A Engenharia de Contexto está se tornando cada vez mais importante na construção de agentes e arquiteturas de IA confiáveis. À medida que os modelos se tornam cada vez melhores, sua eficácia e confiabilidade dependem menos dos dados de treinamento e mais de quão bem eles estão fundamentados no contexto correto. Agentes que conseguem recuperar e aplicar as informações mais relevantes no momento certo têm muito mais probabilidade de produzir resultados precisos e confiáveis.
Neste blog, usaremos o Mastra para construir um agente de conhecimento que memoriza o que os usuários dizem e consegue recuperar informações relevantes posteriormente, utilizando o Elasticsearch como backend de memória e recuperação. Você pode facilmente estender esse mesmo conceito a casos de uso do mundo real, como agentes de suporte que conseguem se lembrar de conversas e soluções anteriores, permitindo que eles personalizem as respostas para usuários específicos ou apresentem soluções mais rapidamente com base no contexto prévio.
Acompanhe aqui como construir isso passo a passo. Se você se perder ou simplesmente quiser executar um exemplo finalizado, confira o repositório aqui.
O que é Mastra?
Mastra é um framework TypeScript de código aberto para a construção de agentes de IA com componentes intercambiáveis para raciocínio, memória e ferramentas. Seu recurso de recuperação semântica permite que os agentes se lembrem e recuperem interações passadas, armazenando mensagens como representações vetoriais em um banco de dados vetorial. Isso permite que os agentes mantenham o contexto e a continuidade da conversa a longo prazo. O Elasticsearch é um excelente armazenamento de vetores para habilitar esse recurso, pois oferece suporte a buscas vetoriais densas e eficientes. Quando a recuperação semântica é acionada, o agente extrai mensagens relevantes do passado para a janela de contexto do modelo, permitindo que o modelo use esse contexto recuperado como base para seu raciocínio e respostas.
O que você precisa para começar
- Node v18+
- Elasticsearch (versão 8.15 ou mais recente)
- Chave da API do Elasticsearch
- Chave da API OpenAI
Observação: você precisará disso porque a demonstração usa o provedor OpenAI, mas o Mastra é compatível com outros SDKs de IA e provedores de modelos da comunidade, então você pode facilmente trocá-lo dependendo da sua configuração.
Construindo um projeto Mastra
Usaremos a CLI integrada do Mastra para fornecer a estrutura básica do nosso projeto. Execute o comando:
Você receberá uma série de instruções, começando com:
1. Dê um nome ao seu projeto.

2. Podemos manter esta opção padrão; fique à vontade para deixar este campo em branco.

3. Para este projeto, usaremos um modelo fornecido pela OpenAI.

4. Selecione a opção “Ignorar por enquanto”, pois armazenaremos todas as nossas variáveis de ambiente em um arquivo `.env` que configuraremos em uma etapa posterior.

5. Também podemos ignorar esta opção.

Ignorando a instalação do servidor MCP da Mastra
Assim que a inicialização estiver concluída, podemos passar para a próxima etapa.
Instalando dependências
Em seguida, precisamos instalar algumas dependências:
ai- Pacote Core AI SDK que fornece ferramentas para gerenciar modelos de IA, prompts e fluxos de trabalho em JavaScript/TypeScript. O Mastra é construído sobre o SDK de IA da Vercel, portanto, precisamos dessa dependência para permitir as interações do modelo com o seu agente.@ai-sdk/openai- Plugin que conecta o SDK de IA aos modelos da OpenAI (como GPT-4, GPT-4o, etc.), permitindo chamadas à API usando sua chave de API da OpenAI.@elastic/elasticsearch- Cliente oficial do Elasticsearch para Node.js, Utilizado para conectar-se ao seu Elastic Cloud ou cluster local para indexação, pesquisa e operações vetoriais.dotenv- Carrega variáveis de ambiente de um arquivo .env arquivo em process.env, permitindo que você insira credenciais com segurança, como chaves de API e endpoints do Elasticsearch.
Configurando variáveis de ambiente
Crie um arquivo .env no diretório raiz do seu projeto, caso ainda não exista um. Alternativamente, você pode copiar e renomear o exemplo .env que eu forneci no repositório. Neste arquivo, podemos adicionar as seguintes variáveis:
Isso conclui a configuração básica. A partir daqui, você já pode começar a construir e orquestrar agentes. Vamos dar um passo além e adicionar o Elasticsearch como camada de armazenamento e busca vetorial.
Adicionando o Elasticsearch como armazenamento vetorial.
Crie uma nova pasta chamada stores e, dentro dela, adicione este arquivo. Antes que a Mastra e a Elastic lancem uma integração oficial de armazenamento vetorial do Elasticsearch, Abhi Aiyer(CTO da Mastra) compartilhou esta classe protótipo inicial chamada ElasticVector. Em termos simples, ele conecta a abstração de memória do Mastra aos recursos de vetores densos do Elasticsearch, permitindo que os desenvolvedores utilizem o Elasticsearch como banco de dados de vetores para seus agentes.
Vamos analisar mais detalhadamente as partes importantes da integração:
Ingestão do cliente Elasticsearch
Esta seção define a classe ElasticVector e configura a conexão do cliente Elasticsearch com suporte para implantações padrão e sem servidor.
ElasticVectorConfig extends ClientOptionsIsso cria uma nova interface de configuração que herda todas as opções do cliente Elasticsearch (comonode,auth,requestTimeout) e adiciona nossas propriedades personalizadas. Isso significa que os usuários podem passar qualquer configuração válida do Elasticsearch juntamente com nossas opções específicas para ambientes sem servidor.extends MastraVectorIsso permite queElasticVectorherde da classe baseMastraVectordo Mastra, que é uma interface comum à qual todas as integrações de armazenamento vetorial estão em conformidade. Isso garante que o Elasticsearch se comporte como qualquer outro backend vetorial do Mastra da perspectiva do agente.private client: ClientEsta é uma propriedade privada que contém uma instância do cliente JavaScript do Elasticsearch. Isso permite que a classe se comunique diretamente com o seu cluster.isServerlessedeploymentChecked: Essas propriedades funcionam em conjunto para detectar e armazenar em cache se estamos conectados a uma implantação do Elasticsearch sem servidor ou padrão. Essa detecção ocorre automaticamente no primeiro uso ou pode ser configurada explicitamente.constructor(config: ClientOptions): Este construtor recebe um objeto de configuração (contendo suas credenciais do Elasticsearch e configurações opcionais sem servidor) e o usa para inicializar o cliente na linhathis.client = new Client(config).super()Isso chama o construtor base do Mastra, portanto, ele herda o registro de logs, os auxiliares de validação e outros recursos internos.
Neste ponto, Mastra sabe que existe uma nova loja de vetores chamada ElasticVector
Detecção do tipo de implantação
Antes de criar os índices, o adaptador detecta automaticamente se você está usando o Elasticsearch padrão ou o Elasticsearch Serverless. Isso é importante porque as implantações sem servidor não permitem a configuração manual de shards.
O que está acontecendo:
- Primeiro verifica se você definiu explicitamente
isServerlessna configuração (ignora a detecção automática). - Chama a API
info()do Elasticsearch para obter informações do cluster. - Verifica o
build_flavor field(implantações sem servidor retornamserverless) - Se a opção de build não estiver disponível, a solução é verificar a descrição da versão.
- Armazena o resultado em cache para evitar chamadas repetidas à API.
- Se a detecção falhar, a implantação padrão será utilizada por padrão.
Exemplo de uso:
Criando o armazenamento de “memória” no Elasticsearch
A função abaixo configura um índice Elasticsearch para armazenar embeddings. Verifica se o índice já existe. Caso contrário, cria um com o mapeamento abaixo que contém um campo dense_vector para armazenar embeddings e métricas de similaridade personalizadas.
Algumas coisas a ter em conta:
- O parâmetro
dimensionrepresenta o comprimento de cada vetor de incorporação, que depende do modelo de incorporação que você está usando. Em nosso caso, geraremos embeddings usando o modelotext-embedding-3-smallda OpenAI, que produz vetores de tamanho1536. Usaremos esse valor como padrão. - A variável
similarityusada no mapeamento abaixo é definida pela função auxiliar const similarity = this.mapMetricToSimilarity(metric), que recebe o valor do parâmetrometrice o converte em uma palavra-chave compatível com o Elasticsearch para a métrica de distância escolhida.- Por exemplo: Mastra usa termos gerais para similaridade de vetores como
cosine,euclideanedotproduct. Se passássemos a métricaeuclideandiretamente para o mapeamento do Elasticsearch, ele geraria um erro porque o Elasticsearch espera que a palavra-chavel2_normrepresente a distância euclidiana.
- Por exemplo: Mastra usa termos gerais para similaridade de vetores como
- Compatibilidade com ambientes sem servidor: o código omite automaticamente as configurações de shard e réplica para implantações sem servidor, pois estas são gerenciadas automaticamente pelo Elasticsearch Serverless.
Armazenar uma nova memória ou anotação após uma interação.
Esta função recebe novos embeddings gerados após cada interação, juntamente com os metadados, e os insere ou atualiza no índice usando a API bulk do Elastic. A API bulk agrupa várias operações de gravação em uma única solicitação; essa melhoria no desempenho de indexação garante que as atualizações permaneçam eficientes à medida que a memória do nosso agente continua a crescer.
Consultar vetores semelhantes para recuperação semântica
Essa função é o núcleo do recurso de recuperação semântica. O agente utiliza a busca vetorial para encontrar incorporações armazenadas semelhantes em nosso índice.
Por dentro do capô:
- Executa uma consulta kNN (k-vizinhos mais próximos) usando a API
knnno Elasticsearch. - Recupera os K vetores mais semelhantes ao vetor de consulta de entrada.
- Opcionalmente, aplica filtros de metadados para refinar os resultados (por exemplo, pesquisar apenas dentro de uma categoria ou intervalo de tempo específico).
- Retorna resultados estruturados, incluindo o ID do documento, a pontuação de similaridade e os metadados armazenados.
Criando o agente de conhecimento
Agora que vimos a conexão entre Mastra e Elasticsearch por meio da integração ElasticVector , vamos criar o próprio Agente de Conhecimento.
Dentro da pasta agents, crie um arquivo chamado knowledge-agent.ts. Podemos começar conectando nossas variáveis de ambiente e inicializando o cliente Elasticsearch.
Aqui, nós:
- Use
dotenvpara carregar nossas variáveis do nosso arquivo.env. - Verifique se as credenciais do Elasticsearch estão sendo inseridas corretamente e, em seguida, poderemos estabelecer uma conexão bem-sucedida com o cliente.
- Passe o endpoint do Elasticsearch e a chave da API para o construtor
ElasticVectorpara criar uma instância do nosso armazenamento de vetores que definimos anteriormente. - Opcionalmente, especifique
isServerless: truese estiver usando o Elasticsearch Serverless. Isso elimina a etapa de detecção automática e melhora o tempo de inicialização. Caso seja omitido, o adaptador detectará automaticamente o seu tipo de implantação na primeira utilização.
Em seguida, podemos definir o agente usando a classe Agent do Mastra.
Os campos que podemos definir são:
nameeinstructions: Dê a ele uma identidade e uma função primária.modelEstamos usando ogpt-4oda OpenAI por meio do pacote@ai-sdk/openai.memory:vector: Aponta para o nosso armazenamento Elasticsearch, de onde os embeddings são armazenados e recuperados.embedderQual modelo usar para gerar embeddings?semanticRecallAs opções definem como funciona o recall:topKQuantas mensagens semanticamente semelhantes devem ser recuperadas?messageRange: Qual a extensão da conversa a ser incluída em cada interação?scopeDefine o limite da memória.
Quase pronto. Basta adicionarmos esse agente recém-criado à nossa configuração do Mastra. No arquivo chamado index.ts, importe o agente de conhecimento e insira-o no campo agents .
Os outros campos incluem:
storageEste é o repositório de dados interno do Mastra para histórico de execuções, métricas de observabilidade, pontuações e caches. Para obter mais informações sobre o sistema de armazenamento Mastra, visite aqui.loggerO Mastra utiliza o Pino, que é um registrador JSON estruturado e leve. Ele registra eventos como início e término de agentes, chamadas e resultados de ferramentas, erros e tempos de resposta do LLM.observabilityControla o rastreamento de IA e a visibilidade da execução de agentes. Ele rastreia:- Início/fim de cada etapa de raciocínio.
- Qual modelo ou ferramenta foi utilizada?
- Entradas e saídas.
- Pontuações e avaliações
Testando o agente com o Mastra Studio
Parabéns! Se você chegou até aqui, está pronto para executar este agente e testar suas capacidades de recuperação semântica. Felizmente, o Mastra oferece uma interface de chat integrada, então não precisamos criar a nossa própria.
Para iniciar o servidor de desenvolvimento do Mastra, abra um terminal e execute o seguinte comando:
Após a inicialização e o empacotamento iniciais do servidor, você deverá receber um endereço para o Playground.

Cole este endereço no seu navegador e você será direcionado para o Mastra Studio.
Selecione a opção knowledgeAgent e comece a conversar.
Para um teste rápido para verificar se tudo está conectado corretamente, forneça algumas informações como: "A equipe anunciou que o desempenho de vendas em outubro aumentou 12%, impulsionado principalmente por renovações de contratos corporativos." O próximo passo é expandir o alcance aos clientes de médio porte.” Em seguida, inicie um novo bate-papo e faça uma pergunta como: "Em qual segmento de clientes dissemos que precisamos nos concentrar a seguir?" O agente de conhecimento deve ser capaz de recordar as informações que você lhe forneceu na primeira conversa. Você deverá ver uma resposta semelhante a esta:

Ao recebermos uma resposta como essa, significa que o agente armazenou com sucesso nossa mensagem anterior como embeddings no Elasticsearch e a recuperou posteriormente usando a busca vetorial.
Inspecionando o armazenamento de memória de longo prazo do agente.
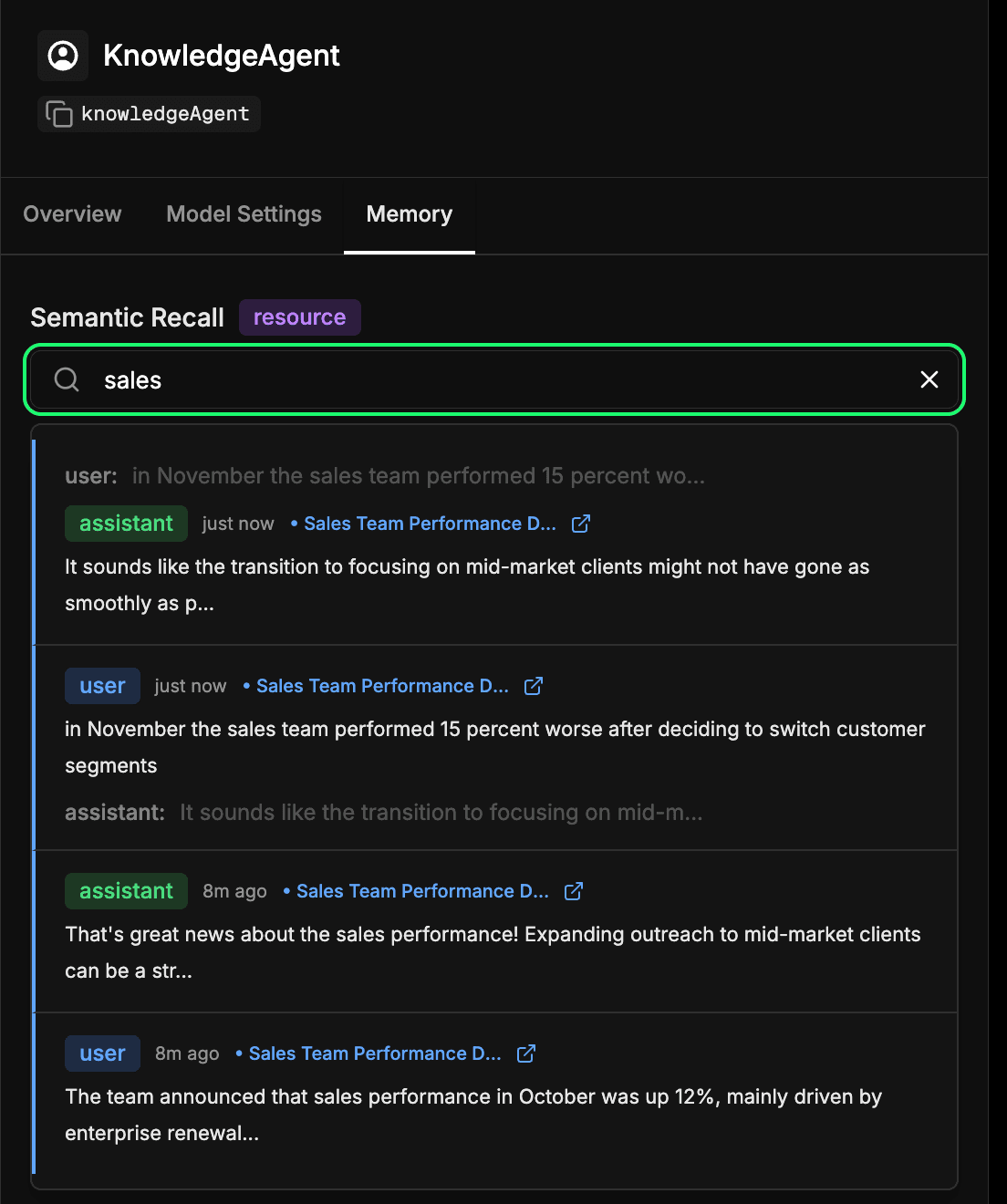
Acesse a aba memory na configuração do seu agente no Mastra Studio. Isso permite que você veja o que seu agente aprendeu ao longo do tempo. Cada mensagem, resposta e interação que é incorporada e armazenada no Elasticsearch passa a fazer parte dessa memória de longo prazo. Você pode realizar buscas semânticas em interações passadas para encontrar rapidamente informações ou contextos que o agente aprendeu anteriormente. Este é essencialmente o mesmo mecanismo que o agente usa durante a recuperação semântica, mas aqui você pode inspecioná-lo diretamente. No exemplo abaixo, estamos pesquisando o termo "vendas" e obtendo como resultado todas as interações que incluíram algo relacionado a vendas.
Conclusão
Ao conectar o Mastra e o Elasticsearch, podemos fornecer memória aos nossos agentes, o que é uma camada fundamental na engenharia de contexto. Com a recuperação semântica, os agentes podem construir contexto ao longo do tempo, fundamentando suas respostas no que aprenderam. Isso significa interações mais precisas, confiáveis e naturais.
Essa integração inicial é apenas o ponto de partida. O mesmo padrão pode permitir que agentes de suporte se lembrem de chamados anteriores, bots internos recuperem documentação relevante ou assistentes de IA consigam recordar detalhes do cliente no meio da conversa. Também estamos trabalhando para uma integração oficial com o Mastra, tornando essa combinação ainda mais perfeita em um futuro próximo.
Estamos ansiosos para ver o que você vai construir em seguida. Experimente, explore o Mastra e seus recursos de memória e sinta-se à vontade para compartilhar suas descobertas com a comunidade.
Conteúdo relacionado

11 de maio de 2026
Impulsionando o Elasticsearch: adicionando suporte nativo à API do Prometheus
Consulte o Elasticsearch diretamente de clientes compatíveis com Prometheus via endpoints nativos de PromQL, descoberta e metadados. Envie dados para o Elasticsearch com Prometheus Remote Write.

20 de abril de 2026
Apresentando chaves de API unificadas para Elastic Cloud Serverless e Elasticsearch
Saiba como a Elastic unificou o plano de controle e a autenticação do plano de dados no Serverless com uma arquitetura IAM distribuída globalmente. Use uma chave de API para as APIs da nuvem e do Elasticsearch.

8 de abril de 2026
Como criar aplicações de IA agentiva com Mastra e Elasticsearch
Aprenda como construir aplicações de IA agentiva usando Mastra e Elasticsearch com um exemplo prático.
3 de abril de 2026
Monitorando as visualizações do dashboard do Kibana com o Elastic Workflows
Aprenda a usar o Elastic Workflows para coletar métricas de visualização do dashboard do Kibana a cada 30 minutos e indexá-las no Elasticsearch, para que você possa criar análises e visualizações personalizadas com base em seus próprios dados.

25 de março de 2026
A ferramenta shell não é uma solução milagrosa para engenharia de contexto
Saiba quais ferramentas de recuperação de contexto existem para a engenharia de contexto, como elas funcionam e as vantagens e desvantagens.