Jina AI und Elastic bringen jina-embeddings-v5-text heraus, eine Familie neuer, leistungsstarker, kompakter Texteinbettungsmodelle mit modernster Leistung für Modelle vergleichbarer Größe über alle wichtigen Aufgabentypen hinweg.
Die Familie umfasst zwei Modelle:
jina-embeddings-v5-text-smalljina-embeddings-v5-text-nano
Diese Modelle sind das erfolgreiche Ergebnis eines innovativen neuen Trainingsverfahrens zum Einbetten von Modellen. Beide übertreffen um ein Vielfaches größere Modelle. Sie sparen Speicherplatz und Rechenressourcen und reagieren schneller auf Anfragen.
Das jina-embeddings-v5-text-small-Modell verfügt über 677 Millionen Parameter, unterstützt ein 32.768-Token-Eingangskontextfenster und erzeugt standardmäßig 1.024-Dimensionseinbettungen.
jina-embeddings-v5-text-nano ist nur etwa ein Drittel so groß wie sein Pendant, mit 239 Mio. Parametern und einem Eingangskontextfenster mit 8192 Token, was schlanke Einbettungen mit 768 Dimensionen ergibt.
| Modellname | Gesamtgröße | Größe des Eingangskontextfensters | Einbettungsgröße |
|---|---|---|---|
| jina-v5-text-small | 677 Mio. Parameter | 32.768 Token | 1024 Dimensionen |
| jina-v5-text-nano | 239 Mio. Parameter | 8192 Tokens | 768 Dimensionen |
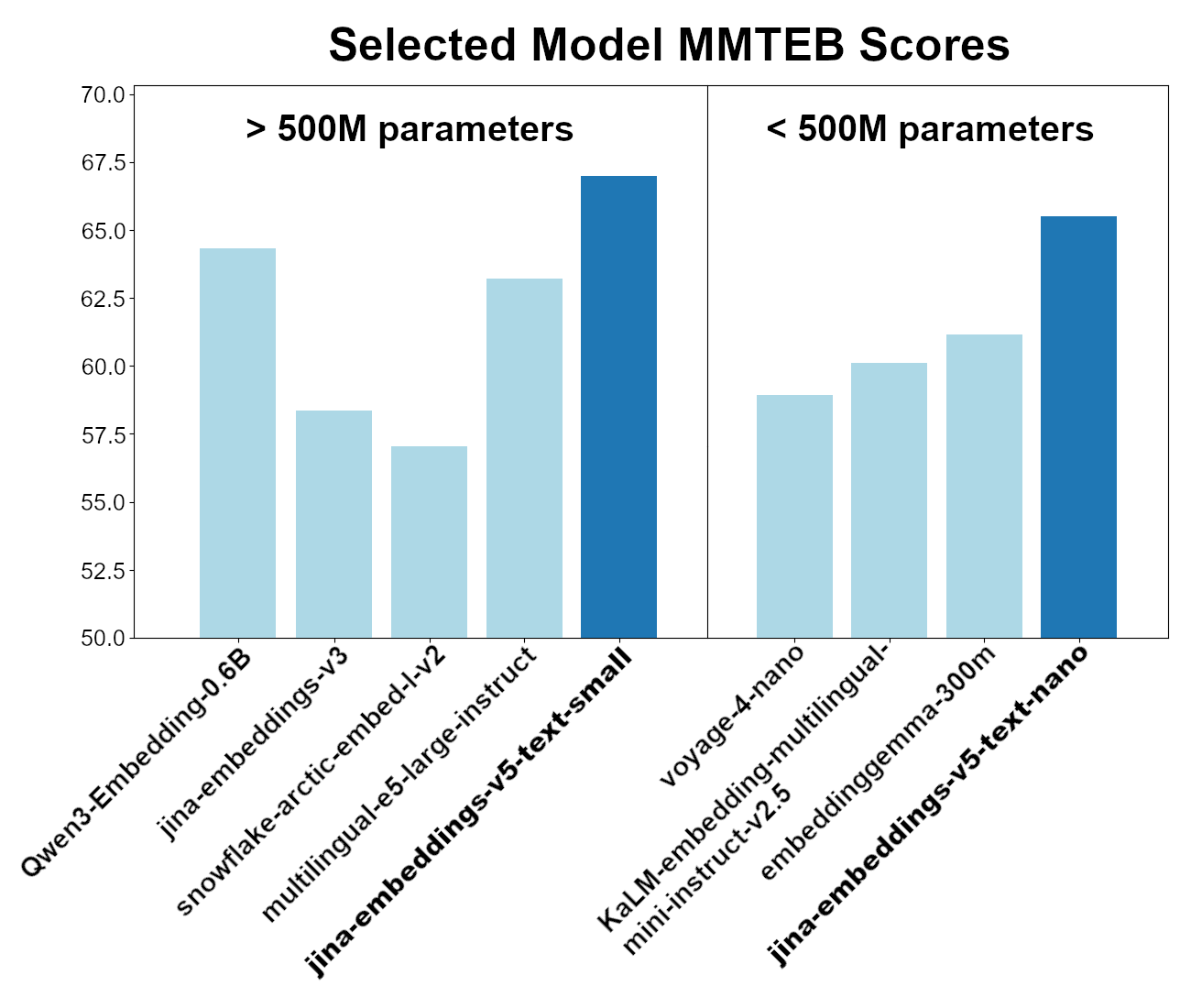
Diese beiden Modelle sind hinsichtlich der Gesamtleistung des MMTEB (Multilingual MTEB)-Benchmarks die besten verfügbaren. Unter den Modellen mit weniger als 500 Millionen Parametern ist jina-embeddings-v5-text-nano trotz weniger als 250 Millionen Parametern der beste Performer, und das jina-embeddings-v5-text-small-Modell ist führend unter mehrsprachigen Einbettungsmodellen mit weniger als 750 Millionen Parametern.
Diese Modelle sind über den Elastic Inference Service (EIS), über eine Online-API und für lokales Hosting verfügbar. Anweisungen zum Zugriff auf jina-embeddings-v5-text-Modelle finden Sie im Abschnitt „Erste Schritte“ weiter unten.
Einbettungsmodelle und semantisches Indexieren erhöhen die Genauigkeit von Suchalgorithmen drastisch, haben aber auch eine Vielzahl anderer Einsatzmöglichkeiten für Aufgaben, die semantische Ähnlichkeit und Bedeutungsextraktion betreffen, zum Beispiel:
- Doppelte Texte finden.
- Paraphrasen und Übersetzungen erkennen.
- Themenfindung.
- Empfehlungssysteme.
- Stimmungs- und Absichtsanalyse.
- Spamfilterung.
- Und vieles mehr.
Features
Diese neue Modellfamilie verfügt über eine Reihe von Features zur Verbesserung der Relevanz und Kostensenkung.
Aufgabenoptimierung
Wir haben die jina-embeddings-v5-text-Modelle für vier breitgefächerte Aufgabentypen optimiert:
| Aufgabe | Beispiel-Anwendungsfälle |
|---|---|
| Abruf | Suche mit natürlichsprachlichen Abfragen und Abrufen der relevantesten Treffer in einer Sammlung von Dokumenten. |
| Textabgleich | Semantische Ähnlichkeiten, Deduplizierung, Paraphrasierungs- und Übersetzungsabgleich und mehr. |
| Clustering | Themenfindung und automatische Organisation von Dokumentensammlungen. |
| Klassifizierung | Kategorisierung von Dokumenten, Stimmungs- und Absichtsanalysen, ähnliche Aufgaben. |
Die Optimierung für eine Aufgabe bedeutet in der Regel, dass man bei einer anderen Aufgabe Kompromisse eingehen muss. Daher bieten die meisten Einbettungsmodelle nur für eine Art von Aufgabe eine wettbewerbsfähige Leistung. jina-embeddings-v5-text-Modelle können sich hingegen auf alle vier Bereiche spezialisieren, ohne Kompromisse einzugehen, indem sie aufgabenspezifische Low-Rank Adaptation (LoRA)-Adapter trainieren.
LoRA-Adapter sind gewissermaßen Plugins für KI-Modelle, die ihr Verhalten drastisch ändern, während sie die Gesamtgröße nur geringfügig erhöhen. Anstatt für jede Aufgabe ein komplettes Modell mit Hunderten Millionen Parametern zu verwenden, ermöglicht die jina-embeddings-v5-text-Modellfamilie die Nutzung eines einzigen Modells mit einem kompakten LoRA-Adapter für jede Aufgabe. Dadurch werden Speicher, Speicherplatz und Inferenzkosten gespart.
Kürzen von Einbettungen
Wir haben die jina-embeddings-v5-text-Modelle mit Matryoshka Representation Learning trainiert, das es Ihnen ermöglicht, Ihre Einbettungen auf kleinere Größen zu reduzieren, ohne die Qualität wesentlich zu beeinträchtigen.
Standardmäßig erzeugt jina-embeddings-v5-text-small Einbettungsvektoren in 1.024 Dimensionen, die jeweils durch eine 16-Bit-Zahl dargestellt werden, sodass jede Einbettung 2 KB groß ist. Für eine große Sammlung von Dokumenten kann dies eine Menge Daten zum Speichern bedeuten, und die Suche in einer Vektordatenbank voller Einbettungen fällt proportional zur Größe der Datenbank sowie zur Anzahl der Dimensionen aus, die jeder gespeicherte Vektor enthält.
Man kann aber einfach die Größe der Einbettungen halbieren (512 der 1.024 Dimensionen weglassen) und so den Speicherplatz halbieren und gleichzeitig die Suchgeschwindigkeit verdoppeln. Dies hat Auswirkungen auf die Leistung. Das Entfernen von Informationen verringert die Präzision. Aber wie der Graph unten zeigt, verringert sich die Leistung selbst dann nur geringfügig, wenn Sie die Hälfte der Einbettung weglassen:
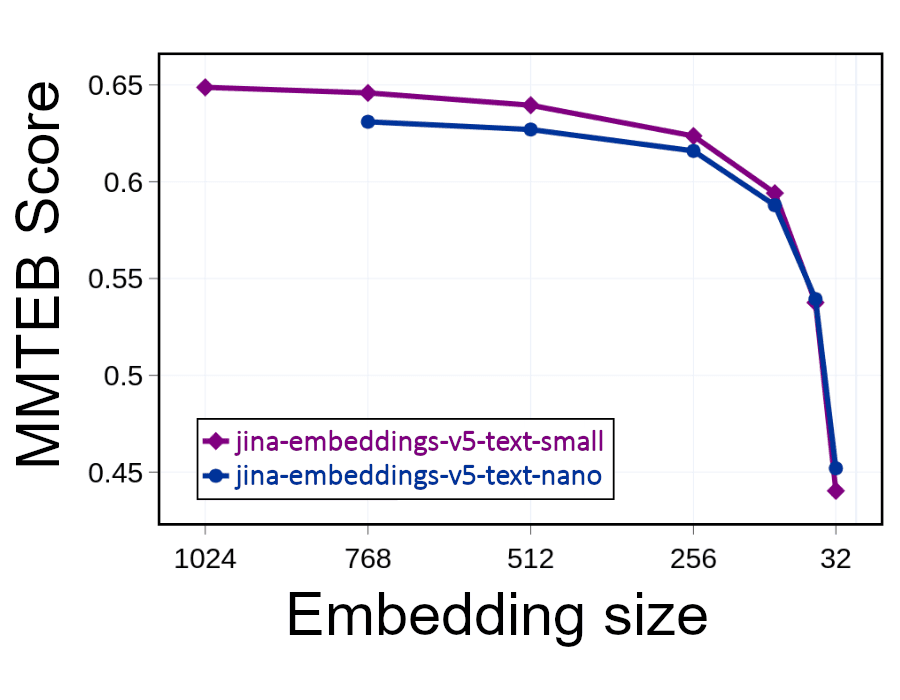
Solange Ihre Einbettungen mindestens 256 Dimensionen haben, sollte der Präzisionsverlust relativ gering bleiben. Unterhalb dieses Niveaus nehmen Relevanz und Genauigkeit jedoch schnell ab.
Das Kürzen von Einbettungen auf diese Weise ermöglicht es Nutzern, ihre eigenen Kompromisse zwischen Genauigkeit und Rechenkosten zu bestimmen. Es bietet Ihnen die nötigen Tools, um große Effizienzgewinne und erhebliche Kosteneinsparungen aus Ihrer Such-KI zu erzielen.
Robuste Quantisierung
Quantisierung ist eine weitere Möglichkeit, um die Größe von Einbettungen zu reduzieren. Anstatt einen Teil jeder Einbettung zu entfernen, reduziert die Quantisierung die Präzision der Zahlen in der Einbettung. Die jina-embeddings-v5-text-Modelle generieren Einbettungen mit 16-Bit-Zahlen, doch diese Zahlen können abgerundet werden, wodurch ihre Präzision und die Anzahl der Bits, die zu ihrer Speicherung nötig sind, reduziert werden. Im Extremfall können wir jede Zahl auf ein Bit (0 oder 1) reduzieren und die standardmäßigen 1.024-dimensionalen Einbettungen von jina-embeddings-v5-textvon 2 Kilobyte auf 128 Byte komprimieren, was einer Reduzierung um 94 % durch alleinige binäre Quantisierung entspricht. Genau wie bei der Kürzung führt dies zu großen Einsparungen bei Speicherplatz und Rechenkosten. Jedoch sorgt die Quantisierung, ähnlich wie eine Kürzung, dafür, dass Einbettungen weniger genau ausfallen.
Wir haben die jina-embeddings-v5-text -Modelle darauf trainiert, mit Elasticsearchs Better Binary Quantization zu arbeiten, indem wir diesen Genauigkeitsverlust minimieren. Benchmark-Tests binarisierter Einbettungen aus diesen Modellen zeigen eine Leistung, die fast der ihrer nicht-binarisierten Äquivalente entspricht. Im technischen Bericht finden Sie detaillierte Ablationsstudien zur Binarisierungsleistung.
Mehrsprachige Leistung
Viele Einbettungsmodelle sind mehrsprachig, weil sie auf Materialien trainiert wurden, die eine große Anzahl von Sprachen enthalten. Das bedeutet jedoch nicht, dass sie in allen unterstützten Sprachen gleich gut funktionieren.
Wir haben 211 Sprachen im MMTEB-Mehrsprachen-Benchmark identifiziert und sie getrennt, um unsere Modelle mit ähnlichen Modellen auf Sprachbasis vergleichen zu können. Die folgende Abbildung fasst unsere Ergebnisse als Heatmap zusammen. Jedes Feld stellt eine Sprache dar (identifiziert durch ihren ISO-639-Code). Je grüner es ist, desto besser hat das Modell im Vergleich zum Durchschnitt ähnlicher Modelle abgeschnitten:

Obwohl die Genauigkeit zwischen Sprachen variiert, sind die jina-embeddings-v5-text-Modelle in den meisten Sprachen weltweit auf dem neuesten Stand der Technik oder nahezu so weit.
Details zur mehrsprachigen Leistung finden Sie im technischen Bericht jina-embeddings-v5-text.
Jina in Elastic: Hochmoderne native KI für die Suche
Mit jina-embeddings-v5-text-Modellen auf EIS können Sie leistungsstarke, mehrsprachige Einbettungsmodelle nativ in Elasticsearch ausführen, mit vollständig verwalteter, GPU-beschleunigter Inferenz und ohne Infrastruktur zur Bereitstellung oder Skalierung. jina-embeddings-v5-text-Modelle erweitern den wachsenden EIS-Modellkatalog mit kompakten, mehrsprachigen Modellen, die von den neuesten Entwicklungen im Bereich der KI angetrieben werden. Diese Modelle weisen eine herausragende Leistung bei der Informationswiedergewinnung und Standard-Datenanalyse-Benchmarks auf und bieten eine unübertroffene, weltweite Unterstützung in mehreren Sprachen.
Mit zwei Modellen in deutlich unterschiedlichen Größen können die Nutzer entscheiden, welches am besten zu ihren Anwendungsbereichen und ihrem Budget passt. Darüber hinaus bieten jina-embeddings-v5-text -Modelle mit robusten Einbettungen, die auch bei Verkleinerung der Größe oder Quantisierung auf eine geringere Genauigkeit leistungsfähig bleiben, Möglichkeiten für weitere konkrete Einsparungen bei Speicher- und Rechenkosten sowie bei der Verarbeitungslatenz.
Mit der jina-embeddings-v5-text-Familie, Jina Reranker und Elastics schneller Vektor- und BM25-Suche haben Nutzer nun Zugang zu einer End-to-End-Hybridsuche von Elastic. Wenn Sie die relevantesten Ergebnisse benötigen – sei es für Retrieval Augmented Generation (RAG) Pipelines, Suchanwendungen oder Datenanalysen – bietet Elastic mit den Such-KI-Modellen von Jina solide und kosteneffiziente Qualität.
Erste Schritte
Die jina-embeddings-v5-text-Modelle sind vollständig in EIS integriert und können durch Einstellen des type Felds für semantic_text verwendet werden, um Ihren Index zu erstellen und das Modell (jina-embeddings-v5-text-small oder jina-embeddings-v5-text-nano) im inference_id Feld zu spezifizieren, wie an diesem Beispiel zu sehen ist:
Elasticsearch wählt während des Indexierens und des Abrufs automatisch den entsprechenden LoRA-Adapter aus. Die Einbettungsdimensionen (siehe Abschnitt „Kürzen von Einbettungen“ oben) können festgelegt werden, wenn ein benutzerdefinierter Inferenz-Endpoint erstellt wird.
In der Elasticsearch-Dokumentation finden Sie weitere Informationen zur Nutzung vonjina-embeddings-v5-text Modellen.
Weitere Informationen
Um mehr über jina-embeddings-v5-text-Modelle zu erfahren, lesen Sie die Versionshinweise im Jina AI-Blog und den technischen Bericht mit detaillierteren technischen Informationen zur Leistung und zum innovativen neuen Trainingsverfahren von Jina AI. Informationen zum lokalen Herunterladen und Betrieb dieser Modelle finden Sie auf der Seite der jina-embeddings-v5-text-Sammlung auf Hugging Face.
Die Jina AI-Modelle stehen unter einer CC-BY-NC-4.0-Lizenz zur Verfügung. Sie können sie also kostenlos herunterladen und ausprobieren. Für die kommerzielle Nutzung wenden Sie sich bitte an den Elastic-Vertrieb.
Zugehörige Inhalte

11. Mai 2026
Ein Index, alle Medien: Einführung von Jina-Embeddings-v5-Omni
Mit jina-embeddings-v5-omni können Sie Text, Bilder, Videos und Audiodateien in einen einzigen Elasticsearch-Index einbetten und gleichzeitig abfragen.

22. April 2026
Jina-Einbettungen v3 sind jetzt im Model Garden der Gemini Enterprise Agent Platform verfügbar
Das Search Foundation Model in Jina, „jina-embeddings-v3“, kann nun eigenständig im Model Garden der Gemini Enterprise Agent Platform bereitgestellt werden und wird bald um weitere Modelle ergänzt. Führen Sie „jina-embeddings-v3“ auf einer einzelnen L4-GPU in Ihrer eigenen VPC aus.
1. Januar 2026
Eine Einführung in Jina-Modelle, ihre Funktionalität und ihre Einsatzmöglichkeiten in Elasticsearch
Entdecken Sie multimodale Einbettungen von Jina, Reranker v3 und semantische Einbettungsmodelle und erfahren Sie, wie Sie diese nativ in Elasticsearch verwenden können.

22. Mai 2026
Kibana reduziert die Dashboard-Ladezeit um bis zu 25 % – hier ist die Polling-Strategie dahinter
Erfahren Sie, wie Kibana durch kontinuierliches Polling und browserseitige HTTP/2-Erkennung die Ladezeiten des Dashboards um bis zu 25 % verkürzt und dabei automatisch auf HTTP/1 zurückgreift.

Beschreiben statt zeichnen: KI-native Kibana-Dashboards über MCP und ES|QL
Vom Prompt zum Dashboard. Erfahren Sie, wie Sie Kibana-Dashboards in natürlicher Sprache mit example-mcp-dashbuilder erstellen: eine Open-Source-MCP-Anwendung, die ES|QL-Abfragen schreibt, interaktive Diagramme erstellt und voll funktionsfähige Dashboards direkt in Kibana exportiert.