Foi assim que construímos uma plataforma de gerenciamento de dependências auto-hospedada usando Kubernetes, Argo Workflows, Argo Events e CLI de Renovate para automatizar atualizações, corrigir de forma rápida vulnerabilidades e exposições comuns (CVEs) e propagar com eficiência novas versões de pacotes em milhares de repositórios.
Gerenciamento de dependências no Elastic
Na Elastic, precisamos gerenciar centenas ou até milhares de repositórios, tanto privados quanto públicos. Quando um CVE crítico é descoberto, precisamos de respostas e ações imediatas: quais repositórios são vulneráveis? Com que rapidez podemos corrigir os problemas? Além da segurança, também surgem questões de produtividade: como podemos propagar de forma rápida o lançamento de uma nova versão do pacote em todos os repositórios que dependem dela sem gastar muito tempo em tarefas manuais?
O gatilho inicial para pesquisar maneiras de fazer o gerenciamento de dependências foi a necessidade de estabelecer uma base segura com atualizações automatizadas para reduzir os CVEs. Após considerar cuidadosamente soluções para gerenciamento de dependências, começamos a trabalhar em uma infraestrutura auto-hospedada. Estávamos usando nosso próprio cluster Kubernetes para executar o Mend Renovate Community Self-Hosted. A ideia era fornecer uma plataforma de gerenciamento de dependências que nossos usuários pudessem acessar de forma autônoma.
O experimento inicial foi bem-sucedido, então mais e mais equipes começaram a integrar nossa plataforma e usá-la no ciclo de vida diário dos repositórios para atualizações e patches de CVE. Isso aconteceu tão rápido que logo chegamos ao limite da nossa instalação auto-hospedada.

Fig. 1: Uma visão geral de alto nível do gerenciamento de dependências na Elastic.
O desafio: como podemos redimensionar uma plataforma de gerenciamento de dependências em uma grande organização com um número significativo de repositórios?
Nossa plataforma de gerenciamento de dependências estava processando um repositório por vez e o modelo de processamento sequencial não conseguia acompanhar, devido ao grande número de repositórios que possuímos. Já havíamos identificado que o problema residia no conceito de que uma única instância de nossa ferramenta de gerenciamento de dependências poderia processar nossa grande e crescente lista de repositórios. Repositórios aguardavam em uma fila, às vezes por muitas horas. Mais de 50% dos nossos repositórios nem sequer eram processados diariamente. Isso significa que mais de 50% dos nossos repositórios esperaram mais de 24 horas entre as varreduras.
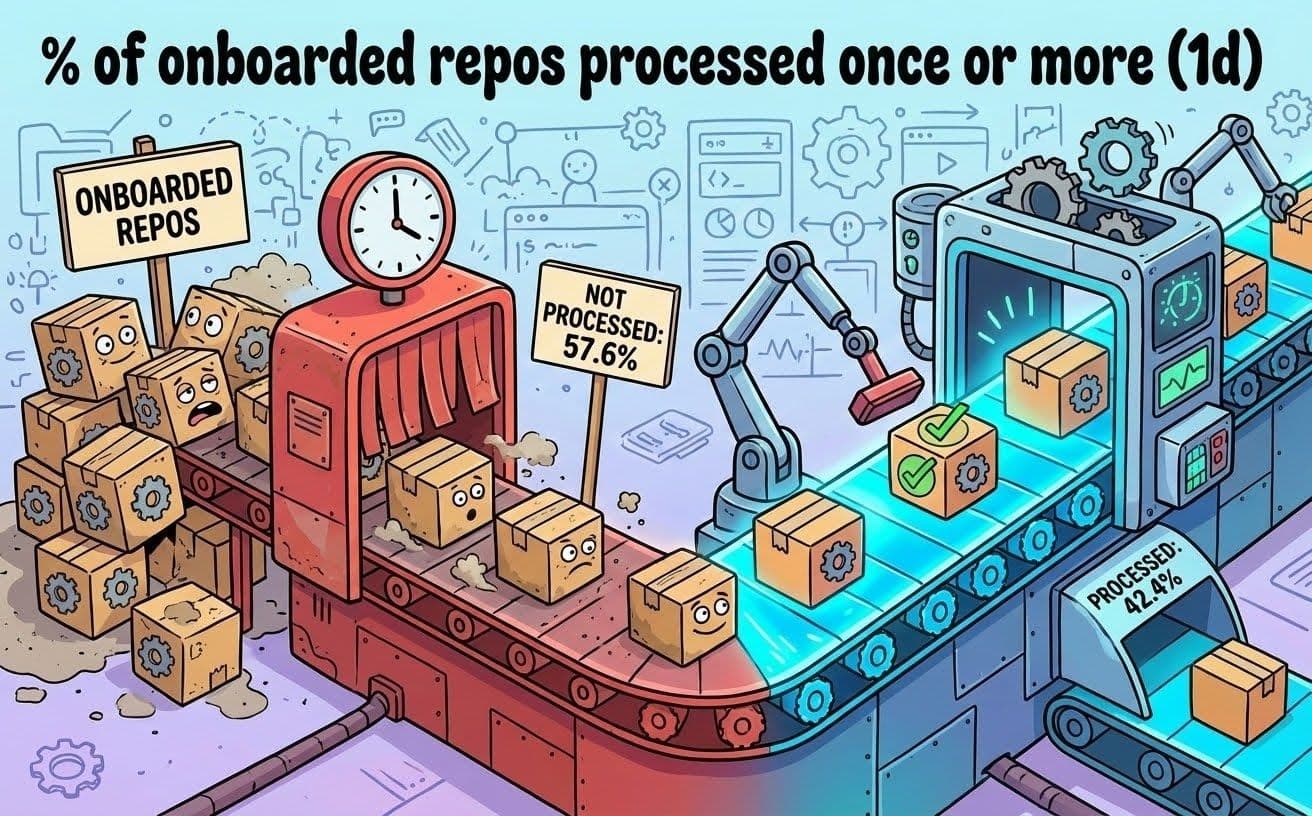
Fig. 2: Número de repositórios processados pelo menos uma vez por dia (feito com Nano Banana).
Repositórios grandes criavam gargalos maiores, devido às bases de código consideráveis e aos múltiplos PRs abertos. Eventos do webhook do GitHub interromperam a sequência. O Automerge tornou-se não confiável porque o tempo de varredura era imprevisível. Fizemos uma promessa aos nossos usuários sobre a frequência dos escaneamentos, mas não conseguimos cumpri-la.
A decisão de criar internamente: atendendo às necessidades únicas de escala e segurança da Elastic
Enquanto considerávamos opções comerciais, incluindo a edição Mend's Renovate Self-Hosted Enterprise Self-Hosted, internamente na Elastic tivemos algumas iniciativas-chave em desenvolvimento.
Nossa decisão de criar uma plataforma interna foi motivada pelo reconhecimento de que somente uma solução personalizada poderia atender aos requisitos específicos e inegociáveis da Elastic:
- Investindo em nossa plataforma interna de desenvolvedores: naquela época, já tínhamos começado a investir fortemente em nossa plataforma interna de desenvolvedores. Estávamos discutindo e projetando formas de como cada um dos nossos serviços poderia se encaixar nisso. Isso significava que queríamos testar nossas próprias regras e práticas para nossa plataforma de gerenciamento de dependências. Além disso, novas diretrizes estavam entrando em ação e queríamos projetar a plataforma antes dos eventos.
- Integração nativa e personalização do fluxo de trabalho: precisávamos de uma integração direta com nossas ferramentas e processos internos. Por exemplo, queríamos centralizar a configuração como código com nosso Catálogo de serviços (Backstage). Temos necessidades específicas relacionadas ao uso do Backstage que queríamos tornar compatíveis com nossa plataforma. Portanto, embora fosse possível usar as APIs Renovate Self-Hosted junto com nossa automação Backstage, isso não cobriria totalmente nossos processos internos.
- Segurança de defesa em profundidade específica da Elastic: nossa rigorosa conformidade de segurança exigiu mecanismos de segurança personalizados, adaptados ao nosso ecossistema. Estávamos trabalhando para fortalecer nosso uso de "identidades não humanas". A forma como esse reforço de acesso funcionava significava que os métodos não padronizados de autenticação no GitHub não funcionariam com uma ferramenta comercial que não suportasse essa implementação interna. Nosso fluxo de trabalho incluía a implementação de um padrão de criptografia secreta de fluxo de trabalho pai-filho e o uso de tokens transitórios e de uso único do GitHub. Criar internamente foi a única maneira prática de incorporar essas camadas de segurança exclusivas e minimizar a superfície de ataque em nosso complexo ambiente multinuvem.
A solução: orquestração de fluxo de trabalho para gerenciamento de dependências
Nossa solução começou com o fato de queríamos criar sobre a ferramenta de gerenciamento de dependências que já usávamos e não substituí-la, buscando outras soluções. Ela já demonstrava sinais de potencial, e a flexibilidade é importante para diferentes necessidades em toda a organização. Consideramos diferentes soluções, e o que nos ajudou a decidir foram as necessidades, às vezes grandes e especiais, que precisamos cobrir. Decidimos criar uma plataforma de gerenciamento de dependências confiável e escalável, na qual cada repositório será processado por conta própria, removendo gargalos e nos preparando para o crescimento.
Projetamos a plataforma seguindo três princípios fundamentais:
1. Processamento paralelo
Cada repositório recebe o próprio ambiente de processamento de gerenciamento de dependências. Não há mais filas. Nossa concorrência é limitada apenas pelo número de recursos que gastamos. Também aplicamos o agendamento distribuído inteligente para evitar que o GitHub limite a taxa.
2. Autoatendimento
Usamos nosso Catálogo de serviços (Backstage) para integrar e gerenciar automaticamente qualquer novo repositório. Usamos nossa própria definição de recursos para dar ao usuário final a opção de selecionar com que frequência um repositório será processado, quantos recursos deseja alocar para os cronogramas e se deseja desligar ou reativar o processamento por qualquer motivo. Planejamos adicionar mais opções assim conforme as necessidades dos nossos usuários evoluem e eles se familiarizam com a nova instalação.
3. Redução do escopo secreto e isolamento do espaço de nome
Para mais segurança, fornecemos aos nossos pods de gerenciamento de dependências tokens efêmeros do GitHub que são gerados no início de cada fluxo de trabalho. Além disso, isolamos nossas cargas de trabalho em espaços de nome específicos para que possam receber apenas os segredos necessários. Controlamos quais segredos podem ser acessados em cada fluxo de trabalho de gerenciamento de dependências usando o Kubernetes RBAC. Também usamos criptografia para propagar o token do GitHub do fluxo de trabalho pai para o filho.
Reconstruímos nossa plataforma usando e aproveitando o melhor de Kubernetes, do Argo Workflows que alimenta a lógica dos nossos processos, e a CLI do Renovate que está configurado para escanear e processar um repositório de cada vez.
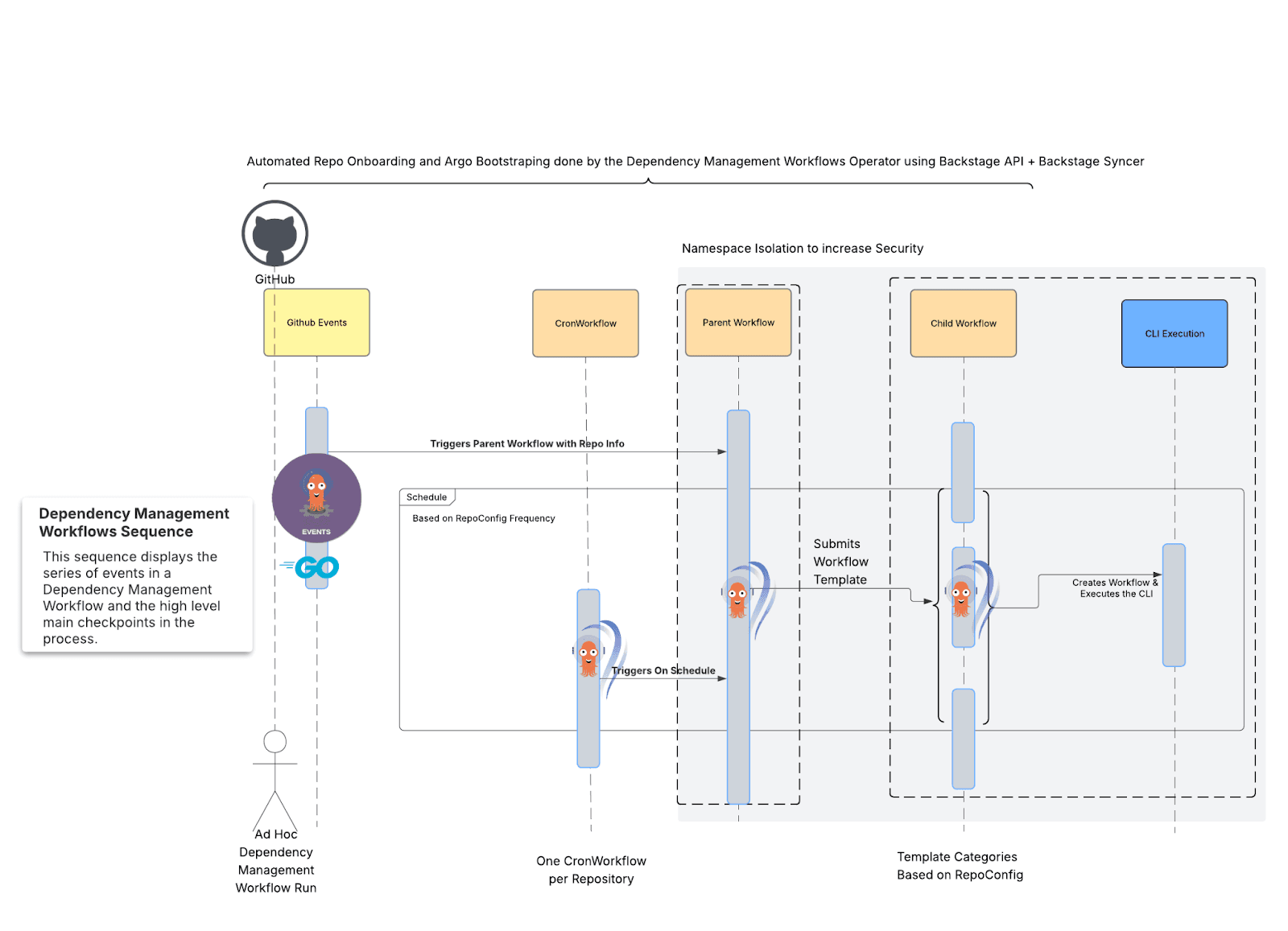
Fig. 3: Uma visão geral em alto nível do novo processo de fluxo de trabalho de gerenciamento de dependências.
A beleza: estamos utilizando projetos open source testados de forma inovadora, fornecendo novos exemplos práticos para todos esses projetos e, ao mesmo tempo, ampliando a velocidade de desenvolvimento e consolidando a redução de CVE para nossas equipes.
Arquitetura de gerenciamento de dependências: quatro microsserviços
A plataforma é composta por quatro componentes personalizados:
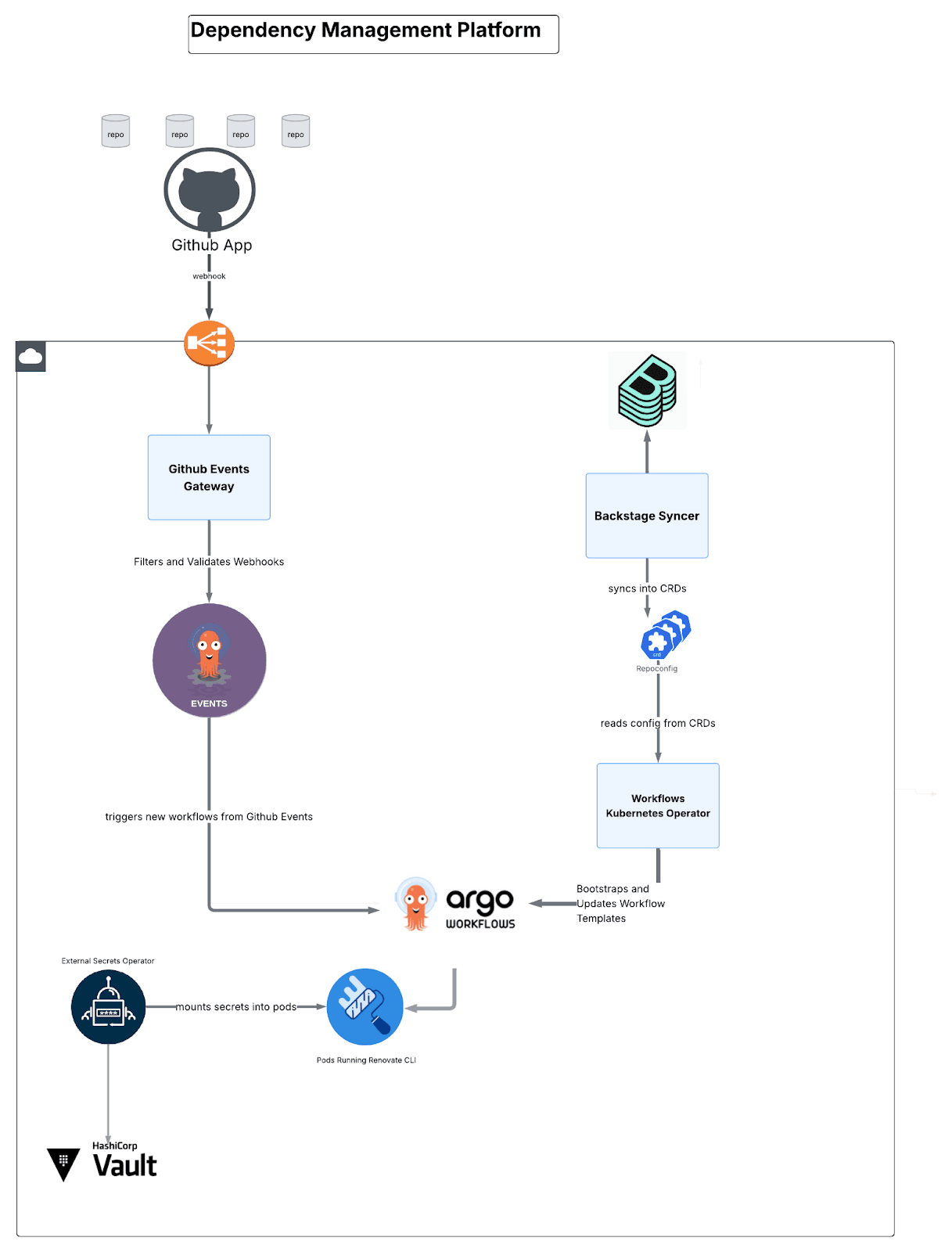
Fig. 4: Uma visão geral de alto nível de como os componentes são conectados.
Operador de fluxos de trabalho (Go/Kubebuilder)
Um operador do Kubernetes gerenciando o ciclo de vida do fluxo de trabalho por meio de três definições de recursos personalizadas (CRDs):
- RepoConfig CRD: fonte única de verdade para configuração de repositórios.
É assim que o RepoConfig é definido no operador:
E essa é a aparência de uma instância do RepoConfig:
- CRD pai: gerencia os fluxos de trabalho do CronWorkflows para varreduras agendadas.
Dentro do loop de reconciliação do controlador principal, garantimos que as configurações de fluxo de trabalho sejam criadas e mantidas atualizadas ou até mesmo excluídas, se necessário.
Primeiro, ele recebe algumas configurações globalmente configuradas para fluxos de trabalho:
Ele garante que um mutex configmap esteja atualizado para evitar fluxos de trabalho semelhantes rodando juntos:
Depois, cria um Gerenciador de fluxo de trabalho que é a estrutura que criará ou atualizará os CronWorkflows e os Modelos de fluxo de trabalho:
- Child CRD: gerencia WorkflowTemplates com recursos por repositório.
O controlador filho tem uma função de reconciliação semelhante à do controlador pai, mas desta vez é responsável pelos modelos de fluxo de trabalho no espaço de nome filho que serão acionados pelos fluxos de trabalho pai.
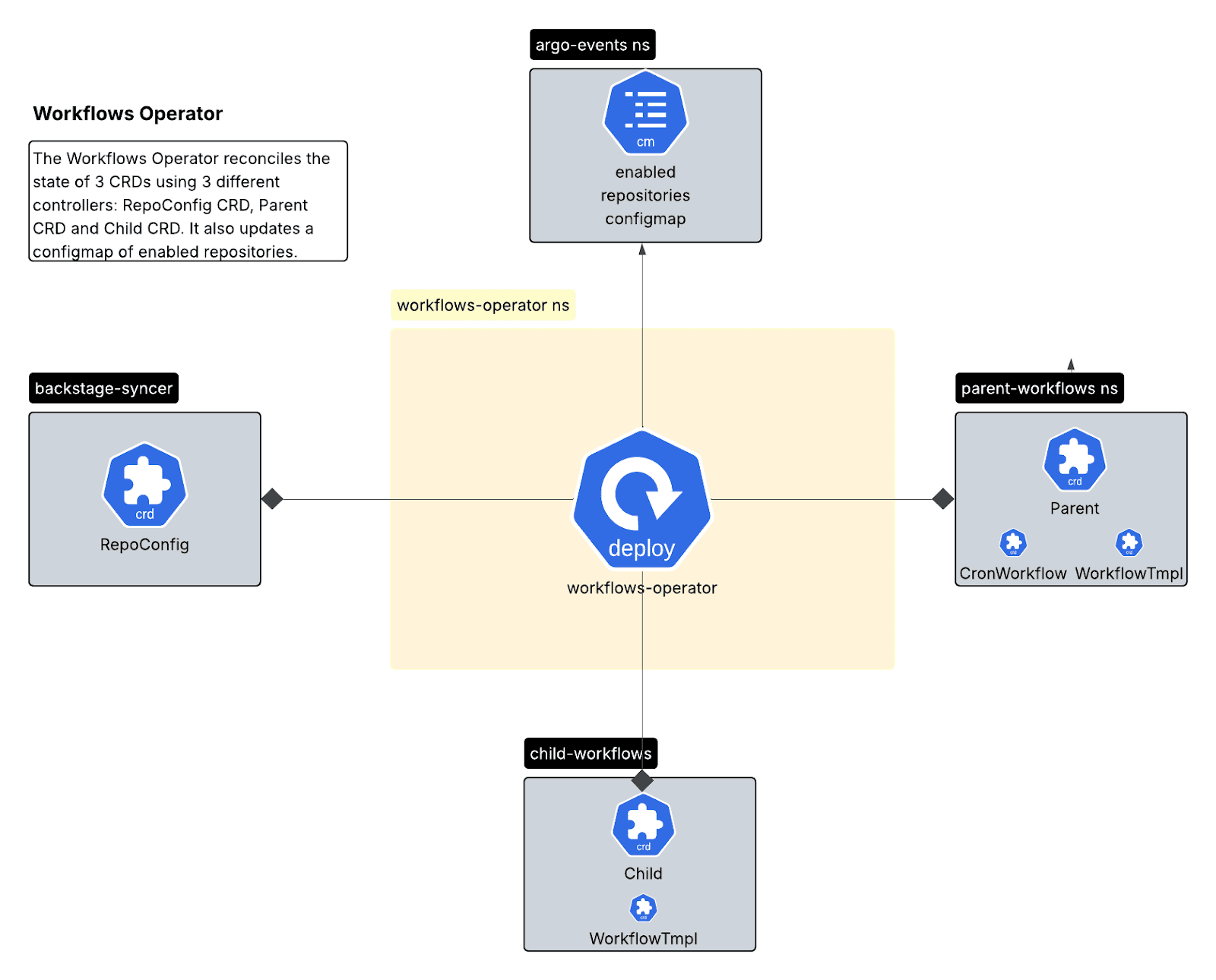
O padrão multicontrolador proporciona separação clara: o RepoConfig Controller cuida do onboarding/offboarding, o Parent Controller gerencia o escalonamento e o Child Controller gerencia os templates de execução.
GitHub Events Gateway (Go)
Um proxy seguro de webhook que recebe webhooks do GitHub, verifica assinaturas, filtra por organização/repositório e direciona para os eventos do Argo. Criamos 10 sensores distintos que respondem a interações com dashboards de dependência, eventos de PR e atualizações de pacotes.
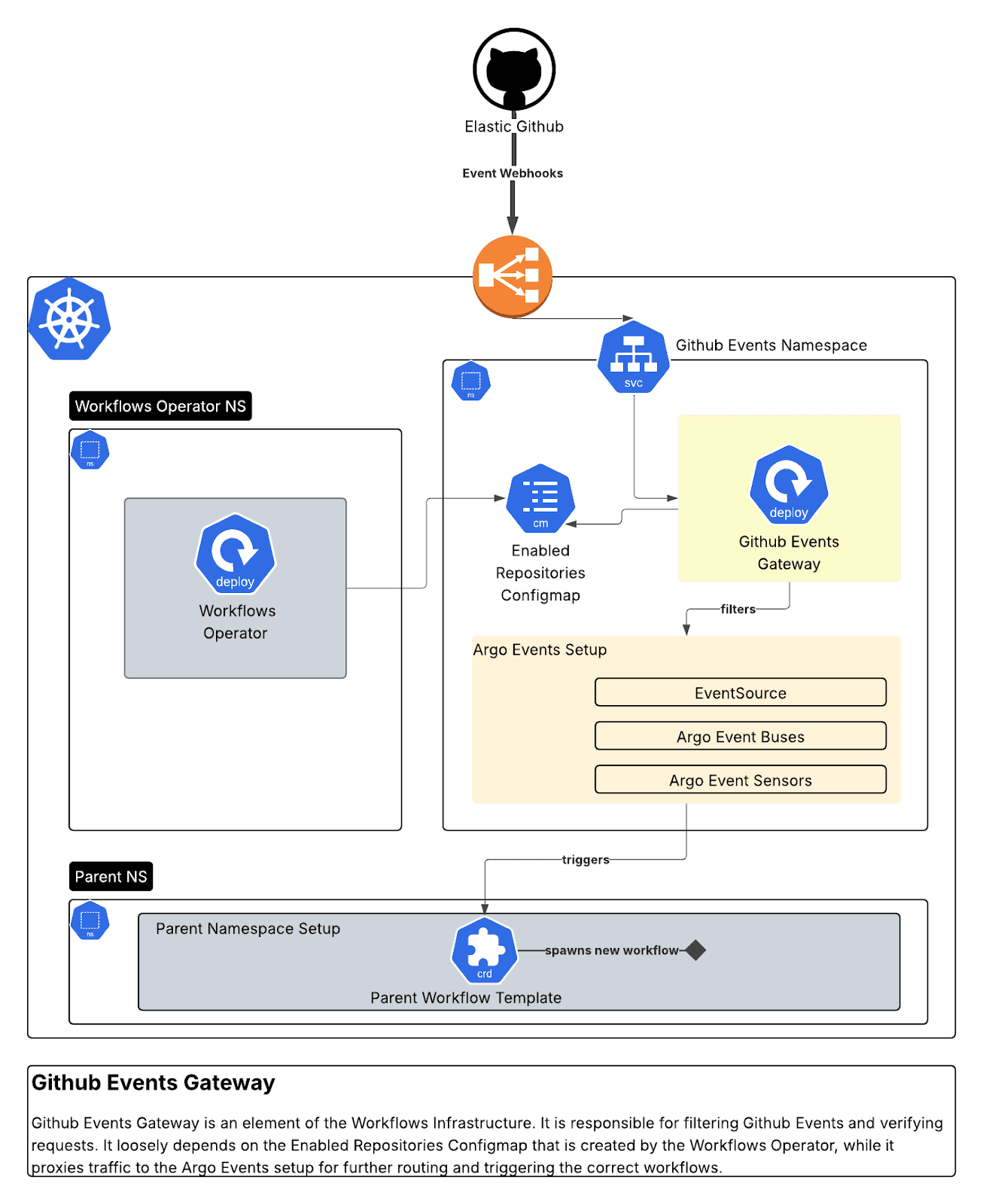
Esse gateway permite a integração com os apps do GitHub por meio de:
- Verificação de assinaturas de webhooks do GitHub recebidas para fins de segurança.
- Encaminhando eventos válidos para o Argo Events EventSource com todos os cabeçalhos e autenticação relevantes.
- Nós também configuramos um authSecret no EventSource e fornecemos isso como um cabeçalho Bearer nas requisições encaminhadas.
- Fornecer loggings, métricas e lógica de repetição.
Ele realiza diversas validações em cada solicitação de evento do GitHub.
Ele garante que alguns atributos HTTP estejam presentes:
Embora também valide a assinatura de cada solicitação e da organização.
Por fim, ele direciona para Argo Events com base no tipo de evento:
Do lado da Argo Events, 10 sensores observam o Argo Events EventBus para novos eventos:
Então, o script aplica a lógica de cada sensor:
Sincronizador de Backstage (Go)
Este procedimento consulta nosso Catálogo de serviços (Backstage) em busca de Entidades de recursos reais do repositório, transforma-as em CRDs do RepoConfig e mantém a plataforma sincronizada com as alterações de configuração. As alterações são aplicadas em três minutos.
Por fim, ele grava esses dados nas instâncias do RepoConfig.
Base de fluxos de trabalho (Misto: JavaScript, Go, Helm)
A camada fundamental contém gráficos Helm, configurações JavaScript, um wrapper Go para a CLI do Renovate com suporte a criptografia e um indexador de APK personalizado para pacotes Alpine.
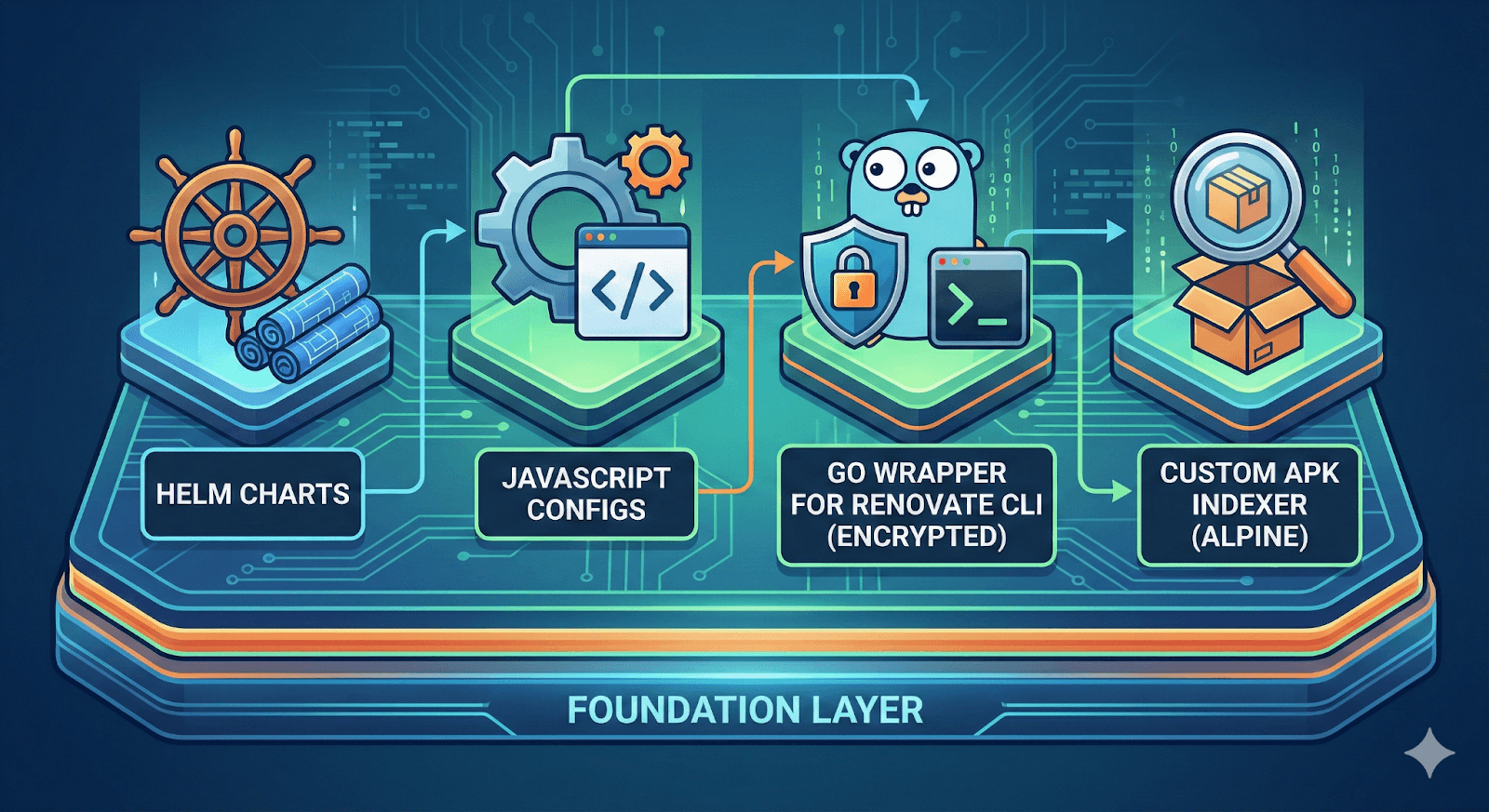
Figura 5: Uma visão de forma geral dos componentes fundamentais (feitos com Nano Banana).
Configuração de autoatendimento
As equipes configuram os repositórios de forma declarativa através do Backstage:
Grupos de recursos alocam CPU e memória com base no tamanho do repositório:
- PEQUENA: CPU de 500m, memória de 1Gi.
- MÉDIA: CPU de 1000m, memória 2Gi.
- GRANDE: CPU de 2000 m, memória de 4Gi.
A configuração é controlada por versão, auditável e aplicada automaticamente.
O padrão pai-filho
O modelo de execução utiliza um padrão de fluxo de trabalho pai-filho:
- Fluxo de trabalho pai: CronWorkflow leve executando conforme programado. Criptografa segredos, determina se uma verificação deve ser executada, passa a configuração para o filho.
- Fluxo de trabalho filho: pod efêmero onde a CLI do Renovate executa. Recursos alocados dinamicamente, descriptografam segredos isoladamente, encerram após a conclusão.
Essa separação oferece segurança (segredos criptografados no nível dos pais), otimização de recursos (os pais utilizam recursos mínimos) e escalabilidade (os filhos executam em paralelo).
Os resultados
Transformação de desempenho
- Antes: um repositório por vez, alguns repositórios não seriam processados, possivelmente nem mesmo por um dia ou mais, menos de 1.000 digitalizações por dia.
- Após: mais de 100 varreduras simultâneas, geralmente 8.000 varreduras e até 10.000 varreduras registradas por dia, limitadas apenas pela quantidade de recursos que estamos dispostos a investir e por como lidamos com os limites de taxa do GitHub.
Eficiência de custos
Por mais estranho que pareça, rodar 8.000 pods por dia pode te dar o mesmo resultado muito mais barato do que ter um pod de longa duração tentando alcançar os mesmos resultados.
Na configuração anterior, estávamos executando uma única instância que, em um bom dia, realizaria de 500 a 600 verificações. Ao mesmo tempo, devido ao fato de que diferentes tipos de repositórios seriam executados no mesmo pod, precisávamos dimensionar o pod para os maiores. Esse tamanho seria muito maior do que nossa oferta extra grande atual, usando 8 CPUs para o pod e 16G de memória.
Para atender à saída diária atual, o pod único precisaria executar por 12 dias. Então, comparando o custo desse único pod funcionando por 12 dias com 8.000 pods do nosso tamanho “MÉDIO” funcionando todos os dias, nosso novo design é muito mais eficiente para a mesma saída de escaneamentos:
| Métrica | Cenário A (Fluxos de trabalho) | Cenário B (O único pod de longa duração) |
|---|---|---|
| Configuração | 8.000 pods (1 vCPU / 2 GB) | 1 pod (8 vCPU / 16 GB)* |
| Duração | 10 minutos cada | 12 dias contínuos |
| Tempo total de trabalho | 1.333 horas de computação | 288 horas de computação |
| Custo total | $ 65,83 | $ 113,75 |
No entanto, vamos levar em consideração que nossa configuração padrão para nossas cargas de trabalho está definida como "PEQUENA", com a grande maioria funcionando com sucesso com 0,5 CPU e 1 GB de RAM, e apenas algumas precisam ser alteradas para média ou grande. Vamos ver o que acontece se 60% das nossas cargas de trabalho rodarem em "PEQUENA", 30% em "MÉDIA" e 10% em "GRANDE", o que está mais próximo da verdade.
| Métrica | Cenário A (Enxame misto) | Cenário B (O de longa duração) |
|---|---|---|
| Estratégia | 8.000 pods (tamanhos variados) | 1 pod (8 vCPU / 16 GB)* |
| Duração | 10 minutos cada | 12 dias contínuos |
| Custo total | $ 52,66 | $ 113,75 |
| Economia | $ 61,09 (54% mais barato) | — |
Podemos ver que, para a mesma saída, somos muito mais econômicos em nosso sistema atual.
Segurança aprimorada
- Tokens efêmeros do GitHub (minutos de exposição versus dias).
- Isolamento de espaço de nome com limites de Controle de acesso por função (RBAC).
- Criptografia de segredos em repouso nos fluxos de trabalho principais.
- Acesso direto ao cofre removido.
Desempenho previsível
Com frequência de varredura garantida, finalmente podemos definir Objetivos de nível de serviço (SLOs). A automerge funciona de forma confiável. As equipes confiam que a plataforma vai entregar o que é prometido.
Principais decisões arquitetônicas
Aqui estão algumas das principais decisões de design que moldaram a aparência da plataforma.
- Por que fluxos de trabalho pai-filho?
Adotamos esse padrão para implementar uma estratégia de defesa em profundidade. Ao restringir credenciais de alto valor (como segredos de app GitHub) a um espaço de nome dedicado e bloqueado, utilizamos RBAC para garantir que pods de execução efêmeros não possam acessar arbitrariamente dados sensíveis. Vulnerabilidades recentes na cadeia de suprimentos (por exemplo, os ataques de integração contínua/entrega contínua [CI/CD] "Shai Hulud") demonstraram a importância crítica de isolar os ambientes de execução que executam scripts dinâmicos do repositório de credenciais.
Ao mesmo tempo, essa dissociação permite a otimização granular de recursos. Os fluxos de trabalho "pai" atuam como orquestradores leves com um espaço mínimo, enquanto os fluxos de trabalho "filho" lidam com a verificação de dependências com uso intensivo de computação. Essa separação simplifica gestão de ciclo de vida, permitindo aplicar uma lógica de reconciliação distinta a cada camada, concedendo aos usuários controle sobre os parâmetros de execução (camada filha) e, ao mesmo tempo, mantendo o controle administrativo sobre a infraestrutura de agendamento e segurança (camada pai).
- Por que é do tipo autoatendimento?
Eliminar nossa equipe como gargalo para a configuração do repositório era uma exigência crítica. Nossa missão era arquitetar uma plataforma escalável e de autoatendimento compatível com diversos casos de uso. Reconhecemos que atuar como guardiões de cada alteração de configuração era insustentável, dado o grande volume de repositórios. Em vez disso, adotamos uma filosofia de capacitação: fornecer os "trilhos" (infraestrutura e proteções) e capacitar os usuários a conduzir os "trens" (execução e personalização). Acreditamos que essa mudança em direção à autonomia da equipe aumenta significativamente a produtividade, permitindo que os usuários adaptem o sistema às suas necessidades operacionais específicas.
- Por que o padrão Operator do Kubernetes?
Como mencionado acima, um princípio fundamental de design era garantir que a plataforma fosse totalmente autoatendida. Precisávamos de um mecanismo automatizado para capturar a intenção do usuário (como alternar varreduras, ajustar a frequência de agendamento ou ajustar limites de recursos em tempo de execução) e propagar instantaneamente essas mudanças para os fluxos de trabalho subjacentes. Antecipando requisitos futuros, o sistema também precisava ser facilmente extensível.
Para alcançar esse objetivo, desenvolvemos um operador Kubernetes personalizado para gerenciamento de dependências. Ao usar CRDs como interface de configuração, estabelecemos um ciclo de reconciliação nativo do Kubernetes. Este operador monitora continuamente o estado desejado definido pelo usuário e orquestra automaticamente as atualizações necessárias na infraestrutura do fluxo de trabalho. Isso garante uma operação perfeita e orientada a eventos, onde a lógica da plataforma lida com toda a complexidade nos bastidores.
- Por que projetar um GitHub Events Gateway?
Adotar uma arquitetura orientada a eventos (EDA) foi essencial para a capacidade de resposta da plataforma. Embora os fluxos de trabalho do CronWorkflows fornecessem uma programação de linha de base confiável, precisávamos de agilidade para lidar com execuções ad hoc, como usuários acionando varreduras manualmente por meio do dashboard. Para isso, precisávamos de um gateway de ingestão dedicado para validar a integridade da carga útil e rotear as solicitações de forma inteligente.
Avaliamos as soluções existentes, incluindo o EventSource nativo do GitHub para Argo, mas identificamos riscos significativos relacionados à sobrecarga operacional e às rígidas cotas da API do GitHub (por exemplo, limites de webhook por repositório). Consequentemente, construímos um gateway personalizado para desacoplar nossa infraestrutura dessas limitações.
Fundamentalmente, esse gateway serviu como um ponto estratégico de controle de tráfego durante nossa migração. Ele funcionou como um switch, permitindo que realizássemos uma implementação gradual e granular (mudança de tráfego) do sistema legado para a nova infraestrutura. Isso garantiu que a integração de milhares de repositórios fosse um processo controlado e sem riscos, e não uma transição de "big bang".
Lições aprendidas
Algumas lições que aprendemos andam de mãos dadas com o Elastic Source Code:
- O cliente em primeiro lugar: as plataformas são criadas para os usuários. Por isso, é importante ter as necessidades dos usuários como prioridade. Isso molda a plataforma em infraestrutura e aplicativos projetados de forma eficiente, que reduzem o atrito com os usuários, simplificam a escalabilidade da plataforma e facilitam a adoção.
- Espaço, tempo: às vezes, o caminho de menor resistência leva a areias movediças. Inicialmente, tentamos otimizar o modelo de processamento sequencial existente, mas isso não resolveu nossos problemas; na verdade, ele apenas introduziu mais complexidade e pontas soltas. A ousada decisão de reestruturar a plataforma com processamento paralelo exigiu um esforço inicial significativo. No entanto, isso acabou abrindo caminho para um crescimento sustentável da plataforma e praticamente eliminou o trabalho administrativo diário tedioso.
- TI, depende: uma plataforma não pode operar isoladamente; o sucesso depende de quão bem ela se integra ao ecossistema mais amplo. Em nosso caso, a integração com o Backstage foi fundamental, pois ele serve como a fonte da verdade para a integração perfeita de serviços. Da mesma forma, a conexão com o Artifactory nos permitiu gerenciar com eficiência as atualizações de pacotes privados, e a lista de integrações essenciais continua.
- Progresso, perfeição SIMPLES: durante toda a implementação, testamos constantemente nossas suposições iniciais e nos adaptamos a novas barreiras à medida que elas surgiam. Em vez de ficarmos paralisados pelo perfeccionismo, adotamos uma abordagem iterativa, enfrentando desafios um a um e ajustando nossa estratégia migratória para atender às condições do mundo real.
O que vem a seguir
A entrega da plataforma nos permite realizar trabalhos mais significativos que ajudarão a melhorar a experiência do usuário e a eficiência da nossa plataforma. Alguns exemplos são:
- Aumentar e colocar proteções na adoção do auto-merge
O recurso de auto-merge acelera significativamente a velocidade da equipe ao eliminar tarefas manuais tediosas. No entanto, precisamos nos certificar de que existam proteções rígidas para garantir que esse aumento de velocidade não prejudique a segurança.
- Melhorar a observabilidade da experiência do usuário final
Uma prioridade crítica para nosso roadmap é aprimorar a observabilidade, não apenas no nível da plataforma, mas também especificamente da perspectiva do usuário final. Embora a captura de métricas de infraestrutura seja simples, entender a experiência real do usuário exige insights mais profundos. Estamos trabalhando para definir os indicadores-chave de desempenho centrados no usuário do núcleo (KPIs) para que nossa telemetria possa detectar pontos de atrito e problemas de desempenho antes que eles se transformem em reclamações dos usuários.
- Remova obstáculos para a adoção
Vislumbrando o futuro, nossa prioridade é identificar e remover quaisquer barreiras que dificultem a adoção da plataforma. Seja desenvolvendo novas integrações ou implantando conjuntos específicos de recursos, estamos comprometidos com o planejamento orientado por dados. Criamos uma plataforma projetada para escalabilidade; nosso foco agora se volta para maximizar o potencial.
O panorama maior
O projeto de fluxos de trabalho de gerenciamento de dependências demonstra um princípio mais amplo: quando você precisa redimensionar ferramentas open source além do modelo de implantação padrão, os padrões nativos do Kubernetes fornecem um caminho a seguir.
Ao adotar:
- CRDs para configuração.
- Operadores para gestão de ciclo de vida.
- Arquitetura orientada por eventos para capacidade de resposta
- GitOps para implantação.
Criamos uma orquestração que se redimensiona independentemente do número de repositórios que gerencia. O desempenho da varredura de um repositório é o mesmo, independentemente de estarmos gerenciando 100 ou 1.000.
Quando um CVE crítico é anunciado, agora temos respostas em minutos, não em horas. Essa é a diferença entre um gargalo e uma vantagem competitiva.
Agradecimentos
Esta plataforma utiliza excelentes ferramentas open source:
- Kubebuilder: o framework open source que usamos para iniciar nossos operadores Kubernetes que inicializam e orquestram nossos fluxos de trabalho. [1][2]
- Backstage: o open source framework no qual construímos nosso Catálogo de serviços e que usamos como nossa versão final. [1][2]
- Argo Workflows e Argo Events: a open source suíte que usamos para orquestrar processos complexos e adicionar processamento dinâmico baseado em eventos. [1][2][3][4]
- CLI do Renovate: a ferramenta de gerenciamento de dependências de open source que processa nossos repositórios. [1][2]
* O modelo de preços do AWS Fargate foi usado como referência para o custo de um único pod, embora nossas cargas de trabalho não estejam necessariamente sendo executadas na AWS, mas sim em clusters Kubernetes completos.
Conteúdo relacionado

20 de abril de 2026
Apresentando chaves de API unificadas para Elastic Cloud Serverless e Elasticsearch
Saiba como a Elastic unificou o plano de controle e a autenticação do plano de dados no Serverless com uma arquitetura IAM distribuída globalmente. Use uma chave de API para as APIs da nuvem e do Elasticsearch.
3 de abril de 2026
Monitorando as visualizações do dashboard do Kibana com o Elastic Workflows
Aprenda a usar o Elastic Workflows para coletar métricas de visualização do dashboard do Kibana a cada 30 minutos e indexá-las no Elasticsearch, para que você possa criar análises e visualizações personalizadas com base em seus próprios dados.

7 de novembro de 2025
Apresentando a interface de usuário de regras de consulta do Elasticsearch no Kibana.
Aprenda a usar a interface de regras de consulta do Elasticsearch para adicionar ou excluir documentos de consultas de pesquisa usando conjuntos de regras personalizáveis no Kibana, sem afetar o ranking orgânico.

6 de novembro de 2025
Construindo um agente de conhecimento com recuperação semântica usando Mastra e Elasticsearch.
Aprenda como construir um agente de conhecimento com recuperação semântica usando Mastra e Elasticsearch como armazenamento vetorial para memória e recuperação de informações.

22 de maio de 2026
Kibana reduz o tempo de carregamento do dashboard em até 25% — aqui está a estratégia de sondagem por trás disso
Descubra como o Kibana usa sondagem contínua e detecção de HTTP/2 no navegador para reduzir o tempo de carregamento do dashboard em até 25%, com recurso automático ao HTTP/1.