以下は、Kubernetes、Argo Workflows、Argo Events、Renovate CLIを使用して、更新を自動化し、Common Vulnerabilities and Exposures(CVE)に迅速に対処し、何千ものリポジトリ全体で新しいパッケージバージョンを効率的に伝播するセルフホスト型の依存関係管理プラットフォームを構築した方法です。
Elasticでの依存関係管理
Elasticでは、プライベートとパブリックの両方で、数百、数千ものリポジトリを管理する必要があります。重大なCVEが発見された場合、どのリポジトリが脆弱であるかを即座に回答して対処する必要があります。どれくらい早くパッチを当てられるでしょうか。セキュリティとは別に、生産性に関する質問も出てきます。手動のタスクにあまり時間をかけずに、新しいパッケージバージョンのリリースを、それに依存するすべてのリポジトリに迅速に広めるにはどうすればよいでしょうか。
依存関係管理の方法を探す最初のきっかけは、CVE削減のための自動更新を備えた安全な基盤を確立する必要性でした。依存関係管理に関するソリューションを慎重に検討した後、まずセルフホスト型のインフラストラクチャーの作業を開始しました。私たちは独自のKubernetesクラスターを使用して、Mend Renovate Community Self-Hostedを実行していました。ユーザーがセルフサービスでアクセスできる依存関係管理プラットフォームを提供するというアイデアがありました。
最初の実験が成功したため、より多くのチームが私たちのプラットフォームを導入し、日常のリポジトリのライフサイクルにおける更新やCVEパッチ適用に使用するようになりました。この展開は非常に速く、私たちはすぐにセルフマネージドインストールの限界に達しました。

図1:Elastic における依存関係管理の概要。
課題:多数のリポジトリを持つ大規模な組織で依存関係管理プラットフォームを拡張するにはどうすればよいでしょうか。
当社の依存関係管理プラットフォームは、一度に1つのリポジトリを処理しており、シーケンシャルな処理モデルでは、当社の所有する多数のリポジトリに対応できませんでした。依存関係管理ツールの単一のインスタンスで拡大し続けるリポジトリのリストを処理するという概念に問題があることは、すでに認識していました。リポジトリはキュー内に留まり、場合によっては何時間も待機することがありました。リポジトリの50%以上は毎日処理されていませんでした。つまり、当社のリポジトリの50%以上がスキャン間でを24時間以上待っていたということです。
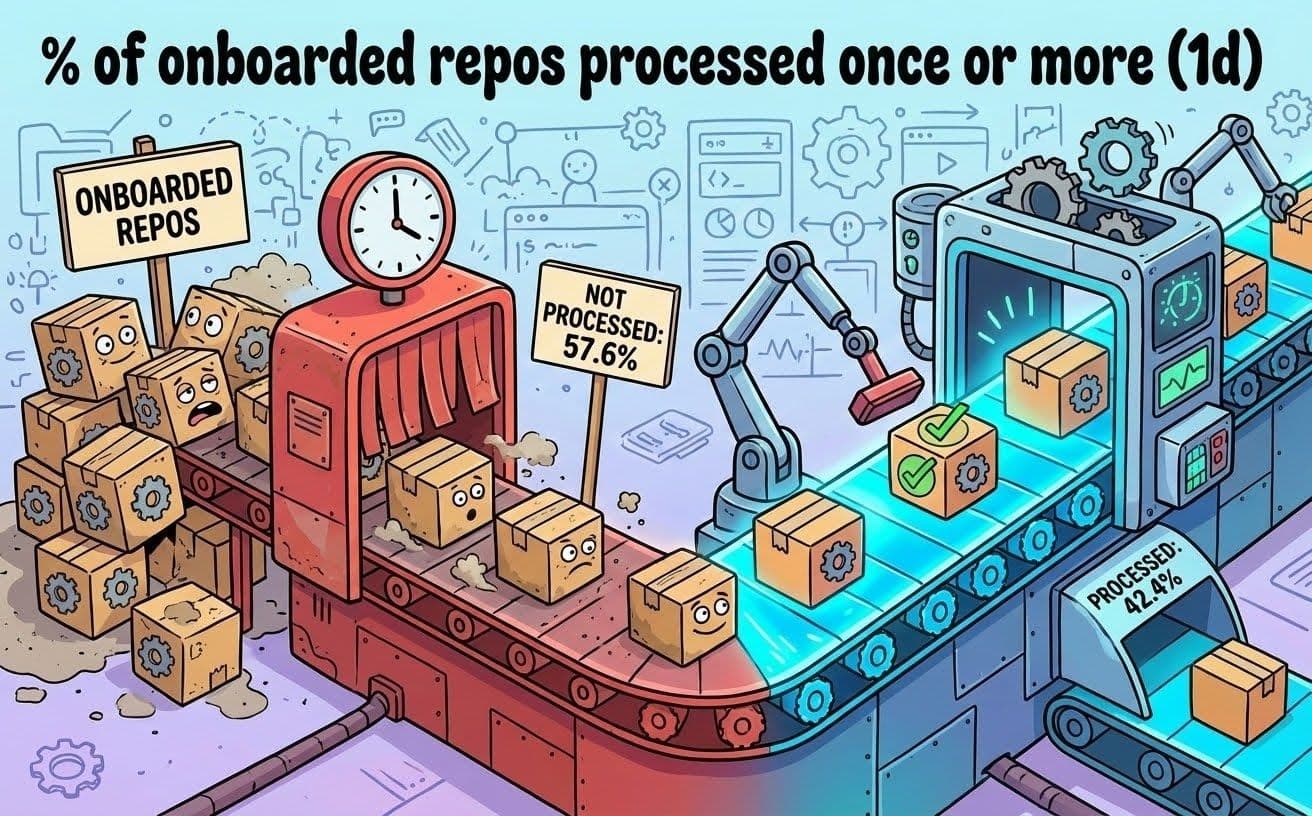
図2:毎日少なくとも1回処理されるリポジトリの数(Nano Bananaで作成)。
大規模なリポジトリでは、コードベースのサイズが大きく、PRが複数オープンしているため、ボトルネックが大きくなります。GitHub Webhookイベントによりこのシーケンスが中断されました。スキャンのタイミングが予測できないため、Automergeの信頼性が低下しました。スキャンの頻度についてはユーザーと約束していましたが、それを果たすことができませんでした。
社内で構築するという決定:Elastic独自のスケールとセキュリティのニーズに対応
商用オプション、具体的にはMendのRenovate Self-Hosted Enterprise Self-Hosted版も検討しましたが、Elastic社内ではいくつかの主要な取り組みが進行中でした。
社内プラットフォームを構築するという当社の決定は、Elastic の特定の譲れない要件を満たすには、徹底的にカスタマイズされたソリューションしかないという認識に基づいていました。
- 内部開発者プラットフォームへの投資:当時、私たちはすでに内部開発者プラットフォームに多額の投資を行っていました。それぞれのサービスをこれに適合させる方法について議論し、設計していました。つまり、依存関係管理プラットフォームの独自のルールと実践をテストドライブするというニーズがあり、それに加えて、新しいガイドラインが導入されることになり、イベントに先立ってプラットフォームを設計したいと考えていました。
- ネイティブ統合とワークフローのカスタマイズ:社内ツールや社内プロセスとの簡単な統合が必要で、例えば、Service Catalog(Backstage)を使用して構成をコードとして一元管理したいと考えていました。Backstageの使用に関しては、特定のニーズがあり、当社のプラットフォームと互換性を持たせたいと考えていました。したがって、Renovate Self-Hosted APIをBackstageの自動化と併用することは可能ですが、これでは当社の内部プロセスを完全にカバーすることはできません。
- Elastic特有の徹底したセキュリティ対策:当社の厳格なセキュリティコンプライアンスには、当社のエコシステムに合わせた特注のセキュリティメカニズムが必要でした。「非人間的アイデンティティ」の使用の強化に取り組んでいました。このアクセス強化の仕組みにより、GitHub への認証を行う非標準の手段は、この内部実装をサポートしていない市販のツールでは機能しなくなります。当社のワークフローには、親子ワークフローの秘密の暗号化パターンを実装し、一時的な使い捨てのGitHubトークンを使用することが含まれていました。社内で構築することが、これらの独自のセキュリティレイヤーを組み込み、複雑なマルチクラウド環境全体の攻撃対象領域を最小限に抑える唯一の実用的な方法でした。
解決策:依存関係管理のためのワークフローオーケストレーション
解決策の構築は、既に使用している依存関係管理ツールを基に構築し、それを置き換えたり他のソリューションを探したりするのではなく、その上に構築することから始まりました。その可能性の兆しはあり、その柔軟性は組織全体のさまざまなニーズにとって重要です。さまざまなソリューションを検討しましたが、最終的に決め手となったのは、カバーしなければならない大きくて時に特殊なニーズでした。私たちは、各リポジトリが独自に処理され、ボトルネックを解消して成長に備えられる、信頼性が高くスケーラブルな依存関係管理プラットフォームを構築することを決定しました。
プラットフォームは次の3つのコア原則に従って設計しました。
1. 並列処理
各リポジトリに独自の依存関係管理処理環境が与えられます。キューはなくなります。同時実行性は、消費するリソースの数によってのみ制限されます。また、GitHubでレート制限を受けないようにスマートな分散スケジューリングを適用しました。
2.セルフサービス可能
Service Catalog(Backstage)を使用して、新しいリポジトリを自動的にオンボードして管理します。独自のリソース定義を使用して、エンドユーザーにリポジトリの処理頻度を選択するオプション、スケジュールに割り当てるリソースの量、何らかの理由で処理をオンまたはオフにするオプションを提供します。ユーザーのニーズが進化し、新しいインストールに慣れてきたら、そのようにしてさらに多くのオプションを追加していく予定です。
3. シークレットのスコープと名前空間の分離の縮小
セキュリティを強化するために、各ワークフローの開始時に生成される一時的なGitHubトークンを依存関係管理ポッドに提供します。さらに、ワークロードを特定の名前空間に分離して、必要なシークレットのみが提供されるようにします。Kubernetes RBACを使用して、各依存関係管理ワークフローでアクセスできるシークレットを制御します。また、暗号化を使用して、親ワークフローから子ワークフローにGitHubトークンを伝播します。
Kubernetesを使用してプラットフォームを再構築し、Kubernetesのパワーを活用しました。Argo Workflowsはプロセスのロジックを強化し、Renovate CLIはリポジトリを一度に1つずつスキャンして処理するように設定されています。
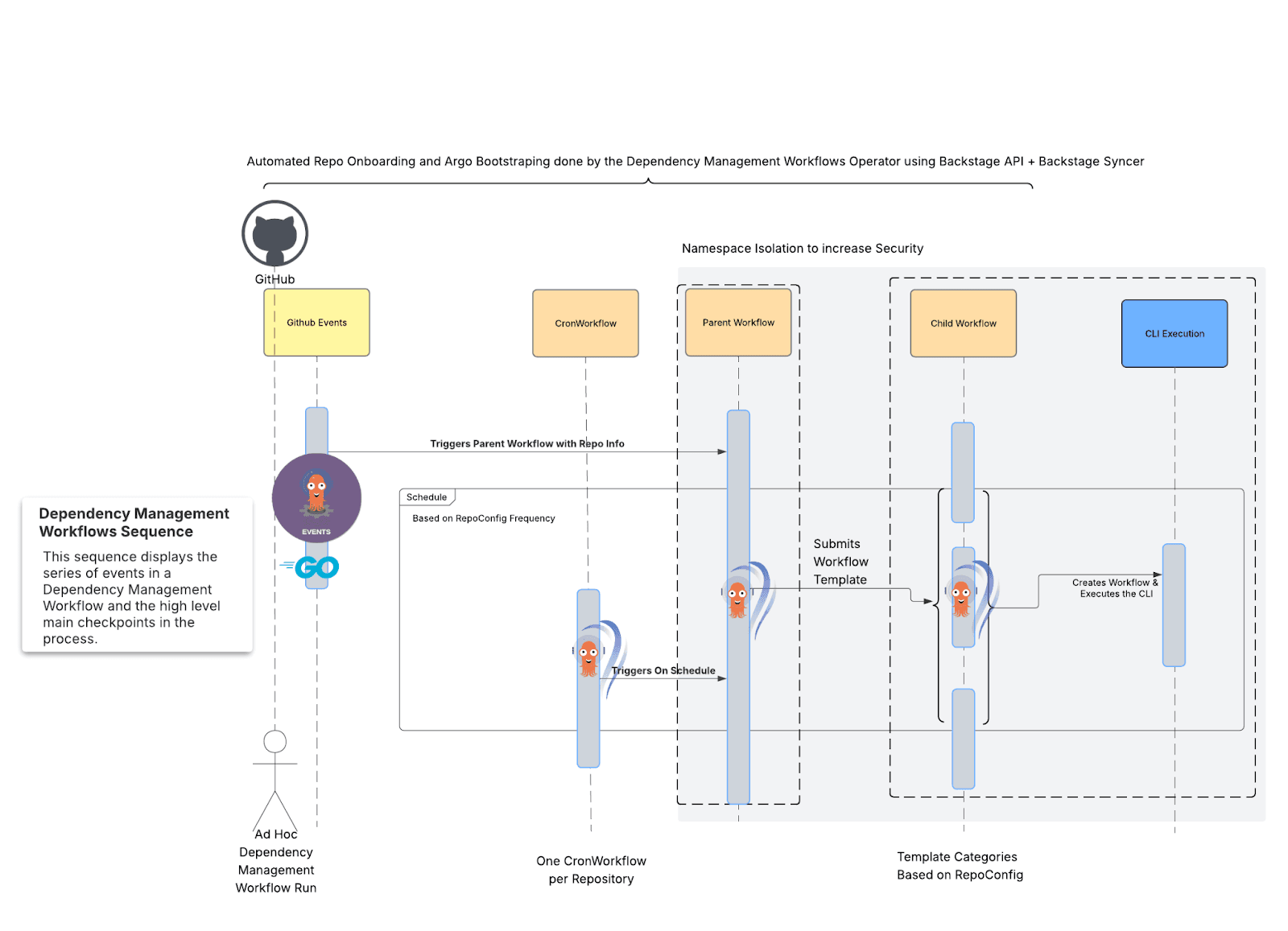
図3:新しい依存関係管理ワークフローの概要。
ここで素晴らしい点は、実績のあるオープンソースプロジェクトを独自の方法で使用し、すべてのプロジェクトに新しい実用的な例を提供すると同時に、開発速度を増幅し、チームのCVE削減を強化していることです。
依存関係管理アーキテクチャー:4つのマイクロサービス
このプラットフォームは、次の4つのカスタムビルドコンポーネントで構成されています。
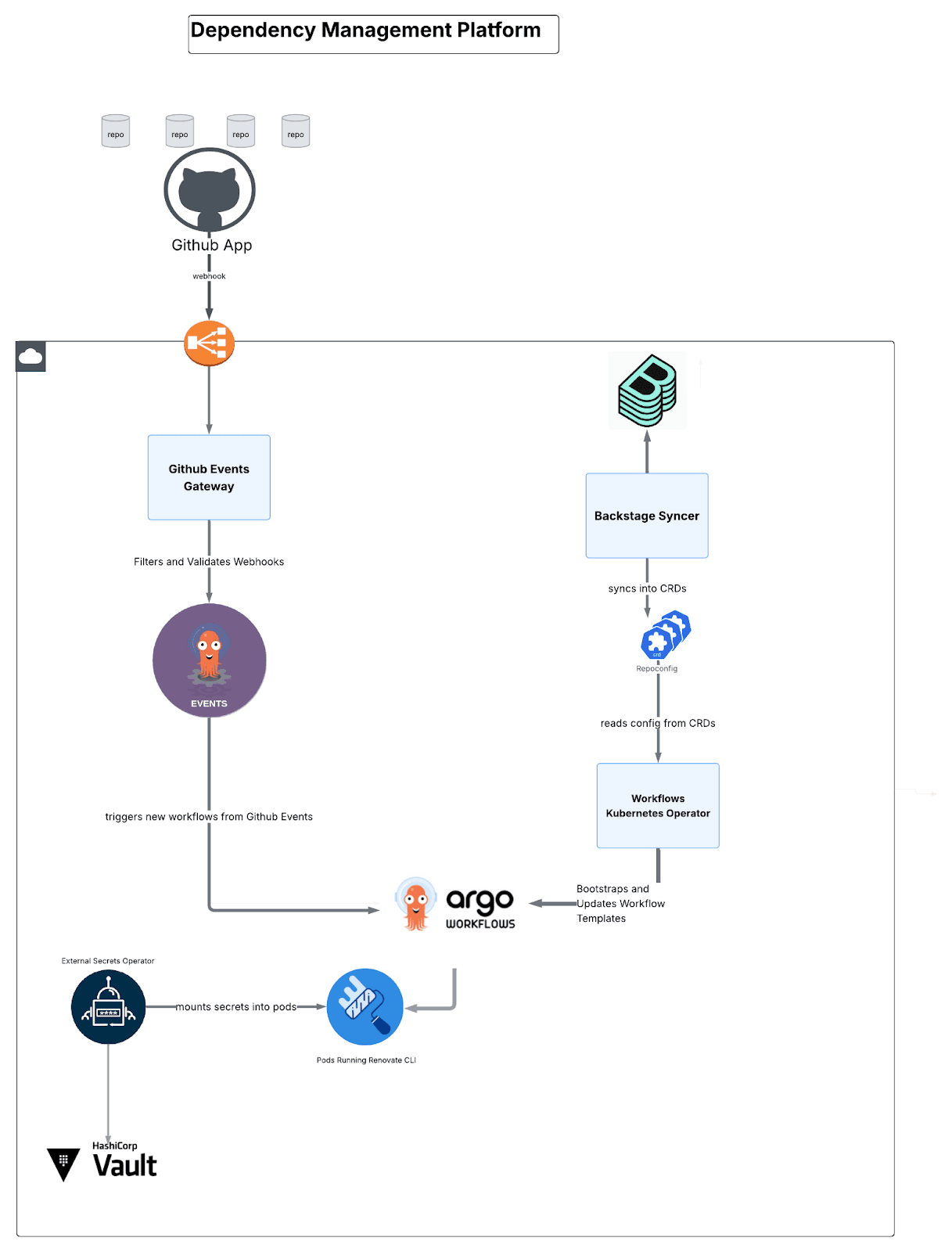
図4:コンポーネントがどのように配線されているかの概要。
ワークフローオペレーター(Go/Kubebuilder)
3つのカスタムリソース定義(CRD)を通じてワークフローライフサイクルを管理するKubernetesオペレーター:
- RepoConfig CRD:リポジトリ設定のための信頼できる唯一の情報源。
RepoConfigはオペレーターで次のように定義されています。
RepoConfigのインスタンスは次のようになります。
- 親CRD:スケジュールされたスキャンのCronWorkflowを管理します。
親コントローラの調整ループ内では、ワークフロー設定が作成され、最新の状態に保たれ、必要に応じて削除されることを確認します。
まず、ワークフローのグローバル設定を取得します。
mutexのconfigmapが最新であることを確認し、類似したワークフローが同時に動作しないようにします:
そして、Cronワークフローとワークフローテンプレートを作成または更新する構造体であるワークフローマネージャーを作成します。
- 子CRD:リポジトリごとのリソースを使用してWorkflowTemplatesを管理します。
子コントローラにーは親と同様の調整義務がありますが、今回は親ワークフローによってトリガーされる子名前空間内のワークフローテンプレートを担当します。
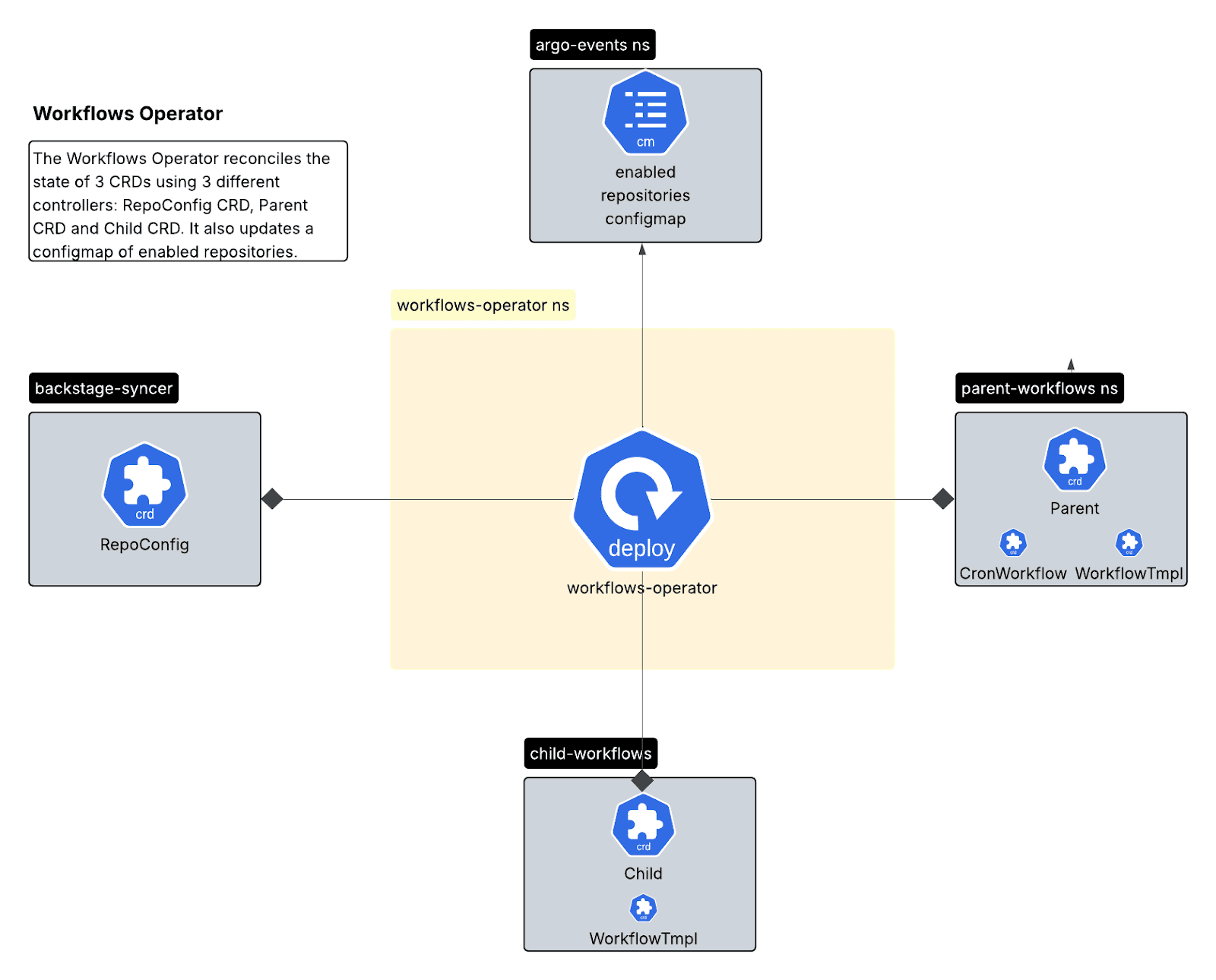
マルチコントローラーパターンでは明確な分離が実現されます。RepoConfigコントローラーはオンボーディング/オフボーディングを処理し、親コントローラーはスケジュールを管理し、子コントローラーは実行テンプレートを処理します。
GitHuイベントゲートウェイ(Go)
GitHubのwebhookを受信し、署名を検証し、組織/リポジトリでフィルタリングし、Argo Eventsにルーティングするセキュアなwebhookプロキシです。依存関係ダッシュボードのインタラクション、PRイベント、パッケージの更新に対応する10個の異なるセンサーを構築しました。
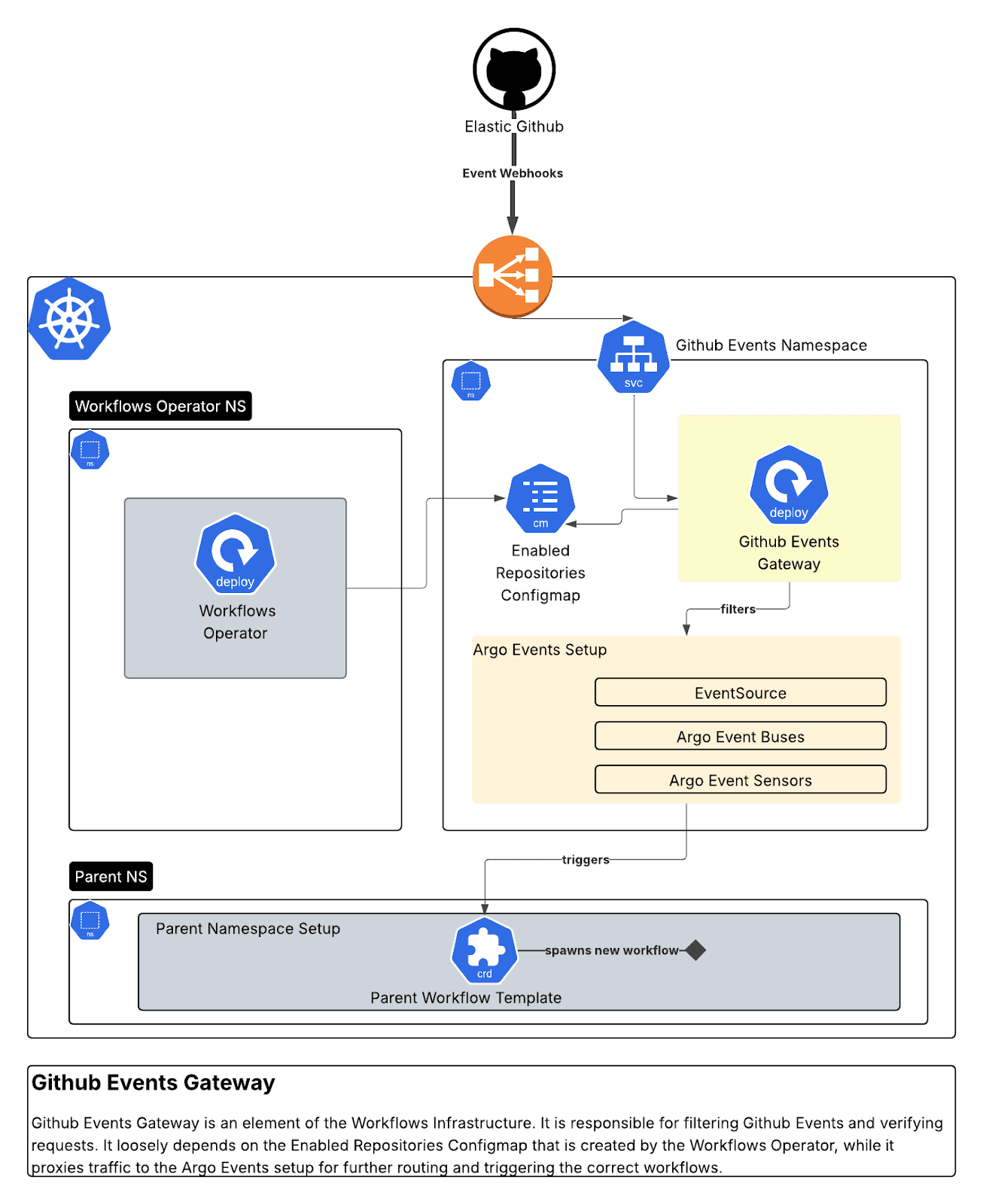
このゲートウェイは、以下の方法でGitHub Appsとの統合を可能にします。
- セキュリティのため、受信したGitHub webhook署名を検証しています。
- 有効なイベントを、すべての関連ヘッダーと認証とともにArgo Events EventSourceに転送します。
- また、EventSourceにAuthSecretを設定し、これを転送されるリクエストのBearerヘッダーとして提供します。
- ログ、メトリクス、再試行ロジックを提供します。
各GitHubイベントリクエストに対して様々な検証を行います。
以下のHTTP属性が存在することを確認します。
また、各リクエストの署名とその構成も検証します。
最後に、イベントの種類に基づいてArgo Eventsにルーティングします。
Argo Events側では、10個のセンサーがArgo Events EventBusで新しいイベントを監視します。
次に、スクリプトは各センサーのロジックを適用します。
Backstage Syncer(Go)
このプロセスでは、Service Catalog(Backstage)に対してRepository Real Resource Entitiesのポーリングを行い、それらをRepoConfig CRDに変換し、プラットフォームを設定変更と同期させます。変更は3分以内に適用されます。
最後に、そのデータをRepoConfigインスタンスに書き込みます。
ワークフローベース(混合:JavaScript、Go、Helm)
基盤レイヤーには、Helmチャート、JavaScript設定、暗号化サポート付きのRenovate CLI用のGoラッパー、Alpineパッケージ用のカスタムAPKインデクサーが含まれています。
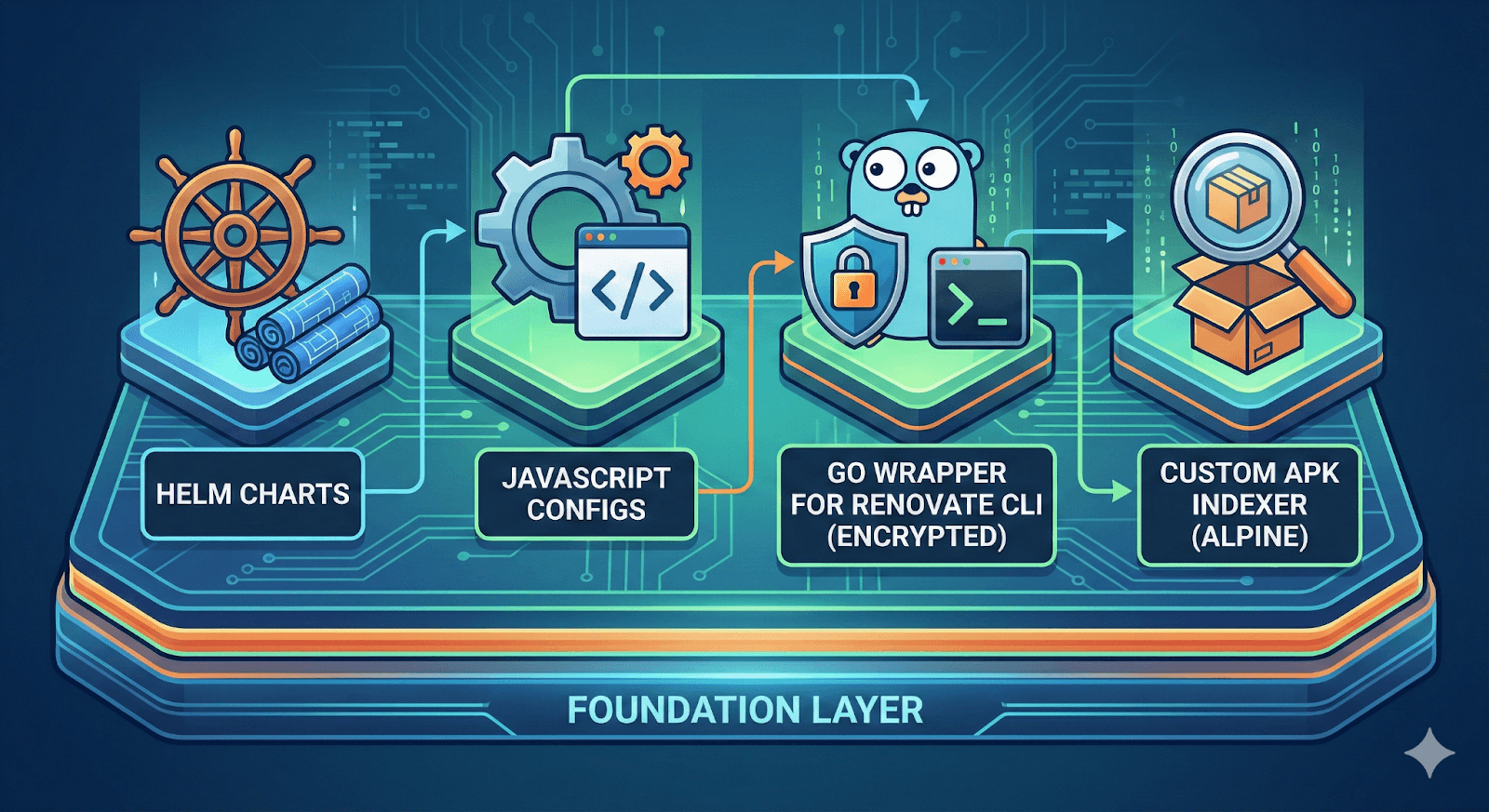
図5:基礎コンポーネントの概要(Nano Bananaで作成)。
セルフサービス構成
チームはBackstageを通じてリポジトリを宣言的に設定します。
リソースグループはリポジトリサイズに基づいてCPUとメモリを割り当てます。
- SMALL: 500m CPU、1Giメモリ。
- MEDIUM: 1000m CPU、2Giメモリ。
- LARGE: 2000m CPU、4Giメモリ。
構成はバージョン管理され、監査可能で、自動的に適用されます。
親子パターン
実行モデルは親子ワークフローパターンを使用しています。
- 親ワークフロー:スケジュールに従って実行される軽量のCronワークフロー。シークレットを暗号化し、スキャンを実行するかどうかを決定し、子プロセスに構成を渡します。
- 子ワークフロー:Renovate CLIが実行される一時的なポッド。リソースを動的に割り当て、シークレットを単独で復号し、完了後に終了します。
この分離により、セキュリティ(親レベルで暗号化されたシークレット)、リソースの最適化(親は最小限のリソースを使用)、拡張性(子が並行して実行)が提供されます。
結果
パフォーマンスの変化
- 変更前:一度に1つのリポジトリで、一部のリポジトリは、おそらく1日以上、1日あたり1,000回未満のスキャンでも処理されませんでした。
- 変更後:100以上の同時スキャン、通常は8,000件のスキャンと1日あたり最大10,000件の記録スキャン。制限は、当社が費やすリソースの量とGitHubのレート制限の扱い方のみです。
費用対効果
奇妙に聞こえるかもしれませんが、1 日に8,000件のポッドを実行すると、同じ結果を達成するために 1 つの長時間実行ポッドを実行するよりもはるかに安価に同じ結果を得ることができます。
以前の設定では、単一のインスタンスを実行していて、調子が良い日には500~600回のスキャンを実行していました。同時に、異なる種類のリポジトリが同じポッドで実行されることから、最大のものに合わせてポッドのサイズを設定する必要がありました。そのサイズは、現在の8つのCPUと16GBのメモリを搭載する特大モデルよりもはるかに大きくなります。
現在の日次出力を満たすには、単一のポッドなら12日間実行する必要があります。それでは、12日間稼働する単一のポッドのコストを、毎日稼働する8,000個の「MEDIUM」サイズのポッドのコストと比較すると、新しい設計は同じスキャン出力に対してはるかに効率的です。
| メトリック | シナリオ A(ワークフロー) | シナリオB(長時間実行される単一のポッド) |
|---|---|---|
| セットアップ | 8,000ポッド(1 vCPU/2GB) | 1 pod (8 vCPU / 16 GB)* |
| 期間 | それぞれ10分 | 12日間連続 |
| 総作業時間 | 1,333計算時間 | 288計算時間 |
| 総コスト | 65.83ドル | $113.75 |
しかし、ワークロードのデフォルト設定が「SMALL」に設定されていることを考慮に入れましょう。大多数は0.5 CPUと1G RAMで正常に実行されており、規模を増やす変更する必要があるのはごく一部です。ワークロードの60%が「SMALL」で実行され、30%が「MEDIUM」で実行され、10%が「LARGE」で実行されている場合(これが実際に近い値です)に何が起こるかを見てみましょう。
| メトリック | シナリオA(混合群) | シナリオB(長時間実行) |
|---|---|---|
| 戦略 | 8,000ポッド(混合サイズ) | 1 pod (8 vCPU / 16 GB)* |
| 期間 | それぞれ10分 | 12日間連続 |
| 総コスト | $52.66 | $113.75 |
| 節約額 | $61.09(54%安価) | — |
同じ出力に対して、現在の設定ではるかに費用対効果に優れていることがわかります。
強化されたセキュリティ
- 一時的なGitHubトークン(数分間の公開と数日間の公開の比較)。
- ロールベースアクセス制御(RBAC)境界による名前空間の分離。
- 親ワークフロー内の保存時のシークレットの暗号化。
- 直接のVaultアクセスを削除。
予測可能なパフォーマンス
スキャン頻度が保証されれば、最終的にサービスレベル目標(SLO)を設定できます。Automergeは確実に動作します。チームは、プラットフォームが約束どおりの成果をもたらすと信頼しています。
重要なアーキテクチャ上の決定
ここでは、プラットフォームの外観を形作る重要な設計上の決定事項をいくつか紹介します。
- 親子ワークフローが必要な理由
多層防御戦略を実施するためにこのパターンを採用しました。価値の高い認証情報(GitHubアプリのシークレットなど)を専用のロックダウンされた名前空間に制限することで、RBACを使用して、一時的な実行ポッドが機密データに恣意的にアクセスできないようにします。最近のサプライチェーンの脆弱性(例えば、"Shai Hulud"継続的インテグレーション/継続的デリバリー[CI/CD]攻撃)は、動的スクリプトを実行するランタイム環境を認証情報ストアから分離することの重要性を実証しています。
同時に、この分離により、きめ細かなリソースの最適化が可能になります。「親」ワークフローは軽量のオーケストレーターとして機能し、最小限のフットプリントで動作します。一方、「子」ワークフローは計算集約型の依存関係スキャンを処理します。この分離により、各レイヤーに個別の調整ロジックを適用し、スケジューリングとセキュリティインフラ(親)の管理制御を維持しながら、実行パラメータ(子)の制御をユーザーに許可することで、ライフサイクル管理を簡素化できます。
- セルフサービス可能な理由
リポジトリ構成のボトルネックとなる当社のチームを排除することは重要な要件でした。私たちの使命は、多様なユースケースをサポートできるスケーラブルなセルフサービスプラットフォームを設計することでした。リポジトリの膨大な量を考慮すると、すべての構成変更のゲートキーパーとして機能することは持続不可能であると認識しました。代わりに、私たちは「レール」(インフラストラクチャとガードレール)を提供しながら、ユーザーが「列車」(実行とカスタマイズ)を運転できるようにするという支援の哲学を採用しました。こうしたチームの自律性へのシフトが、ユーザーがシステムをそれぞれの具体的な業務ニーズに合わせてカスタマイズできるようにすることで、生産性を大幅に向上させると信じています。
- Kubernetes Operatorパターンを選択した理由
上記で述べたように、基本的な設計原則は、プラットフォームが完全にセルフサービス可能であることを確保することでした。ユーザーの意図(スキャンの切り替え、スケジューリング頻度の調整、ランタイムリソース制限の調整など)を捉え、それらの変更を基盤となるワークフローに瞬時に反映する自動化されたメカニズムが必要でした。将来の要件を予測し、システムは簡単に拡張可能である必要もありました。
これを実現するために、カスタムの依存関係管理Kubernetes Operatorを開発しました。設定のインターフェースとしてCRDを使用することで、Kubernetesネイティブな調整ループを確立しました。このオペレーターは、ユーザーが定義した望ましい状態を継続的に監視し、ワークフローインフラに必要な更新を自動的に管理します。これにより、イベント駆動型のシームレスな操作が保証され、プラットフォームのロジックが裏側ですべての複雑さを処理します。
- GitHubイベントゲートウェイを設計する理由
プラットフォームの応答性を高めるために、イベントドリブンアーキテクチャー(EDA)の採用が不可欠でした。CronWorkflowsは信頼性の高いベースラインスケジュールを提供しましたが、ユーザーがダッシュボードから手動でスキャンをトリガーするなどアドホック実行を処理できる俊敏性が必要でした。これを達成するために、ペイロードの整合性を検証し、リクエストをインテリジェントにルーティングするための専用のインジェストゲートウェイが必要でした。
既存のソリューション、特にArgoのネイティブGitHub EventSourceを評価しましたが、 運用上のオーバーヘッドや厳格な GitHub APIクォータ(例:リポジトリごとのwebhook制限)に関する重大なリスクを特定しました。結果として、これらの制限からインフラを切り離すためにカスタムゲートウェイを構築しました。
重要なのは、このゲートウェイが移行中に戦略的なトラフィック制御ポイントとして機能したことです。これはスイッチとして機能し、レガシーシステムから新しいインフラストラクチャへの段階的かつ詳細なロールアウト(トラフィックの移行)を実行できるようになりました。これにより、数千のリポジトリのオンボーディングが「ビッグバン」的な切り替えではなく、制御されたリスクのないプロセスになることが保証されました。
教訓
私たちが学んだいくつかの教訓は Elasticソースコードと密接に関連しています。
- 顧客第一:プラットフォームはユーザーのために構築されます。したがって、ユーザーのニーズを最優先にすることが重要です。これにより、プラットフォームは、ユーザーとの摩擦を減らし、プラットフォームの拡張を簡素化し、導入を容易にする、効率的に設計されたインフラストラクチャとアプリケーションに形作られます。
- 空間と時間:時には、最も抵抗の少ない道が不安定な状況につながることがあります。当初、既存の順次処理モデルを最適化しようとしましたが、問題は解決されず、むしろ複雑さが増し、未解決の問題が増えただけでした。プラットフォームを並列処理で再構築するという大胆な決定には、多大な事前開発が必要でしたが、最終的には持続可能なプラットフォームの成長への道を切り開き、日々の面倒な管理業務を事実上排除しました。
- ITと依存関係:プラットフォームは単独では動作できません。その成功は、より広範なエコシステムとどれだけうまく統合できるかによって決まります。当社の場合、シームレスなサービスオンボーディングのための信頼できる情報源となるため、Backstageとの統合は極めて重要でした。同様に、Artifactoryに接続することで、プライベートパッケージの更新を効率的に管理できるようになります。他にも重要な統合は多々あります。
- 進歩、シンプルな完璧さ:実装全体を通じて、当初の想定を継続的にプレッシャーテストし、新たな障壁が出現するたびにそれに適応しました。完璧主義に陥るのではなく、反復的なアプローチを採用し、課題に一つずつ取り組み、実際の状況に合わせて移行戦略を調整しました。
次のステップ
このプラットフォームの提供により、プラットフォームのUXと効率性の向上に役立つ、より有意義な作業が可能になります。いくつかの例を以下に示します。
- 自動マージの採用を増やし、ガードレールを設定
自動マージ機能により、面倒な手動タスクが排除され、チームの速度が大幅に向上します。しかし、この速度の向上が安全性を犠牲にすることのないよう、厳格なガードレールを確実に設置する必要があります。
- エンドユーザーエクスペリエンスに関するオブザーバビリティの向上
私たちのロードマップにおける重要な優先事項は、プラットフォームレベルだけでなく、特にエンドユーザーの視点からオブザーバビリティを高めることです。インフラの指標を捉えるのは簡単ですが、実際のユーザー体験を理解するにはより深い洞察が必要です。コアユーザー中心の重要業績評価指標(KPI)を定義し、テレメトリがエスカレートする前の摩擦点やパフォーマンスの問題を検出できるように取り組んでいます。
- より広範な採用を促進するための障壁の除去
将来を見据えた当社の優先事項は、プラットフォームの採用を妨げている障壁を特定して取り除くことです。新しい統合の開発や特定の機能セットの展開が必要な場合でも、当社はデータ主導の計画に取り組んでいます。当社は拡張性を重視したプラットフォームの構築に成功しました。今後は、その潜在能力を最大限に引き出すことに注力していきます。
全体像
依存関係管理ワークフロープロジェクトは、より広範な原則を示しています。つまり、デフォルトの導入モデルを超えてオープンソースツールをスケールする必要がある場合、Kubernetesネイティブパターンが前進する道を提供するということです。
以下を取り入れることで、
- 構成用のCRD
- ライフサイクル管理のためのオペレーター
- 応答性を高めるイベント駆動型アーキテクチャ
- 導入用のGitOps
管理するリポジトリの数に関係なく拡張できるオーケストレーションを構築しました。1つのリポジトリをスキャンするパフォーマンスは、管理するリポジトリが100個でも1,000個でも同じです。
重要なCVEが発表されても、数時間ではなく数分で回答が得られます。それがボトルネックと競争優位の違いです。
謝辞
このプラットフォームは優れたオープンソースツールを基盤としています。
- Kubebuilder:ワークフローをブートストラップして管理するKubernetes Operatorを起動するために使用したオープンソースフレームワーク。[1][2]
- Backstage:Service Catalogを構築し、信頼できる情報源として使用するオープンソースフレームワーク。[1][2]
- Argo WorkflowsとArgo Events:複雑なプロセスを調整し、イベントに基づいて動的な処理を追加するために使用したオープンソーススイート。[1][2][3][4]
- Renovate CLI:リポジトリを処理するオープンソースの依存関係管理ツール。[1][2]
* AWS Fargateの料金モデルを単一ポッドのコストの基準として使用しました。ただし、当社のワークロードは必ずしもAWSで実行されているわけではなく、本格的なKubernetesクラスターで実行されています。
関連記事

2026年4月20日
Elastic Cloud ServerlessとElasticsearchの統合APIキーが登場
Elasticがグローバルに分散されたIAMアーキテクチャでServerlessのコントロールプレーンとデータプレーンの認証を統合した方法をご紹介します。Cloud APIとElasticsearch APIに1つのAPIキーを使用できます。
2026年4月3日
Elastic Workflowsを使用したKibanaのダッシュボード表示の監視
Elastic Workflowsを使用して、Kibanaのダッシュボードのビューメトリクスを30分ごとに収集し、それらをElasticsearchにインデックスする方法を学びましょう。これにより、独自のデータ上にカスタム分析と可視化を構築できます。

Kibana に Elasticsearch クエリルール UI を導入
Elasticsearch クエリ ルール UI を使用して、オーガニック ランキングに影響を与えずに Kibana のカスタマイズ可能なルールセットを使用して検索クエリにドキュメントを追加または除外する方法を学びます。

MastraとElasticsearchを使用してセマンティックリコールを備えた知識エージェントを構築する
メモリと情報検索用のベクトル ストアとして Mastra と Elasticsearch を使用して、セマンティック リコールを備えたナレッジ エージェントを構築する方法を学びます。

2026年5月22日
Kibanaはダッシュボードの読み込み時間を最大25%短縮 - その背後にあるポーリング戦略を紹介
Kibanaが継続的なポーリングとブラウザ側のHTTP/2検出を使用して、ダッシュボードの読み込み時間を最大25%削減し、HTTP/1に自動的にフォールバックする仕組みをご覧ください。