Voici comment nous avons construit une plateforme de gestion des dépendances auto-hébergée en utilisant Kubernetes, Argo Workflows, Argo Events et Renovate CLI pour automatiser les mises à jour, traiter rapidement les vulnérabilités et expositions courantes (CVE) et transmettre efficacement les nouvelles versions de packages à des milliers de référentiels.
Gestion des dépendances chez Elastic
Chez Elastic, nous devons gérer des centaines, voire des milliers de référentiels privés et publics. Lorsqu'une CVE critique est découverte, nous avons besoin de réponses et d'actions immédiates : quels référentiels sont vulnérables ? Dans quel délai pouvons-nous les réparer ? Outre la sécurité, des questions de productivité se posent également : comment transmettre rapidement la publication d'une nouvelle version d'un package à tous les référentiels qui en dépendent, sans passer trop de temps à effectuer des tâches manuelles ?
La recherche de méthodes de gestion des dépendances a été motivée à l'origine par la nécessité d'établir une base sécurisée avec des mises à jour automatisées pour réduire les CVE. Après avoir soigneusement réfléchi aux solutions de gestion des dépendances, nous avons d'abord commencé à travailler sur une infrastructure auto-hébergée. Nous utilisions notre propre cluster Kubernetes pour exécuter Mend Renovate Community auto-hébergé. L'idée était de pouvoir fournir une plateforme de gestion des dépendances à laquelle nos utilisateurs pourraient accéder en libre-service.
L'expérience initiale s'est avérée fructueuse, si bien que de plus en plus d'équipes ont commencé à adopter notre plateforme et à l'utiliser dans le cycle de vie quotidien de leurs référentiels pour les mises à jour et les correctifs CVE. Cela s'est passé si vite que nous avons rapidement atteint les limites de notre installation auto-hébergée.

Fig. 1 : Vue d'ensemble de la gestion des dépendances chez Elastic.
Le défi : comment pouvons-nous scaler une plateforme de gestion des dépendances dans une grande organisation disposant d'un nombre important de référentiels ?
Notre plateforme de gestion des dépendances traitait un référentiel à la fois et le modèle de traitement séquentiel ne pouvait pas suivre le rythme, compte tenu du grand nombre de référentiels que nous gérons. Nous avions déjà constaté que le problème provenait du fait qu'une seule instance de notre outil de gestion des dépendances pouvait traiter notre liste importante et toujours croissante de référentiels. Les référentiels attendaient parfois pendant plusieurs heures dans une file d'attente. Plus de 50 % de nos référentiels n'étaient même pas traités quotidiennement. Autrement dit, plus de la moitié de nos référentiels attendaient plus de 24 heures entre les analyses.
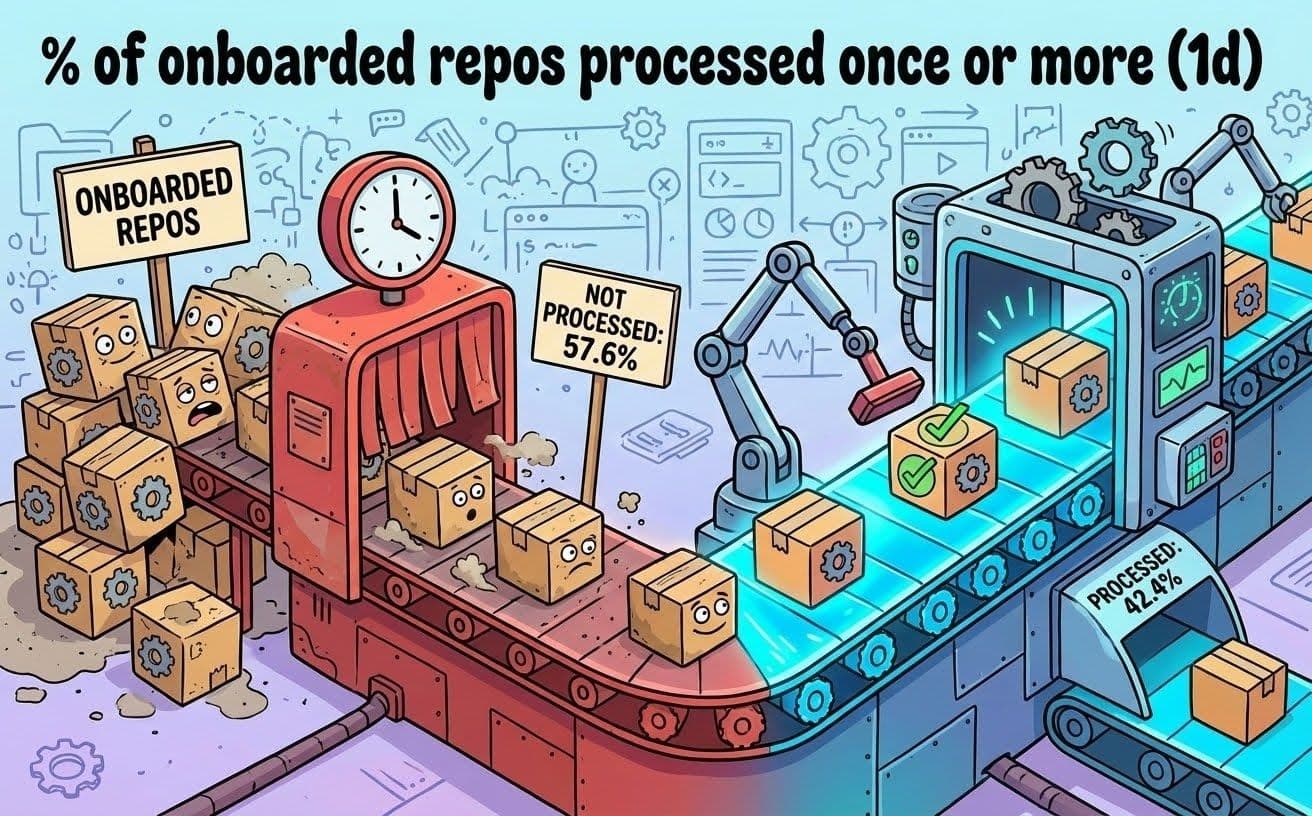
Fig. 2 : Nombre de référentiels traités au moins une fois par jour (réalisé avec Nano Banana).
Les grands référentiels ont créé des goulots d'étranglement plus importants, en raison de leurs bases de code volumineuses et de leurs multiples requêtes pull ouvertes. Les événements du webhook GitHub ont perturbé la séquence. La fusion automatique est devenue peu fiable car le moment des analyses était imprévisible. Nous avions fait une promesse à nos utilisateurs concernant la fréquence des analyses, mais nous n'avons pas pu la tenir.
La décision de développer en interne : répondre aux besoins uniques de scalabilité et de sécurité d'Elastic
Bien que nous envisagions des options commerciales, dont l'édition auto-hébergée Renovate Enterprise de Mend, nous avions en interne chez Elastic quelques initiatives clés en cours de développement.
Notre décision de créer une plateforme en interne a été motivée par la prise de conscience que seule une solution hautement personnalisée pouvait répondre aux exigences spécifiques et non négociables d'Elastic :
- Investissement dans notre plateforme de développement interne : à l'époque, nous avions déjà investi massivement dans notre plateforme de développement interne. Nous réfléchissions à la manière d'intégrer chacun de nos services à cette plateforme et nous concevions des solutions pour y parvenir. Cela impliquait de tester nos propres règles et pratiques pour notre plateforme de gestion des dépendances. De plus, de nouvelles directives entraient en vigueur et nous souhaitions concevoir la plateforme en amont.
- Intégration native et personnalisation du workflow : nous avions besoin d'une intégration simple à nos outils et processus internes. Par exemple, nous souhaitions centraliser la configuration sous forme de code avec notre catalogue de services (Backstage). L'utilisation de Backstage nous impose des exigences spécifiques avec lesquelles nous voulions que notre plateforme soit compatible. Ainsi, bien qu'il soit possible d'utiliser les API auto-hébergées de Renovate en complément de notre automatisation Backstage, cela ne couvrirait pas entièrement nos processus internes.
- Sécurité renforcée par défense en profondeur spécifique à Elastic : notre conformité stricte en matière de sécurité exigeait des mécanismes de sécurité sur mesure, adaptés à notre écosystème. Nous nous efforcions de renforcer la sécurité de notre utilisation des "identités non humaines". Ce renforcement des accès impliquait que les méthodes d'authentification non standard auprès de GitHub ne fonctionneraient pas avec un outil standard qui ne prenait pas en charge cette implémentation interne. Notre workflow comprenait la mise en œuvre d'un modèle de chiffrement des secrets de workflow parent-enfant et l'utilisation de jetons GitHub temporaires à usage unique. Le développement en interne était la seule solution pratique pour intégrer ces couches de sécurité uniques et minimiser la surface d'attaque dans notre environnement multicloud complexe.
La solution : l'orchestration des workflows pour la gestion des dépendances
Notre solution est née de notre volonté de tirer parti de l'outil de gestion des dépendances que nous utilisions déjà plutôt que de le remplacer et rechercher d'autres solutions. Cet outil avait démontré son potentiel, et sa flexibilité est essentielle pour répondre aux différents besoins de notre organisation. Nous avons examiné différentes solutions, et ce qui a guidé notre choix, ce sont les besoins importants et parfois spécifiques que nous devons satisfaire. Nous avons donc décidé de créer une plateforme de gestion des dépendances fiable et évolutive, où chaque référentiel est traité individuellement, éliminant ainsi les goulots d'étranglement et nous préparant à la croissance.
Nous avons conçu la plateforme en respectant trois principes fondamentaux :
1. Traitement parallèle
Chaque référentiel est doté de son propre environnement de gestion des dépendances. Plus de files d'attente. Notre simultanéité d'exécution n'est limitée que par le nombre de ressources que nous utilisons. Nous avons également appliqué une programmation distribuée intelligente pour éviter d'être limité par GitHub.
2. Libre-service
Nous utilisons notre catalogue de services (Backstage) pour intégrer et gérer automatiquement les nouveaux référentiels. Grâce à notre propre système de définition des ressources, l'utilisateur final peut choisir la fréquence de traitement des référentiels, le nombre de ressources à allouer à ses planifications, et activer ou désactiver le traitement à tout moment. Nous prévoyons d'ajouter d'autres options à mesure que les besoins de nos utilisateurs évoluent et qu'ils se familiarisent avec la nouvelle installation.
3. Réduction de la portée des secrets et de l’isolation des espaces de noms
Pour une sécurité accrue, nous fournissons à nos modules de gestion des dépendances des jetons GitHub éphémères qui sont générés au début de chaque workflow. En outre, nous isolons nos charges de travail dans des espaces de noms spécifiques afin de ne leur fournir que les secrets nécessaires. Nous contrôlons les secrets qui peuvent être accessibles par chaque workflow de gestion des dépendances en utilisant le RBAC de Kubernetes. Nous utilisons également le chiffrement pour transmettre le jeton GitHub du workflow parent au workflow enfant.
Nous avons reconstruit notre plateforme en utilisant Kubernetes et en exploitant sa puissance. Argo Workflows gère la logique de nos processus et Renovate CLI est configuré pour analyser et traiter un référentiel à la fois.
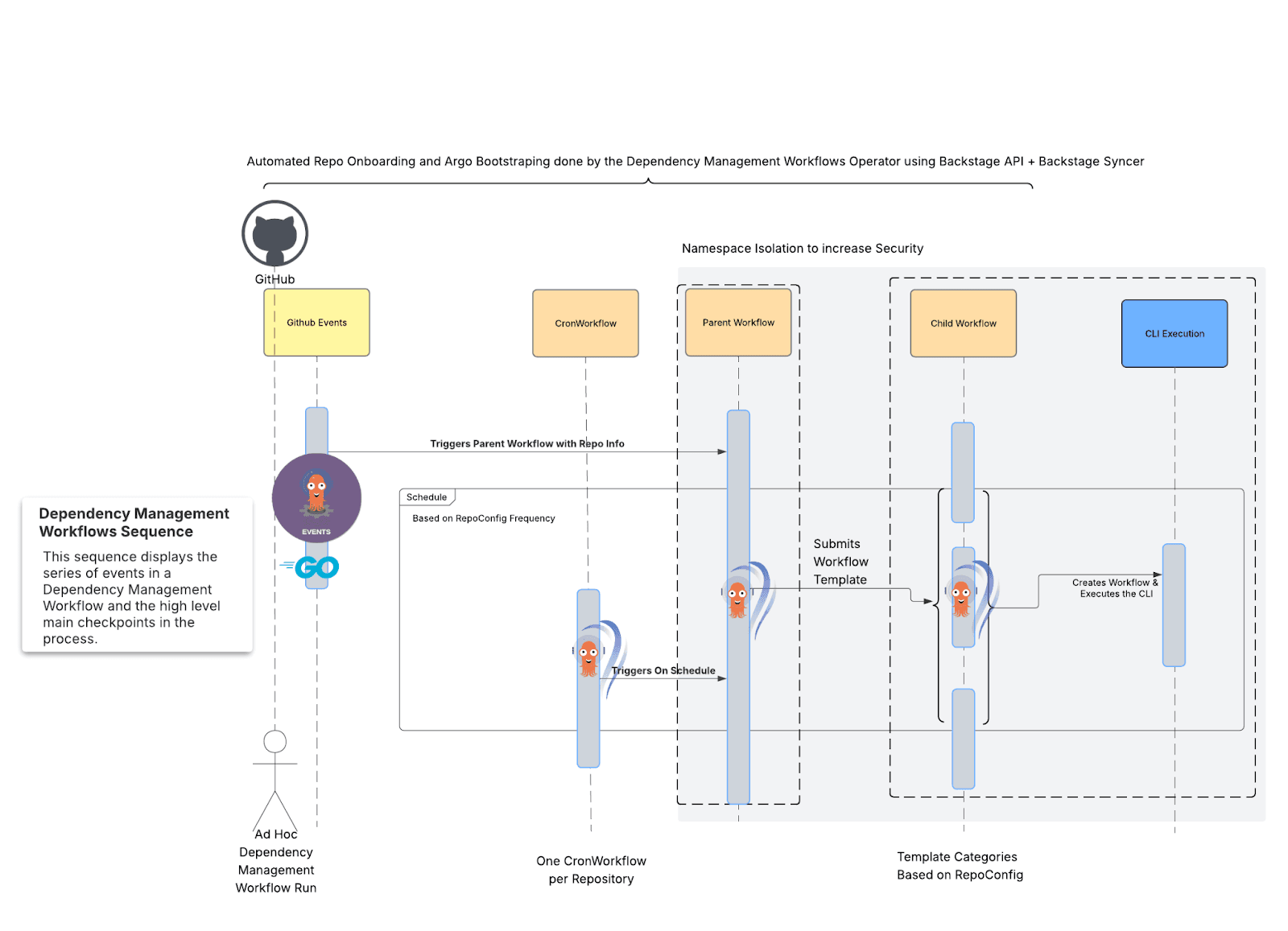
Fig. 3 : Vue d'ensemble du nouveau processus de workflows de gestion des dépendances.
L'intérêt de ce modèle : nous utilisons des projets open source éprouvés d'une manière originale, en fournissant de nouveaux exemples fonctionnels pour tous ces projets et, en même temps, en amplifiant la vitesse de développement et en consolidant la réduction des CVE pour nos équipes.
Architecture de gestion des dépendances : Quatre microservices
La plateforme comprend quatre composants conçus sur mesure :
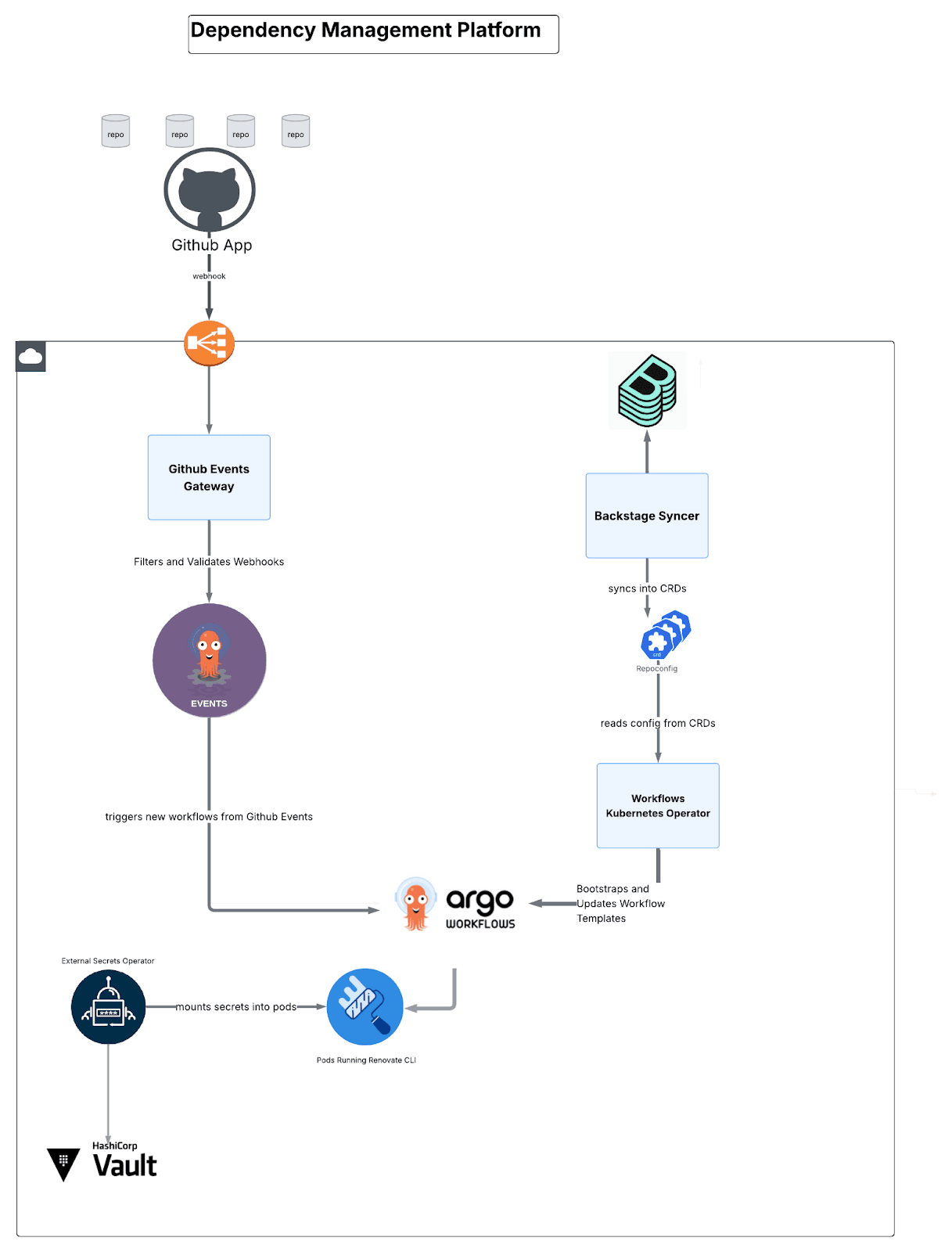
Fig. 4 : Vue d'ensemble de la manière dont les composants sont interconnectés.
Opérateur de workflow (Go/Kubebuilder)
Un opérateur Kubernetes gérant le cycle de vie du workflow à travers trois définitions de ressources personnalisées (CRD) :
- CRD RepoConfig : source unique de référence pour la configuration du référentiel.
Voici comment RepoConfig est défini dans l'opérateur :
Et voici à quoi ressemblerait une instance de RepoConfig :
- CRD parent : gère les workflows Cron pour les analyses programmées.
À l'intérieur de la boucle de rapprochement du contrôleur parent, nous nous assurons que les paramètres du workflow sont créés et maintenus à jour, voire supprimés si nécessaire.
Tout d'abord, le contrôleur parent obtient certains paramètres configurés globalement pour les workflows :
Il s'assure que la configuration du mutex est à jour afin d'empêcher l'exécution simultanée de workflows similaires :
Ensuite, il crée un gestionnaire de workflow qui est la structure qui va créer ou mettre à jour les workflows Cron et les modèles de workflow :
- CRD enfant : gère les modèles de workflow avec des ressources par référentiel.
Le contrôleur enfant a une mission de rapprochement similaire à celle du parent, mais ici, il est responsable des modèles de workflow dans l'espace de noms enfant qui seront déclenchés par les workflows parents.
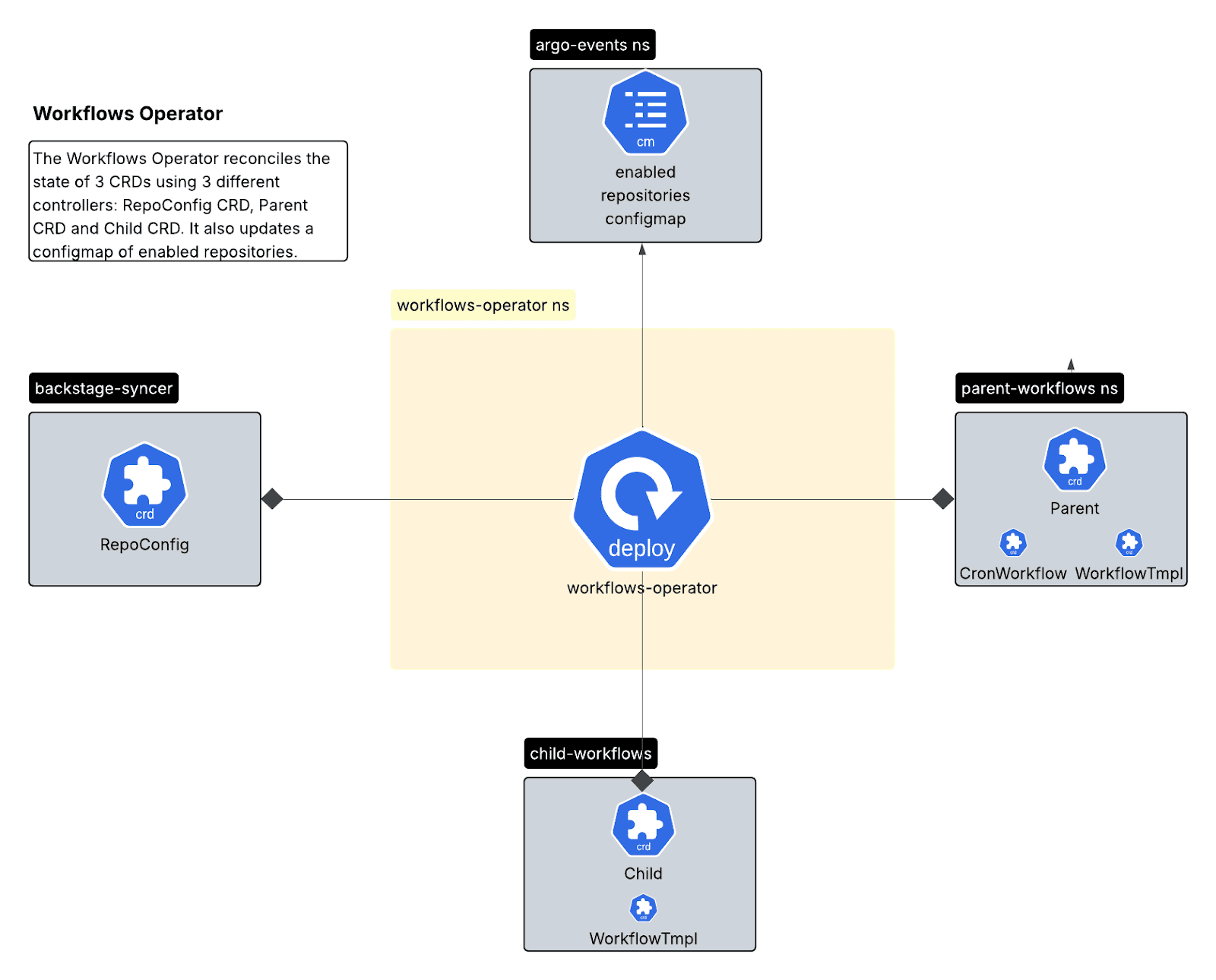
Le modèle multicontrôleur offre une séparation claire : le contrôleur RepoConfig gère l'intégration/dissociation, le contrôleur parent gère la planification, et le contrôleur enfant gère les modèles d'exécution.
Portail d'événements GitHub (Go)
Proxy sécurisé de webhook qui reçoit les webhooks GitHub, vérifie les signatures, filtre par organisation/référentiel, et redirige vers Argo Events. Nous avons conçu 10 capteurs distincts répondant aux interactions du tableau de bord des dépendances, aux événements de requêtes pull (PR) et aux mises à jour des packages.
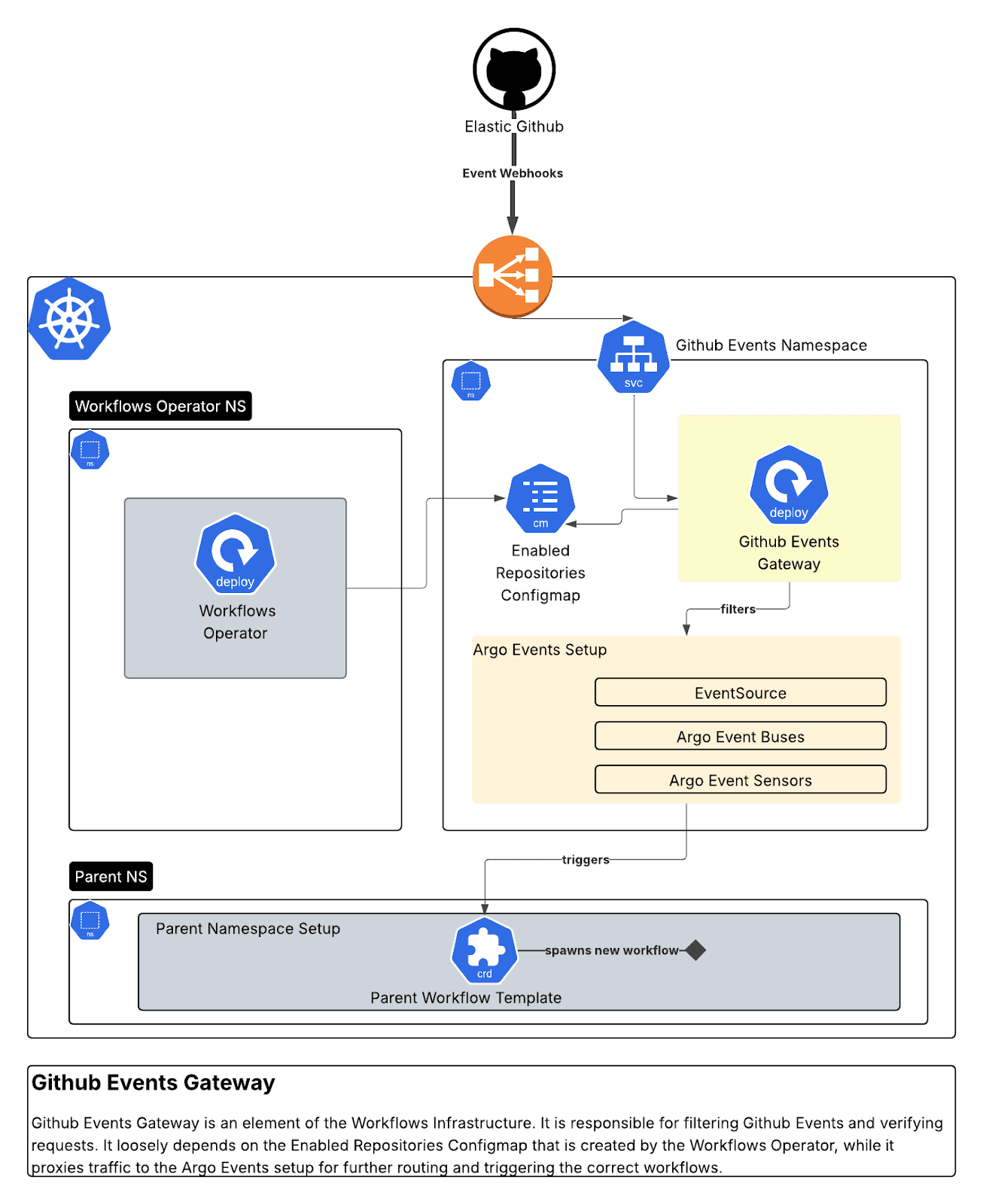
Cette passerelle permet l'intégration aux applications GitHub par :
- Vérification de la sécurité des signatures des webhooks GitHub entrants.
- Transmission des événements valides à l'EventSource Argo Events avec tous les en-têtes correspondants et l'authentification.
- Nous configurons également un authSecret sur l'EventSource et le fournissons comme en-tête Bearer dans les requêtes transférées.
- Fourniture de logging, indicateurs, et logique de tentatives.
Le webhook effectue diverses validations sur chaque requête d'événement GitHub.
Il s'assure que certains attributs HTTP sont présents :
Tout en validant également la signature de chaque requête et son organisation :
Enfin, il redirige vers Argo Events en fonction du type d'événement :
Du côté d'Argo Events, 10 capteurs surveillent l'EventBus d'Argo pour détecter les nouveaux événements.
Le script applique ensuite la logique de chaque capteur :
Backstage Syncer (Go)
Ce composant interroge notre catalogue de services (Backstage) pour obtenir les entités de ressources réelles du référentiel, les transforme en CRD RepoConfig et maintient la plateforme synchronisée avec les modifications de configuration. Celles-ci sont appliquées en trois minutes.
Enfin, il écrit ces données dans des instances RepoConfig.
Base de workflows (mixte : JavaScript, Go, Helm)
La couche de base contient des charts Helm, des configurations JavaScript, un wrapper Go pour Renovate CLI avec prise en charge du chiffrement et un indexeur APK personnalisé pour les packages Alpine.
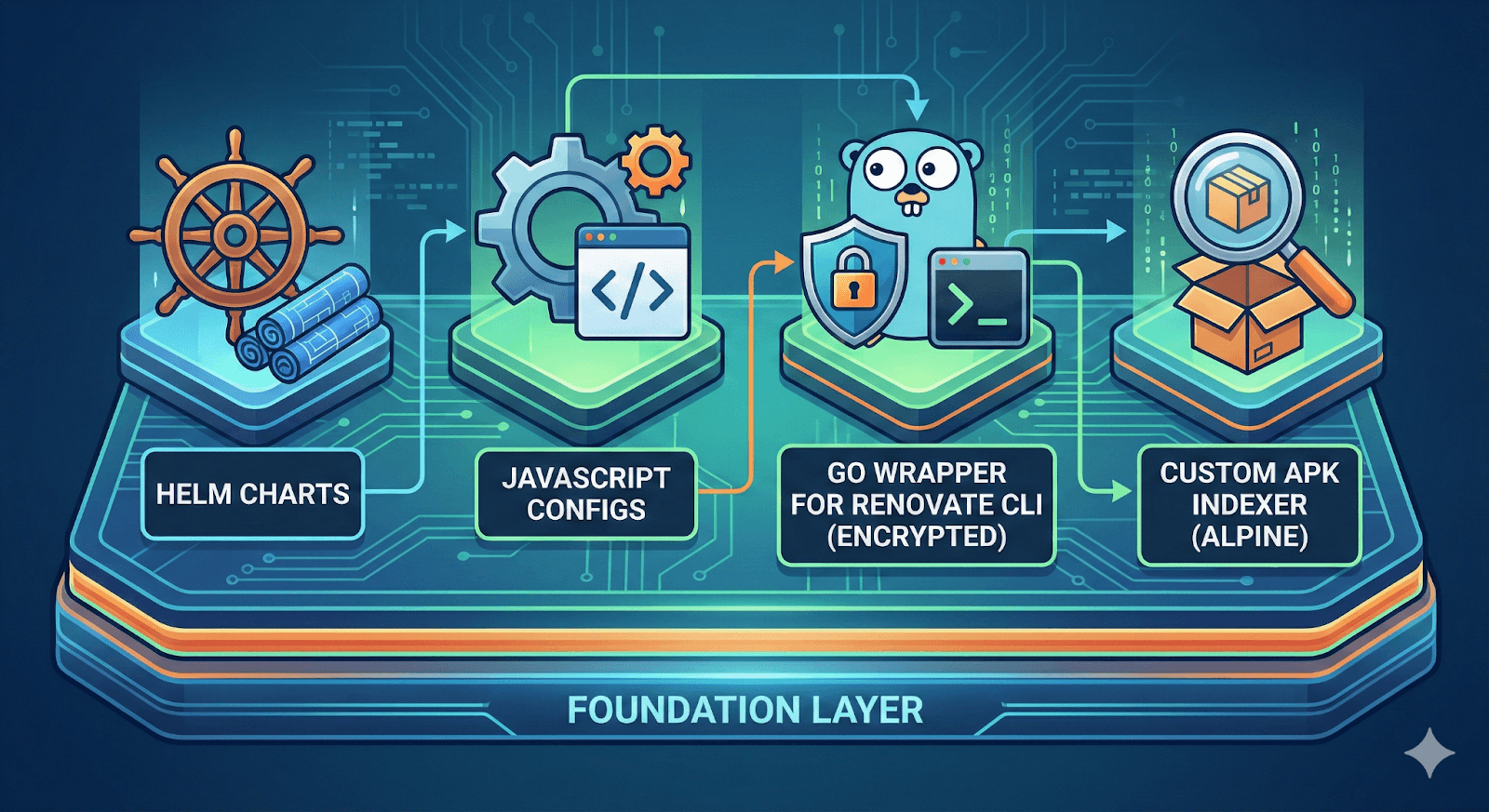
Fig. 5 : Vue d'ensemble des composants de base (réalisée avec Nano Banana).
Configuration en libre-service
Les équipes configurent leurs référentiels de manière déclarative via Backstage :
Les groupes de ressources allouent le processeur et la mémoire en fonction de la taille du référentiel :
- SMALL : CPU 500 m, mémoire 1 Go.
- MEDIUM : CPU 1000 m, mémoire 2 Go.
- LARGE : CPU 2000 m, mémoire 4 Go.
La configuration est versionnée, auditable et s'applique automatiquement.
Le modèle parent-enfant
Le modèle d'exécution utilise un modèle de workflow parent-enfant :
- Workflow parent : workflow Cron léger qui s'exécute comme prévu. Chiffre les secrets, détermine si une analyse doit être exécutée, transmet la configuration à l'enfant.
- Workflow enfant : pod éphémère où s'exécute Renovate CLI. Allocation dynamique des ressources, déchiffrement des secrets de manière isolée, arrêt après exécution.
Cette séparation offre sécurité (secrets chiffrés au niveau parent), optimisation des ressources (les parents utilisent des ressources minimales) et scalabilité (les enfants s'exécutent en parallèle).
Résultats
Transformation des performances
- Avant : un référentiel à la fois, certains référentiels n'étaient pas traités, parfois même pendant un jour ou plus, moins de 1 000 analyses par jour.
- Après : plus de 100 analyses simultanées, généralement 8 000 analyses et jusqu'à 10 000 analyses enregistrées par jour, limitées uniquement par la quantité de ressources que nous sommes prêts à consacrer et par la façon dont nous gérons les limites de débit de GitHub.
Rentabilité
Cependant, aussi étrange que cela puisse paraître, exécuter 8 000 pods par jour peut permettre d'obtenir le même résultat à moindre coût qu'avec un seul pod fonctionnant en continu pour tenter d'atteindre le même résultat.
Dans la configuration précédente, nous utilisions une seule instance qui, en conditions optimales, effectuait 500 à 600 analyses. Par ailleurs, comme différents types de référentiels étaient exécutés sur le même pod, nous devions dimensionner celui-ci pour les plus volumineux. Ce dimensionnement était bien supérieur à notre offre actuelle "extra large", qui utilise 8 cœurs de processeur et 16 Go de mémoire par pod.
Pour traiter le volume quotidien actuel, le pod unique devrait s'exécuter pendant 12 jours. Ainsi, en comparant le coût de ce pod unique fonctionnant pendant 12 jours à celui de 8 000 pods de taille "MEDIUM" s'exécutant chaque jour, notre nouvelle architecture est bien plus efficace pour un même volume d'analyses.
| Métrique | Scénario A (workflows) | Scénario B (pod unique et exécution de longue durée) |
|---|---|---|
| Configuration | 8 000 pods (1 vCPU/2 Go) | 1 pod (8 vCPU / 16 Go)* |
| Durée | 10 minutes chacun | 12 jours en continu |
| Temps de travail total | 1 333 heures de calcul | 288 heures de calcul |
| Coût total | 65,83 $ | 113,75 $ |
Cependant, prenons en considération le fait que notre valeur par défaut pour nos charges de travail est définie sur "SMALL", la grande majorité fonctionnant correctement avec une utilisation CPU de 0,5 Go et 1 Go de RAM, et seules quelques-unes nécessitant une configuration moyenne ou grande. Voyons ce qui se passe si 60 % de nos charges de travail s'exécutent sur "SMALL", 30 % sur "MEDIUM" et 10 % sur "LARGE", ce qui est plus proche de la réalité.
| Métrique | Scénario A (essaim mixte) | Scénario B (exécution de longue durée) |
|---|---|---|
| Stratégie | 8 000 pods (tailles variées) | 1 pod (8 vCPU / 16 Go)* |
| Durée | 10 minutes chacun | 12 jours en continu |
| Coût total | 52,66 $ | 113,75 $ |
| Économies | 61,09 $ (54 % moins cher) | — |
Nous pouvons constater que, pour le même volume, nous sommes beaucoup plus rentables dans notre configuration actuelle.
Sécurité renforcée
- Jetons GitHub éphémères (minutes d'exposition contre plusieurs jours).
- Isolation d'espace de nom avec limites de contrôle d'accès basé sur les rôles (RBAC).
- Chiffrement des secrets au repos dans les workflows parents.
- Accès direct au coffre-fort supprimé.
Performance prévisible
Grâce à une fréquence d'analyse garantie, nous pouvons enfin définir des objectifs de niveau de service (SLO). La fusion automatique fonctionne de manière fiable. Les équipes ont confiance en la plateforme pour tenir ses promesses.
Décisions architecturales clés
Voici quelques-unes des décisions de conception majeures qui ont façonné l'apparence de la plateforme.
- Pourquoi des workflows parent-enfant ?
Nous avons adopté ce modèle pour mettre en œuvre une stratégie de défense en profondeur. En limitant les identifiants sensibles (tels que les secrets d'applications GitHub) à un espace de noms dédié et sécurisé, nous utilisons le RBAC pour garantir que les pods d'exécution éphémères ne puissent pas accéder arbitrairement aux données sensibles. De récentes vulnérabilités de la chaîne d'approvisionnement (par exemple, les attaques "Shai Hulud" ciblant l'intégration continue et le déploiement continu [CI/CD]) ont démontré l'importance cruciale d'isoler les environnements d'exécution qui exécutent des scripts dynamiques depuis le magasin d'identifiants.
Simultanément, ce découplage permet une optimisation granulaire des ressources. Les workflows "parents" agissent comme des orchestrateurs légers avec un encombrement minimal, tandis que les workflows "enfants" gèrent l'analyse des dépendances gourmande en ressources IT. Cette séparation simplifie la gestion du cycle de vie en nous permettant d'appliquer une logique de rapprochement distincte à chaque couche, offrant ainsi aux utilisateurs le contrôle des paramètres d'exécution (enfants) tout en conservant le contrôle administratif sur l'infrastructure de planification et de sécurité (parents).
- Pourquoi en libre-service ?
Il était essentiel d'éliminer notre équipe comme goulot d'étranglement pour la configuration des référentiels. Notre mission était de concevoir une plateforme scalable et en libre-service, capable de prendre en charge divers cas d'utilisation. Nous avons constaté qu'il était impossible, compte tenu du nombre considérable de référentiels, de jouer le rôle de contrôleur d'accès pour chaque modification de configuration. Nous avons donc adopté une approche axée sur l'enablement : fournir les "rails" (l'infrastructure et les garde-fous), tout en donnant aux utilisateurs les moyens d'agir et de conduire les "trains" (l'exécution et la personnalisation). Nous pensons que cette évolution vers l'autonomie des équipes améliore considérablement la productivité en permettant aux utilisateurs d'adapter le système à leurs besoins opérationnels spécifiques.
- Pourquoi le modèle d'opérateur Kubernetes ?
Comme indiqué précédemment, un principe de conception fondamental consistait à garantir que la plateforme soit entièrement en libre-service. Nous avions besoin d'un mécanisme automatisé pour capturer les intentions de l'utilisateur (par exemple, activer/désactiver les analyses, ajuster la fréquence de planification ou paramétrer les limites des ressources d'exécution) et transmettre instantanément ces modifications aux workflows sous-jacents. Afin d'anticiper les besoins futurs, le système devait aussi être facilement extensible.
Pour ce faire, nous avons développé un opérateur Kubernetes de gestion des dépendances personnalisé. En utilisant les CRD comme interface de configuration, nous avons établi une boucle de rapprochement native Kubernetes. Cet opérateur surveille en permanence l'état souhaité défini par l'utilisateur et orchestre automatiquement les mises à jour nécessaires de l'infrastructure de workflow. Ceci garantit un fonctionnement transparent et piloté par les événements, où la logique de la plateforme gère toute la complexité en arrière-plan.
- Pourquoi concevoir une passerelle d’événements GitHub ?
L'adoption d'une architecture pilotée par les événements (EDA) était essentielle à la réactivité de la plateforme. Si les workflows Cron fournissaient une planification de base fiable, nous avions besoin d'agilité pour gérer les exécutions ad hoc, comme le déclenchement manuel d'analyses par les utilisateurs via le tableau de bord. Pour ce faire, nous avions besoin d'une passerelle d'ingestion dédiée afin de valider l'intégrité des données et acheminer intelligemment les requêtes.
Nous avons évalué les solutions existantes, notamment l'EventSource natif de GitHub pour Argo, mais nous avons identifié des risques importants liés à la surcharge opérationnelle et aux quotas stricts de l'API GitHub (par exemple, les limites de webhook par référentiel). Par conséquent, nous avons développé une passerelle personnalisée afin de découpler notre infrastructure de ces limitations.
Cette passerelle s'est avérée cruciale en tant que point de contrôle du trafic lors de notre migration. Elle a agi comme un commutateur, nous permettant d'effectuer un déploiement progressif et granulaire (transfert de trafic) de l'ancien système vers la nouvelle infrastructure. Ainsi, l'intégration de milliers de référentiels s'est déroulée de manière contrôlée et sans risque, plutôt que par une transition brutale.
Enseignements
Certains enseignements que nous avons tirés vont de pair avec le code source d'Elastic :
- Priorité au client : les plateformes sont conçues pour les utilisateurs. Il est donc essentiel de placer leurs besoins au cœur de nos priorités. Cela permet de concevoir une infrastructure et des applications performantes qui réduisent les obstacles pour les utilisateurs, simplifient le scaling de la plateforme et facilitent son adoption.
- Espace, temps : parfois, la voie de la facilité mène à des sables mouvants. Nous avons d'abord tenté d'optimiser le modèle de traitement séquentiel existant, mais cela n'a pas résolu nos problèmes ; au contraire, cela n'a fait qu'accroître la complexité et créer des zones d'ombre. La décision audacieuse de repenser l'architecture de la plateforme avec un traitement parallèle a nécessité un investissement initial important. Cependant, elle a finalement ouvert la voie à une croissance durable de la plateforme et a quasiment éliminé les tâches administratives quotidiennes fastidieuses.
- Informatique, dépendances : une plateforme ne peut pas fonctionner de manière isolée ; son succès dépend de la manière dont elle s'intègre dans un écosystème plus large. Dans notre cas, l'intégration à Backstage était essentielle, car elle constitue la source de référence pour une intégration fluide des services. De même, la connexion à Artifactory nous a permis de gérer efficacement les mises à jour des packages privés, et la liste des intégrations essentielles ne s'arrête pas là.
- Progrès, perfection SIMPLE : tout au long de la mise en œuvre, nous avons constamment testé nos hypothèses initiales et nous nous sommes adaptés aux nouveaux obstacles à mesure qu'ils apparaissaient. Plutôt que de nous laisser paralyser par le perfectionnisme, nous avons adopté une approche itérative, en relevant les défis les uns après les autres et en ajustant notre stratégie de migration aux conditions réelles.
Prochaines étapes
La mise en place de la plateforme nous permet de nous consacrer à des tâches plus importantes qui contribueront à améliorer l'expérience utilisateur et l'efficacité de notre plateforme. En voici quelques exemples :
- Renforcer et garantir l'adoption de la fusion automatique
La fonctionnalité de fusion automatique accélère considérablement la rapidité de l'équipe en éliminant les tâches manuelles fastidieuses. Toutefois, il est essentiel de mettre en place des garde-fous stricts afin de garantir que cette rapidité accrue ne s'obtienne pas au détriment de la sécurité.
- Améliorer la visibilité sur l'expérience des utilisateurs finaux
L'une des priorités essentielles de notre feuille de route est l'amélioration de l'observabilité, non seulement au niveau de la plateforme, mais aussi du point de vue de l'utilisateur final. Si la collecte des indicateurs d'infrastructure est simple, la compréhension de l'expérience utilisateur réelle exige une analyse plus approfondie. Nous travaillons à la définition d'indicateurs clés de performance (KPI) centrés sur l'utilisateur afin que notre système de télémétrie puisse détecter les points de friction et les problèmes de performance avant qu'ils ne se transforment en plaintes d'utilisateurs.
- Supprimer les obstacles à une plus grande adoption
Pour l'avenir, notre priorité est d'identifier et de lever les obstacles à l'adoption de la plateforme. Qu'il s'agisse de développer de nouvelles intégrations ou de déployer des fonctionnalités spécifiques, nous privilégions une planification fondée sur les données. Nous avons développé avec succès une plateforme conçue pour évoluer ; notre objectif est désormais d'en maximiser le potentiel.
Le tableau d'ensemble
Le projet de workflows de gestion des dépendances illustre un principe plus large : lorsque vous devez scaler des outils open source au-delà de leur modèle de déploiement par défaut, les modèles natifs Kubernetes offrent une voie à suivre.
En adoptant :
- Les CRD pour la configuration.
- Les opérateurs pour la gestion du cycle de vie.
- Une architecture basée sur les événements pour une meilleure réactivité
- GitOps pour le déploiement.
Nous avons conçu une orchestration qui scale indépendamment du nombre de référentiels gérés. Les performances d'analyse d'un seul référentiel restent identiques, que nous en gérions 100 ou 1 000.
Lorsqu'une CVE critique est annoncée, nous obtenons désormais des réponses en quelques minutes, et non plus en quelques heures. C'est ce qui fait la différence entre un goulot d'étranglement et un avantage concurrentiel.
Remerciements
Cette plateforme s'appuie sur d'excellents outils open source :
- Kubebuilder : le framework open source que nous avons utilisé pour lancer nos opérateurs Kubernetes qui démarrent et orchestrent nos workflows. [1][2]
- Backstage : le framework open source sur lequel nous avons construit notre catalogue de services et que nous utilisons comme source de référence. [1][2]
- Argo Workflows et Argo Events : la suite open source que nous avons utilisée pour orchestrer des processus complexes et ajouter un traitement dynamique basé sur des événements. [1][2][3][4]
- Renovate CLI : l'outil open source de gestion des dépendances qui traite nos référentiels. [1][2]
* Le modèle de tarification AWS Fargate a été utilisé comme référence pour le coût d'un seul pod, bien que nos charges de travail ne s'exécutent pas nécessairement sur AWS et s'exécutent sur des clusters Kubernetes complets.
Pour aller plus loin

20 avril 2026
Présentation des clés API unifiées pour Elastic Cloud Serverless et Elasticsearch
Découvrez comment Elastic unifie l’authentification des plans de contrôle et des plans de données dans Serverless grâce à une architecture IAM distribuée à l’échelle mondiale. Utilisez une seule clé API pour les API Cloud et Elasticsearch.
3 avril 2026
Monitorer des vues des tableaux de bord Kibana avec Elastic Workflows
Découvrez comment utiliser Elastic Workflows pour collecter les indicateurs des vues du tableau de bord Kibana toutes les 30 minutes et les indexer dans Elasticsearch, afin de pouvoir créer des analyses et des visualisations personnalisées à partir de vos propres données.

7 novembre 2025
Présentation de l'interface utilisateur des règles de requête Elasticsearch dans Kibana
Découvrez comment utiliser l'interface utilisateur Elasticsearch Query Rules pour ajouter ou exclure des documents des requêtes de recherche à l'aide d'ensembles de règles personnalisables dans Kibana, sans affecter le classement organique.

6 novembre 2025
Construire un agent de connaissance avec rappel sémantique en utilisant Mastra et Elasticsearch
Apprenez à construire un agent de connaissance avec rappel sémantique en utilisant Mastra et Elasticsearch comme magasin vectoriel pour la mémoire et la recherche d'informations.

22 mai 2026
Kibana réduit le temps de chargement des tableaux de bord jusqu'à 25 %. Voici la stratégie d'interrogation qui se cache derrière
Découvrez comment Kibana utilise l'interrogation continue et la détection HTTP/2 côté navigateur pour réduire les temps de chargement des tableaux de bord jusqu'à 25 %, avec repli automatique sur HTTP/1.