Jina by Elastic bietet Suchgrundlagenmodelle für Anwendungen und die Automatisierung von Geschäftsprozessen. Diese Modelle bieten Kernfunktionen für den Einsatz von KI in Elasticsearch-Anwendungen und innovativen KI-Projekten.
Jina-Modelle lassen sich in drei Hauptkategorien einteilen, die zur Unterstützung der Informationsverarbeitung, Organisation und den Informationsabruf entwickelt wurden:
- Semantische Einbettungsmodelle
- Reranking-Modelle
- Kleine generative Sprachmodelle
Semantische Einbettungsmodelle
Die Idee hinter semantischen Einbettungen ist, dass ein KI-Modell lernen kann, Aspekte der Bedeutung seiner Eingaben in Bezug auf die Geometrie hochdimensionaler Räume darzustellen.
Sie können sich eine semantische Einbettung als einen Punkt (technisch gesehen einen Vektor) in einem hochdimensionalen Raum vorstellen. Ein Einbettungsmodell ist ein neuronales Netz, das digitale Daten als Eingabe aufnimmt (potenziell alles, aber meist Text oder Bild) und die Position eines entsprechenden hochdimensionalen Punktes als numerische Koordinaten ausgibt. Wenn das Modell seine Aufgabe gut erfüllt, ist der Abstand zwischen zwei semantischen Einbettungen proportional dazu, wie sehr ihre entsprechenden digitalen Objekte dieselbe Bedeutung haben.
Um zu verstehen, wie wichtig das für Suchanwendungen ist, stellen Sie sich eine Einbettung für das Wort „dog“ und eine für das Wort „cat“ als Punkte im Raum vor:
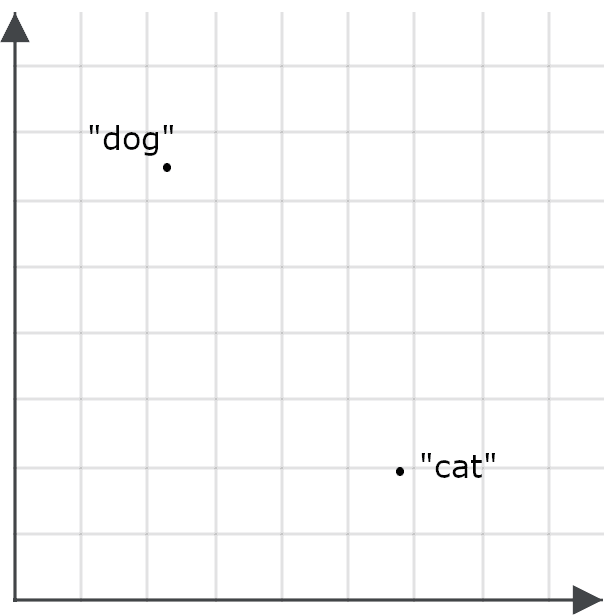
Ein gutes Einbettungsmodell sollte eine Einbettung für das Wort „feline“ generieren, die viel näher an „cat“ als an „dog“ liegt, und „canine“ sollte eine Einbettung haben, die viel näher an „dog“ als an „cat“ liegt, weil diese Wörter fast dasselbe bedeuten:

Wenn ein Modell mehrsprachig ist, würden wir dasselbe für Übersetzungen von „cat“ und „dog“ erwarten:

Einbettungsmodelle übersetzen Ähnlichkeiten oder Unterschiede in der Bedeutung zwischen Dingen in räumliche Beziehungen zwischen Einbettungen. Die Bilder oben haben nur zwei Dimensionen, sodass Sie sie auf einem Bildschirm sehen können, aber das Einbetten von Modellen erzeugt Vektoren mit Dutzenden bis Tausenden von Dimensionen. Dies ermöglicht es ihnen, die Feinheiten der Bedeutung ganzer Texte zu kodieren, indem sie einen Punkt in einem Raum mit Hunderten oder Tausenden von Dimensionen für Dokumente mit Tausenden von Wörtern oder mehr zuweisen.
Multimodale Einbettungen
Multimodale Modelle erweitern das Konzept der semantischen Einbettung auf andere Dinge als Texte, insbesondere auf Bilder. Wir würden erwarten, dass eine Einbettung für ein Bild nahe an einer Einbettung einer getreuen Beschreibung des Bildes liegt:
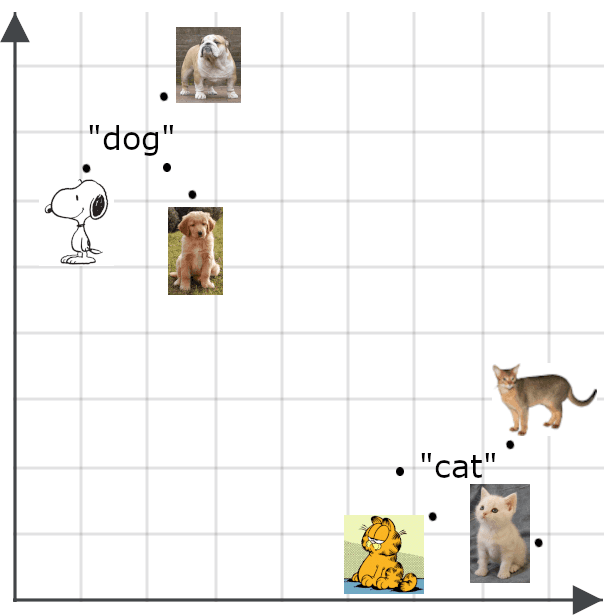
Semantische Einbettungen haben viele Einsatzmöglichkeiten. Unter anderem können Sie sie verwenden, um effiziente Klassifikatoren zu erstellen, Clustering durchzuführen und eine Vielzahl von Aufgaben zu erledigen, wie z. B. die Deduplizierung von Daten und die Untersuchung der Datendiversität. Beides ist wichtig für Big-Data-Anwendungen, bei denen mit zu vielen Daten gearbeitet wird, um sie manuell zu verwalten.
Die größte direkte Anwendung von Einbettungen ist der Informationsabruf. Elasticsearch kann Abrufobjekte mit Einbettungen als Schlüssel speichern. Abfragen werden in Einbettungsvektoren umgewandelt, und eine Suche gibt die gespeicherten Objekte zurück, deren Schlüssel den Abfrage-Einbettungen am nächsten sind.
Bei der traditionellen vektorbasierten Suche (manchmal auch als Sparse Vector Retrieval bezeichnet) werden Vektoren verwendet, die auf Wörtern oder Metadaten in Dokumenten und Anfragen basieren. Die einbettungsbasierte Suche (auch bekannt als Dense Vector Retrieval) verwendet hingegen KI-bewertete Bedeutungen anstelle von Wörtern. Dadurch sind sie im Allgemeinen wesentlich flexibler und genauer als herkömmliche Suchmethoden.
Matryoshka-Darstellungslernen
Die Anzahl der Dimensionen, die eine Einbettung hat, und die Präzision der darin enthaltenen Zahlen haben erhebliche Auswirkungen auf die Leistung. Äußerst hochdimensionale Räume und extrem hochpräzise Zahlen können sehr detaillierte und komplexe Informationen darstellen, erfordern aber größere KI-Modelle, deren Training und Nutzung teurer sind. Die erzeugten Vektoren benötigen mehr Speicherplatz, und es braucht mehr Rechenzyklen, um die Abstände zwischen ihnen zu berechnen. Bei der Verwendung semantischer Einbettungsmodelle müssen wichtige Kompromisse zwischen Präzision und Ressourcenverbrauch eingegangen werden.
Um die Flexibilität für die Nutzer zu maximieren, werden Jina-Modelle mit einer Technik namens Matryoshka Representation Learning trainiert. Dies führt dazu, dass die Modelle die wichtigsten semantischen Unterscheidungen in die ersten Dimensionen des Einbettungsvektors vorladen, sodass man die höheren Dimensionen einfach abschneiden und trotzdem eine gute Leistung erzielen kann.
In der Praxis bedeutet das, dass Nutzer von Jina-Modellen wählen können, wie viele Dimensionen ihre Einbettungen haben sollen. Die Wahl von weniger Dimensionen verringert die Präzision, der Leistungsverlust ist jedoch gering. Bei den meisten Aufgaben sinken die Leistungskennzahlen für Jina-Modelle um 1 bis 2 %, wenn man die Einbettungsgröße um 50 % reduziert, bis hin zu einer Reduzierung um etwa 95 %.
Asymmetrischer Informationsabruf
Semantische Ähnlichkeit wird normalerweise symmetrisch gemessen. Der Wert, den man beim Vergleich von „cat“ mit „dog“ erhält, ist derselbe wie der Wert, den man beim Vergleich von „dog“ mit „cat“ erhält. Bei der Verwendung von Einbettungen für den Informationsabruf funktionieren diese jedoch besser, wenn man die Symmetrie aufhebt und Anfragen anders kodiert als die zu kodierenden Objekte.
Das liegt an der Art, wie wir Einbettungsmodelle trainieren. Die Trainingsdaten enthalten Instanzen der gleichen Elemente, wie z. B. Wörter, in vielen verschiedenen Kontexten. Die Modelle lernen die Semantik, indem sie die kontextuellen Ähnlichkeiten und Unterschiede zwischen den Elementen vergleichen.
So könnten wir beispielsweise feststellen, dass das Wort „animal“ nicht in sehr vielen der gleichen Kontexte wie „cat“ oder „dog“ vorkommt, und daher ist die Einbettung für „animal“ möglicherweise nicht besonders nahe an der von „cat“ oder „dog“:
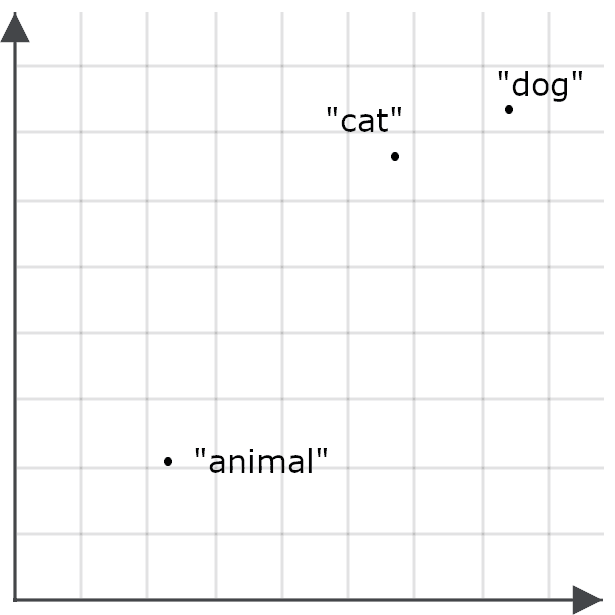
Dies macht es unwahrscheinlicher, dass eine Abfrage nach „animal“ Dokumente über Katzen und Hunde zurückgibt – das Gegenteil unseres Ziels. Deshalb kodieren wir „Tier“ anders, wenn es sich um eine Suchanfrage handelt, als wenn es ein Ziel für den Informationsabruf ist:
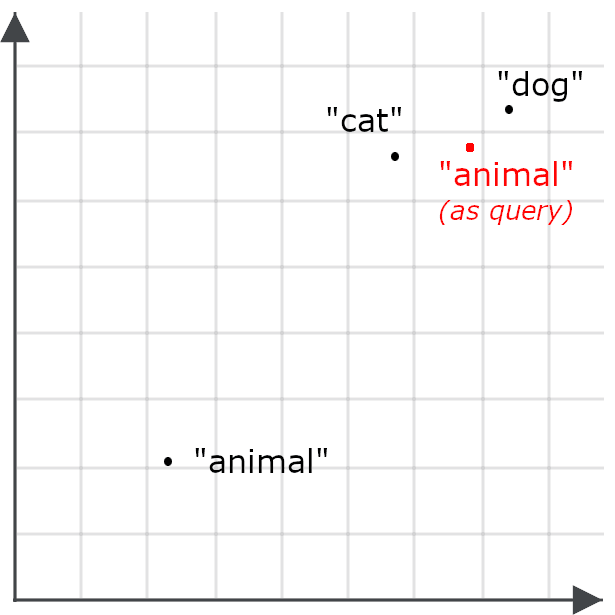
Asymmetrischer Informationsabruf bedeutet, ein anderes Modell für Abfragen zu verwenden oder ein Einbettungsmodell speziell zu trainieren, um Dinge auf eine bestimmte Weise zu kodieren, wenn sie für den Abruf gespeichert sind, und Abfragen auf eine andere Weise zu kodieren.
Multivektor-Einbettungen
Einzelne Einbettungen sind gut für die Informationsabfrage, da sie in das grundlegende Framework einer indizierten Datenbank passen: Wir speichern Objekte für die Abfrage mit einem einzelnen Einbettungsvektor als deren Abfrageschlüssel. Wenn Nutzer den Dokumentenspeicher abfragen, werden ihre Abfragen in Einbettungsvektoren übersetzt und die Dokumente, deren Schlüssel der Abfrage-Einbettung am nächsten sind (im hochdimensionalen Einbettungsraum), werden als Kandidatenmatches abgerufen.
Multivektor-Einbettungen funktionieren etwas anders. Anstatt einen Vektor mit fester Länge zu erzeugen, um eine Abfrage und ein ganzes gespeichertes Objekt darzustellen, erzeugen sie eine Folge von Einbettungen, die kleinere Teile davon repräsentieren. Die einzelnen Teile sind typischerweise Tokens oder Wörter für Texte und Bildkacheln für visuelle Daten. Diese Einbettungen spiegeln die Bedeutung des Teils in seinem Kontext wider.
Betrachten wir zum Beispiel die folgenden Sätze:
- Sie hatte ein Herz aus Gold.
- Sie hatte einen Herzenswandel.
- Sie hatte einen Herzinfarkt.
Oberflächlich betrachtet sehen sie sehr ähnlich aus, aber ein Multivektor-Modell würde wahrscheinlich sehr unterschiedliche Einbettungen für jede Instanz von „Herz“ generieren, was darstellt, wie jede im Kontext des gesamten Satzes etwas anderes bedeutet:
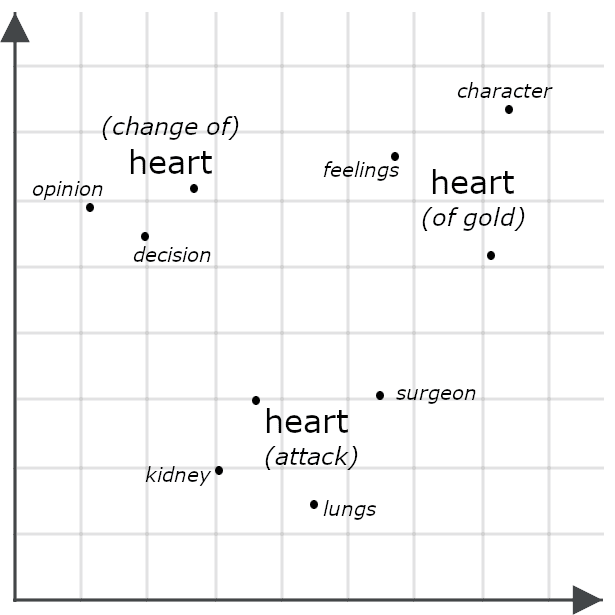
Der Vergleich zweier Objekte anhand ihrer Multivektor-Einbettungen beinhaltet oft die Messung ihres Chamfer-Abstands: der Vergleich jedes Teils einer Multivektor-Einbettung mit jedem Teil einer anderen und die Summierung der minimalen Abstände zwischen ihnen. Andere Systeme, einschließlich des unten beschriebenen Jina Rerankers, geben sie in ein KI-Modell ein, das speziell für die Bewertung ihrer Ähnlichkeit trainiert wurde. Beide Ansätze haben in der Regel eine höhere Präzision als der Vergleich von Einzeleinbettungen, da Einbettungen mit mehreren Vektoren viel detailliertere Informationen enthalten als solche mit einem Vektor.
Allerdings eignen sich Multivektor-Einbettungen nicht gut zum Indexieren. Sie werden häufig bei Neubewertungsaufgaben verwendet, wie im nächsten Abschnitt für das Modell jina-colbert-v2 beschrieben.
Jina-Einbettungsmodelle
Jina-Einbettungen – v4
jina-embeddings-v4 ist ein 3,8 Milliarden (3,8x10⁹) Parameter umfassendes mehrsprachiges und multimodales Einbettungsmodell, das Bilder und Texte in einer Vielzahl weit verbreiteter Sprachen unterstützt. Es verwendet eine neuartige Architektur, um visuelle Kenntnisse und Sprachkenntnisse zu nutzen, um die Leistung bei beiden Aufgaben zu verbessern, sodass es beim Abrufen von Bildern und insbesondere beim visuellen Abrufen von Dokumenten hervorragende Leistungen erbringt. Das bedeutet, dass es Bilder wie Diagramme, Dias, Karten, Screenshots, Seitenscans und Diagramme verarbeitet – gängige Bildtypen, oft mit wichtigem eingebettetem Text, die außerhalb des Bereichs von Computer-Vision-Modellen fallen, die auf Bildern realer Szenen trainiert sind.
Wir haben dieses Modell mithilfe kompakter Low-Rank Adaptation (LoRA)-Adapter für verschiedene Aufgaben optimiert. Dadurch können wir ein einzelnes Modell trainieren, um sich auf mehrere Aufgaben zu spezialisieren, ohne bei einer davon die Leistung zu beeinträchtigen – mit minimalen zusätzlichen Kosten für Speicher oder Verarbeitung.
Zu den wichtigsten Funktionen gehören:
- Spitzenleistung beim visuellen Dokumentenabruf sowie eine mehrsprachige Text- und Bildverarbeitungsleistung, die deutlich größere Modelle übertrifft.
- Unterstützung für große Eingabekontextgrößen: 32.768 Tokens entsprechen ungefähr 80 Seiten doppeltzeiligem englischen Text, und 20 Megapixel entsprechen einem Bild von 4.500 x 4.500 Pixeln.
- Vom Nutzer ausgewählte Einbettungsgrößen, von maximal 2048 Dimensionen bis zu 128 Dimensionen. Wir haben empirisch festgestellt, dass die Leistung unterhalb dieser Schwelle dramatisch abnimmt.
- Unterstützung für sowohl einzelne Einbettungen als auch Multivektor-Einbettungen. Für Texte besteht die Multivektor-Ausgabe aus einer 128-dimensionalen Einbettung für jedes Eingabetoken. Für Bilder erzeugt es eine 128-dimensionale Einbettung für jede 28x28 Pixel große Kachel, die zur Abdeckung des Bildes benötigt wird.
- Optimierung für asymmetrischen Datenabruf mittels eines Paares von LoRA-Adaptern, die speziell für diesen Zweck trainiert wurden.
- Ein LoRA-Adapter, optimiert für die Berechnung semantischer Ähnlichkeit.
- Spezielle Unterstützung für Programmiersprachen und IT-Frameworks, ebenfalls über einen LoRA-Adapter.
Wir haben jina-embeddings-v4 als allgemeines Mehrzweckwerkzeug für eine breite Palette gängiger Such-, Sprachverarbeitungs- und KI-Analyseaufgaben entwickelt. Es handelt sich im Verhältnis zu seinen Fähigkeiten um ein relativ kleines Modell, dessen Bereitstellung jedoch erhebliche Ressourcen erfordert und das sich am besten für die Nutzung über eine Cloud-API oder in einer Umgebung mit hohem Datenaufkommen eignet.
Jina-Einbettungen – v3
jina-embeddings-v3 ist ein kompaktes, leistungsstarkes, mehrsprachiges, ausschließlich textbasiertes Einbettungsmodell mit weniger als 600 Millionen Parametern. Es unterstützt bis zu 8192 Texteingabetoken und liefert Einzelvektor-Einbettungen mit vom Nutzer gewählten Größen von einem Standard von 1024 Dimensionen bis zu 64 als Ausgabe.
Wir haben jina-embeddings-v3 für eine Vielzahl von Textaufgaben trainiert – nicht nur für den Informationsabruf und die semantische Ähnlichkeit, sondern auch für Klassifikationsaufgaben wie die Sentiment-Analyse und Inhaltsmoderation sowie für Clustering-Aufgaben wie die Nachrichtenaggregation und -empfehlung. Wie jina-embeddings-v4 bietet auch dieses Modell LoRA-Adapter, die auf die folgenden Nutzungskategorien spezialisiert sind:
- Asymmetrischer Informationsabruf
- Semantische Ähnlichkeit
- Klassifizierung
- Clustering
jina-embeddings-v3 ist ein deutlich kleineres Modell als jina-embeddings-v4 mit einer deutlich reduzierten Eingabekontextgröße, aber es ist günstiger in der Nutzung. Dennoch bietet es eine sehr wettbewerbsfähige Leistung, wenn auch nur für Texte, und ist für viele Anwendungsfälle eine bessere Wahl.
Jina Code-Einbettungen
Die spezialisierten Code-Einbettungsmodelle von Jina – jina-code-embeddings (0.5b und 1.5b) – unterstützen 15 Programmierschemata und Frameworks sowie englischsprachige Texte aus dem Bereich Informatik und Informationstechnologie. Es handelt sich um kompakte Modelle mit einer halben Milliarde (0,5x10⁹) bzw. eineinhalb Milliarden (1,5x10⁹) Parametern. Beide Modelle unterstützen Eingabekontextgrößen von bis zu 32.768 Token und ermöglichen es den Nutzern, ihre Ausgabe-Einbettungsgrößen auszuwählen, von 896 bis 64 Dimensionen für das kleinere Modell und 1536 bis 128 für das größere.
Diese Modelle unterstützen asymmetrische Abrufe für fünf aufgabenspezifische Spezialisierungen, wobei Präfixabstimmung statt LoRA-Adapter verwendet wird:
- Code zu Code. Ähnlichen Code in verschiedenen Programmiersprachen abrufen. Dies wird für die Code-Ausrichtung, Code-Deduplizierung sowie die Unterstützung von Portierung und Refactoring verwendet.
- Natürliche Sprache zu Code. Abrufen von Code, um Abfragen, Kommentare, Beschreibungen und Dokumentation in natürlicher Sprache abzugleichen.
- Code zu natürlicher Sprache. Vergleichen des Codes mit der Dokumentation oder anderen Texten in natürlicher Sprache.
- Code-zu-Code-Vervollständigung. Vorschlag von relevantem Code, um bestehenden Code zu ergänzen oder zu verbessern.
- Technische Fragen und Antworten. Identifizierung von Antworten in natürlicher Sprache auf Fragen zu Informationstechnologien, ideal geeignet für Anwendungsfälle im technischen Support.
Diese Modelle bieten eine überlegene Leistung für Aufgaben, die Computerdokumentation und Programmiermaterialien erfordern, bei relativ geringen Rechenkosten. Sie eignen sich hervorragend für die Integration in Entwicklungsumgebungen und Code-Assistenten.
Jina ColBERT v2
jina-colbert-v2 ist ein Multivektor-Texteinbettungsmodell mit 560 Millionen Parametern. Es ist mehrsprachig, mit Materialien in 89 Sprachen trainiert und unterstützt variable Einbettungsgrößen sowie asymmetrischen Informationsabruf.
Wie bereits erwähnt, sind Multivektor-Einbettungen schlecht für das Indexieren geeignet, aber sehr nützlich, um die Genauigkeit von Ergebnissen anderer Suchstrategien zu erhöhen. Mit jina-colbert-v2können Sie Multivektor-Einbettungen im Voraus berechnen und sie dann verwenden, um Abrufkandidaten zur Abfragezeit neu zu ordnen. Dieser Ansatz ist weniger präzise als die Verwendung eines der Reranking-Modelle im nächsten Abschnitt, aber viel effizienter, da er nur den Vergleich gespeicherter Multivektor-Einbettungen beinhaltet, anstatt das gesamte KI-Modell für jede Abfrage und jedes Kandidatenmatch aufzurufen. Es eignet sich ideal für Anwendungsfälle, in denen die Latenz und der Rechenaufwand durch die Nutzung von Reranking-Modellen zu groß sind oder die Anzahl der Kandidaten zum Vergleich zu groß für das Reranking von Modellen ist.
Dieses Modell gibt eine Folge von Einbettungen aus – eine pro Eingabetoken – und Nutzer können Token-Einbettungen aus 128-, 96- oder 64-dimensionalen Einbettungen auswählen. Kandidaten-Textmatches sind auf 8.192 Token begrenzt. Abfragen werden asymmetrisch kodiert, daher müssen Nutzer angeben, ob ein Text eine Abfrage oder ein Kandidatenmatch ist, und die Abfragen auf 32 Token begrenzen.
Jina CLIP v2
jina-clip-v2 ist ein multimodales Einbettungsmodell mit 900 Millionen Parametern, das so trainiert wurde, dass Texte und Bilder Einbettungen erzeugen, die nahe beieinander liegen, wenn der Text den Inhalt des Bildes beschreibt. Es dient in erster Linie zum Abrufen von Bildern auf der Grundlage von Textabfragen, ist aber auch ein leistungsstarkes reines Textmodell, das die Nutzerkosten senkt, da Sie keine separaten Modelle für Text-zu-Text- und Text-zu-Bild-Abfragen benötigen.
Dieses Modell unterstützt einen Texteingabekontext von 8.192 Tokens, und Bilder werden vor der Einbettung auf 512x512 Pixel skaliert.
CLIP-Architekturen („Contrastive Language-Image Pretraining“) sind einfach zu trainieren und zu bedienen und können sehr kompakte Modelle erzeugen, aber sie haben einige grundlegende Einschränkungen. Sie können ihr Wissen aus einem Medium nicht nutzen, um ihre Leistung in einem anderen zu verbessern. Sie können nicht ein Medium nutzen, um ihre Leistung in einem anderen zu verbessern. Obwohl das System also wissen mag, dass die Wörter „dog“ und „cat“ in ihrer Bedeutung näher beieinander liegen als jedes von ihnen bei „car“, weiß es nicht unbedingt, dass ein Bild von einem Hund und ein Bild von einer Katze enger miteinander verwandt sind als jedes von ihnen bei einem Bild von einem Auto.
Sie leiden auch unter der sogenannten Modalitätslücke: Die Einbettung eines Textes über Hunde ist wahrscheinlich näher an der Einbettung eines Textes über Katzen als an der Einbettung eines Bildes von Hunden. Aufgrund dieser Einschränkung empfehlen wir, CLIP entweder als Text-zu-Bild-Abfragemodell oder als reines Textmodell zu verwenden, jedoch nicht beide in einer einzigen Abfrage zu vermischen.
Reranking-Modelle
Reranking-Modelle nehmen ein oder mehrere Kandidatenmatches zusammen mit einer Abfrage als Eingabe für das Modell und vergleichen sie direkt, wodurch deutlich präzisere Übereinstimmungen entstehen.
Grundsätzlich könnte man einen Reranker direkt für die Informationsabfrage verwenden, indem man jede Abfrage mit jedem gespeicherten Dokument vergleicht, dies wäre jedoch sehr rechenintensiv und für alle außer den kleinsten Sammlungen unpraktisch. Daher werden Reranker tendenziell zur Bewertung relativ kurzer Listen von Kandidatenmatches verwendet, die mit anderen Mitteln gefunden wurden, wie z. B. durch einbettungsbasierte Suche oder andere Algorithmen für den Informationsabruf. Reranking-Modelle eignen sich ideal für hybride und föderierte Suchverfahren, bei denen eine Suche bedeuten kann, dass Anfragen an separate Suchsysteme mit unterschiedlichen Datensätzen gesendet werden, die jeweils unterschiedliche Ergebnisse liefern. Sie sind sehr gut darin, vielfältige Ergebnisse zu einem einzigen, hochwertigen Ergebnis zu vereinen.
Die auf Einbettungen basierende Suche kann eine große Herausforderung darstellen, da sie eine Neuindizierung aller gespeicherten Daten erfordert und die Erwartungen der Nutzer an die Ergebnisse verändert. Wenn Sie einen Reranker zu einem bestehenden Suchschema hinzufügen, können Sie viele der Vorteile von KI nutzen, ohne Ihre gesamte Suchlösung neu zu entwickeln.
Jina-Reranker-Modelle
Jina Reranker m0
jina-reranker-m0 ist ein multimodaler Reranker mit 2,4 Milliarden (2,4x10⁹) Parametern, der Textanfragen und Kandidatenmatches aus Texten und/oder Bildern unterstützt. Es ist das führende Modell für die visuelle Dokumentensuche und somit eine ideale Lösung für Sammlungen von PDFs, Scans von Texten, Screenshots und anderen computergenerierten oder modifizierten Bildern, die Text oder andere semistrukturierte Informationen enthalten, sowie für gemischte Daten, die aus Textdokumenten und Bildern bestehen.
Dieses Modell nimmt eine einzelne Abfrage und einen Kandidatenmatch entgegen und gibt einen Score zurück. Wenn dieselbe Abfrage mit verschiedenen Kandidaten verwendet wird, sind die Scores vergleichbar und können zur Rangfolge herangezogen werden. Es unterstützt eine gesamte Eingabegröße von bis zu 10.240 Tokens, einschließlich des Anfragetextes und des Kandidatentextes oder -bildes. Jede 28x28 Pixel große Kachel, die zum Abdecken eines Bildes benötigt wird, zählt als Token zur Berechnung der Eingabegröße.
Jina Reranker v3
jina-reranker-v3 ist ein Text-Reranker mit 600 Millionen Parametern und modernster Leistung für Modelle vergleichbarer Größe. Im Gegensatz zu jina-reranker-m0 nimmt er eine einzelne Abfrage und eine Liste von bis zu 64 Kandidatenübereinstimmungen und gibt die Rangfolge zurück. Es hat einen Eingabekontext von 131.000 Token, einschließlich der Abfrage und aller Textkandidaten.
Jina Reranker v2
jina-reranker-v2-base-multilingual ist ein äußerst kompakter, universeller Reranker mit zusätzlichen Features, die Funktionsaufrufe und SQL-Abfragen unterstützen. Mit weniger als 300 Millionen Parametern bietet er ein schnelles, effizientes und genaues mehrsprachiges Text-Reranking mit zusätzlicher Unterstützung für die Auswahl von SQL-Tabellen und externen Funktionen, die Textabfragen entsprechen, wodurch es sich für agentenbasierte Anwendungsfälle eignet.
Kleine generative Sprachmodelle
Generative Sprachmodelle sind Modelle wie ChatGPT von OpenAI, Google Gemini und Claude von Anthropic, die Text- oder Multimedia-Eingaben aufnehmen und mit Textausgaben antworten. Es gibt keine klar definierte Grenze, die große Sprachmodelle (LLMs) von kleinen Sprachmodellen (SLMs) unterscheidet, aber die praktischen Probleme bei der Entwicklung, dem Betrieb und der Nutzung von Top-LLMs sind wohlbekannt. Die bekanntesten werden nicht öffentlich verbreitet, daher können wir ihre Größe nur schätzen, aber es wird erwartet, dass ChatGPT, Gemini und Claude im Bereich von 1 bis 3 Billionen (1–3x10¹²) Parametern liegen.
Das Ausführen dieser Modelle – selbst wenn sie öffentlich verfügbar sind – geht weit über den Umfang herkömmlicher Hardware hinaus und erfordert die fortschrittlichsten Chips, die in riesigen parallelen Arrays angeordnet sind. Der Zugriff auf LLMs ist über kostenpflichtige APIs möglich, dies verursacht jedoch erhebliche Kosten, führt zu einer hohen Latenz und lässt sich nur schwer mit den Anforderungen an Datenschutz, digitale Souveränität und Cloud-Repatriierung vereinbaren. Außerdem können die Kosten für das Training und die Anpassung von Modellen dieser Größe beträchtlich sein.
Aus diesem Grund wurde viel Forschung in die Entwicklung kleinerer Modelle gesteckt, die vielleicht nicht alle Fähigkeiten der größten LLMs haben, aber bestimmte Aufgaben genauso gut erledigen können, und das zu geringeren Kosten. Unternehmen setzen Software in der Regel ein, um spezifische Probleme zu lösen, und KI-Software bildet da keine Ausnahme. Daher sind SLM-basierte Lösungen oft LLM-basierten Lösungen vorzuziehen. Sie können üblicherweise auf Standardhardware laufen, sind schneller, verbrauchen weniger Energie und lassen sich viel leichter anpassen.
Das SLM-Angebot von Jina wächst, da wir uns darauf konzentrieren, wie wir KI am besten in praktische Suchlösungen integrieren können.
Jina SLMs
ReaderLM v2
ReaderLM-v2 ist ein generatives Sprachmodell, das HTML gemäß benutzerdefinierten JSON-Schemata und natürlichen Sprachanweisungen in Markdown oder JSON umwandelt.
Datenvorverarbeitung und -normalisierung sind ein wesentlicher Bestandteil der Entwicklung guter Suchlösungen für digitale Daten, aber reale Daten, insbesondere webbasierte Informationen, sind oft chaotisch, und einfache Umwandlungsstrategien erweisen sich häufig als sehr zerbrechlich. Stattdessen bietet ReaderLM-v2 eine intelligente KI-Modelllösung, die das Chaos eines DOM-Tree-Dumps einer Webseite verstehen und nützliche Elemente robust identifizieren kann.
Mit 1,5 Milliarden (1,5x10⁹) Parametern ist es drei Größenordnungen kompakter als modernste LLMs, leistet aber bei dieser einen engen Aufgabe auf Augenhöhe.
Jina VLM
jina-vlm ist ein generatives Sprachmodell mit 2,4 Milliarden (2,4x10⁹) Parametern, das darauf trainiert wurde, natürlichsprachliche Fragen zu Bildern zu beantworten. Es bietet eine sehr starke Unterstützung für die visuelle Dokumentenanalyse, d. h. für die Beantwortung von Fragen zu Scans, Screenshots, Folien, Diagrammen und ähnlichen nicht natürlichen Bilddaten.
Zum Beispiel:

Es ist auch sehr gut darin, Text in Bildern zu lesen:

.jpg){kind=link}
{kind=link}
Die wahre Stärke von jina-vlm liegt jedoch im Verständnis des Inhalts von informativen und von Menschen erstellten Bildern:

Bild: Wikimedia Commons.
{kind=link}
Oder:

Bild: Wikimedia Commons.
.png){kind=link}
jina-vlm ist gut geeignet für die automatische Generierung von Bildunterschriften, Produktbeschreibungen, Alternativtexten für Bilder und Barrierefreiheitsanwendungen für Sehbehinderte. Es schafft zudem Möglichkeiten für RAG-Systeme („Retrieval-Augmented-Generation“), visuelle Informationen zu verwenden, und für KI-Agenten, Bilder ohne menschliche Unterstützung zu verarbeiten.
Zugehörige Inhalte

11. Mai 2026
Mehr Power für Elasticsearch: native Prometheus-API-Unterstützung hinzufügen
Elasticsearch kann direkt von Prometheus-kompatiblen Clients über native PromQL-, Discovery- und Metadaten-Endpunkte abgefragt werden. Senden Sie Daten an Elasticsearch mit Prometheus Remote Write.

11. Mai 2026
Ein Index, alle Medien: Einführung von Jina-Embeddings-v5-Omni
Mit jina-embeddings-v5-omni können Sie Text, Bilder, Videos und Audiodateien in einen einzigen Elasticsearch-Index einbetten und gleichzeitig abfragen.

22. April 2026
Jina-Einbettungen v3 sind jetzt im Model Garden der Gemini Enterprise Agent Platform verfügbar
Das Search Foundation Model in Jina, „jina-embeddings-v3“, kann nun eigenständig im Model Garden der Gemini Enterprise Agent Platform bereitgestellt werden und wird bald um weitere Modelle ergänzt. Führen Sie „jina-embeddings-v3“ auf einer einzelnen L4-GPU in Ihrer eigenen VPC aus.

23. März 2026
Die Verwendung der Elasticsearch Inference API zusammen mit Hugging Face-Modellen
Erfahren Sie, wie Sie Elasticsearch mithilfe von Inferenz-Endpoints mit Hugging Face Modellen verbinden und ein mehrsprachiges Blog-Empfehlungssystem mit semantischer Suche und Chat-Abschlüssen erstellen.

27. März 2026
Erstellung eines Elasticsearch MCP-Servers mit TypeScript
Erfahren Sie, wie Sie mit TypeScript und Claude Desktop einen Elasticsearch MCP-Server erstellen.