So haben wir mit Kubernetes, Argo Workflows, Argo Events und Renovate CLI eine selbstgehostete Plattform für das Abhängigkeitsmanagement aufgebaut, um Updates zu automatisieren, häufige Schwachstellen und Expositionen (CVEs) schnell zu beheben und neue Paketversionen effizient über Tausende von Repositorys zu verbreiten.
Abhängigkeitsmanagement bei Elastic
Bei Elastic müssen wir Hunderte oder sogar Tausende von Repositorys, sowohl privat als auch öffentlich, verwalten. Wird eine kritische CVE entdeckt, benötigen wir umgehend Antworten und Maßnahmen: Welche Repositorys sind anfällig? Wie schnell können wir sie patchen? Neben der Sicherheit stellen sich auch Produktivitätsfragen: Wie können wir die Veröffentlichung einer neuen Paketversion schnell über alle darauf angewiesenen Repositorys verbreiten, ohne zu viel Zeit mit manuellen Aufgaben zu verbringen?
Der ursprüngliche Auslöser für die Suche nach Möglichkeiten für das Abhängigkeitsmanagement war die Notwendigkeit, eine sichere Grundlage mit automatisierten Updates zur Reduzierung von CVEs zu schaffen. Nachdem wir verschiedene Lösungen zum Abhängigkeitsmanagement sorgfältig geprüft hatten, begannen wir zunächst mit der Arbeit an einer selbstgehosteten Infrastruktur. Wir nutzten unseren eigenen Kubernetes-Cluster genutzt, um Mend Renovate Community Self-Hosted auszuführen. Die Idee war, eine Abhängigkeitsmanagement-Plattform bereitzustellen, auf die unsere Nutzer im Self-Service-Modus zugreifen könnten.
Das erste Experiment war erfolgreich, sodass immer mehr Teams begannen, unsere Plattform zu integrieren und sie im täglichen Lebenszyklus ihrer Repositorys für Updates und CVE-Patches zu nutzen. Das geschah so schnell, dass wir bald die Grenze unserer selbstgehosteten Installation erreichten.

Abb. 1: Ein Überblick über das Abhängigkeitsmanagement bei Elastic.
Die Herausforderung: Wie können wir eine Plattform zur Verwaltung von Abhängigkeiten in einem großen Unternehmen mit einer großen Anzahl von Repositorys skalieren?
Unsere Plattform für das Abhängigkeitsmanagement verarbeitete ein Repository nach dem anderen, und das sequentielle Verarbeitungsmodell konnte aufgrund der großen Anzahl von Repositorys, die wir besitzen, nicht Schritt halten. Wir hatten bereits festgestellt, dass das Problem daran lag, dass eine einzige Instanz unseres Abhängigkeitsverwaltungstools unsere lange und ständig wachsende Liste von Repositorys verarbeiten sollte. Die Repositorys warteten in einer Warteschlange, manchmal stundenlang. Mehr als 50 % unserer Repositorys wurden noch nicht einmal täglich verarbeitet. Das bedeutet, dass bei über 50 % unserer Repositorys zwischen den Scans mehr als 24 Stunden vergingen.
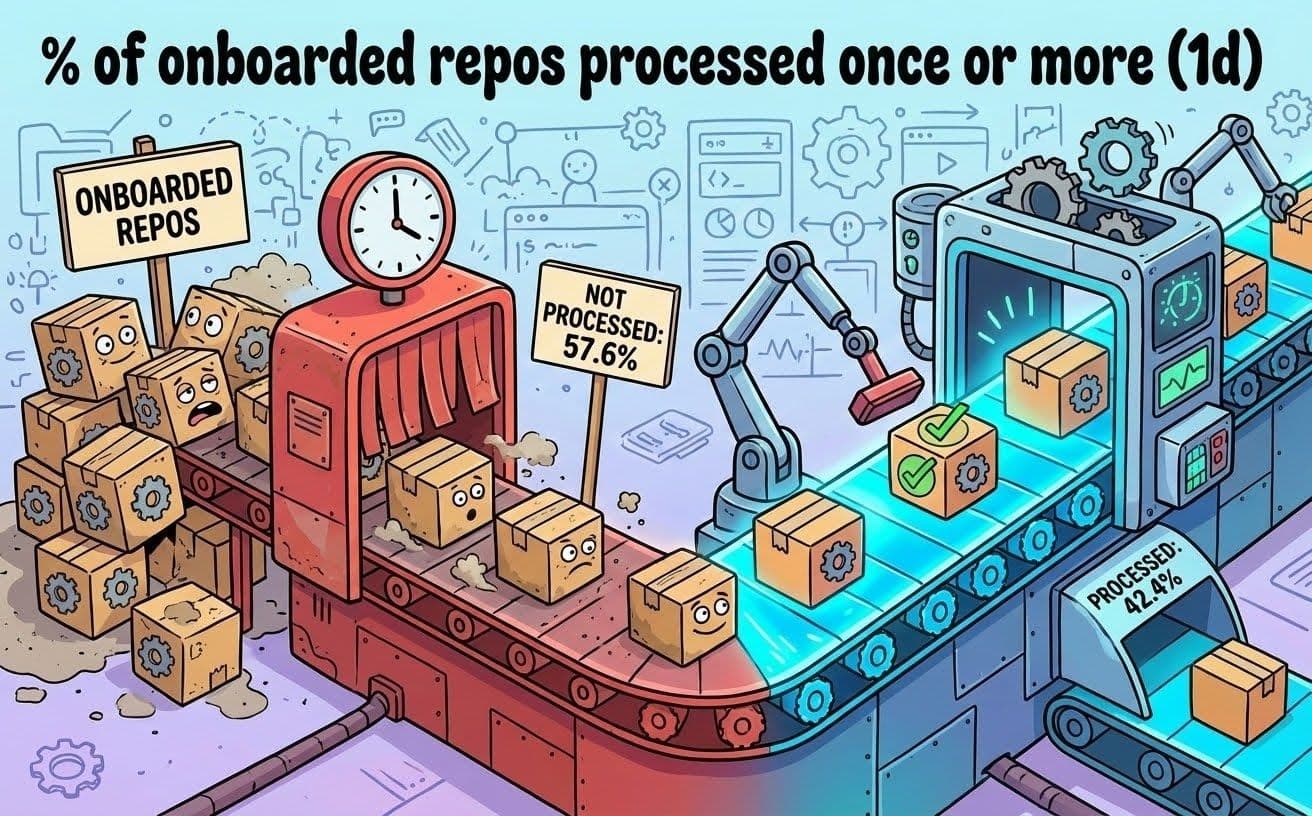
Abb. 2: Anzahl der mindestens einmal täglich verarbeiteten Repositorien (erstellt mit Nano Banana).
Große Repositorys erzeugten aufgrund ihrer umfangreichen Codebasen und ihrer zahlreichen offenen PRs größere Engpässe. GitHub-Webhook-Ereignisse unterbrachen den Ablauf. Die automatische Zusammenführung wurde unzuverlässig, da die Scan-Zeitpunkte unvorhersehbar waren. Wir hatten unseren Nutzern ein Versprechen für die Häufigkeit der Scans gegeben, konnten es aber nicht einhalten.
Die Entscheidung für die Eigenentwicklung: Erfüllung des individuellen Bedarfs für Skalierung und Sicherheit bei Elastic
Während wir auch kommerzielle Optionen in Betracht zogen, darunter die Renovate Self-Hosted Enterprise Edition von Mend, hatten wir intern bei Elastic einige wichtige Initiativen in der Entwicklung.
Unsere Entscheidung, eine interne Plattform zu entwickeln, beruhte auf der Erkenntnis, dass nur eine gut angepasste Lösung die spezifischen, nicht verhandelbaren Anforderungen von Elastic erfüllen kann:
- Investitionen in unsere interne Entwicklerplattform: Zu dieser Zeit hatten wir bereits damit begonnen, stark in unsere hausinterne Entwicklerplattform zu investieren. Wir diskutierten und entwarfen Möglichkeiten dazu, wie jeder einzelne unserer Dienste darin Platz finden könnte. Wir wollten eigene Regeln und Praktiken für unsere Abhängigkeitsverwaltungsplattform testen. Außerdem waren neue Richtlinien zu erwarten, und wir wollten die Plattform im Vorfeld der Ereignisse entwickeln.
- Native Integration und Workflow-Anpassung: Wir benötigten eine unkomplizierte Integration mit unseren internen Tools und internen Prozessen. Zum Beispiel wollten wir die Konfiguration als Code mit unserem Servicekatalog (Backstage) zentralisieren. Wir haben spezifische Anforderungen an die Nutzung von Backstage, mit denen wir unsere Plattform kompatibel machen wollten. Obwohl es möglich wäre, die Renovate Self-Hosted-APIs zusammen mit unserer Backstage-Automatisierung zu nutzen, würde dies unsere internen Prozesse nicht vollständig abdecken.
- Elastic-spezifische Defense-in-Depth-Sicherheit: Unsere strengen Anforderungen an die Sicherheitskonformität erforderten besondere Sicherheitsmechanismen, die auf unser Ökosystem abgestimmt sind. Wir versuchten, unsere Nutzung von „nicht-menschlichen Identitäten“ besser zu sichern. Die Art und Weise, wie diese Zugriffssicherung funktionierte, bedeutete, dass die nicht standardmäßigen Authentifizierungsmethoden für GitHub mit einem Standardtool, das diese interne Implementierung nicht unterstützte, nicht funktionierten. Unser Workflow umfasste die Implementierung eines geheimen Verschlüsselungsmusters für über- und untergeordnete Workflows sowie die Verwendung temporärer, einmalig verwendbarer GitHub-Token. Die Eigenentwicklung war die einzig praktikable Möglichkeit, diese individuellen Sicherheitsebenen zu integrieren und die Angriffsfläche in unserer komplexen Multi-Cloud-Umgebung zu minimieren.
Die Lösung: Eine Workflow-Orchestrierung für das Abhängigkeitsmanagement
Unsere Lösung basiert auf der Tatsache, dass wir auf dem bereits von uns verwendeten Abhängigkeitsverwaltungstool aufbauen wollten, statt es zu ersetzen und nach anderen Lösungen zu suchen. Es hatte sein Potenzial bereits gezeigt, und seine Flexibilität ist für die unterschiedlichen Anforderungen innerhalb unseres Unternehmens sehr wichtig. Wir zogen verschiedene Lösungen in Betracht, und was uns bei unserer Entscheidung half, waren die großen und manchmal speziellen Bedarfe, die wir abdecken müssen. Wir entschieden uns dafür, eine zuverlässige und skalierbare Plattform für das Abhängigkeitsmanagement aufzubauen, bei der jedes Repository einzeln verarbeitet wird, um Engpässe zu beseitigen und uns für Wachstum zu rüsten.
Wir gestalteten die Plattform nach drei Kernprinzipien:
1. Parallelverarbeitung
Jedes Repository erhält seine eigene Umgebung für das Abhängigkeitsmanagement. Es gibt keine Warteschlangen mehr. Unsere Parallelität ist nur durch die Anzahl der Ressourcen begrenzt, die wir einsetzen. Wir haben außerdem eine intelligente verteilte Planung implementiert, um eine Quotenbegrenzung durch GitHub zu vermeiden.
2. Selbstbedienbarkeit
Wir nutzen unseren Servicekatalog (Backstage), um jedes neue Repository automatisch zu integrieren und zu verwalten. Wir verwenden unsere eigene Ressourcendefinition, um dem Nutzer die Möglichkeit zu geben, auszuwählen, wie oft ein Repository verarbeitet werden soll, wie viele Ressourcen er seinen Zeitplänen zuweisen möchte und ob er die Verarbeitung aus irgendeinem Grund deaktivieren oder wieder aktivieren möchte. Wir planen, auf diese Weise weitere Optionen hinzuzufügen, sobald sich die Bedürfnisse unserer Nutzer weiterentwickeln und sie mit der neuen Installation vertrauter werden.
3. Reduzierter Geheimnisbereich und Namespace-Isolation
Um die Sicherheit zu erhöhen, versorgen wir unsere Pods zur Verwaltung von Abhängigkeiten mit ephemeren GitHub-Token, die zu Beginn jedes Workflows generiert werden. Darüber hinaus isolieren wir unsere Workloads in spezifischen Namespaces, sodass ihnen nur die notwendigen Geheimnisse bereitgestellt werden. Wir steuern mithilfe von Kubernetes RBAC, auf welche Geheimnisse die einzelnen Workflows des Abhängigkeitsmanagements zugreifen dürfen. Wir verwenden auch eine Verschlüsselung, um das GitHub-Token vom übergeordneten Workflow an die untergeordneten Workflows zu übertragen.
Wir bauten unsere Plattform mit Kubernetes neu auf und nutzten dabei die Leistungsfähigkeit von Kubernetes; Argo Workflows treibt die Logik unserer Prozesse an, und Renovate CLI ist für das Scannen und Verarbeiten eines Repositorys nach dem anderen eingerichtet.
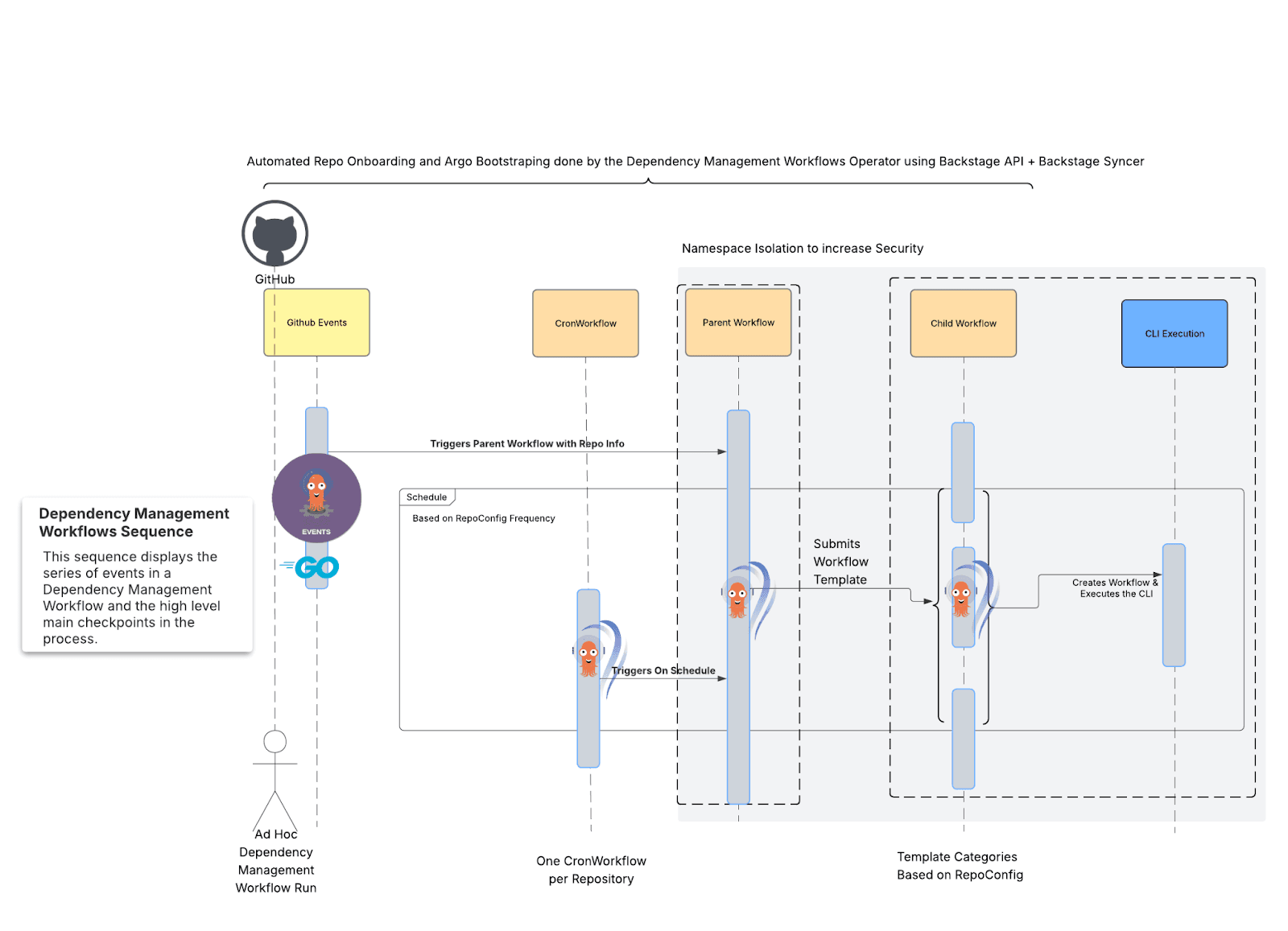
Abb. 3: Ein Überblick über die neuen Workflows für das Abhängigkeitsmanagement.
Das Schöne: Wir verwenden praxiserprobte Open-Source-Projekte auf originelle Weise, bieten neue Arbeitsbeispiele für all diese Projekte, erhöhen gleichzeitig die Entwicklungsgeschwindigkeit und konsolidieren die CVE-Reduzierung für unsere Teams.
Architektur des Abhängigkeitsmanagements: Vier Microservices
Die Plattform besteht aus vier maßgeschneiderten Komponenten:
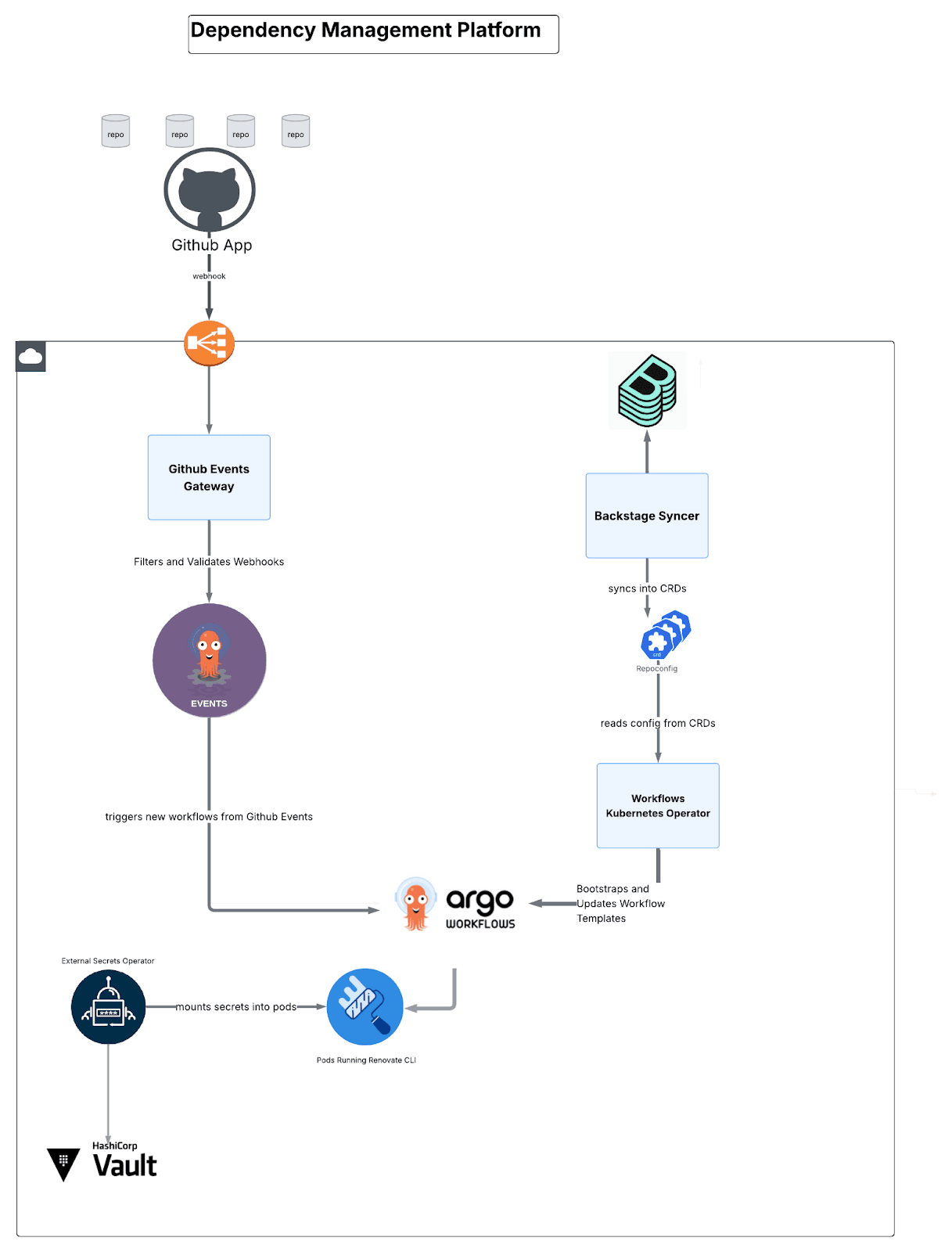
Abb. 4: Ein Überblick über die Verbindung der Komponenten.
Workflows Operator (Go/Kubebuilder)
Ein Kubernetes-Operator, der den Workflow-Lebenszyklus über drei benutzerdefinierte Ressourcendefinitionen (CRDs) verwaltet:
- RepoConfig-CRD: Eine einzige Wahrheitsquelle für die Konfiguration des Repositorys.
So wird RepoConfig im Operator definiert:
Und so würde eine Instanz von RepoConfig aussehen:
- Parent-CRD: Verwaltet CronWorkflows für geplante Scans.
Innerhalb der Abstimmungsschleife des übergeordneten Controllers sorgen wir dafür, dass die Workflow-Einstellungen erstellt und auf dem neuesten Stand gehalten oder bei Bedarf sogar gelöscht werden.
Zunächst werden einige global konfigurierte Einstellungen für Workflows abgerufen:
Das stellt sicher, dass eine Mutex-Configmap auf dem neuesten Stand ist, um zu verhindern, dass ähnliche Workflows gleichzeitig ausgeführt werden:
Anschließend wird ein Workflow-Manager erstellt, der als Struktur die CronWorkflows und die Workflow-Vorlagen erstellt oder aktualisiert:
- Child-CRD: Verwaltet WorkflowTemplates mit Ressourcen pro Repository.
Der untergeordnete Controller hat eine ähnliche Abgleichsaufgabe wie der übergeordnete Controller, ist aber diesmal für Workflow-Vorlagen im untergeordneten Namespace verantwortlich, die von den Workflows des übergeordneten Controllers ausgelöst werden.
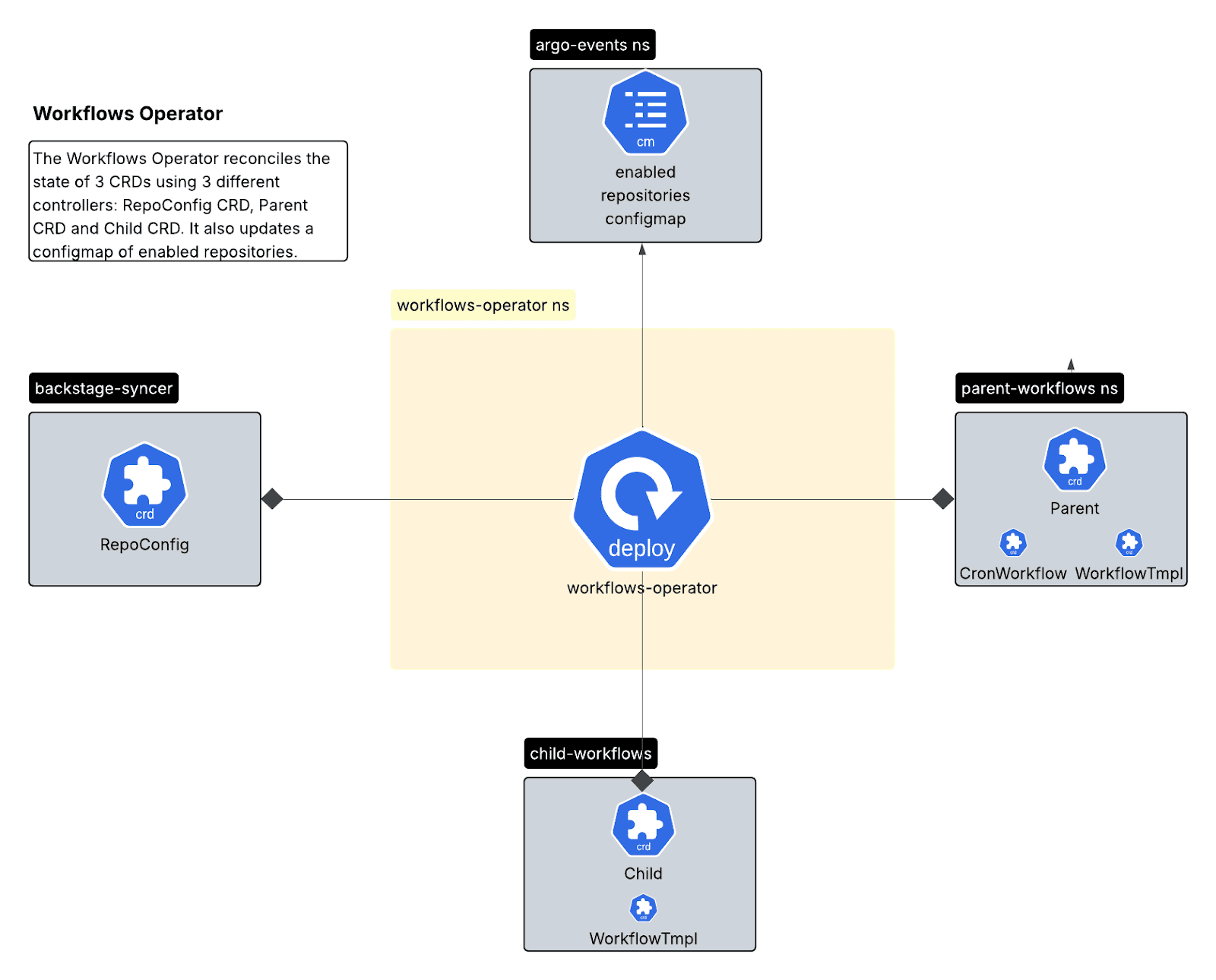
Das Multi-Controller-Muster bietet eine klare Trennung: Der RepoConfig-Controller übernimmt das Onboarding/Offboarding, der Parent-Controller verwaltet die Planung und der Child-Controller kümmert sich um die Ausführungsvorlagen.
GitHub Events Gateway (Go)
Ein sicherer Webhook-Proxy, der GitHub-Webhooks empfängt, Signaturen verifiziert, nach Organisation/Repository filtert und an Argo Events weiterleitet. Wir haben 10 verschiedene Sensoren entwickelt, die auf Interaktionen im Abhängigkeits-Dashboard, PR-Ereignisse und Paketaktualisierungen reagieren.
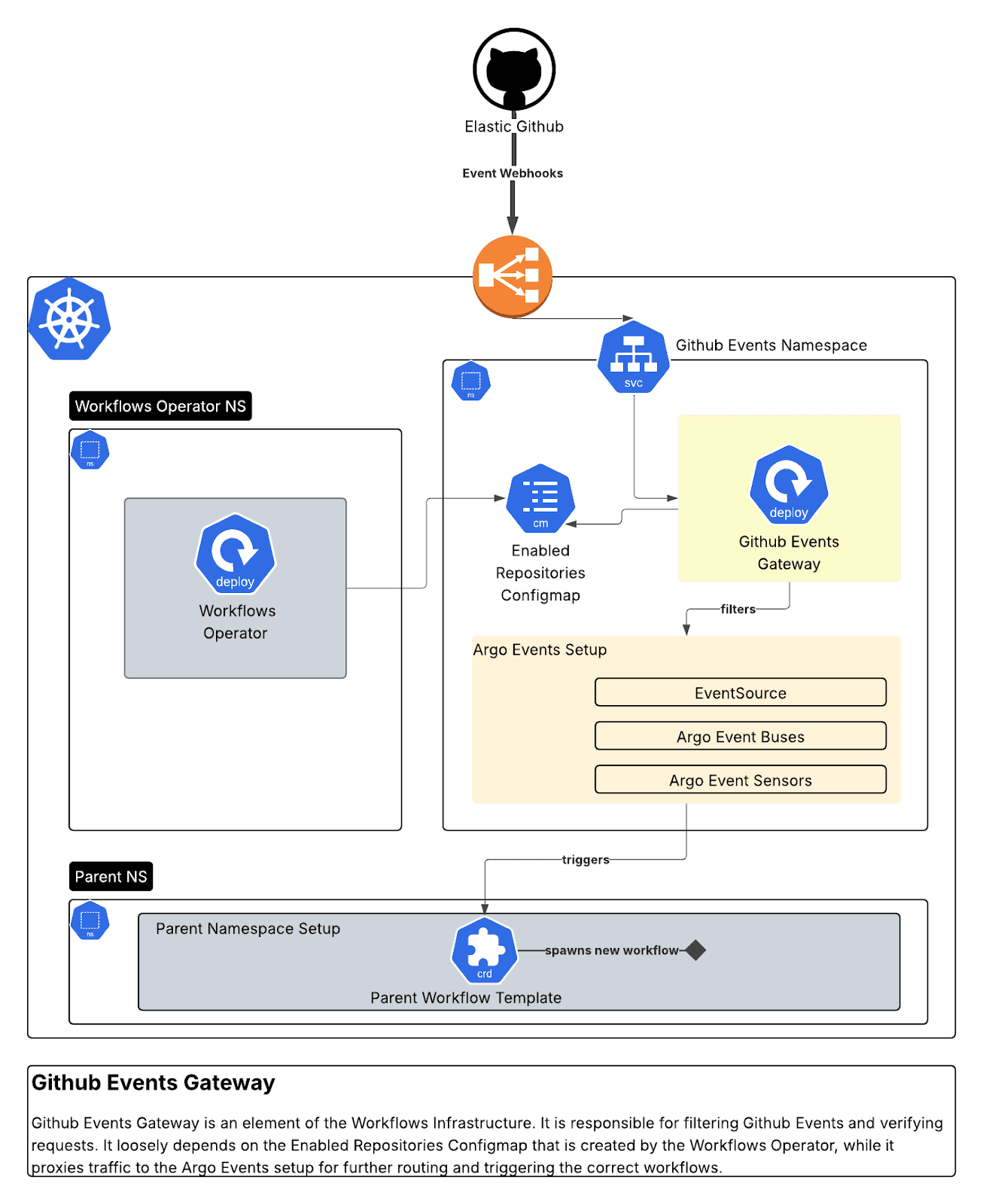
Dieses Gateway ermöglicht die Integration mit GitHub-Apps durch:
- Überprüfung eingehender GitHub-Webhook-Signaturen auf Sicherheit.
- Weiterleitung gültiger Ereignisse an die Argo Events EventSource mit allen relevanten Headern und der Authentifizierung.
- Wir konfigurieren außerdem ein authSecret auf der EventSource und stellen dieses als Bearer-Header in weitergeleiteten Anfragen bereit.
- Bereitstellung von Protokollierung, Metriken und Wiederholungslogik.
Es führt verschiedene Überprüfungen für jede GitHub-Ereignisanfrage durch.
Es stellt sicher, dass bestimmte HTTP-Attribute vorhanden sind:
Gleichzeitig validiert es auch die Signatur jeder Anfrage und deren Organisation:
Schließlich wird je nach Ereignistyp an Argo Events weitergeleitet:
Auf der Seite von Argo Events überwachen 10 Sensoren den Argo Events EventBus auf neue Ereignisse:
Anschließend wendet das Skript die Logik jedes Sensors an:
Backstage-Synchronisierer (Go)
Dies fragt unseren Service-Katalog (Backstage) nach Repository Real Resource Entities ab, wandelt sie in RepoConfig-CRDs um und hält die Plattform mit den Konfigurationsänderungen synchron. Änderungen werden innerhalb von drei Minuten wirksam.
Schließlich werden diese Daten in RepoConfig-Instanzen eingeschrieben.
Workflows-Basis (Gemischt: JavaScript, Go, Helm)
Die Basisschicht enthält Helm-Charts, JavaScript-Konfigurationen, einen Go-Wrapper für die Renovate CLI mit Verschlüsselungsunterstützung und einen benutzerdefinierten APK-Indexer für Alpine-Pakete.
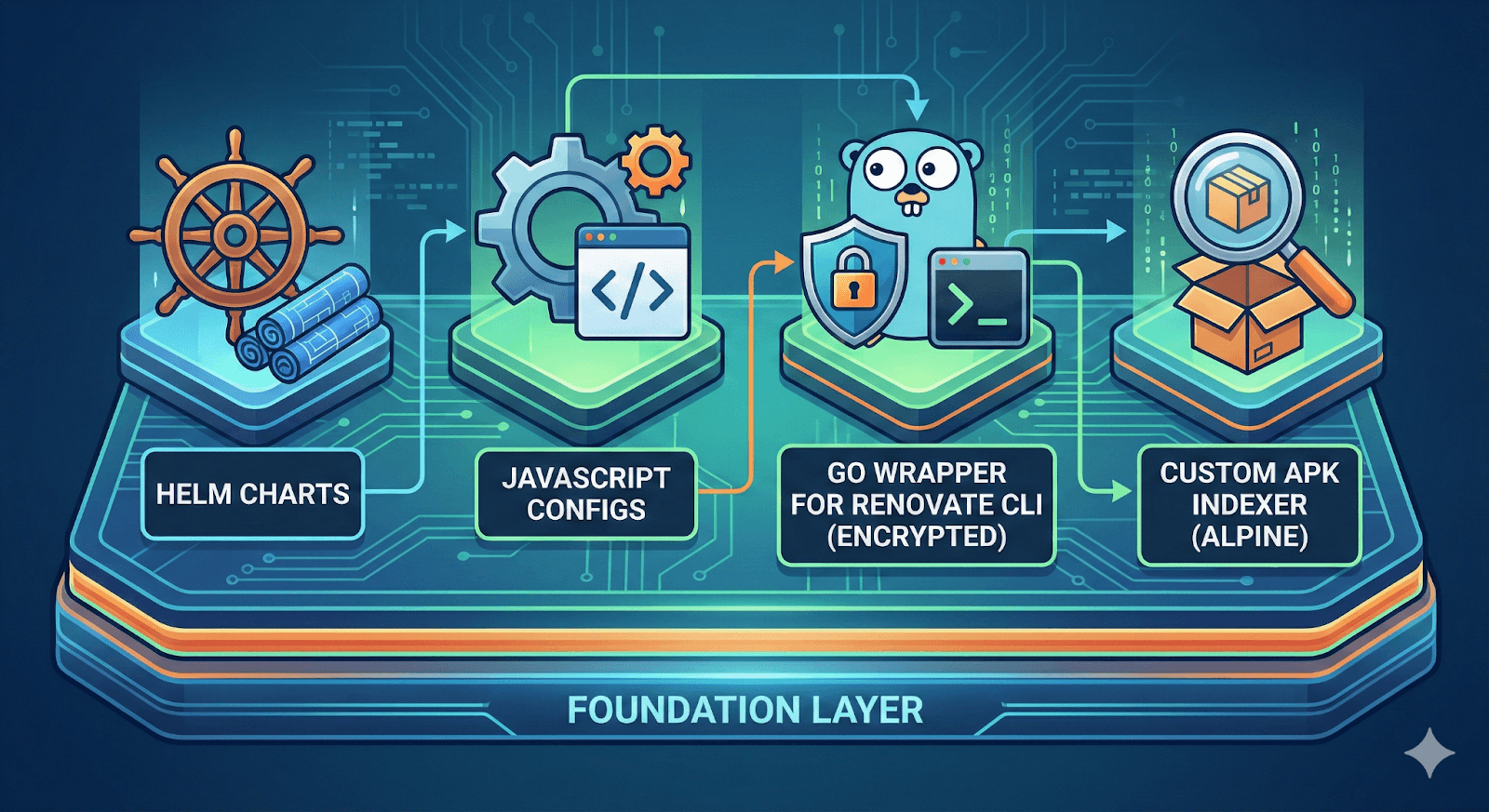
Abb. 5: Eine allgemeine Ansicht der grundlegenden Komponenten (hergestellt mit Nano Banana).
Self-Service-Konfiguration
Teams konfigurieren ihre Repositories deklarativ über Backstage:
Ressourcengruppen verteilen CPU und Speicher basierend auf der Größe des Repositorys:
- KLEIN: 500 m CPU, 1 Gi Arbeitsspeicher.
- MITTEL: 1000 m CPU, 2 Gi Arbeitsspeicher.
- GROSS: 2000 m CPU, 4 Gi Arbeitsspeicher.
Die Konfiguration ist versionskontrolliert, überprüfbar und wird automatisch angewendet.
Das Parent-Child-Muster
Das Ausführungsmodell verwendet ein Parent-Child-Workflow-Muster:
- Übergeordneter Workflow: Der Lightweight CronWorkflow läuft planmäßig. Verschlüsselt Geheimnisse, bestimmt, ob ein Scan ausgeführt werden soll, und gibt die Konfiguration an die untergeordneten Workflows weiter.
- Untergeordneter Workflow: Ein flüchtiger Pod, auf dem Renovate CLI läuft. Weist Ressourcen dynamisch zu, entschlüsselt Geheimnisse isoliert und beendet sich nach Abschluss.
Diese Trennung bietet Sicherheit (Geheimnisse werden auf der Ebene der übergeordneten Prozesse verschlüsselt), Ressourcenoptimierung (übergeordnete Prozesse verbrauchen nur minimale Ressourcen) und Skalierbarkeit (untergeordnete Prozesse laufen parallel).
Die Ergebnisse
Leistungsveränderung
- Vorher: Es wurde jeweils nur ein Repository bearbeitet, manche Repositorys wurden unter Umständen sogar einen Tag oder länger nicht verarbeitet, insgesamt wurden weniger als 1.000 Scans pro Tag durchgeführt.
- Nachher: Mehr als 100 gleichzeitige Scans, in der Regel 8.000 Scans und bis zu 10.000 aufgezeichnete Scans pro Tag, begrenzt nur durch die Menge an Ressourcen, die wir verbrauchen möchten, und unseren Umgang mit den Quotenbegrenzungen von GitHub.
Kosteneffizienz
So seltsam es auch klingen mag, mit 8.000 Pods pro Tag erzielt man das gleiche Ergebnis viel günstiger als mit einem einzigen, lange laufenden Pod, der versucht, das gleiche Ergebnis zu erzielen.
In der vorherigen Konfiguration betrieben wir eine einzelne Instanz, die an einem guten Tag 500 bis 600 Scans durchführte. Da gleichzeitig verschiedene Arten von Repositorys auf demselben Pod ausgeführt werden sollten, mussten wir den Pod auf die größten Repositorys abstimmen. Diese Größe wäre mit 8 CPUs für den Pod und 16 GB Speicher deutlich größer als unser aktuelles, besonders großes Angebot.
Um die aktuelle Tagesproduktion zu erreichen, müsste der einzelne Pod 12 Tage laufen. Vergleicht man also die Kosten für einen einzelnen Pod, der 12 Tage lang läuft, mit den Kosten für 8.000 Pods unserer Größe „MEDIUM“, die täglich im Einsatz sind, so ist unser neues Design bei gleicher Scan-Ausgabe weitaus effizienter:
| Metrik | Szenario A (Workflows) | Szenario B (Der einzelne, lange laufende Pod) |
|---|---|---|
| Einrichtung | 8.000 Pods (1 vCPU / 2 GB) | 1 Pod (8 vCPUs / 16 GB)* |
| Dauer | jeweils 10 Minuten | 12 Tage ununterbrochen |
| Gesamtarbeitszeit | 1.333 Rechenstunden | 288 Rechenstunden |
| Gesamtkosten | 65,83 $ | 113,75 $ |
Allerdings sollten wir berücksichtigen, dass unsere Standardeinstellung für unsere Workloads auf „KLEIN“ gesetzt ist, wobei die große Mehrheit erfolgreich mit 0,5 CPU und 1 GB RAM läuft und nur wenige auf „MITTEL“ oder „GROSS“ umgestellt werden müssen. Mal sehen, was passiert, wenn 60 % unserer Arbeitslasten auf „KLEIN“, 30 % auf „MITTEL“ und 10 % auf „GROSS“ laufen, was den tatsächlichen Anforderungen näherkommt.
| Metrik | Szenario A (Gemischter Schwarm) | Szenario B (Der Langläufer) |
|---|---|---|
| Strategie | 8.000 Pods (unterschiedliche Größen) | 1 Pod (8 vCPUs / 16 GB)* |
| Dauer | jeweils 10 Minuten | 12 Tage ununterbrochen |
| Gesamtkosten | 52,66 $ | 113,75 $ |
| Einsparungen | 61,09 $ (54% günstiger) | — |
Wir können sehen, dass wir bei gleicher Ausgabe in unserem aktuellen Setup weitaus kosteneffizienter sind.
Verbesserte Sicherheit
- Kurzlebige GitHub-Token (Minuten der Exposition im Vergleich zu Tagen).
- Namespace-Isolation mit rollenbasierten Zugriffskontrollgrenzen (RBAC).
- Geheime Verschlüsselung inaktiver Daten in übergeordneten Workflows.
- Kein direkter Tresorzugriff mehr.
Vorhersagbare Leistung
Mit einer garantierten Scanfrequenz können wir endlich Service Level Objectives (SLOs) festlegen. Die automatische Zusammenführung funktioniert zuverlässig. Die Teams vertrauen darauf, dass die Plattform das Versprochene auch tatsächlich liefert.
Wichtige architektonische Entscheidungen
Zu den wichtigsten Designentscheidungen, die die Gestaltung der Plattform geprägt haben, gehören die Folgenden.
- Warum über- und untergeordnete Workflows?
Wir haben dieses Muster übernommen, um eine tiefgreifende Verteidigungsstrategie durchzusetzen. Indem wir wertvolle Zugangsdaten (wie GitHub-App-Geheimnisse) auf einen dedizierten, gesperrten Namespace beschränken, nutzen wir RBAC, um sicherzustellen, dass flüchtige Ausführungspods keinen beliebigen Zugriff auf sensible Daten haben. Jüngste Sicherheitslücken in Lieferketten (zum Beispiel die „Shai Hulud“ Continuous Integration/Continuous Delivery [CI/CD]-Angriffe) haben gezeigt, wie wichtig es ist, Laufzeitumgebungen, die dynamisches Scripting ausführen, vom Anmeldeinformationsspeicher zu isolieren.
Gleichzeitig ermöglicht diese Entkopplung eine granulare Ressourcenoptimierung. Die „übergeordneten“ Workflows fungieren als leichtgewichtige Orchestrierer mit minimalem Ressourcenbedarf, während die „untergeordneten“ Workflows die rechenintensive Abhängigkeitsanalyse übernehmen. Diese Trennung vereinfacht das Lifecycle-Management, da wir auf jede Ebene eine eigene Abstimmungslogik anwenden können, sodass die Nutzer die Kontrolle über die Ausführungsparameter haben (untergeordnet), während wir die administrative Kontrolle über die Planungs- und Sicherheitsinfrastruktur (übergeordnet) behalten.
- Warum Selbstbedienbarkeit?
Die Beseitigung unseres Teams als Engpass bei der Repository-Konfiguration war eine entscheidende Voraussetzung. Unser Ziel war es, eine skalierbare Self-Service-Plattform zu entwickeln, die vielfältige Anwendungsfälle unterstützen kann. Wir haben erkannt, dass es angesichts der schieren Menge an Repositorys nicht nachhaltig ist, als Gatekeeper für jede Konfigurationsänderung zu agieren. Stattdessen verfolgten wir eine Philosophie der Befähigung: Wir stellten die „Schienen“ (Infrastruktur und Leitplanken) bereit, während wir die Nutzer in die Lage versetzten, die „Züge“ (Ausführung und Anpassung) zu fahren. Wir sind überzeugt, dass dieser Wandel hin zur Teamautonomie die Produktivität erheblich steigert, da Nutzer das System nun an ihre spezifischen operativen Bedürfnisse anpassen können.
- Warum das Kubernetes-Operator-Muster?
Wie oben bereits erwähnt, wollten wir grundsätzlich sicherstellen, dass die Plattform vollkommen selbstbedienbar sein würde. Wir benötigten einen automatisierten Mechanismus, um die Absicht des Nutzers zu erfassen (z. B. das Umschalten von Scans, das Anpassen der Planungsfrequenz oder das Optimieren der Laufzeitressourcengrenzen) und diese Änderungen sofort an die zugrunde liegenden Workflows weiterzugeben. In Erwartung zukünftiger Anforderungen sollte das System zudem leicht erweiterbar sein.
Um dies zu erreichen, entwickelten wir einen individuellen Dependency Management Kubernetes Operator. Mithilfe von CRDs als Schnittstelle für die Konfiguration etablierten wir eine Kubernetes-native Abgleichschleife. Dieser Operator überwacht kontinuierlich den vom Nutzer definierten gewünschten Zustand und orchestriert automatisch die notwendigen Aktualisierungen der Workflow-Infrastruktur. Das gewährleistet einen ereignisgesteuerten, nahtlosen Betrieb, bei dem die Plattformlogik die gesamte Komplexität hinter den Kulissen bewältigt.
- Warum ein GitHub Events Gateway entwickeln?
Die Einführung einer ereignisgesteuerten Architektur (EDA) war für die Reaktionsfähigkeit der Plattform unerlässlich. Zwar bot CronWorkflows einen zuverlässigen Basisplan, aber wir brauchten auch die Flexibilität zur Bewältigung von Ad-hoc-Ausführungen, wie etwa das manuelle Auslösen von Scans durch Nutzer über das Dashboard. Dafür benötigten wir ein dediziertes Ingestionsgateway, um die Integrität der Nutzlasten zu validieren und Anfragen intelligent weiterzuleiten.
Wir evaluierten bestehende Lösungen, darunter die native GitHub EventSource für Argo, aber stellten erhebliche Risiken hinsichtlich des operativen Aufwands und der strengen GitHub API-Kontingente (z. B. Webhook-Limits pro Repository) fest. Deshalb entwickelten wir ein benutzerdefiniertes Gateway, um unsere Infrastruktur von diesen Einschränkungen zu entkoppeln.
Entscheidend war, dass dieses Gateway während unserer Migration als strategischer Verkehrskontrollpunkt diente. Es fungierte als Switch und ermöglichte uns die Durchführung eines schrittweisen, granularen Rollouts (Verkehrsverlagerung) vom Altsystem zur neuen Infrastruktur. Dies stellte sicher, dass die Einbindung von Tausenden von Repositorys ein kontrollierter, risikofreier Prozess und kein abrupter „Big Bang“-Wechsel war.
Erkenntnisse
Einiges, was wir dabei gelernt haben, entspricht dem Elastic Source Code:
- Der Kunde steht im Mittelpunkt: Plattformen sind für Nutzer gebaut. Deshalb sind die Bedürfnisse der Nutzer an erste Stelle zu setzen. Die Plattform wird damit zu einer effizient gestalteten Infrastruktur mit Anwendungen, die Reibungsverluste für die Nutzer reduzieren, das Skalieren der Plattform vereinfachen und die Akzeptanz erhöhen.
- Raum und Zeit: Manchmal gerät man beim Weg des geringsten Widerstands in Treibsand. Wir haben zunächst versucht, das bestehende sequenzielle Verarbeitungsmodell zu optimieren, aber das löste unsere Probleme nicht, sondern ergab nur noch mehr Komplexität und lose Enden. Die mutige Entscheidung, die Plattform mit paralleler Verarbeitung neu zu gestalten, erforderte erhebliche Vorarbeiten. Letztendlich ebnete es jedoch den Weg für ein nachhaltiges Plattformwachstum und beseitigte praktisch die mühsame tägliche Verwaltungsarbeit.
- IT-Abhängigkeiten: Eine Plattform kann nicht isoliert betrieben werden; ihr Erfolg hängt davon ab, wie gut sie sich in das breitere Ökosystem integriert. In unserem Fall war die Integration mit Backstage entscheidend, da es als Wahrheitsquelle für ein nahtloses Service-Onboarding dient. In ähnlicher Weise ermöglichte uns die Verbindung zu Artifactory, private Paket-Updates effizient zu verwalten, und das sind nur einige der wichtigsten Integrationen.
- Fortschritt und EINFACHE Perfektion: Während der gesamten Implementierung stellten wir unsere ursprünglichen Annahmen immer wieder auf den Prüfstand und passten uns an neue Hindernisse an, sobald sie auftauchten. Anstatt uns durch Perfektionismus lähmen zu lassen, wählten wir einen iterativen Ansatz, gingen Herausforderungen nacheinander an und richteten unsere Migrationsstrategie an den realen Gegebenheiten aus.
Was kommt als Nächstes?
Die Bereitstellung der Plattform ermöglicht uns sinnvollere Arbeit, die uns wiederum helfen wird, das Nutzererlebnis und die Effizienz unserer Plattform zu verbessern. Einige Beispiele sind:
- Ausweitung und Absicherung der Einführung einer automatischen Zusammenführung
Die Auto-Merge-Funktion beschleunigt die Teamgeschwindigkeit erheblich, da sie mühsame manuelle Aufgaben eliminiert. Allerdings müssen wir sicherstellen, dass strenge Schutzmaßnahmen vorhanden sind, um zu gewährleisten, dass diese erhöhte Geschwindigkeit nicht auf Kosten der Sicherheit geht.
- Verbesserung der Beobachtbarkeit rund um die Endnutzererfahrung
Ein zentrales Anliegen unserer Roadmap ist die Verbesserung der Beobachtbarkeit, nicht nur auf Plattformebene, sondern auch speziell aus der Perspektive des Endnutzers. Die Erfassung von Infrastrukturkennzahlen ist zwar einfach, aber für ein Verständnis der tatsächlichen Nutzererfahrung sind tiefere Einblicke erforderlich. Wir arbeiten daran, zentrale, benutzerzentrierte Leistungskennzahlen (KPIs) zu definieren, damit unsere Telemetrie Reibungspunkte und Leistungsprobleme erkennen kann, bevor sie zu Nutzerbeschwerden eskalieren.
- Beseitigung von Hindernissen für eine breitere Akzeptanz
Mit Blick in die Zukunft liegt unser Schwerpunkt darauf, alle Barrieren zu identifizieren und zu beseitigen, die die Einführung der Plattform behindern. Ob dies die Entwicklung neuer Integrationen oder die Bereitstellung spezifischer Funktionssets erfordert – wir setzen uns für datengetriebene Planung ein. Wir haben erfolgreich eine skalierbare Plattform aufgebaut; unser Fokus verlagert sich nun darauf, ihr Potenzial zu maximieren.
Im Ganzen betrachtet
Das Projekt zu den Workflows für das Abhängigkeitsmanagement demonstriert ein allgemeineres Prinzip: Wenn Sie Open-Source-Tools über deren Standard-Bereitstellungsmodell hinaus skalieren müssen, sind Kubernetes-native Muster eine Möglichkeit dafür.
Indem Sie Folgendes annehmen:
- CRDs für die Konfiguration.
- Operatoren für das Lifecycle-Management.
- Ereignisgesteuerte Architektur für Reaktionsfähigkeit
- GitOps für das Deployment.
Wir haben eine Orchestrierung entwickelt, die unabhängig von der Zahl der verwalteten Repositorys skaliert. Die Leistung beim Scannen eines Repositorys ist gleich, egal ob wir 100 oder 1.000 verwalten.
Wenn ein kritisches CVE angekündigt wird, haben wir jetzt Antworten innerhalb von Minuten, nicht Stunden. Das ist der Unterschied zwischen einem Engpass und einem Wettbewerbsvorteil.
Danksagungen
Diese Plattform basiert auf exzellenten Open-Source-Tools:
- Kubebuilder: Das Open Source-Framework, das wir genutzt haben, um unsere Kubernetes-Operatoren zu starten, die unsere Arbeitsabläufe initialisieren und orchestrieren. [1][2]
- Backstage: Das Open-Source-Framework, auf dem wir unseren Servicekatalog aufgebaut haben und das wir als unsere Informationsquelle verwenden. [1][2]
- Argo Workflows und Argo Events: Die Open-Source-Suite, die wir verwendeten, um komplexe Prozesse zu orchestrieren und eine dynamische Verarbeitung basierend auf Ereignissen hinzuzufügen. [1][2][3][4]
- Renovate CLI: Das Open-Source-Tool zur Verwaltung von Abhängigkeiten, das unsere Repositorys verarbeitet. [1][2]
* Als Referenz für die Kosten eines einzelnen Pods wurde das AWS Fargate-Preismodell verwendet, obwohl unsere Workloads nicht unbedingt auf AWS laufen, sondern auf vollwertigen Kubernetes-Clustern.
Zugehörige Inhalte

20. April 2026
Einführung einheitlicher API-Schlüssel für Elastic Cloud Serverless und Elasticsearch
Erfahren Sie, wie Elastic die Authentifizierung von Steuerebenen und Datenebenen in Serverless mit einer global verteilten IAM-Architektur vereint. Verwenden Sie einen API-Schlüssel für Cloud- und Elasticsearch-APIs.
3. April 2026
Überwachung der Kibana-Dashboard-Ansichten mit Elastic Workflows
Erfahren Sie, wie Sie mit Elastic Workflows alle 30 Minuten Kibana-Dashboard-Ansichtsmetriken erfassen und in Elasticsearch indexieren können, um benutzerdefinierte Analysen und Visualisierungen auf Basis Ihrer eigenen Daten zu erstellen.

7. November 2025
Einführung der Elasticsearch-Abfrageregeln-Benutzeroberfläche in Kibana
Erfahren Sie, wie Sie mit der Elasticsearch Query Rules UI Dokumente mithilfe anpassbarer Regelsätze in Kibana zu Suchanfragen hinzufügen oder ausschließen können, ohne das organische Ranking zu beeinträchtigen.

6. November 2025
Erstellung eines Wissensagenten mit semantischem Recall unter Verwendung von Mastra und Elasticsearch
Lernen Sie, wie Sie einen Wissensagenten mit semantischer Erinnerung unter Verwendung von Mastra und Elasticsearch als Vektorspeicher für Gedächtnis und Informationsabruf erstellen.

22. Mai 2026
Kibana reduziert die Dashboard-Ladezeit um bis zu 25 % – hier ist die Polling-Strategie dahinter
Erfahren Sie, wie Kibana durch kontinuierliches Polling und browserseitige HTTP/2-Erkennung die Ladezeiten des Dashboards um bis zu 25 % verkürzt und dabei automatisch auf HTTP/1 zurückgreift.