L'ingénierie contextuelle devient de plus en plus importante dans la construction d'agents et d'architectures d'IA fiables. Au fur et à mesure que les modèles s'améliorent, leur efficacité et leur fiabilité dépendent moins de leurs données d'entraînement que de leur ancrage dans le bon contexte. Les agents qui peuvent récupérer et appliquer les informations les plus pertinentes au bon moment sont beaucoup plus susceptibles de produire des résultats précis et fiables.
Dans ce blog, nous utiliserons Mastra pour construire un agent de connaissance qui se souvient de ce que les utilisateurs disent et peut rappeler les informations pertinentes plus tard, en utilisant Elasticsearch comme mémoire et backend de récupération. Vous pouvez facilement étendre ce même concept à des cas d'utilisation réels, comme des agents d'assistance qui peuvent se souvenir de conversations et de résolutions antérieures, ce qui leur permet d'adapter les réponses à des utilisateurs spécifiques ou de trouver des solutions plus rapidement en fonction du contexte antérieur.
Suivez ici les étapes de sa construction. Si vous vous perdez ou si vous voulez simplement exécuter un exemple fini, consultez le repo ici.
Qu'est-ce que Mastra ?
Mastra est un framework TypeScript open-source pour la construction d'agents d'intelligence artificielle avec des parties interchangeables pour le raisonnement, la mémoire et les outils. Sa fonction de rappel sémantique permet aux agents de se souvenir des interactions passées et de les retrouver en stockant les messages sous forme d'enchâssements dans une base de données vectorielle. Cela permet aux agents de conserver le contexte et la continuité de la conversation à long terme. Elasticsearch est un excellent magasin de vecteurs pour activer cette fonctionnalité, car il prend en charge la recherche vectorielle dense efficace. Lorsque le rappel sémantique est déclenché, l'agent introduit les messages antérieurs pertinents dans la fenêtre contextuelle du modèle, ce qui permet à ce dernier d'utiliser le contexte récupéré comme base de son raisonnement et de ses réponses.
Ce qu'il faut pour commencer
- Node v18+
- Elasticsearch (version 8.15 ou plus récente)
- Clé API Elasticsearch
- Clé API OpenAI
Note : Vous en aurez besoin parce que la démo utilise le fournisseur OpenAI, mais Mastra prend en charge d'autres SDK d'IA et fournisseurs de modèles communautaires, vous pouvez donc facilement l'échanger en fonction de votre configuration.
Construire un projet Mastra
Nous utiliserons le CLI intégré de Mastra pour fournir l'échafaudage de notre projet. Exécutez la commande :
Vous obtiendrez une série d'invites, commençant par :
1. Donnez un nom à votre projet.

2. Nous pouvons conserver cette valeur par défaut ; n'hésitez pas à la laisser vide.

3. Pour ce projet, nous utiliserons un modèle fourni par OpenAI.

4. Sélectionnez l'option "Skip for now" car nous allons stocker toutes nos variables d'environnement dans un fichier `.env` que nous configurerons plus tard.

5. Nous pouvons également ignorer cette option.

Sauter l'installation du serveur MCP de Mastra
Une fois l'initialisation terminée, nous pouvons passer à l'étape suivante.
Installation des dépendances
Ensuite, nous devons installer quelques dépendances :
ai- Ensemble de SDK d'IA de base qui fournit des outils pour gérer les modèles d'IA, les invites et les flux de travail en JavaScript/TypeScript. Mastra est construit sur le SDK AI de Vercel, nous avons donc besoin de cette dépendance pour permettre les interactions du modèle avec votre agent.@ai-sdk/openai- Plugin qui connecte le SDK AI aux modèles OpenAI (comme GPT-4, GPT-4o, etc.), permettant des appels API en utilisant votre clé API OpenAI.@elastic/elasticsearch- Client Elasticsearch officiel pour Node.js, utilisé pour se connecter à votre Elastic Cloud ou à votre cluster local pour l'indexation, la recherche et les opérations vectorielles.dotenv- Charge les variables d'environnement à partir d'un fichier .env dans le fichier process.env, vous permettant d'injecter en toute sécurité des informations d'identification telles que des clés d'API et des points d'extrémité Elasticsearch.
Configuration des variables d'environnement
Créez un fichier .env dans le répertoire racine de votre projet si vous n'en avez pas déjà un. Vous pouvez également copier et renommer l'exemple .env que j'ai fourni dans le répertoire. Dans ce fichier, nous pouvons ajouter les variables suivantes :
Voilà qui conclut la configuration de base. À partir de là, vous pouvez déjà commencer à construire et à orchestrer des agents. Nous allons aller plus loin et ajouter Elasticsearch en tant que couche de stockage et de recherche vectorielle.
Ajouter Elasticsearch comme magasin de vecteurs
Créez un nouveau dossier appelé stores et ajoutez-y ce fichier. Avant que Mastra et Elastic ne proposent une intégration officielle de Elasticsearch vector store, Abhi Aiyer(Mastra CTO) a partagé ce prototype de classe appelé ElasticVector. Simplement, il relie l'abstraction mémoire de Mastra aux capacités vectorielles denses d'Elasticsearch, de sorte que les développeurs peuvent utiliser Elasticsearch comme base de données vectorielle pour leurs agents.
Examinons plus en détail les éléments importants de l'intégration :
Ingestion du client Elasticsearch
Cette section définit la classe ElasticVector et met en place la connexion du client Elasticsearch avec un support pour les déploiements standards et sans serveur.
ElasticVectorConfig extends ClientOptions: Ceci crée une nouvelle interface de configuration qui hérite de toutes les options du client Elasticsearch (commenode,auth,requestTimeout) et ajoute nos propriétés personnalisées. Cela signifie que les utilisateurs peuvent passer n'importe quelle configuration Elasticsearch valide avec nos options spécifiques au serveur.extends MastraVector: Cela permet àElasticVectord'hériter de la classe de baseMastraVectorde Mastra, qui est une interface commune à laquelle se conforment toutes les intégrations de magasins vectoriels. Cela garantit qu'Elasticsearch se comporte comme n'importe quel autre backend vectoriel Mastra du point de vue de l'agent.private client: Client: Il s'agit d'une propriété privée qui contient une instance du client JavaScript Elasticsearch. Cela permet à la classe de s'adresser directement à votre cluster.isServerlessetdeploymentChecked: Ces propriétés fonctionnent ensemble pour détecter et mettre en cache si nous sommes connectés à un déploiement Elasticsearch standard ou sans serveur. Cette détection se fait automatiquement lors de la première utilisation ou peut être configurée explicitement.constructor(config: ClientOptions): Ce constructeur prend un objet de configuration (contenant vos identifiants Elasticsearch et des paramètres serverless optionnels) et l'utilise pour initialiser le client dans la lignethis.client = new Client(config).super(): Il appelle le constructeur de base de Mastra, ce qui lui permet d'hériter de la journalisation, des aides à la validation et d'autres crochets internes.
À ce stade, Mastra sait qu'il existe un nouveau magasin de vecteurs appelé ElasticVector
Détection du type de déploiement
Avant de créer des index, l'adaptateur détecte automatiquement si vous utilisez Elasticsearch standard ou Elasticsearch Serverless. C'est important car les déploiements sans serveur ne permettent pas la configuration manuelle des shards.
Ce qui se passe :
- Vérifie d'abord si vous avez explicitement défini
isServerlessdans la configuration (ignore l'autodétection). - Appelle l'API
info()d'Elasticsearch pour obtenir des informations sur les clusters. - Vérifie le
build_flavor field(les déploiements sans serveur renvoientserverless). - Renvoie à la vérification du slogan si la saveur de la construction n'est pas disponible
- Met en cache le résultat afin d'éviter les appels répétés à l'API
- Déploiement standard par défaut en cas d'échec de la détection
Exemple d'utilisation :
Création du magasin "memory" dans Elasticsearch
La fonction ci-dessous met en place un index Elasticsearch pour le stockage des embeddings. Il vérifie si l'index existe déjà. Si ce n'est pas le cas, il en crée un avec le mappage ci-dessous qui contient un champ dense_vector pour stocker les embeddings et les métriques de similarité personnalisées.
Quelques points à noter :
- Le paramètre
dimensionest la longueur de chaque vecteur d'intégration, qui dépend du modèle d'intégration utilisé. Dans notre cas, nous allons générer des embeddings en utilisant le modèletext-embedding-3-smalld'OpenAI, qui produit des vecteurs de taille1536. Nous l'utiliserons comme valeur par défaut. - La variable
similarityutilisée dans la correspondance ci-dessous est définie à partir de la fonction d'aide const similarity = this.mapMetricToSimilarity(metric), qui prend la valeur du paramètremetricet la convertit en un mot-clé compatible avec Elasticsearch pour la métrique de distance choisie.- Par exemple : Mastra utilise des termes généraux pour la similarité vectorielle comme
cosine,euclidean, etdotproduct. Si nous devions passer la métriqueeuclideandirectement dans le mappage Elasticsearch, une erreur se produirait car Elasticsearch s'attend à ce que le mot-clél2_normreprésente la distance euclidienne.
- Par exemple : Mastra utilise des termes généraux pour la similarité vectorielle comme
- Compatibilité sans serveur : Le code omet automatiquement les paramètres de shard et de réplique pour les déploiements sans serveur, car ils sont gérés automatiquement par Elasticsearch Serverless.
Enregistrement d'un nouveau souvenir ou d'une nouvelle note après une interaction
Cette fonction prend les nouveaux embeddings générés après chaque interaction, ainsi que les métadonnées, puis les insère ou les met à jour dans l'index à l'aide de l'API bulk d'Elastic. L'API bulk regroupe plusieurs opérations d'écriture en une seule demande ; cette amélioration de nos performances d'indexation garantit que les mises à jour restent efficaces alors que la mémoire de notre agent ne cesse de croître.
Interrogation des vecteurs similaires pour le rappel sémantique
Cette fonction est au cœur de la fonction de rappel sémantique. L'agent utilise la recherche vectorielle pour trouver des enregistrements similaires dans notre index.
Sous le capot :
- Exécute une requête kNN (k-nearest neighbors) à l'aide de l'API
knndans Elasticsearch. - Récupère les K premiers vecteurs similaires au vecteur d'entrée de la requête.
- Possibilité d'appliquer des filtres de métadonnées pour limiter les résultats (par exemple, recherche uniquement dans une catégorie ou une période spécifique).
- Renvoie des résultats structurés comprenant l'identifiant du document, le score de similarité et les métadonnées stockées.
Création de l'agent de connaissance
Maintenant que nous avons vu la connexion entre Mastra et Elasticsearch à travers l'intégration ElasticVector, créons l'agent de connaissance lui-même.
Dans le dossier agents, créez un fichier appelé knowledge-agent.ts. Nous pouvons commencer par connecter nos variables d'environnement et initialiser le client Elasticsearch.
Ici, nous :
- Utilisez
dotenvpour charger nos variables à partir de notre fichier.env. - Vérifiez que les informations d'identification Elasticsearch sont injectées correctement et que nous pouvons établir une connexion réussie avec le client.
- Passez le point de terminaison Elasticsearch et la clé API dans le constructeur
ElasticVectorpour créer une instance de notre magasin vectoriel que nous avons défini plus tôt. - Spécifiez éventuellement
isServerless: truesi vous utilisez Elasticsearch Serverless. Cela permet d'éviter l'étape d'autodétection et d'améliorer le temps de démarrage. S'il est omis, l'adaptateur détectera automatiquement votre type de déploiement lors de la première utilisation.
Ensuite, nous pouvons définir l'agent à l'aide de la classe Agent de Mastra.
Les champs que nous pouvons définir sont les suivants :
nameetinstructions: lui donner une identité et une fonction première.model: Nous utilisonsgpt-4od'OpenAI à travers le paquet@ai-sdk/openai.memory:vector: Pointe vers notre magasin Elasticsearch, de sorte que les embeddings sont stockés et récupérés à partir de ce magasin.embedder: Quel modèle utiliser pour générer des embeddings ?semanticRecalldécident de la manière dont le rappel fonctionne :topK: Nombre de messages sémantiquement similaires à récupérer.messageRange: Quelle partie de la conversation doit être incluse dans chaque match.scope: Définit la limite de la mémoire.
Presque terminé. Il ne nous reste plus qu'à ajouter cet agent nouvellement créé à notre configuration Mastra. Dans le fichier appelé index.ts, importez l'agent de connaissance et insérez-le dans le champ agents.
Les autres champs sont les suivants :
storage: Il s'agit du magasin de données interne de Mastra pour l'historique des exécutions, les mesures d'observabilité, les scores et les caches. Pour plus d'informations sur le stockage Mastra, cliquez ici.logger: Mastra utilise Pino, qui est un enregistreur JSON structuré et léger. Il capture des événements tels que le démarrage et l'arrêt de l'agent, les appels d'outils et les résultats, les erreurs et les temps de réponse du LLM.observability: Contrôle le suivi de l'IA et la visibilité de l'exécution pour les agents. Il suit :- Début/fin de chaque étape du raisonnement.
- Quel modèle ou outil a été utilisé.
- Entrées et sorties.
- Notes et évaluations
Test de l'agent avec Mastra Studio
Félicitations ! Si vous êtes arrivé jusqu'ici, vous êtes prêt à faire fonctionner cet agent et à tester ses capacités de rappel sémantique. Heureusement, Mastra fournit une interface de chat intégrée, ce qui nous évite d'avoir à créer notre propre interface.
Pour démarrer le serveur de développement Mastra, ouvrez un terminal et exécutez la commande suivante :
Après le regroupement initial et le démarrage du serveur, celui-ci devrait vous fournir une adresse pour le terrain de jeu.

Collez cette adresse dans votre navigateur et vous serez accueilli par le Mastra Studio.
Sélectionnez l'option knowledgeAgent et discutez.
Pour vérifier rapidement si tout est bien branché, donnez-lui des informations telles que : "L'équipe a annoncé que les ventes d'octobre ont augmenté de 12%, principalement grâce aux renouvellements de contrats d'entreprise. La prochaine étape consistera à élargir le champ d'action aux clients du marché intermédiaire". Ensuite, démarrez un nouveau chat et posez une question du type : "Sur quel segment de clientèle avons-nous dit que nous devions nous concentrer ensuite ?". L'agent de connaissance doit pouvoir se souvenir des informations que vous lui avez communiquées lors de la première conversation. Vous devriez obtenir une réponse du type

Une telle réponse signifie que l'agent a stocké avec succès notre message précédent sous forme d'éléments intégrés dans Elasticsearch et qu'il l'a récupéré ultérieurement à l'aide d'une recherche vectorielle.
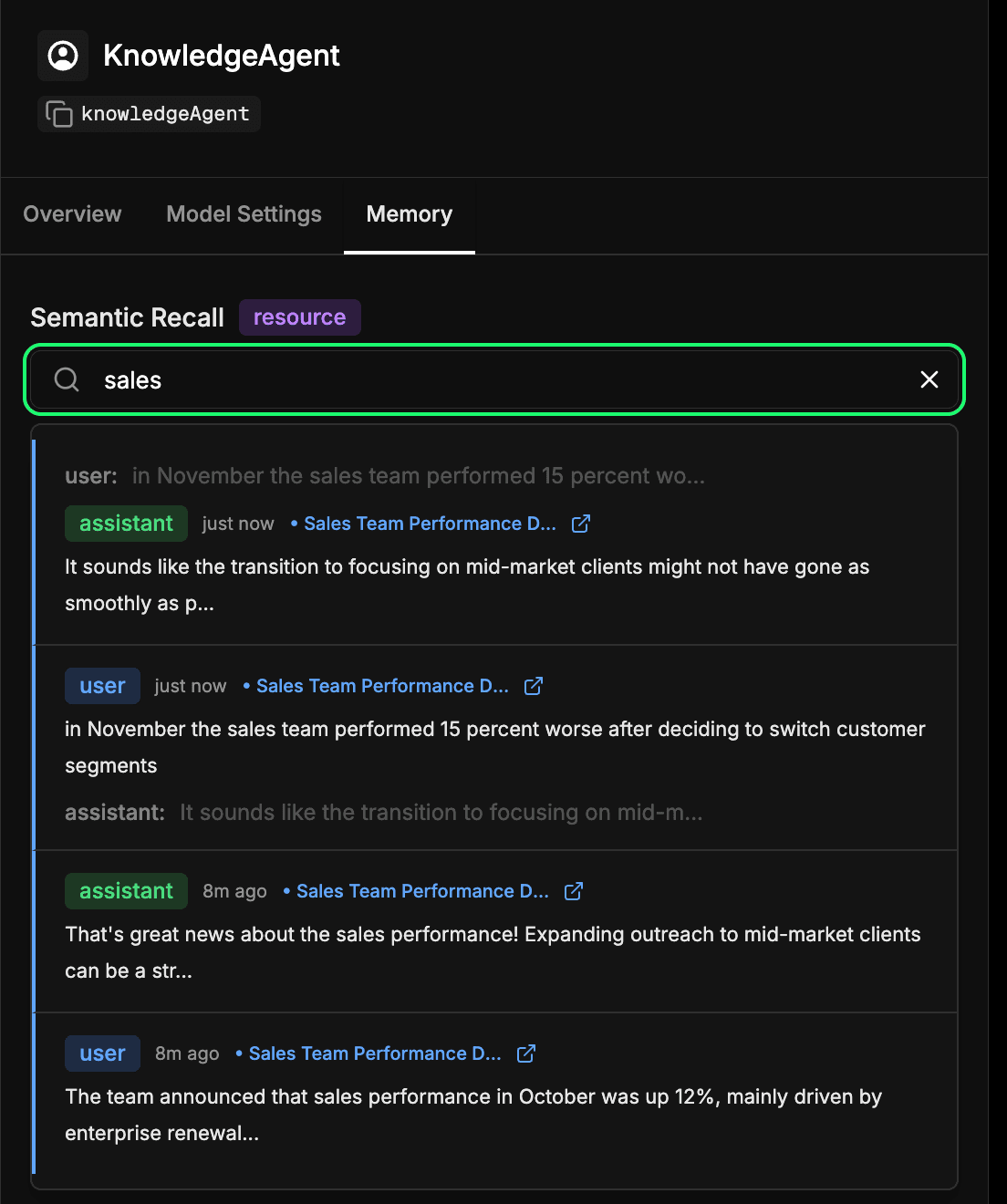
Inspection de la mémoire à long terme de l'agent
Rendez-vous sur l'onglet memory dans la configuration de votre agent dans le Studio Mastra. Cela vous permet de voir ce que votre agent a appris au fil du temps. Chaque message, réponse et interaction qui est intégré et stocké dans Elasticsearch fait partie de cette mémoire à long terme. Vous pouvez effectuer une recherche sémantique dans les interactions passées pour retrouver rapidement les informations ou le contexte que l'agent a appris précédemment. Il s'agit essentiellement du même mécanisme que celui utilisé par l'agent lors du rappel sémantique, mais ici, vous pouvez l'inspecter directement. Dans l'exemple ci-dessous, nous recherchons le terme "ventes" et nous obtenons en retour toutes les interactions qui contiennent un élément relatif aux ventes.
Conclusion
En connectant Mastra et Elasticsearch, nous pouvons donner à nos agents de la mémoire, qui est une couche clé dans l'ingénierie contextuelle. Grâce au rappel sémantique, les agents peuvent construire un contexte au fil du temps, en fondant leurs réponses sur ce qu'ils ont appris. Cela signifie des interactions plus précises, plus fiables et plus naturelles.
Cette intégration précoce n'est que le point de départ. Le même modèle peut permettre aux agents d'assistance de se souvenir des tickets précédents, aux robots internes de retrouver la documentation pertinente ou aux assistants d'IA de se souvenir des détails d'un client au cours d'une conversation. Nous travaillons également à l'intégration officielle de Mastra, afin de rendre cette association encore plus transparente dans un avenir proche.
Nous sommes impatients de voir ce que vous allez construire. Essayez-le, explorez Mastra et ses fonctions de mémoire, et n'hésitez pas à partager vos découvertes avec la communauté.
Pour aller plus loin

11 mai 2026
Apporter du dynamisme à Elasticsearch : intégration de la prise en charge native de l’API Prometheus
Interrogez Elasticsearch directement depuis des clients compatibles Prometheus via les points de terminaison natifs PromQL, de découverte et de métadonnées. Envoyez des données à Elasticsearch avec Prometheus Remote Write.

20 avril 2026
Présentation des clés API unifiées pour Elastic Cloud Serverless et Elasticsearch
Découvrez comment Elastic unifie l’authentification des plans de contrôle et des plans de données dans Serverless grâce à une architecture IAM distribuée à l’échelle mondiale. Utilisez une seule clé API pour les API Cloud et Elasticsearch.

8 avril 2026
Comment créer des applications d'IA agentique avec Mastra et Elasticsearch
Découvrez comment créer des applications d'IA agentiques avec Mastra et Elasticsearch à travers un exemple pratique.
3 avril 2026
Monitorer des vues des tableaux de bord Kibana avec Elastic Workflows
Découvrez comment utiliser Elastic Workflows pour collecter les indicateurs des vues du tableau de bord Kibana toutes les 30 minutes et les indexer dans Elasticsearch, afin de pouvoir créer des analyses et des visualisations personnalisées à partir de vos propres données.

25 mars 2026
L'outil shell n'est pas une solution miracle pour l'ingénierie du contexte
Découvrez quels outils de récupération de contexte existent pour l'ingénierie contextuelle, comment ils fonctionnent et leurs compromis.