
Operador de los flujos de trabajo (Go/Kubebuilder)
Un operador de Kubernetes que gestiona el ciclo de vida del flujo de trabajo a través de tres definiciones de recursos personalizados (CRD):
- CRD de RepoConfig: Única fuente de verdad para la configuración de repositorios.
Así es como se define RepoConfig en el operador:
Y así es como se vería una instancia de RepoConfig:
- CRD principal: Gestiona CronWorkflows para escaneos programados.
Dentro del bucle de reconciliación del controlador principal, nos aseguramos de que los flujos de trabajo se creen y se mantengan actualizados o incluso se eliminen si es necesario.
En primer lugar, obtienes algunos ajustes configurados globalmente para los flujos de trabajo:
Se asegura de que un configmap de mutex esté actualizado para evitar que flujos de trabajo similares se ejecuten juntos:
Luego crea un gestor de flujo de trabajo que es la estructura que creará o actualizará los CronWorkflows y las plantillas de flujo de trabajo:
- CRD infantil: Gestiona las plantillas de flujo de trabajo con recursos por repositorio.
El controlador secundario tiene un deber de reconciliación similar al del padre, pero esta vez es responsable de las plantillas de flujo de trabajo en el espacio de nombres secundario que se activarán por los flujos de trabajo principales.
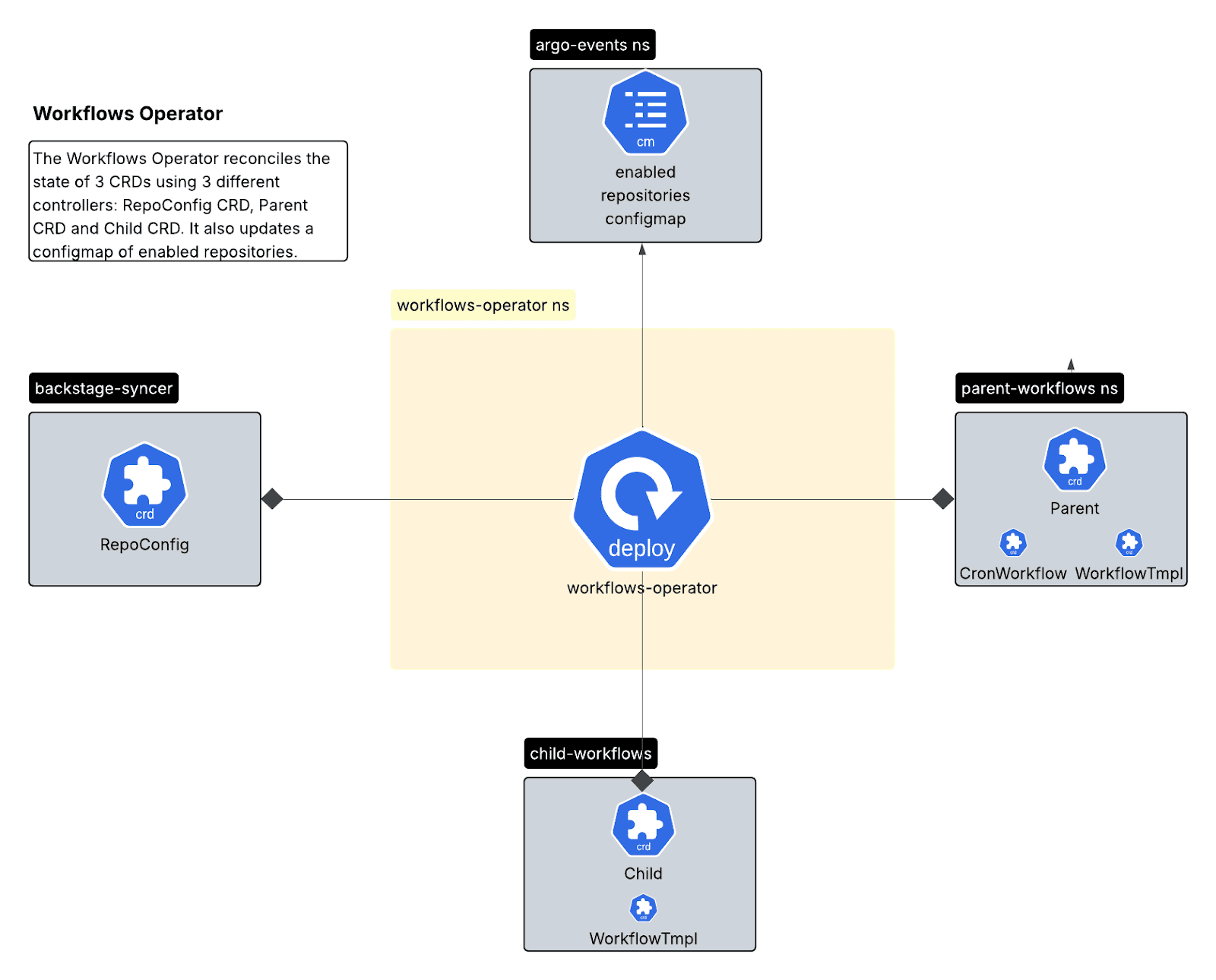
El patrón de controlador múltiple proporciona una clara separación: el controlador RepoConfig maneja la incorporación/eliminación, el controlador principal administra la programación y el controlador secundario maneja las plantillas de ejecución.
Puerta de enlace de eventos de GitHub (Go)
Un proxy de webhook seguro que recibe webhooks de GitHub, verifica firmas, filtra por organización/repositorio y los redirige a Argo Events. Creamos 10 sensores distintos que respondían a interacciones en paneles de dependencias, eventos de relaciones públicas y actualizaciones de paquetes.
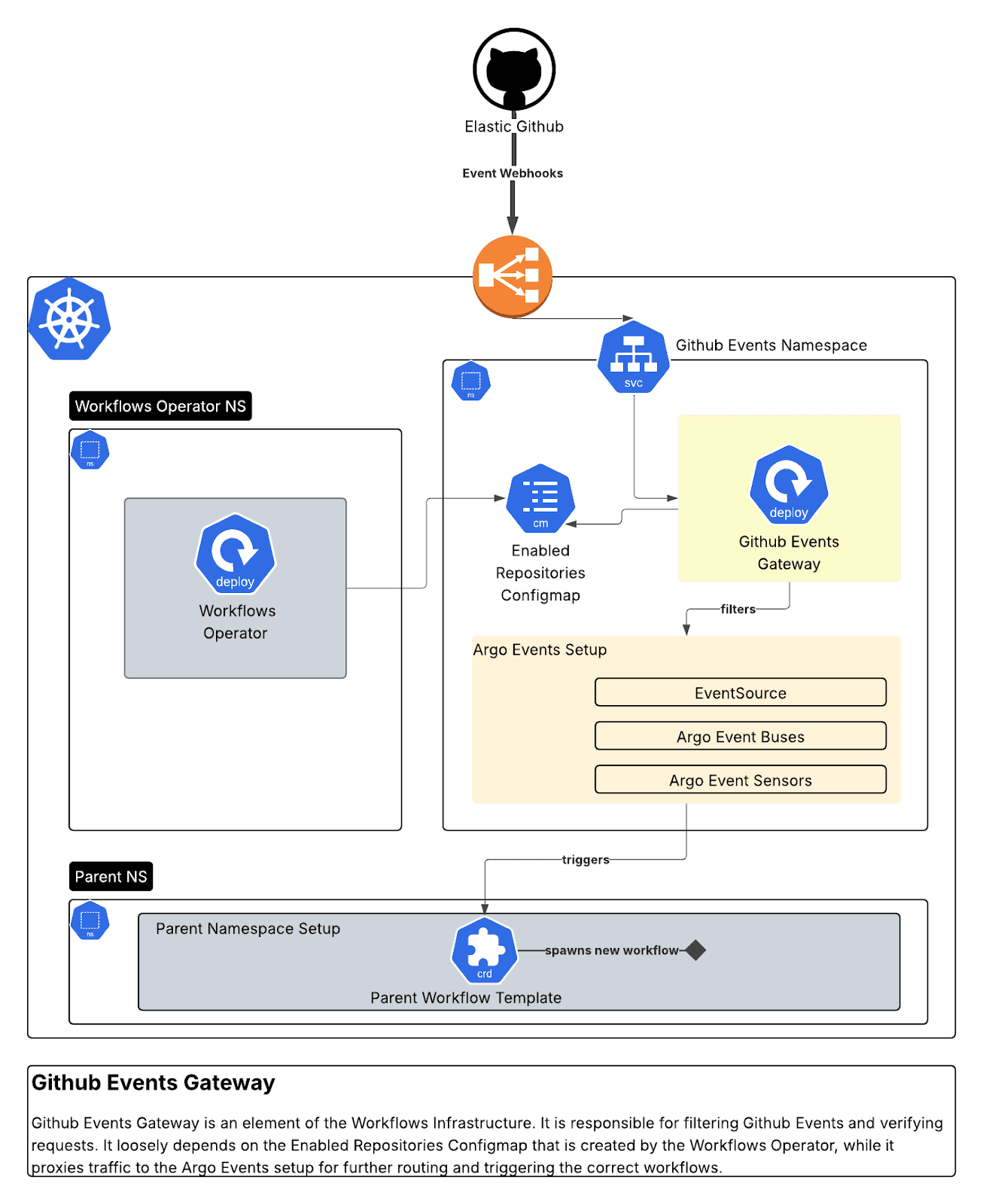
Este gateway permite la integración con las aplicaciones de GitHub de la siguiente manera:
- Verifica las firmas entrantes de webhook de GitHub para mayor seguridad.
- Reenvía eventos válidos al EventSource de Argo Events con todos los encabezados relevantes y la autenticación.
- También configuramos un AuthSecret en EventSource y lo proporcionamos como un encabezado Bearer en las solicitudes reenviadas.
- Proporcionamos logging, métricas y lógica de reintentos.
Realiza varias validaciones en cada solicitud de evento de GitHub.
Se asegura de que algunos atributos HTTP estén presentes:
Al mismo tiempo que valida la firma de cada solicitud y su organización:
Por último, se redirige a Argo Events según el tipo de evento:
En lo que respecta a Argo Events, 10 sensores vigilan el EventBus de Argo Events en busca de nuevos eventos.
Luego, el script aplica la lógica de cada sensor:
Backstage Syncer (Go)
Esto sondea nuestro catálogo de servicios (Backstage) para las entidades de recursos reales del repositorio, las transforma en CRD de RepoConfig y mantiene la Platform sincronizada con los cambios de configuración. Los cambios se aplican en tres minutos.
Por último, escribe esos datos en instancias de RepoConfig.
Base de flujos de trabajo (mixta: JavaScript, Go, Helm)
La capa base contiene gráficos de Helm, configuraciones de JavaScript, un contenedor Go para Renovate CLI con soporte de cifrado y un indexador APK personalizado para paquetes Alpine.
Fig. 5: Una vista de alto nivel de los componentes fundamentales (hechos con Nano Banana)
Configuración de autoservicio
Los equipos configuran sus repositorios de manera declarativa a través de Backstage:
Los grupos de recursos asignan CPU y memoria en función del tamaño del repositorio:
- PEQUEÑO: CPU de 500m, memoria 1Gi.
- MEDIO: CPU 1000m, memoria 2Gi.
- GRANDE: CPU de 2000 m, memoria de 4 Gi.
La configuración está bajo control de versiones, es auditable y se aplica automáticamente.
El patrón padre-hijo
El modelo de ejecución usa un patrón de flujo de trabajo primario y secundario:
- Flujo de trabajo principal: CronWorkflow ligero que se ejecuta según lo programado. Cifra los secretos, determina si se debe ejecutar un escaneo y pasa la configuración al secundario.
- Flujo de trabajo infantil: pod efímero donde se ejecuta Renovate CLI. Asigna recursos de forma dinámica, descifra secretos de forma aislada y se cierra al completar la tarea.
Esta separación proporciona seguridad (los secretos se cifran en el nivel superior), optimización de recursos (los niveles superiores utilizan recursos mínimos) y escalabilidad (los niveles inferiores se ejecutan en paralelo).
Los resultados
Transformación del rendimiento
- Antes: Un repositorio a la vez, algunos repositorios no se procesaban posiblemente incluso por un día o más, menos de 1000 escaneos por día.
- Después: más de 100 escaneos simultáneos, normalmente 8000 escaneos y hasta 10 000 escaneos registrados al día, limitados únicamente por la cantidad de recursos que estamos dispuestos a invertir y cómo gestionamos los límites de GitHub.
Rentabilidad
Sin embargo, por extraño que parezca, ejecutar 8000 pods al día puede darte el mismo resultado de forma mucho más económica que tener un pod de larga duración que intenta lograr los mismos resultados.
En la configuración anterior, ejecutábamos una sola instancia que, en un buen día, realizaba entre 500 y 600 escaneos. Al mismo tiempo, debido al hecho de que se ejecutarían diferentes tipos de repositorios en el mismo pod, necesitábamos dimensionar el pod para los más grandes. Ese tamaño sería mucho mayor que nuestra oferta extra grande actual, que usa 8 CPU para el pod y 16 GB de memoria.
Para cumplir con la salida diaria actual, el pod único tendría que ejecutarse durante 12 días. Entonces, al comparar el costo de un solo pod que funciona durante 12 días con 8000 pods de nuestro tamaño “MEDIO” funcionando cada día, nuestro nuevo diseño es mucho más eficiente para la misma salida de escaneos:
| Métrica | Escenario A (Flujos de trabajo) | Escenario B (El pod único de larga duración) |
|---|---|---|
| Configuración | 8000 pods (1 vCPU / 2 GB) | 1 pod (8 vCPU / 16 GB)* |
| Duración | 10 minutos cada uno | 12 días continuos |
| Tiempo total de trabajo | 1333 horas de procesamiento | 288 horas de computación |
| Costo total | $65,83 | $113,75 |
Sin embargo, tomemos en consideración que nuestro valor predeterminado para nuestras cargas de trabajo está configurado en “PEQUEÑO”, con la gran mayoría ejecutándose con éxito con 0.5 CPU y 1 G de RAM, y solo unos pocos necesitan cambiar a mediano y grande. Veamos qué sucede si el 60 % de nuestras cargas de trabajo se ejecutan en “PEQUEÑO”, el 30 % en “MEDIANO” y el 10 % en “GRANDE”, lo cual está más cerca de la realidad.
| Métrica | Escenario A (Enjambre mixto) | Escenario B (El corredor de fondo) |
|---|---|---|
| Estrategia | 8000 pods (tamaños mixtos) | 1 pod (8 vCPU / 16 GB)* |
| Duración | 10 minutos cada uno | 12 días continuos |
| Costo total | $52,66 | $113,75 |
| Ahorros | $61,09 (54 % más barato) | — |
Podemos ver que, con la misma salida, somos mucho más rentables en nuestra configuración actual.
Seguridad mejorada
- Tokens efímeros de GitHub (minutos de exposición versus días).
- Aislamiento del espacio de nombres con límites de control de acceso basado en roles (RBAC).
- Cifrado secreto en reposo en flujos de trabajo principales.
- Acceso directo a Vault eliminado.
Rendimiento previsible
Con una frecuencia de escaneo garantizada, finalmente podemos establecer Objetivos de nivel de servicio (SLO). La autofusión funciona de forma confiable. Los equipos confían en la plataforma para cumplir lo prometido.
Decisiones arquitectónicas clave
Aquí tienes algunas de las decisiones clave de diseño que moldearon el aspecto de la plataforma.
- ¿Por qué flujos de trabajo padre-hijo?
Adoptamos este patrón para aplicar una estrategia de defensa en profundidad. Al restringir las credenciales de alto valor (como los secretos de GitHub App) a un espacio de nombres dedicado y bloqueado, usamos RBAC para asegurarnos de que los pods de ejecución efímeros no puedan acceder arbitrariamente a datos confidenciales. Las vulnerabilidades recientes de la cadena de suministro (por ejemplo, los ataques "Shai Hulud" de integración continua/entrega continua [CI/CD]) han demostrado la importancia de aislar entornos de ejecución que ejecutan scripts dinámicos desde el almacén de credenciales.
Simultáneamente, este desacoplamiento permite una optimización granular de recursos. Los flujos de trabajo "primarios" actúan como orquestadores ligeros con una huella mínima, mientras que los flujos de trabajo "secundarios" manejan el escaneo de dependencia con uso intensivo de computación. Esta separación simplifica la gestión de ciclo de vida al permitirnos aplicar una lógica de reconciliación distinta a cada capa, lo que brinda a los usuarios control sobre los parámetros de ejecución (hijo) mientras conservamos el control administrativo sobre la programación y la infraestructura de seguridad (principal).
- ¿Por qué es de autoservicio?
Eliminar a nuestro equipo como un cuello de botella para la configuración del repositorio fue un requisito crítico. Nuestra misión era diseñar una plataforma escalable y de autoservicio capaz de admitir diversos casos de uso. Nos dimos cuenta de que actuar como filtros para cada cambio de configuración era insostenible, dado el gran volumen de repositorios. En su lugar, adoptamos una filosofía de habilitación: proporcionar los “rieles” (infraestructura y barandillas) mientras capacitamos a los usuarios para conducir los “trenes” (ejecución y personalización). Creemos que este cambio hacia la autonomía del equipo mejora significativamente la productividad al permitir a los usuarios adaptar el sistema a sus necesidades operativas específicas.
- ¿Por qué el patrón de Kubernetes Operator?
Como se mencionó anteriormente, un principio de diseño fundamental era garantizar que la plataforma fuera completamente de autoservicio. Necesitábamos un mecanismo automatizado para capturar la intención de los usuarios (como alternar escaneos, ajustar la frecuencia de programación o ajustar los límites de recursos de tiempo de ejecución) y propagar instantáneamente esos cambios a los flujos de trabajo subyacentes. Al anticipar los requisitos futuros, el sistema también necesitaba ser fácilmente extensible.
Para lograr esto, desarrollamos un Operador de Kubernetes para la gestión de dependencias personalizado. Al utilizar CRD como interfaz para la configuración, establecimos un bucle de reconciliación nativo de Kubernetes. Este operador monitoriza continuamente el estado deseado definido por el usuario y orquesta automáticamente las actualizaciones necesarias en la infraestructura del flujo de trabajo. Esto asegura una operación fluida y basada en eventos, donde la lógica de la plataforma maneja toda la complejidad detrás de escena.
- ¿Para qué sirve diseñar una puerta de enlace de eventos de GitHub?
Adoptar una arquitectura impulsada por eventos (EDA) fue esencial para la capacidad de respuesta de la plataforma. Aunque CronWorkflows proporcionaba un calendario de referencia fiable, requeríamos la agilidad para gestionar ejecuciones ad hoc, como que los usuarios activaran escaneos manualmente a través del panel. Para lograr esto, necesitábamos una puerta de enlace de ingestión dedicada para validar la integridad de la carga útil y enrutar las solicitudes de manera inteligente.
Evaluamos las soluciones existentes, incluido el GitHub EventSource nativo para Argo, pero identificamos riesgos significativos en cuanto a la sobrecarga operativa y las estrictas cuotas de la API de GitHub (por ejemplo, los límites de webhook por repositorio). En consecuencia, creamos una puerta de enlace personalizada para desacoplar nuestra infraestructura de estas limitaciones.
Crucialmente, esta puerta de enlace sirvió como un punto de control de tráfico estratégico durante nuestra migración. Actuó como un interruptor, lo que nos permitió realizar una implementación gradual y granular (cambio de tráfico) del sistema heredado a la nueva infraestructura. Esto garantizó que la incorporación de miles de repositorios fuera un proceso controlado y sin riesgos, en lugar de un cambio radical.
Lecciones aprendidas
Algunas lecciones que hemos aprendido van de la mano con el código fuente de Elastic:
- El cliente primero: las plataformas están diseñadas para los usuarios. Por eso es importante tener las necesidades de los usuarios como prioridad número uno. Esto moldea la plataforma en una infraestructura y aplicaciones diseñadas de manera eficiente que reducen la fricción con los usuarios, simplifican el escalado de la plataforma y facilitan la adopción.
- Espacio-tiempo: a veces el camino de menor resistencia lleva a arenas movedizas. Inicialmente, intentamos optimizar el modelo de procesamiento secuencial existente, pero esto no resolvió nuestros problemas. De hecho, solo introdujo más complejidad y cabos sueltos. La audaz decisión de rediseñar la plataforma con procesamiento paralelo requirió un esfuerzo inicial significativo. Sin embargo, finalmente allanó el camino para un crecimiento sostenible de la plataforma y prácticamente eliminó el tedioso trabajo administrativo diario.
- Depende: una plataforma no puede operar de forma aislada. Su éxito depende de qué tan bien se integre con el ecosistema más amplio. En nuestro caso, la integración con Backstage fue crítica, ya que sirve como la única fuente de verdad para la incorporación fluida de servicios. Del mismo modo, conectarnos a Artifactory nos permitió gestionar las actualizaciones de paquetes privados de manera eficiente, y la lista de integraciones esenciales continúa.
- Progreso, perfección simple: a lo largo de la implementación, sometimos constantemente a prueba nuestras hipótesis iniciales y nos adaptamos a los nuevos obstáculos que iban surgiendo. En lugar de quedar paralizados por el perfeccionismo, adoptamos un enfoque iterativo, abordamos los desafíos uno por uno y ajustamos nuestra estrategia de migración para cumplir con las condiciones del mundo real.
Lo que se viene
La entrega de la plataforma nos permite realizar un trabajo más significativo que nos ayudará a mejorar la UX y la eficiencia de nuestra plataforma. Algunos ejemplos son:
- Aumento y protección de la adopción de la fusión automática
La característica de fusión automática acelera significativamente la velocidad del equipo al eliminar las tareas manuales tediosas. Sin embargo, tenemos que asegurarnos de que haya barreras estrictas para garantizar que este aumento de velocidad no se haga a expensas de la seguridad.
- Mejora la observabilidad en torno a la experiencia del usuario final
Una prioridad fundamental de nuestra hoja de ruta es mejorar la observabilidad, no solo a nivel de plataforma, sino también específicamente desde la perspectiva del usuario final. Aunque capturar métricas de infraestructura es sencillo, comprender la experiencia real del usuario requiere conocimientos más profundos. Estamos trabajando para definir los indicadores de rendimiento (KPI) centrados en el usuario de núcleo para que nuestra telemetría pueda detectar los puntos de fricción y los problemas de rendimiento antes de que se conviertan en quejas de los usuarios.
- Elimina obstáculos para una mayor adopción
De cara al futuro, nuestra prioridad es identificar y eliminar cualquier barrera que dificulte la adopción de plataformas. Ya sea que esto requiera desarrollar nuevas integraciones o desplegar conjuntos de características específicas, estamos comprometidos con la planificación basada en datos. Construimos con éxito una plataforma diseñada para escalar; nuestro enfoque ahora cambia a maximizar su potencial.
El panorama general
El proyecto de flujos de trabajo de gestión de dependencias demuestra un principio más amplio: cuando necesites escalar herramientas de código abierto más allá de su modelo de despliegue predeterminado, los patrones nativos de Kubernetes proporcionan un camino a seguir.
Al adoptar:
- CRDs para configuración.
- Operadores para la gestión de ciclo de vida.
- Arquitectura basada en eventos para mayor capacidad de respuesta.
- GitOps para el despliegue.
Creamos una orquestación que escala independientemente de la cantidad de repositorios que gestiona. El rendimiento de escanear un solo repositorio es el mismo tanto si gestionamos 100 como si gestionamos 1000.
Cuando se anuncia un CVE crítico, ahora tenemos respuestas en minutos, no en horas. Esa es la diferencia entre un cuello de botella y una ventaja competitiva.
Agradecimientos
Esta plataforma se basa en excelentes herramientas de código abierto:
- Kubebuilder: el marco de trabajo de código abierto que usamos para poner en marcha nuestros operadores Kubernetes que inician y orquestan nuestros flujos de trabajo. [1][2]
- Backstage: el marco de trabajo de código abierto sobre el cual hemos construido nuestro catálogo de servicios y que utilizamos como nuestra fuente de la verdad. [1][2]
- Argo Workflows y Argo Events: la suite de código abierto que usábamos para orquestar procesos complejos y agregar procesamiento dinámico basado en eventos. [1][2][3][4]
- Renovate CLI: la herramienta de gestión de dependencias de código abierto que procesa nuestros repositorios. [1][2]
* El modelo de precios de AWS Fargate se usó como referencia para el costo de un solo pod, aunque nuestras cargas de trabajo no se ejecutan necesariamente en AWS y se ejecutan en clústeres de Kubernetes completos.
Contenido relacionado

20 de abril de 2026
Introducción de claves API unificadas para Elastic Cloud Serverless y Elasticsearch
Aprende cómo Elastic unificó la autenticación del plano de control y del plano de datos en Serverless con una arquitectura de IAM distribuida globalmente. Usa una sola clave de API para las API de Cloud y de Elasticsearch.
3 de abril de 2026
Monitoreo de las vistas del dashboard de Kibana con flujos de trabajo de Elastic
Conoce cómo usar flujos de trabajo de Elastic para recopilar métricas de vista del dashboard de Kibana cada 30 minutos e indexarlas en Elasticsearch, para que puedas crear análisis y vistas personalizadas sobre tus propios datos.

7 de noviembre de 2025
Introducción de la interfaz de reglas de consulta Elasticsearch en Kibana
Aprende a usar la interfaz de Reglas de Consulta de Elasticsearch para agregar o excluir documentos de consultas de búsqueda usando conjuntos de reglas personalizables en Kibana, sin afectar al ranking orgánico.

6 de noviembre de 2025
Construir un agente de conocimiento con recordación semántica usando Mastra y Elasticsearch
Aprende a construir un agente de conocimiento con recordación semántica usando Mastra y Elasticsearch como almacén vectorial para la recuperación de memoria e información.

22 de mayo de 2026
Kibana reduce el tiempo de carga del dashboard hasta en un 25 %: esta es la estrategia de sondeo que hay detrás
Descubre cómo Kibana usa el sondeo continuo y la detección de HTTP/2 en el navegador para reducir los tiempos de carga del dashboard hasta en un 25 %, con una transición automática a HTTP/1 en caso de que no sea posible.