Jina AI 和 Elastic 正在发布 jina-embeddings-v5-text,这是一系列新的、高性能、紧凑的文本嵌入模型,在所有主要任务类型中,其性能在同等规模的模型中处于最先进水平。
该系列包括两个型号:
jina-embeddings-v5-text-smalljina-embeddings-v5-text-nano
这些模型是创新的嵌入模型新训练方法的成功结果。它们的性能优于规模是其数倍的模型,节省了内存和计算资源,并更快地响应请求。
jina-embeddings-v5-text-small 模型拥有 6.77 亿个参数,支持 32,768 个令牌的输入上下文窗口,并默认生成 1,024 维的嵌入。
jina-embeddings-v5-text-nano 其大小约为同类产品的三分之一,拥有 2.39 亿个参数和 8,192 个令牌的输入上下文窗口,并生成 768 维的嵌入。
| 型号名称 | 总大小 | 输入上下文窗口大小 | 嵌入大小 |
|---|---|---|---|
| jina-v5-text-small | 677M 参数 | 32,768 个令牌 | 1024 维度 |
| jina-v5-text-nano | 239M 参数 | 8,192 个令牌 | 768 维度 |
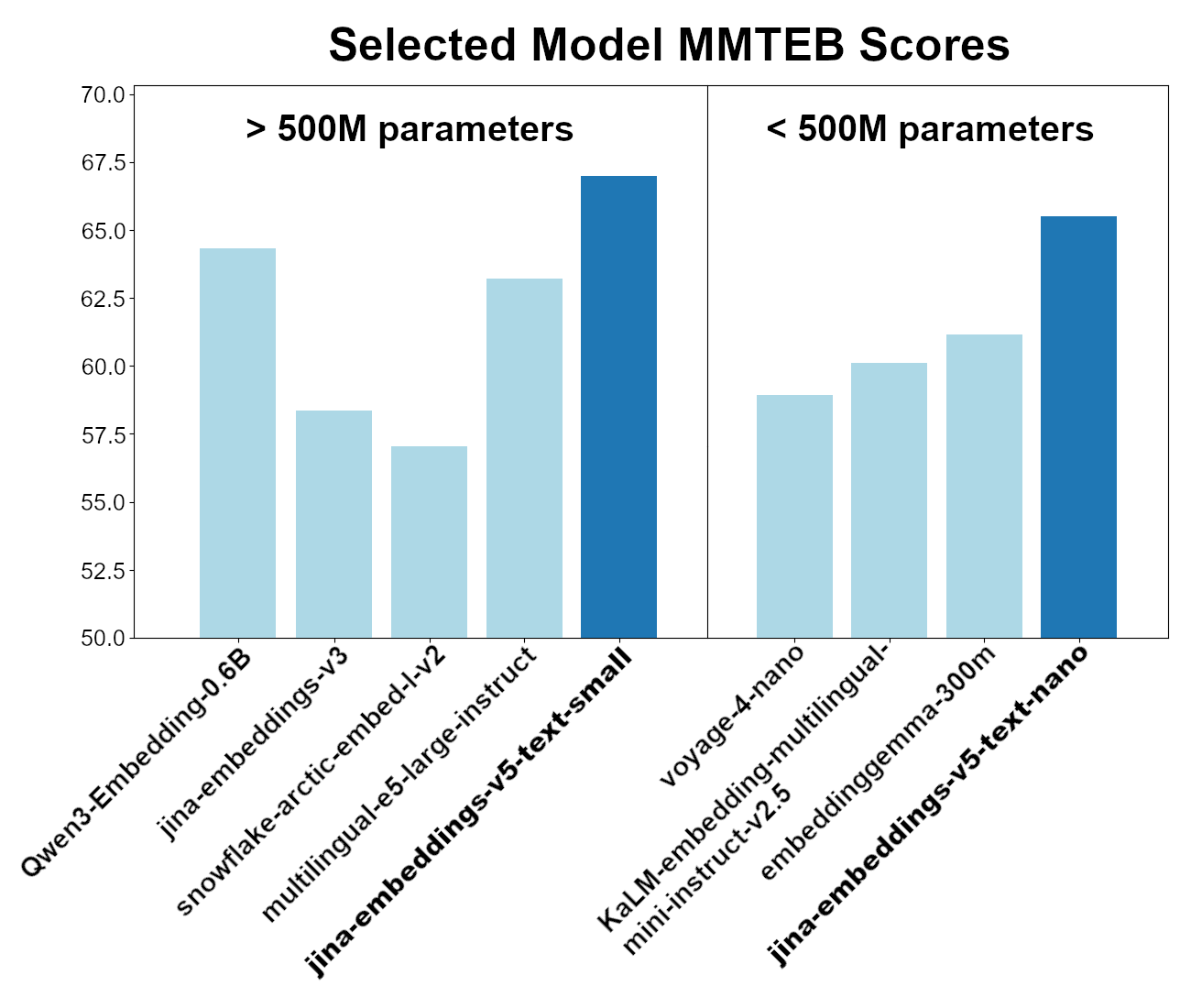
这两个模型在整体 MMTEB(多语言 MTEB)基准性能方面是同类中最好的。在参数量少于 5 亿的模型中,jina-embeddings-v5-text-nano 表现最佳,尽管其参数量不足 2.5 亿,而 jina-embeddings-v5-text-small 模型是参数量少于 7.5 亿的多语言嵌入模型中的领先者。
这些模型可通过 Elastic 推断服务 (EIS)、在线 API 获得,并支持本地托管。有关如何访问 jina-embeddings-v5-text 模型的说明,请参阅以下“入门”部分。
嵌入模型和语义索引显著提高了搜索算法的准确性,但在涉及语义相似性和意义提取的任务中也有各种其他用途,例如:
- 查找重复文本。
- 识别释义和翻译。
- 发现主题。
- 推荐引擎。
- 情感和意图分析。
- 垃圾邮件过滤。
- 还有更多。
功能
这个新型号系列具有多项旨在提高相关性和降低成本的功能。
任务优化
我们针对四种广泛的任务类型优化了 jina-embeddings-v5-text 模型:
| 任务 | 示例用例 |
|---|---|
| 检索 | 使用自然语言查询进行搜索,并从文档集合中检索出最相关的匹配项。 |
| 文本匹配 | 语义相似性、去重、释义与翻译对齐等。 |
| 聚类 | 发现主题,自动组织文件集合。 |
| 分类 | 文档分类、情感和意图检测、类似任务。 |
针对一项任务进行优化通常意味着必须在另一项任务上做出妥协,因此大多数嵌入模型仅在某一种任务上具有竞争力。但 jina-embeddings-v5-text 模型能够通过训练特定任务的低秩适配 (LoRA) 适配器在所有四个领域实现专业化,而不会相互影响。
LoRA 适配器是一种用于 AI 模型的插件,它可以显著改变模型的行为,同时仅略微增加模型的总体大小。与为每个任务都配备一个拥有数亿参数的完整模型不同,jina-embeddings-v5-text 模型系列允许您仅使用一个带有紧凑型 LoRa 适配器的模型来完成每项任务。这节省了内存、存储空间和推理成本。
截断嵌入
我们使用套娃式表征学习对 jina-embeddings-v5-text 模型进行了训练,这种方法能让您在几乎不影响嵌入质量的情况下将其压缩到更小的尺寸。
默认情况下,jina-embeddings-v5-text-small 会生成 1024 维嵌入向量,每个向量由 16 位数字表示,使每个嵌入大小为 2KB。对于大量文档集合而言,这可能需要存储大量数据,而在充满嵌入向量的向量数据库中进行搜索,其复杂度与数据库的大小以及每个存储向量的维度数都成正比。
但您可以将嵌入的大小减半(丢弃 1,024 维度中的 512 维),这样占用的空间减半,而搜索速度将翻倍。这会对性能产生影响。丢弃信息会降低精确度。但如下图所示,即使去掉一半的嵌入,性能也只是略有下降:
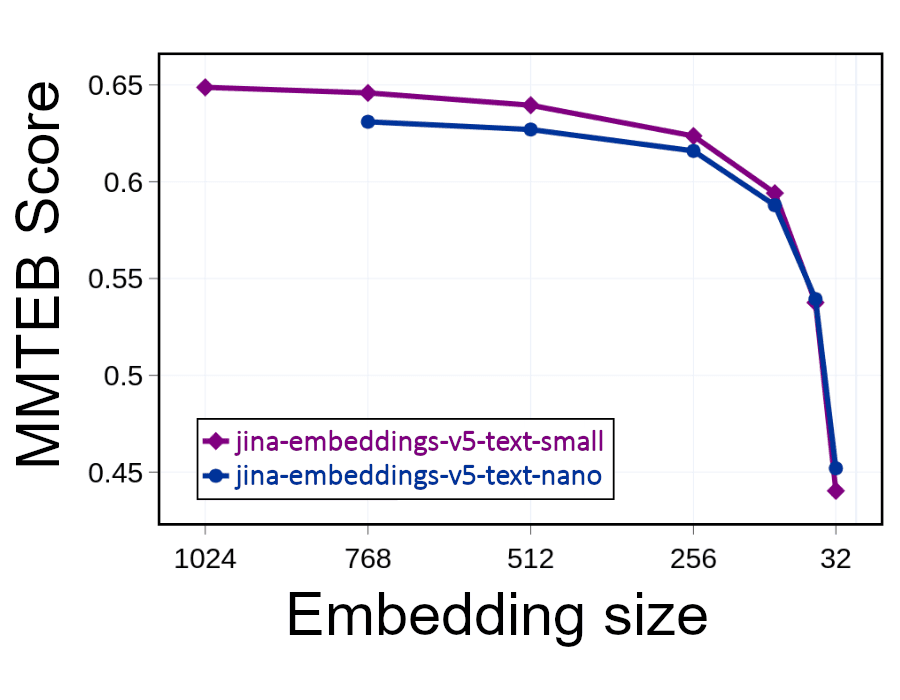
只要您的嵌入至少有 256 维,精确度损失就会相当小。然而,如果低于这一水平,相关性和准确性就会迅速下降。
通过这种截断嵌入方法,用户可以在准确性和计算成本之间自行权衡。它为您提供了从搜索 AI 中大幅提高效率和节约成本的工具。
稳健量化
量化是另一种缩小嵌入尺寸的方法。量化不是丢弃嵌入中的部分数据,而是降低嵌入中数字的精度。jina-embeddings-v5-text 模型以 16 位数字生成嵌入,但我们可以对这些数字进行四舍五入,从而降低其精度和存储所需的位数。在最极端的情况下,我们可以将每个数字缩减为一位(0 或 1),将 jina-embeddings-v5-text 的默认 1024 维嵌入从 2 千字节压缩到 128 字节,仅通过二进制量化就实现了 94% 的压缩率。这与截断一样,能大幅节省内存和计算成本。然而,和截断一样,量化也会使嵌入的准确性降低。
我们已训练了 jina-embeddings-v5-text 模型,通过将精度损失降至最低,使这些模型与 Elasticsearch 的更优的二进制量化一起工作。对这些模型的二值化嵌入进行的基准测试表明,其性能几乎与未二值化的等效模型相当。请参阅技术报告,以获取有关二值化性能的详细消融研究。
多语言性能
许多嵌入模型是多语言的,因为它们已在包含大量语言的材料上进行了训练。但这并不意味着它们在所有支持的语言中都有同样出色的表现。
我们在 MMTEB 多语言基准测试中确定了 211 种语言,并将它们区分开来,以便能够逐个语言地将我们的模型与类似模型进行比较。下图以热力图的形式总结了我们的结果。每个补丁都是一种语言(通过 ISO-639 编码识别),颜色越绿,表明该模型的表现与同类模型的平均表现相比越好:

虽然不同语言的准确性各不相同,但 jina-embeddings-v5-text 模型在世界大多数语言中都处于领先或接近领先地位。
有关多语言性能的详细信息,请参阅 jina-embeddings-v5-text 技术报告。
Elastic 中的 Jina:用于搜索的最先进的原生 AI
借助 EIS 上的 jina-embeddings-v5-text 模型,您可以在 Elasticsearch 中原生运行高性能多语言嵌入模型,并享受完全托管、GPU 加速的推理服务,而无需配置或扩展基础设施。jina-embeddings-v5-text 模型通过采用最新的 AI 技术,以紧凑的多语言模型扩展了不断增长的 EIS 模型目录。这些模型在信息检索和标准数据分析基准方面拥有最先进的性能,并提供了无与伦比的全球多语言支持。
两种模型的大小相差很大,用户可以根据自己的应用需求和预算来选择最合适的模型。此外,jina-embeddings-v5-text 模型拥有强大的嵌入功能,即使截断为较小尺寸或量化为较低精度时仍能保持性能,从而为进一步节省存储和计算成本以及处理延迟提供了机会。
借助 jina-embeddings-v5-text 系列、Jina Reranker 以及 Elastic 的快速向量和 BM25 搜索,用户现在可以使用 Elastic 提供的端到端、最先进的混合搜索功能。当您需要最相关的结果时,无论是用于检索增强生成 (RAG) 管道、搜索应用程序还是数据分析,Elastic 与 Jina 搜索 AI 模型都能提供可靠且经济高效的优质服务。
开始使用
jina-embeddings-v5-text 模型已完全集成到 EIS 中,您可以在创建索引时将 type 字段设置为 semantic_text,并在 inference_id 字段中指定模型(jina-embeddings-v5-text-small 或jina-embeddings-v5-text-nano),如本示例所示:
Elasticsearch 在索引和检索过程中会自动选择合适的 LoRA 适配器。嵌入维度(请参阅上文“截断嵌入”部分)可以在创建自定义推理端点时设置。
有关使用 jina-embeddings-v5-text 模型的更多信息,请参阅 Elasticsearch 文档。
更多信息
要了解有关 jina-embeddings-v5-text 模型的更多信息,请阅读 Jina AI 博客上的发行说明和技术报告,其中包含有关性能和 Jina AI 创新的新训练程序的更详细技术信息。有关在本地下载和运行这些模型的信息,请访问 Hugging Face 上的jina-embeddings-v5-text 集合页面。
Jina AI 模型在 CC-BY-NC-4.0 许可证下可用,因此您可以免费下载并试用它们,但如需用于商业用途,请联系 Elastic 销售人员。
相关内容

2026年5月11日
一个索引,涵盖所有媒体:jina-embeddings-v5-omni 正式发布
jina-embeddings-v5-omni 可让您将文本、图片、视频和音频嵌入到单个 Elasticsearch 索引中,并同时对所有这些内容进行查询。

2026年4月22日
Jina Embeddings v3 现已登陆 Gemini Enterprise Agent Platform Model Garden
Jina 搜索基础模型 jina-embeddings-v3 现可在 Gemini Enterprise Agent Platform Model Garden 上自行部署,后续还将有更多模型加入。在您自己的 VPC 内,使用单个 L4 GPU 即可运行 jina-embeddings-v3。

2026年5月22日
Kibana 将仪表板加载时间最多缩短了 25%——以下是其背后的轮询策略
了解 Kibana 如何使用连续轮询和浏览器端 HTTP/2 检测将仪表板加载时间减少多达 25%,并自动回退到 HTTP/1。

用描述代替手动绘制:通过 MCP 和 ES|QL 构建 AI 原生 Kibana 仪表板。
从提示词到仪表板了解如何使用 example-mcp-dashbuilder 通过自然语言构建 Kibana 仪表板:这是一款开源 MCP 应用,能够编写 ES|QL 查询、创建交互式图表,并将功能完整的仪表板直接导出到 Kibana。
2026年5月18日
一次查询,多个 Elasticsearch Serverless 项目:隆重推出跨项目搜索
Elastic Cloud Serverless 中的跨项目搜索允许您在单个 Elasticsearch 或 ES|QL 请求中查询跨隔离项目的数据:无需重复、无需网络对等,也无需因复制日志而产生出口成本。