コンテキスト エンジニアリングは、信頼性の高い AI エージェントとアーキテクチャの構築においてますます重要になっています。モデルがどんどん良くなるにつれて、その有効性と信頼性はトレーニングされたデータに依存するのではなく、適切なコンテキストにどれだけ適切に基づいているかに依存するようになります。最も関連性の高い情報を適切なタイミングで取得して適用できるエージェントは、正確で信頼できる出力を生成する可能性がはるかに高くなります。
このブログでは、 Mastraを使用して、Elasticsearch をメモリおよび検索バックエンドとして使用し、ユーザーの発言を記憶し、後で関連情報を思い出すことができるナレッジ エージェントを構築します。これと同じ概念を実際のユースケースに簡単に拡張できます。サポート エージェントが過去の会話や解決策を記憶し、特定のユーザーへの応答をカスタマイズしたり、以前のコンテキストに基づいてより迅速に解決策を提示したりできると考えてください。
ここから手順に従って、ステップごとに構築する方法を確認してください。迷ってしまったり、完成した例を実行したいだけの場合は、ここにあるリポジトリを確認してください。
マストラとは何ですか?
Mastra は、推論、メモリ、ツールの交換可能なパーツを備えた AI エージェントを構築するためのオープンソースの TypeScript フレームワークです。セマンティック リコール機能により、エージェントはメッセージをベクター データベースに埋め込みとして保存することで、過去のやり取りを記憶して取り出すことができます。これにより、エージェントは長期的な会話のコンテキストと継続性を維持できます。Elasticsearch は効率的な高密度ベクトル検索をサポートしているため、この機能を有効にするのに最適なベクトル ストアです。セマンティックリコールがトリガーされると、エージェントは関連する過去のメッセージをモデルのコンテキストウィンドウに引き出し、モデルが取得したコンテキストを推論と応答の基礎として使用できるようにします。
始めるために必要なもの
- ノード v18+
- Elasticsearch(バージョン8.15以降)
- Elasticsearch APIキー
- OpenAI APIキー
注: デモでは OpenAI プロバイダーを使用するため、これが必要になりますが、Mastra は他の AI SDK とコミュニティ モデル プロバイダーをサポートしているため、設定に応じて簡単に交換できます。
Mastraプロジェクトの構築
プロジェクトの足場を提供するために、Mastra の組み込み CLI を使用します。次のコマンドを実行します。
次のような一連のプロンプトが表示されます。
1. プロジェクトに名前を付けます。

2. このデフォルト設定を維持することもできますし、空白のままにしておくこともできます。

3. このプロジェクトでは、OpenAI が提供するモデルを使用します。

4. すべての環境変数を、後のステップで設定する `.env` ファイルに保存するため、「今はスキップ」オプションを選択します。

5. このオプションをスキップすることもできます。

MastraのMCPサーバーのインストールをスキップする
初期化が完了したら、次のステップに進むことができます。
依存関係のインストール
次に、いくつかの依存関係をインストールする必要があります。
ai- JavaScript/TypeScript で AI モデル、プロンプト、ワークフローを管理するためのツールを提供するコア AI SDK パッケージ。Mastra は Vercel のAI SDK上に構築されているため、エージェントとのモデルのインタラクションを有効にするにはこの依存関係が必要です。@ai-sdk/openai- AI SDK を OpenAI モデル (GPT-4、GPT-4o など) に接続し、OpenAI API キーを使用した API 呼び出しを可能にするプラグイン。@elastic/elasticsearch- Node.js 用の公式 Elasticsearch クライアント、インデックス作成、検索、ベクター操作のために Elastic Cloud またはローカル クラスターに接続するために使用されます。dotenv- .envから環境変数を読み込みますファイルをprocess.envにコピーし、API キーや Elasticsearch エンドポイントなどの資格情報を安全に挿入できるようになります。
環境変数の設定
プロジェクトのルート ディレクトリに.envファイルが存在しない場合は作成します。あるいは、リポジトリに提供されている例.envをコピーして名前を変更することもできます。このファイルでは、次の変数を追加できます。
これで基本的な設定は完了です。ここから、エージェントの構築とオーケストレーションを開始できます。さらに一歩進んで、Elasticsearch をストアおよびベクター検索レイヤーとして追加します。
ベクターストアとしてElasticsearchを追加する
storesという新しいフォルダーを作成し、その中にこのファイルを追加します。Mastra と Elastic が公式の Elasticsearch ベクター ストア統合を出荷する前に、 Abhi Aiyer (Mastra CTO) がElasticVectorと呼ばれるこの初期のプロトタイプ クラスを共有しました。簡単に言えば、Mastra のメモリ抽象化を Elasticsearch の高密度ベクトル機能に接続することで、開発者はエージェントのベクトル データベースとして Elasticsearch を導入できるようになります。
統合の重要な部分を詳しく見てみましょう。
Elasticsearchクライアントの取り込み
このセクションでは、 ElasticVectorクラスを定義し、標準デプロイメントとサーバーレスデプロイメントの両方をサポートする Elasticsearch クライアント接続を設定します。
ElasticVectorConfig extends ClientOptions: これにより、すべての Elasticsearch クライアント オプション (node、auth、requestTimeoutなど) を継承し、カスタム プロパティを追加する新しい構成インターフェースが作成されます。つまり、ユーザーは、サーバーレス固有のオプションとともに、有効な Elasticsearch 構成を渡すことができるということです。extends MastraVector: これにより、ElasticVector、すべてのベクター ストア統合が準拠する共通インターフェースである Mastra の基本MastraVectorクラスから継承できるようになります。これにより、エージェントの観点から見ると、Elasticsearch は他の Mastra ベクター バックエンドと同じように動作するようになります。private client: Client: これは、Elasticsearch JavaScript クライアントのインスタンスを保持するプライベート プロパティです。これにより、クラスはクラスターと直接通信できるようになります。isServerlessおよびdeploymentChecked: これらのプロパティは連携して、サーバーレスまたは標準の Elasticsearch デプロイメントに接続されているかどうかを検出し、キャッシュします。この検出は最初の使用時に自動的に行われますが、明示的に構成することもできます。constructor(config: ClientOptions): このコンストラクターは、構成オブジェクト (Elasticsearch の資格情報とオプションのサーバーレス設定を含む) を受け取り、それを使用してthis.client = new Client(config)行でクライアントを初期化します。super(): これは Mastra の基本コンストラクターを呼び出すため、ログ記録、検証ヘルパー、およびその他の内部フックを継承します。
この時点で、Mastraは新しいベクターストアがあることを知っています。 ElasticVector
展開タイプの検出
インデックスを作成する前に、アダプターは標準の Elasticsearch を使用しているか Elasticsearch Serverless を使用しているかを自動的に検出します。サーバーレス デプロイメントでは手動でのシャード構成が許可されないため、これは重要です。
何が起こっていますか:
- まず、構成で明示的に
isServerlessが設定されているかどうかを確認します (自動検出をスキップします) - Elasticsearch の
info()API を呼び出してクラスター情報を取得します build_flavor fieldをチェックします (サーバーレス デプロイメントはserverlessを返します)- ビルドフレーバーが利用できない場合はタグラインをチェックする
- 結果をキャッシュして、API 呼び出しの繰り返しを回避します。
- 検出に失敗した場合は標準展開をデフォルトとする
使用例:
Elasticsearchに「メモリ」ストアを作成する
以下の関数は、埋め込みを保存するための Elasticsearch インデックスを設定します。インデックスがすでに存在するかどうかを確認します。そうでない場合は、埋め込みとカスタム類似度メトリックを格納するためのdense_vectorフィールドを含む以下のマッピングを使用して作成します。
注意すべき点:
dimensionパラメータは各埋め込みベクトルの長さであり、使用している埋め込みモデルによって異なります。私たちの場合、サイズ1536のベクトルを出力する OpenAI のtext-embedding-3-smallモデルを使用して埋め込みを生成します。これをデフォルト値として使用します。- 以下のマッピングで使用される
similarity変数は、ヘルパー関数 const similarity = this.mapMetricToSimilarity(metric)から定義されます。この関数は、metricパラメータの値を受け取り、選択された距離メトリックの Elasticsearch 互換キーワードに変換します。- たとえば、Mastra では、ベクトルの類似性を表すために
cosine、euclidean、dotproductなどの一般的な用語を使用します。メトリックeuclideanElasticsearch マッピングに直接渡すと、Elasticsearch はキーワードl2_normがユークリッド距離を表すと想定するため、エラーが発生します。
- たとえば、Mastra では、ベクトルの類似性を表すために
- サーバーレス互換性: サーバーレスデプロイメントのシャードとレプリカの設定は Elasticsearch Serverless によって自動的に管理されるため、コードでは自動的に省略されます。
やりとりの後に新しい記憶やメモを保存する
この関数は、各インタラクションの後に生成された新しい埋め込みをメタデータとともに取得し、Elastic のbulk API を使用してそれらをインデックスに挿入または更新します。bulk API は複数の書き込み操作を 1 つのリクエストにグループ化します。このインデックス作成パフォーマンスの向上により、エージェントのメモリが増加し続けても更新の効率が維持されます。
意味的想起のための類似ベクトルのクエリ
この機能は、セマンティック リコール機能の中核です。エージェントはベクトル検索を使用して、インデックス内に保存されている類似の埋め込みを見つけます。
内部構造:
- Elasticsearch の
knnAPI を使用してkNN (k 近傍法) クエリを実行します。 - 入力クエリ ベクトルに類似する上位 K 個のベクトルを取得します。
- オプションでメタデータ フィルターを適用して結果を絞り込む (例: 特定のカテゴリまたは時間範囲内のみを検索する)
- ドキュメント ID、類似度スコア、保存されたメタデータを含む構造化された結果を返します。
知識エージェントの作成
ElasticVector統合を通じて Mastra と Elasticsearch の接続を確認したので、次は Knowledge Agent 自体を作成しましょう。
フォルダーagents内に、 knowledge-agent.tsというファイルを作成します。まず、環境変数を接続し、Elasticsearch クライアントを初期化します。
ここでは、次の操作を行います。
dotenvを使用して、.envファイルから変数を読み込みます。- Elasticsearch の資格情報が正しく挿入されているかどうかを確認し、クライアントへの接続を正常に確立できるかどうかを確認します。
- Elasticsearch エンドポイントと API キーを
ElasticVectorコンストラクターに渡して、先ほど定義したベクター ストアのインスタンスを作成します。 - Elasticsearch Serverless を使用している場合は、オプションで
isServerless: trueを指定します。これにより、自動検出手順がスキップされ、起動時間が短縮されます。省略した場合、アダプタは最初の使用時にデプロイメント タイプを自動的に検出します。
次に、Mastra のAgentクラスを使用してエージェントを定義します。
定義できるフィールドは次のとおりです。
nameそしてinstructions: アイデンティティと主な機能を与えます。model:@ai-sdk/openaiパッケージを通じて OpenAI のgpt-4oを使用しています。memory:vector: Elasticsearch ストアを指すので、埋め込みはそこから保存され、取得されます。embedder: 埋め込みを生成するためにどのモデルを使用するかsemanticRecallオプションによってリコールの動作が決まります。topK: 意味的に類似したメッセージを取得する数。messageRange: 各マッチにどの程度の会話を含めるか。scope: メモリの境界を定義します。
もうすぐ終わりです。新しく作成したエージェントを Mastra 構成に追加するだけです。index.tsというファイルで、ナレッジ エージェントをインポートし、 agentsフィールドに挿入します。
その他のフィールドには以下が含まれます。
storage: これは、実行履歴、観測性メトリック、スコア、キャッシュのための Mastra の内部データ ストアです。Mastra ストレージの詳細については、こちらをご覧ください。logger: Mastra は、軽量の構造化 JSON ロガーであるPinoを使用します。エージェントの開始と停止、ツールの呼び出しと結果、エラー、LLM 応答時間などのイベントをキャプチャします。observability: エージェントの AI トレースおよび実行の可視性を制御します。追跡対象:- 各推論ステップの開始/終了。
- 使用されたモデルまたはツール。
- 入力と出力。
- スコアと評価
Mastra Studioでエージェントをテストする
おめでとうございます!ここまで到達したら、このエージェントを実行し、そのセマンティックリコール能力をテストする準備が整いました。幸いなことに、Mastra には組み込みのチャット UI が用意されているため、独自に構築する必要はありません。
Mastra 開発サーバーを起動するには、ターミナルを開いて次のコマンドを実行します。
サーバーの初期バンドルと起動が完了すると、Playground のアドレスが提供されるはずです。

このアドレスをブラウザに貼り付けると、Mastra Studio が表示されます。
knowledgeAgentのオプションを選択してチャットを開始してください。
すべてが正しく接続されているかどうかを確認するための簡単なテストでは、次のような情報を入力します。「チームは、主にエンタープライズ契約の更新により、10 月の売上実績が 12% 増加したと発表しました。次のステップは、中規模市場の顧客へのリーチを拡大することです。」次に、新しいチャットを開始して、「次に重点を置く必要があると言った顧客セグメントはどれですか?」などの質問をします。ナレッジエージェントは、最初のチャットで提供した情報を思い出せるはずです。次のような応答が表示されます。

このような応答が表示された場合、エージェントが以前のメッセージを Elasticsearch に埋め込みとして正常に保存し、後でベクトル検索を使用して取得したことを意味します。
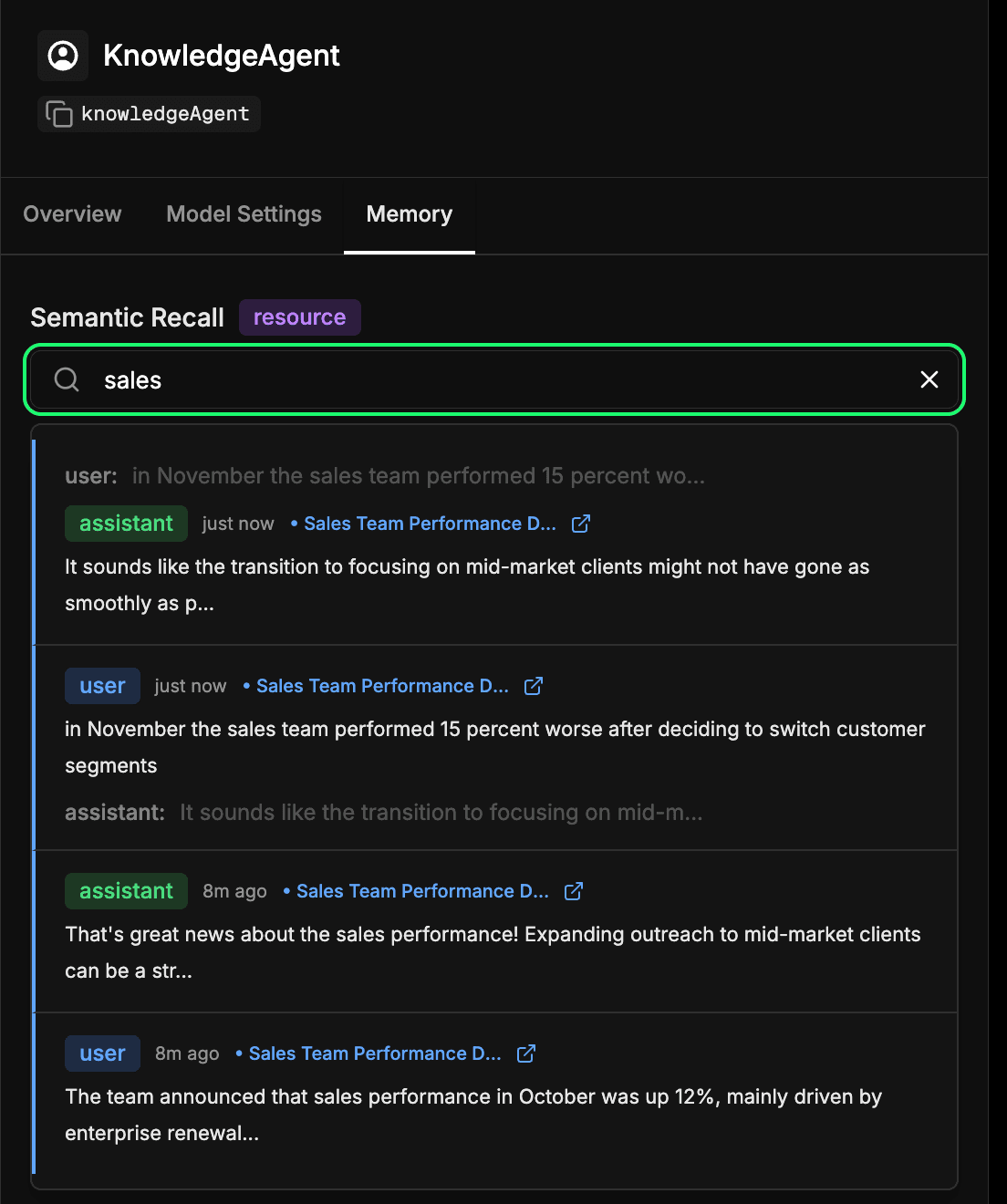
エージェントの長期記憶ストアの検査
Mastra Studio のエージェント構成のmemoryタブに移動します。これにより、エージェントが時間の経過とともに何を学習したかを確認できます。Elasticsearch に埋め込まれて保存されるすべてのメッセージ、応答、およびやり取りは、この長期メモリの一部になります。過去のやり取りを意味的に検索して、エージェントが以前に学習した思い出の情報やコンテキストをすぐに見つけることができます。これは本質的には、エージェントがセマンティックリコール中に使用するメカニズムと同じものですが、ここではそれを直接検査できます。以下の例では、「sales」という用語を検索し、sales に関連する内容を含むすべてのインタラクションを取得しています。
まとめ
Mastra と Elasticsearch を接続することで、コンテキスト エンジニアリングの重要なレイヤーであるメモリをエージェントに付与できます。セマンティックリコールを使用すると、エージェントは時間の経過とともにコンテキストを構築し、学習した内容に基づいて応答することができます。つまり、より正確で信頼性が高く、自然なやりとりが可能になります。
この早期の統合は単なる出発点にすぎません。ここで同じパターンを使用すると、過去のチケットを記憶しているサポートエージェント、関連ドキュメントを取得する内部ボット、会話の途中で顧客の詳細を思い出すことができる AI アシスタントなどが可能になります。当社は公式の Mastra 統合にも取り組んでおり、近い将来この組み合わせがさらにシームレスになる予定です。
次に何を構築するのか楽しみにしています。ぜひ試してみて、 Mastraとそのメモリ機能を調べ、発見したことをコミュニティと自由に共有してください。
関連記事

2026年5月11日
Elasticsearchに火を灯す:Prometheus APIのネイティブサポートを追加
Prometheus互換のクライアントから、ネイティブのPromQL、ディスカバリー、メタデータエンドポイント経由でElasticsearchに直接クエリを実行できます。Prometheus Remote WriteでElasticsearchにデータを送信します。

2026年4月20日
Elastic Cloud ServerlessとElasticsearchの統合APIキーが登場
Elasticがグローバルに分散されたIAMアーキテクチャでServerlessのコントロールプレーンとデータプレーンの認証を統合した方法をご紹介します。Cloud APIとElasticsearch APIに1つのAPIキーを使用できます。

2026年4月8日
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法を実例を通じて学びましょう。
2026年4月3日
Elastic Workflowsを使用したKibanaのダッシュボード表示の監視
Elastic Workflowsを使用して、Kibanaのダッシュボードのビューメトリクスを30分ごとに収集し、それらをElasticsearchにインデックスする方法を学びましょう。これにより、独自のデータ上にカスタム分析と可視化を構築できます。

2026年3月25日
シェルツールはコンテキストエンジニアリングの万能薬ではありません
コンテキストエンジニアリングに利用できるコンテキスト検索ツールにはどのようなものがあるのか、それらがどのように機能するのか、そしてそれぞれのトレードオフについて学びましょう。