Jina, développé par Elastic, propose des modèles fondamentaux pour la recherche, adaptés aux applications et à l’automatisation des processus métier. Ces modèles fournissent des fonctionnalités essentielles pour intégrer l’IA dans des applications Elasticsearch ou des projets d’IA innovants.
Les modèles Jina se répartissent en trois grandes catégories, conçues pour faciliter le traitement, l’organisation et la recherche d’informations :
- Modèles d’embedding sémantique
- Modèles de reclassification
- Petits modèles de langage génératif
Modèles d’embedding sémantique
L’idée derrière les embeddings sémantiques est qu’un modèle d’IA peut apprendre à représenter certains aspects du sens d’une entrée en s’appuyant sur la géométrie d’espaces à très grande dimension.
On peut considérer un embedding sémantique comme un point (techniquement un vecteur) dans un espace à plusieurs dimensions. Un modèle d’embedding est un réseau de neurones qui reçoit des données numériques en entrée (souvent du texte ou une image) et renvoie l’emplacement du point correspondant dans un espace multidimensionnel, sous forme de coordonnées numériques. Si le modèle est efficace, la distance entre deux embeddings sémantiques est proportionnelle à la similarité de sens des objets correspondants.
Pour comprendre l’intérêt de cette approche dans les applications de recherche, imaginez les embeddings des mots « chien » et « chat » comme des points dans l’espace :
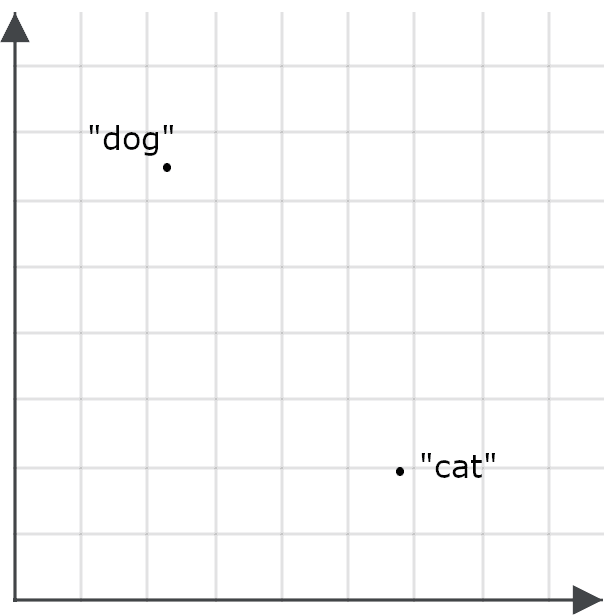
Un bon modèle d’embedding générera une représentation du mot « félin » bien plus proche de « chat » que de « chien », tandis que « canidé » sera plus proche de « chien » que de « chat », car ces mots partagent un sens très proche :

Si un modèle est multilingue, nous nous attendrions à la même chose pour les traductions de « chat » et « chien » :

Les modèles d’embedding traduisent la similarité ou la différence de sens entre des éléments en relations spatiales entre leurs représentations vectorielles. Les illustrations ci-dessus sont en deux dimensions pour faciliter la visualisation, mais les modèles d’embedding produisent des vecteurs comportant des dizaines, voire des milliers de dimensions. Cela leur permet de capturer les subtilités du sens dans des textes entiers, en leur associant un point dans un espace comportant des centaines, voire des milliers de dimensions, pour des documents pouvant contenir des milliers de mots.
Embeddings multimodaux
Les modèles multimodaux étendent le principe des embeddings sémantiques à d’autres types de contenu que le texte – notamment les images. On s’attend donc à ce qu’un embedding d’image soit proche de celui d’une description fidèle de cette image :
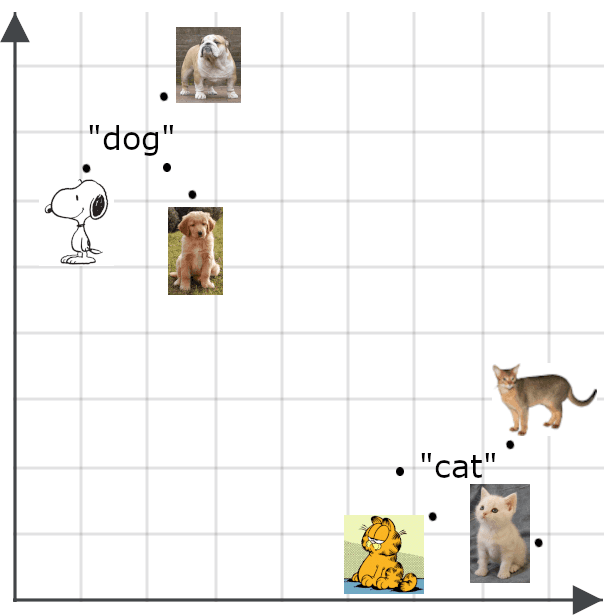
Les embeddings sémantiques offrent de nombreux cas d’usage. Ils peuvent notamment servir à créer des classificateurs efficaces, à regrouper les données (data clustering), ou encore à effectuer des tâches comme la déduplication ou l’analyse de la diversité des données – des fonctionnalités clés dans les environnements big data où les volumes à traiter sont trop importants pour être gérés manuellement.
L’usage principal des embeddings concerne la recherche d’informations. Elasticsearch peut stocker des objets de récupération avec des embeddings comme clés. Les requêtes sont converties en vecteurs d’embedding, et une recherche renvoie les objets stockés dont les clés sont les plus proches du vecteur d’embedding de la requête.
Là où la recherche vectorielle traditionnelle (par vecteur unique ou vecteur clairsemé) utilise des vecteurs basés sur les mots ou les métadonnées dans les documents et les requêtes, la recherche par embeddings (ou vecteurs denses) utilise des significations évaluées par l’IA plutôt que des mots. Cela les rend en général plus flexibles et plus précis que les méthodes de recherche classiques.
Apprentissage par représentation de type matriochka
Le nombre de dimensions d’un embedding et la précision des valeurs qu’il contient ont un impact significatif sur les performances. Les espaces très dimensionnels et les nombres de très grande précision permettent de représenter des informations très complexes et détaillées, mais nécessitent des modèles d’IA plus coûteux à entraîner et à exécuter. Les vecteurs générés occupent également plus d’espace de stockage et nécessitent davantage de ressources de calcul pour mesurer les distances entre eux. L’utilisation de modèles d’embedding sémantique implique donc un compromis important entre précision et consommation de ressources.
Pour maximiser la flexibilité côté utilisateur, les modèles Jina sont entraînés avec une technique appelée Matryoshka Representation Learning. Cette méthode pousse le modèle à prioriser les distinctions sémantiques importantes dans les premières dimensions du vecteur, ce qui permet ensuite de tronquer les dimensions les plus élevées sans perte significative de performance.
Concrètement, cela signifie que les utilisateurs des modèles Jina peuvent choisir le nombre de dimensions qu’ils souhaitent attribuer à leurs embeddings. Réduire le nombre de dimensions entraîne une perte de précision, mais la dégradation des performances reste mineure. Pour la plupart des tâches, les performances des modèles Jina diminuent d’environ 1 à 2 % chaque fois que l’on réduit la taille des embeddings de 50 %, jusqu’à une réduction d’environ 95 %.
Récupération asymétrique
La similarité sémantique est généralement mesurée de façon symétrique. La valeur obtenue en comparant « chat » à « chien » est la même que celle obtenue en comparant « chien » à « chat ». Mais lorsqu’on utilise des embeddings pour la recherche d’informations, les résultats sont meilleurs si l’on casse cette symétrie et qu’on encode les requêtes différemment des objets à retrouver.
Cela tient à la façon dont les modèles d’embedding sont entraînés. Les données d’entraînement contiennent des éléments similaires, comme des mots, dans des contextes variés, et les modèles apprennent à en déduire le sens en comparant les similitudes et les différences contextuelles entre ces éléments.
Ainsi, il se peut par exemple que le mot « animal » apparaisse rarement dans les mêmes contextes que « chat » ou « chien », et que l’embedding du mot « animal » ne soit donc pas particulièrement proche de ceux de « chat » ou « chien ».
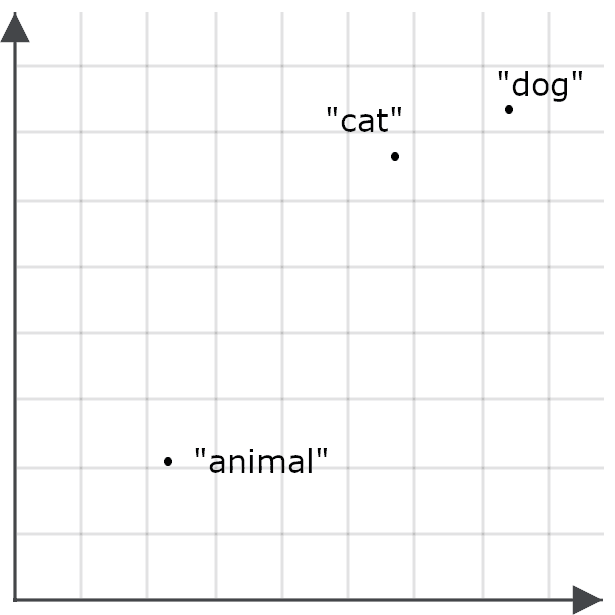
Cela réduit la probabilité qu’une requête sur le mot « animal » retourne des documents traitant de chats et de chiens — ce qui est précisément l’effet inverse de l’objectif recherché. On encode donc le mot « animal » différemment selon qu’il s’agit d’une requête ou d’un objet cible à retrouver :
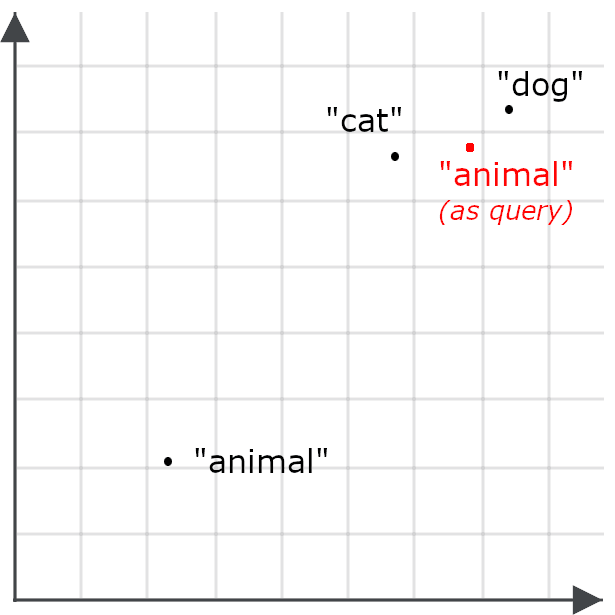
La recherche asymétrique consiste à utiliser un modèle différent pour les requêtes, ou à entraîner un modèle d’embedding de façon spécifique pour encoder différemment les éléments selon qu’ils sont stockés pour la recherche ou utilisés comme requêtes.
Embeddings multi-vecteurs
Les embeddings simples sont efficaces pour la recherche d’informations car ils s’intègrent bien au fonctionnement d’une base indexée : les objets à retrouver sont stockés avec un unique vecteur d’embedding utilisé comme clé de recherche. Lorsque les utilisateurs interrogent le magasin de documents, leurs requêtes sont converties en vecteurs d’embedding, et les documents dont la clé est la plus proche de celle de la requête (dans l’espace vectoriel de haute dimension) sont retournés comme correspondances candidates.
Les embeddings multi-vecteurs fonctionnent différemment. Au lieu de générer un vecteur de longueur fixe pour représenter une requête ou un objet stocké, ils produisent une séquence d’embeddings représentant des parties plus petites de ces éléments. Ces parties sont généralement des jetons ou mots pour les textes, ou des fragments d’image pour les données visuelles. Ces embeddings traduisent le sens de chaque élément dans son contexte.
Par exemple, prenons ces phrases:
- She had a heart of gold.
- She had a change of heart.
- She had a heart attack.
En apparence, ces phrases sont très similaires, mais un modèle multi-vecteur générerait probablement des embeddings très différents pour chaque occurrence du mot « heart », car son sens varie dans le contexte de chaque phrase:
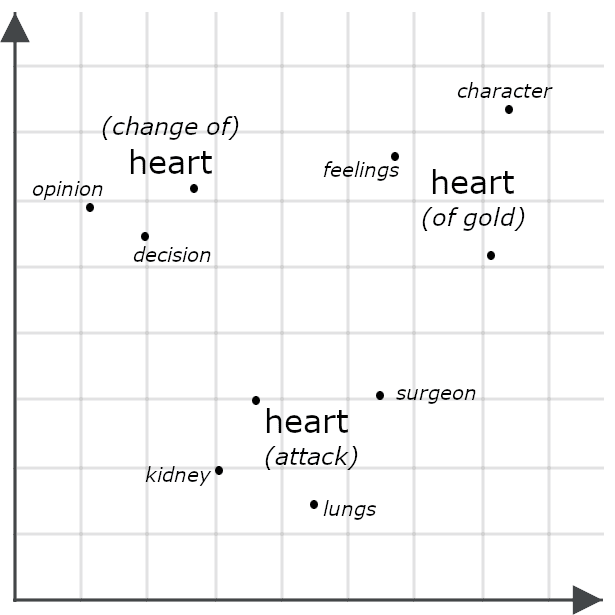
Comparer deux objets à l’aide de leurs embeddings multi-vecteurs revient souvent à calculer leur distance de Chamfer : on compare chaque élément d’un embedding avec ceux de l’autre, puis on additionne les distances minimales. D’autres systèmes, y compris les modules de reclassification Jina présentés plus bas, transmettent ces données à un modèle d’IA spécifiquement entraîné à évaluer leur similarité. Ces deux approches offrent généralement une précision supérieure à la simple comparaison de vecteurs uniques, car les embeddings multi-vecteurs capturent beaucoup plus d’informations contextuelles.
Toutefois, les embeddings multivecteurs sont peu adaptés à l’indexation. Ils sont souvent utilisés dans les tâches de reclassification, comme illustré dans le modèle jina-colbert-v2 présenté dans la section suivante.
Modèles d’embedding Jina
Jina Embeddings v4
jina-embeddings-v4 est un modèle multilingue et multimodal de 3,8 milliards de paramètres (3,8 × 10⁹), compatible avec des textes dans une grande diversité de langues. Il repose sur une architecture innovante qui exploite les connaissances visuelles et linguistiques pour améliorer les performances dans les deux domaines, en particulier dans les tâches de recherche d’images — notamment la recherche de documents visuels. Cela signifie qu’il est capable de traiter des images comme des graphiques, des présentations, des captures d’écran, des pages scannées ou des schémas — des types d’images courants contenant souvent du texte embarqué, en dehors du champ des modèles de vision entraînés sur des scènes du monde réel.
Nous avons optimisé ce modèle pour différentes tâches à l’aide d’adaptateurs compacts LoRA (Low-Rank Adaptation). Cette approche nous permet d’entraîner un modèle unique capable de se spécialiser dans plusieurs tâches sans perte de performance, pour un coût mémoire ou calculatoire minimal.
Principales fonctionnalités :
- Des performances de pointe en recherche de documents visuels, avec en plus une excellente prise en charge du texte multilingue et des images classiques — surpassant des modèles bien plus volumineux.
- Prise en charge de contextes d’entrée étendus : 32 768 jetons correspondent à environ 80 pages de texte en anglais double interligne, et 20 mégapixels équivalent à une image de 4 500 × 4 500 pixels.
- Taille des embeddings sélectionnée par l’utilisateur, allant de 2048 dimensions au maximum jusqu’à 128 dimensions. Nous avons constaté empiriquement une forte dégradation des performances en dessous de ce seuil.
- Compatibilité avec les embeddings simples et multi-vecteurs. Pour le texte, la sortie multivecteur se compose d’un embedding de 128 dimensions pour chaque jeton d’entrée. Pour les images, un embedding de 128 dimensions est généré pour chaque bloc de 28 × 28 pixels nécessaires à la couverture de l’image.
- Optimisation pour la recherche asymétrique grâce à une paire d’adaptateurs LoRA spécialement entraînés à cet effet.
- Un adaptateur LoRA optimisé pour le calcul de similarité sémantique.
- Prise en charge spécifique des langages de programmation et des frameworks IT, également via un adaptateur LoRA.
Nous avons développé jina-embeddings-v4 comme outil polyvalent pour toute une gamme de tâches : recherche, compréhension du langage naturel et analyse basée sur l’IA. C’est un modèle relativement compact au vu de ses capacités, mais qui demande tout de même des ressources importantes pour être déployé, et convient mieux à une utilisation via une API cloud ou dans un environnement haute performance.
Jina Embeddings v3
jina-embeddings-v3 est un modèle d’embedding multilingue, léger, performant, axé sur le texte, avec moins de 600 millions de paramètres. Il prend en charge jusqu’à 8 192 jetons de texte en entrée et génère des embeddings vectoriels simples, avec des tailles personnalisables (de 1 024 à 64 dimensions).
Nous avons entraînerjina-embeddings-v3 non seulement pour la recherche d’informations et la similarité sémantique, mais aussi pour des tâches de classification, comme l’analyse de sentiments, la modération de contenu, le clustering, l’agrégation de nouvelles et la recommandation. Comme jina-embeddings-v4, ce modèle utilise des adaptateurs LoRA spécialisés pour les cas d’usage suivants :
- Récupération asymétrique
- Similarité sémantique
- Classification
- Clustering
jina-embeddings-v3 est un modèle beaucoup plus compact que jina-embeddings-v4 , avec une taille de contexte en entrée considérablement réduite, mais qui est aussi moins coûteux à exécuter. Malgré cela, il offre des performances très compétitives (bien qu’uniquement sur du texte) et représente un choix pertinent pour de nombreux cas d’usage.
Embeddings de code Jina
Les modèles Jina spécialisés pour l’embedding de code — jina-code-embeddings (0,5 Md et 1,5 Md de paramètres) — prennent en charge 15 langages de programmation ainsi que des textes en anglais dans le domaine de l’informatique et des technologies de l’information. Ce sont des modèles compacts, avec respectivement 500 millions et 1,5 milliard de paramètres. Les deux modèles acceptent jusqu’à 32 768 jetons en entrée et permettent à l’utilisateur de définir la taille des embeddings générés : de 896 à 64 dimensions pour le plus petit, et de 1 536 à 128 pour le plus grand.
Ces modèles prennent en charge la recherche asymétrique, pour cinq spécialisations par type de tâche, en utilisant une méthode de réglage par préfixe plutôt que des adaptateurs LoRA :
- Code vers code. Récupère du code similaire entre différents langages de programmation. Utilisé pour l’alignement de code, l’élimination des doublons, la migration et le refactoring.
- Langage naturel vers code. Permet de retrouver du code correspondant à une requête en langage naturel, un commentaire ou une description.
- Code vers langage naturel. Associe du code source à de la documentation ou à d’autres textes en langage naturel.
- Complétion de code à partir de code. Suggère du code pertinent pour compléter ou améliorer un extrait existant.
- Questions-réponses techniques. Fournit des réponses en langage naturel sur des sujets technologiques, idéal pour des cas d’usage liés à l’assistance technique.
Ces modèles offrent des performances supérieures pour les tâches portant sur la documentation technique et les ressources de développement, à un coût computationnel relativement faible. Ils s’intègrent facilement dans les environnements de développement et les assistants de programmation.
Jina ColBERT v2
jina-colbert-v2 est un modèle d’embedding multivecteur de 560 millions de paramètres. Il est multilingue, entraîné à partir de données couvrant 89 langues, et prend en charge les tailles d’embedding variables et la recherche asymétrique.
Comme mentionné précédemment, les plongements multivecteurs sont peu adaptés à l’indexation mais sont très utiles pour augmenter la précision des résultats d’autres stratégies de recherche. En utilisant jina-colbert-v2, vous pouvez calculer à l’avance les embeddings multivecteurs, puis les utiliser pour reclasser les candidats lors de la recherche, au moment de la requête. Cette méthode est moins précise que l’utilisation directe d’un modèle de reclassification, mais beaucoup plus efficace, car elle consiste uniquement à comparer les embeddings multivecteurs déjà stockés, sans faire appel au modèle d’IA à chaque requête ou comparaison de candidats. Elle est particulièrement adaptée aux cas d’usage où la latence et le coût de calcul d’un modèle de reclassification seraient trop élevés, ou lorsque le nombre de documents candidats est trop important.
Ce modèle produit une séquence d’embeddings, un par jeton d’entrée, et les utilisateurs peuvent choisir des embeddings de 128, 96 ou 64 dimensions. Les correspondances candidates sont limitées à 8 192 jetons. Les requêtes sont encodées de manière asymétrique, ce qui impose à l’utilisateur de spécifier si un texte est une requête ou une correspondance candidate, et de limiter la requête à 32 jetons.
Jina CLIP v2
jina-clip-v2 est un modèle d’embedding multimodal de 900 millions de paramètres, entraîné pour produire des embeddings proches entre un texte et une image décrivant le même contenu. Son usage principal est la recherche d’images à partir de requêtes textuelles, mais c’est aussi un modèle textuel performant. Il permet de réduire les coûts liés à la gestion de modèles distincts pour la recherche texte-texte et texte-image.
Ce modèle prend en charge un contexte d’entrée textuel de 8 192 jetons, et les images sont redimensionnées à 512 × 512 pixels avant génération des embeddings.
Les architectures CLIP (Contrastive Language–Image Pretraining) sont simples à entraîner, produisent des modèles compacts, mais présentent des limites structurelles importantes. Elles ne permettent pas de transférer la connaissance d’un support à un autre pour améliorer les performances. Elles ne peuvent pas utiliser un support pour améliorer leurs performances sur un autre. Ainsi, même si le modèle sait que les mots « chien » et « chat » sont plus proches en sens que ne l’est « voiture », il ne saura pas forcément qu’une image de chien est plus proche d’une image de chat qu’elle ne l’est d’une image de voiture.
Cependant, ce modèle souffre également d’un problème connu sous le nom de décalage de modalité : par exemple, un texte sur les chiens pourrait être plus proche, en termes d’embedding, d’un texte sur les chats que d’une image de chien. À cause de cette limitation, nous recommandons d’utiliser CLIP soit pour la recherche texte-image, soit comme modèle textuel seul, mais pas pour combiner les deux dans une même requête.
Modèles de reclassification
Les modèles de reclassification prennent une ou plusieurs correspondances candidates, ainsi qu’une requête en entrée, et les comparent directement, produisant ainsi des correspondances beaucoup plus précises.
En théorie, on pourrait utiliser un reranker directement pour la recherche d’informations, en comparant chaque requête à chaque document stocké, mais cela serait extrêmement coûteux en calcul et peu réaliste, sauf pour de très petites collections. En pratique, les rerankers sont donc surtout utilisés pour réévaluer des listes restreintes de correspondances candidates identifiées par d’autres moyens, comme une recherche par embeddings ou d’autres algorithmes de recherche. Les modèles de reclassification conviennent parfaitement aux architectures de recherche hybrides ou fédérées, où une requête peut être envoyée à plusieurs systèmes de recherche distincts, chacun interrogeant ses propres ensembles de données et retournant des résultats différents. Ils sont très efficaces pour fusionner des résultats hétérogènes en une seule réponse de haute qualité.
La recherche basée sur des embeddings peut représenter un engagement important : elle implique de réindexer toutes vos données stockées et de revoir les attentes des utilisateurs sur les résultats. L’ajout d’un reranker à une solution de recherche existante permet de bénéficier des avantages de l’IA sans avoir à réarchitecturer toute la solution.
Modèles de reclassification Jina
Jina Reranker m0
jina-reranker-m0 est un reclassificateur multimodal de 2,4 milliards de paramètres, qui prend en charge des requêtes textuelles et des candidats textuels et/ou visuels. C’est le modèle de référence pour la recherche documentaire visuelle, idéal pour interroger des bases contenant des PDF, captures d’écran, images modifiées ou documents semi-structurés, qu’ils soient textuels, visuels ou mixtes.
Ce modèle prend une requête et une correspondance candidate, et retourne un score. Lorsque la même requête est utilisée avec différents candidats, les scores sont comparables et peuvent être utilisés pour les classer. Il prend en charge une taille d’entrée totale allant jusqu’à 10 240 jetons, incluant la requête et le texte ou l’image candidat(e). Chaque bloc d’image de 28 × 28 pixels utilisé pour couvrir l’image compte comme un jeton pour le calcul de la taille d’entrée.
Jina Reranker v3
jina-reranker-v3 est un reclassificateur textuel de 600 millions de paramètres avec des performances de pointe pour sa taille. Contrairement à jina-reranker-m0, il traite une requête unique et une liste pouvant aller jusqu’à 64 candidats, puis renvoie leur ordre de classement. Il prend en charge un contexte d’entrée de 131 000 jetons, incluant la requête et tous les candidats.
Jina Reranker v2
jina-reranker-v2-base-multilingual est un modèle compact et polyvalent, intégrant des fonctionnalités supplémentaires comme le support de l’appel de fonction et des requêtes SQL. Pesant moins de 300 millions de paramètres, ce modèle offre un reclassement multilingue rapide, efficace et précis, avec un support supplémentaire pour la sélection de tables SQL et de fonctions externes associées aux requêtes textuelles, ce qui le rend adapté aux cas d’usage orientés agent.
Petits modèles de langage génératif
Les modèles de langage génératif sont des modèles comme ChatGPT d’OpenAI, Google Gemini et Claude d’Anthropic, qui acceptent des entrées textuelles ou multimédias et renvoient des sorties textuelles. Il n’existe pas de frontière claire entre les grands modèles de langage (LLM) et les petits modèles de langage (SLM), mais les difficultés pratiques liées au développement, à l’exploitation et à l’usage de LLM de pointe sont bien connues. Les modèles les plus connus ne sont pas distribués publiquement, donc nous ne pouvons qu’estimer leur taille : ChatGPT, Gemini et Claude seraient dans la fourchette des 1 à 3 milliards de milliards de paramètres (1–3×10¹²).
Exécuter ces modèles, même lorsqu’ils sont en accès libre, dépasse largement les capacités du matériel conventionnel et requiert les puces les plus avancées, organisées en réseaux massivement parallèles. Il est possible d’utiliser des LLM via des API payantes, mais cela implique des coûts importants, une forte latence, et pose des défis en matière de protection des données, de souveraineté numérique et de rapatriement hors du cloud. En outre, les coûts liés à l’entraînement et à la personnalisation de modèles de cette taille peuvent être conséquents.
C’est pourquoi de nombreuses recherches portent sur le développement de modèles plus petits qui, bien qu’ils n’offrent pas toutes les capacités des plus grands LLM, peuvent exécuter certaines tâches spécifiques avec une qualité équivalente et à moindre coût. Les entreprises déploient généralement des logiciels pour répondre à des besoins spécifiques, et les logiciels d’IA n’échappent pas à cette règle : les solutions basées sur des SLM sont souvent préférées aux LLM. Ils peuvent généralement être exécutés sur du matériel standard, sont plus rapides, consomment moins d’énergie et sont beaucoup plus faciles à personnaliser.
L’offre SLM de Jina se développe à mesure que nous cherchons à intégrer l’IA dans des solutions de recherche concrètes.
Jina SLMs
ReaderLM v2
ReaderLM-v2 est un modèle de langage génératif capable de convertir du HTML en Markdown ou en JSON, selon des schémas JSON fournis par l’utilisateur et des instructions en langage naturel.
Le prétraitement et la normalisation des données sont des étapes clés dans le développement de solutions de recherche performantes pour les données numériques, mais les données issues du web sont souvent désordonnées, et les stratégies simples de conversion montrent vite leurs limites. Au contraire, ReaderLM-v2 propose une solution d’IA intelligente, capable de comprendre le chaos d’un arbre DOM brut issu d’une page web, et d’identifier avec robustesse les éléments utiles.
Avec 1,5 milliard de paramètres (1,5 × 10⁹), ils sont mille fois plus compacts que les LLM de dernière génération tout en offrant des performances comparables sur des tâches ciblées.
Jina VLM
jina-vlm est un modèle de langage génératif de 2,4 milliards de paramètres (2,4×10⁹), conçu pour répondre à des questions en langage naturel à propos d’images. Il offre un excellent support pour l’analyse de documents visuels, c’est-à-dire la réponse à des questions sur des captures d’écran, des présentations, des schémas ou d’autres images non naturelles.
Par exemple :

Crédit photo : User dave_7 at Wikimedia Commons.
.jpg){kind=link}
Ils sont également très performants pour la lecture de texte dans des images:

Crédit photo : ser Vauxford at Wikimedia Commons.
{kind=link}
Mais là où jina-vlm excelle vraiment, c'est dans la compréhension du contenu des images informatives et artificielles :

Crédit image : Wikimedia Commons.
{kind=link}
Ou :

Crédit image : Wikimedia Commons.
.png){kind=link}
jina-vlm Ils conviennent parfaitement pour la génération automatique de légendes, les descriptions de produits, les balises alt pour les images, et les applications d’accessibilité pour les personnes malvoyantes. Ils ouvrent aussi la voie à des systèmes RAG (retrieval-augmented generation) capables d’utiliser des données visuelles et de permettre à des agents d’IA de traiter des images sans intervention humaine.
Pour aller plus loin

11 mai 2026
Apporter du dynamisme à Elasticsearch : intégration de la prise en charge native de l’API Prometheus
Interrogez Elasticsearch directement depuis des clients compatibles Prometheus via les points de terminaison natifs PromQL, de découverte et de métadonnées. Envoyez des données à Elasticsearch avec Prometheus Remote Write.

11 mai 2026
Un seul index, tous les médias : présentation de jina-embeddings-v5-omni
jina-embeddings-v5-omni vous permet d’intégrer du texte, des images, des vidéos et de l’audio dans un seul index Elasticsearch, et d’effectuer des requêtes sur tous ces éléments à la fois.

22 avril 2026
Jina Embeddings v3 désormais disponible via Model Garden sur Gemini Enterprise Agent Platform
Le modèle de fondation de recherche Jina, jina-embeddings-v3, est désormais déployable automatiquement via Model Garden sur Gemini Enterprise Agent Platform ; d’autres suivront. Exécutez jina-embeddings-v3 sur un seul GPU L4 au sein de votre propre VPC.

23 mars 2026
Utilisation de l'API d'inférence Elasticsearch avec les modèles Hugging Face
Découvrez comment connecter Elasticsearch aux modèles Hugging Face à l'aide de points de terminaison d'inférence, et comment créer un système de recommandation de blogs multilingue avec recherche sémantique et complétion de chat.

27 mars 2026
Création d'un serveur Elasticsearch MCP avec TypeScript
Apprenez à créer un serveur MCP Elasticsearch avec TypeScript et Claude Desktop.