Jina AI et Elastic lancent jina-embeddings-v5-text, une famille de modèles d’embeddings textuels compacts et hautes performances, offrant des performances de pointe pour des modèles de taille comparable sur l’ensemble des principaux types de tâches.
La famille comprend deux modèles :
jina-embeddings-v5-text-smalljina-embeddings-v5-text-nano
Ces modèles sont le fruit d’une nouvelle méthode d’entraînement innovante pour les modèles d’embeddings. Tous deux surpassent des modèles bien plus volumineux, tout en réduisant les besoins en mémoire et en ressources de calcul, et en accélérant les temps de réponse.
Le modèle jina-embeddings-v5-text-small compte 677 millions de paramètres, prend en charge une fenêtre de contexte d’entrée de 32 768 tokens et génère par défaut des embeddings de 1 024 dimensions.
jina-embeddings-v5-text-nano pèse environ un tiers de la taille de son homologue, avec 239 millions de paramètres et une fenêtre de contexte d’entrée de 8 192 tokens, offrant des embeddings de 768 dimensions.
| Nom du modèle | Taille totale | Taille de la fenêtre contextuelle d'entrée | Taille des embeddings |
|---|---|---|---|
| jina-v5-text-small | 677M paramètres | 32 768 tokens | 1 024 dimensions |
| jina-v5-text-nano | 239M paramètres | 8 192 tokens | 768 dimensions |
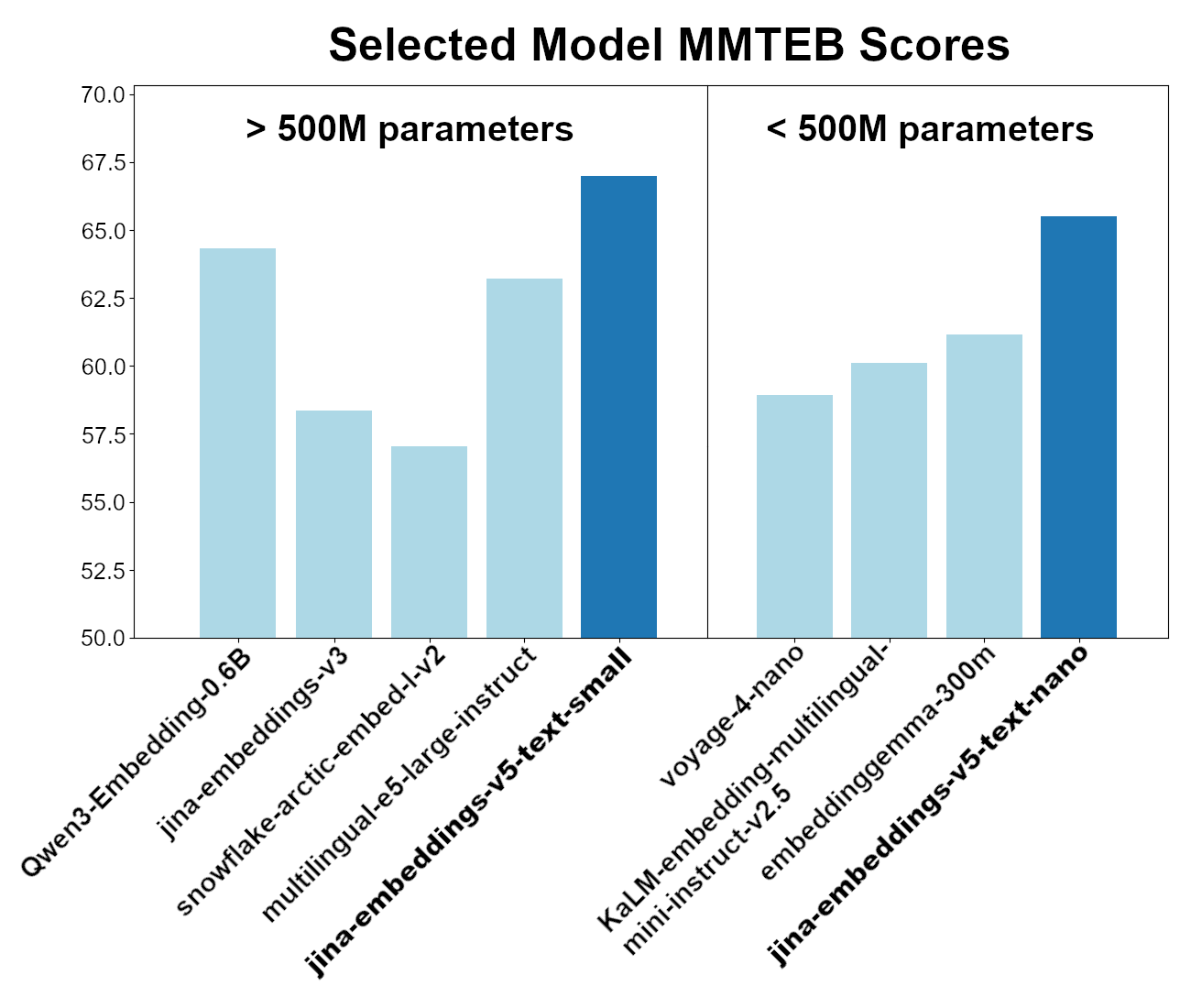
Ces deux modèles se classent parmi les meilleurs pour les performances globales au benchmark MTEB (Massive Text Embedding Benchmark) et au benchmark multilingue MTEB. Parmi les modèles ayant moins de 500 millions de paramètres, jina-embeddings-v5-text-nano est le plus performant, malgré moins de 250 millions de paramètres, et jina-embeddings-v5-text-small est le leader parmi les modèles d’embeddings multilingues de moins de 750 millions de paramètres.
Ces modèles sont disponibles via Elastic Inference Service (EIS), via une API en ligne, et peuvent également être déployés en local. Pour savoir comment accéder aux modèles jina-embeddings-v5-text, consultez la section « Commencer » ci-dessous.
Les modèles d’embeddings et l’indexation sémantique améliorent considérablement la précision des algorithmes de recherche, tout en répondant à de nombreux autres cas d’usage liés à la similarité sémantique et à l’extraction de sens, par exemple :
- Détection de textes en double.
- Reconnaissance des paraphrases et des traductions.
- Découverte de thématiques.
- Moteurs de recommandation.
- Analyse des sentiments et des intentions.
- Filtrage des spams.
- Et bien d'autres encore.
Fonctionnalités
Cette nouvelle famille de modèles propose un ensemble de fonctionnalités conçues pour améliorer la pertinence et réduire les coûts.
Optimisation des tâches
Nous avons optimisé les modèles jina-embeddings-v5-text pour quatre grands types de tâches :
| Tâche | Exemples de cas d'utilisation |
|---|---|
| Récupération | Recherche à l’aide de requêtes en langage naturel et récupération des correspondances les plus pertinentes au sein d’une collection de documents. |
| Correspondance de texte | Similarité sémantique, déduplication, alignement des paraphrases et des traductions, et plus encore. |
| Clustering | Découverte de thématiques, organisation automatique de collections de documents. |
| Classification | Catégorisation de documents, analyse des sentiments et détection des intentions, tâches similaires. |
Optimiser un modèle pour une tâche implique généralement de faire des compromis sur une autre. La plupart des modèles d’embeddings n’offrent donc des performances compétitives que pour un seul type de tâche. En revanche, les modèles jina-embeddings-v5-text peuvent se spécialiser dans les quatre catégories sans compromettre l’entraînement, grâce à des adaptateurs Low-Rank Adaptation (LoRA) spécifiques à chaque tâche.
Les adaptateurs LoRA sont une sorte de plugin pour un modèle d’IA, qui en modifie fortement le comportement tout en n’augmentant que légèrement sa taille totale. Au lieu d’avoir un modèle distinct pour chaque tâche, chacun comportant des centaines de millions de paramètres, la famille de modèles jina-embeddings-v5-text vous permet d’utiliser un seul modèle, associé à un adaptateur LoRA compact pour chaque tâche. Cela permet d’économiser de la mémoire, de l’espace de stockage et de réduire les coûts d’inférence.
Troncature des embeddings
Nous avons entraîné les modèles jina-embeddings-v5-text avec Matryoshka Representation Learning (MRL), ce qui vous permet de réduire la taille de vos embeddings tout en limitant l’impact sur leur qualité.
Par défaut, jina-embeddings-v5-text-small génère des vecteurs d’embeddings de 1 024 dimensions, chaque valeur étant représentée sur 16 bits, ce qui porte la taille de chaque embedding à 2 Ko. Pour une vaste collection de documents, cela peut représenter un volume de données important à stocker. La recherche dans une base de données vectorielle remplie d’embeddings est proportionnelle à la taille de la base et au nombre de dimensions de chaque vecteur stocké.
Vous pouvez toutefois réduire de moitié la taille des embeddings (en supprimant 512 des 1 024 dimensions), diminuer l’espace occupé de moitié et doubler la vitesse de recherche. Cela a un impact sur les performances. Supprimer des informations réduit la précision. Mais comme le montre le graphique ci-dessous, supprimer la moitié de l’embedding n’entraîne qu’une légère baisse des performances :
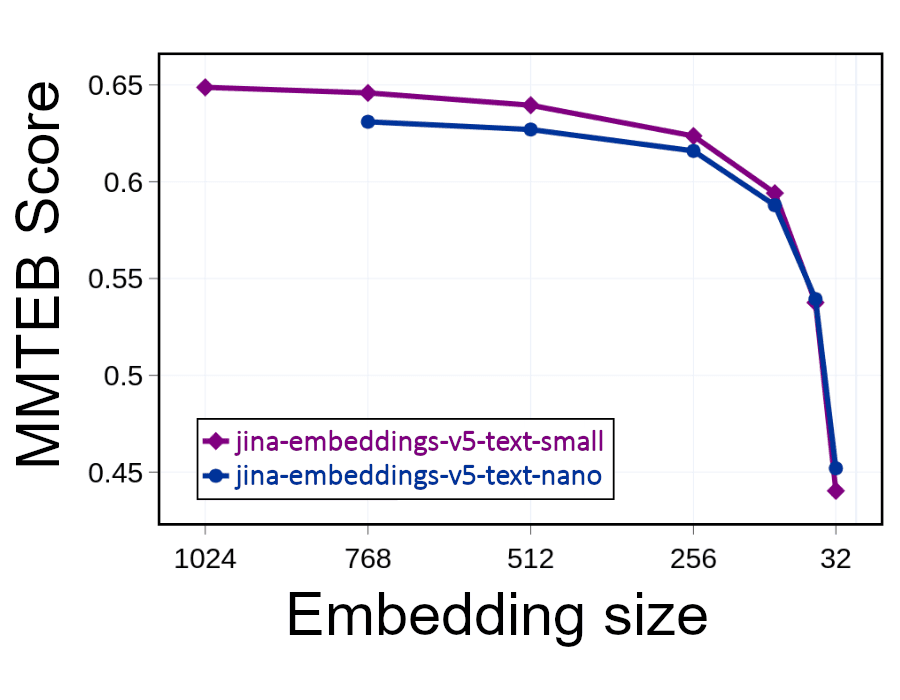
Tant que vos embeddings comportent au moins 256 dimensions, la perte de précision devrait rester relativement faible. En dessous de ce seuil, en revanche, la pertinence et la précision se dégradent rapidement.
La troncature des embeddings de cette manière vous permet de gérer vos arbitrages entre précision et coûts de calcul. Vous disposez ainsi des leviers nécessaires pour obtenir des gains d’efficacité significatifs et réduire sensiblement les coûts de votre Search AI.
Quantification robuste
La quantification constitue une autre méthode pour réduire la taille des embeddings. Au lieu de supprimer une partie de chaque embedding, la quantification diminue la précision des valeurs numériques qui le composent. Les modèles jina-embeddings-v5-text génèrent des embeddings avec des valeurs sur 16 bits, mais nous pouvons arrondir ces valeurs, ce qui réduit leur précision ainsi que le nombre de bits nécessaires pour les stocker. Dans le cas le plus extrême, il est possible de ramener chaque valeur à un seul bit (0 ou 1), ce qui compresse les embeddings par défaut de 1 024 dimensions de jina-embeddings-v5-textde 2 kilooctets à 128 octets, soit une réduction de 94 % grâce à la seule quantification binaire. Comme pour la troncature, cela permet de réaliser d’importantes économies de mémoire et de ressources de calcul. Cependant, à l’instar de la troncature, la quantification réduit la précision des embeddings.
Nous avons entraîné les modèles jina-embeddings-v5-text pour fonctionner avec la Better Binary Quantization (BBQ) d’Elasticsearch, en minimisant la perte de précision. Les tests comparatifs des embeddings binarisés issus de ces modèles montrent des performances presque équivalentes à celles de leurs versions non binarisées. Consultez le rapport technique pour accéder à des études d’ablation détaillées sur les performances de la binarisation.
Performance multilingue
De nombreux modèles d’embeddings sont multilingues, car ils ont été entraînés sur des corpus couvrant un grand nombre de langues. Cela ne signifie pas pour autant qu’ils offrent des performances équivalentes dans toutes les langues prises en charge.
Nous avons identifié 211 langues dans le benchmark multilingue MTEB et les avons isolées afin de comparer nos modèles à des modèles similaires, langue par langue. L’image ci-dessous synthétise nos résultats sous la forme d’une carte thermique. Chaque zone correspond à une langue (identifiée par son code ISO-639) et plus la couleur est verte, meilleures sont les performances du modèle par rapport à la moyenne des modèles similaires :

Bien que la précision varie selon les langues, les modèles jina-embeddings-v5-text atteignent des performances de pointe, ou proches de l’état de l’art, dans la majorité des langues du monde.
Pour en savoir plus sur les performances multilingues, consultez le rapport techniquejina-embeddings-v5-text .
Jina in Elastic : une IA native de pointe pour la recherche
Avec les modèles jina-embeddings-v5-text sur EIS, vous exécutez des modèles d’embeddings multilingues hautes performances de manière native dans Elasticsearch, avec une inférence entièrement gérée, accélérée par GPU, et sans infrastructure à provisionner ni à faire évoluer. Les modèles jina-embeddings-v5-text enrichissent le catalogue de modèles EIS en proposant des modèles multilingues compacts, tirant parti des dernières avancées en matière d’IA. Ces modèles affichent des performances de pointe sur les benchmarks de recherche d’information et d’analyse de données standard, tout en offrant une prise en charge multilingue inégalée à l’échelle mondiale.
Avec deux modèles de tailles très différentes, vous pouvez déterminer celui qui convient le mieux à vos applications et à votre budget. De plus, grâce à des embeddings robustes qui restent performants lorsqu’ils sont tronqués à des tailles plus réduites ou quantifiés avec une précision moindre, les modèles jina-embeddings-v5-text offrent des opportunités supplémentaires d’économies concrètes en matière de stockage, de coûts de calcul et de latence de traitement.
Avec la famille jina-embeddings-v5-text, Jina Reranker et la recherche vectorielle rapide et BM25 d’Elastic, vous bénéficiez désormais d’une recherche hybride de bout en bout, de pointe, proposée par Elastic. Lorsque vous avez besoin des résultats les plus pertinents, que ce soit pour des pipelines de génération augmentée par récupération (RAG), des applications de recherche ou des analyses de données, Elastic associé aux modèles Search AI de Jina vous garantit une qualité robuste et un excellent rapport coût-efficacité.
Premiers pas
Les modèles jina-embeddings-v5-text sont entièrement intégrés dans EIS, et vous pouvez les utiliser en définissant le champ typesur semantic_text lors de la création de votre index et en spécifiant le modèle (jina-embeddings-v5-text-small ou jina-embeddings-v5-text-nano) dans le champ inference_id, comme dans cet exemple :
Elasticsearch sélectionne automatiquement l’adaptateur LoRA approprié lors de l’indexation et de la recherche. Les dimensions de l'intégration (voir la section « Troncature des intégrations » ci-dessus) peuvent être définies lors de la création d'un point de terminaison d'inférence personnalisé.
Consultez la documentation Elasticsearch pour plus d'informations sur l'utilisation des modèles jina-embeddings-v5-text .
Plus d'informations
Pour en savoir plus sur les modèles jina-embeddings-v5-text, lisez les notes de publication sur le blog de Jina AI et le rapport technique, qui contiennent des informations techniques détaillées sur les performances et la nouvelle procédure de formation innovante de Jina AI. Pour plus d'informations sur le téléchargement et l'exécution de ces modèles localement, consultez la jina-embeddings-v5-text page de la collection sur Hugging Face.
Les modèles Jina AI sont disponibles sous licence CC-BY-NC-4.0, vous êtes donc libre de les télécharger et de les essayer, mais pour un usage commercial, veuillez contacter les ventes d’Elastic.
Pour aller plus loin

11 mai 2026
Un seul index, tous les médias : présentation de jina-embeddings-v5-omni
jina-embeddings-v5-omni vous permet d’intégrer du texte, des images, des vidéos et de l’audio dans un seul index Elasticsearch, et d’effectuer des requêtes sur tous ces éléments à la fois.

22 avril 2026
Jina Embeddings v3 désormais disponible via Model Garden sur Gemini Enterprise Agent Platform
Le modèle de fondation de recherche Jina, jina-embeddings-v3, est désormais déployable automatiquement via Model Garden sur Gemini Enterprise Agent Platform ; d’autres suivront. Exécutez jina-embeddings-v3 sur un seul GPU L4 au sein de votre propre VPC.
1 janvier 2026
Présentation des modèles Jina, de leurs fonctionnalités et de leurs cas d’usage dans Elasticsearch
Explorez les embeddings multimodaux Jina, Reranker v3 et les modèles d'embedding sémantique, et découvrez comment les utiliser en mode natif dans Elasticsearch.

22 mai 2026
Kibana réduit le temps de chargement des tableaux de bord jusqu'à 25 %. Voici la stratégie d'interrogation qui se cache derrière
Découvrez comment Kibana utilise l'interrogation continue et la détection HTTP/2 côté navigateur pour réduire les temps de chargement des tableaux de bord jusqu'à 25 %, avec repli automatique sur HTTP/1.

Décrivez, ne dessinez pas : tableaux de bord Kibana IA natifs via MCP et ES|QL
Du prompt au tableau de bord. Apprenez à créer des tableaux de bord Kibana en langage naturel grâce à example-mcp-dashbuilder : une application MCP open source qui écrit des requêtes ES|QL, crée des graphiques interactifs et exporte des tableaux de bord entièrement fonctionnels directement vers Kibana.