Kontextentwicklung gewinnt zunehmend an Bedeutung beim Aufbau zuverlässiger KI-Agenten und -Architekturen. Je besser die Modelle werden, desto weniger hängen ihre Effektivität und Zuverlässigkeit von den Trainingsdaten ab, sondern vielmehr davon, wie gut sie im richtigen Kontext verankert sind. Agenten, die die relevantesten Informationen zum richtigen Zeitpunkt abrufen und anwenden können, liefern mit viel höherer Wahrscheinlichkeit genaue und verlässliche Ergebnisse.
In diesem Blogbeitrag verwenden wir Mastra , um einen Wissensagenten zu entwickeln, der sich merkt, was Benutzer sagen, und relevante Informationen später abrufen kann. Als Speicher- und Abruf-Backend nutzen wir Elasticsearch. Dieses Konzept lässt sich problemlos auf reale Anwendungsfälle übertragen. Man denke beispielsweise an Supportmitarbeiter, die sich an frühere Gespräche und Lösungen erinnern können, sodass sie ihre Antworten auf bestimmte Benutzer zuschneiden oder Lösungen schneller auf Basis des vorherigen Kontextes präsentieren können.
Folgen Sie dieser Anleitung, um zu sehen, wie Sie es Schritt für Schritt bauen können. Falls Sie nicht weiterkommen oder einfach nur ein fertiges Beispiel ausführen möchten, schauen Sie sich das Repository hier an.
Was ist Mastra?
Mastra ist ein Open-Source-TypeScript-Framework zum Erstellen von KI-Agenten mit austauschbaren Teilen für Schlussfolgerungen, Speicher und Werkzeuge. Die semantische Abruffunktion ermöglicht es Agenten, vergangene Interaktionen zu erinnern und abzurufen, indem Nachrichten als Einbettungen in einer Vektordatenbank gespeichert werden. Dies ermöglicht es den Agenten, den Gesprächskontext und die Kontinuität langfristig aufrechtzuerhalten. Elasticsearch ist ein hervorragender Vektorspeicher, um diese Funktion zu ermöglichen, da er eine effiziente dichte Vektorsuche unterstützt. Wenn der semantische Abruf ausgelöst wird, ruft der Agent relevante vergangene Nachrichten in das Kontextfenster des Modells ab, sodass das Modell diesen abgerufenen Kontext als Grundlage für seine Schlussfolgerungen und Antworten nutzen kann.
Was Sie für den Einstieg benötigen
- Node v18+
- Elasticsearch (Version 8.15 oder neuer)
- Elasticsearch API-Schlüssel
- OpenAI API-Schlüssel
Hinweis: Sie benötigen dies, da die Demo den OpenAI-Provider verwendet. Mastra unterstützt jedoch auch andere KI-SDKs und Community-Modell-Provider, sodass Sie ihn je nach Ihrer Konfiguration problemlos austauschen können.
Aufbau eines Mastra-Projekts
Wir werden die integrierte CLI von Mastra verwenden, um das Grundgerüst für unser Projekt bereitzustellen. Führen Sie folgenden Befehl aus:
Sie erhalten eine Reihe von Eingabeaufforderungen, beginnend mit:
1. Gib deinem Projekt einen Namen.

2. Wir können diese Standardeinstellung beibehalten; Sie können dieses Feld gerne leer lassen.

3. Für dieses Projekt verwenden wir ein von OpenAI bereitgestelltes Modell.

4. Wählen Sie die Option „Jetzt überspringen“, da wir alle unsere Umgebungsvariablen in einer `.env`-Datei speichern, die wir in einem späteren Schritt konfigurieren werden.

5. Diese Option können wir auch überspringen.

Überspringen der Installation des MCP-Servers von Mastra
Sobald dieser Initialisierungsprozess abgeschlossen ist, können wir zum nächsten Schritt übergehen.
Abhängigkeiten installieren
Als Nächstes müssen wir einige Abhängigkeiten installieren:
ai- Core AI SDK-Paket, das Werkzeuge zur Verwaltung von KI-Modellen, Eingabeaufforderungen und Arbeitsabläufen in JavaScript/TypeScript bereitstellt. Mastra basiert auf dem AI SDK von Vercel, daher benötigen wir diese Abhängigkeit, um Modellinteraktionen mit Ihrem Agenten zu ermöglichen.@ai-sdk/openai- Plugin, das das AI SDK mit OpenAI-Modellen (wie GPT-4, GPT-4o usw.) verbindet und API-Aufrufe mit Ihrem OpenAI-API-Schlüssel ermöglicht.@elastic/elasticsearch- Offizieller Elasticsearch-Client für Node.js, Wird verwendet, um eine Verbindung zu Ihrer Elastic Cloud oder Ihrem lokalen Cluster für Indizierungs-, Such- und Vektoroperationen herzustellen.dotenvLädt Umgebungsvariablen aus einer .env-Datei Datei in process.env, ermöglicht das sichere Einfügen von Anmeldeinformationen wie API-Schlüsseln und Elasticsearch-Endpunkten.
Konfiguration von Umgebungsvariablen
Erstellen Sie eine .env -Datei in Ihrem Projektstammverzeichnis, falls dort noch keine vorhanden ist. Alternativ können Sie das von mir im Repository bereitgestellte Beispiel .env kopieren und umbenennen. In dieser Datei können wir die folgenden Variablen hinzufügen:
Damit ist die grundlegende Einrichtung abgeschlossen. Von hier aus können Sie bereits mit dem Erstellen und Orchestrieren von Agenten beginnen. Wir gehen noch einen Schritt weiter und fügen Elasticsearch als Speicher- und Vektorsuchschicht hinzu.
Elasticsearch als Vektorspeicher hinzufügen
Erstellen Sie einen neuen Ordner namens stores und fügen Sie darin diese Datei ein. Bevor Mastra und Elastic eine offizielle Elasticsearch-Vektorspeicherintegration veröffentlichten, teilte Abhi Aiyer(CTO von Mastra) diese frühe Prototypklasse mit dem Namen ElasticVector. Vereinfacht gesagt verbindet es die Speicherabstraktion von Mastra mit den dichten Vektorfunktionen von Elasticsearch, sodass Entwickler Elasticsearch als Vektordatenbank für ihre Agenten verwenden können.
Werfen wir einen genaueren Blick auf die wichtigen Aspekte der Integration:
Aufnahme des Elasticsearch-Clients
Dieser Abschnitt definiert die Klasse ElasticVector und richtet die Elasticsearch-Clientverbindung mit Unterstützung für Standard- und serverlose Bereitstellungen ein.
ElasticVectorConfig extends ClientOptionsDadurch wird eine neue Konfigurationsschnittstelle erstellt, die alle Elasticsearch-Clientoptionen (wienode,auth,requestTimeout) erbt und unsere benutzerdefinierten Eigenschaften hinzufügt. Das bedeutet, dass Benutzer jede gültige Elasticsearch-Konfiguration zusammen mit unseren serverlosen Optionen übergeben können.extends MastraVectorDies ermöglicht esElasticVectorvon Mastras BasisklasseMastraVectorzu erben, die eine gemeinsame Schnittstelle darstellt, der alle Vektorspeicherintegrationen entsprechen. Dadurch wird sichergestellt, dass sich Elasticsearch aus Sicht des Agenten wie jedes andere Mastra-Vektor-Backend verhält.private client: ClientDies ist eine private Eigenschaft, die eine Instanz des Elasticsearch JavaScript-Clients enthält. Dadurch kann die Klasse direkt mit Ihrem Cluster kommunizieren.isServerlessunddeploymentChecked: Diese Eigenschaften arbeiten zusammen, um zu erkennen und zwischenzuspeichern, ob wir mit einer serverlosen oder einer Standard-Elasticsearch-Bereitstellung verbunden sind. Diese Erkennung erfolgt automatisch bei der ersten Nutzung oder kann explizit konfiguriert werden.constructor(config: ClientOptions)Dieser Konstruktor nimmt ein Konfigurationsobjekt entgegen (das Ihre Elasticsearch-Zugangsdaten und optionale Serverless-Einstellungen enthält) und verwendet es, um den Client in der Zeilethis.client = new Client(config)zu initialisieren.super(): Dadurch wird der Basiskonstruktor von Mastra aufgerufen, sodass Logging, Validierungshilfsmechanismen und andere interne Hooks geerbt werden.
Zu diesem Zeitpunkt weiß Mastra, dass es einen neuen Vektor-Shop namens gibt. ElasticVector
Erkennung des Bereitstellungstyps
Vor dem Erstellen von Indizes erkennt der Adapter automatisch, ob Sie Elasticsearch Standard oder Elasticsearch Serverless verwenden. Dies ist wichtig, da serverlose Bereitstellungen keine manuelle Shard-Konfiguration zulassen.
Was passiert:
- Zuerst wird geprüft, ob Sie
isServerlessexplizit in der Konfiguration festgelegt haben (überspringt die automatische Erkennung). - Ruft die
info()-API von Elasticsearch auf, um Clusterinformationen zu erhalten. - Prüft den Wert
build_flavor field(serverlose Bereitstellungen gebenserverlesszurück) - Falls die Build-Variante nicht verfügbar ist, wird auf die Überprüfung des Slogans zurückgegriffen.
- Speichert das Ergebnis im Cache, um wiederholte API-Aufrufe zu vermeiden.
- Wird standardmäßig die Bereitstellung durchgeführt, wenn die Erkennung fehlschlägt.
Anwendungsbeispiel:
Erstellen des „Speichers“ in Elasticsearch
Die folgende Funktion richtet einen Elasticsearch-Index zum Speichern von Einbettungen ein. Es wird geprüft, ob der Index bereits existiert. Andernfalls wird eine solche mit der unten stehenden Zuordnung erstellt, die ein dense_vector -Feld zum Speichern von Einbettungen und benutzerdefinierten Ähnlichkeitsmetriken enthält.
Einige Dinge sind zu beachten:
- Der Parameter
dimensiongibt die Länge des jeweiligen Einbettungsvektors an und hängt davon ab, welches Einbettungsmodell Sie verwenden. In unserem Fall generieren wir Einbettungen mithilfe destext-embedding-3-small-Modells von OpenAI, das Vektoren der Größe1536ausgibt. Dies werden wir als Standardwert verwenden. - Die in der folgenden Zuordnung verwendete Variable
similaritywird durch die Hilfsfunktion const similarity = this.mapMetricToSimilarity(metric)definiert, welche den Wert für den Parametermetricentgegennimmt und ihn in ein Elasticsearch-kompatibles Schlüsselwort für die gewählte Distanzmetrik umwandelt.- Zum Beispiel: Mastra verwendet allgemeine Begriffe für Vektorähnlichkeit wie
cosine,euclidean, unddotproduct. Würden wir die Metrikeuclideandirekt in das Elasticsearch-Mapping einfügen, würde dies einen Fehler auslösen, da Elasticsearch erwartet, dass das Schlüsselwortl2_normdie euklidische Distanz repräsentiert.
- Zum Beispiel: Mastra verwendet allgemeine Begriffe für Vektorähnlichkeit wie
- Serverless-Kompatibilität: Der Code lässt Shard- und Replikateinstellungen für serverlose Bereitstellungen automatisch aus, da diese von Elasticsearch Serverless automatisch verwaltet werden.
Speichern einer neuen Erinnerung oder Notiz nach einer Interaktion
Diese Funktion nimmt die nach jeder Interaktion neu generierten Einbettungen zusammen mit den Metadaten entgegen und fügt sie anschließend mithilfe der bulk -API von Elastic in den Index ein oder aktualisiert sie. Die bulk API bündelt mehrere Schreibvorgänge in einer einzigen Anfrage; diese Verbesserung unserer Indexierungsleistung stellt sicher, dass Aktualisierungen effizient bleiben, während der Speicher unseres Agenten immer größer wird.
Abfrage ähnlicher Vektoren für semantische Wiedererkennung
Diese Funktion ist der Kern des semantischen Recall-Features. Der Agent verwendet eine Vektorsuche, um ähnliche gespeicherte Einbettungen in unserem Index zu finden.
Unter der Haube:
- Führt eine kNN- Abfrage (k-nächste Nachbarn) mit Hilfe der
knn-API in Elasticsearch aus. - Gibt die K ähnlichsten Vektoren zum Eingabeabfragevektor zurück.
- Optional können Metadatenfilter angewendet werden, um die Ergebnisse einzugrenzen (z. B. nur innerhalb einer bestimmten Kategorie oder eines bestimmten Zeitraums zu suchen).
- Gibt strukturierte Ergebnisse zurück, einschließlich der Dokument-ID, des Ähnlichkeitswerts und der gespeicherten Metadaten.
Erstellung des Wissensagenten
Nachdem wir nun die Verbindung zwischen Mastra und Elasticsearch durch die ElasticVector -Integration kennengelernt haben, erstellen wir den Knowledge Agent selbst.
Erstellen Sie im Ordner agents eine Datei namens knowledge-agent.ts. Wir können damit beginnen, unsere Umgebungsvariablen zu verbinden und den Elasticsearch-Client zu initialisieren.
Hier, wir:
- Verwenden Sie
dotenvum unsere Variablen aus unserer.env-Datei zu laden. - Prüfen Sie, ob die Elasticsearch-Zugangsdaten korrekt eingefügt werden, dann können wir eine erfolgreiche Verbindung zum Client herstellen.
- Übergeben Sie den Elasticsearch-Endpunkt und den API-Schlüssel an den
ElasticVector-Konstruktor, um eine Instanz unseres zuvor definierten Vektorspeichers zu erstellen. - Optional können Sie
isServerless: trueangeben, wenn Sie Elasticsearch Serverless verwenden. Dadurch wird der automatische Erkennungsschritt übersprungen und die Startzeit verkürzt. Wird dieser Parameter weggelassen, erkennt der Adapter Ihren Bereitstellungstyp bei der ersten Verwendung automatisch.
Als nächstes können wir den Agenten mithilfe der Klasse Agent von Mastra definieren.
Folgende Felder können wir definieren:
nameundinstructions: Gib ihr eine Identität und eine primäre Funktion.modelWir verwenden OpenAIsgpt-4oüber das@ai-sdk/openai-Paket.memory:vector: Verweist auf unseren Elasticsearch-Speicher, sodass Einbettungen dort gespeichert und abgerufen werden.embedderWelches Modell soll zur Generierung von Einbettungen verwendet werden?semanticRecallDie Optionen bestimmen, wie der Rückruf funktioniert:topK: Wie viele semantisch ähnliche Nachrichten sollen abgerufen werden?messageRange: Wie viel vom Gespräch soll bei jedem Spielzug einbezogen werden?scope: Definiert die Speichergrenze.
Fast fertig. Wir müssen diesen neu erstellten Agenten lediglich zu unserer Mastra-Konfiguration hinzufügen. Importieren Sie in der Datei mit dem Namen index.ts den Wissensagenten und fügen Sie ihn in das Feld agents ein.
Zu den weiteren Bereichen gehören:
storageDies ist Mastras interner Datenspeicher für Laufzeitverlauf, Observability-Metriken, Scores und Caches. Weitere Informationen zu Mastra-Speicherlösungen finden Sie hier.loggerMastra verwendet Pino, einen leichtgewichtigen, strukturierten JSON-Logger. Es erfasst Ereignisse wie Agentenstart und -stopp, Toolaufrufe und -ergebnisse, Fehler und LLM-Reaktionszeiten.observability: Steuert die KI-Verfolgung und die Sichtbarkeit der Ausführung von Agenten. Es verfolgt:- Beginn/Ende jedes Denkschritts.
- Welches Modell oder Werkzeug wurde verwendet?
- Ein- und Ausgänge.
- Bewertungen und Beurteilungen
Testen des Agenten mit Mastra Studio
Glückwunsch! Wenn Sie es bis hierher geschafft haben, sind Sie bereit, diesen Agenten auszuführen und seine semantischen Erinnerungsfähigkeiten zu testen. Zum Glück bietet Mastra eine integrierte Chat-Benutzeroberfläche, sodass wir keine eigene entwickeln müssen.
Um den Mastra-Entwicklungsserver zu starten, öffnen Sie ein Terminal und führen Sie folgenden Befehl aus:
Nach der ersten Bündelung und dem Start des Servers sollte Ihnen eine Adresse für den Playground bereitgestellt werden.

Fügen Sie diese Adresse in Ihren Browser ein, und Sie gelangen zum Mastra Studio.
Wählen Sie die Option für knowledgeAgent und legen Sie los.
Um schnell zu prüfen, ob alles richtig verkabelt ist, geben Sie ihm beispielsweise folgende Information: „Das Team gab bekannt, dass die Umsatzentwicklung im Oktober um 12 % gestiegen ist, hauptsächlich aufgrund von Vertragsverlängerungen im Unternehmensbereich.“ Der nächste Schritt besteht darin, die Kundenansprache auf mittelständische Unternehmen auszuweiten.“ Starten Sie anschließend einen neuen Chat und stellen Sie eine Frage wie: „Auf welches Kundensegment sollten wir uns als Nächstes konzentrieren?“ Der Wissensagent sollte in der Lage sein, die Informationen aus dem ersten Chat abzurufen. Sie sollten eine Antwort wie diese sehen:

Eine solche Antwort bedeutet, dass der Agent unsere vorherige Nachricht erfolgreich als Einbettungen in Elasticsearch gespeichert und später mithilfe der Vektorsuche abgerufen hat.
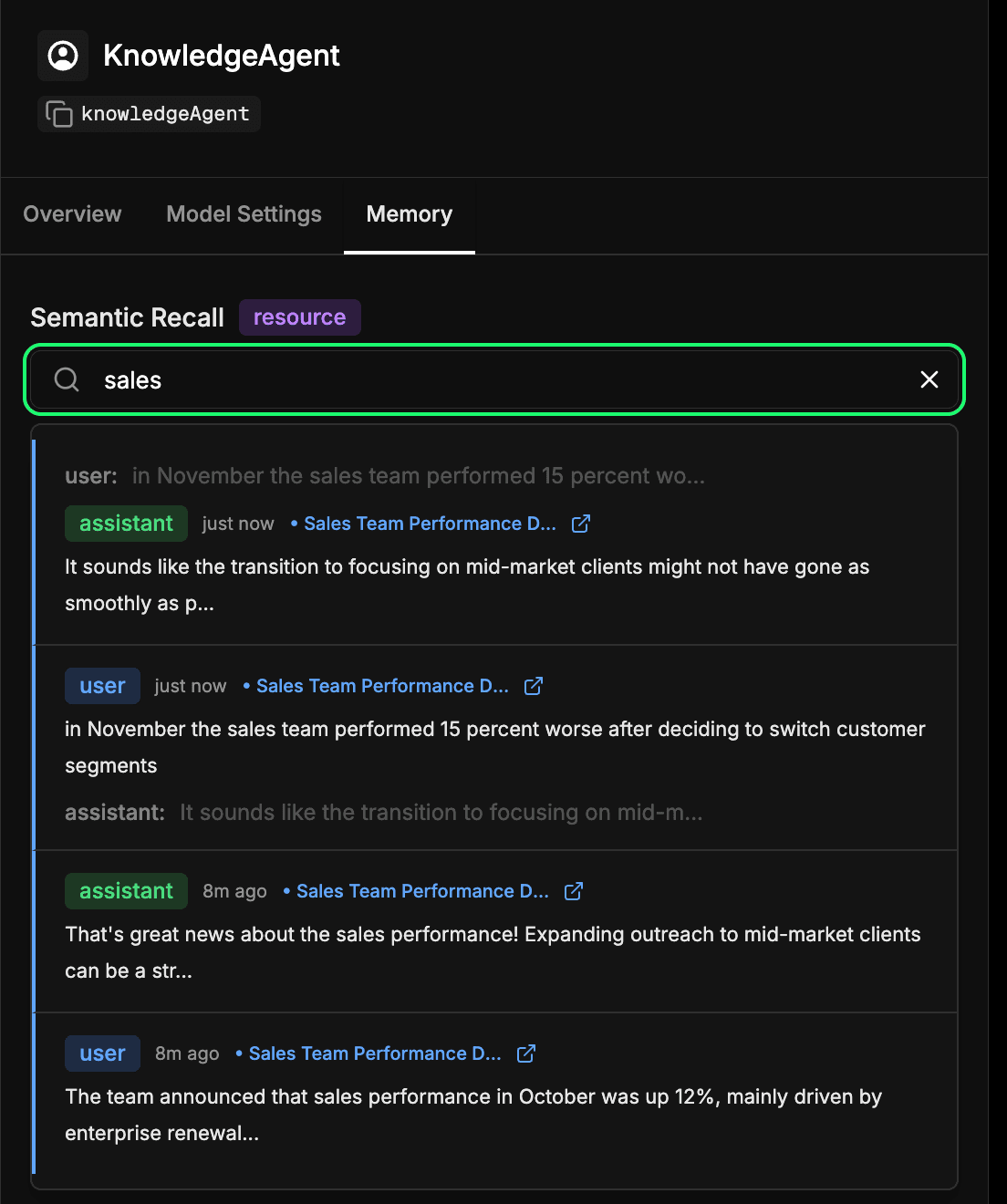
Überprüfung des Langzeitspeichers des Agenten
Wechseln Sie im Mastra Studio zur Registerkarte memory in der Konfiguration Ihres Agenten. So können Sie sehen, was Ihr Agent im Laufe der Zeit gelernt hat. Jede Nachricht, Antwort und Interaktion, die in Elasticsearch eingebettet und gespeichert wird, wird Teil dieses Langzeitgedächtnisses. Sie können vergangene Interaktionen semantisch durchsuchen, um schnell erinnerte Informationen oder Kontexte wiederzufinden, die der Agent zuvor gelernt hat. Dies ist im Wesentlichen derselbe Mechanismus, den der Agent beim semantischen Abruf verwendet, aber hier können Sie ihn direkt untersuchen. In unserem unten stehenden Beispiel suchen wir nach dem Begriff „Vertrieb“ und erhalten jede Interaktion zurück, die etwas mit Vertrieb zu tun hat.
Fazit
Durch die Verbindung von Mastra und Elasticsearch können wir unseren Agenten Speicher zur Verfügung stellen, was eine wichtige Ebene im Kontext-Engineering darstellt. Mithilfe des semantischen Abrufs können Agenten im Laufe der Zeit Kontext aufbauen und ihre Antworten auf dem basieren, was sie gelernt haben. Das bedeutet genauere, zuverlässigere und natürlichere Interaktionen.
Diese frühe Integration ist nur der Ausgangspunkt. Das gleiche Prinzip kann hier Support-Mitarbeitern ermöglichen, die sich an frühere Tickets erinnern, internen Bots, die relevante Dokumente abrufen, oder KI-Assistenten, die sich mitten im Gespräch an Kundendetails erinnern können. Wir arbeiten außerdem an einer offiziellen Mastra-Integration, wodurch diese Verbindung in naher Zukunft noch nahtloser wird.
Wir sind gespannt, was Sie als Nächstes entwickeln werden. Probieren Sie es aus, erkunden Sie Mastra und seine Speicherfunktionen und teilen Sie Ihre Entdeckungen gerne mit der Community.
Zugehörige Inhalte

11. Mai 2026
Mehr Power für Elasticsearch: native Prometheus-API-Unterstützung hinzufügen
Elasticsearch kann direkt von Prometheus-kompatiblen Clients über native PromQL-, Discovery- und Metadaten-Endpunkte abgefragt werden. Senden Sie Daten an Elasticsearch mit Prometheus Remote Write.

20. April 2026
Einführung einheitlicher API-Schlüssel für Elastic Cloud Serverless und Elasticsearch
Erfahren Sie, wie Elastic die Authentifizierung von Steuerebenen und Datenebenen in Serverless mit einer global verteilten IAM-Architektur vereint. Verwenden Sie einen API-Schlüssel für Cloud- und Elasticsearch-APIs.

8. April 2026
So erstellen Sie agentische KI-Anwendungen mit Mastra und Elasticsearch
Lernen Sie anhand eines praktischen Beispiels, wie Sie agentische KI-Anwendungen mit Mastra und Elasticsearch erstellen.
3. April 2026
Überwachung der Kibana-Dashboard-Ansichten mit Elastic Workflows
Erfahren Sie, wie Sie mit Elastic Workflows alle 30 Minuten Kibana-Dashboard-Ansichtsmetriken erfassen und in Elasticsearch indexieren können, um benutzerdefinierte Analysen und Visualisierungen auf Basis Ihrer eigenen Daten zu erstellen.

25. März 2026
Das Shell-Tool ist kein Allheilmittel für Kontext-Engineering
Erfahren Sie, welche Tools zur Kontextsuche für das Kontext-Engineering existieren, wie sie funktionieren und welche Nachteile sie mit sich bringen.